HPC and AI Sharing from U. of Tokyo
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

HPC and AI Sharing
from U. of Tokyo
Toshihiro Hanawa
Information Technology Center
The University of Tokyo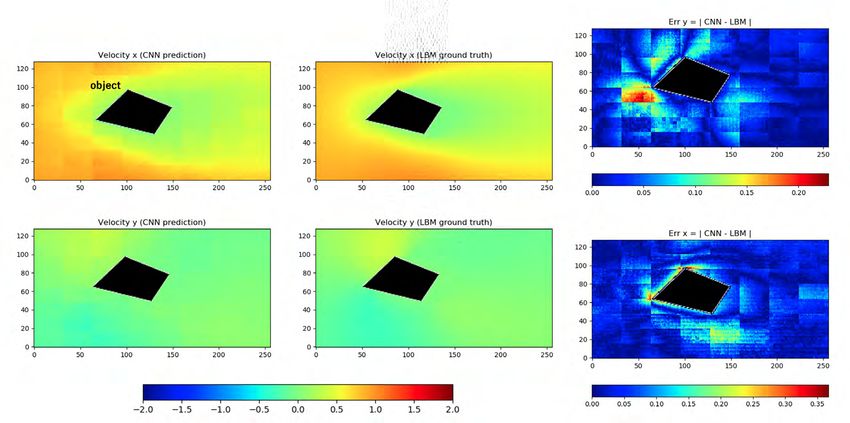
2 Now operating 3 Systems !! 2,600+ users (55+% from outside of U.Tokyo) • Reedbush (HPE, Intel BDW + NVIDIA P100 (Pascal)) – “Integrated Supercomputer Sys. for Data Analyses & Scientific Simulations” – Our first GPU System, DDN IME (Burst Buffer) – Reedbush-U: CPU only, 420 nodes, 508 TF (Jul. 2016-June 2020) – Reedbush-H: 120 nodes, 2 GPUs/node: 1.42 PF (Mar. 2017- Nov. 2021) – Reedbush-L: 64 nodes, 4 GPUs/node: 1.43 PF (Oct. 2017 – Nov. 2021) • Oakforest-PACS (OFP) (Fujitsu, Intel Xeon Phi (KNL)) – JCAHPC (U.Tsukuba & U.Tokyo) – 25 PF, #22 in 56th TOP 500 (November 2020) (#4 in Japan) – Omni-Path Architecture, DDN IME (Burst Buffer) • Oakbridge-CX (OBCX) (Fujitsu, Intel Xeon Platinum 8280, CLX) – Massively Parallel Supercomputer System – 6.61 PF, #69 in 56th TOP 500, July 2019-June 2023 – SSD’s are installed to 128 nodes (out of 1,368)

3
Reedbush: Our First System with GPU’s
• Data Science, Deep Learning
– New types of users other than Compute Nodes: 1.925 PFlops
Reedbush-H (w/Accelerators)
1297.15-1417.15 TFlops
traditional CSE (Computational Reedbush-U (CPU only) 508.03 TFlops
CPU: Intel Xeon E5-2695 v4 x 2 socket
CPU: Intel Xeon E5-2695 v4 x 2 socket
Science & Engineering) are (Broadwell-EP 2.1 GHz 18 core,
45 MB L3-cache) ×420
Mem: 256 GB (DDR4-2400, 153.6 GB/sec)
GPU: NVIDIA Tesla P100 x 2 ×120
(Pascal, SXM2, 4.8-5.3 TF,
needed Mem: 256GB (DDR4-2400, 153.6 GB/sec)
Mem: 16 GB, 720 GB/sec, PCIe Gen3 x16,
NVLink (for GPU) 20 GB/sec x 2 brick )
SGI Rackable
C2112-4GP3 SGI Rackable C1100 series
InfiniBand EDR 4x Dual-port InfiniBand FDR 4x
100 Gbps /node 56 Gbps x2 /node
