Experimentally realized in situ backpropagation for deep learning in nanophotonic neural networks
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Experimentally realized in situ backpropagation for deep learning in nanophotonic
neural networks
Sunil Pai,1, ∗ Zhanghao Sun,1 Tyler W. Hughes,1, 2 Taewon Park,1 Ben Bartlett,3 Ian A.
D. Williamson,1, 4 Momchil Minkov,1, 2 Maziyar Milanizadeh,5 Nathnael Abebe,1 Francesco
Morichetti,5 Andrea Melloni,5 Shanhui Fan,1 Olav Solgaard,1 and David A.B. Miller1
1
Department of Electrical Engineering, Stanford University, Stanford, CA 94305, USA
2
now at Flexcompute Inc., Belmont, MA, USA
3
Department of Applied Physics, Stanford University, Stanford, CA 94305, USA
4
now at X Development LLC, Mountain View, CA USA.
5
Politecnico di Milano, Milan, Italy
Neural networks are widely deployed models across many scientific disciplines and commercial
endeavors ranging from edge computing and sensing to large-scale signal processing in data cen-
arXiv:2205.08501v1 [cs.ET] 17 May 2022
ters. The most efficient and well-entrenched method to train such networks is backpropagation, or
reverse-mode automatic differentiation. To counter an exponentially increasing energy budget in the
artificial intelligence computing sector, there has been recent interest in analog implementations of
neural networks, specifically nanophotonic optical neural networks for which no analog backpropa-
gation demonstration exists. We design mass-manufacturable silicon photonic neural networks that
alternately cascade our custom designed “photonic mesh” accelerator with digital nonlinearities to
output the result of arbitrary matrix multiplication of the input signal. These photonic meshes
are parametrized by reconfigurable physical voltages that tune the interference of optically encoded
input data propagating through integrated Mach-Zehnder interferometer networks. Here, using our
packaged photonic chip, we demonstrate in situ backpropagation for the first time to solve classi-
fication tasks and evaluate a new protocol to keep the entire gradient measurement and update of
physical device voltages in the analog domain, improving on past theoretical proposals. This in situ
method is made possible by introducing three changes to typical photonic meshes: (1) measurements
at optical “grating tap” monitors, (2) bidirectional optical signal propagation automated by fiber
switch, and (3) universal generation and readout of optical amplitude and phase. After training,
our classification achieves accuracies similar to digital equivalents even in the presence of systematic
error. Our findings suggest a new training paradigm for photonics-accelerated artificial intelligence
based entirely on a physical analog of the popular backpropagation technique.
Neural networks (NNs) are intelligent computational updating gradients on each element in the graph. Im-
graph-based models that are ubiquitous in scientific data portantly, this can be physically implemented in linear
analysis and commercial artificial intelligence (AI) appli- optical devices by simply sending light-encoded errors
cations such as self-driving cars and speech recognition backwards through photonic devices and performing op-
software. Through deep learning, NN models are dynam- tical measurements [5], which is a faster and more ef-
ically “trained” on input image, audio or language data ficient calculation than a digital implementation. Our
to automatically make decisions (“inference”) for com- demonstration of this new physics-based backpropaga-
plex signal processing powering much of today’s mod- tion algorithm, and analysis of systematic error in gra-
ern technology. Due to increasing demand, these models dient calculations used in backpropagation, could help
require an ever-increasing computational energy budget, ultimately offer new, possibly energy-efficient strategies
which has recently been estimated to double every 3 to 4 to teach modern AI to make intelligent decisions on mass
months, according to OpenAI [1]. An increasingly large manufacturable silicon photonics hardware using efficient
reservoir of available data and adoption of AI in mod- model-free training [5, 6].
ern technology necessitates an energy-efficient solution
for training of NNs. As a physical platform for our backpropagation demon-
In this paper, we experimentally demonstrate the first stration, we explore programmable nanophotonic devices
(to our knowledge) optical implementation of backprop- called “photonic meshes” for accelerating matrix multi-
agation, the most widely used and accepted method of plication [7, 8]. Photonic meshes shown in Fig. 1 are
training NNs [2, 3], on a scalable foundry-manufactured silicon-based low-cost, commercially scalable N × N port
device. (A minimal bulk optical demonstration has been photonic integrated circuits (PICs) consisting of Mach-
previously explored [4].) Specifically, backpropagation Zehnder interferometers (MZIs) and programmable opti-
consists of backward propagating model errors computed cal phase shifts. These PICs are capable of representing
for training data through the NN graph to determine matrix-vector multiplication (MVM) through only the
propagation of guided monochromatic light (1560 nm in
our demonstration) through N silicon waveguide “wires”
clad by silicon oxide [7–9]. Each waveguide can support
∗ sunilpai@stanford.edu a single optical mode which has two degrees of freedom:
2
amplitude and phase, yielding a complex N -dimensional adding new capabilities beyond existing inference or in
vector x at the input of the system. Programmable phase silico learning demonstrations [7, 17, 18]. Our findings
shift settings physically modulate the propagation speed ultimately pave the way for a new class of approaches for
(and relative phases) of the wave over segments of silicon energy-efficient analog training of neural networks and
wire to affect how the N propagating modes construc- optical devices more broadly.
tively or destructively interfere in each interferometer.
The energy efficiency of these devices has been estimated
to be up to two orders of magnitude higher than current
state-of-the-art electronic application-specific integrated PHOTONIC NEURAL NETWORKS
circuits (ASICs) in AI [10].
Assuming no light is lost in the ideal photonic circuit,
the mesh can be programmed to transform optical inputs At a high level, a neural network is able to transform
using an arbitrary programmable unitary MVM y = U x data into useful decisions or interpretations, an example
[8, 11, 12]. The matrix U is parametrized by the pro- of which is shown in Fig. 1(a) and (d) where we label
grammable phase shifters on the device and transforms points in 2D based on their location within or outside
inputs x propagating through the device to output modes of a ring. This problem (and in principle many more
y. The programmed phase shifts on the device define the complex problems like audio signal processing [7]) can
matrix U , and the N output mode amplitude and phase be solved in the optical domain using photonic neural
measurements y represent the solution to this optical networks (PNNs) as shown in Fig 1(a)-(d). To solve the
computation. This fundamental mathematical operation problem, we design and evaluate a hybrid digital-optical
enables meshes to be widely employed in various analog deep PNN architecture parameterized by trainable pro-
signal processing applications 13 such as telecommunica- grammable phase shifts η ∈ [0, 2π)D , where D represents
tions [9], quantum computing [14], sensing, and machine the total number of phase shifting elements across all lay-
learning [7], the last of which we explore experimentally ers in the overall PNN.
