Transformer visualization via dictionary learning: contextualized embedding as a linear superposition of transformer factors
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Transformer visualization via dictionary learning:
contextualized embedding as a linear superposition of transformer factors
Zeyu Yun∗ 2 Yubei Chen∗ 1,2 Bruno A Olshausen2,4 Yann LeCun1,3
1
Facebook AI Research
2
Berkeley AI Research (BAIR), UC Berkeley
3
New York University
4
Redwood Center for Theoretical Neuroscience, UC Berkeley
Abstract models have excellent performance in those prob-
ing tasks. These results indicate that transformer
Transformer networks have revolutionized models have learned the language representation
NLP representation learning since they were
related to the probing tasks. Though the probing
arXiv:2103.15949v1 [cs.CL] 29 Mar 2021
introduced. Though a great effort has been
made to explain the representation in trans- tasks are great tools for interpreting language mod-
formers, it is widely recognized that our un- els, their limitation is explained in (Rogers et al.,
derstanding is not sufficient. One important 2020). We summarize the limitation into three ma-
reason is that there lack enough visualiza- jor points:
tion tools for detailed analysis. In this pa-
per, we propose to use dictionary learning • Most probing tasks, like POS and NER tag-
to open up these ‘black boxes’ as linear su- gering, are too simple. A model that performs
perpositions of transformer factors. Through well in those probing tasks does not reflect the
visualization, we demonstrate the hierarchi- model’s true capacity.
cal semantic structures captured by the trans-
former factors, e.g. word-level polysemy dis- • Probing tasks can only verify whether the cer-
ambiguation, sentence-level pattern formation, tain prior structure is learned in a language
and long-range dependency. While some of model. They can not reveal the structures be-
these patterns confirm the conventional prior
yond our prior knowledge.
linguistic knowledge, the rest are relatively
unexpected, which may provide new insights. • It’s hard to locate where exactly the related
We hope this visualization tool can bring fur-
linguistic representation is learned in the trans-
ther knowledge and a better understanding of
how transformer networks work. former.
Efforts are made to remove those limitations and
1 Introduction make probing tasks more diverse. For instance,
Though the transformer networks (Vaswani et al., (Hewitt and Manning, 2019) propose “structural
2017; Devlin et al., 2018) have achieved great probe”, which is a much more intricate probing
success, our understanding of how they work is task. (Jiang et al., 2020) propose to automatically
still fairly limited. This has triggered increas- generate certain probing tasks. Non-probing meth-
ing efforts to visualize and analyze these “black ods are also explored to relieve the last two limi-
boxes”. Besides a direct visualization of the atten- tations. For example, (Reif et al., 2019) visualize
tion weights, most of the current efforts to inter- embedding from BERT using UMAP and show
pret transformer models involve “probing tasks”. that the embeddings of the same word under dif-
They are achieved by attaching a light-weighted ferent contexts are separated into different clusters.
auxiliary classifier at the output of the target trans- (Ethayarajh, 2019) analyze the similarity between
former layer. Then only the auxiliary classifier embeddings of the same word in different contexts.
is trained for well-known NLP tasks like part-of- Both of these works show transformers provide a
speech (POS) Tagging, Named-entity recognition context-specific representation.
(NER) Tagging, Syntactic Dependency, etc. (Ten- (Faruqui et al., 2015; Arora et al., 2018; Zhang
ney et al., 2019; Liu et al., 2019) show transformer et al., 2019) demonstrate how to use dictionary
∗
learning to explain, improve, and visualize the un-
equal contribution. Correspondence to: Zeyu
Yun , Yubei Chen contextualized word embedding representations. In
this work, we propose to use dictionary learning
to alleviate the limitations of the other transformer as {x(1) (s, i), x(2) (s, i), · · · , x(L) (s, i)}, where
interpretation techniques. Our results show that x(l) (x, i) ∈ Rd . Each x(l) (x, i) represents the hid-
dictionary learning provides a powerful visualiza- den output of Transformer at layer-l, given the in-
tion tool, which even leads to some surprising new put sentence s and index i, d is the dimension of
knowledge. the embedding vectors.
2 Method To learn a dictionary of Transformer Factors
with Non-Negative Sparse Coding. Let S be the
Hypothesis: contextualized word embedding as set of all sequences, X (l) = {x(l) (s, i)|s ∈ S, i ∈
a sparse linear superposition of transformer [0, len(s)]}, and X = X (1) ∪ X (2) ∪ · · · ∪ X (L) .
factors. It is shown that word embedding vectors ∀x ∈ X, we assume x is a sparse linear superposi-
can be factorized into a sparse linear combination tion of transformer factors:
of word factors (Arora et al., 2018; Zhang et al.,
2019), which correspond to elementary semantic x = Φα + , s.t. α 0, (1)
meanings. An example is:
where Φ ∈ IRd×m is a dictionary matrix with
apple =0.09“dessert” + 0.11“organism” + 0.16 columns Φ:,c , α ∈ IRm is a sparse vector of coef-
ficients to be inferred and is a vector containing
“fruit” + 0.22“mobile&IT” + 0.42“other”.
independent Gaussian noise samples, which are as-
We view the latent representation of words in a sumed to be small relative to x. Typically m > d
transformer as contextualized word embedding. so that the representation is overcomplete. This
Similarly, our hypothesis is that a contextualized inverse problem can be efficiently solved by FISTA
word embedding vector can also be factorized as a algorithm (Beck and Teboulle, 2009). The dictio-
sparse linear superposition of a set of elementary nary matrix Φ can be learned in an iterative fashion
elements, which we call transformer factors. by using non-negative sparse coding, which we
leave to the appendix section C. Each column Φ:,c
of Φ is a transformer factor and its corresponding
sparse coefficient αc is its activation level.
Visualization by Top Activation and LIME In-
terpretation. An important empirical method to
visualize a feature in deep learning is to use the
input samples, which trigger the top activation of
the feature (Zeiler and Fergus, 2014). We adopt
Figure 1: Building block (layer) of transformer
this convention. As a starting point, we try to
visualize each of the dimensions of a particular
Due to the skip connections in each of the trans- layer, X (l) . Unfortunately, the hidden dimensions
former blocks, we hypothesize that the representa- of transformers are not semantically meaningful,
tion in any layer would be a superposition of the hi- which is similar to the uncontextualized word em-
erarchical representations in all of the lower layers. beddings (Zhang et al., 2019).
