Mava: a research framework for distributed multi-agent reinforcement learning
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Mava: a research framework for distributed multi-agent
reinforcement learning
Arnu Pretorius1,∗ , Kale-ab Tessera1,∗ , Andries P. Smit2,†,∗ , Claude Formanek3,† , St John Grimbly3,† ,
Kevin Eloff2,† , Siphelele Danisa3,† , Lawrence Francis1 , Jonathan Shock3 , Herman Kamper2 , Willie
Brink2 , Herman Engelbrecht2 , Alexandre Laterre1 , Karim Beguir1
1 InstaDeep
2 Stellenbosch University
arXiv:2107.01460v1 [cs.LG] 3 Jul 2021
3 University of Cape Town
† Work done during a research internship at InstaDeep
∗ Equal contribution
Abstract
Breakthrough advances in reinforcement learning (RL) research have led to a surge in the
development and application of RL. To support the field and its rapid growth, several
frameworks have emerged that aim to help the community more easily build effective and
scalable agents. However, very few of these frameworks exclusively support multi-agent
RL (MARL), an increasingly active field in itself, concerned with decentralised decision
making problems. In this work, we attempt to fill this gap by presenting Mava: a research
framework specifically designed for building scalable MARL systems. Mava provides useful
components, abstractions, utilities and tools for MARL and allows for simple scaling for
multi-process system training and execution, while providing a high level of flexibility
and composability. Mava is built on top of DeepMind’s Acme (Hoffman et al., 2020),
and therefore integrates with, and greatly benefits from, a wide range of already existing
single-agent RL components made available in Acme. Several MARL baseline systems have
already been implemented in Mava. These implementations serve as examples showcasing
Mava’s reusable features, such as interchangeable system architectures, communication and
mixing modules. Furthermore, these implementations allow existing MARL algorithms to be
easily reproduced and extended. We provide experimental results for these implementations
on a wide range of multi-agent environments and highlight the benefits of distributed system
training. Mava’s source code is available here: https://github.com/instadeepai/Mava.
1. Introduction
Reinforcement learning (RL) has proven to be a useful computational framework for building
effective decision making systems (Sutton and Barto, 2018). This has been shown to be
true, not only in simulated environments and games (Mnih et al., 2015; Silver et al., 2017;
Berner et al., 2019; Vinyals et al., 2019), but also in real-world applications (Mao et al.,
2016; Gregurić et al., 2020). Advances in deep learning (Goodfellow et al., 2016) combined
with modern frameworks for distributed environment interaction and data generation (Liang
et al., 2018; Hoffman et al., 2020) have allowed RL to to deliver research breakthroughs that
were previously out of reach. However, as the complexity of a given problem increases, it
might become impossible to solve by only increasing representational capacity and agent
training data. This is the case when a problem poses an exponential expansion of the problem
representation as it scales, for example, in distributed decision making problems such as fleet
©2021 InstaDeep Ltd.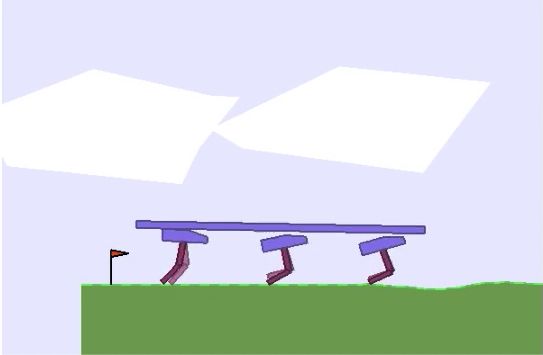
management (Lin et al., 2018) where the action space grows exponentially with the size of
the fleet.
Multi-agent reinforcement learning (MARL) extends the decision-making capabilities of
single-agent RL to include distributed decision making problems. In MARL, multiple agents
are trained to act as individual decision makers of some larger system, typically with the
goal of achieving a scalable and effective decentralised execution strategy when deployed
(Shoham and Leyton-Brown, 2008). MARL systems can be complex and time consuming
to build, while at the same time, be difficult to design in a modular way. This modularity
helps to be able to quickly iterate and test new research ideas. Furthermore, despite the
added complexity of MARL, it is crucial that these systems maintain the advantages of
distributed training. Often the core system implementation and the distributed version of
these systems pose two completely different challenges, which makes scaling single process
prototypes towards deployable multi-process solutions a nontrivial undertaking.
In this work, we present Mava, a research framework for distributed multi-agent rein-
forcement learning. Mava aims to provide a library for building MARL systems in a modular,
reuseable and flexible manner using components and system architectures specifically de-
signed for the multi-agent setting. A key criterion for Mava is to provide enough flexibility
for conducting research. At its core, Mava leverages the single-agent distributed RL research
framework Acme (Hoffman et al., 2020) and closely follows Acme’s design principles. This
means Mava immediately benefits from a large repository of single-agent RL components and
abstractions, such as commonly used networks, loss functions, utilities and other tools that
will keep growing alongside Mava as Acme is further developed. Furthermore, we inherit the
same RL ecosystem built around Acme. Most notably, Mava interfaces with Reverb (Cassirer
et al., 2021) for data flow management and supports simple scaling using Launchpad (Yang
et al., 2021). As a consequence, Mava is able to run systems at various level of scale without
changing a single line of the system code. Finally, Mava integrates with popular environment
suites for MARL, including PettingZoo (Terry et al., 2020), multi-agent Starcraft (SMAC)
(Samvelyan et al., 2019), Flatland (Mohanty et al., 2020) and OpenSpiel (Lanctot et al.,
2019).
2. Related work
To support the rapid growth in research and development in RL, several frameworks have
been created to assist the community in building, as well as scaling, modern deep RL agents.
As is the case with Mava, most frameworks aim to adhere to a set of criteria that center
around flexibility, reusability, reproducibility and ease of experimentation.
Single-Agent RL. Among the earliest software libraries for single-agent deep RL are
RLlab (Duan et al., 2016), baselines (Dhariwal et al., 2017) and Spinning up (Achiam, 2018).
Other similar libraries include Dopamine (Castro et al., 2018), TF agents (Guadarrama et al.,
2018), Surreal (Fan et al., 2018), SEED RL (Espeholt et al., 2019) and RLax (Budden et al.,
2020). These libraries all aim to provide either useful abstractions for building agents, or
specific well-tested agent implementations, or both. RLLib (Liang et al., 2018) and Arena
(Song et al., 2020) are libraries that support both single and multi-agent RL and is built
on top of Ray (Moritz et al., 2017) for distributed training. Finally, Acme (Hoffman et al.,
2020), a recently released research framework, provides several agent implementations as
2
well as abstractions and tools for building novel agents. Acme is built around an ecosystem
of RL related libraries including Reverb (Cassirer et al., 2021) for controlling data flow
between actors, learners and replay tables and Launchpad (Yang et al., 2021) for distributed
computation.