in this work via our backpropagation demonstration. Using a combination of photonic hardware and soft-
To form what we call a “hybrid” digital-photonic NN ware implementations, our hybrid PNN can solve non-
(PNN), we alternately cascade photonic meshes and digi- trivial tasks using alternating sequences of analog linear
tal nonlinear functions [13, 15], which ultimately forms a optical MVM operations U (`) (η (`) ) and digital nonlinear
composite function and model capable of complex de- transformations f (`) where ` denotes the neural network
cision making. While performing inference or back- layer and we assume a total of L layers. For example, af-
propagation, the hybrid PNN performs time-and energy- ter L = 3 neural network layers for N = 4, our photonic
efficient MVM, converts photonic mesh output signals to neural network is capable of transforming the boundary
the digital domain, applies nonlinearities, and then con- function used to separate the labelled points in Fig. 1(d).
verts the data back to optical domain for MVM in the To realize this implementation in a mathematical model,
next layer. Hybrid PNNs offer more versatility over fully the following sequence of functions transforms the data,
analog PNNs in the near term due to flexible manipu- proceeding in a “feedforward” manner through the layers
lation of signals in the digital domain easing implemen- of the network:
tations for recurrent and convolutional neural networks.
As a result, hybrid PNNs have been demonstrated to y (`) = U (`) x(`)
provide a reliable low-latency and energy-efficient analog (1)
x(`+1) = f (`) (y (`) ).
optical solution for inference, recently in circuit sizes of
up to 64 × 64 in commercial settings [16]. Despite this
success in PNN-based inference, on-device backpropaga- The inputs x = x(1) to the overall system are forward-
tion training of PNNs has not been demonstrated, due propagated to the final layer (layer L), outputting zb :=
to significantly higher experimental complexity compared x(L+1) . This forward propagation and resulting out-
to the inference procedure. put measurement of data sent through this network is
In this paper, we address this gap by experimentally called “inference” and is depicted in Fig. 1(a, b, d). The
demonstrating in situ backpropagation in a hybrid PNN model cost or error function is represented by L(x, z) =
architecture. First, we propose a novel and energy ef- c(b
z (x), z) for a given set of ground truth labels z, where
ficient implementation of the technique for measuring c is any cost function representing the error between zb
phase shifter updates entirely in the optoelectronic (ana- and z. We refer to the input, label pair of training data
log) domain. Second, we experimentally validate training (x, z) as a “training example.” Backpropagation and
a backpropagation-enabled, foundry-manufactured pho- other gradient-based training approaches seek to update
tonic circuit using a custom optical rig setup on a mul- parameters η based on the vector gradient ∂L D
∂η ∈ R eval-
tilayer neural network. Our demonstration solves ma- uated for a given training example (or averaged over a
chine learning tasks on this photonic hardware using this batch of training examples). We now explain how we im-
optically-accelerated backpropagation with similar accu- plement both the inference and backpropagation training
racy compared to a conventional digital implementation, calculations directly on our core photonic neural network.
3
(a) Unlabelled inputs (b) In situ backpropagation training (d) Labelled outputs
...
Example Label (post-training)
2 (1) (1) Cost 1.0
U f ... U
(L)
f
(L)
L 2
1 0.8
... 1
(1) (1) (2) (L) (L)
0 x y x x y 0 0.6
∂L ∂L
−1
(c) ∂η ∂η −1
(1) ( ) (2) (L) (L)
xaj yaj1 xaj xaj yaj 0.4
−2 ... −2
−2 −1 0 1 2 −2 −1 0 1 2
(1) (1) (L) (L)
U faj ... U faj
... Tapped MZI
ϕ θ
(e) In situ backpropagation optical measurement protocol pϕ pθ
U xaj U yaj x − i(xaj )∗ U
x y
1 2 3
pη Send input signal forward pη,aj Send error signal back pη,sum Send sum signal forward
Measure output signal Measure adjoint signal Measure gradient
Monitor powers Monitor powers via digital subtraction
input reference output sum
adjoint reference error
IR Camera IR Camera IR Camera
Input laser pθ IR Camera pθ,aj Input laser
pθ,sum
Generator Analyzer Analyzer Generator Generator Analyzer
FIG. 1. (a) Example machine learning problem: an unlabelled 2D set of inputs that are formatted to be input into a photonic
neural network. (b, c) In situ backpropagation training of an L photonic neural network for (b) the forward direction and (c) the
backward direction showing the procedure for calculating gradient updates for phase shifts. (d) An inference task implemented
on the actual chip results in good agreement between the chip-labelled points and the ideal implemented ring classification
boundary (resulting from the ideal model) and a 90% classification accuracy. (e) We depict our proposed architecture and
the three steps of in situ (analog) backpropagation, consisting of a 6 × 6 mesh implementing coherent 4 × 4 forward and
inverse unitary matrix-vector products using a reference arm. We depict the (1) forward (2) backward (3) sum steps of in
situ photonic backpropagation. Arbitrary input setting and complete amplitude and phase output measurement are enabled in
both directions using the reciprocity and symmetries of our architecture. All powers throughout the mesh are monitored using
the tapped MZI shown in the inset for each step, allowing for digital subtraction to compute the gradient [5]. These power
measurements performed at phase shifts are indicated by green horizontal bars.
BACKPROPAGATION DEMONSTRATION (shown in green) capable of sending any input vector x
and measuring any output vector y from Eq. 1. These
calibrated optical I/O circuits are referred to as “Gener-
For practical demonstration purposes, our multilayer ator” and “Analyzer” circuits are shown in red and blue
PNN is completely controlled by a single a photonic mesh respectively in Figs. 1(e) and 2(b). A more complete
(Note that in practice, energy-efficient photonic NNs are discussion of how an MVM operation is achieved using
controlled by separate photonic meshes of MZIs for each our architecture is provided in the Methods, and similar
linear layer). Each MZI unit is controlled by an elec- approaches have been attempted for complex-valued pho-
tronic control unit that applies voltages to set various tonic neural network architectures [19]. Note that for the
phase shifts on the device packaged on a thermally con- input generation and output measurements, we need to
trolled assembly as shown in Fig. 2(a, b). These phase calibrate the voltage mappings θ(vθ ), φ(vφ ) (equivalently
shifts are placed at the input external arm of the MZI for the output measurement, vθ (θ), vφ (φ)), which is dis-
(φ, controlled by voltage vφ ) and in the internal arm cussed in detail in Ref. 20. This is a standard calibration
of the MZI (θ controlled by voltage vθ ); this ultimately protocol [7, 21, 22] discussed at length in the Appendix
controls the propagation pattern of the light through the and required for accurate operation of the chip.
chip, enabling arbitrary unitary matrix multiplication.
