TRECVID 2019 Ad-hoc Video Search Task : Overview - Retrieval Group
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

TRECVID 2019
Ad-hoc Video Search Task : Overview
Georges Quénot
Laboratoire d'Informatique de Grenoble
George Awad
Georgetown University;
National Institute of Standards and Technology
Disclaimer
The identification of any commercial product or trade name does not imply endorsement or
recommendation by the National Institute of Standards and Technology.
Outline • Task Definition • Video Data • Topics (Queries) • Participating teams • Evaluation & results • General observation 2 TRECVID 2019

Task Definition
• Goal: promote progress in content-based retrieval based on end user ad-
hoc (generic) textual queries that include searching for persons, objects,
locations, actions and their combinations.
• Task: Given a test collection, a query, and a master shot boundary
reference, return a ranked list of at most 1000 shots (out of 1,082,657)
which best satisfy the need.
• Testing data: 7475 Vimeo Creative Commons Videos (V3C1), 1000 total
hours with mean video durations of 8 min. Reflects a wide variety of
content, style and source device.
• Development data: ≈2000 hours of previous IACC.1-3 data used between
2010-2018 with concept and ad-hoc query annotations.
3 TRECVID 2019
Query Development
• Test videos were viewed by 10 human assessors hired by the National
Institute of Standards and Technology (NIST).
• 4 facet descriptions of different scenes were used (if applicable):
– Who : concrete objects and beings (kind of persons, animals, things)
– What : are the objects and/or beings doing ? (generic actions, conditions/state)
– Where : locale, site, place, geographic, architectural
– When : time of day, season
• In total assessors watched random selection of ≈1% (12000 videos) of
the V3C1 segmented shots.
• All random shots were selected to cover all original 7475 videos.
• 90 candidate queries chosen from human written descriptions to be
used between 2019 to 2021 including 20 progress topics (10 shared with
the Video Browser Showdown (VBS)).
4 TRECVID 2019
TV2019 Queries by complexity • Person + Action + Object + Location (most complex) Find shots of a woman riding or holding a bike outdoors Find shots of a person smoking a cigarette outdoors Find shots of a woman wearing a red dress outside in the daytime • Person + Action + Location Find shots of a man and a woman dancing together indoors Find shots of a person running in the woods Find shots of a group of people walking on the beach • Person + Action/state + Object Find shots of a person wearing a backpack Find shots of a race car driver racing a car Find shots of a person holding a tool and cutting something 5 TRECVID 2019

TV2019 Queries by complexity • Person + Object + Location Find shots of a person wearing shorts outdoors Find shots of a person in front of a curtain indoors • Person + Object Find shots of a person with a painted face or mask Find shots of person in front of a graffiti painted on a wall Find shots of a person in a tent • Object + Location Find shots of one or more picnic tables outdoors Find shots of coral reef underwater Find shots of one or more art pieces on a wall 6 TRECVID 2019

TV2019 Queries by complexity • Object + Action Find shots of a drone flying Find shots of a truck being driven in the daytime Find shots of a door being opened by someone Find shots of a small airplane flying from the inside • Person + Action Find shots of a man and a woman holding hands Find shots of a black man singing Find shots of a man and a woman hugging each other • Person/being + Location Find shots of a shirtless man standing up or walking outdoors Find shots of one or more birds in a tree 7 TRECVID 2019

TV2019 Queries by complexity • Object Find shots of a red hat or cap • Person Find shots of a woman and a little boy both visible during daytime Find shots of a bald man Find shots of a man and a baby both visible 8 TRECVID 2019
Training and run types
• Three run submission types:
ü Fully automatic (F): System uses official query directly(37 runs)
ü Manually-assisted (M): Query built manually (10 runs)
ü Relevance Feedback (R): Allow judging top-5 once (0 runs)
• Four training data types:
ü A – used only IACC training data (7 runs)
ü D – used any other training data (33 runs)
ü E – used only training data collected automatically using
only the query text (7 run)
ü F – used only training data collected automatically using a
query built manually from the given query text (0 runs)
• New novelty run was introduced to encourage retrieving non-common
relevant shots easily found across runs.
