Reducing Buffering Delay Using Memory Arbitration Mechanism for IPTV Based Applications
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Reducing Buffering Delay Using Memory Arbitration
Mechanism for IPTV Based Applications
Cammillus S ( cammillus@gmail.com )
National Engineering College
Shanmugavel S
National Engineering College
Research Article
Keywords: IPTV, playback mechanism, video buffering delay, Verilog
Posted Date: July 20th, 2021
DOI: https://doi.org/10.21203/rs.3.rs-616269/v1
License: This work is licensed under a Creative Commons Attribution 4.0 International License.
Read Full License
Page 1/16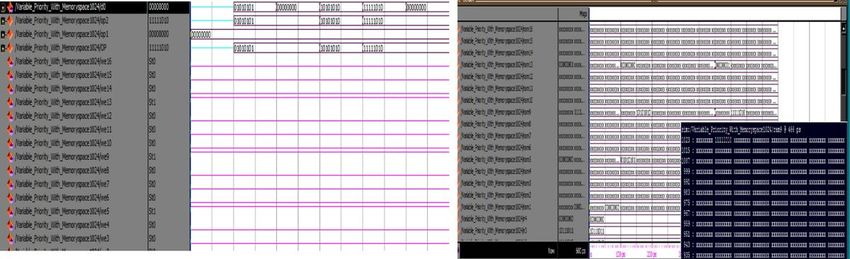
Abstract
High-speed communication needs high data transfer capacity and low latency, which are the key
parameters of high-speed communication. Converging different applications such as IPTV to high-speed
networks requires high transmission capacity and low delay with good QoS. Delays related to IPTV are
video buffering, synchronization, and switching delay that obstructs the client's excellent quality
assistance. In an application like IPTV, the video signals are buffered (happened to be in near end
routers), and they are recombined for the client when it is asserted. To achieve the above stated, memory
banks are deployed in a set top box that is used to buffer the video signals that enter in, thereby reducing
expected delay. Playback mechanism is also included along with the proposed model to accomplish a
better outcome. Proposed RTL schematic design was simulated using Verilog, executed in Model Sim –
Altera 10.1b (Quartus II 12.1 edition) and Cadence 5.
1. Introduction
In the early of 1950, TV broadcast was started in many countries. Commercial programs are broadcasted
and viewed at the user end. Starting from an analog mode of transmission till reaching home via Direct to
Home (DTH), many technological changes incurred in TV broadcasting. Combining numerous
applications with high-speed networks are expected in the future. High bandwidth and least delay are
typical at the customer end. Television such network should be met with the central organization, which
requires high exchange speed for good Quality of Service (QoS) at the customer end. Various users of
different age groups are accompanied by TV, and numerous live programs like sports and news are
watched by users worldwide. Transformation from simple transmission to DTH has improved digital
delivery to individuals that upgrade the Quality of Experience (QoE). Internet Protocol TV (IPTV), an
application that integrates television service to high-speed networks and makes TV service anywhere. The
application demands high transmission capacity and low latency. Early approaches [1–4] address the
bandwidth constraint by reconstructing video signals using buffers that adjust delay in the client's front
end. Many authors [7–9] proposed playback mechanism to reduce the delay at user end. Low-resolution
video signals are streamed, stored in buffer, and integrated at user's end on request. The low resolution
lasts until the user's end get connected with high-speed server.
Daniel et.al (2013) [1] proposed a bandwidth restriction algorithm. As user claims for a new video stream,
low quality I frames are acquainted with the standard stream, thereby reducing the quality. The
synthesized video quality will be low, and expecting the human visual framework can't differentiate it. The
play-out buffer got loaded up with multicast stream. Mandal et.al (2008) [3] utilizes a feedback
mechanism. The clients are equipped with preview channels managed of low-resolution video signal. The
mechanism used to prefetch the low resolution channels occurred at service end to reduce the switching
delay between channels. The channels are limited, and only popular channels are recommended. Hence,
the authors' recommendation is to introduce low resolution I frames and streaming the popular channels
for next viewing. The client's interest is not focused on next view.
