Perspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Noname manuscript No.
(will be inserted by the editor)
Perspectives and Prospects on Transformer Architecture for
Cross-Modal Tasks with Language and Vision
Andrew Shin · Masato Ishii · Takuya Narihira
arXiv:2103.04037v2 [cs.CV] 9 Nov 2021
Received: date / Accepted: date
Abstract Transformer architectures have brought about fun- learn the language representation. While a plethora of varia-
damental changes to computational linguistic field, which tions exist as to specific ways to extract features and how to
had been dominated by recurrent neural networks for many blend them into common embedding space, the fundamental
years. Its success also implies drastic changes in cross-modal pipeline has almost invariably been restricted to the combi-
tasks with language and vision, and many researchers have nation of CNN and RNN.
already tackled the issue. In this paper, we review some of
This steadfast landscape started to change with the intro-
the most critical milestones in the field, as well as overall
duction of transformer architecture (Vaswani et al. (2017)).
trends on how transformer architecture has been incorpo-
Transformer has first demonstrated its capacity in natural
rated into visuolinguistic cross-modal tasks. Furthermore,
language processing (NLP), achieving state-of-the-art per-
we discuss its current limitations and speculate upon some
formances in countless number of NLP tasks (Peters et al.
of the prospects that we find imminent.
(2018); Dai et al. (2019); Yang et al. (2019b)), and has rapidly
Keywords language and vision · transformer · attention · replaced recurrent neural networks. Its application has also
BERT been expanded to speech recognition domain (Dong et al.
(2018); Wang et al. (2020c)). While a variety of transformer-
based language models exist, BERT (Devlin et al. (2019))
1 Introduction has particularly gained wide attention not only with its per-
formance, but also with its unique approach to pre-training
Ever since the advent of deep learning revolution, the de- and adaptability to downstream tasks. A GPT-line of works
facto standard for cross-modal tasks with language and vi- (Radford and Sutskever (2018); Radford et al. (2019); Brown
sion has been to use convolutional neural networks (CNN) et al. (2020)) have also demonstrated that pre-training with
(LeCun et al. (1998); Krizhevsky et al. (2012)) to extract a very large corpus and fine-tuning the model to a target
features from visual domain, with VGG (Simonyan and Zis- task can outperform conventional models by a large mar-
serman (2015)) or ResNet (He et al. (2016)) being the most gin. In particular, GPT-3 shows that pre-training with ex-
frequently used CNN architectures, while employing recur- tremely large amount of corpus and parameters easily ex-
rent neural networks (RNN) (Elman (1990)), such as long tends to high performance in few-shot learning tasks without
short-term memory (LSTM) (Hochreiter and Schmidhuber performing any fine-tuning.
(1997)) or gated recurrent unit (GRU) (Cho et al. (2014)), to
Success of transformer architecture in language domain
Andrew Shin
Sony Corporation
has naturally led to its further application in cross-modal
E-mail: andrew.shin@sony.com tasks involving language and vision. ViLBERT (Lu et al.
Masato Ishii
(2019)) was one of the first models to demonstrate that pre-
Sony Corporation training objectives of BERT can be extended to cross-modal
E-mail: masato.a.ishii@sony.com learning, and that it obtains state-of-the-art or comparable
Takuya Narihira performances to models based on conventional CNN-RNN
Sony Corporation approach. Many other models followed with similar approach,
E-mail: takuya.narihira@sony.com and now the assumption that pre-training with a large amount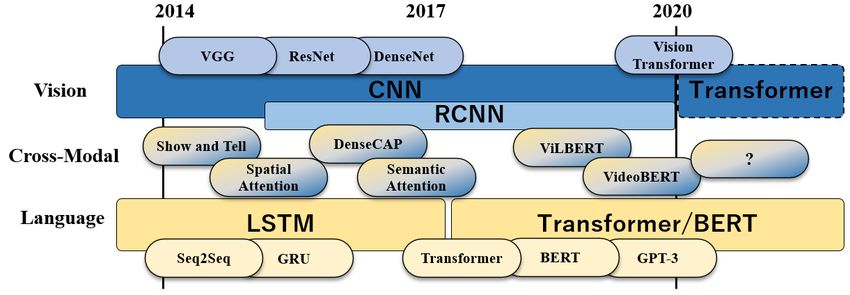
2 Andrew Shin et al.
Fig. 1: A brief timeline showing important models in vision (upper) and language (lower) domains respectively, and how
they have affected approaches in cross-modal domains (middle).
of data leads to superior performance holds true for cross- uation metrics in Sec 2. We also review the elementary trans-
modal domain as well. former architecture and its variations, mostly restricted to
Yet, many important arguments can be raised with re- language domain, centered around BERT in Sec 3. We then
gards to the limitations and prospects of transformer-based introduce and inspect the recent models on cross-modal tasks
cross-modal models. For example, while most models re- that employ transformer architecture in Sec 4, focusing on
quire that images or videos be tokenized and serialized in their architectural modifications and pre-training schemes.
some way, they still fundamentally rely on CNN-based mod- While the works introduced in Sec 4 mostly employ trans-
els to extract features for each visual token. It also remains former architecture to acquire linguistic representation, Sec 5
arguable whether transformers learn fundamentally superior introduces works that examine representing vision with trans-
embeddings or whether its performance is simply due to a former architecture, suggesting the possibility of replacing
large amount of computations and data, bringing up the is- convolutional neural networks. Sec 6 discusses some of the
sue of computational efficiency. Furthermore, blending the prospects on transformer architecture for cross-modal tasks.
transformer architecture with generative models is an open Finally, we conclude the paper in Sec 7, by summarizing the
challenge, which is just beginning to be explored. important points raised in the paper, while also discussing
Figure 1 shows a brief timeline over the past few years the current limitations and future works.
with important models in vision and language domains re-
spectively, and how they have influenced the approaches for
2 Preliminaries I: Visuolinguistic Tasks
cross-modal tasks. Looking back at the important milestones
and current trends, we project that transformer architecture
In this section and Sec 3, we briefly go over the preliminaries
may take over the vision representation part of cross-modal
necessary to understand the topics and implications put for-
tasks, as its performance in vision domain has been shown
ward by this paper. We first review some of the representa-
to be comparable to CNNs (Dosovitskiy et al. (2020)). More
tive tasks in visuolinguistic domain, namely image caption-
about this will be discussed in Sec 5 and Sec 6.
ing and visual question answering, with commonly used ap-
This paper attempts to review some of the representa- proaches. We also visit other important tasks, some of which
tive works on transformer-based cross-modal models, with have become benchmark tasks for transformer-based cross-
emphasis on pre-training schemes, discussing the common modal tasks. We then go over evaluation metrics for these
characteristics in various models along with their differences. tasks.