9 TRECVID 2019Main Task Finishers : 10 out of 19
Runs
Team Organization
M F R N
Carnegie Mellon University(USA); Monash University
INF (Australia) Renmin University (China) Shandong University - 4 -
(China)
Department of Informatics, Kindai University; Graduate
Kindai_kobe - 4 - 1
School of System Informatics, Kobe University
EURECOM EURECOM - 3 -
IMFD_IMPRESEE Millennium Institute Foundational Research on Data
- 4 -
(IMFD) Chile; Impresee Inc ORAND S.A. Chile
ATL Alibaba group; ZheJiang University - 4 -
WasedaMeiseiSoft Waseda University; Meisei University; SoftBank
4 1 -
bank Corporation
VIREO City University of Hong Kong 2 4 - 1
FIU_UM Florida International University; University of Miami - 6 - 1
Renmin University of China; Zhejiang Gongshang
RUCMM - 4 -
University
SIRET Charles University 4 - -
M: Manually-assisted, F: Fully automatic, R: Relevance feedback, N: Novelty run
10 TRECVID 2019Progress Task Submitters : 9 out of 10
Runs
Team Organization
M F R N
Carnegie Mellon University(USA); Monash University
INF (Australia) Renmin University (China) Shandong University - 4 -
(China)
Department of Informatics, Kindai University; Graduate
Kindai_kobe - 4 - -
School of System Informatics, Kobe University
EURECOM EURECOM - 3 -
ATL Alibaba group; ZheJiang University - 4 -
WasedaMeiseiSoft Waseda University; Meisei University; SoftBank
4 1 -
bank Corporation
VIREO City University of Hong Kong 2 4 - -
FIU_UM Florida International University; University of Miami - 4 - -
Renmin University of China; Zhejiang Gongshang
RUCMM - 4 -
University
SIRET Charles University 4 - -
M: Manually-assisted, F: Fully automatic, R: Relevance feedback, N: Novelty run
11 TRECVID 2019Evaluation Each query assumed to be binary: absent or present for each master reference shot. NIST judged top ranked pooled results from all submissions 100% and sampled the rest of pooled results. Metrics: Extended inferred average precision per query. Compared runs in terms of mean extended inferred average precision across the 30 queries. 12 TRECVID 2019
Mean Extended Inferred Average Precision (XInfAP)
2 pools were created for each query and sampled as:
ü Top pool (ranks 1 to 250) sampled at 100 %
ü Bottom pool (ranks 251 to 1000) sampled at 11.1 %
ü % of sampled and judged clips from rank 251 to 1000 across all runs
and topics (min= 10.8 %, max = 86.4 %, mean = 47.6 %)
30 queries
181649 total judgments
23549 total hits
10910 hits at ranks (1 to100) # Hits >> IACC
8428 hits at ranks (101 to 250) data (2016-2018)
4211 hits at ranks (251 to 1000)
Judgment process: one assessor per query, watched complete
shot while listening to the audio. infAP was calculated using the
judged and unjudged pool by sample_eval tool
13 TRECVID 2019Inferred frequency of hits varies by query
Inf. Hits / query 0.5% of test shots
5,000.00
truck being driven person in front of shirtless
4,000.00 in the daytime a curtain indoors man
standing up
woman person holding a tool and
3,000.00 cutting something or walking
Inf. hits
wearing a outdoors
red dress
2,000.00
outside in
the daytime
1,000.00
0.00
611 613 615 617 619 621 623 625 627 629 631 633 635 637 639
Queries
14 TRECVID 2019Total unique relevant shots contributed by team
across all runs
Number of true unique shots
1200
Top scoring teams
1000 not necessary
800 contributing a lot of
600 unique true shots
400
200
0
be
UM
EE
f
EO
L
k
ET
M
M
In
an
AT
CO
CM
R
ES
ko
R
tb
U_
SI
VI
PR
i_
RE
RU
of
FI
da
M
EU
iS
kin
_I
se
FD
ei
aM
IM
ed
as
W
15 TRECVID 2019Novelty Metric
• Goal
Novelty runs are supposed to retrieve more unique relevant shots as opposed
to more common relevant shots easily found by most runs.
