Time Dependencies Between Equity Options Implied Volatility Surfaces and Stock Loans
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Degree Project in Financial Mathematics
Second Cycle, 30 Credits
Time Dependencies Between Equity
Options Implied Volatility Surfaces
and Stock Loans
A Forecast Analysis with Recurrent Neural Networks and
Multivariate Time Series
SIMON WAHLBERG
Stockholm, Sweden 2022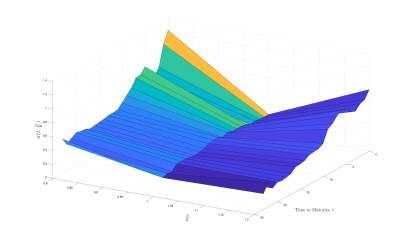
ABSTRACT
Abstract
Synthetic short positions constructed by equity options and stock loan short sells are
linked by arbitrage. This thesis analyses the link by considering the implied volatility
surface (IVS) at 80%, 100%, and 120% moneyness, and stock loan variables such as
benchmark rate (rt ), utilization, short interest, and transaction trends to inspect time-
dependent structures between the two assets. By applying multiple multivariate time-
series analyses in terms of vector autoregression (VAR) and the recurrent neural networks
long short-term memory (LSTM) and gated recurrent units (GRU) with a sliding window
methodology. This thesis discovers linear and complex relationships between the IVS
and stock loan data. The three-day-ahead out-of-sample LSTM forecast of IV at 80%
moneyness improved by including lagged values of rt and yielded 19.6% MAPE and
forecasted correct direction 81.1% of samples. The corresponding 100% moneyness GRU
forecast was also improved by including stock loan data, at 10.8% MAPE and correct
directions for 60.0% of samples. The 120% moneyness VAR forecast did not improve
with stock loan data at 26.5% MAPE and correct directions for 66.2% samples. The
one-month-ahead rt VAR forecast improved by including a lagged IVS, at 25.5% MAPE
and 63.6% correct directions. The presented data was optimal for each target variable,
showing that the application of LSTM and GRU was justified. These results indicate
that considering stock loan data when forecasting IVS for 80% and 100% moneyness is
advised to gain exploitable insights for short-term positions. They are further validated
since the different models yielded parallel inferences. Similar analysis with other equity
is advised to gain insights into the relationship and improve such forecasts.
Keywords
Recurrent neural networks, RNN, long short-term memory, LSTM, gated recurrent units,
GRU, vector autoregression, VAR, implied volatility surface, stock loan, equity options,
multivariate time-series analysis, financial mathematics.
ii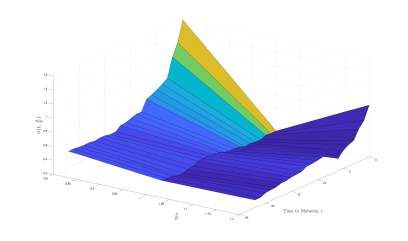
SAMMANFATTNING
Sammanfattning
Syntetiska kortpositioner konstruerade av aktieoptioner och blankning med aktielån är
kopplade med arbitrage. Denna tes analyserar kopplingen genom att överväga den
implicerade volatilitetsytan vid 80%, 100% och 120% moneyness och aktielånvariabler
såsom referensränta (rt ), låneutnyttjande, låneintresse, och transaktionstrender för att
granska tidsberoende strukturer mellan de två tillgångarna. Genom att tillämpa multi-
pel multidimensionell tidsserieanalys såsom vektorautoregression (VAR) och de rekursiva
neurala nätverken long short-term memory (LSTM) och gated recurrent units (GRU).
Tesen upptäcker linjära och komplexa samband mellan implicerade volatilitetsytor och
aktielånedata. Tre dagars LSTM-prognos av implicerade volatiliteten vid 80% money-
ness förbättrades genom att inkludera fördröjda värden av rt och gav 19, 6% MAPE
och prognostiserade korrekt riktning för 81, 1% av prover. Motsvarande 100% money-
ness GRU-prognos förbättrades också genom att inkludera aktielånedata, resulterande
i 10, 8% MAPE och korrekt riktning för 60, 0% av prover. VAR-prognosen för 120%
moneyness förbättrades inte med alternativa data på 26, 5% MAPE och korrekt rik-
tning för 66, 2% av prover. En månads VAR-prognos för rt förbättrades genom att
inkludera en fördröjd implicerad volatilitetsyta, resulterande i 25, 5% MAPE och 63, 6%
korrekta riktningar. Presenterad statistik var optimala för dessa variabler, vilket visar
att tillämpningen av LSTM och GRU var motiverad. Därav rekommenderas det att
inkludera aktielånedata för prognostisering av implicerade volatilitetsytor för 80% och
100% moneyness, speciellt för kortsiktiga positioner. Resultaten valideras ytterligare
eftersom de olika modellerna gav dylika slutsatser. Liknande analys med andra aktier
är rekommenderat för att få insikter i förhållandet och förbättra sådana prognoser.
Nyckelord
Rekursiva neurala nätverk, LSTM, GRU, VAR, implicerade volatilitetsytor, aktielån,
aktieoptioner, multidimensionell tidsserieanalys, finansiell matematik.
iii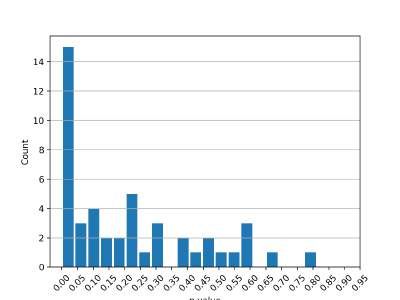
ACKNOWLEDGEMENTS
Acknowledgements
I want to thank SEB Equities, especially Jonas Andersson and Jonne Viitanen for
your support with data gathering, insights on financial markets, and machine learn-
ing throughout this thesis.
I would also like to thank Boualem Djehiche for your helpful and knowledgeable in-
puts. Also Camilla Landén who further improved this thesis by conducting adequate
and informative seminars.
