Neural Representations for Modeling Variation in Speech
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Neural Representations for Modeling Variation in Speech
Martijn Barteldsa Wietse de Vriesa Faraz Sanalb
Caitlin Richterb Mark Libermanb Martijn Wielingac
a
Center for Language and Cognition, Faculty of Arts, University of Groningen, Groningen, The Netherlands
b
Department of Linguistics, University of Pennsylvania, Philadelphia, PA, USA
c
Haskins Laboratories, New Haven, CT, USA
Correspondence: Martijn Bartelds, Center for Language and Cognition, Faculty of Arts, University of Groningen,
Oude Kijk in ’t Jatstraat 26, 9712 EK Groningen, The Netherlands, E-mail: m.bartelds@rug.nl
Abstract While acoustic variability may be caused by techni-
cal aspects such as microphone variability (Mathur
Variation in speech is often quantified by com-
paring phonetic transcriptions of the same et al., 2019), an important source of variation is
arXiv:2011.12649v3 [cs.CL] 26 Jan 2022
utterance. However, manually transcribing the embedding of accent or dialect information in
speech is time-consuming and error prone. As the speech signal (Hanani et al., 2013; Najafian
an alternative, therefore, we investigate the et al., 2014). Non-native accents are frequently ob-
extraction of acoustic embeddings from sev- served when a second language is spoken, and are
eral self-supervised neural models. We use mainly caused by the first language background of
these representations to compute word-based
non-native speakers. Similarly, regional accents are
pronunciation differences between non-native
and native speakers of English, and between
caused by the (first) dialect or regional language
Norwegian dialect speakers. For comparison of the speaker. The accent strength of a speaker
with several earlier studies, we evaluate how depends on the amount of transfer from their na-
well these differences match human percep- tive language or dialect, and is generally influenced
tion by comparing them with available human by a variety of characteristics, of which the age of
judgements of similarity. We show that speech learning the (second) language, and the duration
representations extracted from a specific type of exposure to the (second) language are important
of neural model (i.e. Transformers) lead to a
predictors (Asher and Garcı́a, 1969; Leather, 1983;
better match with human perception than two
earlier approaches on the basis of phonetic Flege, 1988; Wieling et al., 2014a).
transcriptions and MFCC-based acoustic fea- However, accent and dialect variability are often
tures. We furthermore find that features from overlooked in modeling languages using speech
the neural models can generally best be ex- technology, and consequently high-resource lan-
tracted from one of the middle hidden layers guages such as English are often treated as homo-
than from the final layer. We also demon- geneous (Blodgett et al., 2016). Given that the
strate that neural speech representations not
number of non-native speakers of English is almost
only capture segmental differences, but also in-
tonational and durational differences that can- twice as large as the former group, this assumption
not adequately be represented by a set of dis- is problematic (Viglino et al., 2019). It is there-
crete symbols used in phonetic transcriptions. fore important to accurately model pronunciation
Keywords: acoustic distance, acoustic embed- variation using representations of speech that al-
dings, neural networks, pronunciation varia- low accent and dialect variability to be adequately
tion, speech, transformers, unsupervised rep- incorporated.
resentation learning. Traditionally, pronunciations are often repre-
sented by phonetically transcribing speech (Ner-
1 Introduction
bonne and Heeringa, 1997; Livescu and Glass,
Past work in (e.g.,) automatic speech recognition 2000; Gooskens and Heeringa, 2004; Heeringa,
has found that variability in speech signals is often 2004; Wieling et al., 2014b; Chen et al., 2016;
poorly modeled, despite recent advances in speech Jeszenszky et al., 2017). However, accurately tran-
representation learning using deep neural networks scribing speech using a phonetic alphabet is time
(Huang et al., 2014a,b; Koenecke et al., 2020). This consuming, labor intensive, and interference from
may be particularly true for monolingual as op- transcriber variation might lead to inconsistencies
posed to multilingual models (Żelasko et al., 2020). (Hakkani-Tür et al., 2002; Bucholtz, 2007; Novot-ney and Callison-Burch, 2010). Additionally, pho- linear relationships (Schneider et al., 2019; Baevski
netic transcriptions are not entirely adequate in et al., 2020a; Ling et al., 2020; Baevski et al.,
representing how people speak, as fine-grained pro- 2020b). Generally, neural models benefit from
nunciation differences that are relevant for study- large amounts of labeled training data. However,
ing accented speech (or dialect variation) may not self-supervised neural models learn representations
be fully captured with a discrete set of symbols of speech without the need for (manually) labeled
(Mermelstein, 1976; Duckworth et al., 1990; Cuc- training data. Therefore, these models can be
chiarini, 1996; Liberman, 2018). trained using even larger amounts of data. Previous
Consequently, acoustic-only measures have been work has shown that fine-tuning these neural mod-
proposed for comparing pronunciations (Huckvale, els using transcribed speech resulted in representa-
2007; Ferragne and Pellegrino, 2010; Strycharczuk tions that resembled phonetic structure, and offered
et al., 2020). Whereas these studies only consid- significant improvements in downstream speech
ered limited segments of speech, or exclusively recognition tasks (van den Oord et al., 2019; Kahn
included speakers from a single language back- et al., 2020). In contrast to previous methods for
ground, Bartelds et al. (2020) introduced a new comparing pronunciations, these self-supervised
method that did not have these limitations. Specifi- (monolingual and multilingual) neural models are
cally, Bartelds et al. (2020) proposed an acoustic- based on large amounts of data from a large group
only method for comparing pronunciations without of (diverse) speakers and are therefore potentially
phonetic transcriptions, including speakers from robust against accent variation.