• Metric
1- A weight is given to each topic and shot pairs in the ground truth such that
highest weight is given to unique shots:
TopicX_ShotY_weight = 1 - (N/M)
Where N : Number of times Shot Y was retrieved for topic X by any run submission.
M : Number of total runs submitted by all teams
E.g. A unique relevant shot weight = 0.978 (given 47 runs in 2019), a shot submitted by all runs = 0.
2- For Run R and for all topics, we calculate the summation S of all *unique*
shot weights ONLY.
Final novelty score = S/30 (the mean across all evaluated 30 topics)
16 TRECVID 2019F_
M
_N Novelty metric score
F_ F_ _E_
17
M M FI
_N _N U _
10
15
20
25
30
35
0
5
F_ F_ _D_ _D_ UM
M M k V .1
F_ _C _C ind IRE 9_
M _D _A a i O 7
_C _ _ _k .1
_D F_ IMF EUR o be 9_5
_W M D_ EC .1
as _C_ I MP OM 9 _5
ed A_ R .1
aM EU ES 9_
F_
M ei RE EE.1 2
se C
_C O 9
_D F_ iSo f M _3
_I M _ tba .19
M C n _1
FD _D k.
_ _ 19
Novelty runs
M F_ F_ I MP ATL _1
Common runs
_M M M R .1
_C _C _C ES 9_
_D _A _D EE 3
_ _ .1
F_ _W F_ EUR ATL 9_2
M as M EC .1
_C ed _ O 9_
_D aM C_ M 1
_I ei D_ .19
M M s A _
_M F_ FD_ eiSo TL.1 3
M I M ft 9_
_C _C P ba 4
_D _D RE nk
_W
F _ S .1
as _M RUC EE.1 9 …
ed _ M 9_
C
F_ aM _D M. 1 4
M eis _A 9_
Runs
_C ei TL 2
TRECVID 2019
M _D_ So ft .19_
F_ _M R ba 2
U
M n
_C M_ _C_ C M k.1
Novelty scores
_D M A_ M 9 …
_I _C SIR . 19
M _ E _
F_ FD_ A_S T.1 3
M I M IR 9_
M _C P E T 1
_M M _D_ RES .19
_C _M R EE _3
_D _ UC .1
_W M_ C_ MM 9_
as M_ A_S . 1 1
ed C_ IR 9_
E
F_ aM A_S T.1 4
e
M is IR 9_
_C ei ET 4
_D So .1
_ ft 9_
F_ RU ban 2
M C M k.
_ 1
F_ C_ M. 9 …
M D 1
_C _In 9_1
_D f.1
_I 9_
nf 4
.1
9_
1Mean Inf. AP
18
0
0.02
0.04
0.06
0.08
0.12
0.14
0.16
0.18
0.1
C_D_ATL.19_2
C_D_ATL.19_1
C_D_RUCMM.19_1
C_D_ATL.19_4
C_D_RUCMM.19_2
C_D_RUCMM.19_4
C_D_RUCMM.19_3
C_D_WasedaMeiseiSoftbank.…
C_D_Inf.19_3
C_D_Inf.19_2
C_D_Inf.19_4
C_D_Inf.19_1
C_D_ATL.19_3
C_D_kindai_kobe.19_2
C_D_kindai_kobe.19_1
C_E_FIU_UM.19_4
N_D_kindai_kobe.19_5
C_E_FIU_UM.19_1
C_D_kindai_kobe.19_3
Runs
TRECVID 2019
C_E_FIU_UM.19_3
C_E_FIU_UM.19_6
N_D_VIREO.19_5
C_D_VIREO.19_2
C_E_FIU_UM.19_2
N_E_FIU_UM.19_7
Sorted overall scores
C_E_FIU_UM.19_5
C_D_VIREO.19_4
C_D_VIREO.19_3
C_D_kindai_kobe.19_4
C_D_IMFD_IMPRESEE.19_2
C_D_IMFD_IMPRESEE.19_1
(37 Fully automatic runs, 9 teams)
C_D_IMFD_IMPRESEE.19_3
C_D_IMFD_IMPRESEE.19_4
Median = 0.08
C_D_VIREO.19_1
C_A_EURECOM.19_3
C_A_EURECOM.19_2
C_A_EURECOM.19_1C_
D_
W Mean Inf. AP
19
as
ed
C_ aM
D_ ei
W se
i
0
0.02
0.04
0.06
0.08
0.12
0.14
0.16
0.1
as So
ed ft b
C_ aM
D_ an
W ei k.