iv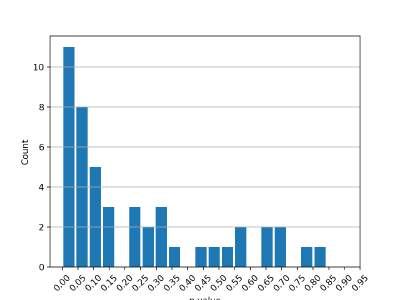
CONTENTS
Contents
1 Introduction 1
1.1 European Equity Options . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Stock Loans . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 The Link . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 Research Questions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.5 Summary of Findings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.6 Outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Mathematical Background 8
2.1 Black & Scholes Market Model . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Accuracy Measures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 VAR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4 LSTM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.5 GRU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.6 Dummy Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3 Method 17
3.1 Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Stock Category . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3 Data Normalization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.4 Granger Causality . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.5 Johansen’s Cointegration Test . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.6 Augmented Dickey-Fuller . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.7 Lag Optimization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.8 Forecast Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.9 Feature Selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.10 Hyperparameter Selection . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
v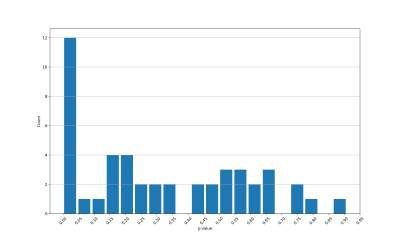
CONTENTS
4 Results 24
4.1 Feature Selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.2 Forecast Errors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.3 Forecasts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.4 Variable Influence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.5 Implied Volatility Surface . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5 Discussion 31
5.1 Model Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.2 The Relationship Seen From RMSE . . . . . . . . . . . . . . . . . . . . . 33
5.3 Arbitrage and Linear Dependence . . . . . . . . . . . . . . . . . . . . . . . 35
5.4 Using the Forecasted IVS . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.5 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
6 Conclusion 39
References 41
A Put-Call Parity 43
B Graphs and Tables 44
vi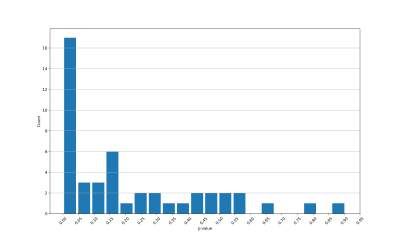
LIST OF FIGURES
List of Figures
1.1 Payoff functions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1 IVS example . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 LSTM architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 GRU architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.1 Autocorrelation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.1 IV out-of-sample forecasts . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.2 rt out-of-sample forecasts . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.3 IVS forecast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
B.1 Granger causality . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
B.2 Feature selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
B.3 GRU forecasts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
B.4 LSTM forecasts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
B.5 VAR forecasts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
vii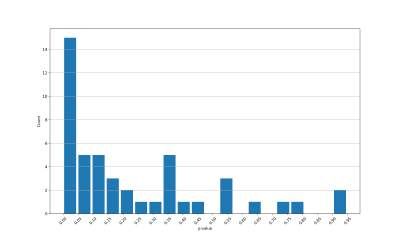
LIST OF TABLES
List of Tables
3.1 Raw data set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2 Normalized data set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3 Granger causality, three stocks . . . . . . . . . . . . . . . . . . . . . . . . 21
3.4 Johansen’s cointegration test . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.5 Lag evaluation for VAR . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.1 Feature selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.2 Forecast errors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.3 IVS: Granger and feature selection . . . . . . . . . . . . . . . . . . . . . . 29
4.4 rt : Granger and feature selection . . . . . . . . . . . . . . . . . . . . . . . 30
B.1 Chosen hyperparameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
B.2 Augmented Dickey-Fuller test . . . . . . . . . . . . . . . . . . . . . . . . . 50
B.3 Complete list of forecast errors . . . . . . . . . . . . . . . . . . . . . . . . 51
viii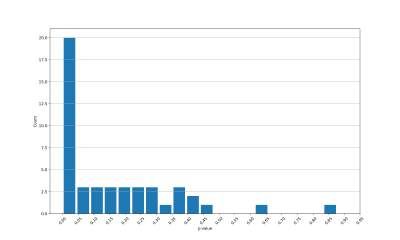
CHAPTER 1. INTRODUCTION
Chapter 1
Introduction
Recurrent neural networks (RNN), such as long short-term memory (LSTM) and gated
recurrent units (GRU) have been successfully applied to financial markets in forecast-
ing and contextualizing complex structures (Bernales and Guidolin, 2014), (Fischer and
Krauss, 2018), (Hamayel and Owda, 2021). Option pricing and its different methodolo-
gies have been thoroughly studied, including forecasting these. One important variable
is namely the implied volatility surface (IVS) and its evidential impact on option pricing
in the Black and Scholes market model (Goncalves and Guidolin, 2006), (Audrino and
Colangelo, 2010). Some researchers have included alternative data, such as news feeds in
their implied volatility (IV) forecast and have resulted in more accurate forecasts (Xiong,
Nichols, and Shen, 2015), (Gu et al., 2020). This thesis will continue the exploration
of alternative data in the form of stock loan quantities, and cover both implications.
This will be done through applications of multivariate time-series analysis, specifically
modeled with vector autoregression (VAR), to gain statistically relevant insights into
this relationship. Further application of LSTM and GRU will be conducted in an at-
tempt to improve the VAR forecasts and analyze if similar inferences can be drawn from
these. Equity options and their related stock loan alternatives are bound by arbitrage
(Cocquemas, 2017), which can be shown by constructing alternative portfolios, with
similar or even equal payoffs. This could imply the relationship in question, which will
be quantitatively analyzed throughout this thesis.
1.1 European Equity Options
A European equity call or put option is the right to buy or sell certain underlying equity
on a specified date on a long position. Conversely, for the short holder, it is the obligation
11.1. EUROPEAN EQUITY OPTIONS CHAPTER 1. INTRODUCTION
to sell or buy the underlying equity on the specified date. A European option may only
be exercised on the maturity date. The famous Black and Scholes market model is
assumed for this thesis. The put-call parity holds if and only if the implied volatilities
σCall (t, St /K) = σP ut (t, St /K), (1.1)
which is proven in Appendix A, this is however only true in theory, these may differ
empirically. Equation 1.1 confirms a one-to-one ratio between the IVS for a call and
put option. The standard Black and Scholes model is thus extended to handle an IVS,
depending on time and strike. This is important for this thesis since IV data is extracted
from three strikes, out of the money (OTM), at the money (ATM), and in the money
(ITM), specifically for 80%, 100%, and 120% moneyness. Furthermore, the options con-
sidered have closest time to maturity, that is, if an option reaches maturity it is replaced
by the next closest to maturity option, and so forth.
A rudimentary example of short selling is possible to construct from both calls and
puts. Namely, the long holder of a put is not obliged to possess the underlying stock,
but may still sell it at a future date at a fixed price. Likewise, for the short holder of a
call, the difference is the obligation to sell the stock at maturity. In terms of arbitrage
theory, there is of course a premium to be paid by the long holder, which in this market
setting is determined by Black and Scholes partial differential equation (PDE) and its
governing Itô diffusion’s, presented in subsection 2.1. IV is an important variable in op-
tion pricing, the parameter is the market’s expectation of the volatility for the underlying
stock until maturity (Björk, 2009). An increase in σ(t, St /K) and all other parameters
equal will imply a premium increase, conversely, if σ(t, St /K) decreases, the premium
will decrease. Being able to forecast IV more accurately is, trivially, compelling for any
market participant.