We also investigate models of novel and promising direc- .
tion, such as transformer-based vision representation, or im-
age generation from text. By doing so, our goal is to acquire
up-to-date insights as to various aspects of cross-modal learn- 2.1 Classical Tasks
ing, as well as prospects on how they may continue to influ-
ence deep learning field. Prior to deep learning era, early models frequently tack-
The rest of the paper is organized as following: we first led visuolinguistic cross-modal tasks with template-based
review the conventional visuolinguistic cross-modal tasks model (Barbu et al. (2012); Elliott and Keller (2013); Ushiku
and recent benchmark tasks, along with frequently used eval- et al. (2012)) or ranking and retrieval models (Farhadi et al.Perspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision 3
(2010); Ordonez et al. (2011); Hodosh et al. (2013)). With et al. (2014); Venugopalan et al. (2015b,a)) still heavily re-
the advent of deep learning, however, the mainstream paradigm lied on CNNs and RNNs for representing video and lan-
for tackling cross-modal tasks has rapidly shifted towards guage.
the approach incorporating convolutional and recurrent neu-
ral networks.
2.2 Benchmark Tasks
Image captioning and visual question answering (VQA)
(Antol et al. (2015); Zhang et al. (2016); Goyal et al. (2017)) While image captioning and visual question answering have
have conventionally been considered two of the most repre- been exemplary visuolinguistic cross-modal tasks, other im-
sentative examples of cross-modal tasks involving language portant and intriguing variations have emerged. In particu-
and vision. In image captioning, the model is trained with lar, some of these novel variations, along with VQA task,
pairs of image and the captions describing that image, and have been consolidated as benchmark tasks for pre-trained
learns to generate descriptive captions for unseen images. cross-modal tasks. Interestingly, image captioning task, de-
While early works relied on straightforward combination of spite being a representative visuolinguistic task, has only
CNN and LSTM, (Vinyals et al. (2015); Karpathy and Li rarely been tackled with recent transformer-based models.
(2014)), advanced models appeared with dense localization We conjecture that it may be attributable to the fact that im-
(Johnson et al. (2016)), semantic attention (Xu et al. (2015); age captioning task employs a different array of evaluation
You et al. (2016); Zhou et al. (2016)), to name a few. Some metrics, and makes it less intuitive to compare the perfor-
works (Dai et al. (2017)) went steps further to incorporate mance along with other simple accuracy-based tasks, as we
generative adversarial networks (GANs) (Goodfellow et al. shall see in Sec. 2.3. However, it is still being actively exam-
(2014)) for image captioning, in which GANs are used to ined in video and language field, and is likely to remain an
predict whether the captioning is natural. important indicator of cross-modal models’ performances.
VQA is a task in which a question in natural language One of the frequently visited benchmark tasks is visual
is asked about an image, and the model is asked to provide commonsense reasoning (VCR) (Zellers et al. (2019)), which
an answer to the question. While many variations of VQA extends VQA by not only asking a question about a referred
task exist, VQA as a benchmark task usually refer to the one agent’s action, but also asking why the model chose that an-
based on MS COCO (Lin et al. (2014)) with roughly 0.6M swer. This notably attempts to accomplish the logical infer-
questions, each of which comes with 10 crowd-sourced an- ence made by humans. Three subtasks with varying difficul-
swers. For VQA, most approaches can be categorized by 4 ties exist within the task, where 1) the question is given and
primary components; image representation, text represen- the model predicts the answer (Q→A), or 2) the question
tation, common embedding scheme, and attention mecha- and the answer are given and the model predicts the rea-
nism. Image representation mostly relied on CNNs, often son or intention (QA→R), or 3) the question is given and
employing region detection models, while text representa- the model predicts both the answer and the reason for that
tions may rely on RNN-line of models, Skipthoughts (Kiros answer (Q→AR). VCR dataset contains roughly 290k mul-
et al. (2015)), or more classical models, such as word2vec tiple choice questions accompanied by bounding boxes and
(Mikolov et al. (2013)) or Glove (Pennington et al. (2014)). semantic masks to indicate which agent the question or the
While cross-modal embedding scheme may be simple con- answer candidate refers to.
catenation or element-wise addition and multiplications, more Natural language for visual reasoning (NLVR) (Suhr et al.
sophisticated schemes have also been proposed, such as com- (2019)) also requires an advanced understanding of vision
pact bilinear pooling (Fukui et al. (2016)), low-rank bilinear and language, by judging whether a statement is true with re-
pooling (Kim et al. (2017)), or cross-modal tucker fusion gards to a juxtaposition of two images, based on the dataset
(Ben-younes et al. (2017)). Various attention mechanisms consisting of roughly 100k human statements made about
(Yang et al. (2015); Lu et al. (2016)) have also been pro- the pairs of images. The unique setting of the task in which
posed, and have demonstrated its effectiveness.1 there are two images to consider brings new challenges as to
Image captioning and VQA have also been extended to how to embed the images, e.g., whether they should be em-
cross-modal domain involving language and video, as video bedded separately or together, and how the decision should
captioning (Das et al. (2013); Gella et al. (2018)) and video affect common embedding with text. RefCOCO (Yu et al.
QA (Tapaswi et al. (2016)) respectively. As in image cap- (2016)) is also a frequently visited benchmark task, where
tioning and VQA, the models in video domain (Donahue the goal is to identify which object in the image is referred
to by the linguistic statement, based on the dataset consisting
1 Note that attention mechanism referred to here, while nearly iden-
of 140k referring expressions from ReferitGame (Kazemzadeh
tical in its motivation, deviates from the same term employed in trans-
et al. (2014)). Grounding referring expressions (Kazemzadeh
former architecture, and must not be confused with the works that do
employ transformer architecture to tackle the same task, which will be et al. (2014)), caption-based image retrieval (Young et al.
introduced in Sec. 4 (2014)), and embodied visual recognition (Yang et al. (2019a))4 Andrew Shin et al.
are also noteworthy tasks involving vision and language. Fi- usually appear to retain mutual agreement to a fair extent.
nally, image generation from text is also an important yet Also, when necessary, accuracy is measured at different re-
largely unexplored axis in visuolinguistic task. So far, it has call levels, as in image retrieval task shown in Table 1.
mostly been limited to certain target domains, such as birds
or flowers (Reed et al. (2016); Zhang et al. (2018b)), but
promising works have started to appear, as we will see in 3 Preliminaries II: Transformer-Based models
Sec. 6.