In our chip specifically, we embed an arbitrary 4 × 4 uni- Our core contribution in this paper, shown in Fig. 1(e),
tary matrix multiply in a 6 × 6 triangular network of is to devise and test a photonic mesh matrix accelerator
MZIs. This configuration incorporates two 1 × 5 pho- architecture that experimentally implements backprop-
tonic meshes on either end of the 4 × 4 “Matrix unit” agation as proposed in Ref. 5 within a hybrid digital-
4
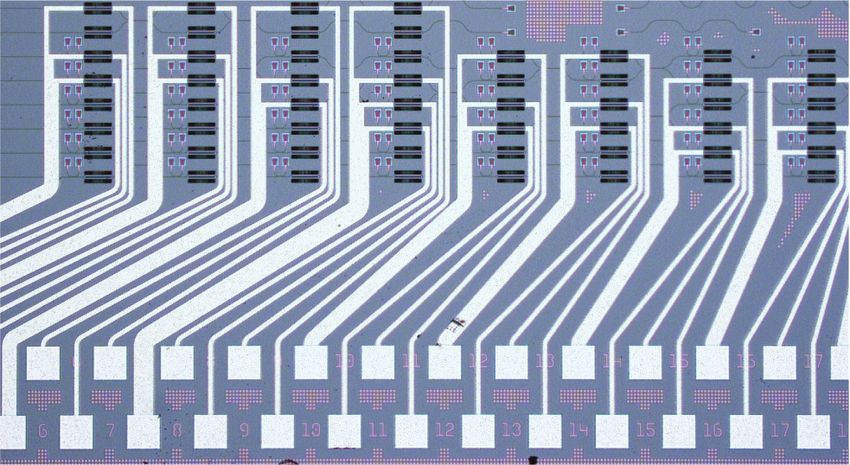
(a) Experimental chip close-up (b) Control and measurement protocol
5 mW Generator Matrix unit Analyzer Camera
Laser Fiber
Program U
Set input feature Measure output
Electronic control / calibration parameters DAC, PCB
(c) Thermal TiN
Analog gradient detection phase shifter
Spot
images
Grating tap monitor
U (d) Gradient measurement: σθ,φ = 1 (e) Gradient histogram: σθ,φ = 1 (f) Gradient error near convergence
100
1.0
Gradient error (1 − g · g )
Analog
dθ (η) update
∂L 0.4
Gradient ∂L/∂ η
AC Power (dη )
x 0.5 ∂η Digital
subtraction
0.2 10−1
0.0
ζ 0.0
−0.5
−0.2 10−2
−(xaj )∗
−1.0
0 π 2π Measured 10−1 100
Phase sweep † U )|2 )
Adjoint phase (ζ) Predicted Convergence distance (1 − |tr(U
FIG. 2. (a) Image of the packaged photonic chip wirebonded to a custom PCB with fiber array for laser input and a camera
overhead for imaging the chip. Zooming in reveals the core control-and-measurement unit of the chip, enabling power mea-
surement using 3% grating tap monitors and a thermal phase shifter nearby. (b) The DAC control is used to set up inputs
and perform coherent detection of the outputs, and the IR camera over the chip can be used to image all waveguide segments
throughout the chip via grating tap monitors, which we use for backpropagation. (c) Analog gradient detection could be used
to measure the gradient by introducing a summing interference circuit (not implemented on the chip in (b)) between the input
and adjoint fields. (d) The adjoint phase ζ can be swept from 0 to 2π to perform an all-analog gradient measurement, and,
ultimately in principle, update phase shifters with an optoelectronic scheme. (e) Gradients measured using our analog scheme
yield approximately correct gradients when the implemented mesh is perturbed from the optimal (target) unitary U = DFT(4)
with phase error σθ,φ = 1. (f) The average normalized gradient error (averaged over 20 instances of random implemented U b)
decreases with distance of the device implementation Û (η) from the optimal U = DFT(4). This “distance” is represented in
b † U )|2 .
terms of the fidelity error 1 − |tr(U
analog model implementing the most expensive opera- 3. We implement both amplitude and phase detec-
tions using universal linear optics. Our backpropagation- tion (improving on past approaches [19]) using a
enabled architecture differs from previously-proposed self-configuring programmable Matrix unit layer
photonic mesh architectures in three ways: [20, 23] on both the red and blue Generator and
Analyzer subcircuits of Fig. 1(e) and Fig. 2(b),
1. We enable “bidirectional light propagation,” the which by symmetry works for sending and mea-
ability to send and measure light propagating left- suring light that propagates forward or backward
to-right or right-to-left through the circuit (as de- through the mesh.
picted in Fig. 1(e)).
These improvements on an already versatile photonic
2. We implement “global monitoring,” the ability to hardware architecture enable backpropagation-based ma-
measure optical power at any waveguide segment chine learning implemented entirely using optical mea-
in the circuit using 3% grating taps (shown in the surement to optimize programmable phase shifters in
inset of Fig. 1(e) and Fig. 2(a, b)). In our proof- PNNs. As shown in Fig. 1(e), all three steps of back-
of-concept setup, we use an IR camera mounted on propagation 5 require monitoring of optical powers at
an automated stage to image these taps throughout each phase shifter and measurement of complex field out-
the chip. puts at the left and right sides of the mesh. Furthermore,5
the bidirectionality of the monitoring and optical I/O is where the last equation indicates the equivalence of “dig-
required to switch between forward and backward propa- ital subtraction,” shown in Fig. 1 and our proposed “ana-
gation of signals required for in situ backpropagation to log update” scheme dη (0)/2 in Fig. 2(c, d) (Appendix).
be experimentally realized. Equipped with these addi- Pseudocode and the complete enumerated backpropaga-
tional elements, our protocol can be implemented on any tion protocol are discussed in the Appendix. Note that
feedforward photonic circuit [6] with the requisite Ana- the digital and analog gradient updates can both be im-
lyzer and Generator circuitry, though we use a triangular plemented in parallel across all photonic layers of the
mesh in this work to enable the chip to be used in other network.