se 1…
as iSo
ed ft b
aM an
ei k.
se 1…
iSo
C_ ft b
D_ C_ an
W D_ k.
1…
as VI
ed RE
aM O.
ei 19
se _2
iSo
ft b
C_ an
D_ k.
VI 1…
RE
TRECVID 2019
O.
19
Runs
C_
A_ _1
Sorted scores
SIR
ET
C_ .1
9_
A_ 3
SIR
ET
C_ .1
9_
A_ 2
SIR
ET
C_ .1
9_
A_ 1
SIR
(10 Manually-assisted runs, 3 teams)
ET
.1
Median = 0.09
9_
4Top 10 runs by query (Fully Automatic)
0.7
person in front of a person wearing a 1
0.6 graffiti painted on a wall backpack 2
inside views of a
3
0.5 small airplane flying 4
5
0.4 Person holding tool
Inf. AP
and cutting something 6
0.3 7
8
0.2
9
0.1 10
Median
0
611
613
615
617
619
621
623
625
627
629
631
633
635
637
639
Topics
20 TRECVID 2019Top 10 runs by query (Manually-Assisted)
0.7
1
0.6
2
0.5 3
4
0.4
5
Inf. AP
0.3 6
7
0.2 8
9
0.1
10
0 Median
611
613
615
617
619
621
623
625
627
629
631
633
635
637
639
Topics
21 TRECVID 2019Unique vs Common relevant shots
2100
2000
1900 13% of all hits are
1800 unique
1700
1600
1500
1400
1300
1200
1100
1000
900
800
700
600
500
400
300
200
100
0
1611
1612
1613
1614
1615
1616
1617
1618
1619
1620
1621
1622
1623
1624
1625
1626
1627
1628
1629
1630
1631
1632
1633
1634
1635
1636
1637
1638
1639
1640
Unique Overlapped
22 TRECVID 2019Performance in the last 4 years ?
IACC.3 Dataset V3C1 Dataset
Automatic 2016 2017 2018 2019
Teams 9 8 10 9
Runs 30 33 33 37
Min xInfAP 0 0.026 0.003 0.014
Max xInfAP 0.054 0.206 0.121 0.163
Median xInfAP 0.024 0.092 0.058 0.08
Manually-Assisted 2016 2017 2018 2019
Teams 8 5 6 3
Runs 22 19 16 10
Min xInfAP 0.005 0.048 0.012 0.033
Max xInfAP 0.169 0.207 0.106 0.152
Median xInfAP 0.043 0.111 0.072 0.09
23 TRECVID 2019Easy vs difficult topics overall (2019)
Top 10 Easy Top 10 Hard
sorted by count of runs with InfAP >= 0.3 sorted by count of runs with InfAP < 0.3
person in front of a graffiti painted on a wall one or more picnic tables outdoors
coral reef underwater inside views of a small airplane flying
person in front of a curtain indoors person holding a tool and cutting something
person wearing shorts outdoors door being opened by someone
Hardness
Easiness
person wearing a backpack woman wearing a red dress outside in the
daytime
bald man a black man singing