As we shall see in Sec 4.1.2, benchmark tasks appear to In this section, we first describe transformer architecture by
be less consolidated in video and language domain, although looking at multi-heads self-attention mechanism. We then
video captioning tasks with YouCook2 (Zhou et al. (2017)) introduce BERT, which is a transformer-based model and
and ActivityNet (Heilbron et al. (2015)) are frequently vis- has become a crucial component in recent surge of transformer-
ited. based cross-modal models, with emphasis on its unique pre-
training objectives. We also introduce pre-training objec-
tives from models other than BERT for reference.
2.3 Evaluation Metrics
Evaluation metrics for visuolinguistic tasks can be catego- 3.1 Transformer Architecture
rized as those for classification task and those for genera-
tion tasks, such as image captioning. While the classifica- Vaswani et al. (2017) proposed transformer architecture, and
tion tasks mostly rely on straightforward accuracy, genera- demonstrated that it outperforms the then-dominant RNN or
tion tasks usually employ multiple metrics for evaluation. CNN-based approaches on several sequential transduction
BLEU (Papineni et al. (2002)), originally proposed for ma- tasks, such as machine translation. Transformer comprises
chine translation, is one of the most frequently used evalua- an encoder part and a decoder part, and both of them con-
tion metrics and computes the portion of n-grams in candi- sist of a series of self-attention based modules. Differently
date caption that also appear in ground truth. While BLEU from CNN and RNN, it adopts self-attention as a basic oper-
places emphasis on precision, ROUGE (Lin (2004)) takes ation in the model instead of convolution or memory gating,
more recall-oriented approach by counting the occurrences which leads to obtaining suitable properties for handling se-
of exact match of n-grams. While BLEU and ROUGE look quential data as will be shown later.
for exact match of words, METEOR (Banerjee and Lavie In a self-attention process, each input vector is first trans-
(2005)) evaluates n-grams considering synonyms and stems, formed into three vectors called query, key, and value. The
based on WordNet (Miller (1995)). CIDEr (Vedantam et al. output is computed as a weighted sum of the values, where
(2015)), designed specifically for image captioning task, looks the weight of each value is assigned according to the simi-
at the consensus between generated image caption and the larity between the query and the corresponding key. Let Q,
reference caption, with assigning more weights on n-grams K, and V be matrices that contain all queries, keys, and val-
that appear specifically for the image and less weights on ues extracted from the given input vectors, respectively. The
n-grams that appear frequently for all images. SPICE (An- self-attention process can then be formulated as
derson et al. (2016)) is also a popular metric for image cap- QK T
tioning task, where a set of tuples are extracted from the Attention(Q, K, V ) = softmax( √ )V, (1)
dk
semantic parse graph of the sentences. All of these metrics
are also widely used for video captioning task as well. where dk is a dimensionality of the key.
Most of the benchmark tasks apart from captioning eval- To boost the flexibility of the self-attention process, the
uate the performance with straightforward accuracy, although transformer adopted multi-head attention mechanism instead
accuracy might be defined slightly differently depending on of the simple self-attention, as shown in Eq. (2). In multi-
the task. For example, VQA defines accuracy with respect head attention, several self-attention processes are conducted
to the number of humans that provided the same answer in parallel, and each output is integrated by concatenation
out of all ground truth answers available for the question. followed by a linear projection to obtain the final output vec-
Also, GQA (Hudson and Manning (2019)) proposes to sup- tor as shown in the following equations:
plement accuracy by proposing additional metrics such as MultiHead(Q, K, V ) = Concat(head1 , ..., headh )W O ,(2)
consistency, validity and plausibility. While the straightfor-
headi = Attention(QWiQ , KWiK , V WiV ),(3)
ward nature of the accuracy metric may risk loss of account-
ability for more subtle aspects of performance, such as the where W O is a projection matrix to integrate the outputs
model’s ability to yield the second best answer when not of all attention processes. The queries, keys, and values for
giving the correct answer, it is usually reported over a set each attention process are computed by a linear projection
of frequently visited tasks, and such aggregated evaluations of the original ones, and their projection matrices WiQ , WiK ,Perspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision 5
and WiV are jointly optimized with W O and other trainable prediction. In masked language modeling, tokens are ran-
parameters via training. domly masked with 15% probability, and the model is trained
In the self-attention process, the order of the input vec- to predict those masked tokens. For next sentence predic-
tors does not affect the resulting output vectors. For exam- tion, two sentences are provided, where the second sentence
ple, a model’s prediction on a certain sentence does not de- may be actual succeeding sentence or a random sentence
pend on the order of words in the sentence, which should be with 50% probability, and the model is given a task of bi-
inappropriate in many NLP tasks. To avoid this problem, po- nary classification of whether the second sentence is an ac-
sition information of each input is encoded and added to the tual succeeding sentence. While the first objective of masked
input embedded token before being fed to the transformer- language modeling aims to learn token-level dependency,
based model. Specifically, the position information is en- the motivation of the second task is to learn the inter-sentence
coded as following: relationship. Although (Liu et al. (2019b)) has shown that
the next sentence prediction turns out not to be crucial for
PE(p,2i) = sin(p/100002i/dmodel ), (4)
the model’s performance, these two objectives, along with
PE(p,2i+1) = cos(p/100002i/dmodel ), (5) the bidirectional architecture, characterize and differentiate
BERT from other transformer-based language models.
where p is the position of the target token in the input se-
For reference, we would like to highlight a few more
quence, dmodel and i are the dimensionality of the embedded
notable pre-training objectives proposed by other models.
token and its index, respectively. As for positional embed-
XLNet (Yang et al. (2019b)) attempts to overcome some of
ding, other embedding methods have been proposed. For ex-
the drawbacks of masked language modeling of BERT, e.g.,
ample, (Wang et al. (2021a)) have shown that relative sinu-
the absence of masked tokens in real data, or its inability to
soidal positional embedding outperforms absolute positional
model the joint probability with product rule used in autore-
embedding in longer distances. Modified attention matrix
gressive language modeling. Specifically, they propose per-
(MAM) (Dufter et al. (2021)) has also been proposed, where
mutation language modeling, where the model maximizes
positional embedding is added as bias of attention map.
likelihood of the input sequence over all possible permu-
Some of the distinctive merits of transformer over pre-
tations of the factorization order, thereby learning bidirec-
vious models are modeling long-term dependency and its
tional context while retaining the merits of autoregressive
flexibility for parallel computing. For instance, RNNs gen-
models. MT-DNN (Liu et al. (2019a)) performs multi-task
erally find it difficult to preserve context as the distance be-
learning, which leverages supervised data from multiple re-
tween tokens becomes longer. Since they are executed in a
lated tasks, such as single-sentence or pairwise text classi-
sequential manner, it also becomes non-trivial to run them in
fication and relevance ranking, on top of language model
parallel. Long-distance dependency is also challenging for
pre-training. The paper claims that it prevents the model
CNNs, as it would require a proportionally large number of
from overfitting to a specific task, with complementary ef-
layers. On the other hand, attention mechanism can model
fect to general language model pre-training. (Chang et al.
dependency for words of any distance within the pre-defined
(2020)) proposes three pre-training objectives with empha-
sequence length, and as it does not require sequential order
sis on capturing granularity of semantics between the query
of the input, it is highly suitable for parallel, distributed com-
and document, namely inverse cloze task to capture local se-
putation.
mantic context, body first selection to capture global context
within the document, and wiki link prediction to capture dis-
tant inter-article context. Their experiments suggest that the
3.2 BERT
proposed pre-training objectives can perform significantly
While a large number of variations on transformer exist, better than masked language modeling.
