WASP WINTER CONFERENCE 2022 - Poster Catalogue SOFTWARE - Wallenberg AI ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

WASP WINTER CONFERENCE 2022 Poster Catalogue SOFTWARE

WASP WINTER CONFERENCE 2022 POSTER CATALOGUE 4/4 SOFTWARE Author Pages Andersson, Pontus.......................................................................................................................164 A+B Couderc, Noric............................................................................................................................... 165 A+B Etemadi, Khashayar.....................................................................................................................166 A+B Gissurarson, Matthías Páll....................................................................................................... 167 A+B Hrusto, Adha................................................................................................................................... 168 A+B Nilsson, Alexander....................................................................................................................... 169 A+B Riouak, Idriss.................................................................................................................................. 170 A+B Rizwan, Momina............................................................................................................................171 A+B Spanghero, Marco........................................................................................................................172 A+B Tiwari, Deepika.............................................................................................................................. 173 A+B Waldemarson, Gustaf................................................................................................................. 174 A+B Zhang, Long.................................................................................................................................... 175 A+B

SOFTWARE Page 164 A Andersson, Pontus Lund University / NVIDIA Evaluating Differences Between Rendered Images and Videos In rendering research and development, it is important to have a formalized way of visualizing and communicating how and where errors occur when rendering with a given algorithm. Such evaluation is often done by comparing the test image or video to a ground-truth reference. We have presented a tool for comparing both low and high dynamic range images. Our tool is based on a perception-mo- tivated image metric. Now, we are exploring how to extend that metric to also convey the differences in rendered videos, an extension that poses several challenges, as the presence of perceptual effects increase significantly when we consider spatiotemporal stimuli.

SOFTWARE Page 164 B Andersson, Pontus Lund University / NVIDIA Evaluating Differences Between Rendered Images and Videos Pontus Andersson, Lund University Centre for Mathematical Sciences Abstract In rendering research and development, it is important to have a formalized way of visualizing and communicating how and where errors occur when rendering with a given algorithm. Such evaluation is often done by comparing the test image or video to a ground-truth reference. We have presented a tool for comparing both low and high dynamic range images. Our tool is based on a perception- motivated image metric. Now, we are exploring how to extend that metric to also convey the differences in rendered videos, an extension that poses several challenges, as the presence of perceptual effects increase significantly when we consider spatiotemporal stimuli. Image Differences: ꟻLIP [1, 2] Video Differences: ? Evaluates and visualizes the perceived differences Sequences of images are the main focus in rendering. observed when alternating between images Importantly, errors that are imperceptible in static images can be noticeable in videos, and vice versa. - Removes unperceivable details (spatial filtering) Use cases for a video metric: - Perceptually uniform color space - Replace user studies and other expensive video comparisons - Enhancing edge and point errors - Objective assessment of video generation algorithms - Preferred viewing protocol in rendering - Cost functions in, e.g., deep-learning-based techniques Challenges in developing a video metric: - Motion: How do we perceive errors on moving objects? - Flicker: How can we determine if flickering is present? - Complexity: A second of video could contain 240+ images - Evaluation: Flipping not possible. What can we do instead? Our research targets a new perception-based video metric: User study: How well does the error map ꟻLIP @ GitHub - Current subproject: Temporal Edge Detection (TED): correspond to the errors you perceive? Results showed that ꟻLIP corresponds - Estimate the temporal edge detection filters in human vision significantly better to the perceived error than any of the other metrics in the study. - This has been done for spatial edge detection filters [3] Through an extension, ꟻLIP handles both - Result used to compare perceptible flicker between videos high and low dynamic range imagery [2] References 1. Andersson, P., Nilsson, J., Akenine-Möller, T., Oskarsson, M., Åström, K., & Fairchild, M. D. (2020). ꟻLIP: A Difference Evaluator for Alternating Images. Proceedings of the ACM on Computer Graphichs and Interactive Techniques, 3(2), 15:1-15:23. 2. Andersson, P., Nilsson, J., Shirley, P., & Akenine-Möller, T. (2021). Visualizing Errors in Rendered High Dynamic Range Images. In Eurographics Short Papers. 3. McIlhagga, W. (2018). Estimates of Edge Detection Filters in Human Vision. Vision Research, 153, 30-36.

SOFTWARE Page 165 A Couderc, Noric Lund University Building an data-structure selection tool for Java programs Writing programs require using both algorithms and data-structures. Most programming languages provide implementations for some ”classical” data-structures (lists, maps, and sets). The developer chooses which implementations to use. Unfortunately, programmers are not that good at picking the data-structure that minimizes runtime. There is existing work which uses machine learning to provide suggestions to C++ developers. Adap- ting this work to Java poses new challenges. In this poster, we evaluate how effective this tool is on Java programs.