Page 2/16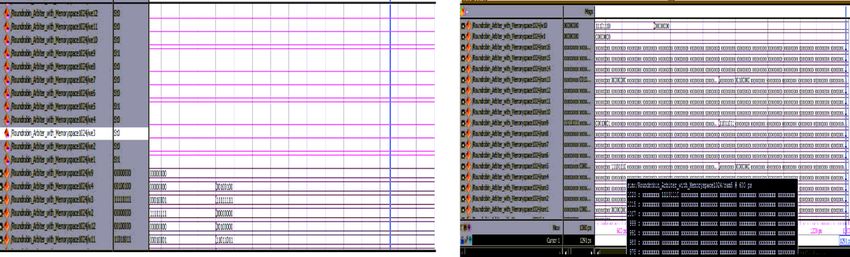
Bandodkaret.al(2008) [2] focused on reducing the user-perceived latency. The author proposed multicast
based approach to reduce the display latency with a good quality multicast stream. The method supports
network with high load and server load. Lee et.al(2007) [4] uses IGMP proxy servers. The scheme involves
prejoining strategy dependent on the past visit of client that is held by the IGMP proxy server. The
constraint that the IGMP needs to support the switching between the adjacent channels. The authors use
the study of previous view history and involving multicast, IGMP proxy servers.
Kim et.al(2008) [5] works with surfing behaviour to address the switching delay. STB sums the data to
multicast proxy server to prejoin the expected channels of the user. As user claims for the new channel,
the channel is switched with minimum delay. Ramos et.al (2013) [7] conveys additional I frames thereby,
the play-out mechanism reduces the latency at the user's front end. Insertion of I frames support to clip
the required size video as adapted with the buffer at service provider. As more I frames are inserted, it
results in the complexity of encoder design.
Lee et.al (2008) [6] uses H.264 scalable video scheme that utilizes base layer and enhancement layer. In
preview mode, the users are permitted to get to the base layer and switch over to the channel effectively.
When the user switches to a new channel, watching mode, both base layer and enhancement layer are
served to equip the signal's good quality. Lee et.al (2014) [8] classifies the accessible channels into hot
and cold channels. The channels that will probably be watched in the future are named hot channels, and
the following channels are cold channels. The channels are classified as hot and cold as with the back
history of the IPTV users and back history of viewing. For the preview mode, the hot channels are
prefetched as low-resolution signals. The author classifies the watch channels based on the client's
interest as hot and cold channels. Further, the datas are stored and made available in the nearby service
provider.
Yang et.al (2015) [9] proposes framework-based IPTV (FIPTV). The model uses Backing United Stream
(BUS) virtual channel that downloads sample of video segments and stores in the client's local buffer. As
the user demands the target channel, the playback mechanism will get initiated, leading to zero switching
delay. M.S.K Manikandan (2016) [10] uses Grouped Frequency Interleaved Ordering (GFIO) with Pre-
Fetching (PF) to reduce the delay in IPTV switching. The strategy used to lessen the channel seek time of
IPTV channels. Closely associated channels are put nearer that lessen the channel seek time.
Zare (2016) [11] proposes Program Driven Channel Switching (PDCS) and Program Driven with Weight
(PDW). Here, the user can choose the desired program rather than switch to channels; hence, channel
switching gets free from the channel number. Zare (2018) [12] uses Pre-Buffering join with program
Driven to lessen the channel switches. This will lessen the holding time to deliver the first frame as the
user selects the channel to the previous method adapted like Frequency Interleave Ordering (FIO),
Frequency Circular Ordering (FCO), Program Driven with Weight (PDW). Li (2020) [19] identifies the user's
zapping pattern and recommends the channel to view for the next zapping. The method dilutes the user’s
confusion to choose the desired channel. Neural-based recommender system is used for the above-said
process. The model involves two modules Recommender System (RS) attention module and Channel
Page 3/16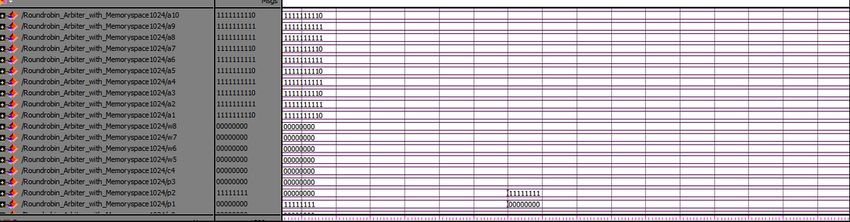
attention module. The former captures the user’s interest, and the latter captures the channel switching
behaviour of the user.