BERT (bidirectional encoder representations from transform-
ers) (Devlin et al. (2019)) is particularly important in our
topic, as its architecture has been employed by many cross- 4 Analysis of Cross-Modal Embeddings
modal models, as well as its pre-training tasks that have
been extended to account for cross-modal setting. Follow- We now look into cross-modal models that have employed
ing transformer, BERT applies layer normalization (Ba et al. transformer/BERT architectures. We first review their pre-
(2016)) on top of multi-head attention with residual connec- training objectives, many of which have been directly in-
tion, and applies feed-forward propagation with its unique spired by BERT, albeit with notable variations, and spec-
choice of non-linear activation function, namely Gaussian ulate on how they relate to the models’ performances. We
error linear units (GELU) (Hendrycks and Gimpel (2016)). also look at the models’ attempts to construct network archi-
BERT is also known for its unique choice of pre-training tectures that learn inter-modal dependency, along with how
tasks, namely masked language modeling and next-sentence they deal with distinct modalities for mutual compatibility.6 Andrew Shin et al.
Fig. 2: Visualization of representative cross-modal models in terms of dataset size used for pre-training, performance as measured by VQA task,
the type of pre-training objectives employed, and the model size. The size of block for respective model corresponds to the size of the model, as
approximated by the implementation details reported in respective paper. VM1 and VM2 refer to two distinct tasks of masked visual modeling
with image regions.
4.1 Pre-training Tasks Another pre-raining task of BERT, next sentence prediction,
is mostly converted to binary classification of whether in-
One of the primary arguments laid by the transformer-based put image and sentence are semantically matched. This also
language models, including BERT, is that large-scale pre- is performed by most cross-modal models, with few excep-
training is the key to their successful performance. It fol- tions such as VL-BERT (Su et al. (2020)) or UnifiedVLP
lows evidently that the choice of pre-training tasks is es- (Zhou et al. (2019)) that explicitly opt not to perform this
sential in obtaining a high-quality language model. Cross- pre-training task. InterBERT again makes a unique variation
modal models employing transformer architecture have gen- by explicitly involving matching with hard negative exam-
erally followed the same presumption, placing a strong em- ples.
phasis on the design of pre-training objectives, and the key One of the key challenges for pre-training tasks among
challenge is consequently how to replicate large-scale pre- cross-modal embedding models is with the way they imple-
training with cross-modal setting. For example, as shown in ment masked language modeling task for visual inputs, as it
Sec 3.2, BERT is known for its unique pre-training tasks of cannot be naively extended to vision domain in a straightfor-
masked language modeling and next sentence classification, ward manner, due to the non-sequential nature of vision. In
but since it is designed solely for language, it inevitably re- fact, some models, such as B2T2 and VisualBERT (Li et al.
quires adjustments to be extended to cross-modal setting. (2019)), simply opt not to perform any extended masked
While most models adopt those two pre-training tasks in modeling task for visual inputs. On the other hand, many
modified ways, some models propose additional pre-training models propose novel ways to apply masked language mod-
tasks designed specifically for cross-modal setting. eling for visual tokens. For example, ViLBERT handles this
Masked language modeling, one of the two pre-training challenge by proposing to mask the image regions extracted
tasks of BERT, is used as is for linguistic input tokens in by Faster R-CNN (Ren et al. (2015)), and trains the model
cross-modal models, almost without exception. One notable to predict the class distribution of the region, with the class
variation is InterBERT (Lin et al. (2021)), which performs distribution output from Faster R-CNN as the ground truth.
masked language modeling by replacing the masked word VL-BERT (Su et al. (2020)) and Unicoder-VL (Li et al.
with continuous words, rather than random words as with (2020a)) are also notable examples that perform masked vi-
most other models. B2T2 (Alberti et al. (2019)) also extends sual modeling with class prediction. In particular, VL-BERT
the task by training language model while seeing the image. proposes masked RoI classification with linguistic clues, wherePerspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision 7
VQA GQA VCR RefCOCO NLVR2 IR ZS IR
dev/std dev/std Q/A QA/R Q/AR val/ testA/testB test-P R1/R5/R10 R1/R5/R10
ViLBERTnopt (Lu et al. (2019)) 68.93/– – 69.26 71.01 49.48 68.61/75.97/58.44 – 45.50/76.78/85.02 0.00/0.00/0.00
ViLBERT 70.55/70.92 – 73.3 74.6 54.8 72.34/78.52/62.61 – 58.20/84.90/91.52 31.86/61.12/72.80
B2T2(Alberti et al. (2019)) – – 72.6 75.7 55.0 – – – –
B2T2ensemble – – 74.0 77.1 57.1 – – – –
VL-BERTnopt (Su et al. (2020)) 69.58/– – – – – 66.03/71.87/56.13 – – –
VL-BERT 71.16/– – – – – 71.60/77.72/60.99 – – –
VL-BERTlarge 71.79/72.22 – 75.8 78.4 59.7 72.59/78.57/62.30 – – –
LXMERT(Tan and Bansal (2019)) –/72.5 60.0/60.3 – – – – – – –
Unicoder-VLzs (Li et al. (2020a)) – – – – – – – 48.4/76.0/85.2 –
Unicoder-VLnopt – – – – – – – 57.8/82.2/88.9 –
Unicoder-VL – – 73.4 74.4 54.9 – – 71.5/90.9/94.9 –
VisualBERT(Li et al. (2019)) 70.80/71.00 – 71.6 73.2 52.4 – 67.0 – –
