Automatic Generation of German Drama Texts Using Fine Tuned GPT-2 Models
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Automatic Generation of German Drama Texts
Using Fine Tuned GPT-2 Models
Mariam Bangura, Kristina Barabashova, Anna Karnysheva, Sarah Semczuk, Yifan Wang
Universität des Saarlandes
{maba00008, krba00001, anka00001, s8sasemc, yiwa00003}@stud.uni-saarland.de
7009604, 7023878, 7010958, 2573377, 7023035
Abstract drama generation. The approaches considered in
This study is devoted to the automatic gen-
our study are mentioned in Section 2.
eration of German drama texts. We suggest Nowadays, some of the most advanced methods
an approach consisting of two key steps: fine- for text generation comprise transformer decoder or
arXiv:2301.03119v2 [cs.CL] 10 Jan 2023
tuning a GPT-2 model (the outline model) to encoder-decoder architecture pre-trained on large-
generate outlines of scenes based on keywords scale unsupervised texts. In previous study refer-
and fine-tuning a second model (the generation ring to drama generation, GPT-2 is applied (Rosa
model) to generate scenes from the scene out- et al., 2021). In the current study, we propose an
line. The input for the neural model comprises
approach to the generation of drama texts in Ger-
two datasets: the German Drama Corpus (Ger-
DraCor) and German Text Archive (Deutsches man, based on the production of outlines (Fan et al.,
Textarchiv or DTA). In order to estimate the ef- 2018; Yao et al., 2018), and compare it with two
fectiveness of the proposed method, our mod- baseline GPT-2 models. The detailed information
els are compared with baseline GPT-2 models. about these models and their comparison can be
Our models perform well according to auto- found in Section 4. The datasets, used as training
matic quantitative evaluation, but, conversely, materials for the system, are described in Section
manual qualitative analysis reveals a poor qual-
3.
ity of generated texts. This may be due to the
quality of the dataset or training inputs. In order to analyze the performance of story gen-
eration models, various evaluation metrics can be
1 Introduction involved (Alabdulkarim et al., 2021). For the mod-
Text generation is a subarea of natural language pro- els represented in the current study, we propose
cessing (NLP), appearing in the 1970s (Goldman, automatic quantitative evaluation along with man-
1974). Its main purpose is the automatic genera- ual qualitative analysis, described in Section 5. The
tion of natural language texts, which can satisfy main challenges and limitation referring to the pro-
particular communicative requirements (Liu and posed approach and ideas for further improvement
Özsu, 2009). Text generation can be a constituent of drama generation are discussed in Section 6.
of AI-based tools related to machine translation, di-
2 Related Work
alogue systems, etc. Computational generation of
stories is specifically challenging task, as it refers Automatic text generation has long been a task
to the problem of selecting a sequence of events or of research interests, and various approaches have
actions that meet a set of criteria and can be told as been proposed to improve the quality of generated
a story (Alhussain and Azmi, 2021). Many studies outputs. Among all genres, story generation sees
focus on automatic story generation (Cheong and the most innovation and progress. Before the era of
Young, 2014), however, a limited number of them deep learning, some structural and planning-based
emphasize drama generation (Rosa et al., 2020). models have been applied to perform story gener-
Dramatic texts differ from other genres by hav- ation. The prevalence of RNN (Rumelhart et al.,
ing dialogues of acting characters, authorial notes, 1986) and LSTM (Hochreiter and Schmidhuber,
scenes, and other specific elements, usually written 1997) motivated researches to introduce deep learn-
for the purpose of being performed on stage (Leth- ing to the field of text generation, which results
bridge and Mildorf, 2004). Therefore, the methods in higher model capacity and better performance.
described in research devoted to generation of nar- Leveraging language models with more complex
ratives or poetry is not always applicable for the architecture and pre-trained on large scale datasetsfurther improved the generation quality by a con- dramas used from GerDraCor. In the corpus, speak-
siderable margin. (Alabdulkarim et al., 2021) ers, stages and sets1 , scenes and acts are annotated.