InfiniBand EDR 4x, Full-bisection Fat-tree
Mellanox CS7500
145.2 GB/s 634 port +
436.2 GB/s SB7800/7890 36
port x 14
Management
Servers
Parallel File High-speed
Integrated Supercomputer System System
5.04 PB
File Cache System Login
Login
Login
Login
nodeLogin
node Login
node UTnet Users
for Data Analyses & Scientific 209 TB node
node
node
Login Node x6
Simulations Lustre Filesystem
DDN SFA14KE x3
DDN IME14K x6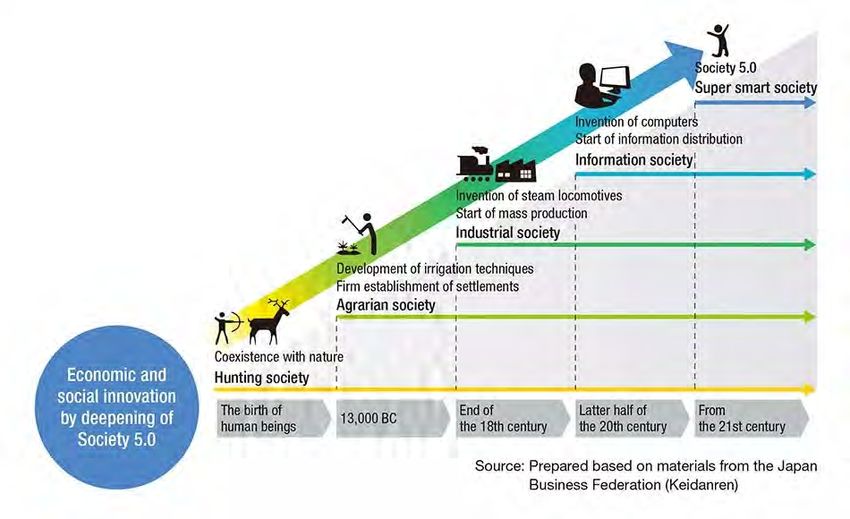
Coordination between UTokyo Hospital and Reedbush System
Reedbush
• Security is crucial !! Compute node
• Anonymized personal
data is transferred to
RB
• Dedicated login node
and VPN are
introduced
for isolation with other ITC, UTokyo
projects
• Only least amount of
data required for
calculation is placed
on RB
Allowed PCs
UTokyo
Hospital
4
5
Research Area based on CPU Hours (FY.2019)
Engineering
Earth/Space
Bio Informatics Material
Info. Sci. Engineering
Alg.
Medical Image Energy/Physics
Recognition, Info. Sci. : System
Genome Analysis Material
Engineering 医療画像処理 Science Info. Sci. : Algrorithms
Info. Sci. : AI
Energy/
Material
Bio Simulations Physics Education
Science
Molecular Sim. Industry
Biomechanics Bio
Earth/ 生体力学
Space Info. Sci: Bioinformatics
AI
Social Sci. & Economics
Multicore Cluster GPU Cluster Data
Intel BDW Only Intel BDW + NVIDIA P100
(Reedbush-U) (Reedbush-H)
6
Research Area based on CPU Hours (FY.2019)
OBCX: October 2019~September 2020
Engineering Engineering
Bio Informatics
Bio Info. Earth/Space
Medical Image Earth/Space
Material
Recognition Material
Bio Sim.
Energy/Physics
医療画像処理 Energy/Physics
Earth & Info. Sci. : System Engineering
Bio Sim. Info. Sci. : System
Space
Info. Sci. : Algrorithms Info. Sci. : Algrorithms
Science Energy/
Info. Sci.(QCD)
Physics : AI Info. Sci. : AI
Energy/ Education Education
Physics (QCD)
Industry Earth & Industry
Space Sci.