applications [24]. Now that we have defined the analog in situ backprop-
Here we give a quick summary of the procedure (fully agation update, we experimentally evaluate the accuracy
described in the Appendix). For each layer ` and train- of the analog gradient measurement for a matrix opti-
ing example pair, a “forward inference” signal x(`) is sent mization problem in Fig. 2(b, d). Since our circuit does
forward and a corresponding “backward adjoint” signal not have an explicit backprop unit architecture, we ex-
(`)
xaj is sent backward through a mesh implementing U (`) . perimentally simulate the “backprop unit” of Fig. 2(c)
The backward pass is in a sense a mirror image of the for- by programming a sequence of summing vectors in the
ward pass (error signal is sent from final layer to input Generator unit of our chip and recording dη (ζ) to com-
layer) which algorithmically computes an efficient “re- pute the gradient with respect to η. We implement back-
verse mode” chain rule calculation. The final step sends propagation in a single photonic mesh layer optimizing
(`)
what we call a “sum” vector x(`) − i(xaj )∗ . Previously a linear cost function Lm = 1 − |b uTm u∗m |2 , where um is
[5], it was shown that global monitoring in all three steps row m of U , a target matrix that we choose to be the
enables us to calculate the gradient by subtracting the four-point discrete Fourier transform (DFT), and u b m is
b
row m of U , the implemented matrix on the device. Each
backward and forward measurements from sum measure-
ments in the digital domain, in what we call an “optical phase shifter in the photonic network implements a phase
vector-Jacobian product (VJP)” (Appendix). shift θ + δθ, where θ is the optimal phase shift for U
and δθ is some random phase error with standard de-
viation σθ,φ , which can serve as a measure of “distance
ANALOG UPDATE to convergence” during training of the device. For our
gradient measurement step, we send in the derivative
Going beyond an experimental implementation of the yaj = ∂L∂y = −2(b
m
uTm u∗m )∗ em to achieve an adjoint field
theoretical proposal of Ref. 5, we additionally explore a xaj , where em is the mth standard basis vector (1 at po-
more energy-efficient fully analog gradient measurement sition m, 0 everywhere else). We find in Fig. 2(f) that
update for the final step that avoids the digital subtrac- analog gradient measurement is increasingly less accu-
tion update. The key difference is in the final “sum” rate when calculated near convergence, likely due to un-
step where we instead sweep the adjoint phase ζ (giving corrected photonic circuit error (e.g. due to loss and/or
(`)
x(`) − i(xaj )∗ eiζ ) from 0 to 2π repeatedly (e.g., using a thermal crosstalk) resulting in large gradient measure-
ment errors.
sawtooth signal). During the sweep, we record dη (ζ), the
AC component of the measured power monitored through
phase shifter θ, pη,sum (ζ). It is straightforward to show
PHOTONIC NEURAL NET TRAINING
that gradient is dη (0), the AC component evaluated when
no adjoint phase is applied (Appendix). To achieve the ζ
sweep physically, we can employ the summing architec- To test overall training within our photonic mesh chip,
(`) we assess the accuracy of in situ backpropagation in Fig.
ture in Fig. 2(c) which sums x(`) , i(xaj )∗ interferometri-
√ 3 to train L-layer photonic neural networks to solve mul-
cally with a constant loss factor of 1/2 in power (1/ 2 in tiple 2D classification tasks using the digital subtraction
amplitude). Then, using a boxcar gated integrator and protocol in Ref. 5. The classification problem assigns
high pass filter, we can physically compute dη (ζ) and up- points in 2D space to a 0 or 1 label (red or blue coloring)
date the phase shift voltage entirely in the analog domain based on whether the point is in a region of space, and the
(Appendix). Ultimately, this approach potentially avoids neural network implements the nonlinear boundary (for
a costly analog-digital conversion and additional memory instance circle-, moon- or ring-shaped) separating points
complexity required to program N 2 elements. Since the of different labels standardized using the Python package
PNN has L layers, the gradient calculation step requires Sklearn and specified in our code [26]. The points are ran-
local feedback circuits at each phase shifter η that update domly synthetically generated and are “noisy,” meaning
the parameters using the measured gradient: some training example points have a small probability of
∂L being assigned a label despite being on the wrong side of
= −I(xη xη,aj ) the ideal boundary.
∂η
(2) To solve this task, we use a three layer PNN where
= (|xη − ix∗η,aj |2 − |xη |2 − |xη,aj |2 )/2 each linear layer uses 4 optical ports (4 × 4 MVM), i.e.
= (pη,sum − pη − pη,aj )/2 = dη (0)/2, L = 3 with N = 4 inputs and outputs. The inference6
(a) Chip Computer Chip Computer Chip Computer (b)
+
Digital subtraction
Softmax
1
|x | |x | 2 Sum Backward Forward
U U U |x | +
∂L
0 Compute
∂η pη,sum − −
pη,aj pη
(c) Circle: in situ training curve (d) Circle: classification
(e) Circle: gradient error histogram
1.0 80 Optical monitor measurements
Digital: test 2
Iteration 930
in situ: test (1) Forward 1.0
2.0 0.8
Digital: train 60 Predicted
1
Cost function L
in situ: train 0.5
1.5 0.6
Measured
x2 0 40
0.0
0.4
1.0
−1 (2) Backward
1.0
0.2 20 Predicted
0.5
−2 0.5
0.0 Measured
0
0 500 1000 −2 0 2
10−3 10−2 10−1 100 0.0
Iteration x1 Gradient errors:
= 1 − ĝ · g
(f) (g) (h) (3) Sum 1.0
Moons: in situ training curve Moons: classification Moons: gradient error histograms Predicted
2.0 1.0
Digital 2
Iteration 1800 Correct phase 0.5
80 Measured
in situ, correct phase Measured phase
0.8
1.5 in situ, meas phase 0.0
1
Cost function L
60
0.6 Gradient: g = 5.70
x2
1.0 0 Measured
0.4 40 Predicted
−1
0.5
0.2 20
−2
0.0 0.0
0 1000 2000 −2 0 2 0
10−3 10−2 10−1 100
Iteration x1 Gradient errors:
= 1 − ĝ · g
FIG. 3. We perform in situ backpropagation training based on stochastic gradient descent and Adam update [25] (learning
rate 0.01) for two classification tasks solvable by (a) a three layer hybrid photonic neural network consisting of absolute value
nonlinearities and a softmax (effectively sigmoid) decision layer. For the circle dataset, (b) the training curve for Adam update
for stochastic gradient descent shows excellent agreement between test and train for both digital and in situ backpropagation
updates resulting in (c) a classification plot showing the true labels and the classification curve based on the learned parameters
resulting in 96% model test accuracy and 93% model train accuracy. (d) For the moons dataset, we compare the test cost
curves for the digital and the in situ updates, where we find that our phase measurements are sufficiently inaccurate to impact
training leading to a lower model train accuracy of 87%. If we use ground truth phase measurements (red) instead of measured
phases (blue), we ultimately arrive at (e) a sufficiently high model test accuracy of 98% (model train accuracy is lower at
95%). When using ground truth phases instead of measured phases, (f) the gradient error reduces considerably by roughly
an order of magnitude. (g) While training the circle classification was successful, the measured gradient error is similarly
large as that measured in the moons training experiment. This suggests that the importance of accurate gradients can be
problem-dependent.
operation of our photonic neural network consists of pro- where we define the softmax2 : C4 → [0, 1]2
gramming the inputs in the red Generator circuit and as two-element vector representing the prob-
measuring outputs on the blue Analyzer circuit, repro- ability of 0 or 1 label to be softmax2(y) =
2 2 2 2 2 2 2 2
gramming the unitary for each Matrix unit layer on the (e|y1 | +|y2 | , e|y3 | +|y4 | )/(e|y1 | +|y2 | + e|y3 | +|y4 | ).
same chip, and square-rooting the output power mea- We then apply a softmax cross entropy (SCE) cost func-
surement to achieve absolute value nonlinearities of the tion L(x) = SCE(ẑ(x), z) = z0 log ẑ0 + z1 log ẑ1 . The
form |y| (see Appendix for more detailed description). ultimate goal is to apply automatic differentiation and
This unitary layer reprogramming is only intended for in situ analog gradient measurement on our photonic
a proof-of-concept; the ultimate implementation would device to optimize L.
dedicate a separate optical device to each linear layer.
