INTEGRATING KNOWLEDGE-SUPPORTED SEARCH INTO THE INCEPTION ANNOTATION PLATFORM
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Integrating Knowledge-Supported Search
into the INCEpTION Annotation Platform
Beto Boullosa Richard Eckart de Castilho Naveen Kumar
Jan-Christoph Klie Iryna Gurevych
Ubiquitous Knowledge Processing Lab
Technische Universität Darmstadt, Germany
https://www.ukp.tu-darmstadt.de
Abstract which facilitates interpreting, processing, and nav-
Annotating entity mentions and linking them
igating the annotated texts by effectively creating
to a knowledge resource are essential tasks cross-document coreferences.
in many domains. It disambiguates mentions, Consider a wine market specialist analysing a
introduces cross-document coreferences, and corpus of wine reviews. She wants to annotate men-
the resources contribute extra information, e.g. tions of different types of wines and link them to
taxonomic relations. Such tasks benefit from a knowledge resource, more specifically to a wine
text annotation tools that integrate a search taxonomy. However, since annotating the entire
which covers the text, the annotations, as well
corpus would take too much time, she wants to
as the knowledge resource. However, to the
best of our knowledge, no current tools inte- focus on statements made about certain properties
grate knowledge-supported search as well as of specific wines. Thus, she needs to search for
entity linking support. We address this gap by keywords (“price”, “quality”, etc.), mentions of
introducing knowledge-supported search func- wines of certain types (“Bordeaux”, “Burgundy”),
tionality into the INCEpTION text annotation or already annotated statements (e.g. to find com-
platform. In our approach, cross-document ref- parative reviews). Thus, the specialist might pose
erences are created by linking entity mentions
queries such as “sentences containing statements
to a knowledge base in the form of a structured
hierarchical vocabulary. The resulting annota- about the price of all kinds of Bordeaux wines”
tions are then indexed to enable fast and yet in order to completely perform her corpus analy-
complex queries taking into account the text, sis. Note that the analyst cannot prepare a task-
the annotations, and the vocabulary structure. specific corpus in advance, because she only dis-
covers which properties of the wines are addressed
1 Introduction
by the reviews as she goes along with the analysis.
In many domains, annotating documents is a key re- We are not aware of any web-based text anno-
quirement to solve complex problems like identify- tation tool that supports this kind of explorative
ing sentiment targets in customer reviews, or identi- annotation tasks requiring full-text search, cross-
fying disease symptoms in medical texts. Tradition- document entity linking, and annotation search,
ally, annotation tasks involved creating dense layers and, at the same time, takes into account the hi-
of annotation, e.g. part-of-speech or dependency erarchical relations of a taxonomy in a tightly in-
annotations made on every single word, single or tegrated way. To address this gap, we integrate
multi-token named entity mentions. Nowadays, the knowledge-supported search capabilities into the
information to be annotated is often sparsely dis- INCEpTION annotation platform (Klie et al., 2018)
tributed, e.g. the mentions of particular types of to provide a flexible way of searching the corpus
entities. Finding spans of text which are candidates during the annotation process. The corpus and
for a particular annotation type has thus become an annotations are indexed at token level. Primitive
important and challenging aspect of the annotation attributes (string, numeric, boolean) and attributes
process. Therefore, it is essential that annotators linking annotations to a knowledge base are in-
can search the corpus, making queries over the full dexed and can be queried. For linked annotations,
text as well as over the annotations. Linking en- it also considers the super-type/hypernym relations
tity mentions to a structured knowledge resource in the respective knowledge resource.