Material Bio Material Science Bio
Science
Bioinformatics Bioinformatics
Social Sci. & Economics Social Sci. & Economics
Data Data
Manycore Cluster Multicore Cluster
Intel Xeon Phi Intel Xeon CLX
(Oakforest-PACS) (OFP) (Oakbridge-CX) (OBCX)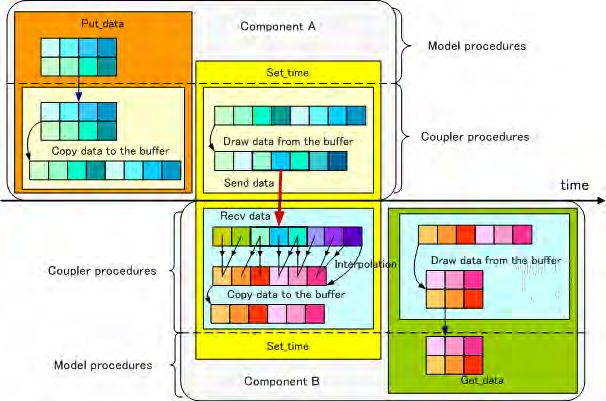
7
Society 5.0: the Cabinet Office of Japan
• Super Smart & Human-centered Society by Digital Innovation
(IoT, Big Data, AI etc.) and by Integration of Cyber Space &
Physical Space
5.0: Super Smart
4.0: Information
3.0: Industry
2.0: Agrarian
1.0: Hunting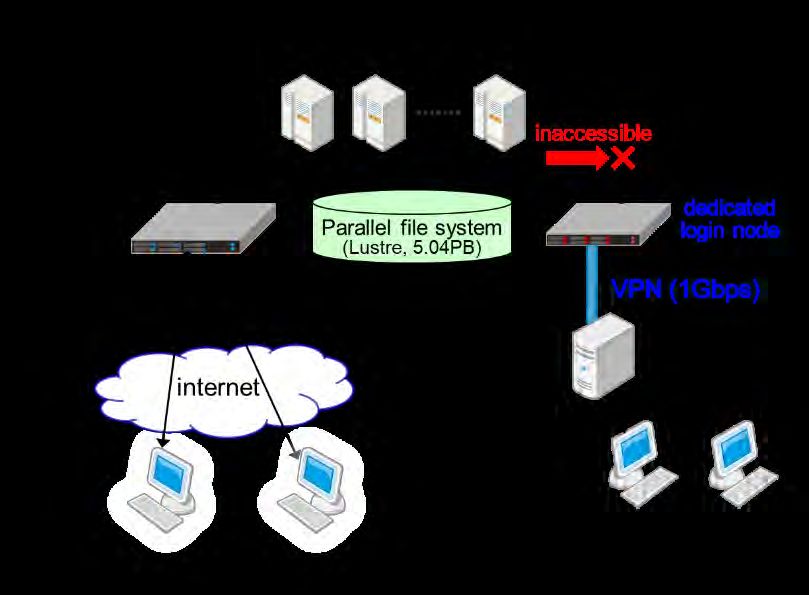
8
Future of Supercomputing Info. Sci.
Bio Informatics
Engineering
Engineering
Earth/Space
Material
Energy/Physics
Alg.
Medical Image Info. Sci. : System
• Various Types of Workloads
Recognition Material
Engineering Science Info. Sci. : Algrorithms
医療画像処理
Info. Sci. : AI
Energy/
Material
Bio Simulations Physics Education
Science
Molecular Sim. Industry
– Computational Science & Engineering: Simulations Earth/
Space
Biomechanics
生体力学 Info. Sci:
AI
Bio
Bioinformatics
Social Sci. & Economics
Data
– Big Data Analytics Multicore Cluster
Intel BDW Only
(Reedbush-U)
GPU Cluster
Intel BDW + NVIDIA P100
(Reedbush-H)
– AI, Machine Learning …
• Integration/Convergence of (Simulation + Data + Learning)
(S+D+L) is important towards Society 5.0: AI for HPC,
Sophiscated Simulation
• Two Platforms will be introduced in
Kashiwa II Campus of the University of BDEC: S +D+L
Tokyo (Spring 2021)
D
– BDEC (Big Data & Extreme Computing): Batch
– Data Platform (DP/mdx): Cloud-like, More
Flexible/Interactive
mdx: S + + L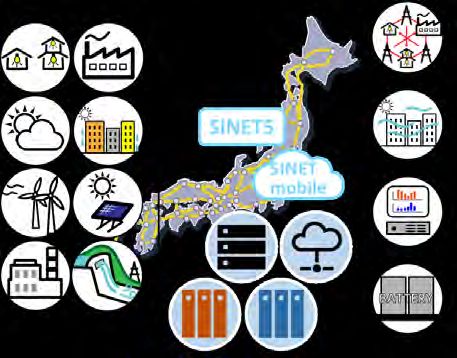
Supercomputers in ITC/U.Tokyo
9
Information Technology Center, The University of Tokyo
FY11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Yayoi: Hitachi SR16000/M1 Oakbridge-CX Massively Parallel
IBM Power-7 Intel Xeon CLX Supercomputer
54.9 TFLOPS, 11.2 TB 6.61 PFLOPS System
T2K Tokyo Manycore-based Large- Oakforest-PACS (OFP) (JCAHPC)
Hitachi scale Supercomputer Post OFP
Fujitsu, Intel Xeon Phi (JCAHPC)
140TF, 31.3TB System, JCAHPC 25PFLOPS, 919.3TB
Integrated Supercomputer
Oakleaf-FX: Fujitsu PRIMEHPC FX10, BDEC: Wisteria/BDEC-01
SPARC64 IXfx System for Simulation, Data Big Data & Extreme Computing
1.13 PFLOPS, 150 TB and Learning 33.1 PFLOPS
Oakbridge-FX
136.2 TFLOPS, 18.4 TB mdx
Integrated Supercomputer System for Reedbush-U/H, HPE
Data Analyses & Scientific Intel BDW + NVIDIA P100
Simulations 1.93 PFLOPS
Supercomputer System with
Accelerators for Long-Term
Reedbush-L HPE
1.43 PFLOPS