UNITERbase (Chen et al. (2020c)) 72.70/72.91 – 75.0 77.2 58.2 75.31/81.30/65.58 77.85 72.52/92.36/96.08 66.16/88.40/92.94
UNITERlarge 73.82/74.02 – 77.3 80.8 62.8 75.9/81.45/66.7 79.98 75.56/94.08/96.76 68.74/89.2/93.86
MiniVLM(Wang et al. (2020b)) 69.39/69.06 – – – – – 73.93 – –
PixelBERTr50 (Huang et al. (2020b)) 71.35/71.42 – – – – – 72.4 59.8/85./91.6 –
PixelBERTx152 74.45/74.55 – – – – – 77.2 71.5/92.1/95.8 –
OSCARbase (Li et al. (2020c)) –/73.44 – – – – – 78.36 – –
OSCARlarge –/73.82 61.58/61.62 – – – – 80.37 – –
UnifiedVLP(Zhou et al. (2019)) 70.5/70.7 – – – – – – – –
InterBERTnopt (Lin et al. (2021)) – – 63.6 63.1 40.3 – – 53.1/80.6/87.9 –
InterBERT – – 73.1 74.8 54.9 – – 61.9/87.1/92.7 49.2/77.6/86.0
ERNIE-ViLbase (Yu et al. (2020)) 72.62/72.85 – 77.0 80.3 62.1 74.02/80.33/64.74 – 74.44/92.72/95.94 –
ERNIE-ViLlarge 73.78/73.96 – 79.2 83.5 66.3 74.24/80.97/64.70 – 75.10/93.42/96.26 –
DeVLBERTV (Zhang et al. (2020)) – – – – – – – 59.3/85.4/91.8 32.8/63.0/74.1
DeVLBERTVL – – – – – – – 60.3/86.7/92.2 34.9/65.5/77.0
DeVLBERTVLC 71.1/71.5 – – – – – – 61.6/87.1/92.6 36.0/67.1/78.3
SemVLP(Li et al. (2021a)) 74.52/74.68 62.87/63.62 – – – – /–/– 79.55 74.10/92.43/96.12 –
CAPT(Luo et al. (2020a)) 72.78/73.03 60.48/60.93 – – – – 75.13 – –
LAMPcoco (Guo et al. (2020)) 70.85/71.0 – – – – – 74.34 – 42.5/70.9/80.8
LAMPcoco+vg 72.48/72.62 –/61.05 – – – – 75.43 – 51.8/77.4/85.3
(Kervadec et al. (2019)) – –/60.5 – – – – 75.5 – –
ImageBERT(Qi et al. (2020)) – – – – – – – 73.1/92.6/96.0 54.3/79.6/87.5
Human – 89.3 91.0 93.0 85.0 – 96.3 – –
Table 1: Comparison of performances of cross-modal models on various tasks. The subscript nopt refers to the model without pre-training, zs
refers to zero-shot. Other subscripts follow respective papers. Human performances are compiled from respective papers for the tasks.
Masked LM Img-Sentence Match Masked Visual Modeling Other
ViLBERT class prediction –
B2T2 7 –
VL-BERT 7 class prediction –
LXMERT class prediction+feature regression image QA
Unicoder-VL class prediction –
VisualBERT 7 task-specific masked LM
UNITER class prediction+feature regression word region alignment
MiniVLM 7 detection+captioning+tagging
PixelBERT 7 pixel random sampling
OSCAR 7 –
UnifiedVLP 7 class prediction+feature regression –
InterBERT (same word) (hard negative) class prediction –
ERNIE-ViL class prediction –
DeVLBERT class prediction –
SemVLP class prediction+feature regression image QA
CAPT class prediction contrastive
LAMP class prediction+feature regression –
(Kervadec et al. (2019)) class prediction VQA
ImageBERT class prediction+feature regression –
Table 2: Pre-training tasks performed by various cross-modal models.8 Andrew Shin et al.
Dataset Computation Optimizer Batch Size BERT L/H/A Cross-Modal Depth
ViLBERT CC 8 TitanX Adam 512 12/12/762 8
B2T2 CC – Adam – 24/16/1024 –
VL-BERT CC 16 V100 Adam 256 24/16/1024 –
LXMERT COCO/VG/VQA/GQA/VG-QA 4 Titan Xp Adam 256 12/12/768 9
Unicoder-VL CC/SBU 4 V100 Adam 192 12/12/768 –
VisualBERT COCO 4 V100 Adam – 12/12/768 –
UNITER COCO/VG/CC/SBU – – – 24/16/1024 –
MiniVLM COCO/CC/SBU/Flicker/VQA/GQA/VG-QA – SGD 512 12/–/386 –
PixelBERT COCO/VG 64 V100 SGD/AdamW 4096 – –
OSCAR COCO/CC/SBU/Flicker/GQA – AdamW 512 24/16/1024 –
UnifiedVLP CC 8 V100 AdamW 512 12/12/768 –
InterBERT CC/COCO/SBU – AdamW – – –
ERNIE-ViL CC/SBU 8 V100 Adam 512 24/16/1024 6
DeVLBERT CC 8 V100 – – – –
SemVLP COCO/VG/VQA/GQA/VG-QA/CC/SBU 4 V100 Adam 256 12/12768 6
CAPT – – Adam – 24/16/1024 –
LAMP COCO/VG 2 Titan RTXs – 256 12/12/768 –
Kervadec et al. (2019) COCO/VG 4 V100 Adam 512 12/12/768 5
ImageBERT LAIT 4 V100 Adam 48 12/12/768 –
Table 3: We report the setting for the largest model reported in respective papers. COCO refers to MS COCO (Lin et al. (2014)), CC to Conceptual
Captions (Sharma et al. (2018)), VG to Visual Genome (Krishna et al. (2016)), VG-QA to Q&A subset of Visual Genome, and SBU to SBU
Captions (Ordonez et al. (2011)). LAIT is collected by ImageBERT. BERT L/H/A refer to the number of layers, the number of attention heads, and
hidden size, respectively. Cross-modal depth refers to the number of inter-modality layers, after embedding each modality separately. We report
cross-modal depth only for two-stream models, since most single stream models follow the same network depth as their language embedding for
cross-modal embedding.
a region of interest (for example, a cat) is randomly masked learn similar representations for sequences that share the
out, and the model is trained to predict the category of the same semantics by matching the original sequence and the
masked out RoI by solely relying on linguistic clues, such corresponding corrupted sequence.
as “kitten drinking from bottle.” Here, the RoIs are obtained While most models so far have relied on Fast/Faster R-
via Fast R-CNN (Girshick (2015)). Such setting is derived CNN for region extraction, MiniVLM (Wang et al. (2020b))
from the concern that there may be cases where it is nearly employs a region extraction module inspired by EfficientDet
impossible to identify a region when the region is masked. (Tan et al. (2020)), and as such, they first attempt to enhance
While VL-BERT opts not to perform image-sentence match- their visual features by performing large-scale image classi-
ing task, this unique setup intends to make up for the learn- fication and object detection with Objects365 dataset (Shao
ing of cross-modal dependency. et al. (2019)). Cross-modal representation is subsequently
fine-tuned with captioning and tagging, where captions and
While the models above relied on the prediction of class
tags are obtained by existing models.
distribution, it has also been found beneficial to incorpo-
rate feature regression into masked visual modeling task.