(e.g. a taxonomy) allows them to be disambiguated, Section 2 highlights use cases in which those
127
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (System Demonstrations), pages 127–132
Brussels, Belgium, October 31–November 4, 2018. c 2018 Association for Computational Linguistics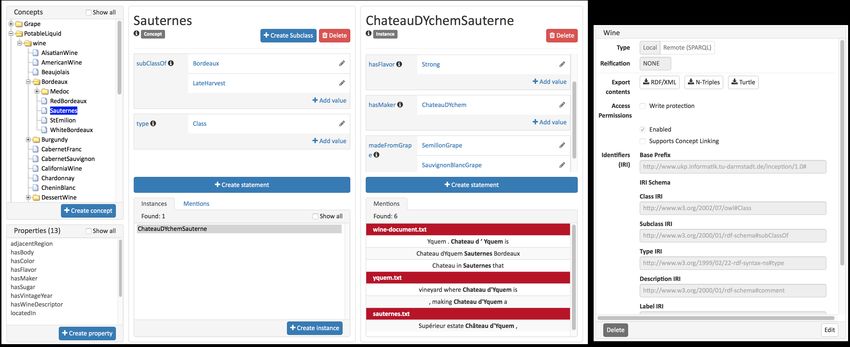
functionalities are beneficial. Section 3 briefly now wants to query the linked concept mentions in
introduces the INCEpTION annotation platform. conjunction with these claims, e.g. to locate claims
Section 4 describes the knowledge-supported about particular types of wines. She may search
search functionality. Section 5 describes which for “claims about wines either from the Bordeaux or
types of knowledge resources the platform supports. from the Burgundy types, containing words matching
Finally, Section 6 describes the related work. the pattern ’expensive.*’” (Figure 1).
These scenarios underline the benefit of integrat-
2 Use cases ing full text and knowledge-supported annotation
This section examines three exemplary scenarios search into an annotation tool. The next sections
of increasing complexity that highlight the benefits shows how INCEpTION addresses these needs.
of knowledge-supported search in an annotation 3 The INCEpTION platform
tool. We consider a wine market specialist who is
investigating a corpus of wine reviews to identify INCEpTION2 is a generic multi-user annotation
the qualities most valued by the consumers and for platform aiming to cover three essential aspects of
which they may be willing to pay more. Her goal is text annotation in a single tool: 1) corpus building,
to gain insights on consumer preferences, and the 2) knowledge modelling, and 3) annotation, and
annotations she performs are a means to achieve to combine them with machine-learning-based as-
this goal. The examples use the wine ontology from sistive mechanisms (so-called recommenders) to
the W3C’s OWL Web Ontology Language Guide,1 improve the annotation efficiency and quality.
a popular example of an OWL-based ontology. INCEpTION is implemented as a Java-
Scenario I: Mention identification. The user based web application using Tomcat, Spring
wants to annotate mentions of a certain concept, Boot and Wicket. It is partially based on
e.g. types of wines. She starts with an initial list WebAnno (Eckart de Castilho et al., 2016), which
of wine types and uses the full text search to locate we have modularized step-by-step to accommodate
potential mentions, e.g. Bordeaux. Since the query the needs of INCEpTION. This has allowed us to
is ambiguous (e.g. it could refer to the city or to the exclude certain WebAnno modules, e.g. the origi-
region instead of the wine type), she reviews each nal automation module, which we replace with our
match and annotates it only when appropriate. If own recommender framework, as well as to add
she discovers a wine type during this process that new modules such as the search capabilities and
is not yet on her list, she adds it and again uses the knowledge base integration discussed here. We
full text search to locate and annotate its mentions. retain the WebAnno modules for project manage-
Scenario II: Concept linking. The user now ment, inter-annotator agreement calculation, adju-
links the previously identified mentions to a taxon- dication, etc. as they are compatible with our new
omy where the types of wines are organized into a modules. The platform is open source software
tree or directed acyclic graph. For example, the vo- licensed under the Apache License 2.0.
cabulary encodes that Château d’Yquem is a wine This paper focusses on the annotation search ca-
belonging to the Sauternes type, which in turn is pabilities of INCEpTION together with its knowl-
a subtype of Bordeaux. These links effectively in- edge base support. For the recommender mecha-
troduce cross-document coreferences within the nism, please refer to Klie et al. (2018).
corpus. Using the annotation search capabilities,
the user wants to locate mentions of a wine type.