The neural network inference model outputs probabil- Input data to our device is formatted into the form
ity of 0 or 1 (red or blue assignment) of each point based (x1 , x2 , p, p), where x1 , x2 correspond to the location in
on the following model: 2D space and p is some power ensuring that all inputs are
normalized to the same power P , i.e. x21 + x22 + 2p2 = P ;
ẑ(x) = softmax2(|U (3) |U (2) |U (1) x|||) (3) this convention follows the simple example in Ref. 5.7 We perform a 80/20% train-test split (200 train points, the simulated and measured training curves. Despite 50 test points), holding out test data from training to these swings and phase shift gradient errors shown in ensure no “overfitting” takes place, though this is unlikely Fig. 2(e), our results of 96% model test accuracy and for our simple model. We generally find higher test than 93% model train accuracy indicate successful training as train accuracy in our results since there are fewer “noisy shown in Fig. 2(d). examples” in our randomly generated test sets. We then train a moons dataset, where we apply the Our single photonic chip is used to perform the data same procedure to achieve a model train accuracy of input, data output and matrix operations for all three 87% and model test accuracy of 94%, which suggests layers of our photonic neural network shown in Fig. 3(a). that training occurs but there is room for improvement After each pass through the photonic chip, we measure as shown in green in Fig. 3(f). Upon further investi- the output power and digitally perform a square-root op- gation, we find that if we use the ground truth phase eration to effectively implement absolute value nonlinear- for the phase measurement but keep the amplitude mea- ities on the computer. Throughout the process (forward, surements, we reduce the phase shift gradient error by backward and sum steps), we also perform digital simula- roughly an order of magnitude on average as shown in tions so we can compare the experimental and simulated Fig. 3(h). This results in the successfully trained classifi- performance at each step as shown in Fig. 1(b). Mini- cation of Fig. 3(g) and the red curve in in Fig. 3(f) which mizing the cost L ultimately leads to maximum accuracy shows excellent correlation with the black digital train- in classifying points to the appropriate labels. ing curve. When using the corrected ground truth phase When performing training, the most critical informa- measurement, we achieve a model train accuracy of 95% tion is in the gradient direction, so we compute gradi- and model test accuracy of 97% for the full backpropa- ent direction error using 1 − g · ĝ comparing normalized gation demonstration based on measured phase (stopped measured and predicted g = ∂L/∂η · k∂L/∂ηk−1 . An early at 1000 iterations), an improvement that under- important distinction to make for metric reporting is the scores the importance of accurate phase measurement for difference in “model” versus “device” cost function and improved training efficiency. accuracy. In Fig. 3, we report “model metrics” by evalu- ating device parameters learned on our chip on the true model. Thus, actual training of the physical parameters DISCUSSION AND OUTLOOK is performed on the device itself, and the result of train- ing is evaluated on the computer. In this paper, we have laid the foundation for the anal- Our first task is to verify that inference works on our ysis of our new in situ backpropagation proposal and platform, which we show for a randomly generated “ring” tolerance to gradient errors for the design of practically dataset to have 90% device test set accuracy on our phys- useful photonic mesh accelerators. Our proof-of-principle ical platform shown previously in Fig. 1(c). Once we experiments suggests that even in the presence of such confirm that the inference performance is acceptable, we gradient error, gradient measurement and training pho- then perform training of 2D classification problems using tonic neural networks using analog backpropagation up- our digital subtraction approach on our randomly gener- dates is efficient and feasible. ated datasets. We use standard gradient update Adam Although there exist many approaches for training stochastic gradient descent [25] with a learning rate of photonic neural networks, our demonstration and en- 0.01, with all non-linear automatic differentiation per- ergy calculations (Appendix) suggest that in situ back- formed off the chip via Python libraries JAX and Haiku propagation is the most practical and efficient approach [27, 28]. for training deep multilayer hybrid photonic neural net- We first report our training update model metrics for works. Our hybrid approach to training optically ac- the circle dataset for the photonic neural network shown celerates the most computationally intensive operations in Fig. 3(a). In Fig. 3(b), we show the grating tap- (both in energy and in time complexity), specifically to-camera measurements of normalized field magnitudes O(N 2 ) matrix-vector products and matrix gradient com- in the final layer for all three passes required for digital putations (backward pass). On the other hand, all subtraction across all layers of our device at iteration 930 other O(N ) computations such as nonlinearities and their (near the optimum), which show excellent agreement be- derivatives are implemented on the computer directly, tween predicted and measured fields. The training curves which is reasonable because O(N ) time is needed to mod- in Fig. 3(c) indicate that stochastic gradient descent is a ulate and measure optical inputs and outputs anyway. highly noisy training process due to the noisy synthetic Other techniques such as population-based methods [29], dataset about the boundary; this phenomenon can be ob- direct feedback alignment [30, 31], and perturbative ap- served for both the digital and analog approaches. Due proaches require fewer components to implement but are to these outliers, we only observe convergence in the time ultimately less efficient for training deep neural networks (iteration)-averaged curves because even at convergence, compared to backpropagation. updates based on outliers or some incorrectly labelled Our main finding is that gradient accuracy plays an points can result in large swings in the cost function. important role in reaching optimal results during train- These large swings appear roughly correlated between ing. As we find in Fig. 3, more accurate gradients result
8
in training convergence speeds and oscillations compara- perimental code via Phox [26], simulation code via Sim-
ble to digital calculations of the gradients updated over phox [35], and circuit design code via Dphox [36].
the same training example sequence. This accuracy is vi-
tal for in situ backpropagation to be a viable competitor
to existing purely digital training schemes; in particular, CONTRIBUTIONS
even if individual updates are faster to compute, high
error would result in longer training times that mitigate SP taped out the photonic integrated circuit and ran
that benefit. In the Appendix, we frame this error scaling all experiments with input from ZS, TH, TP, BB, NA,
in terms of a larger scale PNN simulation on the MNIST MM, OS, SF, DM. SP and ZS wrote code to control ex-
dataset originally as explored in Ref. [32], where we con- perimental device. TP designed the custom PCB with
sider errors in gradient measurement due to optical I/O input from SP. SP wrote the manuscript with input from
errors and photodetector noise at the global monitoring all coauthors. All coauthors contributed to discussions
taps. of the protocol and results.