4.1.1 Analysis of Performance
LXMERT (Tan and Bansal (2019)) is one such example.
On top of masked object classification, where the label for
Table 1 compares the performance of various models on
the masked RoI should be classified based on other visual
representative cross-modal tasks. Note that the models are
inputs and linguistic inputs, they also perform RoI-feature
trained with different size of datasets with varying size of
regression with L2 loss. UnifiedVLP also reports that com-
model sizes, so direct comparison of performance does not
bining class prediction and feature prediction improves per-
necessarily imply superiority of certain models over oth-
formance. UNITER (Chen et al. (2020c)) also performs both
ers. Table 2 compares pre-training tasks performed by each
class prediction and feature regression, but they propose to
model, with 4 rough categories for pre-training tasks. Ta-
add a third task for masked visual modeling, where they per-
ble 3 compares settings of the models, ranging from datasets
form class prediction with KL divergence.
used for pre-training to their implementation details. Fig-
Some models further propose novel pre-training tasks ure 2 visualizes representative models in terms of the dataset
that do not fall into any of the 3 categories above, which fre- size used for pre-training, their performance in VQA task,
quently depends on the target downstream task. For exam- the types of pre-training objectives performed, and the re-
ple, LXMERT, SemVLP (Li et al. (2021a)) and (Kervadec spective model size. While it remains arguable whether we
et al. (2019)) propose image question answering task for can attribute a certain aspect to the respective model’s per-
pre-training, whereas PixelBERT (Huang et al. (2020b)) em- formance, the models with higher performance have one or
ploys pixel random sampling. (Luo et al. (2020a)) proposes more of the following characteristics in common; pre-trained
contrastive pre-training, where they encourage the model to on a relatively large amount of data, larger model size, andPerspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision 9
more pre-training objectives. While the observations are quite performance on specific tasks, it appears beneficial to per-
generic, note that they are consistent with recent trend of form similar type of pre-training task for a certain target
pre-training a model with a very large number of parameters downstream task. LXMERT and SemVLP are again notable
with large-scale dataset, as affirmed by GPT-3. examples, as they propose unique pre-training objective of
Table 4 shows some of the frequently used datasets for image QA and indeed achieve better performances on VQA
both images and videos, along with the description of their task. MiniVLM also performs additional pre-training objec-
contents, annotation types, and sizes. Although it would be tive of image captioning task to demonstrate reliable per-
difficult to generalize from a small group of models described formance on image captioning task. Furthermore, video and
so far, as it is easy to be overfitting, further observations language models pre-trained with YouCook2 annotations can
can be made with respect to dataset and pre-training objec- be considered a similar case.
tives that may likely be of reference. It must first be noted
that all datasets with images are at the order of millions, 4.1.2 Video and Language
once again affirming the indispensable role played by pre-
training with large-scale dataset. In fact, even models of rel- Extending vision domain of cross-modal tasks from images
atively small sizes can attain fair performance when pre- to videos naturally brings new challenges. For example, a
trained with large-scale dataset, as is the case with mini- truly reliable supervision would require annotations at frame-
VLM. Pre-training with large-scale dataset also appears to level, which necessitates prohibitive amount of manual labour.
overcome the noisiness of labels obtained via weak, web In fact, existing large-scale video datasets, such as YouTube-
supervision. For example, ERNIE-ViL is pre-trained with 8M (Abu-El-Haija et al. (2016)) or Sports-1M (Karpathy
Conceptual Captions and SBU Captions, both of which are et al. (2014)), often rely on user-attached tags, resulting in
”webly” supervised, yet demonstrates fairly high performance noisy labels. As such, self-supervised learning has become
throughout the tasks. To be fair, however, under similar set- a frequently used approach for learning video representa-
tings, pre-training with manually annotated datasets appears tions (Vondrick et al. (2018); Agrawal et al. (2015); Wang
to provide an edge over pre-training with datasets with web and Gupta (2015)). Transformer-based cross-modal models
supervision, particularly in terms of the size of the dataset tackling video and language are relatively newly emerging
necessary to obtain the desirable level of performance, which research topic, and have displayed varying approaches with
makes sense considering the inevitable presence of noise in more task-oriented principles. While many models adopted
web supervision. Higher efficiency of human annotation in approaches employed in the models for images, for exam-
terms of the required dataset size is well-illustrated by Visu- ple the BERT-inspired pre-training objectives, there are also
alBERT and a variation of LAMP, both of which are trained models that opt to diverge, as we shall see below.
only with MS COCO, displaying more reliable performance When aligning video and language, where language su-
than ViLBERT trained with Conceptual Captions, although pervision is extracted from the corresponding audio of the
Conceptual Captions is more than 5 times larger than MS unannotated raw videos, a frequent problem is that the se-
COCO. As noted above, however, it should be highlighted mantic of the language and video may not align. For exam-
again that this is equivalent to saying, alternatively, that pre- ple, the speaker may be talking about cars, where the video
training with web supervision can demonstrate comparable shows the speaker himself. (Sun et al. (2019)) notes that
performance to human annotations when given a sufficient cooking videos have high probability of visual and linguistic
amount of data, as is the case with models like ERNIE-ViL. semantics temporally well-aligned, and exploit such proper-
As we shall see in Sec. 4.1.2, a similar tendency can also ties to examine video caption generation and next frame pre-
be observed with video and language models. For example, diction with their VideoBERT. In order to extend BERT’s
VideoBERT (Sun et al. (2019)), which is pre-trained with pre-training objectives to video domain, they obtain visual
large-scale YouTube videos with annotations obtained by tokens using hierarchical vector quantization to video fea-
YouTube video annotation system and uses human-annotated tures. On top of the masked language modeling and masked
YouCook2 (Zhou et al. (2017)) for evaluation only, falls be- visual token modeling, next-sentence classification is ex-
low the models directly pre-trained with YouCook2, such as tended as alignment classification for visual and linguistic
UniVL (Luo et al. (2020b)). sentences. Even with cooking videos, however, the align-
It may also be inferred that pre-training with dataset de- ment may still be noisy, and they deal with this problem
signed for the same or similar task as the target task helps by concatenating neighboring sentences into a long single
boost performance in that target task. LXMERT, OSCAR, sentence, and varying the subsampling rate of video tokens,
and SemVLP, which are trained with at least one dataset making the model robust to variations in video speed.
designed for image QA task, all demonstrate higher per- Similarly to VideoBERT, CBT (Sun et al. (2020)) em-
formance on VQA task, as shown in Fiugre 2. Similarly, ploys sliding window approach to extract visual tokens us-
in terms of correlation between pre-training objectives and ing S3D network (Xie et al. (2018)). Visual and linguistic to-10 Andrew Shin et al.