As a result, the output of a particular transformer Instead, we can try to visualize the transformer
block would be the sum of all of the modifications factors. For a transformer factor Φ:,c and for a
along the way. Indeed, we verify this intuition layer-l, we denote the 1000 contextualized word
(l)
with the experiments. Based on the above observa- vectors with the largest sparse coefficients αc ’s as
(l)
tion, we propose to learn a single dictionary for the Xc ⊂ X (l) , which correspond to 1000 different
(l)
contextualized word vectors from different layers’ sequences Sc ⊂ S. For example, Figure 3 shows
output. the top 5 words that activated transformer factor-17
Given a transformer model with L layer and Φ:,17 at layer-0, layer-2, and layer-6 respectively.
a tokenized sequence s, we denote a contex- Since a contextualized word vector is generally af-
tualized word embedding1 of word w = s[i] fected by many tokens in the sequence, we can use
1
LIME (Ribeiro et al., 2016) to assign a weight to
In the following, when we use either “word vector" or
“word embedding", to refer to the latent output (at a particular each token in the sequence to identify their relative
layer of BERT) of any word w in a context s importance to αc . The detailed method is left to
Section 3.
To Determine Low-, Mid-, and High-Level
Transformer Factors with Importance Score.
As we build a single dictionary for all of the trans-
former layers, the semantic meaning of the trans-
former factors has different levels. While some of (a) (b)
the factors appear in lower layers and continue to
Figure 2: Importance score (IS) across all layers for
be used in the later stages, the rest of the factors two different transformer factors. (a) This figure shows
may only be activated in the higher layers of the a typical IS curve of a transformer factor correspond-
transformer network. A central question in rep- ing to low-level information. (b) This figure shows a
resentation learning is: “where does the network typical IS curve of a transformer factor corresponds to
learn certain information?” To answer this ques- mid-level information.
tion, we can compute an “importance score” for
(l) (l) word-level disambiguation, sentence-level pattern
each transformer factor Φ:,c at layer-l as Ic . Ic is formation, and long-range dependency. In the fol-
the average of the largest 1000 sparse coefficients lowing, we provide detailed visualization for each
(l) (l)
αc ’s, which correspond to Xc . We plot the im- semantic category. We also build a website for the
portance scores for each transformer factor as a interested readers to play with these results.
curve is shown in Figure 2. We then use these im-
portance score (IS) curves to identify which layer Low-Level: Word-Level Polysemy Disambigua-
a transformer factor emerges. Figure 2a shows tion. While the input embedding of a token con-
an IS curve peak in the earlier layer. The corre- tains polysemy, we find transformer factors with
sponding transformer factor emerges in the ear- early IS curve peaks usually correspond to a spe-
lier stage, which may capture lower-level semantic cific word-level meaning. By visualizing the top
meanings. In contrast, Figure 2b shows a peak in activation sequences, we can see how word-level
the higher layers, which indicates the transformer disambiguation is gradually developed in a trans-
factor emerges much later and may correspond to former.
mid- or high-level semantic structures. More sub- Disambiguation is a rather simple task in natural
tleties are involved when distinguishing between language understanding. We show some examples
mid-level and high-level factors, which will be dis- of those types of transformer factors in Table 1:
cussed later. for each transformer factor, we list out the top 3
An important characteristic is that the IS curve activated words and their contexts. We also show
for each transformer factor is fairly smooth. This how the disambiguation effect develops progres-
indicates if a strong feature is learned in the be- sively through each layer. In Figure 3, the top-
ginning layers, it won’t disappear in later stages. activated words and their contexts for transformer
Rather, it will be carried all the way to the end factor Φ:,30 in different layers are listed. The top
with gradually decayed weight since many more activated words in layer 0 contain the word “left”
features would join along the way. Similarly, ab- with different word senses, which is being mostly
stract information learned in higher layers is slowly disambiguated in layer 2 albeit not completely. In
developed from the early layers. Figure 3 and 5 layer 4, the word “left” is fully disambiguated since
confirm this idea, which will be explained in the the top-activated word contains only “left” with the
next section. word sense “leaving, exiting.”
Further, we can quantify the quality of the disam-
3 Experiments and Discoveries biguation ability of the transformer model. In the
example above, since the top 1000 activated words
We use a 12-layer pre-trained BERT model (Pre; and contexts are “left” with only the word sense
Devlin et al., 2018) and freeze the weights. Since “leave, exiting”, we can assume “left” when used
we learn a single dictionary of transformer factors as a verb, triggers higher activation in Φ:,30 than
for all of the layers in the transformer, we show that “left” used as other sense of speech. We can verify
these transformer factors correspond to different this hypothesis using a human-annotated corpus:
levels of semantic meanings. The semantic mean- Brown corpus (Francis and Kucera, 1979). In this
ing can be roughly divided into three categories: corpus, each word is annotated with its correspond-
3 example words and their contexts with high activation Explanation
Φ:,2 • that snare shot sounded like somebody’ d kicked open the door to your • Word “mind”
mind". • Noun
• i became very frustrated with that and finally made up my mind to start • Definition: the element of a
getting back into things." person that enables them to be
• when evita asked for more time so she could make up her mind, the crowd aware of the world and their ex-
demanded," ¡ ahora, evita,< periences.
Φ:,16 •nington joined the five members xero and the band was renamed to linkin • Word “park”
park. • Noun
• times about his feelings about gordon, and the price family even sat away • Definition: a common first and
from park’ s supporters during the trial itself. last name
• on 25 january 2010, the morning of park’ s 66th birthday, he was found
hanged and unconscious in his
Φ:,30 • saying that he has left the outsiders, kovu asks simba to let him join his pride • Word “left"
• eventually, all boycott’ s employees left, forcing him to run the estate without • Verb
help. • Definition: leaving, exiting
• the story concerned the attempts of a scientist to photograph the soul as it
left the body.
Φ:,33 • forced to visit the sarajevo television station at night and to film with as little • Word “light”
light as possible to avoid the attention of snipers and bombers. • Noun
• by the modest, cream@-@ colored attire in the airy, light@-@ filled clip. • Definition: the natural agent
• the man asked her to help him carry the case to his car, a light@-@ brown that stimulates sight and makes
volkswagen beetle. things visible
Table 1: Several examples of the transformer factors correspond to low-level information. Their top-activated
words in layer 4 are marked blue, and the corresponding contexts are shown as examples for each transformer
factor. As shown in the table, all of the top-activated words are disambiguated into a single sense. More examples,
top-activated words, and contexts are provided in Appendix.