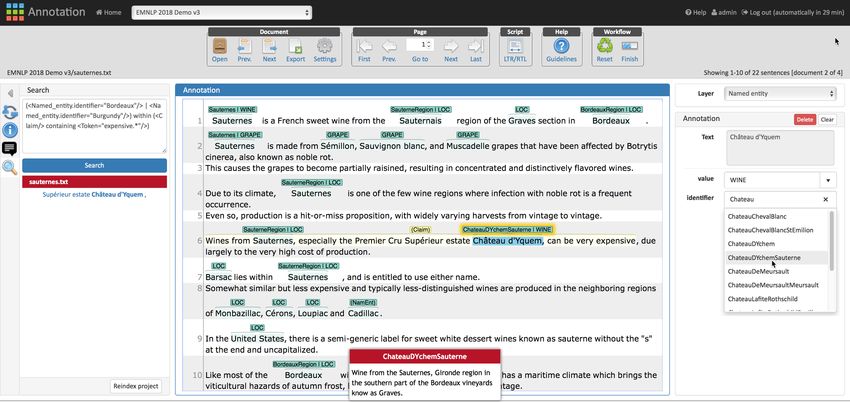
4 Search
This should consider the vocabulary structure, such The search functionality of INCEpTION is acces-
that a search for a general wine type (e.g. Bordeaux) sible through a sidebar 1 in the annotation editor
also finds mentions of all its subtypes. (Figure 1). It allows searching within the docu-
Scenario III: Concepts in context. In addition ments of the project the user is currently work-
to the linked concept mentions from the previous ing on. After executing a query, the correspond-
scenario, we assume that the corpus also carries ing results are displayed grouped by document 2 .
other types of annotation, e.g. a custom claim anno- Clicking on a result causes the annotation area to
tation which identifies text spans containing state- switch to the corresponding document/text span 3 .
ments made about properties of the wine. The user Attributes that link an annotation to a knowledge
1 2
https://www.w3.org/TR/owl-guide/wine.rdf https://inception-project.github.io
1281
2
3
5 4
Figure 1: 1 Search sidebar with the query “all mentions of wines belonging either to the Bordeaux or to the
Burgundy type, located inside a claim which contains the pattern expensive.* ”; 2 search results grouped by
document; 3 annotation area with a highlighted result; 4 auto-complete field allowing to select an entity from
the knowledge base; 5 description of the entity the mouse cursor hovers over.
base item are conveniently editable through an auto- All frameworks support searching the full text
complete field 4 . as well as span annotations and their attributes.
Mı́mir and IMS CWB both assume that corpora
4.1 Choosing a search framework
are indexed once and queried often. Indexed docu-
The knowledge-supported search functionality ments can neither be updated nor easily be deleted
called for a search framework that met three re- and replaced. MTAS does not support updates
quirements: 1) supporting text and annotation to documents, but it allows deleting and then re-
search; 2) supporting frequent updates, since the indexing individual documents.
index needs to be updated whenever the user cre- IMS CWB is implemented in C and can be run
ates, changes or deletes an annotation; 3) it can either as a server or in an interactive mode. It
be embedded directly in the annotation tool (i.e. cannot be easily embedded into a Java application
no separate installation required). We considered such as INCEpTION. Mı́mir is implemented in
three frameworks: the IMS Open Corpus Work- Java, but its architectural design assumes that it
bench, Mı́mir and MTAS. is being used as a server. MTAS can be run as
The IMS Open Corpus Workbench (Christ, a server, but it can also be embedded into a Java-
1994) (IMS CWB) is an old but powerful tool to based application.
index and search annotated corpora. It introduced In conclusion, this made MTAS the best choice
the popular Corpus Query Language (CQL). to be integrated with INCEpTION.