Goncalves and Guidolin (2006) considered an IVS, specifically the one generated by daily
closing prices from the S&P 500 index options. Their framework consists of the empiri-
cally proven assumption that the surface is time and strike varying (Christoffersen and
Jacobs, 2004), (Dumas, Fleming, and Whaley, 1998), with predictable patterns. Their
approach consists of applying vector autoregression, resulting in more accurate forecasts
and significant returns. This thesis will partly build on their framework, however with
58 single equity options on the Swedish market instead of an index. It will also include
applications of RNN in an attempt to further improve the predictive capabilities. Au-
21.2. STOCK LOANS CHAPTER 1. INTRODUCTION
drino and Colangelo (2010) further improved Goncalves and Guidolins work by applying
semi-parametric forecasts using regression trees and a boosting algorithm. Their results
indicate better forecast accuracy, robustness to information loss, and time series discon-
tinuities, also advising that a machine learning approach can be fruitful. Bernales and
Guidolin (2014) finds similar predictability patterns as Goncalves and Guidolin in eq-
uity options, they propose a VARX model to predict the implied volatility surface which
yields abnormal returns, however not resulting in arbitrage opportunities since they are
lowered by transaction costs (Bernales and Guidolin, 2014). They propose further inves-
tigation to analyze possible relationships between equity options and their underlying
equities. Medvedev and Wang (2022) compared traditional models, such as VAR with
LSTM and convolutional LSTM in forecasting S&P 500 index option IVS. Finding that
the two RNNs outperformed the traditional models, the convolutional LSTM was the
most accurate. They mention that hyperparameter tuning such as grid search (which is
applied in this thesis) could make LSTM competitive against convolutional LSTM. It is
noteworthy that they did not use alternative data, only options data. Similar studies
include the application of machine learning algorithms, such as naive Bayes and adap-
tive boosting to predict the direction of the fear index (VIX) compared to standard
economical models (S. D. Vrontos, Galakis, and I. D. Vrontos, 2021). They found that
the application of machine learning yielded better forecasts.
1.2 Stock Loans
Stock lending is a subset of security loans, including two parts, lender and borrower.
An elemental case is that the borrower borrows stocks from the lender, and are then
instantly sold (short sell). The lender usually receives an equivalent value of collateral
from the borrower to compensate for the counterparty risk, in case the borrower de-
faults, the lender keeps the collateral. In exchange for borrowing stocks, the borrower is
obliged to pay an interest rate, proportional to the underlying stocks value, denoted rt .
The floating part may increase drastically if the underlying asset price increases, which
may be a short squeeze market reaction. When the stocks are returned to the lender,
collateral is returned to the borrower (ISLA, 2010), stock lending can be utilized for
prospecting and hedging purposes. As mentioned in subsection 1.1, a short holder of a
call option is not obliged to possess the underlying stock, if the long holder chooses to
exercise, the short holder is obliged to sell the underlying stocks to the strike price. If
the short holder sees for example, a prospecting opportunity, it may instead be valid to
borrow stocks to sell.
31.2. STOCK LOANS CHAPTER 1. INTRODUCTION
The nature of this asset is quite risky in the prospecting sense, if the stocks value
increases drastically the borrower is inclined to either pay an expensive rate and col-
lateral or buy the stock at a much higher price. This was the case when many market
participants had short positions in GameStop in 2021, this was established by other
market participants who took long positions. Subsequently, large investors also took
long positions due to the market’s virtual bull scenario. Short holders urgently tried to
buy back their short positions, however, since there were many short positions, the price
iteratively increased. Further examples can be found in Volkswagen 2008 and KaloBios
2015.
Short interest is the percentage of stocks that are sold short, which is a natural in-
dication of the market’s bear scenario anticipation. A relative increase in short interest
implies that further market participants anticipate the stock to decline in value. Con-
versely, if the short interest decreases it implies that the market expects bull scenarios.
This statistic was very high in the GameStop example, resulting in a short squeeze.
Utilization is the percentage of loaned stocks relative to lendable stocks, similar to short
interest because it quantifies the market’s short interest. However, it might not be as
indicative on its own due to the dependency on short quantity which may differ vastly
between stocks. Days to cover inform the number of days in which companies short sold
stocks takes until covered, that is, bought back from the market. Many days to cover
indicate an increased risk for short squeezes.
Xia and Zhou (2007) considered the instrument as an American option in the Black
and Scholes market model with a time-varying strike. Chen, Xu, and Zhu (2015) val-
uated stock loans based on a stochastic interest rate framework, applying the model
proposed by Xia and Zhou. It is however misrepresentative of modern stock loans due
to several reasons: It is assumed that a loan is defaultable so that the lender keeps the
principal. If the stock price declines the lender will cancel the loan and keep princi-
pal. In contrast to increased stock price, the lender will get the stocks back and return
principal, hence creating arbitrage opportunities. It is unfortunate since the Black and
Scholes model can be easily applied to this framework. Collateral is instead calculated
each day to cover mark to market movements to generate margin calls, default is not a
real possibility for lenders. Options theory has been further applied to price long-term
stock loans, Kashyap (2016) applies exotic options theory and assumes that a long-
term security loan has optionality due to the availability of shares being modeled as a
41.3. THE LINK CHAPTER 1. INTRODUCTION
Geometric-Brownian-Motion. Specifically, Kashyap applies rainbow and basket binary
barrier American options to construct a pricing framework. Kashyap runs numerical
simulations and confirms that it is a practical and efficient tool. His framework is more
realistic in the modern stock loan setting than the previous articles. However, his model
will not be used in this study, it merely acts as a complementary framework.
1.3 The Link
Cocquemas (2017) examined the possibility of linking the security loan market with the
options market. He constructed a synthetic short position by buying a put and selling a
call, with equal strikes, replicating a stock loan short sell, then extracting IV and implied
lending fee from the trade. These two term structures were shown to be, statistically
significantly positively related by applying panel regression, with and without time fixed
effects. However, he concluded that the loan fee prediction was not especially improved
by IV, just slightly. It is still noteworthy that a relationship is existent between these
variables. This thesis will further investigate this relationship, and only consider Euro-
pean options, however with a dissimilar methodology. Cocquemas only considers ATM
options, whereas this thesis considers OTM -, ATM -, and ITM options. Furthermore,
panel regression will not be applied, instead, VAR, LSTM, and GRU.
Cocquemas study is quite illustrative in the context of linking the two assets by replicat-
ing a short position through options. There are many strategies to yield similar payoff
functions. Consider the very simplified payoff of a short sell, averting the margin costs,
transaction fees, and rate, presented in figure 1.1a. It is essentially equal to the payoff
function of a synthetic short sell. As Cocquemas infer, the two portfolios are linked by
arbitrage, and should therefore obtain similar transactional costs. That is, the premium,
margins, rate, and fees should have a theoretical relationship, at least in the Black and
Scholes market model which, by definition, is arbitrage-free (Björk, 2009) (which any
reasonable market model should be). Generally, call options OTM are cheaper than put
options OTM (this can be seen in the IVS presented in figure 2.1, where the skew is
apparent between 80%- and 120% moneyness). If a portfolio manager is bearish, it is
reasonable to prospect on an OTM put option by selling two OTM call options, which
in this example yields an equal premium. That is, financing the downside by selling the
upside. It does however not yield as much leverage compared to the short- or synthetic
short position. This strategy is known as risk reversal, which hedges some unwanted
fluctuations in the stock price, but somewhat mitigates eventual payoffs, which can be
51.4. RESEARCH QUESTIONS CHAPTER 1. INTRODUCTION
(a) Short sell payoff (b) Payoff function for a (c) Portfolio payoff with a
function, the graph does not synthetic short position, the long put written on K = 80
consider transaction fees, portfolio consists of a long and two short calls written
rates, or margins, only the put and a short call written on K = 120, equal tenor, the
very simplified asset payoff. on equal strike and tenor. calls financed the put.
Figure 1.1: Simplified payoff functions for three portfolios.
seen by inspecting figure 1.1c. With similar arguments as for synthetic short positions,
this might indicate further relations with OTM and ITM IV and stock loan rates.