multiple native language backgrounds while us- Consequently, in this paper, we employ and eval-
ing all information available within the speech sig- uate several of these self-supervised neural mod-
nal. In their method, they represented accented els in order to create a fully automatic acoustic-
speech as 39-dimensional Mel-frequency cepstral only pronunciation difference measure, which is
coefficients (MFCCs), which were used to com- able to quantify fine-grained differences between
pute acoustic-based non-native-likeness ratings be- accents and dialects. Specifically, we compare
tween non-native and native speakers of English. and evaluate five self-supervised neural models,
They found a strong correlation of r = −0.71 namely wav2vec (Schneider et al., 2019, sub-
between their automatically determined acoustic- sequently denoted by w2v), vq-wav2vec with
based non-native-likeness scores and previously the BERT extension (Baevski et al., 2020a, sub-
obtained native-likeness ratings provided by hu- sequently denoted by vqw2v), wav2vec 2.0
man raters (Wieling et al., 2014b). This result was (Baevski et al., 2020b, subsequently denoted by
close to, but still not equal to, the performance w2v2), the multilingual w2v2 model XLSR-53
of an edit distance approach on the basis of pho- (Conneau et al., 2020, subsequently denoted by
netic transcriptions (which showed a correlation of XLSR), and DeCoAR (Ling et al., 2020). Each
r = −0.77). of these models learned speech representations by
Bartelds et al. (2020) conducted several small- predicting short fragments of speech (e.g., approxi-
scale experiments to investigate whether more fine- mately 300 milliseconds on average in the case of
grained characteristics of human speech were cap- w2v2) within spoken sentences from the training
tured as compared to the phonetic transcription- data. These predicted fragments therefore roughly
based pronunciation difference measure. Their re- correspond to one or more subsequent phonemes
sults showed that the acoustic-only measure cap- (including their transitions). These neural models
tured segmental differences, intonational differ- were selected for this study as they achieved state-
ences, and durational differences, but that the of-the-art speech recognition results on standard
method was not invariant to characteristics of the benchmarks such as the Wall Street Journal corpus
recording device. (WSJ; Garofalo et al., 2007) and the Librispeech
corpus (Panayotov et al., 2015), while differing
The quality of MFCC representations is known
with respect to their specific architecture.
to be dependent on the presence of noise (Zhao
and Wang, 2013). Recent work has shown that There are several use cases in which adequately
neural network models for self-supervised rep- quantifying pronunciation differences automati-
resentation learning are less affected by noise, cally is important. First, the field of dialectometry
while being well-equipped to model complex non- (see e.g., Nerbonne and Heeringa, 1997; Wielinget al., 2011; Wieling and Nerbonne, 2015) inves- by the neural models, we introduce a visualiza-
tigates geographical (and social) dialect variation tion approach revealing the location of differences
on the basis of pronunciation differences between between two compared recordings, and conduct
different dialects. While there are several dialect several additional small-scale experiments, in line
(atlas) datasets containing phonetic transcriptions, with those conducted by Bartelds et al. (2020).
differences in transcription practices (sometimes
even within the same dataset; Wieling et al., 2007) 2 Materials
limit the extent to which these pronunciations can
be compared. An acoustic-only method would 2.1 Datasets
solve these compatibility issues, and would allow Our acoustic data comes from three datasets in two
datasets that do not have phonetic transcriptions different languages. We use two datasets that con-
to be analyzed directly. Another use case is high- tain (mostly) non-native American-English pronun-
lighted by a recent study of San et al. (2021). They ciations, and an additional dataset with Norwegian
automatically compare pronunciations acoustically dialect pronunciations.
to find pronunciations of a specific word from en-
dangered languages in a large set of unannotated 2.1.1 Non-native American-English
speech files. Such a system, if successful, directly Pronunciations from non-native speakers of
impacts language maintenance and revitalisation American-English are obtained from the Speech
activities. Accent Archive (Weinberger and Kunath, 2011),
To evaluate the quality of the pronunciation dif- as well as the Dutch speakers dataset described in
ferences, we will use human perceptual judge- Offrede et al. (2020). The Speech Accent Archive
ments. Previous work has shown that human lis- covers a wide variety of language backgrounds,
teners can adequately assess and quantify differ- while the Dutch speakers dataset is suitable for
ences between pronunciations (e.g., Preston, 1999; evaluating our method on a set of English pronun-
Gooskens, 2005; Scharenborg, 2007). To deter- ciations that have more fine-grained accent differ-
mine the relative performance of our methods, we ences, as it only contains speakers with the same
compare the use of self-supervised neural mod- native (Dutch) language background.
els to the phonetic-transcription-based approach The Speech Accent Archive contains over 2000
of Wieling et al. (2014b), and the MFCC-based speech samples from native and non-native speak-
acoustic-only approach of Bartelds et al. (2020). ers of English. Each speaker reads the same 69-
More details about these methods are provided in word paragraph that is shown in Example (1).
Section 3.2.
(1) Please call Stella. Ask her to bring these
To investigate the versatility and robustness of
things with her from the store: Six spoons
the various models, we use three different datasets
of fresh snow peas, five thick slabs of blue
for evaluation. The first is identical to the dataset
cheese, and maybe a snack for her brother
used by Wieling et al. (2014b) and Bartelds et al.
Bob. We also need a small plastic snake and
(2020), and includes both acoustic recordings of na-
a big toy frog for the kids. She can scoop
tive and non-native English speakers as well as hu-
these things into three red bags, and we will
man native-likeness judgements to compare against.
go meet her Wednesday at the train station.
The second is a new dataset which focuses on ac-
cented speech from a single group of (Dutch) non- Similar to past work of Wieling et al. (2014b) and
native speakers, for which human native-likeness Bartelds et al. (2020), we use 280 speech sam-
judgements are likewise available. As we would ples from non-native American-English speakers
also like to evaluate the effectiveness of the neural as our target dataset (i.e. the non-native speakers for
models for a different type of data in another lan- whom human native-likeness ratings are available),
guage, we additionally include a dataset with Nor- and 115 speech samples from U.S.-born L1 speak-
wegian dialect pronunciations and corresponding ers as our reference native speaker dataset. As there
human native-likeness ratings. For reproducibility, is much regional variability in the pronunciation
we provide our code via https://github.com/ of the native American-English pronunciations, we
Bartelds/neural-acoustic-distance. use a set of reference speakers (cf. Wieling et al.
To understand the phonetic information captured 2014b) instead of a single reference speaker.Among the 395 English samples from the Earlier work has used this dataset for compar-
Speech Accent Archive, 206 speakers are male and ing dialect differences on the basis of the Leven-
189 speakers are female. From these speakers, 71 shtein distance (Gooskens and Heeringa, 2004) and
male and 44 female speakers belong to the native formant-based acoustic features (Heeringa et al.,
speaker (reference) set. The average age of the 2009) to human perceptual dialect differences. We
speakers in the entire dataset is 32.6 years (σ = included this dataset and the perceptual ratings
13.5). Non-native speakers have an average age from Gooskens and Heeringa (2004) to specifically
of onset for learning English of 10.5 years (σ = investigate whether the self-supervised neural mod-
6.6). The 280 non-native American-English speak- els (even though these are, except for XLSR, based
ers have a total of 99 different native languages, on the English language) are able to model differ-
with Spanish (N = 17), French (N = 13), and ences for languages other than English.
