Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Super Tickets in Pre-Trained Language Models: From Model
Compression to Improving Generalization
Chen Liang∗ , Simiao Zuo , Minshuo Chen , Haoming Jiang ,
Xiaodong Liu† , Pengcheng He‡ , Tuo Zhao , Weizhu Chen‡
Georgia Tech, † Microsoft Research, ‡ Microsoft Azure AI
Abstract of such a collection of tickets, which is usually
referred to as “winning tickets”, indicates the po-
tential of training a smaller network to achieve the
arXiv:2105.12002v1 [cs.LG] 25 May 2021
The Lottery Ticket Hypothesis suggests that an full model’s performance. LTH has been widely
over-parametrized network consists of “lottery tick- explored in across various fields of deep learning
ets”, and training a certain collection of them (i.e., (Frankle et al., 2019; Zhou et al., 2019; You et al.,
a subnetwork) can match the performance of the 2019; Brix et al., 2020; Movva and Zhao, 2020;
full model. In this paper, we study such a collec- Girish et al., 2020).
tion of tickets, which is referred to as “winning Aside from training from scratch, such winning
tickets”, in extremely over-parametrized models, tickets have demonstrated their abilities to transfer
e.g., pre-trained language models. We observe that across tasks and datasets (Morcos et al., 2019; Yu
at certain compression ratios, generalization perfor- et al., 2019; Desai et al., 2019; Chen et al., 2020a).
mance of the winning tickets can not only match, In natural language processing, Chen et al. (2020b);
but also exceed that of the full model. In particular, Prasanna et al. (2020) have shown existence of
we observe a phase transition phenomenon: As the the winning tickets in pre-trained language models.
compression ratio increases, generalization perfor- These tickets can be identified when fine-tuning
mance of the winning tickets first improves then the pre-trained models on downstream tasks. As
deteriorates after a certain threshold. We refer to the pre-trained models are usually extremely over-
the tickets on the threshold as “super tickets”. We parameterized (e.g., BERT Devlin et al. (2019),
further show that the phase transition is task and GPT-3 Brown et al. (2020), T5 Raffel et al. (2019)),
model dependent — as model size becomes larger previous works mainly focus on searching for a
and training data set becomes smaller, the transi- highly compressed subnetwork that matches the
tion becomes more pronounced. Our experiments performance of the full model. However, behav-
on the GLUE benchmark show that the super tick- ior of the winning tickets in lightly compressed
ets improve single task fine-tuning by 0.9 points on subnetworks is largely overlooked.
BERT-base and 1.0 points on BERT-large, in terms In this paper, we study the behavior of the win-
of task-average score. We also demonstrate that ning tickets in pre-trained language models, with
adaptively sharing the super tickets across tasks a particular focus on lightly compressed subnet-
benefits multi-task learning. works. We observe that generalization performance
of the winning tickets selected at appropriate com-
1 Introduction pression ratios can not only match, but also exceed
that of the full model. In particular, we observe
The Lottery Ticket Hypothesis (LTH, Frankle and
a phase transition phenomenon (Figure 1): The
Carbin (2018)) suggests that an over-parameterized
test accuracy improves as the compression ratio
network consists of “lottery tickets”, and training a
grows until a certain threshold (Phase I); Passing
certain collection of them (i.e., a subnetwork) can
the threshold, the accuracy deteriorates, yet is still
1) match the performance of the full model; and 2)
better than that of the random tickets (Phase II). In
outperform randomly sampled subnetworks of the
Phase III, where the model is highly compressed,
same size (i.e., “random tickets”). The existence
training collapses. We refer to the set of winning
∗
Work was done at Microsoft Azure AI. tickets selected on that threshold as “super tickets”.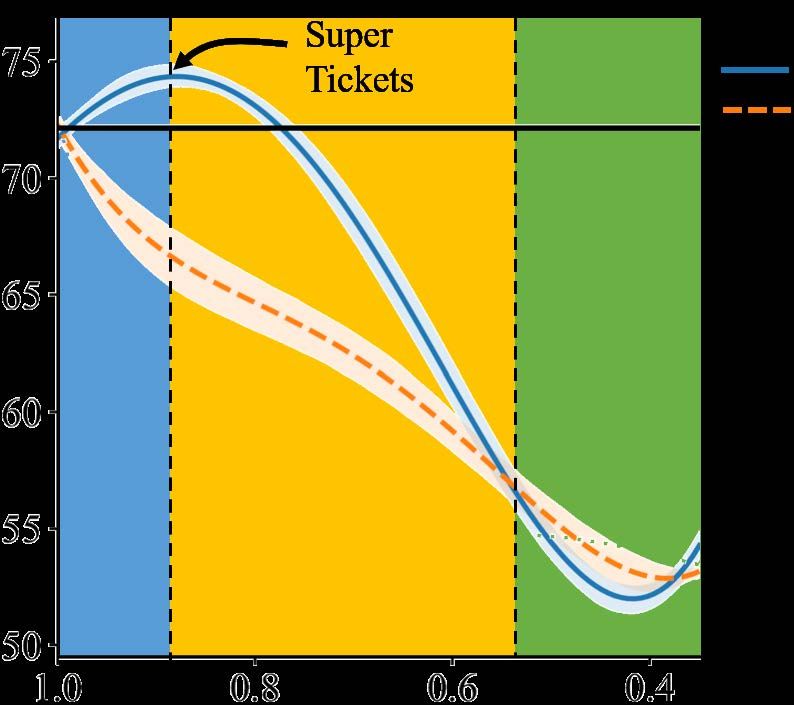
Phase
PhaseI I Phase II Phase III Phase I Phase
Phase I
Phase II PhasePhase
II Phase
II III Phase III
III Phase I Phase II Phase III
Winning
Random
Random
Bias
Bias
Accuracy
Variance
Accuracy
Bias
1.0 0.8 0.6 0.4
Variance
Variance
1.0 0.8
1.0 0.6
0.8 0.4
0.6 0.4 1.0 0.8 0.6 0.4
Percent of of
Percent Weight Remaining
Weight Remaining Percent of
Percent ofPercent
Weightof
Weight Remaining
Weight Remaining
Remaining Percent of Weight Remaining
Figure 1: Illustrations of the phase transition phenomenon. Left: Generalization performance of the fine-tuned
subnetworks (the same as Figure 4 in Section 5). Middle and Right: An interpretation of bias-variance trade-off.