Multi-Agent RL (MARL). Software libraries for MARL are fewer in number compared
to single-agent RL. As mentioned above, RLlib and Arena (which directly leverages RLlib)
both support MARL. RLlib is able to provide options such as parameter sharing between
independent agents for some of its single-agent implementations, as well as shared critic
networks for actor-critic algorithms. But it has not been specifically designed for MARL:
RLlib provides only a few MARL specific algorithm implementations such as MADDPG
(Lowe et al., 2017) and QMIX (Rashid et al., 2018). PyMARL (Samvelyan et al., 2019), is
a MARL library centered around research on value decomposition methods, such as VDN
(Sunehag et al., 2017) and QMIX. Recent work on networked MARL (Chu et al., 2020),
provide several open-source implementations of MARL algorithms, in particular those capable
of using communication across a network, such as DIAL (Foerster et al., 2016) and CommNet
(Sukhbaatar et al., 2016) as well as the author’s own proposal, NeurComm. OpenSpiel
(Lanctot et al., 2019) is a collection of environments and algorithm implementations that
focus on research in games. Most of the algorithms in OpenSpiel are inspired by research
in game theory as well as RL, and algorithms are provided that are suitable for either
single-agent or multi-agent RL.
To the best of our knowledge, Mava is the first software library that is solely dedicated
to providing a comprehensive research framework for large-scale distributed multi-agent
reinforcement learning. The abstractions, tools and components in Mava serve a single
purpose: to make building scalable MARL systems easier, faster and more accessible to the
wider community.
In the remainder of the paper, we will discuss the design philosophy behind Mava, showcase
some existing system implementations and demonstrate the effectiveness of distributed
training. However, for the sake of making the paper self-contained, in the following we first
provide some background on the topic of RL and MARL before moving on to discuss the
framework itself.
3. Background
Reinforcement learning is concerned with optimal sequential decision making within an
environment. In single agent RL, the problem is often modeled as a Markov decision process
(MDP) defined by the following tuple (S, A, r, p, ρ0 , γ) (Andreae, 1969; Watkins, 1989). At
time step t, in a state st ∈ S, the agent selects an action at from a set of actions A.
The environment state transition function p(st+1 |st , at ) provides a distribution over next
states st+1 , and a reward function r(st , at , st+1 ) returns a scalar reward, given the current
state, action and next state. The initial state distribution is given by ρ0 , with s0 ∼ ρ0 ,
and γ ∈ (0, 1] is a discount factor controlling the influence of future rewards. The goal
of RL is to find an optimal policy π ∗ , where the policy is a mapping from states to a
distribution over actions,
P∞ that maximises long-term discounted future reward such that
∗
π = argmaxπ Eτ ∼π [ t=0 γ r(s , at , st+1 )]. If the environment state is partially observed
t t
by the agent, an observation function o(st ) is assumed and the agent has access only to
3
the observation ot = o(st ) at each time step, with the full observation space defined as
O = {o(s)|s ∈ S}.
Deep RL. Popular algorithms for solving classic (tabular) RL problems include value-
based methods such as Q-learning (Watkins and Dayan, 1992) and policy gradient methods
such as the REINFORCE algorithm (Williams, 1992). Q-learning learns a value function
Q(s, a) for state-action pairs and obtains a policy by selecting actions according to these
learned values using a specific action selector, e.g. -greedy (Watkins, 1989) or UCB (Auer
et al., 2002). In contrast, policy gradient methods learn a parameterised policy πθ , with
parameters θ, directly by following a performance gradient signal with respect to θ. The
above approaches are combined in actor-critic methods (Sutton et al., 2000), where the actor
refers to the policy being learned and the critic to a value function. In deep RL, the policy
and value functions are parameterised using deep neural networks as high-capacity function
approximators. These networks are capable of learning abstract representations from raw
input signals capable of generalising across states, making it possible to scale RL beyond
the tabular setting. Recent state-of-the-art deep RL methods include Deep Q-Networks
(DQN) (Mnih et al., 2013) and related variants (Hessel et al., 2017), as well as advanced
actor-critic methods such as DDPG (Lillicrap et al., 2015), PPO (Schulman et al., 2017) and
SAC (Haarnoja et al., 2018). For a more in-depth review of deep RL, we recommend the
following resources (Arulkumaran et al., 2017; Li, 2017).
Distributed RL. Distributed algorithms such as A3C (Mnih et al., 2016), Impala
(Espeholt et al., 2018), R2D2 (Kapturowski et al., 2018) and D4PG (Barth-Maron et al.,
2018) are examples of algorithms specifically designed to train value-based and actor-critic
methods at scale. Different paradigms exist for distributing the training of RL agents. For
example, one way to distribute training is to batch the observations of distributed actors
and use a centralised inference server (Espeholt et al., 2019). A different approach is to
launch a large number of workers that are responsible for both data collection and gradient
updates (the worker here is both the actor and the learner) and to periodically synchronize
their gradients across different processes (Berner et al., 2019). In Acme (Hoffman et al.,
2020), distributed RL is achieved by distributing the actor processes that interact with the
environment. The generated data is collected by a central or distributed store such as a
replay table, where learner processes are able to periodically sample from the table and
update the parameters of the actor networks using some form of gradient based learning.
Finally, actors periodically synchronize their parameters with the latest version of the trainer
and the process continues. In general, distributed training often leads to significant speed-ups
in the time to convergence compared to standard single process RL.
Deep MARL. In multi-agent RL, we can model the problem as a partially ob-
servable Markov game (Littman, 1994) between N agents, defined as the tuple given
above for the single-agent case, but Q with observation and action QN spaces given by the
N
following cartesian products: O = O
i=1 i ⊆ S and A = i=1 Ai , for agents i =
1, ..., N . In a typical cooperative setting, the goal is to find an optimal joint policy
π ∗ (a1 , ..., aN |o1 , ..., oN ) that P
maximises
P∞ at shared long-term discounted future reward for
all agents as π ∗ = argmaxπ E[ N i=1 t=0 γ r(o t , at , ot+1 )]. However, the framework can easily
i i i
be extended beyond pure cooperation to more complicated settings. Figure 1 shows the
canonical environment-system interaction loop in MARL where multiple agents each take
4
an action in the environment and subsequently receive a new observation and reward from
taking that particular action.