Executions
10
Wisteria/BDEC-01 The 1st BDEC System (Big Data &
• Operation starts in May 2021 Extreme Computing)
Platform for Integration of (S+D+L)
• 33.1 PF, 8.38 PB/sec by Fujitsu
– ~4.5 MVA with Cooling, ~360m2
Wisteria/BDEC-01
• Hierarchical, Hybrid, Heterogeneous
(h3) Simulation Nodes:
Odyssey
Fujitsu/Arm A64FX
• 2 Types of Node Groups 25.9PF, 7.8 PB/s
Shared File 2.0 TB/s Fast File
– Simulation Nodes: Odyssey System System
(SFS) Data/Learning (FFS)
• Fujitsu PRIMEHPC FX1000 (A64FX), 25.9 PF 25.8 PB, 500 GB/s
Nodes: Aquarius
1 PB, 1.0 TB/s
– 7,680 nodes (368,640 cores) Intel Ice Lake + NVIDIA A100
7.20 PF, 578.2 TB/s
– Data/Learning Nodes: Aquarius 800 Gbps
• Data Analytics & AI/Machine Learning
External External
• Intel Xeon Ice Lake + NVIDIA A100, 7.2PF Resources Resources
– 45 nodes (90x Ice Lake, 360x A100) External Network
• Some of the DL nodes are connected to external resources directly
• File Systems: SFS (Shared/Large) + FFS (Fast/Small)System Overview
Odyssey (Simulation)︓7,680 node (Peak 25.9 PFLOPS, Aggregate Mem. BW. 7.8 PB/s)
Aquarius (Data+Learning)︓45 node (Peak 7.2 PFLOPS, Aggregate Mem. BW. 578.2 TB/s)
External Communication (Ethernet)
Odyssey (Simulation) Aquarius (Data+Learning) Login node Shared FS for Login node
7,680 node
45node 20node
FUJITSU Server
PRIMERGY RX2530 M5 x 20 node FUJITSU Server
Peak Performance(FP64): 96TFLOPS PRIMERGY RX2530 M5 x 2
Aggregate Memory Bandwidth:7.5TiB ETERNUS DX60 S5 x 1
FUJITSU Server Effective capacity: 14.4TB
PRIMERGY GX2570-next x 45 node
FUJITSU Supercomputer Interconnect for (NVIDIA A100 x 8 unit / node)
PRIMEHPC FX1000 x 7,680 node (20 rack) Peak Performance(FP64): 7.2PFLOPS
Odyssey
Peak Performance(FP64) : 25.9PFLOPS (Tofu Interconnect-D) Total Memory Capacity : 36.5TiB
Total Memory Capacity : 240TiB Aggregate Memory Bandwidth: 578.2TB/s
Bisection BW : 13TB/s
Aggregate Memory Bandwidth : 7.8PB/s
Interconnect for Aquarius and Interconnect between Odyssey and Aquarius (InfiniBand EDR/HDR)
Life network / Management network (Ethernet)
Network Storage for
Fast Filesystem Shared Filesystem Management server
Management server
MDS,MDT x1set OSS,OST x16set
MDS,MDT x1set OSS,OST x16set
FUJITSU Server
PRIMERGY RX2530 M5
x 13 FUJITSU Server
Filesystem: FEFS
1PB Filesystem︓FEFS 25PB (Job x5, Operation x2, PRIMERGY RX2530 M5 x 2
Data transfer rate for storage: 1.0TB/s Data transfer rate for storage: 0.5TB/s
Auth. x2, Web portalx2, ETERNUS DX100 S5 x 1
MDS︓PRIMERGY RX2540 M5 x 2 MDS︓PRIMERGY RX2540 M5 x 4
Security log x2) Effective capacity: 420TB