1.4 Research Questions
This thesis will attempt to answer the following questions.
• Is it possible to infer a predictive, time-dependent relationship between equity
options IVS and their related stock loan rate rt by applying multivariate time-
series analysis and RNNs?
• Is it possible to accurately forecast the implied volatility surface and loan rate
through the application of VAR? Is it further possible to improve these forecasts
by applying LSTM and GRU?
• Will LSTM and GRU give similar inferences as VAR?
1.5 Summary of Findings
This thesis discovers linear and complex relationships between the IVS and stock loan
data. The linear dependencies are prominent for some stocks and improve the VAR
forecast accuracy for both implications, that is, for IVS and loan rate predictions. These
forecasts are further improved by applying LSTM and GRU, the complex relationships
are prominent by applying feature selection where IV for 80% and 100% moneyness
is enhanced by including stock loan data. It is not the case for 120% moneyness IV
and the loan rate, it is shown to be difficult to forecast rt due to much noise. The
61.6. OUTLINE CHAPTER 1. INTRODUCTION
application of LSTM and GRU is shown to be beneficial to gain further insights into
this relationship and also improve forecasts. The inferences drawn from these models are
further validated by comparison of the different models. This thesis contributes to the
research subject by applying new methods for studying this relationship, especially for
80%- and 120% moneyness which has not been previously researched (to the author’s
limited knowledge), to gain forecasting accuracy and link these assets. The forecast
instrument is furthermore shown to be prominent in following trends and directional
movements which can be exploited for short-term positions.
1.6 Outline
Chapter 2 presents the mathematical background and some previously researched appli-
cations, and chapter 3 presents the methodology following the mathematical background.
Chapter 4 presents results such as forecast errors, feature importance, and forecast plots
for the IVS and rt . An analysis and discussion is presented in chapter 5 which is sum-
marized in chapter 6.
7CHAPTER 2. MATHEMATICAL BACKGROUND
Chapter 2
Mathematical Background
2.1 Black & Scholes Market Model
The continuous, arbitrage-free (Björk, 2009) market model developed by Fischer Black,
Myron Scholes, and Robert C. Merton follows from the two asset Itô diffusion
dSt = rSt dt + σSt dWtQ ,
(2.1)
dBt = rBt dt,
where St is the spot price for a risky asset and Bt a risk-free asset. Further assuming
a constant, risk-free interest rate r, and where dWtQ is a Wiener process under the
risk-neutral (martingale) measure Q. σ refers to the implied volatility and is assumed
constant in standard Black and Scholes. The price of a European option at time t is
derived from the Black-Scholes equation
∂V (t, x) 1 2 2 ∂ 2 V (t, x) ∂V (t, x)
+ σ x 2
+ rx − rV (t, x) = 0,
∂t 2 ∂x ∂x (2.2)
V (T, x) = Φ(x),
where Φ(x) is the value process and V (T, x) the price at maturity. σ is determined by
observing the price of an option and invert these equations. However, σ has been shown
to be non-constant (Christoffersen and Jacobs, 2004), (Dumas, Fleming, and Whaley,
1998), and varies with observed parameters, it is customary to plot it as a function of
t and St /K which is presented in figure 2.1, considering a call option. At maturity, IV
tends to increase, it also illustrates the IV smile, that is, IV is lowest for ATM options
and increases in both directions. However, it is more reminiscent of a skew, where IV
82.2. ACCURACY MEASURES CHAPTER 2. MATHEMATICAL BACKGROUND
Figure 2.1: Smoothed IVS for an option with one month to maturity.
at 80% moneyness is larger than at 120% moneyness. It is further apparent that the
volatility increases as maturity approaches. This thesis will present another method of
approximating σ(t, St /K), namely by multivariate time-series analysis by applying VAR,
LSTM, and GRU.
2.2 Accuracy Measures
Mean square error is defined as
n
1X
MSE = (yi − ŷi )2 (2.3)
n
i=1
where ŷi is the predicted variable. Root mean squared error is simply
√
RMSE = MSE. (2.4)
92.3. VAR CHAPTER 2. MATHEMATICAL BACKGROUND
Another accuracy measure to be used is the percentage of correct directional forecast,
n
1X
PCDF = 1i,PCDF
n
i=1
1 if yi+1yi−yi < −c and ŷi+1yi−yi < −c
(2.5)
1 if yi+1 −yi > c and ŷi+1 −yi > c
1i,PCDF = yi
yi+1 −yi
yi
ŷi+1 −yi
1 if | yi | ≤ c and | yi | ≤ c
0 else,
where c = 0.1%. Also, mean absolute percentage error
n
100 X yi − ŷi
MAPE = | |. (2.6)
n yi
i=1
2.3 VAR
VAR is a multivariate time-series model, assuming a linear relationship between the
endogenous variables y t and their predecessors up to a certain lag p. A VAR(p) model
is defined as
p
X
y t = φ0 + Φi y t−i + εt , (2.7)
i=1
where φ0 is the m-variate intercept, Φi is the m × m variate coefficient matrix for lag
i, and εt ∼ N (0, Σε ) is m-variate white noise, it is assumed that cov(εt , εs ) = 0 for t ̸=
s. By implementing the following compact form of equation 2.7,
Y = ϕZ + ϵ (2.8)
where Y := (y1 , . . . , y T ), ϕ := (φ0 , Φ1 , . . . , Φp ), Z t := (1, y t , . . . , y t−p+1 )T ,
Z := (Z 0 , . . . , Z T −1 ), ϵ = (ε1 , . . . , εT ), it can be proven that the least square estimator
of ϕ is
ϕ̂ = ϕ + ϵZ T (ZZ T )−1 (2.9)
(Lütkepohl, 2005). It is further assumed that the processes y t are stationary, that is
E[y t ] = µ ∀t ,
(2.10)
E[(y t − µ)(y t−h − µ)T ] = Γy (h) = Γy (−h)T ∀t , h = 0, 1, 2 . . . .
102.3. VAR CHAPTER 2. MATHEMATICAL BACKGROUND
Where the first condition means that y t has a finite and equal mean vector for all times,
and the second that autocovariance does not depend on t but only on the difference in
periods h. The time-series data for volatility, rates, and trade prices are however usually
not stationary. To test this, an augmented Dickey-Fuller test is necessary, which is a
unit root test, conducted for each series (y)it∈(p,T ) , i = 1, 2, . . . , m, where
yti = α + βt + γyt−1
i i
+ γ1 ∆yt−1 + · · · + γp ∆yt−p + εit . (2.11)
The model imposes that the disturbances are white noise if α = 0 and β = 0. The
statistic is defined as
T (γ̂ − 1)
DFγ = , (2.12)
1 − γ̂1 . . . γ̂p
where γ̂ is the OLS estimator of γ and T is the time series sample size. If DFγ is less
than a critical value with regards to the t-distribution then the null hypothesis of γ = 0
is rejected, that is, no unit root is present and the time-series can be regarded as sta-
tionary (Greene, 2012). If not, first-order differences are applied to the series, this is
iterated until DFγ is less than the critical value.