Early work in MARL investigated the effectiveness of simply training multiple inde-
pendent Q-learning agents (Tan, 1993). This work has since been extended to include
deep neural networks, or more specifically independent DQNs (Tampuu et al., 2017).
However, from the perspective of an individ-
ual agent, these approaches treat all other
learning agents as part of the environment,
resulting in the optimal policy distribution to Agent
become non-stationary. Furthermore, if the
Environment
environment is only partially observable, the observations
and rewards Agent actions
learning task can become even more difficult,
where agents may struggle with credit assign- Environment
ment due to spurious rewards received from
unobserved actions of other agents (Claus
and Boutilier, 1998). To mitigate the issue Figure 1: Multi-agent reinforcement learning
of non-stationarity, MARL systems are often system-environment interaction loop.
designed within the paradigm of centralised
training with decentralised execution (CTDE) (Lowe et al., 2017; Foerster et al., 2017a). In
CTDE, a centralised information processing unit (most often a critic network in actor-critic
methods) is conditioned on the global state, or joint observations, and all of the actions of
the agents during training. This makes the learning problem stationary. The central unit is
then later removed once the individual agents’ policies have been learned, making it possible
to use each policy independently during system execution.
Research in MARL has grown in popularity over the past few years in tandem with single-
agent deep RL and has seen several key innovations such as novel centralised training, learned
communication, replay stabilisation, as well as value and policy function decomposition
strategies, all developed only fairly recently (Foerster et al., 2016, 2017b; Lowe et al., 2017;
Foerster et al., 2017a; Rashid et al., 2018; Das et al., 2019; de Witt et al., 2020; Wang et al.,
2020a). For an overview of MARL, past and present, we recommend the following surveys
(Powers et al., 2003; Busoniu et al., 2008; Hernandez-Leal et al., 2019a,b; OroojlooyJadid
and Hajinezhad, 2019; Nguyen et al., 2019; Zhang et al., 2019; Yang and Wang, 2020). We
discuss distributed training of MARL systems in the next section where we give an overview
of Mava.
4. Mava
In this section, we provide a detailed overview of Mava: its design, components, abstractions
and implementations. We will discuss the Executor-Trainer paradigm and how Mava
systems interact with the environment, inspired by the canonical Actor-Learner paradigm
in distributed single-agent RL. We proceed by giving an overview of distributed system
training. We will mention some of the the available components and architectures in Mava for
building systems and provide a brief description of the currently supported baseline system
implementations. Furthermore, we will demonstrate Mava’s functionality, for example, how
5
System
Trainer Trainer
Learner Dataset Learner Dataset
Executor Executor
Actor Actor
Policy Observe Policy Observe
Environment
Distributed Executors
Environment
Figure 2: Multi-agent reinforcement learning systems and the executor-trainer paradigm.
Left: Executor-Trainer system design. Right: Distributed systems.
to change the system architecture in only a few lines of code. Finally, we will show how
Launchpad is used to launch a distributed MARL system in Mava.
Systems and the Executor-Trainer paradigm. At the core of Mava is the concept
of a system. A system refers to a full MARL algorithm specification consisting of the following
components: an executor, a trainer and a dataset. The executor is a collection of single-agent
actors and is the part of the system that interacts with the environment, i.e. performs an
action for each agent and observes the reward and next observation for each agent. The
dataset stores all of the information generated by the executor in the form of a collection
of dictionaries with keys corresponding to the individual agent ids. All data transfer and
storage is handled by Reverb, which provides highly efficient experience replay as well as
data management support for other data structures such as first-in-first-out (FIFO), last-
in-first-out (LIFO) and priority queues. The trainer is a collection of single-agent learners,
responsible for sampling data from the dataset and updating the parameters for every agent
in the system. The left panel in Figure 2 gives a visual illustration of the building blocks
of a system. Essentially, executors are the multi-agent version of the actor class (that use
policy networks to act and generate training data) and trainers are the multi-agent version
of the typical learner class (responsible for updating policy parameters for the actors).
The executor-environment interaction loop. Environments in Mava adhere to
the DeepMind environment API (Muldal et al., 2019) and support multi-agent versions of
the API’s TimeStep and specs classes in addition to the core environment interface. The
timestep represents a container for environment transitions, which in Mava holds a set of
dictionaries of observations and rewards indexed by agent ids, along with a discount factor
shared among agents and the environment step type (first, middle or last). Each environment
6Decentralised Centralised Networked
System System System
Centralised unit
Agent 2 Agent 4 Agent 2 Agent 4
Agent 2 Agent 4
Agent 1 Agent 3 Agent N Agent 1 Agent 3 Agent N Agent 1 Agent 3 Agent N
Environment Environment Environment
Figure 3: Multi-agent reinforcement learning system architectures. Left: Decentralised.
Middle: Centralised. Right: Networked.
also has a multi-agent spec specifying environment details such as the environment’s action
and observation spaces (which could potentially be different for each agent in the system).
Block 1 shows a code example of how an ex-
ecutor interacts with an environment. The Block 1: The executor-environment
loop closely follows the canonical single-agent interaction loop in Mava
environment loop. When an executor calls
while True :
observe and related functions, an internal # make initial observation for each agent
adder class interfaces with a reverb replay ta- step = environment . reset ()
executor . observe_first ( step )
ble and adds the transition data to the table. while not step . last () :
Mava already supports environment wrap- # take agent actions and step the environment
obs = step . observation
pers for well-known MARL environments, actions = executor . select_actions ( obs )
step = environment . step ( actions )
including PettingZoo (Terry et al., 2020), # make an observation for each agent
(a library similar to OpenAI’s Gym (Brock- executor . observe ( actions , next_timestep = step )
man et al., 2016) but for multi-agent en- # update the executor policy networks
executor . update ()
vironments), multi-agent Starcraft (SMAC)
(Samvelyan et al., 2019), Flatland (Mohanty
et al., 2020) and OpenSpiel (Lanctot et al., 2019).
Distributed systems. As mentioned before, Mava shares much of its design philosophy
with Acme for the following reasons: to provide a high level of composability suitable for
novel research (i.e. building new systems) as well as making it possible to easily run systems
distributed at various levels of scale, using the same underlying MARL system code. For
example, the system executor may be distributed across multiple processes, each with a
copy of the environment. Each process collects and stores data which the trainer uses to
update the parameters of the actor networks used within each executor. This basic design is
illustrated in the right panel of Figure 2. The distribution of processes is defined through
constructing a multi-node graph program using Launchpad. In Mava, we use Launchpad’s
CourierNode to connect executor and trainer processes. Furthermore, we use the specifically
designed ReverbNode to expose reverb table function calls to the rest of the system. For
each node in the graph, we can specify the local resources (CPU and GPU usage) that will
be made available to that node by passing a dictionary of node keys with their corresponding
environment variables as values.