We interpret the phase transition in the context of model bias and variance. However, existing meth-
trade-offs between model bias and variance (Fried- ods do not specifically balance the bias and vari-
man et al., 2001, Chapter 7). It is well understood ance to accommodate each task. In fact, the fine-
that an expressive model induces a small bias, and tuning performance on tasks with a small dataset
a large model induces a large variance. We classify is very sensitive to randomness. This suggests that
the tickets into three categories: non-expressive model variance in these tasks are high due to over-
tickets, lightly expressive tickets, and highly ex- parameterization. To reduce such variance, we
pressive tickets. The full model has a strong expres- propose a tickets sharing strategy. Specifically, for
sive power due to over-parameterization, so that each task, we select a set of super tickets during
its bias is small. Yet its variance is relatively large. single task fine-tuning. Then, we adaptively share
In Phase I, by removing non-expressive tickets, these super tickets across tasks based on a similar
variance of the selected subnetwork reduces, while strategy in sparse sharing (Sun et al., 2020).
model bias remains unchanged and the expressive Our experiments show that tickets sharing im-
power sustains. Accordingly, generalization per- proves MTL by 0.9 points over MT-DNNBASE (Liu
formance improves. We enter Phase II by further et al., 2019) and 1.0 points over MT-DNNLARGE , in
increasing the compression ratio. Here lightly ex- terms of task-average score. Tickets sharing further
pressive tickets are pruned. Consequently, model benefits downstream fine-tuning of the multi-task
variance continues to decrease. However, model model, and achieves a gain of 1.0 task-average
bias increases and overturns the benefit of the re- score. In addition, the multi-task model obtained
duced variance. Lastly for Phase III, in the highly by such a sharing strategy exhibits lower sensitiv-
compressed region, model bias becomes notori- ity to randomness in downstream fine-tuning tasks,
ously large and reduction of the variance pales. As suggesting a reduction in variance.
a result, training breaks down and generalization
performance drops significantly. 2 Background
We conduct systematic experiments and analyses We briefly introduce the Transformer architecture
to understand the phase transition. Our experiments and the Lottery Ticket Hypothesis.
on multiple natural language understanding (NLU)
2.1 Transformer Architecture
tasks in the GLUE (Wang et al., 2018) benchmark
show that the super tickets can be used to improve The Transformer (Vaswani et al., 2017) encoder
single task fine-tuning by 0.9 points over BERT- is composed of a stack of identical Transformer
base (Devlin et al., 2019) and 1.0 points over BERT- layers. Each layer consists of a multi-head attention
large, in terms of task-average score. Moreover, module (MHA) followed by a feed-forward module
our experiments show that the phase transition phe- (FFN), with a residual connection around each. The
nomenon is task and model dependent. It becomes vanilla single-head attention operates as
more pronounced as a larger model is used to fit a QK >
task with less training data. In such a case, the set Att(Q, K, V ) = Softmax √ V,
d
of super tickets forms a compressed network that
where Q, K, V ∈ Rl×d are d-dimensional vector
exhibits a large performance gain.
representations of l words in sequences of queries,
The existence of super tickets suggests poten- keys and values. In MHA, the h-th attention head
tial benefits to applications, such as Multi-task is parameterized by WhQ , WhK , WhV ∈ Rd×dh as
Learning (MTL). In MTL, different tasks require {Q,K,V }
different capacities to achieve a balance between Hh (q, x, Wh ) = Att(qWhQ , xWhK , xWhV ),where q ∈ Rl×d and x ∈ Rl×d are the query and layers. Specifically, in each Transformer layer, we
key/value vectors. In MHA, H independently pa- associate mask variables ξh to each attention head
rameterized attention heads are applied in parallel, and ν to the FFN (Prasanna et al., 2020):
and the outputs are aggregated by WhO ∈ Rdh ×d : H
{Q,K,V }
X
H MHA(Q, x) = ξh Hh (Q, x, Wh )WhO ,
{Q,K,V }
X
MHA(q, x)= Hh (q, x, Wh )WhO . h
h FFN(z) = νFFN(z).
Each FFN module contains a two-layer fully con- Here, we set ξh , ν ∈ {0, 1}, and a 0 value indicates
nected network. Given the input embedding z, we that the corresponding structure is pruned.
let FFN(z) denote the output of a FFN module. We adopt importance score (Michel et al., 2019)
as a gauge for pruning. In particular, the impor-
2.2 Structured and Unstructured LTHs
tance score is defined as the expected sensitivity
LTH (Frankle and Carbin, 2018) has been widely of the model outputs with respect to the mask vari-
explored in various applications of deep learning ables. Specifically, in each Transformer layer,
(Brix et al., 2020; Movva and Zhao, 2020; Girish
h ∂L(x) ∂L(x)
et al., 2020). Most of existing results focus on IMHA = E , IFFN = E ,
finding unstructured winning tickets via iterative x∼Dx ∂ξh x∼Dx ∂ν
magnitude pruning and rewinding in randomly ini- where L is a loss function and Dx is the data distri-
tialized networks (Frankle et al., 2019; Renda et al., bution. In practice, we compute the average over
2020), where each ticket is a single neuron. Re- the training set. We apply a layer-wise `2 normal-
cent works further investigate learning dynamics of ization on the importance scores of the attention
the tickets (Zhou et al., 2019; Frankle et al., 2020) heads (Molchanov et al., 2016; Michel et al., 2019).
and efficient methods to identify them (You et al., The importance score is closely tied to expres-
2019; Savarese et al., 2020). Besides training from sive power. A low importance score indicates that
scratch, researchers also explore the existence of the corresponding structure only has a small con-
winning tickets under transfer learning regimes for tribution towards the output. Such a structure has
over-parametrized pre-trained models across var- low expressive power. On the contrary, a large
ious tasks and datasets (Morcos et al., 2019; Yu importance score implies high expressive power.
et al., 2019; Desai et al., 2019; Chen et al., 2020a). We compute the importance scores for all the
For example, Chen et al. (2020b); Prasanna et al. mask variables in a single backward pass at the end
(2020) have shown the existence of winning tickets of fine-tuning. We perform one-shot pruning of the
when fine-tuning BERT on downstream tasks. same percent of heads and feed-forward layers with
There is also a surge of research exploring the lowest importance scores. We conduct pruning
whether certain structures, e.g., channels in convo- multiple times to obtain subnetworks, or winning
lutional layers and attention heads in Transformers, tickets, at different compression ratios.
exhibit properties of the lottery tickets. Compared We adopt the weight rewinding technique in
to unstructured tickets, training with structured tick- Renda et al. (2020): We reset the parameters of
ets is memory efficient (Cao et al., 2019). Liu et al. the winning tickets to their values in the pre-trained
(2018); Prasanna et al. (2020) suggest that there is weights, and subsequently fine-tune the subnetwork
no clear evidence that structured winning tickets with the original learning rate schedule. The super
exist in randomly initialized or pre-trained weights. tickets are selected as the winning tickets with the
Prasanna et al. (2020) observe that, in highly com- best rewinding validation performance.
pressed BERT (e.g., the percent of weight remain-
ing is around 50%), all tickets perform equally 4 Multi-task Learning with Tickets
well. However, Prasanna et al. (2020) have not Sharing
investigated the cases where the percent of weight
In multi-task learning, the shared model is highly
remaining is over 50%.
over-parameterized to ensure a sufficient capacity
3 Finding Super Tickets for fitting individual tasks. Thus, the multi-task
model inevitably exhibits task-dependent redun-
We identify winning tickets in BERT through struc- dancy when being adapted to individual tasks. Such
tured pruning of attention heads and feed-forward redundancy induces a large model variance.pared to Sparse Sharing (Sun et al., 2020): 1) Sun
et al. (2020) share winning tickets, while our strat-
egy focuses on super tickets, which can better gen-
eralize and strike a sensible balance between model
bias and variance. 2) In tickets sharing, tickets are
structured and chosen from pre-trained weight pa-
rameters. It does not require Multi-task Warmup,
which is indispensable in Sun et al. (2020) to stabi-
lize the sharing among unstructured tickets selected
from randomly initialized weight parameters.