In addition to the increasing complexity of There is also metadata available for the whole cor-
model architecture, researchers are also committed pus and containing information about number of
to proposing innovative generation schemes. Peng speakers and their sex, number of acts and words,
et al. attempted to steer generation by adding con- etc.
trol factors. They extracted control factors from ex- DTA, hosted by the CLARIN service center at
isting corpora and trained a model conditioned on the Berlin-Brandenburg Academy of Sciences and
them, so that users can control the generation pro- Humanities, is the largest single corpus of his-
cess by selecting different control factors. Fan et al. torical New High German that contains around
(2018, 2019) explored the possibility of a hierarchi- 1500 cross-genre texts from the early 16th to the
cal story generation process, where an intermediate early 20th century. 92 drama texts with an ortho-
stage expands the given prompt and simplifies the graphic normalization of historical spelling were
following generation process by conditioning it on extracted from the corpus. One of them was ex-
expanded prompts. Similarly, Wang et al. (2020) cluded, as it was a poem. All historical spellings
also applied a two-stage story generation scheme, are adopted true to the original, i.e., they are not
where the system additional generates a story out- implicitly modernized. However, modern or oth-
line as a guideline for the second stage. It is shown erwise normalized equivalents of historical writ-
that the hierarchical generation scheme effectively ings may be noted with the tags (histori-
enhances the consistency and coherency of outputs. cal spelling) and (modernized/normalized
Despite the similarities with story generation, spelling) (Deutsches Textarchiv, 2022).
drama generation faces some extra challenges. The standard GerDraCor format and DTA basic
Firstly, a drama play is usually longer than the format (DTABf), which were used in this work,
upper limit of pre-trained language models, thus an follow the P5 guidelines of the Text Encoding Ini-
iterative generative process is necessary. Secondly, tiative (TEI), which are specified for the annotation
the lack of prompt-output data makes it impossible of historical printed works in a corpus (Deutsches
to adopt the same approaches as in story generation, Textarchiv, 2022; Fischer et al., 2019). The TEI
and the model must learn to generate plays from Guidelines for Electronic Text Encoding and In-
nothing. The inherent difficulty of drama genera- terchange determines and document markup lan-
tion task discourages researches in this field. To our guages for the representation of the structural and
best knowledge, the only drama generation model conceptual text features. They refer to a modu-
is THEaiTRE project (Rosa et al., 2020, 2021). The lar, extensible XML schema, consisting of a set
system leverages a GPT-2 model to generate each of markers (or tags) and accompanied by detailed
scene step by step conditioned on both local and documentation, and they are published under an
remote contexts. However, the generative model is open-source license2 .
not fine-tuned on any drama texts, and the genera- The following sections describe how dramas
tion process requires intensive human interference, from aforementioned sources were parsed and pre-
which compromise usability of the model and is processed in Python.
not suitable for amateur users.
3.2 Drama Parsing
3 Drama Preprocessing Parsing of dramas in XML format was performed
3.1 Corpora with XMLHandler class inheriting from Con-
tentHandler class from “xml.sax” module. This
The input for the neural model were dramas from class reads xml-tags and operates with their param-
the German Drama Corpus (GerDraCor) developed eters and/or content between starting and closing
by the Drama Corpora Project (DraCor) (Fischer tags. The class contains methods that were over-
et al., 2019) and German Text Archive (Deutsches written in order to suit the task of parsing dramas
Textarchiv or DTA) (Deutsches Textarchiv, 2022). from both GerDraCor and DTA (Table 1).
GerDraCor consists of 591 German dramas, with
1
the earliest written in the 1640s and the latest in the Stages and sets are texts describing the setting (decora-
tions, position of characters) or commenting on characters’
1940s. 46 dramas appeared to be the same with the actions and manner of speech.
2
ones in DTA and were removed, resulting in 545 https://tei-c.org/Method Parameters Functionality
__init__ output: the empty dictionary that is filled with the - initializes instant variables used for the XML tags
data from processed XML file and processed text
- assigns the empty “output” dictionary to the in-
stance variable
startElement xml_tag: the start xml-tag (of the form) which - stores xml-tag and its attributes in instance variables
is passed to the method from the file
attrs: attributes of the tag
endElement xml_tag: the end xml-tag (of the form) which - stores the text processed between start and end tags
is passed to the method from the file into a specific instance variable
characters content: the text between start and end xml-tags - processes the text by skipping empty lines, tokeniz-
ing text into words at spaces
- normalizes words spelling if needed (in GerDraCor
only)
- stores processed words by adding them into a list
Table 1: XMLHandler Class Structure
The tag passed to “startElement” and “endEle- Eventually, the latter version was used for the fur-
ment” defined how the content between tags should ther model training. Figure 1 shows an example of
be stored. For example, if “startElement” read a drama parsed from GerDraCor with characters’
tag, then the value of the “xml:id” tag was speeches alone.