Components. Mava aims to provide several useful components for building MARL
systems. These include custom MARL specific networks, loss functions, communication and
7mixing modules (for value and policy factorisation methods). Perhaps the most fundamental
component is the system architecture. The architecture of a system defines the information
flow between agents in the system. For example, in the case of centralised training with
decentralised execution using a centralised critic, the architecture would define how observa-
tion and action information is shared in the critic during centralised training and restrict
information being shared between individual agent policies for decentralised execution. In
other cases, such as inter-agent communication, the architecture might define a networked
structure specifying how messages are being shared between agents. An illustration of popular
architectures for MARL is given in Figure 3. Decentralised architectures create systems
with fully independent agents, whereas centralised architectures allow for information to
be shared with some centralised unit, such as a critic network. Networked architectures
define an information topology where only certain agents are allowed to share information,
for example with their direct neighbours.
System implementations. Mava has a set of already implemented baseline systems
for MARL. These systems serve as easy-to-use and out-of-the-box approaches for MARL, but
perhaps more importantly, also as building blocks and examples for designing custom systems.
We provide the following overview of implemented systems as well as related approaches that
could potentially be implemented in future versions of Mava using its built-in components.
spaMulti-Agent Deep Q-Networks (MADQN): Tampuu et al. (2017) studied inde-
pendent multi-agent DQN, whereas Foerster et al. (2017c), proposed further stabilisation
techniques such as policy fingerprints to deal with non-stationarity. In Mava, we provide
implementations of MADQN using either feed-forward or recurrent actors in the executor
and allow for the addition of replay stabilisation using policy fingerprints. Our systems are
also interchangeable with respect to the different variants of DQN that are available in Acme.
spaLearned Communication (DIAL): A common component of MARL systems is agent
communication. Mava supports general purpose components specifically for implementing
systems with communication. In terms of baseline systems, Mava has an implementation of
differentiable inter-agent learning (DIAL) (Foerster et al., 2016). However, other communi-
cation protocols such as RIAL (Foerster et al., 2016), CommNet (Sukhbaatar et al., 2016),
TarMAC (Das et al., 2019), and NeurComm (Chu et al., 2020), should be accessible given
the general purpose communication modules provided inside Mava.
spaValue Decomposition (VDN/QMIX): Value function decomposition in MARL has
become a very active area of research, starting with VDN (Sunehag et al., 2017) and QMIX
(Rashid et al., 2018), and subsequently spawning several extensions and related ideas such
as MAVEN (Mahajan et al., 2019), Weighted QMIX (Rashid et al., 2020), QTRAN (Son
et al., 2019), QTRAN++ (Son et al., 2020), QPLEX (Wang et al., 2020b), AI-QMIX (Iqbal
et al., 2020) and UneVEn (Gupta et al., 2020). Mava has implementations of both VDN and
QMIX and provides general purpose modules for value function decomposition, as well as
associated hypernetworks.
spaMulti-Agent Deep Deterministic Policy Gradient (MADDPG/MAD4PG):
The deterministic policy gradient (DPG) method (Silver et al., 2014) has in recent years been
extended to deep RL, in DDPG (Lillicrap et al., 2015) as well as to the multi-agent setting
using a centralised critic, in MADDPG (Lowe et al., 2017). More recently, distributional
RL (Bellemare et al., 2017) approaches have been incorporated into a scaled version of the
8Block 2: Launching a distributed Mava system: MADQN
1 # Mava imports
2 from mava . systems . tf import madqn
3 from mava . components . tf . architectures import D e c e n t r a l i s e d P o l i c y A c t o r
4 from mava . systems . tf . system . helpers import environment_factory , network_factory
5
6 # Launchpad imports
7 import launchpad Program graph
8
9 # Distributed program Replay
Trainer
10 program = madqn . MADQN ( (GPU) table
11 e n v i r o n m en t _ f a c t o r y = environment_factory ,
12 network_factory = network_factory ,
13 architecture = DecentralisedPolicyActor , Executor 0
14 num_executors =2 , (CPU) Courier Node
15 ) . build ()
Reverb Node
16
17 # Launch
18 launchpad . launch ( Executor 1
(CPU)
19 program ,
20 launchpad . LaunchType . LOCAL_MULTI_PROCESSING ,
21 )
algorithm, in D4PG (Barth-Maron et al., 2018). In Mava, we provide an implementation of
the original MADDPG, as well as a multi-agent version of D4PG.
5. Examples
To illustrate the flexibility of Mava in terms of system design and scaling, we step through
several examples of different systems and use cases. We will begin by providing a system
template using MADQN which we will keep updating as we go through the different examples.
The code for the template is presented in Block 2, where the distributed system program
is built, starting on line 10. The first two arguments to the program are environment and
network factory functions. These helper functions are responsible for creating the networks
for the system, initialising their parameters on the different compute nodes and providing
a copy of the environment for each executor. The next argument num_executors sets the
number of executor processes to be run. The inset on the right shows the program graph
consisting of two executor courier nodes, a trainer courier node and the replay table node.
After building the program we feed it to Launchpad’s launch function and specify the
launch type to perform local multi-processing, i.e. running the distributed program on a
single machine. Scaling up or down is simply a matter of adjusting the number of executor
processes.
Modules. Our first use case is communication. We will add a communication module
to MADQN to have agent’s be able to learn how to communicate across a differentiable
communication channel. However, before adding the communication module, we first show
how to change our MADQN system to support recurrent execution. As long as the network
factory specifies a recurrent model for the Q-Networks used in MADQN, the system can be
made recurrent by changing the executor and trainer functions. This code change is shown
in the top part of Block 3. Next, we add communication. To do this, we adapt the system
code by wrapping the architecture fed to the system with a communication module, in this
case broadcasted communication. This code change is shown in the bottom part of Block 3,
where we can set whether the communication channel is shared between agents, the size of
9Block 3: Code changes for communication Switch game
1.0
Evaluator episode Return
# Recurrent MADQN 0.5
program = madqn . MADQN ( 0.0
...
executor_fn = madqn . MADQNRecurrentExecutor , 0.5
trainer_fn = madqn . MADQNRecurrentTrainer , 1.0
Random system
... Foerster et al. (2016)
) . build () 1.5 Recurrent-MADQN
Comms-MADQN (channel_size=1)
2.0 Comms-MADQN (channel_size=2)
0 25 50 75 100 125 150 175
Episodes
--------------------------------------------------------
SMAC (3m)
25
Foerster et al. (2017)
# Inside MADQN system code VDN
from mava . components . tf . modules import communication 20 FF-MADQN
Evaluator episode Return
15
# Wrap architecture in communication module
communication . B r o a d c a s t e d C o m m u n i c a t i o n ( 10
architecture = architecture ,
shared = True , 5
channel_size =1 ,
0
channel_noise =0 ,
) 5
0 500 1000 1500 2000 2500 3000 3500
Episodes
Figure 4: MADQN system code and experiments. Top Left: Code changes to MADQN. Top
Right: Experiments on switch game and Starcraft 2, showing the benefits of communication.