Algorithm 1 Tickets Sharing
Input: Pre-trained base model parameters θ. Num-
ber of tasks N . Mask variables {Ωi }N SN. Loss
i=1
i N
functions {L }i=1 . Dataset D = i=1 Di .
Figure 2: Illustration of tickets sharing.
Number of epochs Tmax .
We propose to mitigate the aforementioned 1: for i in N do
model redundancy by identifying task-specific 2: Initialize the super tickets for task i: θi =
super tickets to accommodate each task’s need. M (θ, Ωi ).
Specifically, when viewing an individual task in 3: end for
isolation, the super tickets can tailor the multi-task 4: for epoch in 1, . . . , Tmax do
model to strike an appealing balance between the 5: Shuffle dataset D.
model bias and variance (recall from Section 3 that 6: for a minibatch bi of task i in D do
super tickets retain sufficient expressive power, yet 7: Compute Loss Li (θi ).
keep the model variance low). Therefore, we ex- 8: Compute gradient ∇θ Li (θi ).
pect that deploying super tickets can effectively 9: Update θi using SGD-type algorithm.
tame the model redundancy for individual tasks. 10: end for
Given the super tickets identified by each task, 11: end for
we exploit the multi-task information to reinforce
fine-tuning. Specifically, we propose a tickets shar-
ing algorithm to update the parameters of the multi- 5 Single Task Experiments
task model: For a certain network structure (e.g., an
attention head), if it is identified as super tickets by 5.1 Data
multiple tasks, then its weights are jointly updated General Language Understanding Evaluation
by these tasks; if it is only selected by one specific (GLUE, Wang et al. (2018)) is a standard bench-
task, then its weights are updated by that task only; mark for evaluating model generalization perfor-
otherwise, its weights are completely pruned. See mance. It contains nine NLU tasks, including ques-
Figure 2 for an illustration. tion answering, sentiment analysis, text similarity
In more detail, we denote the weight parameters and textual entailment. Details about the bench-
in the multi-task model as θ. Suppose there are N mark are deferred to Appendix A.1.1.
tasks. For each taskSi ∈ {1, . . . , N }, we denote
i }H,L
Ωi = {ξh,` i L 5.2 Models & Training
h=1,`=1 {ν` }`=1 as the collection of
the mask variables, where ` is the layer index and We fine-tune a pre-trained BERT model with task-
h is the head index. Then the parameters to be specific data to obtain a single task model. We ap-
updated in task i are denoted as θi = M (θ, Ωi ), pend a task-specific fully-connected layer to BERT
where M (·, Ωi ) masks the pruned parameters ac- as in Devlin et al. (2019).
cording to Ωi . We use stochastic gradient descent- • ST-DNNBASE/LARGE is initialized with BERT-
type algorithms to update θi . Note that the task- base/large followed by a task-specific layer.
shared and task-specific parameters are encoded • SuperTBASE/LARGE is initialized with the chosen
by the mask variable Ωi . The detailed algorithm is set of super tickets in BERT-base/large followed
given in Algorithm 1. by a task-specific layer. Specifically, we prune
Tickets sharing has two major difference com- BERT-base/large in unit of 10% heads and 10%RTE MRPC CoLA SST STS-B QNLI QQP MNLI-m/mm Average Average
Acc Acc/F1 Mcc Acc P/S Corr Acc Acc/F1 Acc Score Compression
ST-DNNBASE 69.2 86.2/90.4 57.8 92.9 89.7/89.2 91.2 90.9/88.0 84.5/84.4 82.8 100%
SuperTBASE 72.5 87.5/91.1 58.8 93.4 89.8/89.4 91.3 91.3/88.3 84.5/84.5 83.7 86.8%
ST-DNNLARGE 72.1 85.2/89.5 62.1 93.3 89.9/89.6 92.2 91.3/88.4 86.2/86.1 84.1 100%
SuperTLARGE 74.1 88.0/91.4 64.3 93.9 89.9/89.7 92.4 91.4/88.5 86.5/86.2 85.1 81.7%
Table 1: Single task fine-tuning evaluation results on the GLUE development set. ST-DNN and SuperT results are
the averaged score over 5 trails with different random seeds.
RTE MRPC CoLA SST STS-B QNLI QQP MNLI-m/mm Average Average
Acc Acc/F1 Mcc Acc P/S Corr Acc Acc/F1 Acc Score Compression
ST-DNNBASE 66.4 -/88.9 52.1 93.5 -/85.8 90.5 -/71.2 84.6/83.4 79.6 100%
SuperTBASE 69.6 85.4/89.4 54.3 94.1 87.4/86.2 90.5 89.1/71.3 84.6/83.8 80.4 86.8%
Table 2: Single task fine-tuning test set results scored using the GLUE evaluation server1 . Results of ST-DNNBASE
are from Devlin et al. (2019).
4
feed-forward layers (FFN) at 8 different sparsity
Performance Gain
SuperT-Large
3
levels (10% heads and 10% FFN, 20% heads and SuperT-Base
2
20% FFN, etc). Among them, the one with the best
1
rewinding validation result is chosen as the set of
0
super tickets. We randomly sample 10% GLUE
% of Weight Remaining
1.0
development set for tickets selection. 0.93 0.93 0.920.93
0.9 0.89 0.89
Our implementation is based on the MT-DNN 0.86 0.84 0.86 0.86 0.84
0.820.83
0.8 0.79
code base2 . We use Adamax (Kingma and Ba, 0.77
2014) as our optimizer. We tune the learning rate 0.7 0.66
RTE MRPC STS-B CoLA SST-2 QNLI QQP MNLI
in {5×10−5 , 1×10−4 , 2×10−4 } and batch size in 2.49k 3.67k 5.75k 8.55k 67.3k 108k 364k 393k
Task (Size)
{8, 16, 32}. We train for a maximum of 6 epochs
with early-stopping. All training details are sum- Figure 3: Single task fine-tuning validation results
marized in Appendix A.1.2. in different GLUE tasks. Upper: Performance Gain.
Lower: Percent of weight remaining.