Granger causality is a test to assess bivariate relationships between time series, specifi-
j
cally to explore if yt−τ cause yti for i ̸= j and τ = 1, 2, . . . , p. In probabilistic terms,
j
P(yti ∈ A|I(t − 1)) ̸= P(yti ∈ A|yt−τ ∈
/ I(t − 1)), (2.13)
that is, the probability of ytj being in set A given information of everything that has
happened until that point is not equal to the probability of ytj being in set A given
j
information of everything that has happened excluding information generated by yt−τ .
j
If equation 2.13 holds, it is said that yt−τ Granger causes yti (Greene, 2012). Numerically,
the statistic boils down to the VAR(p) models
p p
(1) (1) (2)
X X
yt = Φ11,i yt−i + Φ12,i yt−i + ε1,t ,
i=1 i=1
p p (2.14)
(2) (1) (2)
X X
yt = Φ21,i yt−i + Φ22,i yt−i + ε2,t ,
i=1 i=1
if the variance of ε1,t or ε2,t is reduced by including lagged values of y (2) or y (1) respec-
tively, then y (2) Granger causes y (1) and conversely, with confidence level α (Geweke,
1982).
112.4. LSTM CHAPTER 2. MATHEMATICAL BACKGROUND
Johansen’s cointegration test is a method to further assess relationships between multiple
time series, in contrast to the Granger test. For a detailed explanation of the method,
see Lütkepohl (2005).
2.4 LSTM
LSTM was discovered by Hochreiter and Schmidhuber which is a permutation of RNN.
Vanilla RNN suffers from exploding and vanishing gradients, making them difficult to
train. Instead, the LSTM algorithm has a constant error carousel to normalize gradients
by using shortcut connections (Ushiku, 2021). This enables long-term dependencies
which could not be considered before, more than 1000 discrete time steps to be specific
(Hochreiter and Schmidhuber, 1997). That is, being able to store relevant data for
substantially longer periods than RNN to contextualize input data. Each cell has several
gates, a forget gate, which is described as
" #
xt
ft = ς(Wf + bf ), (2.15)
ht−1
1
at time t. Where ς(x) = 1+e−x
is the sigmoid function, Wf a weight matrix, xt is the
current input vector with dimension d, ht−1 is the previous short term memory and bf
a bias vector. An input gate
" #
xt
int = ς(Win + bin ), (2.16)
ht−1
with similar notations as before. To decide what new information should be stored, int
is multiplied with new possible values
" #
xt
c̃t = tanh (Wc + bc ). (2.17)
ht−1
ex −e−x
Where tanh(x) = ex +e−x
is the hyperbolic tangent function. Then, the next cell state is
determined as
ct = ft ⊙ ct−1 + int ⊙ c̃t . (2.18)
122.4. LSTM CHAPTER 2. MATHEMATICAL BACKGROUND
Where ⊙ denotes the Hadamard product. Finally, an output gate
" #
xt
ot = ς(Wo + bo ) (2.19)
ht−1
is considered, which produces the next short-term memory as
ht = ot ⊙ tanh(ct ). (2.20)
The architecture of the algorithm is presented in figure 2.2.
This algorithm was applied to financial data such as stock prices and volatility by Fischer
and Krauss (2018). Specifically, they compared daily returns for S&P 500 stocks based on
LSTM, logistic regression, random forest classification, and standard deep nests. Their
study showed that a single input LSTM network with a sliding window methodology
can find patterns and contextualize data which is usually a manual constriction when
modeling financial time series data. It is also capable of extracting meaningful features
from noisy financial data. Their study shows statistically, and economically significant
returns, 0.46 % before transaction costs. Their LSTM network outperforms the bench-
mark algorithms (Fischer and Krauss, 2018), this return is based on a trading strategy
to rank stocks based on the classification of expected performance outcomes. However,
it is noteworthy that LSTM outperformed the general market from 1992 to 2009, from
2010 the market seems to have been accustomed to the application, hence the return
was worse than prior but still significant.
Lin et al. (2021) studied the accuracy improvement by applying Complete Ensemble
Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) to LSTM. Ordi-
nary EMD is used to reduce noise in data, Lin et al. used it on financial time-series
data, specifically S&P500 and CSI300 prices. They compare this algorithm to support
vector machines, Elman networks, and wavelet neural networks. It is concluded that
CEEMDAN-LSTM outperforms the compared algorithms and yields accurate out-of-
sample forecasts. This thesis will however not use EMD or CEEMDAN, but rather
acknowledge the possible fruitfulness of applying these to the presented RNNs.
Research conducted by Xiong, Nichols, and Shen (2015) considered S&P 500 volatil-
ity forecasting in terms of alternative data. Specifically with regards to Google domestic
trends, in the context of word searches somewhat related to the index. Compared to
132.5. GRU CHAPTER 2. MATHEMATICAL BACKGROUND
linear Ridge/Lasso and autoregressive GARCH, LSTM showed significantly better ac-
curacy in terms of RMSE and MAPE. Their results are promising in the sense that deep
learning networks, such as LSTM with alternative data, can more accurately predict
market behavior.
Figure 2.2: Architecture of an LSTM at a discrete time step t with input vector xt , short
term memory ht , cell state ct , forget gate ft , information gate int , possible cell state
c̃t , output gate ot , and Wf , Win , Wc , Wo weights for the corresponding gates. Where
furthermore ς is the sigmoid function, tanh the hyperbolic tangent function and ⊙ the
Hadamard product.
2.5 GRU
GRU is a less complex version of the LSTM algorithm with only two gates (Cho et al.,
2014). Similar to LSTM, it solves the problem of exploding or vanishing gradients by
introducing sigmoid functions to normalize the data processing through gates. First
represented as a reset gate
ret = ς(Wre xt + Ure ht−1 + bre ), (2.21)
142.5. GRU CHAPTER 2. MATHEMATICAL BACKGROUND
ret with similar notations as before (see subsection 2.4), where Wre and Ure are weight
matrices. Secondly as an update gate
upt = ς(Wup xt + Uup ht−1 + bup ). (2.22)
Thereafter, new possible memory contents are introduced
h̃t = tanh(Wh xt + Uh (ret ⊙ ht−1 ) + bh ), (2.23)
and updates the proposed memory unit as
ht = (1 − upt ) ⊙ ht−1 + upt ⊙ h̃t . (2.24)
A trivial limit implies
lim ht → ht−1 , (2.25)
upt →0
the hidden state completely forgets the current input and only remembers the previous
memory state. Conversely, if
lim ht → h̃t (2.26)
upt →1
the hidden state ignores the previous input and only remembers the proposed memory
unit. The network is thus qualified to forget and remember relevant input based on
the learned weights. Noticeable in figure 2.3, and comparatively with figure 2.2, is the
decreased complexity, with only two gates, ret and upt , without a cell state ct .
Similar to Xiong, Nichols, and Shen (2015), Gu et al. (2020), applied GRU on real-
ized volatility data, with alternative data, specifically news feeds. They found that a
GRU, with a single input parameter, and its extension, GRU-AI, with multiple features
and single input, gave more accurate predictive results than the linear time-series models
HAR-RV, and HAR-RV-AI respectively. The model was set up with a sliding window
scheme and evaluated based on four loss functions. Noteworthy is that GRU-AI outper-
formed GRU in terms of those statistics, but only slightly. They further implied that,
trivially, it is easier to infer variable weights and relationships between these in the linear
models, which is applicable to this thesis as well.