Action: On None
Agent in Agent 1
interrogation room: 3 2
“Green”
On On
Switch: Off Speaker
Off
Day 1 Day 2
None Guess
Agent 2
3 1
Agent 3
On On
Off
Listener
Off
Day 3 Day 4
Figure 5: Environments: From left to right, top to bottom: switch game, speaker-listener,
spread, 3v3 marine level on Starcraft and Multi-Walker.
the channel and the amount of noise injected into the channel (which can sometimes help
with generalisation).
– Switch game. Using this new MADQN system with communication, we run experiments
on the switch riddle game introduced by Foerster et al. (2016) to specifically test a system’s
communication capabilities. In this simple game, agent’s are sent randomly to an interrogation
room one by one and are witness to a switch either being on or off. Once in the room,
each agent has the option to guess whether it thinks all agents have already visited the
interrogation room or not. The switches are modelled as messages sent between the agents
and the actions are either the final guess that all agents have been in the room or a no-op
action. The guess is final, since once any agent makes a first guess the game ends and
all agents receive either a reward of 1, if the guess is correct, or a reward of -1, if it is
incorrect. Even though the game is relatively simple, the size of the space of possible policies
O(N )
is significant, calculated by Foerster et al. (2016) to be 43N , where N is the number of
agents in the game. Our results for the switch game are shown in the top plot in Figure 4,
demonstrating the benefit of the added communication module. Most Mava modules work
by wrapping the system architecture. For example, we could also add a replay memory
stabilisation module to our MADQN system using the fingerprint technique proposed by
10Foerster et al. (2017c). This module may help deal with non-stationarity in the replay
distribution. To add the module, we can import the stabilisation module and wrap the
system architecture as follows: stabilising.FingerPrintStabalisation(architecture).
– StarCraft Multi-Agent Challenge (SMAC). In our next example use case, we test on the
SMAC environment (Samvelyan et al., 2019). This environment offers a set of decentralised
unit micromanagement levels where a MARL system is able to control a number of starcraft
units and is pitted against the game heuristic AI in a battle scenario. Value decomposition
networks (VDN) and related methods such as QMIX have been demonstrated to work well
on Starcraft. These methods all center around the concept of building a Q-value mixing
network to learn a decomposed joint value function for all the agents in the system. In
VDN the "network" is only a sum of Q-values, but in more complex cases such QMIX
and derivative systems, the mixing is done using a neural network where the weights are
being determined by a type of hypernetwork. In Mava, we can add mixing as a module,
typically to a MADQN based system, by importing the module and wrapping the architecture:
e.g. mixing.AdditiveMixing(architecture). The bottom plot in Figure 4 shows episode
returns for our implementation of a VDN system on the 3v3 marine level compared to
standard independent MADQN using feedforward networks. Unfortunately, we have been
unable to reach similar performance on SMAC using our implementation of QMIX compared
to the results presented in the original paper (Rashid et al., 2018).
Architectures. To demonstrate the use of different system architectures we switch to
using an actor-critic system, suitable for both discrete and continuous control. Specifically,
we use MAD4PG as an example, where the running changes to our program will now be
associated with the code shown in Block 4. Here, we import the mad4pg system and pass
the system architecture type, in this case a decentralised (independent agents) Q-value
actor-critic architecture, along with its trainer function. As a test run, we show in Figure 6
the performance of decentralised MAD4PG compared to MADDPG using weight sharing on
the simple agent navigation levels spread and speaker-listener (Lowe et al., 2017). Here, both
systems are able to obtain a mean episode return similar to previously reported performances
(Lowe et al., 2017).
– Multi-Walker. The multi-agent bipedal environment, Multi-Walker (Gupta et al., 2017),
presents a more difficult continuous control task, where agents are required to balance a beam
while learning to walk forward in unison. As mentioned before, a popular training paradigm
for actor-critic MARL systems is to share information between agents using a centralised critic.
To change the architecture of our system we can import a different supported architecture
type and specify the corresponding trainer. For example, to convert our MAD4PG system
to use a centralised critic, we replace the architecture with a CentralisedQValueCritic
architecture and set the trainer to a MAD4PGCentralisedTrainer. We compare centralised
versus decentralised training on Multi-Walker in Figure 6. Even though decentralised
MAD4PG is able to solve the environment, centralised training does not seem to help,
however, we note this is consistent with the findings of Gupta et al. (2017). In a similar way
to changing to a centralised architecture, we can have the system be a networked system.
Given a network specification detailing the connections between agents, we can replace the
architecture of the system with a networked architecture using the NetworkedQValueCritic
class.
11Spread Speaker-listener
Random system
24 MADDPG 10
Block 4: MAD4PG 26
MAD4PG
Evaluator episode Return
Evaluator episode Return
15
28 20
30
# MAD4PG system 25
32
program = mad4pg . MAD4PG ( 34
30
... 36
35 Random system
DecentralisedQValueCritic Lowe et al. (2017)
38 40 MADDPG
MAD4PG
MADDPGFeedForwardExecutor , 45
0 500 1000 1500 2000 2500 3000 0 500 1000 1500 2000 2500 3000
MAD4PGDecentralisedTrainer , Episodes Episodes
num_executors =2 ,
... Multi-Walker Multi-Walker Scaling
75 Random system 70
) . build () Gupta et al. (2017)
60
MADDPG-D
Evaluator episode Return
50
MAD4PG-D
Evaluator episode Return
50
MADDPG-C
25 MAD4PG-C 40
0 30
25 20
50 10
0 MAD4PG (num_executor=1)
75 MAD4PG (num_executor=2)
10 MAD4PG (num_executor=4)
100
0:00 5 :00 0:00 5 :00 0 :00 5:0
0
0:0
0
0 1000 2000 3000 4000 5000 6000 0:0 2:0 4:1 6:1 8:2 10:2 12:3
Episodes Walltime (hours:minutes:seconds)
Figure 6: MAD4PG system code and experiments. Left: Code for MAD4PG. Evaluation
run of MAD4PG "solving" the Multi-Walker environment. Right: Experiments on MPE
and Multi-Walker environments using different architectures and number of executors.