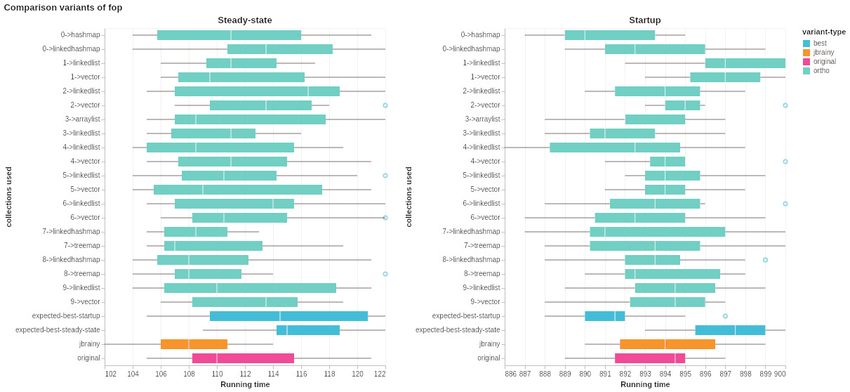
SOFTWARE Page 165 B Couderc, Noric Lund University Noric Couderc, Lund University I used machine learning to make Java programs faster, It didn't really work My tool doesn't improve much over the original, exhaustive search does slightly better Exhaustive search finds a massive optimization, but my tool misses it My tool doesn't improve over the original, neither does exhaustive search My tool does slightly better than exhaustive search on steady state performance My tool does worse on startup than the original program This is ok I t' s a re p ro d u cti o n stu d y! Pa p e r wi th d e ta i ls co m i n g so o n !

SOFTWARE Page 166 A Etemadi, Khashayar KTH Estimating the Potential of Program Repair Search Spaces with Commit Analysis The most natural method for evaluating program repair systems is to run them on bug datasets, such as Defects4J. Yet, usingthis evaluation technique on arbitrary real world software projects requires heavy configuration. In this paper, we propose a newmethod, which is purely static, to evaluate the breadth of the search space of repair approaches. Our key insight is to encode thesearch spaces of repair approaches by specifying the repair strategies they employ. Next, we use the specifications to check whetheror not past commits lie in repair search spaces. For a repair approach, including many human-written past commits in its searchspace indicates its potential to generate useful patches. We implement our evaluation method in a tool, called LighteR. LighteRgets a Git repository as input and outputs a list of commits whose corresponding source code changes lie in the search spaces ofrepair approaches. Using LighteR, we conduct a study on 55,309 commits from the history of 72 Github repositories and showthat the precision and recall of LighteR are 77% and 92%, respectively. Overall, our experiments show that our novel method isboth lightweight and effective to study the search spa- ce of program repair approaches.

SOFTWARE Page 166 B Etemadi, Khashayar KTH Estimating Program Repair Potential with Commit Analysis Khashayar Etemadi, khaes@kth.se Theoretical Computer Science Department @ EECS Context: Running program repair tools is usually very costly [1]. Therefore, it is not an efficient way to assess the strength of program repair tools. Contribution: We propose a new purely static method, which is purely static, to evaluate the breadth of the search space of repair approaches. Our key insight is to encode the search spaces of repair approaches by specifying the repair strategies they employ. Next, we use the specifications to check whether or not past human-made commits lie in repair search spaces. Our method is implemented in LighteR, with precision and recall of 77% and 92%, respectively. We find that 1.35% of 55,309 commits from 72 projects lie in search spaces of eight considered tools. Overview of LighteR’s Approach Identifying Repair-space Commits: Sample Strategy Specification for GenProg ● Uses GumTree [2] to extract AST actions. ● Uses Coming [3] to match actions with specification. ● Uses post-matching rules to discard non- synthesizable patches. References Considered Tools: 1- Durieux, Thomas, et al. "Empirical review of Java program repair tools: A large-scale experiment on 2,141 bugs and 23,551 repair Arja, Cardumen, Elixir, GenProg, jMutRepair, Kali, attempts." Proceedings of the 2019 27th ACM Joint Meeting on Nopol, NPEfix European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 2019. 2- Falleri, Jean-Rémy, et al. "Fine-grained and accurate source code Actionable Implications: differencing." Proceedings of the 29th ACM/IEEE international conference on Automated software engineering. 2014. ● Prototyping of New Repair Approaches by 3- Martinez, Matias, and Martin Monperrus. "Coming: A tool for mining Researchers change pattern instances from git commits." 2019 IEEE/ACM 41st International Conference on Software Engineering: Companion ● Evaluation of the Potential Value of Using Proceedings (ICSE-Companion). IEEE, 2019. Program Repair by Practitioners
SOFTWARE Page 167 A Gissurarson, Matthías Páll Chalmers Using Typed-Holes in Haskell for Property-Based Automatic Program Repair This poster presents the use of typed-hole synthesis in PropR, a property-based automatic repair tool for Haskell that uses genetic programming to automatically repair Haskell programs. Haskell pro- grams are often annotated with very specific types and come with a large suite of property-based tests in addition to unit tests. Using those properties and unit tests, we can isolate the parts of the code involved in a failing test case, and then we can leverage the available type information by integrating with the valid hole-fit synthesis in the GHC compiler to do accurate synthesis of well-typed programs as possible repairs for the fault-involved expressions.