Our findings ultimately have wide ranging implications
because backpropagation is the most efficient and widely
used neural network training algorithm in conventional CONFLICTS OF INTEREST
machine learning hardware used today. Our analog ap-
proach for machine learning thus opens up a vast op- SP, ZS, TH, IW, MM, SF, OS, DM have filed a
portunity for energy-efficient artificial intelligence appli- patent for the analog backpropagation update protocol
cations using photonic hardware. We additionally pro- discussed in this work with Prov. Appl. No.: 63/323743.
vide seamless integration into current machine learning The authors declare no other conflicts of interest.
training protocols (e.g. autodifferentiation frameworks
such as JAX [27] and TensorFlow [33]). A particularly
impactful opportunity is in data center machine learn- METHODS
ing where optical signals already store data that can be
fed into PNNs for inference and training tasks. In such A. Circuit design and packaging
settings, our demonstration presents a key new oppor-
tunity for both inference and training of hybrid PNNs
Our photonic integrated circuit is a 6 × 6 triangular
to dramatically reduce carbon footprint and counter the
photonic mesh consisting of a total of 15 MZIs fabricated
exponentially increasing costs of AI computation.
at the AdvancedMicroFoundry (AMF) in Singapore de-
signed using our photonic library DPhox [36] which is
a custom automated photonic design library in Python.
ACKNOWLEDGEMENTS Each of the MZIs in the mesh is controlled using pro-
grammable phase shifters in the form of 80 µm × 2 µm ti-
We would like to acknowledge Advanced Micro- tanium nitride heaters with 10.5 ohm/sq sheet resistance
Foundries (AMF) in Singapore for their help in fabri- surrounded by deep trenches that are 80 µm × 10 µm
cating and characterizing the photonic circuit for our and a total of 7µm away from the waveguide, which use
demonstration and Silitronics for their help in packag- resistive heating to control the interference of light prop-
ing our chip for our demonstration. We would also like agating in the chip. The MZIs consist of two 50/50 direc-
to acknowledge funding from Air Force Office of Scientific tional couplers, with S-bends consisting of 30 µm radius
Research (AFOSR) grants FA9550-17-1-0002 in collabo- arc turns and 40 µm long interaction lengths with a 300
ration with UT Austin and FA9550-18-1-0186 through nm gap. Next to each of the phase shifters is a bidirec-
which we share a close collaboration with UC Davis un- tional grating tap monitor, which is a directional coupler
der Dr. Ben Yoo. Thanks also to Payton Broaddus tap that couples 3% of the light propagating either for-
for helping with wafer dicing, Simon Lorenzo for help in ward or backward through the waveguide attached to the
fiber splicing the fiber switch for bidirectional operation, tap and feeds that light to a grating to be imaged on a
Nagaraja Pai for advice on electrical and thermal con- camera focused on the grating. Traces for one of the ter-
trol packaging, and finally Carsten Langrock and Karel minals of each of the phase shifters are routed to separate
Urbanek for their help in building our movable optical individual pads on the edge of the chip, and the ground
breadboard. connections across all phase shifters in a column of MZIs
are shared and connected to a single ground pad. The
trace widths need to be thick enough to handle high ther-
mal currents, so we use 15 µm wide traces and 15Nwire
DATA AND SOFTWARE µm wide traces when multiple connections are connected
to a shared ground contact.
All software and data for running the simulations The photonic chip is attached using silver paint to
and experiments are available through Zenodo [34] and a 1.5mm thick copper shim and a custom Advanced
Github through the Phox framework, including our ex- Circuits PCB designed in KiCAD consisting of ENIG9
coated metal traces to interface the phase shifters with an triangular mesh circuit is constructed such that the grat-
NI PCIe-6739 controller for setting programmable phase ing taps lie along columns of devices, which means the
shifts throughout the device. Our PCB is wirebonded optical rig images a 6 × 19 array of spots. The infrared
using two-tier wirebonding to the chip by Silitronics So- path has roughly a 700 × 600 µm field of view, allow-
lutions, made possible by fanout to NI SCB-68 connectors ing simultaneous measurements of 6 × 3 grating spots on
that interface directly to our PCIe-6739 system. The in- the chip (MZIs are 625 µm long in total given roughly
put optical source is a Agilent 81606A tunable laser with 165 µm long directional couplers), which necessitates an
a tunable range of 1460 nm to 1580 nm. The laser light is XY translation stage to image multiple spots simultane-
coupled into a single-mode fiber and optically interfaced ously on the chip.
to the chip using W2 Optronics 127 micron pitch fiber The speed of backpropagation is limited by the me-
array interposers at the left and right sides of the mesh, chanics of the XY stage required to image spots through-
with a mirror facet designed to couple optical signals at out the chip, so our demonstration training experiments
10 degrees from the normal as we only need to couple took up to 31 hours of real time to run, limited primarily
into a single grating coupler for each fiber array coupler. by the wait time for the stage to settle on various groups
Optical stray reflections from light not coupled into the of spots on the chip. Assuming T iterations, the stage
chip generally interfere with grating tap signals forming needs to move a total of 15T times (5 for each of the
extra streaks in the camera; these stray reflections are three in situ backpropagation steps to be able to image
blocked using pieces of paper carefully placed above the all of the spots). For 1000 iterations, the stage needs to
fiber arrays that act as lightweight removable stray light move a total of 15000 times which necessitates the need of
blockers. automation for the stage of our proof-of-concept demon-
For thermal stability, this chip-PCB assembly is ther- stration. In a final commercial implementation, the grat-
mally connected to a thermoelectric cooler (TEC). This ing taps would be replaced by integrated photodetectors;
thermal connection is made possible by metal vias con- there would in principle be no separate optical rig system
necting rectangular ENIG-coated copper patches on the in a fully packaged hybrid digital-analog photonic circuit.
top of the PCB to the bottom of the PCB, with thermal
paste between an aluminum heat sink mount and the
bottom rectangular metal patch. For feedback control, C. Forward inference operation
a thermistor placed near the chip and the TEC under
the chip are attached to a TEC controller unit, allowing Forward inference proceeds as follows for layer ` (see
stable chip temperature (kept at 30◦ C) for training. Fig. 1(a) in the main text) where each step is O(N ):
(`) (`)
1. Compute the sets of phase shifter settings θX , φX
B. Optical rig design for the Generator to give the desired vector x(`) of
complex input amplitudes for the Matrix unit in
Our optical rig consists of an Ethernet cable-connected layer ` .