Distribution. In our our final experiment, we demonstrate the effects of distributed
training on the time to convergence. The bottom right plot in Figure 6 shows the results
of distributed training for MAD4PG on Multi-Walker. Specifically, we compare evaluation
performance against training time for different numbers of executors. We see a marked
difference in early training as we increase num_executors beyond one, but less of a difference
between having two compared to four executors.
6. Conclusion
In this work, we presented Mava, a research framework for distributed multi-agent reinforce-
ment learning. We highlighted some of the useful abstractions and tools in Mava for building
scalable MARL systems through a set of examples and use cases. We believe this work is a
step in the right direction, but as with any framework, Mava is an ongoing work in progress
and will remain in active development as the MARL community grows to support the myriad
of its innovations and use cases.
12References
M. Hoffman, B. Shahriari, J. Aslanides, G. Barth-Maron, F. Behbahani, T. Norman,
A. Abdolmaleki, A. Cassirer, F. Yang, K. Baumli, S. Henderson, A. Novikov, S. G.
Colmenarejo, S. Cabi, C. Gulcehre, T. L. Paine, A. Cowie, Z. Wang, B. Piot, and
N. de Freitas, “Acme: A research framework for distributed reinforcement learning,” arXiv
preprint arXiv:2006.00979, 2020. [Online]. Available: https://arxiv.org/abs/2006.00979
R. S. Sutton and A. G. Barto, Introduction to reinforcement learning. Second edition. MIT
press Cambridge, 2018.
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves,
M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep
reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015.
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert,
L. Baker, M. Lai, A. Bolton et al., “Mastering the game of go without human knowledge,”
nature, vol. 550, no. 7676, pp. 354–359, 2017.
C. Berner, G. Brockman, B. Chan, V. Cheung, P. Dębiak, C. Dennison, D. Farhi, Q. Fischer,
S. Hashme, C. Hesse et al., “Dota 2 with large scale deep reinforcement learning,” arXiv
preprint arXiv:1912.06680, 2019.
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi,
R. Powell, T. Ewalds, P. Georgiev, J. Oh, D. Horgan, M. Kroiss, I. Danihelka, A. Huang,
L. Sifre, T. Cai, J. P. Agapiou, M. Jaderberg, A. S. Vezhnevets, R. Leblond, T. Pohlen,
V. Dalibard, D. Budden, Y. Sulsky, J. Molloy, T. L. Paine, C. Gulcehre, Z. Wang, T. Pfaff,
Y. Wu, R. Ring, D. Yogatama, D. Wünsch, K. McKinney, O. Smith, T. Schaul, T. Lillicrap,
K. Kavukcuoglu, D. Hassabis, C. Apps, and D. Silver, “Grandmaster level in StarCraft II
using multi-agent reinforcement learning,” Nature, vol. 575, no. 7782, pp. 350–354, 2019.
H. Mao, M. Alizadeh, I. Menache, and S. Kandula, “Resource management with deep
reinforcement learning,” in Proceedings of the 15th ACM workshop on hot topics in
networks, 2016, pp. 50–56.
M. Gregurić, M. Vujić, C. Alexopoulos, and M. Miletić, “Application of deep reinforcement
learning in traffic signal control: An overview and impact of open traffic data,” Applied
Sciences, vol. 10, no. 11, p. 4011, 2020.
I. Goodfellow, Y. Bengio, A. Courville, and Y. Bengio, Deep learning. MIT press Cambridge,
2016, vol. 1.
E. Liang, R. Liaw, R. Nishihara, P. Moritz, R. Fox, K. Goldberg, J. E. Gonzalez, M. I.
Jordan, and I. Stoica, “RLlib: Abstractions for distributed reinforcement learning,” in
International Conference on Machine Learning (ICML), 2018.
K. Lin, R. Zhao, Z. Xu, and J. Zhou, “Efficient large-scale fleet management via multi-agent
deep reinforcement learning,” in Proceedings of the 24th ACM SIGKDD International
Conference on Knowledge Discovery & Data Mining, 2018, pp. 1774–1783.
13Y. Shoham and K. Leyton-Brown, Multiagent systems: Algorithmic, game-theoretic, and
logical foundations. Cambridge University Press, 2008.
A. Cassirer, G. Barth-Maron, E. Brevdo, S. Ramos, T. Boyd, T. Sottiaux, and M. Kroiss,
“Reverb: A framework for experience replay,” arXiv preprint arXiv:2102.04736, 2021.
[Online]. Available: https://arxiv.org/abs/2102.04736
F. Yang et al., “Launchpad,” https://github.com/deepmind/launchpad, 2021.
J. K. Terry, B. Black, M. Jayakumar, A. Hari, L. Santos, C. Dieffendahl, N. L. Williams,
Y. Lokesh, R. Sullivan, C. Horsch, and P. Ravi, “Pettingzoo: Gym for multi-agent rein-
forcement learning,” arXiv preprint arXiv:2009.14471, 2020.
M. Samvelyan, T. Rashid, C. S. de Witt, G. Farquhar, N. Nardelli, T. G. J. Rudner, C.-M.
Hung, P. H. S. Torr, J. Foerster, and S. Whiteson, “The StarCraft Multi-Agent Challenge,”
CoRR, vol. abs/1902.04043, 2019.
S. Mohanty, E. Nygren, F. Laurent, M. Schneider, C. Scheller, N. Bhattacharya, J. Watson,
A. Egli, C. Eichenberger, C. Baumberger, G. Vienken, I. Sturm, G. Sartoretti, and
G. Spigler, “Flatland-rl : Multi-agent reinforcement learning on trains,” 2020.
M. Lanctot, E. Lockhart, J.-B. Lespiau, V. Zambaldi, S. Upadhyay, J. Pérolat, S. Srinivasan,
F. Timbers, K. Tuyls, S. Omidshafiei, D. Hennes, D. Morrill, P. Muller, T. Ewalds,
R. Faulkner, J. Kramár, B. D. Vylder, B. Saeta, J. Bradbury, D. Ding, S. Borgeaud,
M. Lai, J. Schrittwieser, T. Anthony, E. Hughes, I. Danihelka, and J. Ryan-Davis,
“OpenSpiel: A framework for reinforcement learning in games,” CoRR, vol. abs/1908.09453,
2019. [Online]. Available: http://arxiv.org/abs/1908.09453
Y. Duan, X. Chen, R. Houthooft, J. Schulman, and P. Abbeel, “Benchmarking deep reinforce-
ment learning for continuous control,” in International conference on machine learning.