Using Mı́mir (Tablan et al., 2015), queries over
the annotated text can be combined with informa- 4.2 Integrating the search framework
tion from an knowledge base through SPARQL.
This permits queries such as find all mentions X To manage the annotations, INCEpTION uses
of persons that were born in London, where X is UIMA (Ferrucci and Lally, 2004). For the knowl-
annotated as a person in the text, and X was born edge base (KB), it uses RDF4J4 . Thus, it was nec-
in London is contained in the knowledge base. essary to first implement a bridge from the UIMA
MTAS (Brouwer et al., 2017) is a recent frame- data model to the MTAS data model while support-
work which implements a large part of CQL on top ing the customizable layer configuration provided
of Apache Lucene.3 by INCEpTION. The ability to index annotation
3 4
http://lucene.apache.org/ http://rdf4j.org
129attributes that link to KB items, i.e. classes and in- KB item; 2) mentions of a KB item, including the
stances, was then added as a plugin to this bridge. mentions of its descendants.
The bridge equally supports the built-in anno- The syntax for addressing the attributes linked
tation layers (e.g. NAMED ENTITY) as well as to the knowledge base is the same as for normal
user-defined layers (e.g. C LAIM). It indexes all the attributes. The user can either match against the
spans associated with all types of annotation layers IRI of the linked KB item or against its label. This
(spans, relations, and chains). However, queries will retrieve all mentions of the given item, plus all
over relations and chains are limited since MTAS mentions of its descendants in the ontology. Thus,
does not offer specific query operators for them. the query effectively traverses the ontology hierar-
Indexed annotations must start and end at a token chy, starting in the given item and going down its
boundary. Subtoken annotations are not supported. corresponding subtree. This addresses queries like
Each layer defines a set of attributes. E.g. the the one highlighted in Scenario II (Section 2).
NAMED ENTITY layer defines a string attribute
VALUE , which usually takes values such as LOC,
PER, ORG and OTH for standard named entity anno-
tation tasks. For our examples, we have also added The following example matches all mentions of
WINE and GRAPE to that list. It also provides the wines under the Bordeaux branch of the ontology:
attribute IDENTIFIER which can be used to link an
annotation to a KB item (class or instance).
4.3 Full-text, annotation and attribute search By appending -exact to the attribute name, it is
The token layer is built into INCEpTION and can possible to limit the query to mentions of exactly
be used to perform full-text queries. E.g., this query one particular item:
locates all occurrences of the token Bordeaux:
”Bordeaux”
Note that multiple KB items may in principle
Layers are referenced by their name. Attributes carry the same label. To avoid this ambiguity, it
can be addressed using the syntax [layer].[attribute]. may be necessary to query using the IRI.
Assuming that wine mentions are annotated as Considering again that annotations are linked to
named entities of type WINE, the following query the wine ontology, the following query locates all
finds all mentions of wines. This addresses the exact mentions of the Clos de Vougeot wine:
needs of Scenario I (Section 2).
4.4 Knowledge-supported search The rich query language provided by MTAS
Consider that the named entity annotation layer car- allows to combine different query types like the
ries an IDENTIFIER attribute that holds the IRI (In- ones previously introduced, using operators such
ternationalized Resource Identifier) of a KB item as within or containing. Considering that our exam-
(Figure 2). These IRIs are included in the index, ple dataset includes the custom C LAIM annotation
together with the IRIs of any items located higher type, we can address Scenario III (Section 2) by
in the ontology hierarchy. As IRIs are hard to read, writing the following query, which retrieves all
the index also includes the human-readable labels mentions of wines belonging to the Burgundy or
associated with the entries, so that the user can Bordeaux types (and their subtypes), located inside
query using these labels instead. a claim that matches the regular expression pattern
A KB item can either be a class in the ontology expensive.* (Figure 1).
hierarchy (e.g. a wine type or subtype) or an in-
stance (e.g. a specific wine). The following types ( |
)
of queries can be performed to search for annota- within ( containing ”expensive.*”)
tions linked to the KB: 1) mentions of a specific
1308
7
9
6
Figure 2: Knowledge base page (left): 8 concept explorer; 9 property explorer; 6 annotated mentions of the
seleted KB item. Right: 7 mapping configuration editor.