Gupta (2015) [13] proposed a configurable arbiter for n users. The author uses round-robin techniques for
high-speed SoC design. The arbiter is parameterized and can be configured dynamically that increases
the flexibility for better user’s access. Oveis-Gharan (2015) [14] proposed an index-based round-robin
arbiter that actuates the input port of the router. The arbiter consumes less power, low chip area, and high
performance. The techniques are simple, fast, and have less hardware overhead.
Khanam, R (2015) [15] proposed a dynamic bus arbiter for SoC. The arbiter distributes the priority among
themasters to access the shared bus. The method removes the bus starvation and contention to access
the shared bus. The author identifies that the technique is superior to the previous proposed “Dynamic
Lottery based Algorithm”. Kamal, R (2016) [16] compares three arbitration algorithms fixed priority, round
robin and matrix arbiters. The author identifies that fixed, matrix arbiters are slower and less efficient. The
authors recommend round-robin arbiter for high-speed switching.
Sievers (2017) [17] targets streaming applications like signal and video processing. The author
introduces a tightly coupled shared data memory to CPU clusters. The techniques lower the access
latency to the shared memory. Wittig (2019) [18] uses shared memory for multiple processing elements.
The conflict in accessing the shared memory is reduced by access interval prediction method that
minimizes the collision by different processors to access the memory.
The available work gives a limelight on the role of playback mechanism and proves that it is inevitable to
reduce the switching delay. Many authors proposed this mechanism and contributed a lot to this method.
Hence the playback methodology is taken into account for the work. In early research, the user's interest is
estimated at the service provider end (i.e., router). The low-resolution data are stored at the router end and
streamed back when the user switches between channels. The router uses proxy servers to get around the
user's interest information at its end to supplement when required by the user. As with Ramos et.al [7] the
video buffering delay is between 1 to 2 minutes. Also, the information stored in the router will enlarge with
the number of users. With new inventions of IoT, many devices collect different information and need to
be stored. As a result, a vast memory requirement is expected at the router end (the trespassing
information needs to be stored in the router for at least some time as guided by respective countries).
Hence, it is proposed to deploy local memory in the head-end device of the home. STB serves as the head-
end device. Memory components are added along with the STB and stored the user's interest in low
resolution. The user's interest is computed at the router end, and the information is made available to the
channels of STB. Channel 0 of the STB will be served with the user's interest on the front screen, and the
other channels of the STB are offered with the correlated channels of the user's interest currently running
on the front-end display device. The channel on view is streamed with high quality as per the privileges of
the user. The other signals arriving at the following channels of STB are streamed with low quality and
stored in the local memory of the STB. The work thereby aims to reduce the buffering delay as the
information is made available to the head end device of the client.
Page 4/16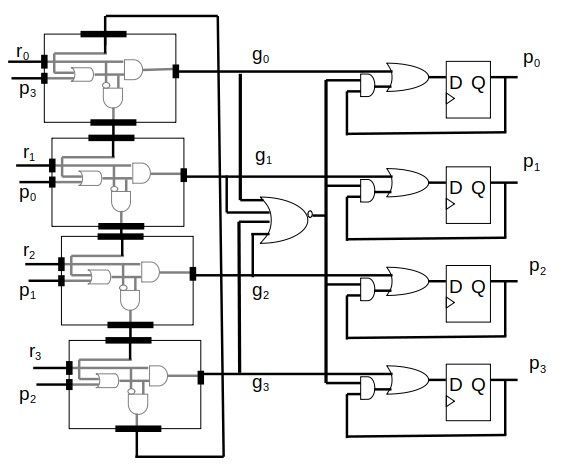
The rest of the paper is organized as follows. The proposed model is discussed in Sect. 2. The proposed
algorithm is discussed in Sect. 3. The next Sect. 4 discusses the obtained results and outcomes of the
proposed architecture. Section 5 discusses the conclusion of the work.