SOFTWARE Page 167 B Gissurarson, Matthías Páll Chalmers Using Typed-Holes in Haskell for Property-Based Automatic Program Repair Matthías Páll Gissurarson, Chalmers University of Technology Department of Computer Science and Engineering Abstract We present the use of typed-hole synthesis in PropR, a property-based automatic repair tool for Haskell that uses genetic programming to automatically repair Haskell programs. PropR: Property-Based The Test-Localize- Automatic Program Repair Synthesize-Rebind Loop Haskell programs are often annotated with very specific types PropR is based on a Test-Localize-Synthesize-Rebind loop and come with a large suite of property-based tests in (TLSR), shown in the figure to the right [1]. We begin by addition to unit tests. Using those properties and unit tests, parsing the source code and discovering properties1, as we can isolate the parts of the code involved in a failing test defined by the name and/or type of the functions in the case, and then we can leverage the available type information provided source ①. By inspecting these properties ②, we by integrating with the valid hole-fit synthesis in the GHC determine top-level targets for repair. We rebind these to compiler to do accurate synthesis of well-typed programs as mutable expressions (making no changes initially, keeping possible repairs for the fault-involved expressions [1]. the original target intact) ③. We test the properties using QuickCheck [2] to determine which ones fail ④, and use the generated counter-examples to determine the fault- involved sub-expressions in the targets ⑤. Then we perforate the targets by replacing each fault-involved sub- expression with a typed-hole2 ⑥. By using GHCs built-in valid hole-fit3 synthesis in conjunction with a hole-fit plugin, we synthesize candidate fixes in place of these holes based on their type ⑦ and mined expressions from the source code. We then evaluate the candidates by replacing the holes in the targets with candidate fixes ⑧ and apply genetic search to select ⑨ potential fixes based on how well the program would perform on the test-suite if they were to be applied. After selection, we apply the selected fixes to the program ⑩ by replacing sub-expressions in the targets using the selections. If all properties are now satisfied, we've found a repair, and output it as a diff ⑪, otherwise we apply the current fixes ③ to the program and repeat until we succeed or run out of search budget [1]. 1 Properties are testable assertions in the code. They can either be unit-tests (i.e. an input-output pair) or more generic, e.g. prop_fIsPositive n = (f n) > 0, is tested by generating random n and checking that the property holds. When QuickCheck finds a value for which the property does not hold, it shrinks it (i.e. minimizes it) and returns it as a counter-example [2]. 2A typed-hole is a placeholder value for unknowns in code, and References include a type inferred from the context and other constraints 1. Gissurarson, M. P., Leonhard, A., Panichella, A., Deursen, A., Sands, D. 2022. PropR: based on where it is placed in the source code. A typed-hole is Property-Based Automatic Program Repair. To be published at the 44th International represented by an underscore (_) in Haskell source-code. Conference on Software Engineering (ICSE 2022), Pittsburgh, PA, USA. 2. Claessen, K., & Hughes, J. 2000. QuickCheck: a lightweight tool for random testing of Haskell programs. In Proceedings of the fifth ACM SIGPLAN international conference 3A valid hole-fit is an expression that matches the type of the on Functional programming (ICFP '00), Montreal, Canada. hole. In GHCs, these can be synthesized by the compiler, either 3. Gissurarson, M. P. 2018. Suggesting Valid Hole Fits for Typed-Holes (Experience Report). In Proceedings of the 11th ACM SIGPLAN International Haskell Symposium a simple fit (e.g. sum for (_ :: [Int] -> Int)) or a more complex (Haskell ’18), St. Louis, MO, USA. refinement hole-fit (e.g. (foldl (+) :: [Int] -> Int) [3].
SOFTWARE Page 168 A Hrusto, Adha Lund University Closing the Feedback Loop in DevOps Through Autonomous Monitors in Operations DevOps represent the tight connection between development and operations. To address challenges that arise on the borderline between development and operations, we conducted a study in collabo- ration with a Swedish company responsible for ticket management and sales in public transportation. The aim of our study was to explore and describe the existing DevOps environment, as well as to identify how the feedback from operations can be improved, specifically with respect to the alerts sent from system operations. Therefore, we design a solution to improve the alert management by opti- mizing when to raise alerts and accordingly introducing a new element in the feedback loop, a smart filter. Moreover, we implemented a prototype of the proposed solution design using a hybrid method that combines rule-based and unsupervised machine learning for operations data analysis.
SOFTWARE Page 168 B Hrusto, Adha Lund University Closing the Feedback Loop in DevOps Through Autonomous Monitors in Operations Adha Hrusto, Lund University Department of Computer Science Abstract DevOps represent the tight connection between development and operations. To address challenges that arise on the borderline between development and operations, we conducted a study in collaboration with a Swedish company responsible for ticket management and sales in public transportation. The aim of our study was to explore and describe the existing DevOps environment, as well as to identify how the feedback from operations can be improved, specifically with respect to the alerts sent from system operations. Therefore, we design a solution to improve the alert management by optimizing when to raise alerts and accordingly introducing a new element in the feedback loop, a smart filter. Moreover, we implemented a prototype of the proposed solution design using a hybrid method that combines rule-based and unsupervised machine learning for operations data analysis. Research approach Selected Results Our study is a problem-driven Problem conceptualization. design science approach as We identified alert targeting, shown in Figure 1. We explored signal to noise optimization, how the general problem, of and system interoperability incorporating feedback from as being three important operations in the development, problem instances of the manifests as a problem instance general alert flooding in the industrial context under problem in the feedback from study. For that purpose, we operations to development. Figure 2 Overview of the proposed solution design conducted interviews and Solution design. We designed a solution for more effective performed observations in the processing of data available through the monitoring system in case company to identify and operations by introducing a smart filter in the feedback loop as articulate the main problems on Figure 1 Overview of the Design Science approach shown in Figure 2. The smart filter is a unique technical solution which to focus further improvements. In the problem that combines various systems’ and applications’ metrics for conceptualization step, we identified three problem instances learning advanced alert rules (see Table 1). related to alert flooding, which is a phenomenon that appears in Prototype implementation. We performed a pilot a case of a high number of alerts that are not properly managed. implementation of the proposed solution in the case environment We provided a conceptual design for only one of the problem as a proof of concept for further work. In the implementation