Arabic (N = 12) occurring most frequently. The speakers in this dataset all read aloud 58
The Dutch speakers dataset includes recordings words from the fable ‘The North Wind and the
of native speakers of Dutch (with no other native Sun’. The recordings were segmented in 58 sam-
languages) that all read the first two sentences of ples corresponding to the words from the fable. For
the same elicitation paragraph used for the Speech five dialects, one or two words were missing, as
Accent Archive. These recordings were collected speakers were not always perfectly reading the text.
at a science event held at the Dutch music festival Phonetic transcriptions, which we use as input for
Lowlands, where Offrede et al. (2020) investigated the Levenshtein distance algorithm, were created
the influence of alcohol on speech production in a by a single transcriber. The text, recordings, pho-
native and non-native language. While the effect of netic transcriptions, and transcription conventions
alcohol on the pronunciation in the non-native lan- are available online.1
guage (English) was limited, we nevertheless only
2.2 Human accent and dialect difference
included the speech samples of all 62 sober partici-
ratings
pants (30 male and 32 female speakers). The aver-
age age of the speakers in this dataset is 33.4 years Human accent ratings are widely used to eval-
(σ = 10.3). The average age of onset for learning uate accentedness in speech (Koster and Koet,
English was not obtained, but generally Dutch chil- 1993; Munro, 1995; Magen, 1998; Munro and
dren are exposed to English at an early age (i.e. the Derwing, 2001). Similarly, human ratings have
subject is mandatory in primary schools from the been used to determine how different dialects are
age of about 10 to 11 onwards, but children are from each other (Gooskens and Heeringa, 2004).
usually exposed to English much earlier via mass To evaluate our method, we report Pearson’s cor-
media). relation between the computed acoustic (or pho-
For each speaker in this dataset, we phonetically netic transcription-based) differences and the aver-
transcribed the pronunciations according to the aged human accent (or dialect difference) ratings.
International Phonetic Alphabet. These phonetic While we evaluated read as opposed to spontaneous
transcriptions were created by a single transcriber speech, Munro and Derwing (1994) found that hu-
(matching the conventions used by Wieling et al. man accent ratings are not different for the two
2014b), and used to obtain the transcription-based types of speech.
pronunciation distances (i.e. for comparison with 2.2.1 Non-native American-English
the acoustic methods).
The perceptual data for the Speech Accent Archive
2.1.2 Norwegian speech samples were collected by Wieling et al.
This dataset consists of 15 recordings and pho- (2014b). Native U.S.-born speakers of English
netic transcriptions from Norwegian dialect speak- were invited to rate the accent strength of a set
ers from 15 dialect areas (4 male and 11 female of (at most) 50 samples through an online question-
speakers). The average age of these speakers is naire. Accent strength ratings were given using a
30.5 years (σ = 11). Moreover, each speaker lived 7-point Likert scale ranging from 1 (very foreign
in the place where their dialect was spoken until the sounding) to 7 (native English speaking abilities).
mean age of 20 years, and all speakers estimated While each speech sample contained the entire 69-
that their pronunciations were representative of the word paragraph (average duration of the samples
1
dialect they speak. https://www.hf.ntnu.no/nos/.was 26.2 seconds), participants were allowed to pro- mally dissimilar from the rater’s own dialect. The
vide their rating without having listened to the full average duration of the speech samples was about
sample. In total, the ratings of 1,143 participants 31 seconds.
were collected (57.6% male and 42.4% female) for On average, each group consisted of 19 listeners
a total of 286 speech samples, where each partic- (48% male and 52% female) with a mean age of
ipant on average rated 41 speech samples (σ = 17.8 years. For the majority of their life (16.7 years,
14). The average amount of ratings per sample on average), raters had lived in the place where
was 157 (σ = 71). The mean age of the partici- their dialect was spoken. Only 3% of the raters
pants was 36.2 years (σ = 13.9), and they most reported to never speak in their local dialect. About
frequently lived in California (13.2%), New York 81% of the raters reported to use their dialect often
(10.1%), and Massachusetts (5.9%). From the 286 or always. The consistency of the ratings was not
samples, six were from native American-English reported by Gooskens and Heeringa (2004).
speakers. These were also identified as such, as
their average ratings ranged between 6.79 and 6.97 3 Methods
(0.22 ≤ σ ≤ 0.52).
3.1 Self-supervised neural models
Human accent ratings of the second (Dutch
speakers) dataset were provided by a different We compare and evaluate five self-supervised pre-
group of U.S.-born L1 speakers of English (Of- trained neural models (i.e. w2v, vqw2v, w2v2,
frede et al., 2020). In this case, a questionnaire XLSR, and DeCoAR). The self-supervised neural
was created in which participants rated the accent models have learned representations of acoustic
strength of the speech samples on a 5-point Likert recordings by training the models to predict up-
scale ranging from 1 (very foreign-sounding) to coming speech frames, without using labeled data
5 (native English speaking abilities). Participants (Schneider et al., 2019; Ling et al., 2020; Baevski
were not required to listen to the complete sample et al., 2020a,b). An important characteristic of
(average duration: 18.7 seconds) before providing these deep learning models is that they contain mul-
their rating. A total of 115 participants (73.0% tiple hidden layers containing information about
male, 25.2% female, and 1.8% other) rated an av- the underlying data. Architectures and training
erage of 17 speech samples each (σ = 9.2). On techniques of these models have typically been in-
average, each sample received 24 ratings (σ = 6.7). spired by successful methods in natural language
The mean age of the participating raters was 47.9 processing such as word2vec (Mikolov et al.,
years (σ = 16). The participants most often origi- 2013), ELMo (Peters et al., 2018), and BERT (De-
nated from California (13.9%), New York (10.4%), vlin et al., 2019).
and Pennsylvania (8.7%). As the samples were All of the evaluated acoustic models, except
shorter than for the Speech Accent Archive, a less XLSR, were pre-trained on the large unlabeled Lib-
fine-grained rating scale was used. rispeech dataset, which contains 960 hours of En-
The consistency of the ratings was assessed us- glish speech obtained from audio books (LS960).
ing Cronbach’s alpha (Cronbach, 1951). For both This dataset is divided into two parts, namely a
studies, the ratings were consistent, with alpha val- part which includes clean data (460 hours), and a
ues of 0.85 and 0.92 for the Speech Accent Archive part which includes noisy data (500 hours). Speak-
dataset and Dutch speakers dataset, respectively ers with accents closest to American-English (rep-
(Nunnally, 1978). resented by pronunciations from the Wall Street
Journal-based CSR corpus (SI-84) described by
2.2.2 Norwegian Paul and Baker 1992) were included in the clean
Gooskens and Heeringa (2004) carried out a listen- data part, while the noisy data part contained
ing experiment using the recordings of the Norwe- accents that were more distant from American-
gian dataset. A total of 15 groups of raters (high English (Panayotov et al., 2015). The XLSR model,
school pupils, one group per dialect area) were instead, was trained on 56,000 hours of speech
asked to judge each speaker on a 10-point scale. from a total of 53 languages, including European,
A score of 1 was given when the pronunciation Asian, and African languages. Note that the major-
of the speaker was perceived to be similar to the ity of the pre-training data for XLSR still consists
rater’s own dialect, while a score of 10 indicated of English speech (44,000 hours).