Hamayel and Owda (2021), applied LSTM and GRU to predict cryptocurrency prices,
their raw data only covered prices at open, high, low, and close. They found that GRU
performed more accurately than LSTM, but only slightly, both algorithms proved ef-
152.6. DUMMY MODEL CHAPTER 2. MATHEMATICAL BACKGROUND
Figure 2.3: Architecture of a GRU algorithm at a discrete time step t with input vector
xt , memory state ht , reset gate ret , update gate upt , possible memory state h̃t and
weights W , U = [Wre , Wup , Wh ], [Ure , Uup , Uh ]. Where furthermore ⊙ is the Hadamard
product, ς and tanh is the sigmoid and hyperbolic tangent function respectively.
ficient prediction tools. They mention alternative data as a future research extension,
specifically news feeds. Moreover, spot prices are not the subject of this project, how-
ever, it is relevant to mention that both algorithms work well with financial data which
is notoriously noisy and more often than not with high autocorrelation. Thus indicat-
ing that it is highly relevant to apply both algorithms to inspect eventual predictive
differences and variable impact on accuracy metrics.
2.6 Dummy Model
The dummy model is an assumption of constant value from the forecast date. That is
j
yt+1:t+n = ytj , (2.27)
and will serve as a comparison relative to the other three models.
16CHAPTER 3. METHOD
Chapter 3
Method
3.1 Data
The IVS and stock loan data are provided by Bloomberg and Markit respectively, with
data ranging from 2015 to late 2021, specifically defined by t = {0, 1, . . . , n}. The mar-
ket implications created by the Corona pandemic are thus included, which extensively
impacted financial markets and have to be considered when modeling. The data set
includes approximately 58 stocks, abbreviated Sk , on the Swedish market, ranging from
large-cap to small-cap which is an important factor for the liquidity of stock loans and
options to consider in terms of data availability. The IVS σ(t, St /K) for this project is
discretized at 80%, 100%, and 120% moneyness, additionally by only extracting clos-
ing volatility for each day t. The structure can thus be seen as multiple multivariate
time-series, for example
σ(0, 80%) σ(0, 100%) σ(0, 120%) r0
σ(1, 80%) σ(1, 100%) σ(1, 120%) r1
.. .. .. .. (3.1)
. . . .
σ(n, 80%) σ(n, 100%) σ(n, 120%) rn
for each stock Sk={1,2,...,58} . Some of these stocks are missing data for certain days, this
is handled by forward filling, specifically if ytj miss data,
ytj = yt−1
j
. (3.2)
Note that equation 3.1 is a reduced example, the data matrix actually includes all
variables presented in table 3.1.
173.2. STOCK CATEGORY CHAPTER 3. METHOD
Table 3.1: Variables in the data set and their corresponding spaces.
Short loan quantity ∈ N
Available loan quantity ∈ N
Shares outstanding ∈ N
Stock loan transactions ∈ N
Benchmark rate (stock loan rate) ∈ R+
Days to cover ∈ R+
Closing stock price (St ) ∈ R+
σ(t, 80 : 120%) ∈ R+
3.2 Stock Category
The loan rate rt is assumed to have a categorical mandate, in terms of finding stocks
with similar stock loan data and behavior. The definition
GC, if rt < 35bp,
SGroup = Warm, if 35bp ≤ rt < 300bp,
if 300bp ≤ rt ,
Special,
specifies these, where GC abbreviates General Collateral, and bp for basis points. This
says that GC stocks are generally quite cheap to borrow, whereas warm and special
stocks are more expensive due to a higher lending rate. The definition is dynamic, hence
re-evaluated at each time step. It is thus necessary to further specify the stability of the
stocks based on these categories, if a stock is
• GC for more than 90% of the time, it is regarded as GC stable,
• warm for more than 50 % of time, it is regarded as Warm stable,
• special for more than 50 % of time, it is regarded as Special stable.
It is quite rare for a stock to be warm or special stable compared to GC stable in this
data set. This is considered when evaluating LSTM and GRU where three GC stable
stocks will serve as out-of-sample accuracy measures.
3.3 Data Normalization
To reduce training time for the LSTM and GRU models it is necessary to normalize the
data set. Well-used methods such as standardization, or mean and variance scaling are
183.4. GRANGER CAUSALITY CHAPTER 3. METHOD
not applied to the data set, instead, some financial concepts. Specifically, new variables
are defined by self-contained permutations from the raw data set. These are
Short loan quantity
Short interest [%] = ,
Shares outstanding
Short loan quantity
Utilization [%] = ,
Available loan quantity
(3.3)
Stock loan transactions
Transaction trend [%] = ,
Average stock loan transactions 30 days prior
St − St−1
Daily return [%] = .
St−1
The transaction trend will imply a 30-row cut of each stock data set. The normalized
data set used in this thesis is presented in table 3.2. The target variables in question,
Table 3.2: The normalized data set used for the remainder of this thesis.
Short interest
Utilization
Transaction trend
rt
Days to cover
Daily return
σ(t, 80 : 120%)
SGroup
σ(t, 80 : 120%) and rt posses quite high autocorrelation. This is however dependent on
the chosen stock, an example is presented in figure 3.1.
3.4 Granger Causality
In table 3.3, p-values for the bivariate relationship is presented with respect to equation
2.13, with max{τ } = 12. Given a significance level of 0.05, it is possible to either reject
the null hypothesis or not be able to reject it. This test is possible to conduct for
each stock, table 3.3, merely presents three stocks, however, differentiated based on the
categories specified in subsection 3.2. For this data set, about 47 stocks are considered
GC stable, 2 are warm stable, and 2 are special stable. There is some fluctuation inside
193.5. JOHANSEN’S COINTEGRATION TEST CHAPTER 3. METHOD
(a) σ(t, 80%). (b) σ(t, 100%).
(c) σ(t, 120%). (d) rt .
Figure 3.1: Target variable autocorrelation for a GC stable stock. Spikes above the
faded area indicate significant autocorrelation.
the GC category in terms of p-values, which is presented in figure B.1. It is however
possible to conclude that many stocks have a significant Granger causality considering
alternative data. Hence, it is valid to build a VAR model with bivariate relationships
between these variables for some stocks.
3.5 Johansen’s Cointegration Test
It is possible to run the test on each stock and variable, however, only the result for
three category stable stocks with some variables are presented. Whom are: Benchmark
rate, σ(t, 80%), σ(t, 100%), and σ(t, 120%), see table 3.4. It may be inferred that every
time series, except σ(t, 100%) for the warm and GC stable stock, are cointegrated based
on these results, given a significance level of 0.05.
203.6. AUGMENTED DICKEY-FULLER CHAPTER 3. METHOD
Table 3.3: Granger causality for a special, warm, and GC stable stock.