of instances, alert flooding as an optimization problem since it the prototype solution, we used unsupervised anomaly detection causes the highest information overflow in the feedback loop. throughout the labeling process of unlabeled operations data Moreover, alongside the proposed solution design, we while also considering the service vulnerability and observed implemented a prototype instance to get a better metrics frequency (see Table 1). Further, for generating new understanding of the opportunities of the available operations advanced alert rules, a supervised tree-based machine learning data, its type, and characteristics as well as the constraints of technique was used. the context. We partially evaluated the implemented solution Table 1 Overview of the selected data, service vulnerabilities and desired decision rules using the limited data set for implementation of the baseline Selected CPU Num. of failed Num. of Num. of dep. Http 4xx Http 5xx Num. of Response metrics Time requests exceptions failures errors errors requests time anomaly detection method in a prototype environment. Services with Service B – buying Service G – service for Service P –> bridge to Service M –> main known tickets on vending validating selected an external payment service for ticketing vulnerabilities machines locations service CASE DESCRIPTION Example of a IF num_of_failed_requests_SG > threshold_1 AND response_time_SB > threshold_2 AND num_ decision rule of_Http500_SB > threshold_3 THEN send_notification The system under study is a backend system of an application for ticketing and payments used in public transportation. It is a Evaluation. We also implemented cloud-based system with a microservice architecture that multivariate anomaly detection consists of 20 services, developed using Microsoft tools and (MAD) to validate our prototype by services. The health status of each service is monitored using comparing it with the pure the Azure Monitor through which various performance metrics unsupervised ML technique for and logs are available to use for alerting and visualization. detecting outliers, representing alerts, in multivariate unlabeled data set. The results revealed that the MAD trained model does not scale References very well the number of predicted alerts, thus, producing the same 1. Adha Hrusto, Per Runeson, and Emelie Engström (2021). level of noise and several alert Closing the Feedback Loop in DevOps Through floods. On the other hand, the smart Autonomous Monitors in Operations. SN Computer filter produces less noise around Science 2, 6 (Aug. 2021). actual failures and more accurately https://doi.org/10.1007/s42979-021-00826-y predicts isolated alerts in case of Figure 3 Distribution of raised alerts in the test data short system’s glitches.
SOFTWARE Page 169 A Nilsson, Alexander Lund University Timing-Attacks on Post-Quantum Cryptographic Primitives Vulnerabilities found in crypto algorithms “HQC” and “BIKE” Next-generation public-key encryption algorithms “HQC” and “BIKE”, which are code-based key encapsulation mechanisms, share a vulnerability due to the use of Rejection Sampling in their decaps- ulation mechanisms. An attacker can use this vulnerability to craft special messages by which a complete secret-key recove- ry can be achieved. The time-complexity of this attack is low enough to be practically managed within a couple of days, in an ideal lab scenario.
SOFTWARE Page 169 B Nilsson, Alexander Lund University Timing-Attacks on Post-Quantum Cryptographic Primitives Alexander Nilsson, Lund University Dept. Electrical and Information Technology, Faculty of Engineering LTH Vulnerabilities found in crypto algorithms “HQC” and “BIKE” Next-generation public-key encryption algorithms “HQC” and “BIKE”, which are code-based key encapsulation mechanisms, share a vulnerability due to the use of Rejection Sampling in their decapsulation mechanisms. An attacker can use this vulnerability to craft special messages by which a complete secret-key recovery can be achieved. The time-complexity of this attack is low enough to be practically managed within a couple of days, in an ideal lab scenario. Post-Quantum Cryptography Rejection Sampling Quantum computers threaten to break most of the encryption The Hamming Weight ℎ ( ) denotes the number of set bits in use over the internet today. Therefore, new algorithms are in the bit vector . needed. Both BIKE and HQC need to generate uniformly random error NIST is currently in an open process to standardize a small vectors , where ℎ = , where T is a constant parameter. number of new public-key primitives for encryption and digital signatures. Among the few remaining candidates are Rejection sampling does this by iteratively generating random bit the code-based key encapsulation mechanisms “HQC” positions and rejecting invalid positions. This is an efficient way of and “BIKE”. ensuring uniform randomness of specific weights. It is, however, very hard to implement it such that the run-time, KEM/PKE Scheme Type Vulnerable to or number of samplings, of the algorithm does not depend on its Rejection input (such as the seed for the random number generator). Sampling Timing Attack Because of this the input to the rejection sampling algorithm must Finalists be comprised entirely of public values, or be derived from entirely Classic McEliece Code-based NO public values. Kyber Lattice NO NTRU Lattice NO SABER Lattice NO Alternates BIKE Code-based YES FrodoKEM Lattice NO HQC Code-based YES NTRU Prime Lattice NO SIKE Supersingular NO elliptic curve isogeny The Vulnerability [ref] An important property in code-based schemes is the malleability References of the ciphertexts. This means that it is inherently possible to slightly modify the ciphertext by a small amount and still decrypt to 1. Qian Guo, Thomas Johansson, and Alexander Nilsson. "A key-recovery timing the very same plaintext. attack on post-quantum primitives using the Fujisaki-Okamoto transformation and its application on FrodoKEM." Annual International Cryptology Conference. Springer, Cham, 2020. This is an undesired property of highly secure KEM/PKE 2. Clemens Hlauschek, Norman Lahr, Robin Leander Schröder, Qian Guo, schemes, and the most common way to resolve the issue has Thomas Johansson, and Alexander Nilsson, ”Key recovery attacks on BIKE been shown to open up PKE/KEM schemes to hitherto unknown and HQC, due to Rejection Sampling” timing attacks. [1] 3. Alexander Nilsson, Thomas Johansson, and Paul Stankovski. "Error Amplification in Code-based Cryptography." IACR Transactions on Cryptographic Hardware and Embedded Systems (TCHES) 2019.1 (2018): In the current work [2] we show how to adapt the known attack to 238-258. apply also to the Rejection Sampling algorithm employed by BIKE 4. Qian Guo, Thomas Johansson, and Paul Stankovski. ”A key recovery attack on MDPC with CCA security using decoding errors”. ASIACRYPT 2016, Springer, and HQC. In this work we rely on techniques from [3] and [4]. Heidelberg, December 2016
SOFTWARE Page 170 A Riouak, Idriss Lund University A Precise Framework for Source-Level Control-Flow Analysis Static program analysis plays a fundamental role in software development and may help developers detect subtle bugs such as null pointer exceptions or security vulnerabilities. We present IntraCFG, a language-independent framework for constructing precise intraprocedural control-flow graphs (CFGs) superimposed on the Abstract Syntax Tree (AST). Source-level dataflow analysis permits easier integration with the IDEs and Cloud tools since the reports can be directly linked to the source code and do not require producing the Intermediate Representation (IR).