(a) layer 0 (b) layer 2 (c) layer 6
Figure 3: Visualization of a low-level transformer factor: Φ:,30 at different layers. (a), (b) and (c) are the top-
activated words and contexts for Φ:,30 in layer-0, 2 and 4 respectively. We can see that at layer-0, this transformer
factor corresponds to word vectors that encode the word “left" with different senses. In layer-2, a majority of the
top activated words “left” correspond to a single sense, "leaving, exiting." In layer 4, all of the top-activated words
“left” have corresponded to the same sense, "leaving, exiting.". Due to space limitations, we leave more examples
in the appendix.
ing part-of-speech. We collect all the sentences layer 4, they are nearly linearly separable by this
contains the word “left” annotated as a verb in one single feature. Since each word “left” corresponds
set and sentences contains “left” annotated as other to an activation value, we can perform a logistic
part-of-speech. As shown in Figure 4a, in layer 0, regression classification to differentiate those two
the average activation of Φ:,30 for the word “left” types of “left”. From the result shown in Figure 4a,
marked as a verb is no different from “left” as other it is quite fascinating to see that the disambigua-
senses. However, at layer 2, “left” marked as verb tion ability of just Φ:,30 is better than the other two
triggers a higher activation of Φ:,30 . In layer 4, classifiers trained with supervised data. This result
this difference further increases, indicating disam- confirms that disambiguation is indeed done in the
biguation develops progressively across layers. In early part of pre-trained transformer model and we
fact, we plot the activation of “left” marked as verb are able to detect it via dictionary learning.
and the activation of other “left” in Figure 4b. In
(a) (b)
Figure 4: (a) Average activation of Φ:,30 for word vector “left” across different layers. (b) Instead of averaging, we
plot the activation of all “left” with contexts in layer-0, 2, and 4. Random noise is added to the y-axis to prevent
overplotting. The activation of Φ:,30 for two different word sense of “left” is blended together in layer-0. They
disentangle to a great extent in layer-2 and nearly separable in layer-4 by this single dimension.
(a) layer 4 (b) layer 6 (c) layer 8
Figure 5: Visualization of a mid-level transformer factor. (a), (b), (c) are the top 5 activated words and contexts
for this transformer factor in layer-4, 6, and 8 respectively. Again, the position of the word vector is marked blue.
Please notice that sometimes only a part of a word is marked blue. This is due to that BERT uses word-piece
tokenizer instead of whole word tokenizer. This transformer factor corresponds to the pattern of “consecutive
adjective”. As shown in the figure, this feature starts to develop at layer-4 and fully develops at layer-8.
Precision Recall F-1 score layer 4, continues to develop at layer 6, and be-
(%) (%) (%)
Average perceptron POS 92.7 95.5 94.1 comes quite reliable at layer 8. Figure 6 shows a
tagger transformer factor, which corresponds to a quite un-
Finetuned BERT base 97.5 95.2 96.3 expected pattern: “unit exchange”, e.g. 56 inches
model for POS task
Logistic regression clas- 97.2 95.8 96.5 (140 cm). Although this exact pattern only starts to
sifier with activation of appear at layer 8, the sub-structures that make this
Φ:,30 at layer 4 pattern, e.g. parenthesis and numbers, appear to
Table 2: Evaluation of binary POS tagging task: predict trigger this factor in layers 4 and 6. Thus this trans-
whether or not “left” in a given context is a verb. former factor is also gradually developed through
several layers.
Mid Level: Sentence-Level Pattern Formation. While some of the mid-level transformer factors
We find most of the transformer factors, with an verify common syntactic patterns, there are also
IS curve peak after layer 6, capture mid-level or many surprising mid-level transformer factors. We
high-level semantic meanings. In particular, the list a few in Table 3 with quantitative analysis. For
mid-level ones correspond to semantic patterns like each listed transformer factor, we analyze the top
phrases and sentences pattern. 200 activating words and their contexts in each
We first show two detailed examples of mid-level layer. We record the percentage of those words and
transformer factors. Figure 5 shows a transformer contexts that correspond to the factors’ semantic
factor that detects the pattern of consecutive us- pattern in Table 3. From the table, we see that large
age of adjectives. This pattern starts to emerge at percentages of top-activated words and contexts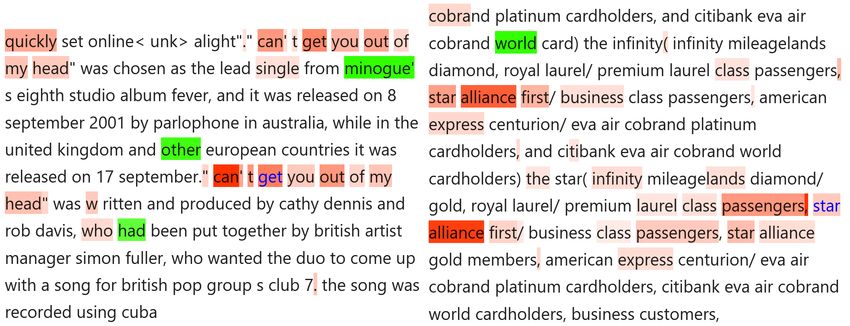
(a) layer 4 (b) layer 6 (c) layer 8
Figure 6: Another example of a mid-level transformer factor visualized at layer-4, 6, and 8. The pattern that cor-
responds to this transformer factor is “unit exchange”. Such a pattern is somewhat unexpected based on linguistic
prior knowledge.
2 example words and their contexts with high activation Patterns L4 L6 L8 L10
(%) (%) (%) (%)
Φ:,13 • the steel pipeline was about 20 ° f(- 7 ° c) degrees. Unit exchange with paren- 0 0 64.5 95.5
• hand( 56 to 64 inches( 140 to 160 cm)) war horse is that theses
it was a
Φ:,42 • he died at the hospice of lancaster county from heart something unfortunate 94.0 100 100 100
• holly’ s drummer carl bunch suffered frostbite to his happened
toes( while aboard the ailments on 23 june 2007.
Φ:,50 • hurricane pack 1 was a revamped version of story mode; Doing something again, 74.5 100 100 100
• in 1998, the categories were retitled best short form or making something new
music video, and best again
Φ:,86 • he finished the 2005 – 06 season with 21 appearances Consecutive years, used 0 100 85.0 95.5
and seven goals. in foodball season nam-
• of an offensive game, finishing off the 2001 – 02 season ing
with 58 points in the 47 games
Φ:,102 • the most prominent of which was bishop abel muzorewa’ African names 99.0 100 100 100
s united african national council
• ralambo’ s father, andriamanelo, had established rules of
succession by
Φ:,125 • music writer jeff weiss of pitchfork describes the" endur- Describing someone in a 15.5 99.0 100 98.5
ing image" paraphrasing style. Name,
• club reviewer erik adams wrote that the episode was a Career
perfect mix
Φ:,184 • the world wide fund for nature( wwf) announced in 2010 Institution with abbrevia- 0 15.5 39.0 63.0
that a biodiversity study from tion
• fm) was halted by the federal communications commis-
sion( fcc) due to a complaint that the company buying
Φ:,193 • 74, 22@,@ 500 vietnamese during 1979 – 92, over 2@,@ Time span in years 97.0 95.5 96.5 95.5
500 bosnian
•, the russo@-@ turkish war of 1877 – 88 and the first
balkan war in 1913.