PMLR, 2016, pp. 1329–1338.
P. Dhariwal, C. Hesse, O. Klimov, A. Nichol, M. Plappert, A. Radford, J. Schulman, S. Sidor,
Y. Wu, and P. Zhokhov, “Openai baselines,” https://github.com/openai/baselines, 2017.
J. Achiam, “Spinning Up in Deep Reinforcement Learning,” 2018.
P. S. Castro, S. Moitra, C. Gelada, S. Kumar, and M. G. Bellemare, “Dopamine:
A Research Framework for Deep Reinforcement Learning,” 2018. [Online]. Available:
http://arxiv.org/abs/1812.06110
S. Guadarrama, A. Korattikara, O. Ramirez, P. Castro, E. Holly, S. Fishman, K. Wang,
E. Gonina, N. Wu, E. Kokiopoulou, L. Sbaiz, J. Smith, G. Bartók, J. Berent, C. Harris,
V. Vanhoucke, and E. Brevdo, “TF-Agents: A library for reinforcement learning in
tensorflow,” https://github.com/tensorflow/agents, 2018, [Online; accessed 25-June-2019].
[Online]. Available: https://github.com/tensorflow/agents
L. Fan, Y. Zhu, J. Zhu, Z. Liu, O. Zeng, A. Gupta, J. Creus-Costa, S. Savarese, and L. Fei-
Fei, “Surreal: Open-source reinforcement learning framework and robot manipulation
benchmark,” in Conference on Robot Learning, 2018.
14L. Espeholt, R. Marinier, P. Stanczyk, K. Wang, and M. Michalski, “Seed rl: Scalable and
efficient deep-rl with accelerated central inference,” 2019.
D. Budden, M. Hessel, J. Quan, S. Kapturowski, K. Baumli, S. Bhupatiraju, A. Guy,
and M. King, “RLax: Reinforcement Learning in JAX,” 2020. [Online]. Available:
http://github.com/deepmind/rlax
Y. Song, A. Wojcicki, T. Lukasiewicz, J. Wang, A. Aryan, Z. Xu, M. Xu, Z. Ding, and L. Wu,
“Arena: A general evaluation platform and building toolkit for multi-agent intelligence.” in
AAAI, 2020, pp. 7253–7260.
P. Moritz, R. Nishihara, S. Wang, A. Tumanov, R. Liaw, E. Liang, W. Paul, M. I. Jordan,
and I. Stoica, “Ray: A distributed framework for emerging AI applications,” CoRR, vol.
abs/1712.05889, 2017. [Online]. Available: http://arxiv.org/abs/1712.05889
R. Lowe, Y. I. Wu, A. Tamar, J. Harb, O. P. Abbeel, and I. Mordatch, “Multi-agent actor-
critic for mixed cooperative-competitive environments,” in Advances in neural information
processing systems, 2017, pp. 6379–6390.
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Qmix:
Monotonic value function factorisation for deep multi-agent reinforcement learning,” arXiv
preprint arXiv:1803.11485, 2018.
P. Sunehag, G. Lever, A. Gruslys, W. M. Czarnecki, V. Zambaldi, M. Jaderberg, M. Lanctot,
N. Sonnerat, J. Z. Leibo, K. Tuyls et al., “Value-decomposition networks for cooperative
multi-agent learning,” arXiv preprint arXiv:1706.05296, 2017.
T. Chu, S. Chinchali, and S. Katti, “Multi-agent reinforcement learning for networked system
control,” International Conference on Learning Representations, 2020.
J. Foerster, I. A. Assael, N. De Freitas, and S. Whiteson, “Learning to communicate with
deep multi-agent reinforcement learning,” in Advances in neural information processing
systems, 2016, pp. 2137–2145.
S. Sukhbaatar, R. Fergus et al., “Learning multiagent communication with backpropagation,”
in Advances in neural information processing systems, 2016, pp. 2244–2252.
J. Andreae, “Learning machines: A unified view,” Encyclopaedia of Linguistics, Information
and Control, Pergamon Press, pp. 261–270, 01 1969.
C. J. C. H. Watkins, “Learning from delayed rewards,” 1989.
C. J. Watkins and P. Dayan, “Q-learning,” Machine learning, vol. 8, no. 3-4, pp. 279–292,
1992.
R. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement
learning.” Machine Learning, pp. 229–256, 1992.
P. Auer, N. Cesa-Bianchi, and P. Fischer, “Finite-time analysis of the multiarmed bandit
problem,” Machine learning, vol. 47, no. 2-3, pp. 235–256, 2002.
15R. S. Sutton, D. A. McAllester, S. P. Singh, and Y. Mansour, “Policy gradient methods for
reinforcement learning with function approximation,” in Advances in neural information
processing systems, 2000, pp. 1057–1063.
V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller,
“Playing atari with deep reinforcement learning,” arXiv preprint arXiv:1312.5602, 2013.
M. Hessel, J. Modayil, H. Van Hasselt, T. Schaul, G. Ostrovski, W. Dabney, D. Horgan,
B. Piot, M. Azar, and D. Silver, “Rainbow: Combining improvements in deep reinforcement
learning,” arXiv preprint arXiv:1710.02298, 2017.
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra,
“Continuous control with deep reinforcement learning,” arXiv preprint arXiv:1509.02971,
2015.
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimiza-
tion algorithms,” arXiv preprint arXiv:1707.06347, 2017.
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum en-
tropy deep reinforcement learning with a stochastic actor,” arXiv preprint arXiv:1801.01290,
2018.
K. Arulkumaran, M. P. Deisenroth, M. Brundage, and A. A. Bharath, “A brief survey of
deep reinforcement learning,” arXiv preprint arXiv:1708.05866, 2017.
Y. Li, “Deep reinforcement learning: An overview,” arXiv preprint arXiv:1701.07274, 2017.
V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and
K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” in International
conference on machine learning, 2016, pp. 1928–1937.
L. Espeholt, H. Soyer, R. Munos, K. Simonyan, V. Mnih, T. Ward, Y. Doron, V. Firoiu,
T. Harley, I. Dunning et al., “Impala: Scalable distributed deep-rl with importance weighted
actor-learner architectures,” in International Conference on Machine Learning. PMLR,
2018, pp. 1407–1416.
S. Kapturowski, G. Ostrovski, J. Quan, R. Munos, and W. Dabney, “Recurrent experience
replay in distributed reinforcement learning,” in International conference on learning
representations, 2018.