2. Proposed Work
The determination of channels is arbitrary, dependent on the decision of the client. As the client's
solicitation originated, the home's routing component issues a request message to the remote server. The
mentioned video data is transferred back with high transmission capacity, and it is given to the client's
front gadget. The exchanging among channels and the buffering delay contribute to a significant setback
in IPTV networks.
Playback mechanism is an effective methodology adopted to minimize the delay that occurs at user's
front end. It includes store and play, where the video of low resolution is stored and played when it is
needed by the client. The playback system is triggered until the high-resolution video arrives at the client
from the remote server.
The videos are broken into pieces contingent on the accessibility of memory in the gadget and the
reclamation time to get good quality video from the remote server. This is accomplished by embedding
low-quality I frames to the video data signal. The inclusion of I frame will empower to spilt the video data
into small pieces.
Subsequently, the playback system is unavoidable to diminish the buffering delay. Extra I frames are
acquainted with help the playback methodology at the client end afforded by the remote server. The
nearby routing element holds the client data and ready to serve as indicated by the client's request. Latest
developments in artificial intelligence help the client's request and diminish the switching delay.
The service provider holds back the information according to the history surfing of the client. As the client
claims for the previously viewed data, the stored content is extracted from the memory and delivered to
the front end. The constraint is that as the client becomes countless, an enormous buffer is needed at the
router (service provider) end.
The proposed strategy, Localized Playback Mechanism (LPM), incorporates memory segments to store
the client interest in the head end gadget, the Set-top box. Subsequently, this would expect to lessen the
delay that occurs because of video buffering in the adjacent router. The inclusion of memory in the set-
top box also enriches to accommodate other gadget's secret information. The proposed block outline is
given beneath (see Fig. 1).
As the memory is nearby, the memory's content can be recovered fastly and the necessary video buffering
done at headend. The proposed strategy also limits the load in the neighbouring router, and the protection
of the information is guaranteed locally. As the approaching channels expand, the memory size enlarges,
Page 5/16and if the channels need to write the data in the same memory zone, that leads to the memory deadlock
or overriding of data.
2.1 Set top box
This structures the head gadget to home that interfaces the electronic devices to the external world. The
components in home are associated to set-top box that gives the network access to the household
electronic gadgets. The head component will be associated to the high-speed network through the
nearest router that provide network access to the set top box. Set-top box is anembedded gadget that
predominantly comprises of power supply, RAM, decoder, video interfaces, audio interfaces, storage, RF
modulator and flash. On any plea from the household gadgets, the STB will issue a plea to the service
provider. The STB gets the requested content from the high-speed network via the directly connected
routers.
The service provider (router) extracts the user's surfing history, and the information is made available in
the router at any time of low resolution. As every component in home uses internet service, the memory
requirement in router continues expanding. Hence, it is proposed to in-build memory components in the
head-end device. Since the client's information is stored nearby, the delay in getting back the information
reduces.
The memory can be limited if Electronic Program Guide (EPG) is used along with the STB. As with new
developments of memory chips, it is conceivable to implant the memory components in STB that can
hold the local data. Likewise, it is conceivable to rearrange the data based on client interest in STB.
3. Localized Playback Mechanism
The data that arrives at the STB input port as with the user's request is allowed to occupy port 0 of the
crossbar switch. The data flits out the crossbar switch and given to the display interface. The service
provider (ISP) understands the user's interest and gets back the low-resolution content of the associated
channels to the set-top box's input and fed to the other ports of the crossbar switch. The user's current
interest is provided with high-resolution content, and the closely correlated choices are streamed to
memory with low-resolution content. The low-resolution contents are back stored in the memory, and
when it is demanded by the user, the low-resolution data is streamed to the front end until the high-
resolution data arrives.
3.1 Proposed Algorithm
Figure 2 depicts the flow process involved. As with the client's previous watch history, the information is
made available nearby in the memory. The client may switch between choices.
Step 1: With client's preferred choice, the choice is searched in the memory of STB.
Page 6/16Step 2: If the claimed content is available in the memory, the low-resolution content is made available to
the user until the high-resolution content arrives from the remote server.
Step 3: The client's choice is to access the prime channel (r0) of the STB and seeks the high-resolution
video signal from the remote server.
Step 4: If the claimed content is not available in the memory, STB resets its memory and seeks the high-
resolution video signal from the remote server.