that the pronunciation of the speaker was maxi- In addition to the pre-trained model variants,there are fine-tuned variants available for the w2v2 3.2.1 Phonetic transcription-based distance
and XLSR models. These models were fine-tuned calculation
on labeled data in a specific language to improve The phonetic transcription-based distances are de-
their performance on speech recognition tasks. termined on the basis of the adjusted Levenshtein
However, the process of fine-tuning might have distance algorithm proposed by Wieling et al.
influenced the linguistic representations that are (2012). The Levenshtein algorithm determines the
learned during pre-training. We therefore also in- cost of changing one phonetically transcribed pro-
clude these fine-tuned model variants in our eval- nunciation into another by counting the minimum
uation. For English, we evaluate the w2v2 model amount of insertions, deletions, and substitutions
that has been fine-tuned on 960 hours of English (Levenshtein, 1966). The adjustment proposed by
speech data (subsequently denoted by w2v2-en), Wieling et al. (2012) extends the standard Leven-
and the XLSR model that was fine-tuned on 1,686 shtein distance by incorporating sensitive segment
hours of English speech data (further denoted by differences (rather than the binary distinction of
XLSR-en). The w2v2-en model was chosen be- same vs. different) based on pointwise mutual infor-
cause it is the largest fine-tuned English model mation (PMI) (Church and Hanks, 1990). This data-
available, and Baevski et al. (2020b) showed that driven method assigns lower costs to sound seg-
increasing the model size improved performance ments that frequently occur together, while higher
on all evaluated speech recognition tasks. For Nor- costs are assigned to pairs of segments that occur
wegian, we included the XLSR model fine-tuned infrequently together. These sensitive sound seg-
on 12 hours of Swedish (which was the closest ment differences are subsequently incorporated in
language available to Norwegian with a fine-tuned the Levenshtein distance algorithm. An example
model available; further denoted by XLSR-sv). of a PMI-based Levenshtein alignment for two pro-
The effectiveness of these self-supervised neu- nunciations of the word “afternoon” is shown in
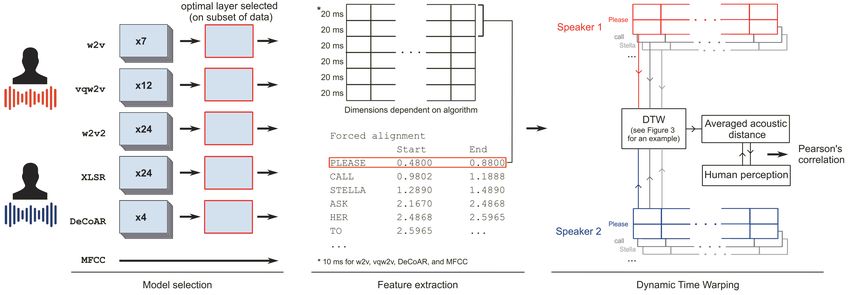
ral models was originally evaluated by using the Figure 1.
learned representations for the task of automatic
æ @ f t @ n 0 n
speech recognition. However, in this study we
æ f t @ r n u n
assess whether or not these acoustic models also
.031 .030 .020
capture fine-grained information such as pronunci-
ation variation. As the investigated algorithms use Figure 1: PMI-based Levenshtein alignment for two
multiple hidden layers to model the acoustic signal, different pronunciations of the word “afternoon”. The
we also evaluate (using a development set) which total transcription-based pronunciation distance be-
layers are most suitable for our specific task. More tween the two pronunciations equals the sum of the
information about these and other aspects of the costs of all edit operations (i.e. 0.081).
models can be found in Appendix A.1 and A.2.
To obtain reliable segment distances using the
PMI-based Levenshtein distance algorithm, it is
beneficial if the number of words and segments is
3.2 Existing methods
as large as possible. As the Dutch speakers dataset
is relatively small, we instead used the sensitive
For comparison with the self-supervised neural segment differences obtained on the basis of the
models, we also report the results on the basis (larger) Speech Accent Archive dataset (i.e. the
of two existing approaches for quantifying pro- same as those used by Wieling et al., 2014b).
nunciation differences, namely the MFCC-based After the Levenshtein distance algorithm (in-
approach of Bartelds et al. (2020) and the pho- corporating sensitive sound differences) is used
netic transcription-based approach of Wieling et al. to quantify the pronunciation difference between
(2012). Both methods are currently the best- each word for a pair of speakers, the pronunciation
performing automatic (acoustic- or transcription- difference between two speakers is subsequently
based) algorithms for determining pronunciation determined by averaging all word-based pronun-
differences that match human perceptual pronunci- ciation differences. Additionally, for the two En-
ation differences well, and are explained in more glish datasets, the difference between the pronunci-
detail below. ation of a non-native speaker and native (American-English) speech (i.e. the non-native-likeness) is cally, we investigated for each neural model which
computed by averaging the pronunciation differ- layer performed best for our task, by evaluating
ence between the non-native speaker and a large the performance (i.e. the correlation with human
set of native English speakers (the same for both ratings) using a held-out development set (25%
datasets). of the data of the Speech Accent Archive dataset,
and 50% of the data of the much smaller Dutch
3.2.2 MFCC-based acoustic distance speaker dataset). As layers sometimes show very
calculation similar performance, we also evaluated which lay-
For the Speech Accent Archive recordings, the ers showed significant lower performance than the
MFCC-based differences between the individual best-performing layer. For this, we used the mod-
non-native speakers and native English speakers ified z-statistic of Steiger (1980) for comparing
were available from Bartelds et al. (2020). For dependent correlations. After selecting the best-
the native Dutch speakers dataset, and the Nor- performing layer, the performance is evaluated on
wegian dataset, we calculate these differences fol- the remaining data (and the full dataset, if the pat-
lowing the same approach. In short, this consists terns of the development set and the other data are
of comparing 39-dimensional MFCCs of pronun- similar). Samples are cut into individual words
ciations of the same word (by two speakers) to after embedding extraction using time-alignments
obtain the acoustic difference between the pronun- from the Penn Phonetics Lab Forced Aligner (Yuan
ciations. We use dynamic time warping to com- and Liberman, 2008). For word pairs between a
pare the MFCCs (Giorgino, 2009). This algorithm reference and target speaker, length normalized
is widely used to compare sequences of speech similarity scores between the embeddings are cal-
features by computing the minimum cumulative culated using dynamic time warping.