Dataset Contents Annotation Size
Conceptual Captions (Sharma et al. (2018)) image + scene-level description web supervision 3.3M
MS COCO (Lin et al. (2014)) image + scene-level description crowd-sourced 0.6M
Visual Genome (Krishna et al. (2016)) image + region descriptions crowd-sourced 5.4M
Visual Genome - Q&A (VG-QA) image + question and answer crowd-sourced 1.7M
SBU (Ordonez et al. (2011)) image + scene-level description web supervision 1M
Flickr 30k (Young et al. (2014)) image + scene-level description crowd-sourced 0.2M
VQA (Antol et al. (2015)) image + question and answer crowd-sourced 0.6M
GQA (Hudson and Manning (2019)) image + question and answer generated 22M
YouCook2 (Zhou et al. (2017)) video + temporal annotations manual annotation 15k
HowTo100M (Miech et al. (2019)) videos + descriptions audio transcription 136M
ActivityNet Captions (Heilbron et al. (2015)) videos + temporal annotations crowd-sourced 72k
MSR-VTT (Xu et al. (2016)) videos + descriptions crowd-sourced 200k
CrossTask (Zhukov et al. (2019)) videos + task descriptins manual annotation 4.7k
CMU-MOSI (Zadeh et al. (2016)) videos + sentence-level sentiment annotations crowd-surce 2k
Table 4: Comparison of frequently used datasets for pre-training visuolinguistic models. Web supervision refers to captions obtained by crawling
the tags or descriptions for corresponding images uploaded on the web pages. Generated refers to synthetic sentences generated in a rule-based
manner. Crowd-sourced and manual annotation both refer to human annotation, but differ in that the former refers specifically to external workforce.
Size refers to the number of descriptions or questions available.
YouCook2 ActivityNet
Method BLEU-4 METEOR ROUGE-L CIDEr BLEU-4 METEOR ROUGE-L CIDEr
Masked Transformer (Zhou et al. (2018)) 1.42 11.20 – – 2.23 9.56 – –
VideoBERT (Sun et al. (2019)) 4.33 11.94 28.80 0.55 – – – –
CBT (Sun et al. (2020)) 5.12 12.97 30.44 0.64 – – – –
COOT (Ging et al. (2020)) 11.30 19.85 37.94 0.57 10.85 15.99 31.45 0.28
UniVL (Luo et al. (2020b)) 17.35 22.35 46.52 1.81 – – – –
ActBERT (Zhu and Yang (2020)) 5.41 13.30 30.56 0.65 – – – –
E2vid (Huang et al. (2020a)) 12.04 18.32 39.03 1.23 – – – –
Table 5: Performances of transformer-based cross-modal models on video captioning for YouCook2 (Zhou et al. (2017) and ActivityNet (Heilbron
et al. (2015)). Metrics used include BLEU (Papineni et al. (2002)), METEOR (Banerjee and Lavie (2005)), ROUGE (Lin (2004)), and CIDER
(Vedantam et al. (2015)).
kens are concatenated and passed to a shallow 1-layer cross- incorporate generative modeling approach, by proposing to
modal transformer, where the mutual information between regard each modality as a translation of each other.
the two is computed. For pre-training objectives, masked
language modeling and masked visual token modeling are Models that do not explicitly employ BERT-inspired ap-
employed, where HowTo100M dataset (Miech et al. (2019)) proaches have also appeared. (Gabeur et al. (2020)) pro-
is used, rather than crawled videos from YouTube as is the poses multi-modal transformer calibrated for video retrieval
case with VideoBERT. Also, unlike VideoBERT where the task. Rather than directly extending pre-training objectives
features are clustered with vector quantization and the task of BERT, they rely on bidirectional max-margin ranking,
is to estimate to which cluster the masked feature belongs enforcing high similarity between video and captions. No-
to, CBT attempts to directly regress the masked features. tably, they extract video features by the combination of pre-
While the models above rely on densely sampled visual to- trained models from 7 different domains, which differen-
kens, ClipBERT (Lei et al. (2021)) notably demonstrates tiates them from other models that generally employ one
that sparse visual tokens can be sufficient for video repre- pre-trained model for each modality. Similarly, Cooperative
sentation. hierarchical transformer (COOT) (Ging et al. (2020)) pro-
poses cross-modal cycle-consistency loss to enforce seman-
Novel pre-training objectives that are specific to video tic alignment, on top of alignment losses from (Zhang et al.
and language domain have also appeared. For example, Act- (2018a)), rather than simply extending pre-training objec-
BERT (Zhu and Yang (2020)) proposes masked action clas- tives of BERT. (Zhou et al. (2018)) also proposes to use
sification, where the objective is to predict the action label masked transformer dense video captioning task, but simply
given the linguistic and object features, whereas HERO (Li uses it as a captioning decoder based on inputs from visual
et al. (2020b)) proposes frame order modeling. VideoAsMT encoder and proposal decoder, without explicit pre-training
(Korbar et al. (2020)) and UniVL (Luo et al. (2020b)) also objective designed for cross-modal learning.Perspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision 11
As we have seen, while there are only a limited num- (2020a)), UNITER (Chen et al. (2020c)), and VisualBERT
ber of transformer-based models dealing with video and lan- (Li et al. (2019)) are some of the notable examples of single-
guage, they tend to be specific to task and domain, taking stream cross-modal models.
varying approaches. Many models have employed approaches Notably, nearly all models perform early fusion of lan-
from cross-modal models for image and language, but it may guage and vision embeddings, in which they are concate-
be still early to capture a definite common ground for these nated prior to being fed to cross-modal transformer blocks.
models, since much more remains to be explored yet. Ta- In fact, B2T2 (Alberti et al. (2019)), designed specifically
ble 5 summarizes the models’ performances on video cap- for VQA and VCR tasks, modifies dual encoder (Wu et al.
tioning task, one of the frequently visited tasks in video and (2017); Gillick et al. (2018)) and compares performing early
language cross-modal domain. fusion with text and bounding boxes to late fusion with the
feature from the entire image, and reports that early fusion
outperforms the late fusion.