MDT︓ETERNUS AF250 S3 x 1 MDT︓ETERNUS AF250 S3 x 1
OSS, OST : 2VM/CM, DDN SFA400NVXE x 16 OSS, OST : 1VM/CM, DDN SFA7990XE x 16
FUJITSU CONFIDENTIAL 11 Copyright 2020 FUJITSU LIMITEDWisteria/BDEC-01:
Platform for Integration of (S+D+L)
• Wisteria (紫藤)
Wisteria/BDEC-01 – “Legend of Princess Wisteria” at
Simulation Nodes: Lake Teganuma in Kashiwa
Odyssey
Fujitsu/Arm A64FX • Odyssey
25.9PF, 7.8 PB/s
Shared File Fast File
– Callsign of Apollo 13’s Command
2.0 TB/s
System System Module (CM)
(SFS) Data/Learning (FFS)
25.8 PB, 500 GB/s
Nodes: Aquarius
1 PB, 1.0 TB/s • Aquarius
Intel Ice Lake + NVIDIA A100
7.20 PF, 578.2 TB/s – Callsign of Apollo 13’s Luna
800 Gbps
Module (LM)
External External
Resources Resources
External Network
https://www.cc.u-tokyo.ac.jp/public/pr/pr-wisteria.php 12Simulation Nodes
Simulation
Odyssey
25.9 PF, 7.8 PB/s Codes
Simulation Nodes
Optimized Models & Odyssey
Fast File Shared File Parameters Results
System System Wisteria/BDEC-01
(FFS) (SFS) Machine Observation
1.0 PB, 25.8 PB,
1.0 TB/s 0.50 TB/s Learning, DDA Data/Learning Data
Nodes, Aquarius
Data/Learning Nodes
Aquarius Data Assimilation
7.20 PF, 578.2 TB/s Data Analysis
External Resources
Server, Storage, DB, Sensors etc.
1314
Possible Applications (S+D+L) on BDEC with
h3-Open-BDEC
• Simulations with Data Assimilation
– Very Typical Example of (S+D+L)
• Atmosphere-Ocean Coupling for
Weather and Climate Simulations
– AORI/U.Tokyo, RIKEN R-CCS
• Earthquake Simulations with Real- * Also applicable to full coupling,
Time Data Assimilation
multiple applications
App. A
2. Send-data extraction from
– ERI/U. Tokyo, prototyping using OBCX the buffer, and data sending
• Real-Time Disaster Simulations
– Flood, Tsunami 1. Data-packing
into a buffer
• (S+D+L) for Existing Simulation Codes 3. Data-packing after the 4. Data extraction
(Open Source Software) interpolation process from the buffer
– OpenFOAM App. B15
Simulation
Codes
3D Earthquake Simulation
Optimized Models &
Simulation Nodes
Odyssey
with Real-Time Data
Parameters
Machine
Wisteria/BDEC-01
Results
Observation
Observation/Assimilation
Learning, DDA Data/Learning Data ㋪㊡㋖㋪㊡㋴㌉㌅㌋& ㎮㍮4
Nodes, Aquarius Observation Network
㍨僳价偬冓& '2000㍱) for Earthquake:
僳㌸价偬冓& '4000㍱) ㊩64O(10
5 Points
亜8etc,))价偬冓& ㎃㍠; )
Data Assimilation
Data Analysis
[c/o Furumura]
External Resources
Server, Storage, DB, Sensors etc. & 丼)㌒㍞㊩6
争@傠㌸㌙僳䁘們E6㋃㋡& 4000㍱)
Fast Network
NIED
JDXnet University’s
Originally Case 1
developed in ERI
ERI/U.Tokyo Case 2
IP Network
TDX
Case N
Univ. Local univ.