Φ:,195 •s, hares, badgers, foxes, weasels, ground squirrels, mice, Consecutive of noun 8.0 98.5 100 100
hamsters (Enumerating)
•-@ watching, boxing, chess, cycling, drama, languages,
geography, jazz and other music
Φ:,225 • technologist at the united states marine hospital in key Places in US, follow- 51.5 91.5 91.0 77.5
west, florida who developed a morbid obsession for ings the convention “city,
• 00°,11”, w, near smith valley, nevada. state"
Table 3: A list of typical mid-level transformer factors. The top-activation words and their context sequences for
each transformer factor at layer-8 are shown in the second column. We summarize the patterns of each transformer
factor in the third column. The last 4 columns are the percentage of the top 200 activated words and sequences that
contain the summarized patterns in layer-4,6,8, and 10 respectively.
do corresponds to the pattern we describe. It also representations for these surprising patterns, we
shows most of these mid-level patterns start to de- believe such a direct visualization can provide ad-
velop at layer 4 or 6. More detailed examples are ditional insights, which complements the “probing
provided in the appendix section F. Though it’s still tasks”.
mysterious why the transformer network develops
To further confirm a transformer factor does
Adversarial Text Explaination α35
(o) album as "full of exhilarating, ecstatic, thrilling, fun and the original top-activated words and 9.5
sometimes downright silly songs" their contexts for transformer factor
Φ:,35
(a) album as "full of delightful, lively, exciting, interesting use different adjective. 9.2
and sometimes downright silly songs"
(b) album as "full of unfortunate, heartbroken, annoying, bor- Change all adjective to negative adjec- 8.2
ing and sometimes downright silly songs" tive.
(c) album as "full of [UNK], [UNK], thrilling, [UNK] and Mask all adjective with Unknown To- 5.3
sometimes downright silly songs" ken.
(d) album as "full of thrilling and sometimes downright silly Remove the first three adjective. 7.8
songs"
(e) album as "full of natural, smooth, rock, electronic and Change adjective to neutral adjective. 6.2
sometimes downright silly songs"
(f) each participant starts the battle with one balloon. these Use an random sentence that has quo- 0.0
can be re@-@ inflated up to four tation mark.
(g) The book is described as "innovative, beautiful and bril- A sentence we created that contain the 7.9
liant". It receive the highest opinion from James Wood pattern of consecutive adjective.
Table 4: We construct adversarial texts similar but different to the pattern “Consecutive adjective”. The last column
(8)
shows the activation of Φ:,35 , or α35 , w.r.t. the blue-marked word in layer 8.
correspond to a specific pattern, we can use con- unknown token). Then we learns a linear model
structed example words and context to probe their gw (s0 ) with weights w ∈ RT to approximate f (s0 ),
activation. In Table 4, we construct several text where T is the length of sentence s. This can be
sequences that are similar to the patterns corre- solved as a ridge regression:
sponding to a certain transformer factor but with
subtle differences. The result confirms that the con- min L(f, w, S(s)) + σkwk22 .
w∈RT
text that strictly follows the pattern represented by
that transformer factor triggers a high activation. The learned weights w can serve as a saliency
On the other hand, the more closer the adversar- map that reflects the “contribution” of each token
ial example to this pattern, the higher activation it in the sequence s. Like in Figure 7, the color re-
receives at this transformer factor. flects the weights w at each position, red means
High-Level: Long-Range Dependency. High- the given position has positive weight, and green
level transformer factors correspond to those lin- means negative weight. The magnitude of weight
guistic patterns that span a long-range in the text. is represented by the intensity. The redder a token
Since the IS curves of mid-level and high-level is, the more it contributions to the activation of
transformer factors are similar, it is difficult to dis- the transformer factor. We leave more implementa-
tinguish those transformer factors based on their IS tion and mathematical formulation details of LIME
curves. Thus, we have to manually examine the top- algorithm in the appendix.
activation words and contexts for each transformer We provide detailed visualization for 2 different
factor to distinguish whether they are mid-level or transformer factors that show long-range depen-
high-level transformer factors. In order to ease the dency in Figure 7, 8. Since visualization of high-
process, we can use the black-box interpretation level information requires longer context, we only
algorithm LIME (Ribeiro et al., 2016) to identify show the top 2 activated words and their contexts
the contribution of each token in a sequence. for each such transformer factor. Many more will
(l) be provided in the appendix section G.
Given a sequence s ∈ S, we can treat αc,i , the
We name the pattern for transformer factor Φ:,297
activation of Φ:,c in layer-l at location i, as a scalar
(l) in Figure 7 as “repetitive pattern detector”. All top
function of s, fc,i (s). Assume a sequence s trig-
activated contexts for Φ:,297 contain an obvious
(l) (l)
gers a high activation αc,i , i.e. fc,i (s) is large. We repetitive structure. Specifically, the text snippet
want to know how much each token (or equivalently “can’t get you out of my head" appears twice in
(l)
each position) in s contributes to fc,i (s). To do the first example, and the text snippet “xxx class
so, we generated a sequence set S(s), where each passenger, star alliance” appears 3 times in the sec-
s0 ∈ S(s) is the same as s except for that several ond example. Compared to the patterns we found
random positions in s0 are masked by [‘UNK’] (the in the mid-level [6], the high-level patterns like
“repetitive pattern detector” are much more abstract. et al., 2018; Zhang et al., 2019). In this paper, we
In some sense, the transformer detects if there are propose to use this simple method to visualize the
two (or multiple) almost identical embedding vec- representation learned in transformer networks to
tors at layer-10 without caring what they are. Such supplement the implicit “probing-tasks” methods.
behavior might be highly related to the concept Our results show that the learned transformer fac-
proposed in the capsule networks (Sabour et al., tors are relatively reliable and can even provide
2017; Hinton, 2021). To further understand this be- many surprising insights into the linguistic struc-
havior and study how the self-attention mechanism tures. This simple tool can open up the transformer
helps model the relationships between the features networks and show the hierarchical semantic repre-
outlines an interesting future research direction. sentation learned from at different stages. In short,
Figure 8 shown another high-level factor, which we find word-level disambiguation, sentence-level
detects text snippets related to “the beginning of pattern formation, and long-range dependency. The
a biography”. The necessary components, day of idea of a neural network learns low-level features
birth as month and four-digit years, first name and in early layers and abstract concepts in the later
last name, familial relation, and career are all mid- stages are very similar to the visualization in CNN
level information. In Figure 8, we see that all the (Zeiler and Fergus, 2014). Dictionary learning can
information relates to biography has a high weight be a convenient tool to help visualize a broad cate-
in the saliency map. Thus, they are all together gory of neural networks with skip connections, like
combined to detect the high-level pattern. ResNet (He et al., 2016), ViT models (Dosovitskiy
et al., 2020), etc. For more interested readers, we
provide an interactive website2 for the readers to
gain some further insights.