SOFTWARE Page 170 B Riouak, Idriss Lund University A Precise Framework for Source-Level Control- Flow Analysis Idriss Riouak*, Christoph Reichenbach*, Görel Hedin*, and Niklas Fors *idriss.riouak, christoph.reichenbach, gorel.hedin, and niklas.fors (@cs.lth.se) Department of Computer Science, Lund University, Sweden DESCRIPTION Static program analysis plays a fundamental role in software development and may help developers detect subtle bugs such as null pointer exceptions or security vulnerabilities. We present IntraCFG, a language-independent framework for constructing precise intraprocedural control-flow graphs (CFGs) superimposed on the Abstract Syntax Tree (AST). Source-level dataflow analysis permits easier integration with the IDEs and Cloud tools since the reports can be directly linked to the source code and do not require producing the Intermediate Representation (IR). OUR APPROACH EXPERIMENTS We build the CFGs on top of the AST using Reference We compared the results of IntraJ with: Attribute Grammars (RAGs). Highlights of our approach: • JastAddJ–Intraflow (JJI): a RAG based framework • Handles implicit control flow • SonarQube: a highly tuned static analyser • Fully declarative specification using JastAdd2 We used as benchmarks: • Overcomes the limitations of an earlier RAG framework, eliminating misplaced and redundant nodes in the constructed CFGs. 33K LOC 49K LOC 95K LOC 97K LOC FRAMEWORK • CFG size reduced by 30-40% # Nodes in CFGs # Edges in CFGs 400000 350000 300000 250000 200000 150000 100000 50000 0 ANTLR PMD JFC FOP ANTLR PMD JFC FOP IntraJ JastAddJ-Intraflow We compared the precision and the performance of IntraJ against SonarQube by implementing two dataflow analyses: • Dead Assignment Analysis [DAA] • Null Pointer Analysis [NPA] DAA INTERFACE ASTNODE CFGRoot MethodDecl, ConstructorDecl, … NPA CFGSupport WhileStmt, IfStmt, … CFGNode All the ASTNodes that might appear in the CFGs. Dead Assignment Analysis Null Pointer Analysis ANTRL PMD JFC FOP ANTRL PMD JFC FOP 40 The IntraCFG interfaces provide client APIs for the 20 18 SonarQube 35 16 Seconds 30 successor and predecessor relations, and default 14 12 25 20 Baseline behaviour that simplifies constructing CFGs for a 10 8 15 6 10 specific language. We used IntraCFG to construct 4 2 0 IntraJ 5 0 high-precision CFGs for Java 7, extending the ExtendJ ANTRL PMD JFC FOP ANTRL PMD JFC FOP Java compiler. • Higher precision and better overall performance CONCLUSIONS & FUTURE WORK IntraCFG is a language-independent RAGs We plan to: framework that overcomes the limitation of • extend the support of IntraJ to Java 8 the earlier approaches: • extend IntraCFG to construct inter-procedural CFGs • High-Precision • Concise CFG specification • ≥30% fewer nodes • Competitive to SonarQube
SOFTWARE Page 171 A Rizwan, Momina Lund University A Domain-Specific language to express dynamic functional safety rules Ensuring functional safety has become more challenging as robots work in a dynamic and unpre- dictable environment. A functionally safe autonomous system performs correctly given a set of inputs and if it receives an unknown input, then it fails predictably. While making a robot safe, sometimes we over-constrain the system that makes the robot incapable of doing anything useful. For example, turning off the robot whenever something unexpected happens is not a good recovery strategy. Spe- cifying static safety constraints is a conservative approach. We develop a domain-specific language (DSL) that facilitates the user to specify dynamic safety specifications. A DSL allows us to reason at an abstract level making it easier to handle abstract domain-specific concerns like functional safety. Domain-specific modeling also allows us to validate if a system behaves as expected.
SOFTWARE Page 171 B
Rizwan, Momina
Lund University
A static safety constraint hinders a robot to
do anything useful!
A Domain-Specific Language to express dynamic robot safety
rules
Momina Rizwan, Christoph Reichenbach and Volker Krueger
Motivation & Research Goal Why use a Domain Specific Language?
Ensuring functional safety has become more challenging as robots work in a
• To reason about domain specific concepts that are easier to understand by
dynamic and unpredictable environment.
non-experts [2].
“A functionally safe autonomous system performs correctly given a set of • One can do domain specific static analysis and report errors early.
inputs and if it can’t, it fails predictably.” • Better error reporting.