SCategory Target variable rt−τ σ(t − τ, 80%) σ(t − τ, 100%) σ(t − τ, 120%)
Special rt 1.00 0.00 0.00 0.05
σ(t, 80%) 0.00 1.00 0.00 0.00
σ(t, 100%) 0.00 0.00 1.00 0.00
σ(t, 120%) 0.00 0.00 0.00 1.00
Warm rt 1.00 0.25 0.60 0.45
σ(t, 80%) 0.71 1.00 0.00 0.00
σ(t, 100%) 0.15 0.00 1.00 0.00
σ(t, 120%) 0.18 0.03 0.00 1.00
GC rt 1.00 0.28 0.01 0.10
σ(t, 80%) 0.01 1.00 0.00 0.04
σ(t, 100%) 0.18 0.17 1.00 0.00
σ(t, 120%) 0.66 0.00 0.00 1.00
Table 3.4: Johansen’s cointegration test statistic on three category-stable stocks, con-
sidered variables are presented in the left-most column. If the test statistic is below the
given significance level, the time series may be considered cointegrated. This is the case
unless a statistic is indicated by *.
Variable Special stable Warm stable GC stable Significance level (0.05)
rt 208.1 224.2 315.1 40.2
σ(t, 80%) 80.8 94.2 169.3 24.3
σ(t, 100%) 6.7 2.3∗ 0.86∗ 4.1
σ(t, 120%) 27.4 24.8 60.0 12.3
3.6 Augmented Dickey-Fuller
As previously mentioned in subsection 2.3, results from the unit root test (still consid-
ering the three category stable stocks) specified in equation 2.12 are presented in B.2
before and after the first difference. The critical value for a significance level of 0.05 is
-2.87, which DFγ has to be below to regard the time series as stationary. If the null
hypothesis cannot be rejected, a first difference is conducted on the complete data set,
this procedure is repeated until each time series can be regarded as stationary. The
forecasted values are then transformed back to the original scale.
3.7 Lag Optimization
After eventually conducting first-order difference, optimal lag is found based on Akaike-
and Hanna-Quinn information criterion for the VAR model, see Lütkepohl (2005) for
a detailed description of these metrics. The general principle is that AIC and HQI
213.8. FORECAST METHODOLOGY CHAPTER 3. METHOD
close to zero imply more accurate models. That is, a VAR(τ ) model is fitted for each
τ = {1, 2, . . . 12} and evaluated using a training set that includes 80% of the stock
available data. The metrics are presented in table 3.5 for a special, warm, and GC
stable stock respectively. It is easy to see that the optimal lag is seven for the warm
Table 3.5: Optimal lag based on Akaike - and Hanna-Quinn information criterion, small
values indicate more accurate models. The smallest number in each row is indicated by
*. Train size set to 80%, presented figures are based on a special, warm, and GC stable
stock respectively.
Lag AICspecial HQIspecial AICwarm HQIwarm AICGC HQIGC
3 - - - - -59.91 −59.54∗
6 - - −50.20∗ -49.47 −60.13∗ -59.40
7 -18.68 -16.79 −50.20∗ −49.35∗ - -
10 -20.60 −18.17∗ - - - -
12 −20.91∗ -18.00 - - - -
stock. However, since the special and GC stock obtain different lags concerning AIC
and HQI it is necessary to make a conjecture. The lag is thus chosen based on HQI
for special and GC which yields τspecial = 10 and τGC = 3 to reduce input parameters
compared to evaluating with AIC. This lag optimization is only relevant for the VAR
model, another approach involving grid search is applied to determine optimal lag for
GRU and LSTM.
3.8 Forecast Methodology
Conveniently, Keras (Chollet et al., 2015) supports LSTM and GRU layers, a layer
expects an input shape of (samples, time, features). In this project, the second shape
can be interpreted as how many past time steps (τ ) are wanted to make predictions.
Samples can be seen as how many time series of length lag are available, for example,
the number of rows in equation 3.1 divided by lag. The set is subsequently split into a
training and a test sample. Sliding window is further applied to emulate a real setting,
denoting the data set in equation 3.1 by X with t = 0, 1, . . . , n,
inputt = Xt−τ :t ,
(3.4)
outputt = Xt+1:t+days to forecast ,
which is iterated n−(days to forecast) times. Both models have one input layer and a
dense, single output layer.
223.9. FEATURE SELECTION CHAPTER 3. METHOD
3.9 Feature Selection
The variable’s importance is determined by dropping each feature except the target vari-
able and assessing RMSE for each temporal data set. It is repeated iteratively until no
improvements are made. This procedure is done before tuning any other hyperparameter
(except for rt where the lag component is determined based on a broad, single parame-
ter grid search) and repeated for each target variable of importance, that is: rt+1:t+21 ,
σ(t + 1 : t + 3, 80%), σ(t + 1 : t + 3, 100%), and σ(t + 1 : t + 3, 120%). This data
set only includes dates when the market is open, and 21 discrete time steps, therefore,
approximately relates to one month forward in time. Furthermore, they are evaluated
based on average out-of-sample forecast RMSE, calculated over three GC stable stocks.
3.10 Hyperparameter Selection
Grid search is applied on both LSTM and GRU, where the hyperparameters to be
determined are lag (τ ), number of units, and batch size, evaluated with average RMSE
over the three GC stable stocks. See table B.1 in Appendix for chosen values, the network
uses tanh as activation function, 80% train size, and the chosen optimizer is adam.
23CHAPTER 4. RESULTS
Chapter 4
Results
This chapter will present results from feature selection in section 4.1, forecast errors in
4.2, forecast graphs compared to actual values in 4.3, variable influence which summa-
rizes important results in 4.4, and the resulting IVS in 4.5.
4.1 Feature Selection
Figure B.2 indicate a preferable variable selection for the three models. Considering
LSTM and figure B.2a, referring to σ(t, 80%), obtains minimal RMSE by only consider-
ing the volatility surface and the stock loan rate. Figure B.2b, referring to σ(t, 100%),
obtains it by removing days to cover, daily return, σ(t, 80%), and σ(t, 120%). While the
previous target variables seems to enhance accuracy by having more variables, σ(t, 120%)
and rt are conversely worsened by it, which can be seen in figure B.2c and B.2d.
Considering GRU, it is clear that figure B.2e, referring to σ(t, 80%), obtains RMSE
minimum by considering utilization, loan rate, and the volatility surface. Figure B.2f,
referring to σ(t, 100%) obtains it by removing utilization, days to cover, daily return,
dummy variables, and loan rate. Similarly to forecasting σ(t, 120%) and rt with LSTM,
GRU also finds that only considering lagged values of σ(t, 120%) rt yields minimal RMSE.
Finally VAR, where it is apparent that minimal RMSE is reached by removing trans-
action trend and rt considering σ(t, 80%) and figure B.2i. Removing utilization, daily
return and rt for σ(t, 100%) in figure B.2j. σ(t, 120%) in figure B.2k reaches it by only
considering the IVS. Conversely from LSTM and GRU, VAR yields minimal RMSE by
considering the entire data set. Note that the dummy variables are not utilized in the
244.2. FORECAST ERRORS CHAPTER 4. RESULTS
Table 4.1: Selected feature for each target variable in LSTM and GRU-setting respec-
tively. X indicates that a variable is used in the data set for forecasting the specific
target variable. These choices are made based on minimizing RMSE, considering the
algorithm explained in subsection 3.9.