Step 5: New correlated channels relevant to the client's choice identified by the service provider are
streamed at the STB and arranged adjacent to the prime channel r0.
Step 6: Low-resolution video streams adjacent to prime channel are stored back in STB and made
available to client when required.
3.2 Working operation
Figure 3 shows the working activity of the proposed model. It comprises an arrangement of multiplexers
that switch the approaching video signal to the output port. The asserted data is accommodated at
channel r0, and closely related channels are adjusted to the adjacent ports. The channels to the adjacent
ports are recommended by the service provider (router). The asserted data will claim the output port of 8
X 1 multiplexer (MUX) M1 and be fed as the input of 2 X 1 MUX M3. MUX M3 will produce the outputs of
the user's information to display interface.
The close associated channels are written to memory block through arbiter. Various arbitration
methodologies are undertaken to identify the efficient arbitration method to write information to memory.
The various arbitration algorithms and their working principles are explained in the forthcoming
sessions.
Assuming the user claims for a new channel stored in memory, then available data stored in the memory
is fetched back and given as input to the multiplexer M3 via 2 X 1 multiplexer M2. This will occur till the
high-resolution content from remote server reverts the claimed data to channel 0 of M1. Depending on the
accommodation limit of M1, the storage limit can be enhanced or minimized.
3.3 Fixed priority
The channel that arrives first will get access to output port. After the completion of the first arrived
channel, the next channel will gain access to the output port. The channel accepts a continuous stream
of 8 bits. Combination of basic gates will felicitate the above process. The channel r0, which arrives first,
occupies the output port g0. Until the channel completes its task, the output port is blocked to rest of the
channels (r1 to r3.). When channel r0 completes its process, the channel r1 takes the output port. Figure 4
gives detailed narration on the operation of the fixed arbitration method.
Page 7/163.4 Variable priority
Here the channels are assigned with variable priority, and hence the channel that occupies at r0 will have
more priority than other channels. The channel accepts a continuous stream of 8 bits. The content of r0 is
allowed to access the output port thereafter the following priority channels r1,r2,r3, respectively. At the
closure of channel r3, channel r0 again regains the output port. The combination of basic gates felicitates
the above process. Figure 5 will elaborate the process involved in variable priority.
3.5 Round robin method
Here the channels are arranged in a round fashion. The channel accepts a continuous stream of 8 bits.
The channels get access over the output port as per its priority. Hence the priority is distributed to all
channels as per the requirement, and thus the channels need not be one after the other. The channel who
got the first access on output, on completion, the same channel will be moved to last with least priority.
Hence the round fashion is accomplished. Figure 6 shows the flow process of round robin method and
the basic gates that are involved to achieve the process.
3.6 Memory block
The arbiter algorithm is used to arbitrate the writing mechanism into memory. The proposed model uses
a block memory of 1KB per channel to store the user’s interest. 8X1 multiplexer is used to switch the input
port content to the user’s peripheral device. Each channel stores its data to block memory of size 1 KB.
The memory bank can be expanded relying on the applications and the capacity of the switching
multiplexer. The write/read command is activated using the 3 X 8 decoder. With the combination of
address and data bus, the data is fetched into the memory. Three different algorithms are used to
arbitrate the writing and reading mechanism onto the block memory. The findings are discussed below.
4. Results And Discussion
Model Sim – Altera 10.1b (Quartus II) is used to analyse HDL design. It also enables to perform timing
analysis, synthesize designs, and examine RTL schematic diagrams. Cadence 5 is used to extract cell
area, power consumed and timing delay.
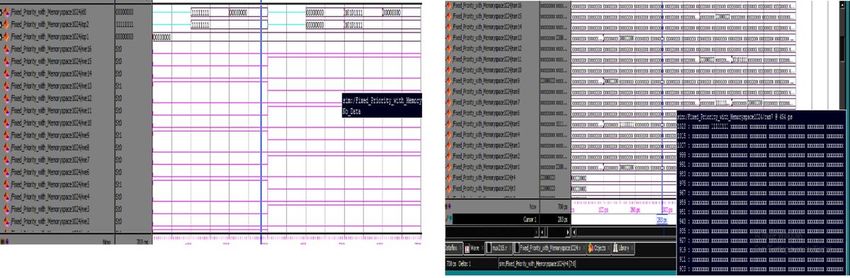
Figure 7(a) shows the initialization of ports during the fixed arbitration into memory. Channel r0 has high
priority, followed by other channels r1,r2,r3 etc. The user’s interest that arrives at STB is allowed to write in
the memory. The channel having highest priority is made to access the memory first, followed by the
other channels. Figure 7(b) shows writing channel information in the memory. The channel with high
priority is allowed to write in the memory. With changes in the user’s choice available in the memory is
fetched back to the output port. Figure 8 shows the fetching from the memory to the output port.