Figure 7: Two examples of the high activated words
and their contexts for transformer factor Φ:,297 . We
also provide the saliency map of the tokens generated
using LIME. This transformer factor corresponds to the
concept: “repetitive pattern detector”. In other words,
repetitive text sequences will trigger high activation of
Φ:,297 .
Figure 8: Visualization of Φ:,322 . This transformer fac-
tor corresponds to the concept: “some born in some
year” in biography. All of the high-activation contexts
contain the beginning of a biography. As shown in the
figure, the attributes of someone, name, age, career, and
familial relation all have high saliency weights.
4 Discussion
Dictionary learning has been successfully used to
2
visualize the classical word embeddings (Arora https://transformervis.github.io/transformervis/
References John Hewitt and Christopher D. Manning. 2019. A
structural probe for finding syntax in word repre-
Pretrained bert base model (12 layers). https: sentations. In Proceedings of the 2019 Conference
//huggingface.co/bert-base-uncased, of the North American Chapter of the Association
last accessed on 03/11/2021. for Computational Linguistics: Human Language
Technologies, Volume 1 (Long and Short Papers),
Sanjeev Arora, Yuanzhi Li, Yingyu Liang, Tengyu Ma, pages 4129–4138, Minneapolis, Minnesota. Associ-
and Andrej Risteski. 2018. Linear algebraic struc- ation for Computational Linguistics.
ture of word senses, with applications to polysemy.
Transactions of the Association for Computational Geoffrey Hinton. 2021. How to represent part-whole
Linguistics, 6:483–495. hierarchies in a neural network. arXiv preprint
arXiv:2102.12627.
Amir Beck and Marc Teboulle. 2009. A fast itera-
tive shrinkage-thresholding algorithm for linear in- Zhengbao Jiang, Frank F. Xu, Jun Araki, and Graham
verse problems. SIAM journal on imaging sciences, Neubig. 2020. How can we know what language
2(1):183–202. models know. Trans. Assoc. Comput. Linguistics,
8:423–438.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2018. BERT: pre-training of
Nelson F. Liu, Matt Gardner, Yonatan Belinkov,
deep bidirectional transformers for language under-
Matthew E. Peters, and Noah A. Smith. 2019. Lin-
standing. CoRR, abs/1810.04805.
guistic knowledge and transferability of contextual
representations. In Proceedings of the 2019 Confer-
Alexey Dosovitskiy, Lucas Beyer, Alexander
ence of the North American Chapter of the Associ-
Kolesnikov, Dirk Weissenborn, Xiaohua Zhai,
ation for Computational Linguistics: Human Lan-
Thomas Unterthiner, Mostafa Dehghani, Matthias
guage Technologies, Volume 1 (Long and Short Pa-
Minderer, Georg Heigold, Sylvain Gelly, et al. 2020.
pers), pages 1073–1094, Minneapolis, Minnesota.
An image is worth 16x16 words: Transformers
Association for Computational Linguistics.
for image recognition at scale. arXiv preprint
arXiv:2010.11929.
Emily Reif, Ann Yuan, Martin Wattenberg, Fernanda B.
John Duchi, Elad Hazan, and Yoram Singer. 2011. Viégas, Andy Coenen, Adam Pearce, and Been Kim.
Adaptive subgradient methods for online learning 2019. Visualizing and measuring the geometry of
and stochastic optimization. Journal of Machine BERT. In Advances in Neural Information Process-
Learning Research, 12(Jul):2121–2159. ing Systems 32: Annual Conference on Neural Infor-
mation Processing Systems 2019, NeurIPS 2019, De-
Kawin Ethayarajh. 2019. How contextual are con- cember 8-14, 2019, Vancouver, BC, Canada, pages
textualized word representations? comparing the 8592–8600.
geometry of bert, elmo, and GPT-2 embeddings.
In Proceedings of the 2019 Conference on Empiri- Marco Túlio Ribeiro, Sameer Singh, and Carlos
cal Methods in Natural Language Processing and Guestrin. 2016. "why should I trust you?": Ex-
the 9th International Joint Conference on Natural plaining the predictions of any classifier. CoRR,
Language Processing, EMNLP-IJCNLP 2019, Hong abs/1602.04938.
Kong, China, November 3-7, 2019, pages 55–65. As-
sociation for Computational Linguistics. Anna Rogers, Olga Kovaleva, and Anna Rumshisky.
2020. A primer in bertology: What we know about
Manaal Faruqui, Yulia Tsvetkov, Dani Yogatama, Chris how BERT works. Trans. Assoc. Comput. Linguis-
Dyer, and Noah A. Smith. 2015. Sparse overcom- tics, 8:842–866.
plete word vector representations. In Proceedings
of the 53rd Annual Meeting of the Association for Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton.
Computational Linguistics and the 7th International 2017. Dynamic routing between capsules. arXiv
Joint Conference on Natural Language Processing preprint arXiv:1710.09829.
(Volume 1: Long Papers), pages 1491–1500, Beijing,
China. Association for Computational Linguistics. Ian Tenney, Patrick Xia, Berlin Chen, Alex Wang,
Adam Poliak, R Thomas McCoy, Najoung Kim,
W. N. Francis and H. Kucera. 1979. Brown corpus Benjamin Van Durme, Samuel R Bowman, Dipan-
manual. Technical report, Department of Linguis- jan Das, et al. 2019. What do you learn from
tics, Brown University, Providence, Rhode Island, context? probing for sentence structure in con-
US. textualized word representations. arXiv preprint
arXiv:1905.06316.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian
Sun. 2016. Deep residual learning for image recog- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob
nition. In Proceedings of the IEEE conference on Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz
computer vision and pattern recognition, pages 770– Kaiser, and Illia Polosukhin. 2017. Attention is all
778. you need. arXiv preprint arXiv:1706.03762.
Matthew D Zeiler and Rob Fergus. 2014. Visualizing and understanding convolutional networks. In Euro- pean conference on computer vision, pages 818–833. Springer. Juexiao Zhang, Yubei Chen, Brian Cheung, and Bruno A Olshausen. 2019. Word embedding vi- sualization via dictionary learning. arXiv preprint arXiv:1910.03833.