person with a painted face or mask truck being driven in the daytime
shirtless man standing up or walking outdoors man and a woman holding hands
man and a baby both visible man and a woman hugging each other
drone flying woman riding or holding a bike outdoors
24 TRECVID 2019Statistical significant differences among top 10 “F” runs
(using randomization test, p < 0.05)
Run Mean Inf. AP score C_D_RUCMM.19_2 #* : no significant
difference among
C_D_ATL.19_2 0.163 # Ø C_D_RUCMM.19_3
each set of runs
C_D_ATL.19_1 0.161 # Ø C_D_RUCMM.19_4
C_D_RUCMM.19_1 0.160 # Ø C_D_Inf.19_2 Ø Runs higher
C_D_ATL.19_4 0.157 # Ø C_D_Inf.19_3 in the
hierarchy are
C_D_RUCMM.19_2 0.152 # C_D_RUCMM.19_1 significantly
C_D_RUCMM.19_4 0.127 * Ø C_D_RUCMM.19_3 better than
C_D_RUCMM.19_3 0.124 * Ø C_D_RUCMM.19_4 runs more
indented.
C_D_WasedaMeiseiSoftbank.19_1 0.123 * Ø C_D_Inf.19_2
C_D_Inf.19_3 0.118 * Ø C_D_Inf.19_3
C_D_Inf.19_2 0.118 *
C_D_ATL.19_1 C_D_ATL.19_2 C_D_ATL.19_4
Ø C_D_RUCMM.19_3 Ø C_D_RUCMM.19_3 Ø C_D_RUCMM.19_3
Ø C_D_RUCMM.19_4 Ø C_D_RUCMM.19_4 Ø C_D_RUCMM.19_4
Ø C_D_Inf.19_2 Ø C_D_Inf.19_2 Ø C_D_Inf.19_2
Ø C_D_Inf.19_3 Ø C_D_Inf.19_3
25 TRECVID 2019Statistical significant differences among top 10 “M”
runs (using randomization test, p < 0.05)
C_D_WasedaMeiseiSoftbank.19_2
Run Mean Inf. AP score
Ø C_D_WasedaMeiseiSoftbank.19_3
C_D_WasedaMeiseiSoftbank.19_2 0.152 Ø C_D_WasedaMeiseiSoftbank.19_4
C_D_WasedaMeiseiSoftbank.19_3 0.136 # Ø C_A_SIRET.19_3
C_D_WasedaMeiseiSoftbank.19_1 0.133 # Ø C_A_SIRET.19_2
Ø C_D_VIREO.19_1
C_D_VIREO.19_2 0.118 # Ø C_A_SIRET.19_1
C_D_WasedaMeiseiSoftbank.19_4 0.114 Ø C_A_SIRET.19_4
C_D_VIREO.19_1 0.066 * Ø C_D_WasedaMeiseiSoftbank.19_1
Ø C_D_WasedaMeiseiSoftbank.19_4
C_A_SIRET.19_3 0.035 *
Ø C_A_SIRET.19_3
C_A_SIRET.19_2 0.035 * Ø C_A_SIRET.19_2
C_A_SIRET.19_1 0.034 ! Ø C_D_VIREO.19_1
C_A_SIRET.19_4 0.033 ! Ø C_A_SIRET.19_1
Ø C_A_SIRET.19_4
Ø C_D_VIREO.19_2
Ø C_A_SIRET.19_3
!#* : no significant difference Ø C_A_SIRET.19_2
among each set of runs Ø C_D_VIREO.19_1
Ø C_A_SIRET.19_1
Ø Runs higher in the hierarchy are Ø C_A_SIRET.19_4
significantly better than runs more
indented.