5.3 Generalization of the Super Tickets
data), but only 0.4/0.3 on QQP (364k data) in the
We conduct 5 trails of pruning and rewinding ex- SuperTBASE experiments. Furthermore, from Fig-
periments using different random seeds. Table 1 ure 3, note that the super tickets are more heavily
and 2 show the averaged evaluation results on the compressed in small tasks, e.g., for SuperTBASE ,
GLUE development and test sets, respectively. We 83% weights remaining for RTE, but 93% for
remark that the gain of SuperTBASE/LARGE over ST- QQP. These observations suggest that for small
DNNBASE/LARGE is statistically significant. All the tasks, model variance is large, and removing non-
results3 have passed a paired student t-test with expressive tickets reduces variance and improves
p-values less than 0.05. More validation statistics generalization. For large tasks, model variance is
are summarized in Appendix A.1.3. low, and all tickets are expressive to some extent.
Our results can be summarized as follows. 3) Performance of the super tickets is related
1) In all the tasks, SuperT consistently achieves to model size. Switching from SuperTBASE to
better generalization than ST-DNN. The task- SuperTLARGE , the percent of weights remaining
averaged improvement is around 0.9 over ST- shrinks uniformly across tasks, yet the generaliza-
DNNBASE and 1.0 over ST-DNNLARGE . tion gains persist (Figure 3). This suggests that in
2) Performance gain of the super tickets is more large models, more non-expressive tickets can be
significant in small tasks. For example, in Ta- pruned without performance degradation.
ble 1, we obtain 3.3 points gain on RTE (2.5k
5.4 Phase Transition
2
https://github.com/namisan/mt-dnn
3
Except for STS-B (SuperTBASE , Table 1), where the p- Phase transitions are shown in Figure 4. We plot
value is 0.37. the evaluation results of the winning, the random,BERT-base BERT-large 1) The winning tickets are indeed the “winners”.
70 In Phase I and early Phase II, the winning tickets
70
Accuracy
perform better than the full model and the random
RTE
60
60 tickets. This demonstrates the existence of struc-
50
tured winning tickets in lightly compressed BERT
50 models, which Prasanna et al. (2020) overlook.
1.0 0.8 0.6 0.4 1.0 0.8 0.6 0.4
2) Phase transition is pronounced over different
94 94 tasks and models. Accuracy of the winning tickets
92 increases up till a certain compression ratio (Phase
Accuracy
92
SST-2
90 90 I); Passing the threshold, the accuracy decreases
88 88 (Phase II), until its value intersects with that of
86 86 the random tickets (Phase III). Note that Phase
1.0 0.8 0.6 0.4 1.0 0.8 0.6 0.4 III agrees with the observations in Prasanna et al.
86
(2020). Accuracy of the random tickets decreases
86
84 in each phase. This suggests that model bias in-
MNLI-m/mm
Accuracy
82 84 creases steadily, since tickets with both low and
80 82 high expressive power are discarded. Accuracy of
80 the losing tickets drops significantly even in Phase
78
1.0 0.8 0.6 0.4 1.0 0.8 0.6 0.4 I, suggesting that model bias increases drastically
Percent of Weight Remaining Percent of Weight Remaining as highly expressive tickets are pruned.
Figure 4: Single task fine-tuning evaluation results of 3) Phase transition is more pronounced in large
the winning (blue), the random (orange), and the losing models and small tasks. For example, in Figure 4,
(green) tickets on the GLUE development set under var- the phase transition is more noticeable in BERT-
ious sparsity levels. large than in BERT-base, and is more pronounced
in RTE (25k) than in SST (67k) and MNLI (393k).
MNLI-m/mm, 10% Split MNLI-m/mm, 1% Split The phenomenon becomes more significant for the
80
72 same task when we only use a part of the data, e.g.,
Figure 5 vs. Figure 4 (bottom left).
BERT-base
70
Accuracy
78
68 6 Multi-task Learning Experiments
76
66
74 6.1 Model & Training
1.0 0.8 0.6 0.4 1.0 0.8 0.6 0.4
Percent of Weight Remaining Percent of Weight Remaining We adopt the MT-DNN architecture proposed in
Liu et al. (2020). The MT-DNN model consists
Figure 5: Phase transition under different randomly of a set of task-shared layers followed by a set of
sampled training subsets. Note that the settings are the
same as Figure 4 (bottom left), except the data size.
task-specific layers. The task-shared layers take in
the input sequence embedding, and generate shared
semantic representations by optimizing multi-task
and the losing tickets under 8 sparsity levels us-
objectives. Our implementation is based on the
ing BERT-base and BERT-large. The winning
MT-DNN code base. We follow the same training
tickets contain structures with the highest impor-
settings in Liu et al. (2020) for multi-task learn-
tance scores. The losing tickets are selected re-
ing, and in Section 5.2 for downstream fine-tuning.
versely, i.e., the structures with the lowest im-
More details are summarized in Appendix A.2.
portance scores are selected, and high-importance
• MT-DNNBASE/LARGE . An MT-DNN model re-
structures are pruned. The random tickets are sam-
fined through multi-task learning, with task-shared
pled uniformly across the network. We plot the
layers initialized by pre-trained BERT-base/large.
averaged scores over 5 trails using different ran-
• MT-DNNBASE/LARGE + ST Fine-tuning. A sin-
dom seeds4 . Phase transitions of all the GLUE
gle task model obtained by further fine-tuning MT-
tasks are in Appendix A.5.
DNN on an individual downstream task.
We summarize our observations: • Ticket-ShareBASE/LARGE . An MT-DNN model
4
Except for MNLI, where we plot 3 trails as the there are refined through the ticket sharing strategy, with
less variance among trails. task-shared layers initialized by the union of theRTE MRPC CoLA SST STS-B QNLI QQP MNLI-m/mm Average Average
Acc Acc/F1 Mcc Acc P/S Corr Acc Acc/F1 Acc Score Compression
MT-DNNBASE 79.0 80.6/86.2 54.0 92.2 86.2/86.4 90.5 90.6/87.4 84.6/84.2 82.4 100%
+ ST Fine-tuning 79.1 86.8/89.2 59.5 93.6 90.6/90.4 91.0 91.6/88.6 85.3/85.0 84.6 100%
Ticket-ShareBASE 81.2 87.0/90.5 52.0 92.7 87.7/87.5 91.0 90.7/87.5 84.5/84.1 83.3 92.9%
+ ST Fine-tuning 83.0 89.2/91.6 59.7 93.5 91.1/91.0 91.9 91.6/88.7 85.0/85.0 85.6 92.9%
MT-DNNLARGE 83.0 85.2/89.4 56.2 93.5 87.2/86.9 92.2 91.2/88.1 86.5/86.0 84.4 100%
+ ST Fine-tuning 83.4 87.5/91.0 63.5 94.3 90.7/90.6 92.9 91.9/89.2 87.1/86.7 86.4 100%
Ticket-ShareLARGE 80.5 88.4/91.5 61.8 93.2 89.2/89.1 92.1 91.3/88.4 86.7/86.0 85.4 83.3%
+ ST Fine-tuning 84.5 90.2/92.9 65.0 94.1 91.3/91.1 93.0 91.9/89.1 87.0/86.8 87.1 83.3%
Table 3: Multi-task Learning evaluation results on the GLUE development set. Results of MT-DNNBASE/LARGE with
and without ST Fine-tuning are from Liu et al. (2020).