distance (i.e. the shortest path) through a cost ma- Scores are averaged across all 69 words (Speech
trix that contains the Euclidean distance between Accent Archive dataset) or 34 words (Dutch speak-
every pair of points in the feature representations. ers dataset) to acquire a distance measurement be-
To account for durational differences between the tween a target speaker and a reference speaker. To
pronunciations, we normalize the minimum cumu- compute a single score of distance between a target
lative distance by the length of the feature repre- speaker and native English speech, the distances
sentations. See Bartelds et al. (2020) for more de- between the target speaker and all reference native
tails. Finally, the non-native-likeness is computed speakers are averaged.
in the same way as for the Levenshtein distance We evaluate our algorithms on both datasets by
algorithm, explained in the previous section. calculating the Pearson correlation between the re-
sulting acoustic distances and the averaged human
4 Experimental setup native-likeness judgements for the target samples.
4.1 Non-native American-English Note, however, that the results on the basis of the
pronunciation differences Speech Accent Archive are likely more robust as
this dataset contains a large amount of (longer) sam-
Following Wieling et al. (2014b) and Bartelds et al. ples, a variety of native language backgrounds, and
(2020), we compute a measure of acoustic distance a larger amount of ratings per sample. We visualize
from native English speech by individually com- the complete approach in Figure 2.
paring the non-native target samples from both
datasets to the 115 native reference samples. Neu-
4.2 Norwegian pronunciation differences
ral representations of all samples are acquired by
using the full samples as input to the neural mod- For the Norwegian dataset, we measure acoustic
els. The final output of these neural models should distances by computing neural representations for
correspond with the original input (including all the segmented word samples similar to the ap-
frames), and will therefore not contain any new proach used for the non-native American-English
information. Because of this, we use the feature samples. The selection of the best-performing layer
representations of hidden layers (discussed in Sec- for the neural methods was determined again using
tion 3.1) as acoustic embeddings. These representa- a validation set, containing a random sample of
tions are extracted by doing a forward pass through 50% of the data. Word-based neural representa-
the model up to the target hidden layer. Specifi- tions of the same word are compared using dy-Figure 2: Visualization of the acoustic distance measure where features are extracted using several acoustic-only
methods. The output layer of the models is selected in a validation step. After feature extraction, the samples
are sliced into individual words, which are subsequently compared using dynamic time warping. The word-based
acoustic distances are then averaged and compared to human perception.
namic time warping to obtain similarity scores, U.S. (Boberg, 2010). Third, as the gender distri-
which are length normalized. These are subse- bution between the native and non-native speakers
quently averaged to obtain a single distance mea- differed for our reference speaker set compared to
sure between two dialects (i.e. two speakers). the set of non-native speakers, we investigate the
We evaluate our algorithms on the Norwegian influence of gender by restricting the reference set
dialects dataset by computing the Pearson correla- to a single gender.
tion between the acoustic distances and perception Finally, while the correlations are determined on
scores provided by the dialect speakers, and com- the basis of an average over 69 words, we are also
pare this value to the correlation obtained by using interested in the performance when only individual
phonetic transcription-based distances and MFCC- words are selected. This analysis may reveal which
based distances instead of the self-supervised neu- words are particularly informative when determin-
ral acoustic-only distances. As Gooskens and ing non-native-likeness.
Heeringa (2004) found that dialect distances with
respect to themselves erroneously increased the cor- 4.4 Understanding representations
relation with the perceptual distances, we excluded To obtain a better understanding of the acous-
these distances from our analysis. tic properties to which our final best-performing
neural acoustic distance measure is sensitive, we
4.3 Influence of sample conduct several additional experiments using the
To obtain a better understanding of the influence of Speech Accent Archive recordings. We first evalu-
our reference sample, and the specific set of words ate how well the models are able to capture varia-
on our results, we conduct several additional exper- tion in specific groups of non-native speakers. By
iments on the (larger) Speech Accent Archive non- restricting the background (i.e. the native language)
native English dataset using our best-performing and thereby creating a more homogeneous sam-
model. ple (similar to the Dutch speakers dataset), human
First, we investigate the effect of choosing a accent ratings may lie closer together. Strong cor-
single reference speaker, as opposed to using the relations between human perception and acoustic
reference set of all 115 speakers. Second, we fur- distances when the range of scores is large (as in the
ther examine the effect of speaker backgrounds full dataset), may not necessarily also imply strong
on the correlation with human perception, by re- correlations when there is less variation. Conse-
stricting the set of reference native speakers to quently, this experiment, together with the analysis
speakers from the western half of the U.S. and of the Dutch speakers data, investigates whether or
the English-speaking part of Canada. We opt for not our models also model human perception at a
this set, as these areas are characterized by less more fine-grained level.
dialect variation compared to the eastern half of the In addition, to understand whether the acousticdistances comprise (linguistically relevant) aspects
11
of pronunciation different from pronunciation dis-
distance per frame
tances computed using MFCCs or phonetic tran- 10
scriptions, we fit multiple linear regression mod- 9
els. In those models, human accent ratings are pre-
dicted based on the acoustic distances of our best- 8
performing self-supervised neural model, MFCC- 7
based acoustic distances (Bartelds et al., 2020), and
6
phonetic transcription-based differences (Wieling 0 200 400 600 800 1000
et al., 2014b). We evaluate the contribution of each time (ms)
predictor to the model fit, and assess the model’s
Figure 3: Visualization of neural acoustic distances
explained variance to determine whether distinctive per frame (based on w2v2) with the pronunciation of
aspects of pronunciation are captured. /hy:d/ on the x-axis and distances to the pronunciation
Finally, Bartelds et al. (2020) found that acoustic of /ho:d/ on the y-axis. The horizontal line represents
distances computed by using MFCCs not only cap- the global distance value (i.e. the average of all indi-
tured segmental differences, but also intonational vidual frames). The blue continuous line represents
and durational differences between acoustically al- the moving average distance based on 9 frames, cor-
tered pronunciations of the same word. To assess responding to 180ms. As a result of the moving aver-
age, the blue line does not cover the entire duration of
whether this information is captured by our best-
the sample. Larger bullet sizes indicate that multiple
performing neural method as well, we replicate the frames in /ho:d/ are aligned to a single frame in /hy:d/.