Static safety rules over-constrain the system that makes the robot incapable
of doing anything useful. Turning off the robot whenever something
A code snippet (Syntax is in the style of Ulrik’s
unexpected happens is not a good strategy. In our research, we try to
work [1])
replicate the work by [S.Adam et. al.] [1] and add dynamic safety rules.
action moveBack ;
action lowSpeed ;
action increaseSpeed ;
Safety scenarios const maxSpeed = 0.5 m/s
const reasonabletilt = 10 deg
const maxtilt = 20 deg
1. Avoid damaging jerks while crossing uneven terrain (IMU) input orientation = topic
imu_information
entity imuSensorSystem
2. Handle ramps in an industrial setting (IMU) {
3. Handle partially closed doors (LIDAR) gentleSlope :
orientation.pitch() not in reasonabletilt
4. Robot arm should never hit anything (Force Sensor) for 4.0 sec;
steepRamp :
orientation.pitch() not in maxtilt
Dynamic recovery strategy follow the rule: }
entity driveSystem {
maxspeedExceeded :
“As soon as the input sensor reading is in safe-range, continue the task.” linearSpeed > maxSpeed for 2.0 sec ;
}
if imuSensorsystem.gentleSlope and driveSystem.moving
then { increaseSpeed ;} ;
• When the ramp slope is gentle, slow down, go back and find a new path if imuSensorsystem.steepRamp and driveSystem.moving
• When the ramp slope is steep, speed up a bit so it can cross the ramp then { lowSpeed ; moveBack; } ;
0
Safety Node As a Filter
*
References
gazebo_plugin
[1] S. Adam, M. Larsen, K. Jensen, and U. P. Schultz, “Rule-based dynamic
/cmd_vel
/gazebo_sim
safety_node move_base_node
/move_base_node /unfil_cmd_vel /move_base safety monitoring for mobile robots,” Journal of Software Engineering for
/cmd_vel Robotics, vol. 7, no. 1, pp. 121–141, 2016.
/tf
move_base_node sensor_info_node /tf
mir_bridge
[2] A. Nordmann, N. Hochgeschwender, and S. Wrede, “A survey on
/move_base_node
/scan
/f_scan
/tf
/amcl /mir_bridge domain-specific languages in robotics,” in International conference
/b_scan
on simulation, modeling, and programming for autonomous robots,
pp. 195–206, Springer, 2014.SOFTWARE Page 172 A Spanghero, Marco KTH Attacking and protecting GNSS receivers Precise time and position obtained by GNSS receivers is an integral part of a wide gamut of strategic infrastructure. Demonstrations of attacks highlight the vulnerability of current civilian GNSS signals. Advanced countermeasures using external information and receiver properties can be used to detect advanced spoofer and recover from attacks. The poster describes both aspects, with a specific outlook on time focused receivers.
SOFTWARE Page 172 B Spanghero, Marco KTH Attacking and protecting GNSS receivers Marco Spanghero, KTH Royal Institute of Technology Networked Systems Security (NSS) group, www.eecs.kth.se/nss Main advisor: Panos Papadimitratos Motivation & Research Goals Precise time and position obtained by Global Navigation Satellite System (GNSS) receivers are an integral part of a wide gamut of strategic infrastructure. Demonstrations of attacks highlight the vulnerability of current civilian GNSS signals. Advanced countermeasures using external information and receiver properties can be used to detect advanced spoofer and recover from attacks. Specifically, integration of different time sources can tackle various spoofing scenarios, from simple cases of simulation to advanced signal lift-off. Time based attack detection GNSS Replay/Relay attacks We seek a general-purpose framework that enables validation of Replay of GNSS signals will be of increasing importance with the the GNSS time information [1]. Fusion of multiple (secure) upcoming shift to authenticated signals [4]. Extending from simple network time sources [2] provides online verification, using meaconing to over-the-network-meaconing allows to break free different off-the-shelf technologies. of the limitations imposed by a physical connection. Local high-precision clocks can be leveraged as an ensemble to guarantee enhanced holdover under attack even when connectivity is not available, reducing the remote timing service polling frequency [3]. Selected results: Meaconing of mobile and static targets was successful over consumer 4G networks, by either replaying the entire spectrum Combination of multiple time sources is not trivial and requires (bandwidth intensive) or by surgically replaying navigation knowledge of the source characteristics: fusion can be possible messages using meacon and recreate strategies (future proof with stochastic filtering, providing statistical indicators of GNSS against authenticated navigation messages). time misbehavior (i.e. Kalman filtering). Selected results: • Detection based on opportunistic WiFi beacons with a 25µs threshold • Multi-technology fusion framework for GNSS attack detection • Local oscillator ensemble-based detection with 0.3µs threshold and dual frequency/phase indicator for advanced attack detection References [1] K. Zhang, M. Spanghero, and P. Papadimitratos, “Protecting GNSS-based Services using Time Offset Validation,” in 2020 IEEE/ION Position, Location and Navigation Symposium (PLANS), Portland, Oregon, April 2020. [2] M. Spanghero, and P. Papadimitratos, “Detecting GNSS misbehaviour with high- We developed a future-proof, flexible precision clocks. WiSec 2021”, in Proceedings of the 14th ACM Conference on and versatile GNSS testing platform. Security and Privacy in Wireless and Mobile Networks, Virtual. [3] M. Spanghero, K. Zhang, and P. Papadimitratos, “Authenticated time for Our modular prototype will enable detecting GNSS attacks,” in Proceedings of the 33rd International Technical Meeting research on security enhanced signals, of the Satellite Division of the Institute of Navigation, ION GNSS+ 2020, Virtual allowing mobile scenario testing without [4] M. Lenhart, M. Spanghero, and P. Papadimitratos, “Relay/replay attacks on gnss signals,” in Proceedings of the 14th ACM Conference on Security and Privacy in requiring any regulatory permission. Wireless and Mobile Networks, Virtual.