super tickets in pre-trained BERT-base/large. Model 0.1% 1% 10% 100%
• Ticket-ShareBASE/LARGE + ST Fine-tuning. A SNLI (Dev Acc%)
fine-tuned single-task Ticket-Share model. # Training Data 549 5493 54k 549k
MNLI-ST-DNNBASE 82.1 85.1 88.4 90.7
6.2 Experimental Results MNLI-SuperTBASE 82.9 85.5 88.8 91.4
MT-DNNBASE 82.1 85.2 88.4 91.1
Table 3 summarizes experimental results. The fine- Ticket-ShareBASE 83.3 85.8 88.9 91.5
tuning results are averaged over 5 trails using differ- SciTail (Dev Acc%)
ent random seeds. We have several observations: # Training Data 23 235 23k 235k
1) Ticket-ShareBASE and Ticket-ShareLARGE MNLI-ST-DNNBASE 80.6 88.8 92.0 95.7
achieve 0.9 and 1.0 gain in task-average score over MNLI-SuperTBASE 82.9 89.8 92.8 96.2
MT-DNNBASE and MT-DNNLARGE , respectively. MT-DNNBASE 81.9 88.3 91.1 95.7
Ticket-ShareBASE 83.1 90.1 93.5 96.5
In some small tasks (RTE, MRPC), Ticket-Share
achieves better or on par results compared to MT-
Table 4: Domain adaptation evaluation results on SNLI
DNN+Fine-tuning. This suggests that by balancing and SciTail development set. Results of MT-DNNBASE
the bias and variance for different tasks, the multi- are from Liu et al. (2020).
task model’s variance is reduced. In large tasks
(QQP, QNLI and MNLI), Ticket-Share behaves
equally well with the full model. This is because SNLI. The Stanford Natural Language Inference
task-shared information is kept during pruning and dataset (Bowman et al., 2015) is one of the most
still benefits multi-task learning. widely used entailment dataset for NLI. It contains
2) Ticket-ShareBASE +Fine-tuning and Ticket- 570k sentence pairs, where the premises are drawn
ShareLARGE +Fine-tuning achieve 1.0 and 0.7 gains from the captions of the Flickr30 corpus and hy-
in task-average score over MT-DNNBASE +Fine- potheses are manually annotated.
tuning and MT-DNNLARGE +Fine-tuning, respec- SciTail is a textual entailment dataset derived from
tively. This suggests that reducing the variance a science question answering (SciQ) dataset (Khot
in the multi-task model benefits fine-tuning down- et al., 2018). The hypotheses are created from
stream tasks. science questions, rendering SciTail challenging.
7.2 Experimental Results
7 Domain Adaptation
We consider domain adaptation on both single
To demonstrate that super tickets can quickly gen- task and multi-task super tickets. Specifically,
eralize to new tasks/domains, we conduct few-shot we adapt SuperTBASE and ST-DNNBASE from
domain adaptation on out-of-domain NLI datasets. MNLI to SNLI/SciTail, and adapt the shared em-
beddings generated by Ticket-ShareBASE and by
7.1 Data & Training MT-DNNBASE to SNLI/SciTail. We adapt these
models to 0.1%, 1%, 10% and 100% SNLI/SciTail
We briefly introduce the target domain datasets.
training sets5 , and evaluate the transferred models
The data and training details are summarized in
5
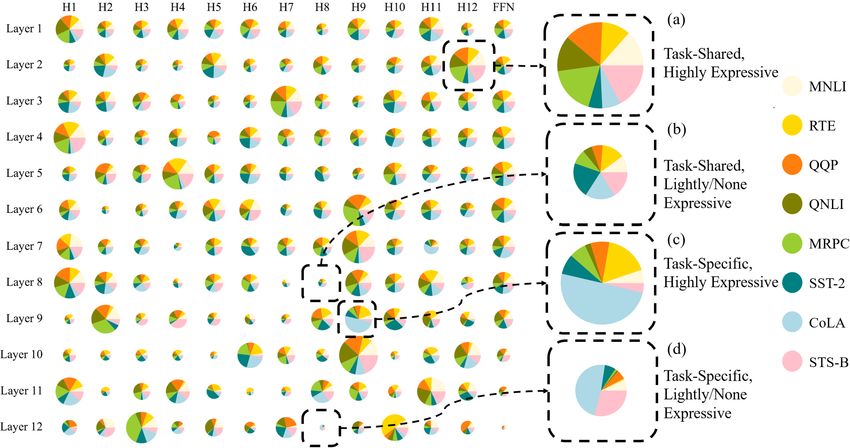
Appendix A.3.1 and A.3.2, respectively. We use the subsets released in MT-DNN code base.Figure 6: Illustration of tickets importance across tasks. Each ticket is represented by a pie chart. The size of a
pie indicates the Ticket Importance, where a larger pie suggests the ticket exhibits higher expressivity. Each task
is represented by a color. The share of a color indicates the Task Share, where a even share suggests the ticket
exhibits equal expressivity in all tasks.
on SNLI/SciTail development sets. Table 4 shows specific importance score out of the sum of all tasks’
the domain adaptation evaluation results. As we scores as the Task Share, as illustrated in Figure 6.
can see, SuperT and Ticket-Share can better adapt We observe that many tickets exhibit almost
to SNLI/SciTail than ST-DNN and MT-DNN, espe- equal Task Shares for over 5 out of 8 tasks (Fig-
cially under the few shot setting. ure 6(a)(b)). While these tickets contribute to the
knowledge sharing in the majority of tasks, they
8 Analysis are considered non-expressive for tasks such as
SST-2 (see Figure 6(a)(c)(d)). This explains why
Sensitivity to Random Seed. To better demon-
SST-2 benefits little from tickets sharing. Further-
strate that training with super tickets effectively
more, a small number of tickets are dominated by
reduces model variance, we evaluate models’ sen-
a single task, e.g., CoLA (Figure 6(c)), or domi-
sitivity to changes in random seeds during single
nated jointly by two tasks, e.g., CoLA and STS-B
task fine-tuning and multi-task downstream fine-
(Figure 6(d)). This suggests that some tickets only
tuning. In particular, we investigate fitting small
learn task-specific knowledge, and the two tasks
tasks with highly over-parametrized models (vari-
may share certain task-specific knowledge.
ance is often large in these models, see Section 5
and 6). As shown in Table 5, SuperTLarge and 9 Conclusion
Ticket-ShareLarge induce much smaller standard de-
viation in validation results. Experimental details In this paper, we study the behavior of the struc-
and further analyses are deferred to Appendix A.4. tured lottery tickets in pre-trained BERT. We ob-
serve that the generalization performance of the
RTE MRPC CoLA STS-B SST
winning tickets exhibits a phase transition, and,
ST-DNNLarge 1.46 0.61 1.32 0.16 0.17 within early phases, exceeds that of the full model.