experiment of Bartelds et al. (2020). Specifically,
we compute acoustic distances between four series
of recordings of the word “living” (ten repetitions
per series) and compare the acoustic distances to pronunciation of a Dutch speaker pronouncing the
those computed using MFCCs. The first two series two non-words /hy:d/ vs. /ho:d/. This example illus-
of recordings were unmodified but recorded with a trates the relative influence of different phonemes
different recording device (the built-in microphone on the acoustic distance within a word. The dif-
of a laptop, versus the built-in microphone of a ference between the two pronunciations is lowest
smartphone). The third and fourth series were ma- in the beginning of the word (/h/), whereas it is
nipulated by changing the intonation (“living?”) highest in the middle part (comparing [y:] and [o:]).
and relative duration of the first syllable (“li:ving”), The difference at the end (i.e. /d/) is higher than
respectively. To illustrate the results of this ex- at the beginning (for /h/), which may reflect perse-
periment, we have developed a visualization tool, verative coarticulation, despite the transcriptions
which is discussed below and may help understand being identical. An online demo of this visualiza-
whether or not our best-performing (black box) neu- tion tool can be used to generate similar figures for
ral method is able to distinguish aspects of speech any pair of recorded pronunciations.2
that are linguistically relevant from those that are
not. 5 Results
4.4.1 Visualization tool
For this study, we have developed a tool that visu- We first report on the performance of the non-native
alizes the dynamic time warping alignments and American-English speakers from the Speech Ac-
the corresponding alignment costs to highlight cent Archive and Dutch speakers dataset. Subse-
where in the acoustic signal the differences be- quently, we present the results on the Norwegian
tween two pronunciations of the same word is most dataset to show how the self-supervised models per-
pronounced. As such, this tool may be helpful form on a language different from English. Finally,
for interpreting the acoustic distances returned by we discuss the phonetic information encoded in
our models, for example by highlighting that the the pre-trained representations using visualizations
acoustic differences between two pronunciations of the acoustic distances, and report on the results
are most divergent at the end (or start) of a word. from our additional experiments.
An illustration of the output (and interpretation) of
2
this tool is shown in Figure 3, which compares the https://bit.ly/visualization-tool5.1 Non-native American-English For the neural models, the numbers between
pronunciation differences parentheses show the best-performing layer (on
the basis of the performance on the validation set).
Table 1 shows the correlations between the non-
As an example of how individual layers may show
native-likeness scores and the average human
a different performance, Figure 4 shows the per-
native-likeness ratings for both datasets. The
formance for each layer for the best-performing
modified z-statistic of Steiger (1980) shows that
w2v2-en model applied to the Speech Accent
the w2v2-en model significantly outperforms all
Archive dataset. It is clear that rather than selecting
other models (including the Levenshtein distance
the final layer, the performance of an intermediate
approach, which was already reported to match hu-
layer (10) is highest (and not significantly different
man perception well; Wieling et al., 2014b) when
from the performance of layers 8 to 11). Further-
applied to the Speech Accent Archive dataset (all
more, there is a close match between the observed
z’s > 3, all p’s < 0.001). Similarly, for the Dutch
pattern for both the validation set and the test set.
speakers dataset, the w2v2-en is also the best-
Appendix A.2 shows these graphs for all neural
performing model. In this case, it significantly
models and datasets.
improved over w2v, vqw2v, DeCoAR, XLSR, and
MFCC (all z’s > 3, all p’s < 0.001), but not over 1.0
the other approaches (p > 0.05). 0.8
correlation 0.6
Model SAA DSD
0.4
w2v (7, 5) -0.69 -0.25
25% validation set
vqw2v (11, 10) -0.78 -0.67 0.2 75% test set
w2v2 (17, 12) -0.85 -0.70 0.0 all samples
XLSR3 (16, 16) -0.81 -0.47
DeCoAR (2, 4) -0.62 -0.40 0 2 4 6 8 10 12 14 16 18 20 22 24
layer
w2v2-en (10, 9) -0.87 -0.71
XLSR-en3 (8, 9) -0.81 -0.63 Figure 4: Pearson correlation coefficients of acoustic
distances compared to human accent ratings for differ-
LD (Wieling et al., 2014b) -0.77 -0.70 ent Transformer layers in the w2v2-en model. The
MFCC (Bartelds et al., 2020) -0.71 -0.34 vertical line marks the layer that was chosen as the best-
performing layer based on the 25% validation set of the
Table 1: Pearson correlation coefficients r between Speech Accent Archive dataset. Layers with a correla-
acoustic-only or phonetic transcription-based distances tion that is not significantly different (p > 0.05) from
and human native-likeness ratings, using w2v, vqw2v, the optimal layer are indicated by the thick red line.
w2v2, XLSR, w2v2-en, XLSR-en, DeCoAR, the
PMI-based Levenshtein distance (LD), and MFCCs
to compute distances on the Speech Accent Archive
5.2 Norwegian pronunciation differences
(SAA) dataset and native Dutch speakers dataset
(DSD). All correlations are significant at the p < 0.001 Table 2 shows the results for the Norwegian di-
level. The values between parentheses show the se- alects dataset. In this experiment, we only include
lected layers of the neural models on the basis of neural representations from the best-performing
the 25% validation set for the Speech Accent Archive fine-tuned monolingual English and multilingual
dataset and the 50% validation set for the Dutch speak-
model in the previous section (i.e. w2v2-en and
ers dataset, respectively.
XLSR-sv as Swedish is more similar to Norwe-
gian than English). Unfortunately, there is no
3
We also computed correlation coefficients using the most
monolingual Norwegian model available. In this
recent XLS-R model (Babu et al., 2021), which is pre-trained case, the performance of the PMI-based Leven-
on 436,000 hours of speech in 128 languages. To directly shtein distance is substantially (and significantly:
compare the results to XLSR and XLSR-en, we used the
pre-trained model with the same number of parameters and all z’s > 3, all p’s < 0.001) higher than both of
fine-tuned this model on English labeled data available in the the neural methods (which did not differ from each
Common Voice dataset. However, the results of these newer other in terms of performance, but were improve
models are not significantly better (p > 0.05) from the results
obtained using XLSR and XLSR-en. We therefore report over the MFCC approach; z > 3, p < 0.001).
those latter results. Note that the correlations are positive, as higherperceptual ratings reflected more different dialects. −0.87 (p < 0.001) and r = −0.87 (p < 0.001),
respectively.