stored from that as drama id; if a tag “ was
passed to the “endElement”, then it signaled of
the end of the drama, and stored all the previously $id_ger000066
parsed text in a dictionary under the drama id as a ...a
key. The text itself was the content read and written $scene
in “characters” method and could be the speech of b
a particular character between specific opening and $sp_#dalton
closing “speech tags”, or, similarly, a description Ein abscheuliches Unglück – ich kann es nicht
of a stage or a set. Additionally, inside “charac- erzählen – dieser Tag ist der letzte dieses
ters”, text was orthographically normalized: histor- Hauses.
ical spelling of words was replaced with modern @sp_#dalton
spelling, which was looked up in a file containing
obsolete-modern spelling pairs and was produced $sp_#frau_von_wichmann
earlier with a File Comparator (described in detail Dalton – ist es –
in Section 3.3). That was done for GerDraCor ex- @sp_#frau_von_wichmann
clusively, as DTA already contained normalized
versions of dramas. In general, XMLHandler was $sp_#dalton
designed to go through each drama, and extract Belmont –
all the drama text, excluding the front page and @sp_#dalton
the cast list. Further, parsed dramas were conse-
quently written into a single text file. In order to $sp_#frau_von_wichmann
separate dramas and their parts from each other, Ach – lebt meine arme Julie noch?
specific tags were introduced: “$” as opening tag @sp_#frau_von_wichmann
and “@” as a closing tag, which were followed by ...
the attribute name or value without a blank space. @scene
For example, at the start/end of each drama a line ...
with an opening/closing tag and drama id was writ- @id_ger000066
a
ten (e.g., “$id_ ger000569” at the beginning and ”. . . ” replaces the text skipped in this example.
b
“@id_ger000569” at the end) (Table 2). Blank lines are added for the convenience of reading the
example.
The function for writing parsed drama allowed Figure 1: A Shortened Example of a Drama Parsed
to produce two different outputs: dramas with the Only with Speeches
whole text parsed or only characters’ speeches (sep-
arated by scenes as well) without sets or stages.Attribute name Text following the “$” or “@” tag Text enclosed between tags Example of opening/closing tag
Drama id id_dramaid Parsed drama $id_ger000569 / @id_ger000569
Set / stagea A set / a stage $/@
Scene/actb scene A scene / an act $scene / @scene
Speaker id sp_#speakername A speech of a particular character $sp_#detlev / @sp_#detlev
a
There was no text following “$” and “@” signs for sets and stage, and the text was enclosed just between those signs.
b
126 dramas in GerDraCor and 15 dramas in DTA did not contain scenes and were separated by acts or equivalent text
delimiters, which were marked with a “scene” tag.
Table 2: Tags Used in Parsed Dramas with Examples
transliterated Hinweg sie nah’n Dort sind wir sicher
normalized Hinweg sie nah ‘n Dort sind wir sicher
Table 3: Example of Erroneously Added Blank Space After Normalization
3.3 File Comparator Since the normalized version resolved hyphen-
Since it was undesirable for generated dramas to ation at the page and line break and sometimes
contain antiquated spellings and characters, the replaced one word with two words, or connected
version of DTA texts used for training the model two words into one, the word pairs could not be col-
was the normalized version offered by the resource. lected by simply comparing each line word by word
GerDraCor did not offer normalized versions of in both version. Sometimes, it was indicated in the
their drama texts, though. To mitigate the influence DTA normalized version, if words were previously
of historical spelling on the training of the model, merged (e.g., “wie_es” in the normalized version
an effort was made to normalize GerDraCor texts corresponded to "wie’s" in the original text). How-
by using DTA texts. ever, such indication was not done consistently:
The DTA offers different versions of each of “thu’s” for example was normalized into "tu es"
their drama texts, two of which were important for without an underscore, and therefore, could be
the File Comparator. treated by the algorithm as two words rather than a
single unit.
1. transliterated: A character-normalized ver- Issues like these could be easily solved by check-
sion with transliterated orthography. Given ing for a specific pattern. The algorithm detects
the age of many of the dramas, the original words ending with “‘s” in the transliterated ver-
texts included characters outside the Latin- sion and tests whether the corresponding word in
1 encoding, as for example the ’langes s’ the transliterated version is followed by an “es”,
(U+017F) or the elevated ’e’(U+0364) for and if this is the case, then the normalized ver-
marking umlauts. sion likely contains two words (e.g., transliterated
“thu’s” is correctly paired with the normalized "tu
2. normalized: A version standardized with
es"). But sometimes the normalized version added
regard to spelling, as well as transliterated
spaces between words, which could not be pre-
orthography. Historical spellings such as
e
dicted and caused wrong indexing, meaning two
"Erkandtnuß." and "weißheyt" are transferred
different words in the line to be compared to each
to their modern equivalents "Erkenntnis" and
other, as shown in the example in Table 3. Added
"Weisheit".