Target Short interest Utilization Transaction trend Days to cover Daily return GC/Warm/Special rt−τ σ(t − τ, 80%) σ(t − τ, 100%) σ(t − τ, 120%)
LSTM σ(t, 80%) X X X X
σ(t, 100%) X X X X X X
σ(t, 120%) X
rt X
GRU σ(t, 80%) X X X X X
σ(t, 100%) X X X X X
σ(t, 120%) X
rt X
VAR σ(t, 80%) X X X X X X X
σ(t, 100%) X X X X X X
σ(t, 120%) X X X
rt X X X X X X X X X
VAR model. These results are summarized in table 4.1. It is noteworthy that no target
variable uses days to cover or daily return, considering LSTM and GRU. These selections
are used throughout the remainder of this analysis.
4.2 Forecast Errors
This section will summarize important results from the out-of-sample model evaluation.
Table 4.2 summarizes average RMSE, MAPE, and PCDF, evaluated over three GC sta-
ble stocks at 20% test data.
σ(t + 3, 80%) achieves minimal RMSE, MAPE, and maximum PCDF with LSTM, it
forecasts the correct direction three days ahead at 81.1% of samples, compared to 0.11%,
76.2%, and 68.7% for the Dummy model, GRU, and VAR respectively. Application of
LSTM is thus considered to be optimal in the case of forecasting σ(t + 3, 80%), achieving
an average RMSE and MAPE of 0.196 and 19.6% respectively, compared with the true
sample mean of 0.606.
σ(t + 3, 100%) achieves minimal RMSE, MAPE, and maximum PCDF with GRU, it
forecasts the correct direction three days ahead at 60.0% of samples. Application of
GRU is thus considered to be optimal in the case of forecasting σ(t + 3, 100%), achieving
an average RMSE and MAPE of 0.044 and 10.8% respectively, compared with the true
sample mean of 0.255.
σ(t + 3, 120%) achieves minimal RMSE and MAPE, and maximum PCDF with VAR
at 66.2%. Achieving an average RMSE and MAPE of 0.143 and 30.2% respectively,
compared with the true sample mean of 0.367.
254.3. FORECASTS CHAPTER 4. RESULTS
Table 4.2: Average RMSE, MAPE, and PCDF were evaluated on an out-of-sample
forecast over three GC stable stocks and 0.8 train size. The best statistic for each target
variable is indicated by *.
Target variable Average RMSE Average MAPE Average PCDF
Dummy σ(t + 3, 80%) 0.349 38.3% 0.1%
σ(t + 3, 100%) 0.053 11.2% 1.1%
σ(t + 3, 120%) 0.207 27.8% 0.6%
rt+21 0.0023 28.7% 0.6%
GRU σ(t + 3, 80%) 0.221 23.2% 76.2%
σ(t + 3, 100%) 0.044∗ 10.8%∗ 60.0%∗
σ(t + 3, 120%) 0.143 30.2% 56.6%
rt+21 0.0018 25.9% 65.3%
LSTM σ(t + 3, 80%) 0.196∗ 19.6%∗ 81.1%∗
σ(t + 3, 100%) 0.051 12.5% 57.4%
σ(t + 3, 120%) 0.156 30.1% 65.2%
rt+21 0.0019 40.3% 65.8%∗
VAR σ(t + 3, 80%) 0.275 31.8% 68.7%
σ(t + 3, 100%) 0.052 14.2% 55.1%
σ(t + 3, 120%) 0.138∗ 26.5%∗ 66.2%∗
rt+21 0.0017∗ 25.5%∗ 63.6%
Finally, rt+21 achieves minimal RMSE and MAPE with VAR, and maximum PCDF
with LSTM, but just slightly. VAR is thus considered optimal for this case. Achieving
an average RMSE and MAPE at 0.0017 and 25.5%, comparatively with the true sample
mean of 0.0019. See table B.3 for a complete table of one, two, and three-day forecasts
on IVS and five, seven, and 21-day forecasts on loan rate.
4.3 Forecasts
Having decided an algorithm for each target variable following section 4.2, and further
evaluating RMSE, MAPE, and PCDF for a single GC stable stock, the forecasts gen-
erated from these are presented here. Figure 4.1a shows an out-of-sample, three days
ahead rolling LSTM forecast on σ(t, 80%), it is apparent that the algorithm managed to
contextualize lagged data in terms of similarity with actual values.
Figure 4.1b presents a three-day ahead rolling GRU forecast on σ(t, 100%), it is easy to
notice how noisy this variable is. The GRU algorithm is however quite capable in terms
of visually following similar trends as the true values. Compared to figure 4.1a it is not
264.3. FORECASTS CHAPTER 4. RESULTS
as accurate, which is also expected from table 4.2.
Figure 4.1c presents a three day ahead rolling GRU forecast on σ(t, 120%), more reminis-
cent of figure 4.1a in regards to accuracy and time trend than figure 4.1b. Noteworthy
here is that this forecast only considers lagged values of itself but is still capable of
contextualizing the information.
(a) σ(t, 80%). (b) σ(t, 100%).
(c) σ(t, 120%).
Figure 4.1: Out-of-sample forecast for σ(t, 80 : 120%) on a GC stable stock with LSTM
and GRU. The blue line is the three days ahead forecast with rolling window methodol-
ogy, orange dotted is the actual three days ahead IV.
Figure 4.2a presents a 21 day ahead rolling GRU forecast on rt , it is apparent that there
is more noise in this variable compared to figure 4.1a, 4.1b, and 4.1c. The GRU model
seems less capable of forecasting this variable compared to the aforementioned. Table
4.2 presents that the directional forecast is correct 65.3% of samples, for the LSTM
model it is 65.8%, which is better than a coin toss (50%) and much better than the
dummy model at 0.6%. Furthermore, table B.3 presents errors for five and seven days
ahead, presenting that the direction is correct 73.6% and 69.7% of samples respectively.
Outperforming the dummy- (0.1% and 0.7%) and LSTM model (59.3% and 68.4%) in
all defined regards. The five and seven days ahead rolling forecasts are presented in
274.3. FORECASTS CHAPTER 4. RESULTS
figure 4.2c and 4.2b respectively. Both are visually more accurate than the 21-day ahead
forecast, however still incapable of matching the actual fluctuations of the rate.
It is noteworthy that VAR is quite capable of forecasting these variables (see figure
B.5) however not as good in following trends and large fluctuations when considering
σ(t, 80%). For σ(t, 100%) the model generates similar results as GRU (figure 4.1b), how-
ever with somewhat lagged trends compared to the true values. Similar inferences can
be drawn from the forecast of σ(t, 120%) as for σ(t, 80%). rt remains seemingly difficult
to forecast, almost constant for the 21-day forecast, explaining the relatively low RMSE
and MAPE. Comparatively to GRU which is capable of finding some trends.
The models with best statistics, in all regards, for variables not yet considered in this
section are here presented concisely accordingly with table B.3. GRU: σ(t + 1, 100%),
σ(t + 2, 100%), rt+5 , and rt+7 . LSTM: σ(t + 1, 80%), σ(t + 2, 80%). VAR: σ(t + 3, 120%).
(a) 21 days ahead. (b) Seven days ahead.
(c) Five days ahead.
Figure 4.2: Out of sample forecast for rt on a GC stable stock with GRU. The blue line
is the rolling window forecast, orange dotted is the actual loan rate.
28You can also read

















