G. Barth-Maron, M. W. Hoffman, D. Budden, W. Dabney, D. Horgan, D. Tb, A. Muldal,
N. Heess, and T. Lillicrap, “Distributed distributional deterministic policy gradients,”
arXiv preprint arXiv:1804.08617, 2018.
M. L. Littman, “Markov games as a framework for multi-agent reinforcement learning,” in
Machine learning proceedings 1994. Elsevier, 1994, pp. 157–163.
M. Tan, “Multi-agent reinforcement learning: Independent vs. cooperative agents,” in Pro-
ceedings of the tenth international conference on machine learning, 1993, pp. 330–337.
16A. Tampuu, T. Matiisen, D. Kodelja, I. Kuzovkin, K. Korjus, J. Aru, J. Aru, and R. Vicente,
“Multiagent cooperation and competition with deep reinforcement learning,” PloS one,
vol. 12, no. 4, p. e0172395, 2017.
C. Claus and C. Boutilier, “The dynamics of reinforcement learning in cooperative multiagent
systems,” AAAI/IAAI, vol. 1998, no. 746-752, p. 2, 1998.
J. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson, “Counterfactual multi-
agent policy gradients,” arXiv preprint arXiv:1705.08926, 2017.
J. Foerster, N. Nardelli, G. Farquhar, T. Afouras, P. H. S. Torr, P. Kohli, and S. Whiteson,
“Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning,” ICML,
2017.
A. Das, T. Gervet, J. Romoff, D. Batra, D. Parikh, M. Rabbat, and J. Pineau, “TarMAC:
Targeted multi-agent communication,” 36th International Conference on Machine Learning,
ICML 2019, vol. 2019-June, pp. 2776–2784, 2019.
C. S. de Witt, B. Peng, P.-A. Kamienny, P. Torr, W. Böhmer, and S. Whiteson, “Deep
Multi-Agent Reinforcement Learning for Decentralized Continuous Cooperative Control,”
arXiv, p. 14, 2020. [Online]. Available: http://arxiv.org/abs/2003.06709
Y. Wang, B. Han, T. Wang, H. Dong, and C. Zhang, “Off-policy multi-agent decomposed
policy gradients,” arXiv preprint arXiv:2007.12322, 2020.
R. Powers, Y. Shoham, and T. Grenager, “Multi-Agent Reinforcement Learning : a critical
survey,” pp. 1–13, 2003.
L. Busoniu, R. Babuska, and B. D. Schutter, “A comprehensive survey of multi-agent
reinforcement learning,” Tech Report, p. 18, 2008.
P. Hernandez-Leal, B. Kartal, and M. E. Taylor, “A survey and critique of multiagent deep
reinforcement learning,” Autonomous Agents and Multi-Agent Systems, vol. 33, no. 6, pp.
750–797, 2019.
P. Hernandez-Leal, M. Kaisers, T. Baarslag, and E. M. de Cote, “A Survey of Learning in
Multiagent Environments: Dealing with Non-Stationarity,” arXiv, pp. 1–64, 2019. [Online].
Available: http://arxiv.org/abs/1707.09183
A. OroojlooyJadid and D. Hajinezhad, “A review of cooperative multi-agent deep reinforce-
ment learning,” arXiv preprint arXiv:1908.03963, 2019.
T. T. Nguyen, N. D. Nguyen, and S. Nahavandi, “Deep Reinforcement Learning for
Multi-Agent Systems: A Review of Challenges, Solutions and Applications,” arXiv, pp.
1–27, 2019. [Online]. Available: http://arxiv.org/abs/1812.11794
K. Zhang, Z. Yang, and T. Başar, “Multi-agent reinforcement learning: A selective overview
of theories and algorithms,” arXiv preprint arXiv:1911.10635, 2019.
17Y. Yang and J. Wang, “An Overview of Multi-Agent Reinforcement Learning
from Game Theoretical Perspective,” pp. 1–122, 2020. [Online]. Available: http:
//arxiv.org/abs/2011.00583
A. Muldal, Y. Doron, J. Aslanides, T. Harley, T. Ward, and S. Liu, “dm_env: A
python interface for reinforcement learning environments,” 2019. [Online]. Available:
http://github.com/deepmind/dm_env
G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba,
“Openai gym,” 2016.
J. Foerster, N. Nardelli, G. Farquhar, T. Afouras, P. H. Torr, P. Kohli, and S. Whiteson,
“Stabilising experience replay for deep multi-agent reinforcement learning,” in Proceedings
of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017,
pp. 1146–1155.
A. Mahajan, T. Rashid, M. Samvelyan, and S. Whiteson, “Maven: Multi-agent variational
exploration,” arXiv preprint arXiv:1910.07483, 2019.
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson,
“Monotonic value function factorisation for deep multi-agent reinforcement learning,”
Journal of Machine Learning Research, vol. 21, no. 178, pp. 1–51, 2020.
K. Son, D. Kim, W. J. Kang, D. E. Hostallero, and Y. Yi, “Qtran: Learning to factorize
with transformation for cooperative multi-agent reinforcement learning,” arXiv preprint
arXiv:1905.05408, 2019.
K. Son, S. Ahn, R. Delos, S. Jinwoo, and Y. Yung, “Qtran++: Improved value transformation
for cooperative multi-agent reinforcement learning,” arXiv preprint arXiv:2006.12010, 2020.
J. Wang, Z. Ren, T. Liu, Y. Yu, and C. Zhang, “Qplex: Duplex dueling multi-agent q-learning,”
arXiv preprint arXiv:2008.01062, 2020.
S. Iqbal, C. A. S. de Witt, B. Peng, W. Böhmer, S. Whiteson, and F. Sha, “Ai-qmix:
Attention and imagination for dynamic multi-agent reinforcement learning,” arXiv preprint
arXiv:2006.04222, 2020.
T. Gupta, A. Mahajan, B. Peng, W. Böhmer, and S. Whiteson, “Uneven: Universal value
exploration for multi-agent reinforcement learning,” arXiv preprint arXiv:2010.02974, 2020.
D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, and M. Riedmiller, “Deterministic
policy gradient algorithms,” in International conference on machine learning. PMLR,
2014, pp. 387–395.
M. G. Bellemare, W. Dabney, and R. Munos, “A distributional perspective on reinforcement
learning,” in International Conference on Machine Learning. PMLR, 2017, pp. 449–458.
J. K. Gupta, M. Egorov, and M. Kochenderfer, “Cooperative multi-agent control using
deep reinforcement learning,” in International Conference on Autonomous Agents and
Multiagent Systems. Springer, 2017, pp. 66–83.
18You can also read

















