Figure 9(a) shows the initialization of ports for variable arbitration techniques to write the content into the
memory. The channels are given with different priorities. If channel r0 gains the highest priority, channel r0
Page 8/16is allowed to write its content into the memory. On completion of the task, the next channel gains the
highest priority, and channel r0 loses its priority and shifted to the last. Fig. 9(b) shows the writing of data
into the memory. The channel that has high priority is allowed to write the data first, followed by others.
Figure 10 shows the reading out of data from memory as per the request by the user.
In round robin mechanism, the ports are arranged in round fashion to write the content into memory.
Figure 11(a) shows the initialization of ports. Fig. 11(b) shows the writing operation into the memory.
Only one channel is allowed to write its data into the memory, followed by the others. Figure 12 shows the
reading operation from memory as requested by the user.
The RTL simulation is carried out in Cadence 5, and the comparison chart is given below. Table 1 shows
the comparison chart for various arbitration algorithm used in our model. The active cells and cell area
occupied for the above-said algorithms is near to each other. The power consumed by the active cells is
lesser in round-robin method rather than the other two methods. The delay in occupying the output port is
similar to all the above-said algorithms.
Table 1 Comparision chart for various arbitration algorithms
Arbitration Algorithm Cells area(m3) Power(mW) Delay(ps)
Fixed Priority 197623 3.968986 33.907896606 831
Variable Priority 197648 3.969085 36.859223919 831
Rond Robin method 197684 3.969302 33.419994389 831
5. Conclusion
The work involves in storing the user's preferred choice in the memory of the STB. The user's preference is
identified by the nearby service provider, streamed to the STB, and stored in its local memory. When the
user shifts their choice, and if the data is available in the memory, the data is played out to the user using
the playback mechanism. Since the data is made available near the device, the information can be
secured and private to the user. Three different arbitration are taken into account, and the comparisons
are made. The other channels are not allowed to write into the memory in fixed arbitration until the first
channel completes the process, whereas the other channels are given with its weighted priority to access
the memory in variable priority arbitration method. Round-robin arbitration method allows the channel to
access the memory eventually, and if the user needs any data from the memory of any preferred channel,
the information is reverted to the user with less delay. Hence, the power consumed by round-robin
arbitration is less than others, and the delay in fetching the data from memory to output port is 831 ps.
Declarations
Page 9/16Funding: No funding Conflicts of interest/Competing interests: No conflict and Competing Interest
Availability of data and material: Available in paper Code availability: Available in paper Ethics approval:
Not applicable Consent to participate: Not applicable Consent for publication: Not applicable
References
1. Manzato, D. A., & da Fonseca, N. L. (2013). A survey of channel switching schemes for IPTV. IEEE
Communications Magazine, 51(8), 120–127
2. Banodkar, D., Ramakrishnan, K. K., Kalyanaraman, S., Gerber, A., & Spatscheck, O. (2008). Multicast
instant channel change in IPTV systems. In: 2008 3rd International Conference on Communication
Systems Software and Middleware and Workshops (COMSWARE'08), pp 370–379.
3. Mandal, S. K., & &MBuru, M. (2008). Intelligent pre-fetching to reduce channel switching delay in IPTV
systems. Texas A & M, pp. 1–6.
4. Lee, J., Lee, G., Seok, S., & Chung, B. (2007). Advanced scheme to reduce IPTV channel zapping time.
In: Asia-Pacific Network Operations and Management Symposium, pp. 235–243.
5. Kim, Y., Park, J. K., Choi, H. J., Lee, S., & Park, H. (2008). Reducing IPTV channel zapping time based
on viewer’s surfing behavior and preference. In: 2008 IEEE International Symposium on Broadband
Multimedia Systems and Broadcasting, pp. 1–6.