SOFTWARE Page 173 A Tiwari, Deepika KTH Tests from Production Traces Context: End users may interact with software in ways that are not well-tested. Contribution: We propose to monitor software in production, in order to automatically improve the effectiveness of test suites. The generated tests can complement developer-written tests, and represent real usages of the application in production.
SOFTWARE Page 173 B Tiwari, Deepika KTH  Tests From Production Traces Deepika Tiwari deepikat@kth.se Division of Software and Computer Systems, School of Electrical Engineering and Computer Science Context: End users may interact with software in ways that are not well-tested [1]. Contribution: We propose to monitor software in production, in order to automatically improve the effectiveness of test suites. The generated tests can complement developer-written tests [2], and represent real usages of the application in production [3]. PANKTI: Automated unit test generation [2] ● Generate tests that improve the test quality of 53 weakly-tested methods in 3 open-source Java applications AutoGraphQL: Tests from GraphQL requests [3] ● Find 8 schema faults in 1 industrial application ● Improve coverage in 1 open-source application Future work ● Monitor the invocation of methods within target methods in production [4] ● Use the collected data for the automated generation of mocks References 1. Wang, Q., Brun, Y., & Orso, A. (2017, March). Behavioral execution comparison: Are tests representative of field behavior?. In 2017 IEEE International Conference on Software Testing, Verification and Validation (ICST). IEEE. 2. Tiwari, D., Zhang, L., Monperrus, M., & Baudry, B. (2021). Production Monitoring to Improve Test Suites. IEEE Transactions on Reliability. 3. Zetterlund, L., Tiwari, D., Monperrus, M., & Baudry, B. (2022, April). Harvesting Production GraphQL Queries to Detect Schema Faults. In 2022 IEEE International Conference on Software Testing, Verification and Validation (ICST). IEEE. 4. Zhang, L., Tiwari, D., Morin, B., Baudry, B., & Monperrus, M. (2021). Automatic Observability for Dockerized Java Applications. Submitted to IEEE Transactions on Dependable and Secure Computing.
SOFTWARE Page 174 A Waldemarson, Gustaf Lund University / Arm Efficient GPU Programming for Visual and Autonomous Software Systems This project aims to improve the efficiency of parallel programming of GPUs in heterogeneous ar- chitectures and environments, potentially leading to new frameworks and algorithms for, e.g., more realistic lighting in graphics systems or higher performance computing in real-time software systems. The aim is to enhance or produce programming tools that can be used to process large datasets from e.g. computer vision, deep learning, data visualization, or other graphics rendering or systems by using the potential available in modern platforms that contain GPUs and other accelerators.
SOFTWARE Page 174 B
Waldemarson, Gustaf
Lund University / Arm
Efficient GPU Programming for Visual and
Autonomous Software Systems
Gustaf Waldemarson Ind. PhD, Arm Ltd and Lund University
Dept. of Computer Science, Lund University Graphics Group
Supervisors: Michael Doggett (LU) and Simone Pellegrini (Arm Ltd)
Motivation & Research Goals
This project aims to improve the efficiency of parallel programming of GPUs in heterogeneous architectures and environments,
potentially leading to new frameworks and algorithms for, e.g., more realistic lighting in graphics systems or higher performance
computing in real-time software systems. The aim is to enhance or produce programming tools that can be used to process large
datasets from e.g. computer vision, deep learning, data visualization, or other graphics rendering or systems by using the potential
available in modern platforms that contain GPUs and other accelerators.
Methods Physically Based Rendering
When devising high-performance algorithms, it is often beneficial to de- Nature is a complicated beauty with many areas that we still do not fully
couple the algorithm itself from scheduling and performance aspects. As understand. Even when we limit ourselves to only light transport, there
an example, the Halide [3] framework (see below) has successfully done are many things that we are not modeling yet. Thus, another part of this
just this for the domain of image filters and as a part of this research we research is to extend the toolkit of physical phenomena we can simulate
are investigating similar DSLs for generating 3D content, such as rasteri- using ray-tracing or rasterization based methods.
zation or ray tracing.
Func blur_3x3(Func input) { Lo (x, ωo ) = Le (x, ωo ) + fr (x, ωi , ωo )Li (x, ωi )(ωi · n) dωi
Func blur_x, blur_y; Ω
Var x, y, xi, yi;
// The algorithm - no storage or order
blur_x(x,y) = (input(x-1,y) + input(x,y) + input(x+1,y))/3;
blur_y(x,y) = (blur_x(x,y-1) + blur_x(x,y) + blur_x(x,y+1))/3; The Rendering Equation,
// The schedule - defines order, locality; implies storage the basis for almost all
blur_y.tile(x, y, xi, yi, 256, 32)
.vectorize(xi, 8).parallel(y);
graphics algorithms.
n
blur_x.compute_at(blur_y, x).vectorize(x, 8); X
return blur_y;
}
Ray Generation
trace()
Any Hit
Selected Results
Acceleration
Structure One of the physical phenomena that is modeled as a part of this project
Traversal Intersection
is the transient light known as Cherenkov radiation. A few examples of
this phenomenon can be seen below and for more details please see our
work in 1.