26 TRECVID 2019Processing time vs Inf. AP (“F” runs)
Across all topics and runs
100000
10000
1000
Time (s)
Few topics
with fast
100 response
and high
score
10
1
0 0.2 0.4 0.6
Inf. AP
27 TRECVID 2019Processing time vs Inf. AP (“M” runs)
Across all topics and runs
10000 Consuming longer
time processing
queries didn’t help
1000 many teams/topics
Time (s)
100
10
1
0 0.1 0.2 0.3 0.4 0.5
Inf. AP
28 TRECVID 2019Samples of (tricky/failed) results
Truck driven in the daytime Drone flying Person in a tent
Person wearing shorts Man and a woman holding hands Black man singing
outdoors
Birds in a tree Red hat or a cap
29 TRECVID 20192019 Main approaches • Two main competing approaches: “concept banks” and “(visual-textual) embedding spaces” • Currently: significant advantage for “embedding space” approaches, especially for fully automatic search and even overall • Training data for semantic spaces: MSR and TRECVid VTT tasks, TGIF, IACC.3, Flickr8k, Flickr30k, MS COCO], and Conceptual Captions 30 TRECVID 2019
2019 Main approaches
• Alibaba Group (presentation to follow):
– Fully automatic (0.163): mapping video embedding and language
embedding into a learned semantic space with graph sequence and
aggregated modeling, and gated CNNs
• Renmin University of China and Zhejiang Gongshang
University (presentation to follow):
– Fully automatic (0.160): Word to Visual Word (W2VV++) similar to
TRECVid 2018 plus “dual encoding network” and BERT as text encoder
• Waseda University; Meisei University; SoftBank Corporation
(presentation to follow):
– Manually assisted (0.152): concept-based retrieval similar to previous
years’ concept bank approach
– Fully automatic (0.123): visual-semantic embedding (VSE++)
31 TRECVID 20192019 Main approaches
• Shandong Normal University; Carnegie Mellon University;
Monash University:
– Fully automatic (0.118): submitted fully automatic runs but notebook
paper currently only about their INS task participation.
• City University of Hong Kong (VIRE0) and Eurecom:
– Manually assisted runs (0.118): concept based approach with manual
query parsing and manual concept filtering
– Fully automatic (0.075): concept based approach
• Kindai University and Kobe University:
– Fully automatic (0.087): embedding that maps visual and textual
information into a common space
• Florida International University; University of Miami
(presentation to follow)
– Fully automatic (0.082): weighted concept fusion and W2VV
32 TRECVID 20192019 Task observations
• New dataset : Vimeo Creative Commons Collection (V3C1) is being used for testing
• Development of 90 queries to be used between 2019-2021 including progress subtask.
• Run training types are dominated by “D” runs. No relevance feedback submissions
received.
• New “novelty” run type (and metric). Novelty runs proved to submit unique true shots
compared to common run types.
• Stable team participation and task completion rate. Manually-assisted runs decreasing.
• High participation in the progress subtask
• Absolute number of hits are higher than previous years.
• We can’t compare performance with IACC.3 (2016-2018) : New dataset + New queries
• Fully automatic and Manually-assisted performance are almost similar.
• Among high scoring topics, there is more room for improvement among systems.
• Among low scoring topics, most systems scores are collapsed in small narrow range.
• Dynamic topics (actions, interactions, multi-facets ..etc) are the hardest topics.
• Most systems are slow. Few topics scored high in fast time.
• Task is still challenging!