Model Mean r Finally, we calculated the correlation with hu-
w2v2-en (3) 0.49 man perception using w2v2-en when instead
XLSR-sv4 (7) 0.49 of the full 69-word paragraph individual words
were selected. These correlations ranged from
LD (Wieling et al., 2014b) 0.66 r = −0.50 for the word “She” to r = −0.78 for
MFCC (Bartelds et al., 2020) 0.22 the word “Stella”. The average correlation was
r = −0.67 (p < 0.001, σ = 0.06). While the
Table 2: Pearson correlation coefficients r between results on the basis of the full dataset show a higher
acoustic-only or phonetic transcription-based distances
correlation with human perception, it is noteworthy
and human native-likeness ratings, using w2v2-en,
XLSR-sv, the PMI-based Levenshtein distance (LD), that some individual words also appear to correlate
and MFCCs for computing pronunciation distances for strongly with perception.
the Norwegian dialect dataset. All correlations are sig-
nificant at the p < 0.001 level. The values between 5.4 Understanding representations
parentheses show the selected layers of the neural mod-
els on the basis of the 50% validation set. To assess whether our best-performing model can
also identify more fine-grained differences, we eval-
uate the model against several subsets of data con-
5.3 Influence of sample sisting of non-native speakers from the same na-
In this section, we report on the influence of the tive language background. The spread in native-
specific sample of reference speakers and the in- likeness ratings, as well as the correlations for the
cluded words across which we averaged. Table 3 groups with the largest number of speakers are
reveals the influence of our specific sample of refer- shown in Figure 5. Except for the native speak-
ence speakers by showing the averaged correlation ers of German (with a relatively restricted range in
coefficients (and the associated standard deviation) native-likeness ratings), we observe strong correla-
for the various methods applied to the Speech Ac- tions for all groups of speakers.
cent Archive dataset. Instead of using the full set of The low correlation for German speakers sug-
115 native speakers as reference set, in this analysis gests that a restricted range of native-likeness rat-
each individual native speaker was used once as ings may negatively affect the correlation with hu-
the single reference speaker. Particularly of note man perceptual ratings. However, subsequent ex-
is that only w2v2, XLSR and their fine-tuned vari- periments using w2v2-en (not shown) revealed
ants, as well as the PMI-based Levenshtein distance that the correlation when only including speakers
appear to be minimally influenced by individual who received average native-likeness ratings be-
reference speaker differences (i.e. reflected by the tween (e.g.,) 5 and 6 was not lower than when
low standard deviations). Specifically, w2v2 and increasing the range to include all speakers who
w2v2-en yield the lowest standard deviations as received average native-likeness ratings between
well as the highest correlation ranges for individual (e.g.,) 3 and 6.
reference speakers. To identify whether the acoustic distances com-
Additionally, we computed the correlation puted using w2v2-en capture additional pronun-
coefficient using our best-performing model ciation characteristics compared to acoustic dis-
(i.e. w2v2-en) based solely on including refer- tances based on MFCCs or phonetic transcription-
ence native speakers from the western half of the based distances, we fitted a multiple regression
U.S. and the English-speaking part of Canada. The model predicting the human native-likeness ratings
resulting correlation of r = −0.87 (p < 0.001) of the Speech Accent Archive dataset. Table 4
was identical to the correlation when including all shows the estimated coefficients (for standardized
reference speakers. The results were also simi- predictors), and summarizes the fit of the regres-
lar when the reference speaker set was restricted sion model. Acoustic distances computed using
to only men or women, with correlations of r = w2v2-en and phonetic transcription-based dis-
4
tances calculated by the PMI-based Levenshtein
When using XLS-R fine-tuned on Swedish labeled data
from the Common Voice dataset, the correlation coefficient is distance both contribute significantly to the model
not significantly different (p > 0.05) from XLSR-sv. fit (p < 0.05), whereas this is not the case forModel Mean r Std. Dev. Range
w2v (7) -0.57 0.11 [-0.14, -0.73]
vqw2v (11) -0.69 0.08 [-0.16, -0.79]
w2v2 (17) -0.83 0.02 [-0.73, -0.86]
XLSR (16) -0.76 0.05 [-0.47, -0.83]
DeCoAR (2) -0.49 0.08 [-0.22, -0.67]
w2v2-en (10) -0.86 0.01 [-0.79, -0.88]
XLSR-en (8) -0.78 0.04 [-0.53, -0.83]
LD (Wieling et al., 2014b) -0.74 0.04 [-0.52, -0.79]
MFCC (Bartelds et al., 2020) -0.45 0.10 [-0.20, -0.69]
Table 3: Averaged Pearson correlation coefficients r, with standard deviations and correlation ranges, between
acoustic-only or phonetic transcription-based distances and human native-likeness ratings applied to the Speech
Accent Archive dataset, using w2v, vqw2v, w2v2 (pre-trained and fine-tuned), XLSR (pre-trained and fine-tuned),
DeCoAR, the PMI-based Levenshtein distance (LD), and MFCCs to compute distances when individual U.S.-born
native American-English speakers were treated as the single reference speaker. All correlation coefficients are
significant at the p < 0.001 level. The values between parentheses show the selected layer of the neural models on
the basis of the validation set.
r = -0.90 r = -0.94 r = -0.86 r = -0.54 r = -0.91
8 provide some (limited) additional information over
Perceived native-likeness
the self-supervised neural models.
6
Table 5 shows how acoustic distances on the
4
basis of the MFCC approach and the w2v2-en
2 model are affected by intonation and timing differ-
ences, as well as by recording device. For each con-
0
dition, ten repetitions were recorded. The record-
Spanish French Arabic German Portuguese ings are the same as those used by Bartelds et al.
(17) (13) (12) (9) (9) (2020). To enable a better comparison, however,
L1
all obtained distances are scaled between 0 and
Figure 5: Violin plots visualizing the spread in native- 1. It is clear that the averaged distances from the
likeness ratings for speakers of different native lan- repetitions of the same word (which may have
guages. The number of speakers is indicated between differed slightly) are somewhat smaller for the
parentheses below the language. The correlation for w2v2-en model than for the MFCC approach.
each group is indicated above each violin plot. Importantly, whereas the MFCC approach does
not cope well with a different recording device,
the w2v2-en model appears to be much more ro-
the MFCC-based distances. The contribution of bust (i.e. resulting in values closer to those for the
w2v2-en is strongest as is clear from the standard- normal pronunciation). Interestingly, whereas the
ized estimates. Overall, this model accounts for MFCC approach appears to find larger differences
77% of the variation in the human native-likeness between recordings differing in intonation com-
assessments. A model fitted exclusively on the ba- pared to those with a lengthened first syllable, this
sis of the phonetic transcription-based distances is opposite for the w2v2-en model. Both meth-
explains 60% of the variation in the human native- ods, however, appear to be sensitive to differences
likeness ratings. Given that a model fitted exclu- regarding these aspects.