SuperTLarge 1.09 0.20 0.93 0.07 0.16
MT-DNNLarge 1.43 0.78 1.14 0.15 0.18
This observation have several implications: 1)
Ticket ShareLarge 0.99 0.67 0.81 0.08 0.16 Model generalization can be improved through
structured pruning. As we only evaluate a one-
Table 5: Standard deviation of tasks in GLUE (dev) shot importance-score-based pruning method, we
over 5 different random seeds. remark that iterative or more sophisticated methods
Tickets Importance Across Tasks. We analyze may identify better generalized tickets. 2) Ticket
the importance score of each ticket computed in searching can be more efficient. As super tickets
different GLUE tasks. For each ticket, we compute compose a lightly compressed subnetwork, they
the importance score averaged over tasks as the might be identified early during training if iterative
Ticket Importance, and the proportion of the task- pruning and rewinding strategy is used.Broader Impact Tianlong Chen, Jonathan Frankle, Shiyu Chang, Sijia
Liu, Yang Zhang, Zhangyang Wang, and Michael
This paper studies the behavior of the structured Carbin. 2020b. The lottery ticket hypothesis
lottery tickets in pre-trained language models. Our for pre-trained bert networks. arXiv preprint
investigation neither introduces any social/ethical arXiv:2007.12223.
bias to the model nor amplifies any bias in the data. Ido Dagan, Oren Glickman, and Bernardo Magnini.
We do not foresee any direct social consequences or 2006. The pascal recognising textual entailment
ethical issues. Furthermore, our proposed method challenge. In Proceedings of the First Inter-
improves performance through model compression, national Conference on Machine Learning Chal-
rendering it energy efficient. lenges: Evaluating Predictive Uncertainty Visual
Object Classification, and Recognizing Textual En-
tailment, MLCW’05, pages 177–190, Berlin, Hei-
delberg. Springer-Verlag.
References
Roy Bar-Haim, Ido Dagan, Bill Dolan, Lisa Ferro, and Shrey Desai, Hongyuan Zhan, and Ahmed Aly. 2019.
Danilo Giampiccolo. 2006. The second PASCAL Evaluating lottery tickets under distributional shifts.
recognising textual entailment challenge. In Pro- In Proceedings of the 2nd Workshop on Deep Learn-
ceedings of the Second PASCAL Challenges Work- ing Approaches for Low-Resource NLP (DeepLo
shop on Recognising Textual Entailment. 2019), pages 153–162.
Luisa Bentivogli, Ido Dagan, Hoa Trang Dang, Danilo Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Giampiccolo, and Bernardo Magnini. 2009. The Kristina Toutanova. 2019. Bert: Pre-training of
fifth pascal recognizing textual entailment challenge. deep bidirectional transformers for language under-
In In Proc Text Analysis Conference (TAC’09). standing. In Proceedings of the 2019 Conference of
the North American Chapter of the Association for
Samuel R Bowman, Gabor Angeli, Christopher Potts, Computational Linguistics: Human Language Tech-
and Christopher D Manning. 2015. A large anno- nologies, Volume 1 (Long and Short Papers), pages
tated corpus for learning natural language inference. 4171–4186.
arXiv preprint arXiv:1508.05326.
Christopher Brix, Parnia Bahar, and Hermann Ney. William B Dolan and Chris Brockett. 2005. Automati-
2020. Successfully applying the stabilized lottery cally constructing a corpus of sentential paraphrases.
ticket hypothesis to the transformer architecture. In In Proceedings of the Third International Workshop
Proceedings of the 58th Annual Meeting of the Asso- on Paraphrasing (IWP2005).
ciation for Computational Linguistics, pages 3909–
3915. Jonathan Frankle and Michael Carbin. 2018. The lot-
tery ticket hypothesis: Finding sparse, trainable neu-
Tom B Brown, Benjamin Mann, Nick Ryder, Melanie ral networks. arXiv preprint arXiv:1803.03635.
Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind
Neelakantan, Pranav Shyam, Girish Sastry, Amanda Jonathan Frankle, Gintare Karolina Dziugaite,
Askell, et al. 2020. Language models are few-shot Daniel M Roy, and Michael Carbin. 2019. Stabi-
learners. arXiv preprint arXiv:2005.14165. lizing the lottery ticket hypothesis. arXiv preprint
arXiv:1903.01611.
Shijie Cao, Chen Zhang, Zhuliang Yao, Wencong Xiao,
Lanshun Nie, Dechen Zhan, Yunxin Liu, Ming Wu, Jonathan Frankle, David J Schwab, and Ari S Morcos.
and Lintao Zhang. 2019. Efficient and effective 2020. The early phase of neural network training.
sparse lstm on fpga with bank-balanced sparsity. arXiv preprint arXiv:2002.10365.
In Proceedings of the 2019 ACM/SIGDA Interna-
tional Symposium on Field-Programmable Gate Ar- Jerome Friedman, Trevor Hastie, Robert Tibshirani,
rays, pages 63–72. et al. 2001. The elements of statistical learning, vol-
Daniel Cer, Mona Diab, Eneko Agirre, Iñigo Lopez- ume 1. Springer series in statistics New York.
Gazpio, and Lucia Specia. 2017. Semeval-2017
task 1: Semantic textual similarity multilingual and Danilo Giampiccolo, Bernardo Magnini, Ido Dagan,
crosslingual focused evaluation. In Proceedings of and Bill Dolan. 2007. The third PASCAL recogniz-
the 11th International Workshop on Semantic Evalu- ing textual entailment challenge. In Proceedings of
ation (SemEval-2017), pages 1–14. the ACL-PASCAL Workshop on Textual Entailment
and Paraphrasing, pages 1–9, Prague. Association
Tianlong Chen, Jonathan Frankle, Shiyu Chang, for Computational Linguistics.
Sijia Liu, Yang Zhang, Michael Carbin, and
Zhangyang Wang. 2020a. The lottery tickets hy- Sharath Girish, Shishira R Maiya, Kamal Gupta, Hao
pothesis for supervised and self-supervised pre- Chen, Larry Davis, and Abhinav Shrivastava. 2020.
training in computer vision models. arXiv preprint The lottery ticket hypothesis for object recognition.
arXiv:2012.06908. arXiv preprint arXiv:2012.04643.Tushar Khot, Ashish Sabharwal, and Peter Clark. 2018. Alex Renda, Jonathan Frankle, and Michael Carbin.
Scitail: A textual entailment dataset from science 2020. Comparing rewinding and fine-tuning
question answering. In Proceedings of the AAAI in neural network pruning. arXiv preprint
Conference on Artificial Intelligence, volume 32. arXiv:2003.02389.