Supplementary Materials B LIME: Local Interpretable
Model-Agnostic Explanations
A Importance Score (IS) Curves
After we trained the dictionary Φ through non-
negative sparse coding, the inference of the sparse
code of a given input is
α(x) = arg min ||x − Φα||22 + λ||α||1
α∈R
For a given sentence and index pair (s, i), the em-
bedding of word w = s[i] by layer l of transformer
is x(l) (x, i). Then we can abstract the inference of
(a) (b)
a specific entry of sparse code of the word vector
as a black-box scalar-value function f :
Figure 9: (a) Importance score of 16 transformer fac-
tors corresponding to low level information. (b) Im- f ((s, i)) = α(x(l) (s, i))
portance score of 16 transformer factors corresponds
to mid level information respectively. Let RandomM ask denotes the operation that
generates perturbed version of our sentence s by
The importance score curve’s characteristic has masking word at random location with “[UNK]”
a strong correspondence to a transformer factor’s (unkown) tokens. For example, a masked sentence
categorization. Based on the location of the peak could be
of a IS curve, we can classify a transformer factor [Today is a [‘UNK’],day]
to low-level, mid-level or high-level. Importance Let h denote a encoder for perturbed sentences
score for low level transformer factors peak in early compared to the unperturbed sentence s, such that
layers and slowly decrease across the rest of the
layers. On the other hand, importance score for 0 if s[t] = [‘UNK’]
h(s)t =
mid-level and high-level transformers slowly in- 1 Otherwis
creases and peaks at higher layers. In Figure 9, The LIME algorithm we used to generated
we show two sets of the examples to demonstrate saliency map for each sentences is the following:
the clear distinction between those two types of IS
curves. Algorithm 1 Explaining Sparse Coding Activation
Taking a step back, we can also plot IS curve for using LIME Algorithm
each dimension of word vector (without sparse cod- 1: S = {h(s)}
ing) at different layers. They do not show any spe- 2: Y = {f (s)}
cific patterns, as shown in Figure 10. This makes 3: for each i in {1, 2, ..., N } do
intuitive sense since we mentioned that each of the 4: s0i ← RandomM ask(s)
entries of a contextualized word embedding does 5: S ← S ∪ h(s0i )
not correspond to any clear semantic meaning. 6: Y ← Y ∪ f (s0i )
7: end for
8: w ← Ridgew (S, Y )
Where Ridgew is a weighted ridge regression
defined as:
w = arg min ||SΩw − Y ||2 + λ||w||22
w∈Rt
(a) (b)
Ω = diag(d(h(S1 ), ~1), d(h(S2 ), ~1), · · · , d(h(Sn ), ~1))
Figure 10: (a) Importance score calculated using cer-
tain dimension of word vectors without sparse coding. d(·, ·) can be any metric that measures how much
(b) Importance score calculated using sparse coding of a perturbed sentence is different from the original
word vectors. sentence. If a sentence is perturbed such that every
token is being masked, then the distance h(h(s0 ), ~1)should be 0, if a sentence is not perturbed at all, Then we use a typical iterative optimization pro-
then h(h(s0 ), ~1) should be 1. We choose d(·, ·) to cedure to learn the dictionary Φ described in the
be cosine similarity in our implementation. main section:
In practice, we also uses feature selection. This X
is done by running LIME twice. After we obtain min 21 kX−ΦAk2F +λ kαi k1 , s.t. αi 0, (2)
A
the regression weight w1 for the time, we use it to i
find the first k indices corresponds to the entry in
w1 with highest absolute value. We use those k min 21 kX − ΦΩAk2F , kΦ:,j k2 ≤ 1. (3)
Φ
index as location in the sentence and apply LIME
These two optimizations are both convex, we
for the second time with only those selected indices
solve them iteratively to learn the transformer fac-
from step 1.
tors: In practice, we use minibatches contains 200
Overall, the regression weight w can be regarded word vectors as X. The motivation of apply In-
as a saliency map. The higher the weight wk is, the verse Frequency Matrix Ω is that we want to make
more important the word s[k] in the sentence since sure all words in our vocabulary has the same con-
it contributes more to the activation of a specific tribution. When we sample our minibatch from A,
transformer factor. frequent words like “the” and “a” are much likely
We could also have negative weight in w. In to appear, which should receive lower weight dur-
general, negative weights are hard to interpret in the ing update.
context of transformer factor. The activation will Optimization 2 can converge in 1000 steps using
increase if they are removed those word correspond the FISTA algorithm3 . We experimented with dif-
to negative weights. Since a transformer factor ferent λ values from 0.03 to 3, and choose λ = 0.27
corresponds to a specific pattern, then word with to give results presented in this paper. Once the
negative weights are those word in a context that sparse coefficients have been inferred, we update
behaves “opposite" of this pattern. our dictionary Φ based on Optimization 3 by one
step using an approximate second-order method,
C The Details of the Non-negative Sparse
where the Hessian is approximated by its diagonal
Coding Optimization
to achieve an efficient inverse (Duchi et al., 2011).
Let S be the set of all sequences, recall how we de- The second-order parameter update method usually
fined word embedding using hidden state of trans- leads to much faster convergence of the word fac-
former in the main section: X (l) = {x(l) (s, i)|s ∈ tors. Empirically, we train 200k steps and it takes
S, i ∈ [0, len(s)]} as the set of all word embedding roughly 2 days on a Nvidia 1080 Ti GPU.
at layer l, then the set of word embedding across
all layers is defined as D Hyperlinks for More Transformer
Visualization
X = X (1) ∪ X (2) ∪ · · · ∪ X (L) In the following three sections, we provide visu-
alization of more example transformer factor in
In practice, we use BERT base model as our trans- low-level, mid-level, and high-level. Here’s table
former model, each word embedding vector (hid- of Contents that contain hyperlinks which direct to
den state of BERT) is dimension 768. To learn the each level:
transformer factors, we concatenate all word vector
x ∈ X into a data matrix A. We also defined f (x) • Low-Level: E
to be the frequency of the token that is embedded
• Mid-Level: F
in word vector x. For example, if x is the embed-
ding of the word “the”, it will have a much larger • High-Level: G
frequency i.e. f (x) is high.
Using f (x), we define the Inverse Frequency
Matrix Ω: Ω is a diagonal matrix where each entry
on the diagonal is the square inverse frequency of
each word, i.e.
3
The FISTA algorithm can usually converge within 300
1 1 steps, we use 1000 steps nevertheless to avoid any potential
Ω = diag( p ,p , ...)
f (x1 ) f (x2 ) numerical issue.E Low-Level Transformer Factors price family even sat away from park’ s supporters
during the trial itself.
Transformer factor 2 in layer 4 • on 25 january 2010, the morning of park’ s 66th
Explaination: Mind: noun, the element of a birthday, he was found hanged and unconscious in
person that enables them to be aware of the his
world and their experiences. • was her, and knew who had done it", expressing
his conviction of park’ s guilt.