Real-Time Data/Simulation Assimilation
L2VPN Real-Time Update of Underground Model
JMA SINET5 / JGN
IP Network [c/o Prof. T.Furumura
(ERI/U.Tokyo)]16
h3-Open-BDEC
Innovative Software Platform for Integration of (S+D+L) on BDEC
① Methods for Numerical Analysis with High-Performance/High-
Reliability/Power-Saving based on the New Principle of Computing by
ü Adaptive Precision
h3-Open-BDEC
ü Accuracy Verification Numerical Alg./Library App. Dev. Framework Control & Utility
ü Automatic Tuning New Principle for Simulation + Data +
Integration +
Communications+
② Hierarchical Data Computations Learning
Utilities
Driven Approach h3-Open-MATH
Algorithms with High- h3-Open-APP: Simulation h3-Open-SYS
(hDDA) based on Performance, Reliability,
Efficiency
Application Development Control & Integration
machine learning h3-Open-VER h3-Open-DATA: Data
h3-Open-UTIL
Utilities for Large-Scale
Verification of Accuracy Data Science
ü Integration of (S+D+L) Computing
AI for HPC
h3-Open-AT h3-Open-DDA: Learning
Automatic Tuning Data Driven Approach17
Acceleration of Transient CFD Simulations using ML/CNN
Integration of (S+D+L), AI for HPC
h3-Open-APPL h3-Open-DATA h3-Open-UTIL
Flow around a
Circular Cylinder h3-Open-DDA/hDDA
Simulation by LBM
Expensive
Super-
Detailed Simplified Simplified
Various types of simplified models are generated by ML, and they are
utilized for generating training data sets, and for simulations in
hierarchical manner -> Prediction of Unsteady Problems
Datasets Model Order Uncertainty
Data Assimilation
(Adjoint, Sparse
AMR
Feature
Reduction (MOR) Quantification (UQ) Modeling etc.) Detection
Visualization Observation Numerical
Information Results Results
Training Simulations:
Ground LBM
truth (LBM simulation)
u v
Prediction of the Results
after 10+ Time Steps …
Prediction of Time
Evolution CNN Predictions
Prediction (DNN)
u v
CNN to predict simulation results
Prediction NN may become “faster simulator”
[c/o Takashi Shimokawabe (ITC/U.Tokyo)]18
Err = | CNN – LBM |
CNN Prediction LBM Ground Truth
u u
v v
・Calculation time (1GPU) … LBM (124000steps) → 70.6 s、 CNN Prediction → 0.6 s
[c/o Takashi Shimokawabe
⇒ Significant reduction in calculation time (ITC/U.Tokyo)]: Infrastructure for leveraging data
• A real-time data processing platform Currently jointly being designed by:
• Geographically distributed IaaS including wide-area network • 9 National Universities (Tokyo,
Hokkaido, Tohoku, Tsukuba,
Disaster protection Medicine
Tokyo Tech, Nagoya, Kyoto,
Osaka, Kyushu)
Shared infrastructure
Network / Storage / Computers
• NII (National Institute of
Informatics)
SINET
5
• AIST (National Institute of
SINET Advanced Industrial Science
mobile Data
and Technology)
クラウド基盤 ストレージ ⼤学IT基盤
Agriculture / Fishing Smart Cities
⾼性能 リアルタイム ⾼可⽤
Energy / Power Grid
19Overview of infrastructure • Facility • Network – < 2.0 MW including Cooling,
Prototype for mdx: Medical image recognition by UTokyo hospital
• Hyper-parameter auto-tuning platform Lung mass detection in
on Reedbush chest radiographs
compute nodes
(GPU cluster) evaluation
automated hyper-parameter
criteria
tuning software
training and
parameter 1 evaluation
!!
Bayesian training and
!"
optimization parameter 2 evaluation
parameter N training and
evaluation
!#
Changes in partial AUC valuesAUC)の最大値
学習ジョブ数と評価値(partial of validation
1 4 8 10 15 data, where each value is the maximum
との関係
上:元画像、下:検出結果
Upper: original image,
value in past evaluations
(黄、緑丸:病変領域)
Lower: detection result
parallel 2 6 9 12 13 16 (Green circle and yellow
workers
filled region: lesion area)
3 5 7 11 14
time →
Asynchronous parallel BO Nomura Y, J Supercomput. 20 Jan 2020 (Epub ahead)
2122
Summary
• Reedbush: Pioneer of “Simulation+Data Analysis+Machine Learning (S+D+L)” platform
– P100 GPU, Burst buffer, L2VPN
– Retire soon (Nov. 2021)
• Wisteria/BDEC-01: Platform for Integration of “S+D+L”, support “AI for HPC”
– Odyssey: Simulation node: A64FX (mini Fugaku)
– Aquarius: Data+Learning: ICX+A100, direct access to external resources
– Shared storage, Fast storage
– Typical application: Simulations with Data Assimilation
• mdx: Infrastructure for leveraging data
– CPU node: ICX, GPU node: ICX+A100, Internal storage, Fast storage, Shared object storage
– Separation external network and internal/storage network, Cloud-like operation: VMware vSphere
– A real-time data processing virtual platform
• Provide PoC environment on demand
• It enables a geographically distributed IaaS, directly connectable to edge devices.
• Leveraging the SINET mobile infrastructure
– Cooperate supercomputers such as ABCI or Wisteria/BDEC-01You can also read

















