Diederik P Kingma and Jimmy Ba. 2014. Adam: A Pedro Savarese, Hugo Silva, and Michael Maire. 2020.
method for stochastic optimization. arXiv preprint Winning the lottery with continuous sparsification.
arXiv:1412.6980. Advances in Neural Information Processing Systems,
33.
Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jian-
feng Gao. 2019. Multi-task deep neural networks Richard Socher, Alex Perelygin, Jean Wu, Jason
for natural language understanding. In Proceedings Chuang, Christopher D Manning, Andrew Ng, and
of the 57th Annual Meeting of the Association for Christopher Potts. 2013. Recursive deep models
Computational Linguistics, pages 4487–4496. for semantic compositionality over a sentiment tree-
bank. In Proceedings of the 2013 conference on
Xiaodong Liu, Yu Wang, Jianshu Ji, Hao Cheng, empirical methods in natural language processing,
Xueyun Zhu, Emmanuel Awa, Pengcheng He, pages 1631–1642.
Weizhu Chen, Hoifung Poon, Guihong Cao, et al.
Tianxiang Sun, Yunfan Shao, Xiaonan Li, Pengfei Liu,
2020. The microsoft toolkit of multi-task deep
Hang Yan, Xipeng Qiu, and Xuanjing Huang. 2020.
neural networks for natural language understanding.
Learning sparse sharing architectures for multiple
In Proceedings of the 58th Annual Meeting of the
tasks. In Proceedings of the AAAI Conference on
Association for Computational Linguistics: System
Artificial Intelligence, volume 34, pages 8936–8943.
Demonstrations, pages 118–126.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob
Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz
and Trevor Darrell. 2018. Rethinking the value of Kaiser, and Illia Polosukhin. 2017. Attention is all
network pruning. arXiv preprint arXiv:1810.05270. you need. arXiv preprint arXiv:1706.03762.
Paul Michel, Omer Levy, and Graham Neubig. 2019. Alex Wang, Amanpreet Singh, Julian Michael, Felix
Are sixteen heads really better than one? In Ad- Hill, Omer Levy, and Samuel R Bowman. 2018.
vances in Neural Information Processing Systems, Glue: A multi-task benchmark and analysis platform
pages 14014–14024. for natural language understanding. arXiv preprint
arXiv:1804.07461.
Pavlo Molchanov, Stephen Tyree, Tero Karras, Timo
Aila, and Jan Kautz. 2016. Pruning convolutional Alex Warstadt, Amanpreet Singh, and Samuel R Bow-
neural networks for resource efficient inference. man. 2019. Neural network acceptability judgments.
arXiv preprint arXiv:1611.06440. Transactions of the Association for Computational
Linguistics, 7:625–641.
Ari S Morcos, Haonan Yu, Michela Paganini, and Yuan-
dong Tian. 2019. One ticket to win them all: gen- Adina Williams, Nikita Nangia, and Samuel Bowman.
eralizing lottery ticket initializations across datasets 2018. A broad-coverage challenge corpus for sen-
and optimizers. arXiv preprint arXiv:1906.02773. tence understanding through inference. In Proceed-
ings of the 2018 Conference of the North American
Rajiv Movva and Jason Y Zhao. 2020. Dissecting lot- Chapter of the Association for Computational Lin-
tery ticket transformers: Structural and behavioral guistics: Human Language Technologies, Volume
study of sparse neural machine translation. arXiv 1 (Long Papers), pages 1112–1122. Association for
preprint arXiv:2009.13270. Computational Linguistics.
Sai Prasanna, Anna Rogers, and Anna Rumshisky. Haoran You, Chaojian Li, Pengfei Xu, Yonggan Fu,
2020. When bert plays the lottery, all tickets are Yue Wang, Xiaohan Chen, Richard G Baraniuk,
winning. arXiv preprint arXiv:2005.00561. Zhangyang Wang, and Yingyan Lin. 2019. Drawing
early-bird tickets: Towards more efficient training of
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine deep networks. arXiv preprint arXiv:1909.11957.
Lee, Sharan Narang, Michael Matena, Yanqi Zhou,
Haonan Yu, Sergey Edunov, Yuandong Tian, and Ari S
Wei Li, and Peter J Liu. 2019. Exploring the limits
Morcos. 2019. Playing the lottery with rewards
of transfer learning with a unified text-to-text trans-
and multiple languages: lottery tickets in rl and nlp.
former. arXiv preprint arXiv:1910.10683.
arXiv preprint arXiv:1906.02768.
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Hattie Zhou, Janice Lan, Rosanne Liu, and Jason
Percy Liang. 2016. SQuAD: 100,000+ questions for Yosinski. 2019. Deconstructing lottery tickets: Ze-
machine comprehension of text. In Proceedings of ros, signs, and the supermask. arXiv preprint
the 2016 Conference on Empirical Methods in Natu- arXiv:1905.01067.
ral Language Processing, pages 2383–2392, Austin,
Texas. Association for Computational Linguistics.A Appendix the task specific layers is set to be 0.1, except 0.3
for MNLI and 0.05 for CoLa. We clipped the gra-
A.1 Single Task Experiments
dient norm within 1. All the texts were tokenized
A.1.1 Data using wordpieces, and were chopped to spans no
GLUE. GLUE is a collection of nine NLU tasks. longer than 512 tokens.
The benchmark includes question answering (Ra- Worth mentioning, the task-specific super tickets
jpurkar et al., 2016), linguistic acceptability (CoLA, used in Ticket Share are all selected during the case
Warstadt et al. 2019), sentiment analysis (SST, where a matched learning rate (i.e., 5 × 10−5 ) is
Socher et al. 2013), text similarity (STS-B, Cer used in single task fine-tuning. We empirically find
et al. 2017), paraphrase detection (MRPC, Dolan that, rewinding the super tickets selected under a
and Brockett 2005), and natural language inference matched optimization settings usually outperforms
(RTE & MNLI, Dagan et al. 2006; Bar-Haim et al. those selected under a mismatched settings (i.e. us-
2006; Giampiccolo et al. 2007; Bentivogli et al. ing two different learning rates in single-task fine-
2009; Williams et al. 2018) tasks. Details of the tuning and rewinding/multi-task learning). This
GLUE benchmark, including tasks, statistics, and agrees with previous observation in literature of
evaluation metrics, are summarized in Table 9. Lottery Ticket Hypothesis, which shows that un-
structured winning tickets are not only related to its
A.1.2 Training weight initialization, but also model optimization
We use Adamax as the optimizer. A linear learning path.
rate decay schedule with warm-up over 0.1 is used.
We apply a gradient norm clipping of 1. We set A.2.2 Multi-task Model Downstream
the dropout rate of all task specific layers as 0.1, Fine-tuning
except 0.3 for MNLI and 0.05 for CoLA. All the We follow the exact optimization setting as in Sec-
texts were tokenized using wordpieces, and were tion 5.2 and in Section A.1.2, except we choose
chopped to spans no longer than 512 tokens. All learning rate in {1 × 10−5 , 2 × 10−5 , 5 × 10−5 , 1 ×
experiments are conducted on Nvidia V100 GPUs. 10−4 , 2 × 10−4 }, and choose the dropout rate of all
A.1.3 Evaluation Results Statistics task specific layers in {0.05, 0.1, 0.2, 0.3}.