4.2 Network Architecture
MiniVLM (Wang et al. (2020b)) aims at building a light-
Network architecture for cross-modal embedding using trans- weight cross-modal model, and unlike the models that em-
former can be roughly divided into two categories; single- ployed Fast R-CNN or Faster R-CNN to extract visual fea-
stream models, where the transformer block is modality- tures, they propose two-stage efficient feature extractor (TEE),
specific, and two-stream models, where the inputs to each consisting of EfficientNet (Tan and Le (2019)) and compact
transformer block are inter-modal. (Figure 3) BERT fusion model. In particular, the visual feature extrac-
ViLBERT (Lu et al. (2019)) is a representative two-stream tion consists of EfficientNet with bidirectional feature pyra-
model, in which they proposed co-attention transformer mech- mid network as in EfficinetDet (Tan et al. (2020)), followed
anism, with input keys and values of one modality being by non-maximum suppression. MiniVLM is also unique in
passed as inputs to the transformer block of another modal- that they propose a triplet input to cross-modal learning block,
ity. In other words, keys and values for the language are in- consisting of visual features, tokenized sentences, and tok-
put to transformer block for the vision part, and vice versa. enized object names. The motivation is that inputting object
Since the queries for each modality still go into the corre- labels explicitly may help further enforce the learning of de-
sponding modalities, the transformer block ends up learning pendency between objects and corresponding text. Similar
to embed features for each modality conditioned on the other approach is also employed by OSCAR (Li et al. (2020c)),
modality. In order to tokenize the vision, they extract image which inputs object tags along with word tokens and region
regions using Faster R-CNN with ResNet (He et al. (2016)) features.
backbone, while also employing 5-dimensional spatial loca- Apart from the cross-modal learning mechanism and in-
tion vector. LXMERT (Tan and Bansal (2019)) takes a simi- put format, positional embedding is another source of vari-
lar approach, where, after embedding each modality and en- ation among the models. Unicoder-VL (Li et al. (2020a))
coding them with transformer separately, cross-modality en- extracts image regions with Faster R-CNN along with 5-d
k
coder is applied, for which query vector hi from one modal- vector, but they notably use the same position embedding
k
ity and context vector vj from another modality are the in- for all image regions, rather than random permutations. In
puts, with k being the number of respective single-modality VisualBERT (Li et al. (2019)) position embedding for each
encoders. DeVLBERT (Zhang et al. (2020)) and (Kervadec visual token is matched to the corresponding input token,
et al. (2019)) also follow ViLBERT by exchanging queries, whenever the alignments between image regions and the in-
or equivalently keys and values, for each modality. SemVLP put tokens are available.
(Li et al. (2021a)) notably performs two-stream cross-modal VL-BERT (Su et al. (2020)) proposes a format where
learning only at the upper parts of the blocks, in order to each input element consists of 4 different types of embed-
learn high-level semantic alignment. ERNIE-ViL (Yu et al. dings, namely token embedding, visual feature embedding,
(2020)), while mostly following ViLBERT, incorporates scene segment embedding, and sequence position embedding. Most
graph approach, where the input text is parsed into the nodes notable is visual feature embedding, which is a combination
of objects, relations, and attributes that the text mentions. of visual appearance feature, corresponding to the output of
Scene graph representation is shown to improve the seman- fully-concatenated features from Fast R-CNN for the image
tic alignment between vision and language, and as the au- region, and visual geometry embedding, a 4-d vector for co-
thors note, hints at the possibility of extending cross-modal ordinates of each corner of the region. Note that, for linguis-
tasks to graph neural networks. tic tokens, the entire image is used for visual feature embed-
Single-stream cross-modal learning is fairly intuitive and ding. Sequence position embedding for image tokens can be
simple, as the conventional transformer blocks can be ex- randomized.
tended in a straightforward manner, without architectural Both single-stream and two-stream have appeared in video
modifications, for concatenated inputs. Unicoder-VL (Li et al. and language domain as well. For example, ActBERT pro-12 Andrew Shin et al.
(a) Single-stream (b) Two-stream
(i) (i)
Fig. 3: Comparison of single-stream and two-stream cross-modal transformer blocks. Hv and Hw refer to embedding of
visual and word tokens respectively, output by i-th layer.
poses tangled transformer, where each of query, key, and representations has for the most part relied on pre-trained
value come from different modalities, while UniVL employs convolutional neural networks. For example, ViLBERT (Lu
cross encoder, where language and video encodings are com- et al. (2019)) relies on Faster R-CNN to extract image re-
bined along the dimension of sequence. On the other hand, gions as tokens. However, some of the recent researches
E2vid (Huang et al. (2020a)) relies on separate-modality ar- have suggested that even convolution may be safely replaced
chitecture, and only partially employs cross-modal co-attention by transformer architecture, which may arguably imply that
transformer. more fundamentally different changes may be possible with
In summary, we can make a few observations that are obtaining visual representations. While these works do not
common in most models. While some models explicitly come explicitly deal with cross-modal tasks, they suggest critical
up with two-stream cross-attention scheme by exchanging implications as to the prospects of cross-modal tasks, as will
inputs to attention heads, many models do not explicitly de- be discussed in Sec 6. We thus briefly introduce recent im-
sign cross-attention scheme and simply rely on pre-training portant works on vision representation with transformers in
objectives for learning cross-modal dependency. Whether this section.
single-stream or two-stream, images are tokenized as re- (Dosovitskiy et al. (2020)) proposes Vision Transformer
gions without exception, although the entire image may re- (ViT) and suggests that pure transformers can achieve com-
place regions in some models for position embedding. Also, parable performance on image classification tasks. While
regions are mostly accompanied by low-dimensional spatial closely following the original transformer architecture, they
vectors containing their coordinate information. Features are split images into patches, feed the sequence of linear em-
extracted with pre-trained object detection models rather than beddings of these patches as input to transformer, so that 2D
classification models, except models like MiniVLM, which images are represented as a sequence of flattened patches.
employs EfficientNet backbone and further trains the detec- In a similar spirit as masked language modeling in BERT,
tion model. Attaching position embedding to image regions they perform masked patch prediction, in which the model
is one source of variations among the models. Many mod- is trained to predict the mean 3bit color for each patch. In
els employ coordinate-based ordering, while some models particular, their ablation study with variations in dataset size
simply use random permutation, or the same position em- shows that pre-training with the largest dataset, JFT-300M
bedding for all visual tokens. (Sun et al. (2017)), resulted in better performance, implicat-
ing that, as in language domain, training a transformer-based
model with a massively large amount of image data can
5 Visual Representation with Transformer lead to models with outstanding performances. Pyramid vi-
sion transformer (Wang et al. (2021b)) expands upon vision
So far, most works tackling cross-modal tasks with trans- transformer and demonstrates that convolution-free models
former architecture have primarily applied it to linguistic can be extended to a wider range of computer vision tasks,
representation, with certain schemes to embed it together including object detection, semantic segmentation, and in-
with visual representation, mostly by tokenizing the visual stance segmentation. VidTr (Li et al. (2021b)) further shows
representation in some ways. Such tokenization of visual that videos can also be handled without using convolutions.You can also read

















