• that snare shot sounded like somebody’ d • jeremy park wrote to the north@-@ west evening
kicked open the door to your mind". mail to confirm that he
• i became very frustrated with that and finally • vanessa fisher, park’ s adoptive daughter,
made up my mind to start getting back into things." appeared as a witness for the prosecution at the
• when evita asked for more time so she could • they played at< unk> for years before joining
make up her mind, the crowd demanded," ¡ ahora, oldham athletic at boundary park until 2010
evita,< when they moved to oldham borough’ s previous
• song and watch it evolve in front of us... almost ground,<
as a memory in your head. • theme park guests may use the hogwarts express
• was to be objective and to let the viewer make up to travel between hogsmead
his or her own mind." • s strength in both singing and rapping while
• managed to give me goosebumps, and those comparing the sound to linkin park.
moments have remained on my mind for weeks • in a statement shortly after park’ s guilty verdict,
afterward." he said he had" no doubt" that
• rests the tir’ d mind, and waking loves to dream • june 2013, which saw the band travel to rock am
•, tracks like’ halftime’ and the laid back’ one ring and rock im park as headline act, the song was
time 4 your mind’ demonstrated a[ high] level of moved to the middle of the set
technical precision and rhetorical dexter • after spending the first decade of her life at the
• so i went to bed with that on my mind". central park zoo, pattycake moved permanently to
•ment to a seed of doubt that had been playing on the bronx zoo in 1982.
mulder’ s mind for the entire season". • south park spoofed the show and its hosts in the
• my poor friend smart shewed the disturbance of episode" south park is gay!"
his mind, by falling upon his knees, and saying his • harrison" sounds like he’ s recorded his vocal
prayers in the street track in one of the park’ s legendary caves".
• donoghue complained that lessing has not made
up her mind on whether her characters are" the salt
of the earth or its sc Transformer factor 30 in layer 4
• release of the new lanois@-@ produced album, Explaination: left: verb, leaving, exiting
time out of mind.
• sympathetic man to illegally" ghost@-@ hack" • did succeed in getting the naval officers
his wife’ s mind to find his daughter. into his house, and the mob eventually left.
• this album veered into" the corridors" of flying • all of the federal troops had left at this point,
lotus’" own mind", interpreting his guest vocalists except totten who had stayed behind to listen to
as" disembodied phantom • saying that he has left the outsiders, kovu asks
simba to let him join his pride
• eventually, all boycott’ s employees left, forcing
Transformer factor 16 in layer 4 him to run the estate without help.
Explaination: Park: noun, ’park’ as the name • the story concerned the attempts of a scientist to
photograph the soul as it left the body.
• allmusic writer william ruhlmann said that" • in time and will slowly improve until he returns
linkin park sounds like a johnny@-@ come@-@ to the point at which he left.
lately to an • peggy’ s exit was a" non event", as" peggy just
•nington joined the five members xero and the left, nonsensically and at complete odds with
band was renamed to linkin park. everything we’ ve
• times about his feelings about gordon, and the• over the course of the group’ s existence, several • factory where the incident took place is the<
hundred people joined and left. unk>(" early light") toy factory(< unk>), owned by
• no profit was made in six years, and the church hong
left, losing their investment. •, a 1934 comedy in which samuel was portrayed
• on 7 november he left, missing the bolshevik in an unflattering light, and mrs beeton, a 1937
revolution, which began on that day. documentary,< unk>
• he had not re@-@ written his will and when • stage effects and blue@-@ red light transitions
produced still left everything to his son lunalilo. give the video a surreal feel, while a stoic crowd
• they continued filming as normal, and when make
lynch yelled cut, the townspeople had left. • set against the backdrop of mumbai’ s red@-@
• with land of black gold( 1950), a story that he light districts, it follows the travails of its personnel
had previously left unfinished, instead. and principal,
• he was infuriated that the government had left • themselves on the chinese flank in the foothills,
thousands unemployed by closing down casinos before scaling the position at first light.
and brothels.
• an impending marriage between her and albert
interfered with their studies, the two brothers left Transformer factor 47 in layer 4
on 28 august 1837 at the close of the term to travel Explaination: plants: noun, vegetation
around europe
• the distinct feature of the main campus is
the mall, which is a large tree – laden grassy area
Transformer factor 33 in layer 4 where many students go to relax.
Explaination: light: noun, the natural agent • each school in the london borough of hillingdon
that stimulates sight and makes things visible: was invited to plant a tree, and the station comman-
der of raf northolt, group captain tim o
• forced to visit the sarajevo television sta- • its diet in summer contains a high proportion
tion at night and to film with as little light as of insects, while more plant items are eaten in
possible to avoid the attention of snipers and autumn.
bombers. • large fruitings of the fungus are often associated
• by the modest, cream@-@ colored attire in the with damage to the host tree, such as that which
airy, light@-@ filled clip. occurs with burning.
• the man asked her to help him carry the case to • she nests on the ground under the cover of plants
his car, a light@-@ brown volkswagen beetle. or in cavities such as hollow tree trunks.
• they are portrayed in a particularly sympathetic • orchards, heaths and hedgerows, especially where
light when they are killed during the ending. there are some old trees.
• caught up" was directed by mr. x, who was • the scent of plants such as yarrow acts as an
behind the laser light treatment of usher’ s 2004 olfactory attractant to females.
video" yeah!" • of its grasshopper host, causing it to climb to the
• piracy in the indian ocean, and the script depicted top of a plant and cling to the stem as it dies.
the pirates in a sympathetic light. • well@-@ drained or sandy soil, often in the
• without the benefit of moon light, the light partial shade of trees.
horsemen had fired at the flashes of the enemy’ s • food is taken from the ground, low@-@ growing
• second innings, voce repeated the tactic late in plants and from inside grass tussocks; the crake
the day, in fading light against woodfull and bill may search leaf
brown. • into his thought that the power of gravity( which
•, and the workers were transferred on 7 july to brought an apple from a tree to the ground) was
another facility belonging to early light, 30 km not limited to a certain distance from earth,
away in< unk> town. • they eat both seeds and green plant parts and
• unk> brooklyn avenue ne near the university of consume a variety of animals, including insects,
washington campus in a small light@-@ industrial crustaceans
building leased from the university. • fyne, argyll in the 1870s was named as the uk ’ stallest tree in 2011. •", or colourless enamel, as in the ground areas, rocks and trees. • produced from 16 to 139 weeks after a forest fire in areas with coniferous trees. This is the end of visualization of low-level transformer factor. Click [D] to go back.
F Mid-Level Transformer Factors • of 32 basidiomycete mushrooms showed that
mutinus elegans was the only species to show
Transformer factor 13 in layer 10 antibiotic( both antibacterial
Explaination: Unit exchange with parentheses: • amphicoelias, it is probably synonymous with
e.g. 10 m (1000cm) camarasaurus grandis rather than c. supremus
because it was found lower in the
• 14@-@ 16 hand( 56 to 64 inches( 140 to •[ her] for warmth and virtue" and mehul s.