We conduct 5 sets of experiments on different ran- A.3 Domain Adaptation Experiments
dom seeds. Each set of experiment consists of
fine-tuning, pruning, and rewinding at 8 sparsity A.3.1 Data
levels. For results on GLUE dev set (Table 1), we SNLI. is one of the most widely used entailment
report the average score of super tickets rewinding dataset for NLI.
results over 5 sets of experiments. The standard SciTail involves assessing whether a given premise
deviation of the results is shown in Table 6. The entails a given hypothesis. In contrast to other en-
statistics of the percent of weight remaining in the tailment datasets, the hypotheses in SciTail is cre-
selected super tickets are shown in Table 7. ated from science questions. These sentences are
For results on GLUE test set (Table 2), as the linguistically challenging. The corresponding an-
evaluation server sets an limit on submission times, swer candidates and premises come from relevant
we only evaluate the test prediction under a sin- web sentences. The lexical similarity of premise
gle random seed that gives the best task-average and hypothesis is often high, making SciTail partic-
validation results. ularly challenging.
Details of the SNLI and SciTail, including tasks,
A.2 Multi-task Learning Experiments
statistics, and evaluation metrics, are summarized
A.2.1 Multi-task Model Training in Table 9.
We adopt the MT-DNN code base and adopt the
exact optimization settings in Liu et al. (2020). We A.3.2 Training
use Adamax as our optimizer with a learning rate For single task model domain adaptation from
of 5 × 10−5 and a batch size of 32. We train for a MNLI to SNLI/SciTail, we follow the exact op-
maximum number of epochs of 5 with early stop- timization setting as in Section 5.2 and in Sec-
ping. A linear learning rate decay schedule with tion A.1.2, except we choose the learning rate in
warm-up over 0.1 was used. The dropout rate of all {5 × 10−5 , 1 × 10−4 , 5 × 10−4 }.RTE MRPC CoLA STS-B SST QNLI QQP MNLI
SuperTBASE 1.09 0.20 0.93 0.07 0.16 0.10 0.08 0.04
SuperTLARGE 1.46 0.61 1.32 0.16 0.17 0.07 0.11 0.02
Table 6: Standard deviation of the evaluation results on GLUE development set over 5 different random seeds.
RTE MRPC CoLA STS-B SST QNLI QQP MNLI
SuperTBASE (Mean) 0.83 0.86 0.89 0.86 0.93 0.93 0.93 0.93
SuperTBASE (Std Dev) 0.07 0.08 0.04 0.06 0.07 0.00 0.00 0.00
SuperTLARGE (Mean) 0.82 0.66 0.84 0.77 0.79 0.90 0.84 0.92
SuperTLARGE (Std Dev) 0.04 0.04 0.00 0.10 0.05 0.03 0.00 0.00
Table 7: Statistics of the percent of weight remaining of the selected super tickets over 5 different random seeds.
A.4 Sensitivity Analysis
A.4.1 Randomness Analysis BERT-base 94
BERT-large
92
For single task experiments in Table 5, we vary 92
90
Accuracy
the random seeds only and keep all other hyper- 90
QQP
88
parameters fixed. We present the standard deviation 88
86
of the validation results over 5 trails rewinding ex- 86
84
periments. For multi-task downstream fine-tuning 1.0 0.8 0.6 0.4
84
1.0 0.8 0.6 0.4
experiments, we present the standard deviation of
the validation results over 5 trails, each result aver- 92
92
aged over learning rates in {5×10−5 , 1×10−4 , 2× 90
Accuracy
90
QNLI
10−4 }. This is because the downstream fine-tuning 88
88
performance is more sensitive to hyper-parameters. 86
86
84
84
A.4.2 Hyper-parameter Analysis 1.0 0.8 0.6 0.4 1.0 0.8 0.6 0.4
We further analyze the sensitivity of Ticket 90
ShareLARGE model to changes in hyper-parameters 85
85
Accuracy
in downstream fine-tuning in some GLUE tasks.
MRPC
We vary the learning rate in {5 × 10−5 , 1 × 80 80
10−4 , 2×10−4 } and keep all other hyper-parameter
75 75
fixed. Table 8 shows the standard deviation of the 1.0 0.8 0.6 0.4 1.0 0.8 0.6 0.4
validation results over different learning rates, each 70
70
result averaged over 5 different random seeds. As 60
Accuracy
can be seen, Task ShareLARGE exhibits stronger ro- 60
CoLA
50
bustness to changes in learning rate in downstream 50
fine-tuning. 40
40
30
1.0 0.8 0.6 0.4 1.0 0.8 0.6 0.4
RTE MRPC CoLA STS-B SST
MT-DNNLarge 1.26 0.86 1.05 0.42 0.26 90.0 90.0
Ticket ShareLarge 0.44 0.58 0.61 0.36 0.25
87.5 87.5
Pearson
STS-B
Table 8: Standard deviation of some tasks in GLUE 85.0 85.0
(dev) over 3 different learning rates. 82.5 82.5
80.0 80.0
1.0 0.8 0.6 0.4 1.0 0.8 0.6 0.4
Percent of Weight Remaining Percent of Weight Remaining
A.5 Phase Transition on GLUE Tasks
Figure 7: Single task fine-tuning evaluation results of
Figure 7 shows the phase transition plots on win-
the winning tickets on the GLUE development set un-
ning tickets on GLUE tasks absent from Figure 4. der various sparsity levels.
All experimental settings conform to Figure 4.Corpus Task #Train #Dev #Test #Label Metrics
Single-Sentence Classification (GLUE)
CoLA Acceptability 8.5k 1k 1k 2 Matthews corr
SST Sentiment 67k 872 1.8k 2 Accuracy
Pairwise Text Classification (GLUE)
MNLI NLI 393k 20k 20k 3 Accuracy
RTE NLI 2.5k 276 3k 2 Accuracy
QQP Paraphrase 364k 40k 391k 2 Accuracy/F1
MRPC Paraphrase 3.7k 408 1.7k 2 Accuracy/F1
QNLI QA/NLI 108k 5.7k 5.7k 2 Accuracy
Text Similarity (GLUE)
STS-B Similarity 7k 1.5k 1.4k 1 Pearson/Spearman corr
Pairwise Text Classification
SNLI NLI 549k 9.8k 9.8k 3 Accuracy
SciTail NLI 23.5k 1.3k 2.1k 2 Accuracy
Table 9: Summary of the GLUE benchmark, SNLI and SciTail.You can also read

















