sively on the basis of the w2v2-en-based dis- For illustration, Figure 6 visualizes a compari-
tances explains 76% of the variation in the human son between a single normal pronunciation of “liv-
native-likeness ratings, these self-supervised neu- ing” and four other pronunciations. Specifically,
ral models capture information that is not captured Figure 6a shows a comparison with another nor-
by phonetic transcriptions. Nevertheless, the ab- mal pronunciation. Figure 6b shows a comparison
stractions provided by phonetic transcriptions do with the same pronunciation, but using a differentEstimate (in z) Std. Error t-value p-value
(Intercept) 2.98 0.03 86.56 < 0.001
LD (Wieling et al., 2014b) -0.15 0.06 -2.35 < 0.05
MFCC (Bartelds et al., 2020) 0.08 0.06 1.33 0.18
w2v2-en -0.98 0.08 -11.75 < 0.001
Table 4: Coefficients of a multiple regression model (R2 = 0.77) predicting human native-likeness judgements on
the basis of phonetic transcription-based distances computed with the PMI-based Levenshtein distance (LD), and
acoustic-only distances based on MFCCs and w2v2-en.
w2v2-en MFCC
Normal pronunciation 0.18 (0.10) 0.23 (0.13)
Normal pronunciation (different recording device) 0.29 (0.08) 0.88 (0.04)
Rising intonation 0.61 (0.07) 0.92 (0.03)
Lengthened first syllable 0.91 (0.05) 0.80 (0.03)
Table 5: Normalized averaged acoustic distances of four variants of the word “living” (each repeated ten times)
compared to the normal pronunciation of “living”, computed using w2v2-en and MFCCs. Standard deviations
are shown between parentheses.
recording device. Figure 6c shows a comparison of native-likeness or perceived dialect distance.
with a rising intonation pronunciation. Finally, Fig- Our experiments showed that acoustic distances
ure 6d shows a comparison with a lengthened first computed with Transformer-based models, such
syllable pronunciation. In line with Table 5, the as w2v2-en, closely match the averaged human
values on the y-axis show that the distance between native-likeness ratings for the English datasets, and
the two normal pronunciations is smaller than when that performance greatly depended on the choice
using a different recording device. Note that these of layer. This finding not only demonstrates that
distances were not normalized, as they simply com- these layers contain useful abstractions and gener-
pare two recordings. Both distances, however, are alizations of acoustic information, but also shows
smaller than comparing against rising intonation that the final layers represent information that is
(revealing a curvilinear pattern) and a lengthened tailored to the target objective (which was speech
first syllable (showing the largest difference at the recognition instead of our present goal of quantify-
beginning of the word; the lengthening is clear ing acoustic differences). This result is in line with
from the larger circle denoting an alignment with findings in the field of natural language process-
similar samples differing in duration). ing when using Transformer-based methods with
textual data (Tenney et al., 2019; de Vries et al.,
6 Discussion and conclusion 2020). Furthermore, the w2v2 and XLSR models
appeared to be robust against the choice of refer-
In this study, we investigated how several self- ence speaker(s) to compare against. Even choosing
supervised neural models may be used to auto- a single reference speaker resulted in correlations
matically quantify pronunciation variation with- that were not substantially different from those that
out needing to use phonetic transcription-based used the full set. Interestingly, correlations on the
approaches. We used neural representations to cal- basis of some words were not much lower than
culate word-based pronunciation differences for those on the basis of the full set of words, suggest-
English accents and Norwegian dialects, and com- ing that a smaller number of words may already
pared the results to human perceptual judgements. yield an adequate assessment of native-likeness.
While these ratings were provided on relatively
crude (5 to 10-point) scales, and individual raters’ Our newly-developed visualization tool helped
biases or strategies may have affected their rat- us to understand these ‘black box’ models, as the vi-
ings, averaging across a large number of raters sualization showed where the differences between
for each sample likely yields an adequate estimate two pronunciations were largest (i.e. the locus ofdistance per frame 6.5 10
distance per frame
6.0 9
5.5 8
5.0 7
4.5 6
4.0 5
0 100 200 300 400 500 600 0 100 200 300 400 500 600
time (ms) time (ms)
(a) Normal pronunciation (b) Different recording device
14 20
18
distance per frame
distance per frame
12 16
14
10 12
10
8
8
6
0 100 200 300 400 500 600 0 100 200 300 400 500 600
time (ms) time (ms)
(c) Rising intonation (d) Lengthened first syllable
Figure 6: Visualization of neural acoustic distances per frame (based on w2v2-en) comparing each of the four
variants of “living” to the same normal pronunciation. The horizontal line represents the global distance value
(i.e. the average of all individual frames). The blue continuous line represents the moving average distance based
on 9 frames, corresponding to 180ms. As a result of the moving average, the blue line does not cover the entire
duration of the sample. Larger bullet sizes indicate that multiple frames in the reference normal pronunciation
are aligned to a single frame in the variant of “living” listed on the x-axis. Note the different scales of the y-axis,
reflecting larger differences for the bottom two graphs compared to the top two graphs. See the text for further
details.
the effect). This type of tool could potentially be hard to capture by a set of discrete symbols used in
used to provide visual feedback to learners of a phonetic transcriptions. Importantly, in contrast to
second language or people with a speech disorder. a previous relatively successful acoustic approach
However, the actual effectiveness of such an ap- (Bartelds et al., 2020), our present neural acoustic
proach would need to be investigated. approach is relatively unaffected by non-linguistic
Our results seem to indicate that phonetic tran- variation (i.e. caused by using a different recording
scriptions are no longer essential when the goal is device). Nevertheless, further detailed research is
to use these to quantify how different non-native needed to obtain a better view of what phonetic
speech is from native speech, and an appropriate information is (not) captured by these models.
Transformer-based model is available. This sug- In contrast to the performance on the English
gests that a time-consuming and labor intensive datasets, we found that Transformer-based neural
process can be omitted in this case. While our representations performed worse when applied to
regression model showed that phonetic transcrip- the Norwegian dialects dataset. However, pronun-
tions did offer additional information not present in ciations of the Norwegian dialects dataset were rep-
our neural acoustic-only approach, this information resented by a model which was trained exclusively
gain was very limited (an increase in R2 of only one or dominantly on English speech. Unfortunately,
percent). We furthermore showed that our neural Norwegian was not among the pre-training lan-
method captures aspects of pronunciations (such as guages included in the multilingual (XLSR) model,
subtle durational or intonation differences) that are nor available for fine-tuning. We expect to see im-You can also read

















