Xenics Bobcat 640 IR camera and microscope assembly 2. Set these as the actual phase shifts in the Gen-
mounted on an XY stage and six-axis stages for free space erator phase shifters using calibration curves for
fiber alignment. The IR camera and microscope image vθ (θ), vφ (φ) and shine light into the Generator cir-
individual grating taps throughout a photonic integrated cuit to create the corresponding actual vector of
circuit (PIC) and is responsible for all measurement on optical input amplitudes for the Matrix unit.
the chip (both optical I/O and optical gradient monitor-
ing). 3. After the propagation of light through the Matrix
The microscope uses an ∞-corrected Mitutuyo IR 10x unit, the system has optically evaluated the vec-
objective and a 40cm tube lens leading to a dichroic con- tor of complex optical output amplitudes y (`) =
nected to visible and IR optical paths for simultaneous U (`) x(`) . Now self-configure [37] the output An-
visible and infrared imaging. The optical rig is also out- alyzer circuit to give all the output power in the
fitted with additional paths for LEDs to illuminate the “top” output waveguide, and note the correspond-
actual chip features. This allows us to find the optimal ing sets of voltages vφ and voltages vθ now applied
focus for the grating spots, an image shown in Fig. 2(a). to each phase shifter in the Generator circuit.
In order to measure intensities directly using the IR cam- (`) (`)
era, the Bobcat camera “Raw” mode is turned on and 4. Deduce the phase shifts θY , φY in the Analyzer
autogain features are turned off. The integration time circuit using calibration curves for θ(vθ ), φ(vφ ), and
is set to 1 millisecond, and the input laser power is set hence compute the corresponding measured output
to 3 mW; note that higher integration times are required amplitudes y (`) .
for lower input laser powers. We take an initial reference 5. Compute x(`+1) = f (`) (y (`) ) on the computer.
image to get a baseline and then to measure the spots in-
tensities or powers, we sum up the pixel values that “fill” The first four steps are also used in cases where light
the appropriate grating taps throughout the device. The is sent backwards (see Fig. 1(g, h)), switching the role10
(a) Grating monitors (b) Metal trace, via, and thermal phase shifter (d) Fiber array inputs
Deep trench: thermal isolation
TiN
Bidirectional Deep trench: thermal isolation
3% coupler
Bidirectional
(c) Routing phase shifters to pads on the chip
Two-tier wirebond to PCB
FIG. 4. Microscope images of the photonic mesh used in this paper. (a) Grating monitor closeup showing the bidirectional
grating tap we use to perform the backpropagation protocol. (b) Metal trace, via, and TiN (titanium nitride) phase shifter is
colocated with the grating monitor and is used to control the interference by changing optical phase in the mesh programmat-
ically. Deep trenches are used for thermal isolation. Here, we show an overlay of phase shifter focal plane on the top metal
trace and via used to connect each phase shifter to the pads. (c) A large scale view of a section of the chip (d) Fiber array
inputs to the photonic mesh are spaced 127 µm apart and are used for interfacing fiber arrays.
of the input and output vector units from Generator to Fig. 1(c), each transformation from the forward step is
Analyzer and vice versa. Pseudocode for the forward mapped to a VJP in the corresponding backward step
operation of the PNN is provided in the Appendix, and (defined in decreasing order from layer L to 1) which de-
code for the actual implementation is provided in our pends on intermediate function evaluations in both for-
photonic simulation and control framework Phox [? ]. ward and backward passes. The in situ backpropagation
step implements the costly intermediate VJP evaluations
(i.e. matrix multiplications) directly in the analog optical
domain. We define the VJP for nonlinearity f (`) (y (`) ) as
D. Backpropagation protocol (`) (`+1)
fvjp (y (`) , xaj ):
For each training example (x, z), we calculate gradient (`) (`) (`+1)
yaj = fvjp (y (`) , xaj )
updates to phase shifts η using a “backward pass” cor- (4)
(`) (`)
responding to the inference “forward pass” for that data. xaj = (U (`) )T yaj
More formally, we define a “vector-Jacobian product” or
VJP for each function U (`) , f (`) to algorithmically com- Finally, we synthesize Eqs. 1 and 4 and the results
pute the gradient of our cost function L. As shown in of Ref. 5 to get the backpropagation update based on11
applying the chain rule evaluating the cost function at a 5. Update η using measured gradients ∂L/∂η.
random training example xt , zt at iteration t: (`)
Note that Step 1 can be simplified to yaj = (f (`) )0 (y (`) )
(`) (`+1)
xaj xaj in the case that f (`) is holomorphic, or complex-
z }| {
differentiable. In this paper for the neural network
∂L ∂y (`) ∂x(`+1) ∂ zb ∂L
= ··· parametrized by Eq. 3, we specifically care about the
∂η (`) ∂η (`) ∂y (`) ∂y (L) ∂ zb nonlinearity f (`) (y) = |y|, which has the associated VJP:
| {z } xt ,zt
(L)
yaj
(`) y
fvjp (y, xaj ) = · R(xaj ). (6)
D` ×N Jacobian
z }| { N ×1 vector
|y|
z}|{
∂y (`) (`) (5) The other VJP required to calculate ∂L/∂y (L) from the
= · xaj
∂η (`) final softmax cross entropy and power measurement at
“optical VJP” the end of the network is handled by our automatic dif-
z }| { D` ×1 in situ gradient
∂U (`) (`) z }| { ferentiation framework JAX [27, 28].
(`) T
= (x ) (`)
xaj = −I(xη(`) xη(`) ,aj ) Steps 3 and 4 can be parallelized over all layers (i.e.,
∂η parameters of the network) for both the digital and ana-
∂L log update schemes. Pseudocode for the overall protocol
ηt := ηt−1 + α (using digital subtraction), along with an energy-efficient
∂η
xt ,zt proposal for analog gradient computation, is discussed
in the Appendix. The final step can be achieved using
where xη represents a vector of intermediate fields at the
“stochastic gradient descent” (which independently up-
input of phase shifters in layer ` η (`) at iteration t, D` dates the loss function based on randomly chosen training
is the number of phase shifts parametrizing the device at examples) or adaptive learning where the update vector
layer `, I refers to imaginary part, and α is the learning depends both on past updates and the new gradient. A
rate. The main idea is that if enough training examples successful and commonly used implementation of this,
are supplied (i.e., after T updates), the device will au- which we use in this paper, is called the Adam update
tomatically discover or “learn” a function that performs [25].
the task we desire.
Based on Eq. 4, the steps of our optical VJP step, as
depicted in Fig. 1(c), is as follows in order from layer Appendix A: Energy and latency analysis
` = L to 1 of the photonic neural network:
(`) In this section, we justify why the analog in situ up-
1. Compute the “adjoint” vector yaj =
(`) (`+1) (`)
date discussed in the main text may be chosen over the
fvjp (y (`) , xaj ).
For the last layer, set yaj digital update proposed in Ref. [5] and used in our main
(L) ∗
to be the error signal yaj = ∂x∂L
(L+1) . backpropagation training demonstration.