No Hit? Yes
Miss Closest Hit
As seen above, one of the core components in ray tracing is the
acceleration structure. It is the single greatest thing that deter-
mines how well ray tracing algorithms perform [2]. Thus, a lot
of research has been devoted to understanding how to make this
better. As a part of our research, we are investigating how to
specialize this structure for particular use cases.
References
G. Waldemarson and M. Doggett, “Photon Mapping Superluminal
Particles,” in Eurographics 2020 - Short Papers, A. Wilkie and F.
[1] Banterle, Eds., The Eurographics Association, 2020, isbn: 978-3-
Recent research has been fo-
03868-101-4. doi: 10.2312/egs.20201004 cused on creating efficient
D. Meister, S. Ogaki, C. Benthin, et al., “A Survey on Bounding rendering algorithms for the
[2] Volume Hierarchies for Ray Tracing,” Computer Graphics Forum, so called glow discharge phe-
2021, issn: 1467-8659. doi: 10.1111/cgf.142662 nomenon, seen here.
J. Ragan-Kelley, A. Adams, D. Sharlet, et al., “Halide: Decoupling
algorithms from schedules for high-performance image process-
[3] ing,” Commun. ACM, vol. 61, no. 1, pp. 106–115, Dec. 2017, issn:
0001-0782. doi: 10.1145/3150211. [Online]. Available: https:
//doi.org/10.1145/3150211SOFTWARE Page 175 A Zhang, Long KTH Application-level Chaos Engineering Chaos engineering is a new scientific method within software engineering that consists in specify- ing and evaluating resilience hypotheses by 1) injecting faults in a production system, 2) observing the impact of such faults, and 3) building new knowledge about the strengths and weaknesses of the resilience of the system. Chaos engineering can be applied at different levels such as network level and infrastructure level. In order to provide more concrete and application-specific insights for develo- pers, our research work focuses on using application-level chaos engineering to address the following challenges: C1-How to evaluate different aspects of resilience, C2-How to automate the chaos experi- ments, and C3-How to improve the efficiency of the chaos engineering experiments.
SOFTWARE Page 175 B Zhang, Long KTH Application-level Chaos Engineering Long Zhang , KTH Main advisor: Martin Monperrus Abstract Chaos engineering is a new scientific method within software engineering that consists in specifying and evaluating resilience hypotheses by 1) injecting faults in a production system, 2) observing the impact of such faults, and 3) building new knowledge about the strengths and weaknesses of the resilience of the system. Chaos engineering can be applied at different levels such as network level and infrastructure level. In order to provide more concrete and application-specific insights for developers, our research work focuses on using application-level chaos engineering to address the following challenges: C1-How to evaluate different aspects of resilience, C2-How to automate the chaos experiments, and C3-How to improve the efficiency of the chaos engineering experiments. ChaosMachine POBS Building confidence in system behavior through EXPERIMENTS in RUNTIME Java Virtual Machine Java Virtual Machine Javaagent, Java byte-code, ASM In order to address C1, we propose to use different perturbation models at the application level [1,2]. This is because: application- level perturbation models are closer to the application’s source code, which helps developers to locate the improvement target, and such models simulate more concrete failure scenarios for this specific application. In order to address C2, we propose to design orchestration • Input frameworks to connect monitoring, injection, and analysis. For • Arbitrary software in Java most of the existing chaos engineering tools, there are several • Hypotheses limitations: 1) steady state and hypotheses have to be manually • Architecture defined, 2) the installation of a tool may be complicated, and 3) • Monitoring sidecars the setup of an experiment may be tedious. • Perturbation injectors • Chaos controller Thus we propose a technique called POBS (imProved • Output OBServability) to statically analyze and transform Docker • Resilience report configuration files of Java applications in order to inject observability capabilities [3]. Perturbation model: try-catch block short-circuit testing • A corresponding exception at the beginning For example, POBS allows developers to observe the JVM • The whole try block is made invalid memory or CPU usage of their application with minimal effort: a single line change in the Docker configuration. Hypotheses • RH (Resilience hypothesis) • OH (Observability hypothesis) Phoebe • DH (Debug hypothesis) • SH (Silence hypothesis) Evaluation • 3 large-scale and well-known Java applications totaling 630k lines of code References 1. Zhang et al, A Chaos Engineering System for Live Analysis and Falsification of Exception-Handling in the JVM, IEEE TSE, In order to address C3, we present a novel fault injection 2019. framework for system call invocation errors, called Phoebe [4]. 2. Zhang et al, TripleAgent: Monitoring, Perturbation and Failure- Phoebe is unique as follows. First, Phoebe enables developers Obliviousness for Automated Resilience Improvement in Java to have full observability of system call invocations. Second, Applications, IEEE 30th International Symposium on Software Phoebe generates error models that are realistic in the Reliability Engineering (ISSRE), 2019. sense that they mimic errors that naturally happen in 3. Zhang et al, Automatic Observability for Dockerized Java production. Third, Phoebe is able to automatically conduct Applications, arXiv preprint:1912.06914, 2019. experiments to s y s t e m a t i c a l l y a s s e s s t h e r e l i a b i l i t y o f 4. Zhang et al, Maximizing Error Injection Realism for Chaos applications with respect to system call invocation errors in Engineering with System Calls, IEEE TDSC, 2021. production.
You can also read

















