5 Knowledge-base integration ally IRIs identifying CLASS and PROPERTY defini-
tions are required in order to populate the concept
The knowledge-oriented search capabilities of explorer 8 and the property explorer 9 (Fig-
INCEpTION are enabled by its KB module. This ure 2) - e.g. . The class
module allows the user to create a KB from scratch hierarchy is defined via the SUBCLASS - OF IRI.
or to import one from an RDF file. Remote KBs can Thus, hierarchies defined e.g. via rdfs:subClassOf or
be accessed in a read-only mode via the SPARQL. skos:broader are supported, but not hierarchies de-
The KB management page (Figure 2) allows fined via skos:narrower.6 While INCEpTION tries
editing classes, properties, instances and the cor- to detect root classes automatically, the correspond-
responding statements they are defined by. Using ing query is resource intensive and may eventually
the search module, it also displays any annotated time out on some large knowledge resources. Thus,
mentions 6 of the currently selected KB item. it is also possible to bypass the automatic detection
As the KB module is RDF-based, every piece of by manually specifying the IRIs of root classes. Fi-
information is stored as a triple . nally, IRIs for LABELs and DESCRIPTIONs can be
Since this model is very abstract, there are a number defined. If present, labels are used instead of the
of different schemas defining common identifiers IRI when referring to a class, property or instance.
(IRIs) that provide additional semantics, e.g. RDF Descriptions are shown as a tooltip (Figure 1) when
Schema5 uses the IRI rdfs:subClassOf to encode a linking an annotation to a KB item.
subclass relation between the items identified by
the subject and the object of a triple. 6 Related work
To support a broad range of different knowledge Several annotation tools support structured vocab-
resources, INCEpTION offers a configurable map- ularies or KBs and some can be used for cross-
ping 7 (Figure 2). The user can choose from document annotation tasks. As INCEpTION is a
several predefined mappings (e.g. RDF, OWL, or generic annotation tool, we compare our work to
SKOS) or define a custom mapping. The mapping the other generic tools.
mechanism relies on a minimal set of IRIs that WebAnno (Eckart de Castilho et al., 2016), while
must be defined for any KB used with the plat- not offering explicit support for structured vocab-
form: the INSTANCE - OF relation is required to be ularies, can approximate them by combining two
able to identify instances, classes and properties of its features: tagsets and constraints. Constraints
within the ontology (). Com- allow to show a certain attribute of an annotation
monly rdf:type is used here, but e.g. the RDF ver- only when another attribute has a specific value,
sion of Wikidata uses a different IRI. Addition- e.g. to show a COUNTRY attribute only if the TYPE
5 6
https://www.w3.org/TR/rdf-schema/ https://www.w3.org/2004/02/skos/
131property of the entity has the value location. Tagsets References
can then be used to control which values are ac- Matthijs Brouwer, Hennie Brugman, and Marc Kemps-
ceptable for the entity type or country properties. Snijders. 2017. MTAS: A Solr/Lucene based Multi
However, WebAnno has no support for search. Tier Annotation Search solution. In Selected papers
from the CLARIN Annual Conference 2016, Aix-en-
AlvisAE (Papazian et al., 2012) supports linguis- Provence, 26–28 October 2016, 136, pages 19–37.
tic and semantic annotations and can connect them Linköping University Electronic Press, Linköpings
to a structured vocabulary. However, it does not Universitet.
offer the ability to search over annotations and con-
Richard Eckart de Castilho, Éva Mújdricza-Maydt,
sequently also has no ability to make use of the Seid Muhie Yimam, Silvana Hartmann, Iryna
vocabulary structure in such queries. Gurevych, Anette Frank, and Chris Biemann. 2016.