In our hybrid scheme, most of the computation is con-
2. Perform the backward “adjoint” pass xaj = U T yaj
(`) (`) centrated in sending in N input modes using modulators
by sending light backwards through layer ` of the (each taking energy Einp ) and digital-analog converters
mesh and measuring the resulting vector of ampli- and measuring the N output mode powers and ampli-
(`) tudes using photodetectors and analog-digital converters
tudes xaj emerging backwards from the mesh.
(each taking energy Emeas ). Therefore, the various ap-
(`) proaches for a given matrix-vector product cost roughly
3. Send the vector of optical amplitudes x(`) −i(xaj )∗ N · (Einp + Emeas ), equivalent to the cost for setting up
forward into layer ` of the mesh. the input/output behavior for the photonic mesh. A dig-
ital electronic computer, on the other hand, requires N 2
4. Measure gradient ∂L/∂θ for any phase shifter θ:
sequential operations (i.e., multiply-and acumulate oper-
(a) If using digital subtraction measurement [5], ations that are not parallel) to compute any given matrix-
measure the sum power pθ,sum and subtract vector product.
pθ and pθ,aj (monitored power from forward Beyond inference tasks, the additional backward and
and backward steps) to get the gradient. sum steps required for in situ backpropagation adds addi-
tional energy and latency contributions. The analog up-
(b) If using analog gradient measurement, sweep date explored in Fig. 2 requires N 2 optoelectronic units
the adjoint global phase ζ (giving x(`) − for energy-efficient operation, each of which is outfitted
(`)
i(xaj )∗ eiζ ) from 0 to 2π repeatedly (e.g., us- with a photodetector, a lock-in amplifier, and high-pass
ing a sawtooth signal). Measure dθ (ζ), the filter consuming energy Egrad to measure dθ (0) for a total
AC component of the measured power through energy consumption of N 2 Egrad + N · (3Einp + 2Emeas )
phase shifter θ, pθ,sum (ζ). The gradient is for all three steps of the full backpropagation measure-
dθ (0)/2. ment. The 2Emeas comes from the output measurements12
in the first two steps, and the Egrad comes from an analog This would dramatically smooth out the noisy training
gradient measurement in the final step. curves shown in Fig. 6(a-f), as the resulting averaged
In comparison, the digital subtraction described in Fig. gradients would actually be much smaller in magnitude.
1 can be useful in adaptive updates that require storing However, as shown in Fig. 6(g), we find that the nor-
information about previous gradients (such as Adam [25] malized error of a minibatch gradient is generally sig-
which we exploit for training), but there are a couple of nificantly higher than that of the gradient for a single
drawbacks. First, a digital update is less memory efficient training example which can have negative implications
since N 2 elements need to be stored using analog memory for training. This is because the variance of the gradient
to be able to run the “digital subtraction” computation error remains the same when averaged over many exam-
in backpropagation. Additionally, the total energy con- ples, but the contribution of the gradient error is much
sumption becomes 3N 2 Egrad,digital +N ·(3Einp +2Emeas ), larger over a batch. This phenomenon might be problem-
with Egrad,digital
Egrad,analog due to large numbers dependent; if the average gradient for the minibatch is
of analog-digital conversions required to implement the not closer to zero than the gradient for individual train-
analog-digital conversions and digital subtraction calcu- ing examples, this error may not be an issue. This under-
lations. Analog-digital conversions are among the most scores the importance of accurate gradient measurement,
energy- and time-consuming operations in a hybrid pho- which can be improved using more accurate output phase
tonic device; when operating at GHz speeds, the best measurements; our output phase measurement alone re-
individual comparators generally require up to 40 fJ sults in an order-of-magnitude increase in gradient error.
[38, 39] (versus around 1 fJ/bit for input modulators Finally, a linear relationship between phase and volt-
[40]) and therefore should ideally be reserved for opti- age can help to improve gradient update accuracy with-
cal input/output in the photonic meshes. out requiring nontrivial scaling complexity in the hard-
A final energy consideration is the phase shift modu- ware. In other words, we ensure ∂L/∂vθ = ∂θ/∂vθ ·
lation. These voltage-controlled modulators may be con- ∂L/∂θ with constant ∂θ/∂vθ which simplifies the re-
trolled by thermal actuation [41], microelectromechanical quired analog circuitry. The ∂θ/∂vθ term is calculated
(MEMS) actuation [42] or phase-change materials such using calibration curves, and this assumption is more-or-
as barium titanate (BTO) [43]. Of these options, MEMS less valid in our case as we operate the phase shifters in
actuation is among the most promising because unlike the linear regime as shown in Fig. 8(e).
thermally actuated phase shifters, they cost no energy
to maintain a given programmed state (“static energy”),
dramatically improving the energy efficiency of operation Appendix C: Usage in machine learning software
compared to thermal phase shifters which constantly dis-
sipate large amounts of heat. Additionally, unlike phase Backpropagation is also known as automatic differenti-
change materials, MEMS phase shifters use CMOS mate- ation (AD) because any program that uses backpropaga-
rials such as silicon or silicon nitride. Furthermore, such tion registers a “backward” gradient function for any for-
devices can be designed to operate in the linearly with ward function, which is used by AD Python engines such
voltage [44, 45] which ensures that the gradient update as JAX[27], TensorFlow2 [33], and PyTorch. We demon-
applied to the voltage is the same as that of the phase strate that our protocol can be easily coupled with an
shift without a calibration curve. This helps with gradi- existing automatic differentiation framework (JAX and
ent accuracy as we discuss now. Haiku [27, 28]), which can register a backward step and
adaptive update based on Adam [25] for all unitary ma-
trix operations as an analog in situ backpropagation gra-
Appendix B: Gradient accuracy dient calculation rather than an expensive digital opera-
tion. In this way, the digital side of our hybrid PNN never
As shown in Fig. 3(f, h) and in Fig. 6(h), gradient needs to store or have any knowledge of parameters in
accuracy can affect the optimization and decrease as the the photonic mesh architecture. However, in cases where
optimization approaches convergence. As we find in the adaptive gradient updates are used, such as Adam, aggre-
main text, accurate phase measurement plays an impor- gated knowledge based on past gradient updates needs
tant role in measuring accurate gradients. This is true to be stored; non-volatile memory may be required to
even when the nonlinearity (as in our case with abso- energy-efficiently store these additional parameters.
lute value) removes the need to measure phases in the
inference step. Since in the main text, we evaluate the
model accuracy (device-trained parameters evaluated on Appendix D: Comparison with other training
a theoretical computer model), we also show some ev- algorithms
idence that the device and model classifications match
quite well in Fig. 6(i, j). Backpropagation is the most widely used and efficient
One popular type of update is based on “minibatch known algorithm for training multilayer neural network
gradient descent,” a machine learning technique that cal- models, though it is far from the only method for calcu-
culating gradients based on multiple training examples. lating gradient-based updates.You can also read

















