6. Lee, Y., Lee, J., Kim, I., & Shin, H. (2008). Reducing IPTV channel switching time using H. 264 scalable
video coding. IEEE Transactions on Consumer Electronics, 54(2), 912–919
7. Ramos, F. M. (2013). Mitigating IPTV zapping delay. IEEE Communications Magazine, 51(8), 128–
133
8. Manikandan, S., & Chinnadurai, M. "Effective Energy Adaptive and Consumption in Wireless Sensor
Network Using Distributed Source Coding and Sampling Techniques",. Wireless Personal
Communication(2021). Springer, https://doi.org/10.1007/s11277-021-08081-3
9. Yang, C., & Liu, Y. (2015). On achieving short channel switching delay and playback lag in IP-based
TV systems. IEEE transactions on multimedia, 17(7), 1096–1106
10. Manikandan, M. S. K., Saurigresan, P., & Ramkumar, R. (2016). Grouped frequency interleaved
ordering with pre-fetching for efficient channel navigation in internet protocol television. Multimedia
Tools and Applications, 75(2), 887–902
11. Zare, S., & Rahbar, A. G. (2016). Program-driven approach to reduce latency during surfing periods in
IPTV networks. Multimedia Tools and Applications, 75(23), 16059–16071
12. Zare, S. (2018). A program-driven approach joint with pre-buffering and popularity to reduce latency
during channel surfing periods in IPTV networks. Multimedia Tools and Applications, 77(24), 32093–
32105
13. Gupta, J., & Goel, N. (2015). Efficient bus arbitration protocol for SoC design. In: 2015 International
Conference on Smart Technologies and Management for Computing, Communication, Controls,
Energy and Materials (ICSTM). pp. 396–400.
Page 10/1614. Manikandan, S., Chinnadurai, M., & Manuel Vianny, D. M. (2020). and D.Sivabalaselvamani, "Real
Time Traffic Flow Prediction and Intelligent Traffic Control from Remote Location for Large-Scale
Heterogeneous Networking using TensorFlow". International Journal of Future Generation
Communication and Networking, ISSN(No.1), 2233–7857
15. Khanam, R., Sharma, H., & Gaur, S. (2015). Design a low latency Arbiter for on chip Communication
Architecture. In: International Conference on Computing, Communication & Automation, pp. 1421–
1426.
16. Kamal, R., & &Arostegui, J. M. M. (2016). RTL implementation and analysis of fixed priority, round
robin, and matrix arbiters for the NoC's routers. In: 2016 International Conference on Computing,
Communication and Automation (ICCCA), pp. 1454–1459.
17. Ax, J., Sievers, G., Daberkow, J., Flasskamp, M., & Vohrmann, M. (2017). CoreVA-MPSoC: A many-core
architecture with tightly coupled shared and local data memories. IEEE Transactions on Parallel and
Distributed Systems, 29(5), 1030–1043
18. Wittig, R., Hasler, M., Matus, E., & Fettweis, G. (2019). Statistical access interval prediction for tightly
coupled memory systems. In: 2019 IEEE Symposium in Low-Power and High-Speed Chips (COOL
CHIPS), pp. 1–3.
19. Li, G., Qiu, L., Yu, C., Cao, H., Liu, Y., & Yang, C. (2020). IPTV Channel Zapping Recommendation with
Attention Mechanism. IEEE Transactions on Multimedia
Figures
Page 11/16Figure 1
Block diagram – Localized Play back Mechanism
Figure 2
Flow chart – LPM
Figure 3
Schematic diagram of LPM
Page 12/16Figure 4
Fixed priority arbiter
Figure 5
Variable priorityarbiter
Page 13/16Figure 6
Round robin arbiter
Figure 7
Fixed arbitration (a) Observation of input and output ports (b) Writing data into memory
Page 14/16Figure 8
Fixed arbitration: Reading data from memory
Figure 9
Variable arbitration (a) Observation of input and output ports (b) Writing data into memory
Figure 10
Reading data from memory
Page 15/16Figure 11
Round robin arbitration (a) Observation of input and output ports (b) Writing into memory
Figure 12
Reading data from memory using RRA
Page 16/16You can also read