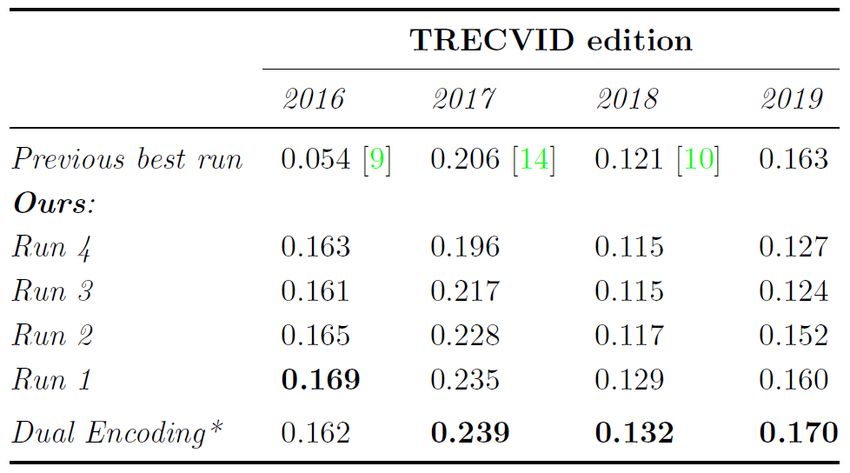
33 TRECVID 2019RUCMM 2019 system on previous years 34 TRECVID 2019
Interactive Video Retrieval subtask will be held
as part of the Video Browser Showdown (VBS)
At MMM 2020
26th International Conference on Multimedia Modeling,
January 5-8, 2020 Daejeon, Korea
• 10 Ad-Hoc Video Search (AVS) topics : Each AVS topic has several/many target
shots that should be found.
• 10 Known-Item Search (KIS) tasks, which are selected completely random on
site. Each KIS task has only one single 20 s long target segment.
• Registration for the task is now closed
35 TRECVID 20199:10 – 12:20 : Ad-hoc Video Search 9:10 – 9:40 am Ad-hoc Video Search Task Overview 9:40 – 10:10 am Learn to Represent Queries and Videos for Ad-hoc Video Search, RUCMM Team - Renmin University of China; Zhejiang Gongshang University 10:10 – 10:40 am Zero-shot Video Retrieval for Ad-hoc Video Search Task WasedaMeiseiSoftbank Team – Waseda University; Meisei University; SoftBank Corporation 10:40 – 11:00 am Break with refreshments 11:00 – 11:30 am Query-Based Concept Tree for Score Fusion in Ad-hoc Video Search Task, FIU_UM Team – Florida Intl. University; University of Miami 11:30 – 12:00 pm Hybrid Sequence Encoder for Text Based Video Retrieval ATL Team – Alibaba Group 12:00 – 12:20 pm AVS Task discussion 36 TRECVID 2019
2019 Questions and 2020 plans
• Was the task/queries realistic enough?!
• How teams feel the difference between IACC data vs V3C ?
• Do we need to change/add/remove anything to the task in 2020 ?
• Is there any specific reason for the low submissions in “E” & “F” training type
runs? (training data collected automatically from the given query text)
• Do we need the relevance feedback run type? 0 submissions this year.
• Did any team run their 2019 system on IACC.3 (2016-2018) topics ? (Yes)
• Any feedback about the new novelty metric (runs)?
• Engineering versus research efforts?
• Shared “consolidated” concept banks?
• How to encourage teams to share resources/concept models,… etc.
• Current plan is to continue the task V3C1 for main and progress subtask.
• Please continue participating in the “progress subtask” to measure accurate
performance difference
• What about an explainability subtask (related to embedding approaches)?
37 TRECVID 2019AVS Progress subtask
Evaluation year
2019 2020 2021
Submit 50 queries (30
2019 new + 20 common)
Eval 30 new Queries
Submit 40 queries (20
new + 20 common)
2020
Eval 30 (20 new + 10
Submission common)
year Submit 40 queries (20
new + 20 common)
2021
Eval 30 (20 New + 10
common)
Goals : Evaluate 10 (set A) common queries submitted in 2 years (2019, 2020)
Evaluate 10 (set B) common queries submitted in 3 years (2019, 2020, 2021)
Evaluate 20 common queries submitted in 3 years (2019 , 2020, 2021)
Ground truth for 20 common queries can be released only in 2021
38 TRECVID 2019You can also read

















