160 cm)) war horse is that it was a matter of pride thakkar of the deccan chronicle wrote that she was
to a successful in" deliver[
•, behind many successful developments, defaulted • em( queen latifah) and uncle henry( david alan
on the$ 214 million($ 47 billion) in bonds held by grier) own a diner, to which dorothy works for
60@,@ 000 investors; the van room and board.
• straus, behind many successful developments, • in melbourne on 10 august 1895, presented by
defaulted on the$ 214 million($ 47 billion) in dion boucicault, jr. and robert brough, and the play
bonds held by 60@,@ 000 investors; was an immediate success.
• the niche is 4 m( 13 ft) wide and 3@. • in the early 1980s, james r. tindall, sr. purchased
• with a top speed of nearly 21 knots( 39 km/ h; 24 the building, the construction of which his father
mph). had originally financed
•@ 4 billion( us$ 21 million) — india’ s highest@- • in 1937, when chakravarthi rajagopalachari
@ earning film of the year became the chief minister of madras presidency,
•) at deep load as built, with a length of 310 ft( 94 he introduced hindi as a compulsory
m), a beam of 73 feet 7 inches( 22@. • in 1905 william lewis moody, jr. and isaac h.
•@ 3@-@ inch( 160 mm) calibre steel barrel. kempner, members of two of galveston’
• and gave a maximum speed of 23 knots( 43 km/ • also, walter b. jones, jr. of north carolina sent a
h; 26 mph). letter to the republican conference chairwoman
• 2 km) in length, with a depth around 790 yards( cathy
720 m), and in places only a few yards separated • empire’ s leading generals, nikephoros bryennios
the two sides. the elder, the doux of dyrrhachium in the western
• hull provided a combined thickness of between balkans
24 and 28 inches( 60 – 70 cm), increasing to • in bengali as< unk>: the warrior by raj chakra-
around 48 inches( 1@. borty with dev and mimi chakraborty portraying
• switzerland, austria and germany; and his mother, the lead roles.
lynette federer( born durand), from kempton park, • on 1 june 1989, erik g. braathen, son of bjørn g.,
gauteng, is took over as ceo
•@ 2 in( 361 mm) thick sides.
•) and a top speed of 30 knots( 56 km/ h; 35 mph).
•, an outdoor seating area( 4@,@ 300 square feet( Transformer factor 25 in layer 10
400 m2)) and a 2@,@ 500@-@ square@ Explaination: Attributive Clauses
• which allows japan to mount an assault on
Transformer factor 24 in layer 10 the us; or kill him, which lets the us discover japan’
Explaination: Male name s role in rigging american elections —
• certain stages of development, and constitutive
• divorcing doqui in 1978, michelle married heterochromatin that consists of chromosome
robert h. tucker, jr. the following year, changed her structural components such as telomeres and
name to gee tucker, moved back centromeres
• divorced doqui in 1978 and married new orleans • to the mouth of the nueces river, and oso bay,
politician robert h. tucker, jr. the following year; which extends south to the mouth of oso creek.
she changed her name to gee tucker and became •@,@ 082 metric tons, and argentina, which ranks
• including isabel sanford, when chuck and new 17th, with 326@,@ 900 metric tons.
orleans politician robert h. tucker, jr. visited • of$ 42@,@ 693 and females had a median
michelle at her hotel.income of$ 34@,@ 795. ship, they died of melancholy, having refused to
• ultimately scored 14 points with 70 per cent eat or drink.
shooting, and crispin, who scored twelve points • on 16 september 1918, before she had even gone
with 67 per cent shooting. into action, she suffered a large fire in one of her
• and is operated by danish air transport, and one 6@-@ inch magazines, and
jetstream 32, which seats 19 and is operated by • orange goalkeeper for long@-@ time starter john
helitrans. galloway who was sick with the flu.
• acute stage, which occurs shortly after an initial • in 1666 his andover home was destroyed by fire,
infection, and a chronic stage that develops over supposedly because of" the carelessness of the
many years. maid".
•, earl of warwick and then william of lancaster, • the government, on 8 february, admitted that
and ada de warenne who married henry, earl of the outbreak may have been caused by semi@-@
huntingdon. processed turkey meat imported directly
• who ultimately scored 14 points with 70 per cent •ikromo came under investigation by the justice
shooting, and crispin, who scored twelve points office of the dutch east indies for publishing
with 67 per cent shooting. several further anti@-@ dutch editorials.
• in america, while" halo/ walking on sunshine" • that he could attend to the duties of his office,
charted at number 4 in ireland, 9 in the uk, 10 in but fell ill with a fever in august 1823 and died in
australia, 28 in canada office on september 1.
• five events, heptathlon consisting of seven events, •@ 2 billion initiative to combat cholera and the
and decathlon consisting of ten< unk> every multi construction of a$ 17 million teaching hospital in<
event, athletes participate in a unk
•@-@ life of 154@,@ 000 years, and 235np with • he would not hear from his daughter until she
a half@-@ life of 396@. was convicted of stealing from playwright george
• comfort, and intended to function as the prison, axelrod in 1968, by which time rosaleen
and the second floor was better finished, with a • relatively hidden location and proximity to
hall and a chamber, and probably operated as the piccadilly circus, the street suffers from crime,
•b, which serves the quonset freeway, and exit 7a, which has led to westminster city council gating
which serves route 402( frenchtown road), another off the man in
spur route connecting the
Transformer factor 50 in layer 10
Transformer factor 42 in layer 10 Explaination: Doing something again, or
Explaination: Some kind of disaster, something making something new again
unfortunate happened
• 2007 saw the show undergo a revamp,
• after the first five games, all losses, jeff which included a switch to recording in hdtv, the
carter suffered a broken foot that kept him out of introduction
the line@-@ up for • during the ship’ s 1930 reconstruction; the maxi-
• allingham died of natural causes in his sleep at 3: mum elevation of the main guns was increased to+
10 am on 18 july 2009 at his 43 degrees, increasing their maximum range from
• upon reaching corfu, thousands of serb troops 25@,
began showing symptoms of typhus and had to be • hurricane pack 1 was a revamped version of story
quarantined on the island of< un mode; team ninja tweaked the
• than a year after the senate general election, the • she was fitted with new engines and more
september 11, 2001 terrorist attacks took place, powerful water@-@ tube boilers rated at 6@
with giuliani still mayor. • from 1988 to 2000, the two western towers were
• the starting job because fourth@-@ year junior substantially overhauled with a viewing platform
grady was under suspension related to driving provided at the top of the north tower.
while intoxicated charges. • latest missoula downtown master plan in
• his majesty, but as soon as they were on board 2009, increased emphasis was directed towardYou can also read

















