CROMER (Girardi et al., 2014) is a tool for en- A Web-based Tool for the Integrated Annotation of
Semantic and Syntactic Structures. In Proceedings
tity and event coreference annotation. It allows of the workshop on Language Technology Resources
to annotate and link entity mentions to entities de- and Tools for Digital Humanities (LT4DH) at COL-
fined in a knowledge base and in this way to create ING 2016, pages 76–84, Osaka, Japan.
implicit cross-document coreference links. It also
Oli Christ. 1994. A modular and flexible architecture
offers a simple string-based search to locate poten- for an integrated corpus query system. In Proceed-
tial entity mentions. However, it does not allow ings of COMPLEX’94 3rd Conference on Computa-
to perform further searches involving the created tional Lexicography and Text Research, pages 23–
annotations or the structure of the vocabulary. 32, Budapest, Hungary.
NeuroCurator (O’Reilly et al., 2017) is a collabo- David Ferrucci and Adam Lally. 2004. UIMA: An
rative framework for annotating experiment param- Architectural Approach to Unstructured Information
Processing in the Corporate Research Environment.
eters in scientific papers using an ontology-driven
Natural Language Engineering, 10(3-4):327–348.
approach. It is rather an interactive knowledge
base population tool than a tool for cross-document Christian Girardi, Manuela Speranza, Rachele Sprug-
coreference. Queries over the texts that make use noli, and Sara Tonelli. 2014. CROMER: a Tool
for Cross-Document Event and Entity Coreference
of the information of the KB are not possible. . In Proceedings of the Ninth International Con-
ference on Language Resources and Evaluation
7 Conclusion and Future Work (LREC-2014), pages 3204–3208, Reykjavik, Iceland.
ELRA.
We have introduced a knowledge-supported search Jan-Christoph Klie, Michael Bugert, Beto Boullosa,
mechanism into a generic text annotation tool, Richard Eckart de Castilho, and Iryna Gurevych.
INCEpTION, to support entity linking and cross- 2018. The INCEpTION Platform: Machine-
Assisted and Knowledge-Oriented Interactive Anno-
document coreference annotation tasks. The need tation. In Proceedings of the 27th International Con-
for such a functionality was motivated using three ference on Computational Linguistics - COLING
scenarios, all of which are facilitated using the 2018, pages 5–9, Santa Fe, New-Mexico, USA.
knowledge-supported search mechanism. In future Christian O’Reilly, Elisabetta Iavarone, and Sean L.
work, we plan to further extend the search mecha- Hill. 2017. A Framework for Collaborative Curation
nism, e.g. allowing to search over annotation sug- of Neuroscientific Literature. Frontiers in Neuroin-
gestions provided by the recommender framework formatics, 11(27):1–16.
of INCEpTION and by further enhancing the abil- Frèdèric Papazian, Robert Bossy, and Claire Nèdellec.
ity to match against information contained in the 2012. AlvisAE: a collaborative Web text annotation
knowledge bases. editor for knowledge acquisition. In Proceedings
of the Sixth Linguistic Annotation Workshop, pages
149–152, Jeju, Republic of Korea. Association for
Acknowledgments Computational Linguistics.
Valentin Tablan, Kalina Bontcheva, Ian Roberts, and
We thank Wei Ding, Peter Jiang, Marcel de Boer Hamish Cunningham. 2015. Mı́mir: An open-
and Michael Bugert for their valuable contribu- source semantic search framework for interactive in-
tions. This work was supported by the German formation seeking and discovery. Web Semantics:
Research Foundation under grant No. EC 503/1-1 Science, Services and Agents on the World Wide Web,
30(0):52–68.
and GU 798/21-1 (INCEpTION).
132You can also read

















