space in the normalized version (“nah ‘n”) causes
the algorithm to combine wrong words in pairs,
Therefore, a collection of word pairs was created,
e.g., “Dort – ‘n”, meaning that “’n” is considered a
by comparing the transliterated and the normalized
normalized version of “Dort”.
versions of the DTA drama texts (Table 4). Punc-
tuation and other unwanted characters (e.g., “%”, In order to exclude wrong pairs, where two
“(“, “/”) were cleaned from the strings before com- different words were treated as normalized and
parison. Each word pair consists of the old spelling transliterated versions of the same word, an al-
of a word, as well as its modern equivalent. Using gorithm to compare the similarity of words was
this list of word pairs, words in GerDraCor with implemented. If the normalized version was too
the old spelling could be changed into their new different from the transliterated version, the word
form. pair was considered faulty (consisting of two dif-ferent words). Firstly, Levenshtein Distance was Transliterated Normalized
Wohlhäbige Wohlhabende
used to find possibly faulty word pairs. With using Verlaubst Laubest
similarity threshold of 3, which appeared to be the Thu’s tue es
most optimal threshold, this method excluded 576 daß’s dass es
hoamgangen heimgegangen
word pairs, but many of them seemed to be correct Zen Zähne
edits of old spellings (Table 5). veracht’ Acht
For that reason, it was decided to try another
Table 5: Examples of Word Pairs Excluded After
method and estimate word similarity in each pair Checking for Faulty Word Pairs with the Levenshtein
with the SequenceMatcher class from the “difflib” Distance Algorithm
module. SequenceMatcher uses “Gestalt Pattern
Matching” algorithm for string matching. In case, Transliterated Normalized
similarity ratio between words in a pair was less Hizt Jetzt
nachi nage
than 0.53 , this word pair was deleted from a list itz Jets
of transliterated-normalized pairs. As getting rid Creyß Kreis
of wrong pairs was the priority, the 0.5 threshold Flick Flügge
Vehd Fett
allowed us to exclude as many as possible faulty dy die
pairs at the cost of losing a few correct ones. Al-
though, this method excluded 712 pairs (more than Table 6: Examples of Word Pairs Excluded After
Levenshtein distance), more of them looked like Checking for Faulty Word Pairs with the Sequence-
Matcher Algorithm
real faulty pairs (Table 6).
Thus, the final version of File Comparator nor-
malizes words by using word pairs left after exclud- Fan et al. first generate a storyline, which is subse-
ing faulty word pairs with SequenceMatcher. quently used as input to the model that generates
While parsing GerDraCor, if the word from the story, we train a model to produce outlines,
drama was found in the dictionary of word pairs, it which become part of the input prompt in the sec-
was lowered, changed to its normalized version and ond stage. Likewise, our approach is different from
restored with regards to its original capitalization. Yao et al.’s in that it uses just 10 keywords instead
of one keyword per sentence in the story. With this
Transliterated Normalized
Ueberraschungen Überraschungen approach, we aim to guide the generation process
Medicinerei Medizinerei of the model by providing it with the keywords sum-
practicieren praktizieren marizing the most important parts of each scene.
Caffeegeschirr Kaffeegeschirr
Cigarettentasche Zigarettentasche Our second goal is to reduce the workload of the
Hausflurthür Hausflurtür user by allowing them to provide only 10 keywords
Nachtheil Nachteil and let the hierarchical model do the rest of the
Legirung Legierung
legirt legiert work.
Gratulire Gratuliere First, we fine-tune a GPT-2 model (the outline
nothwendigerweise notwendigerweise
adressirt adressiert
model) to generate outlines of scenes based on an
cuvertiert kuvertiert input of keywords extracted from the text. In the
todtgeboren totgeboren second step, we fine-tune a second model (the gen-
eration model) to generate scenes based on input
Table 4: Examples of Pairs Collected from Transliter-
ated and Normalized Versions of DTA Drama Texts which consists of the outline of the scene, a sum-
mary of the remote context as well as that of the
local context.
4 The Proposed Approach
4.1 GPT-2
Inspired by the two-stage story generation ap- GPT-2 (Radford et al., 2019) has been demon-
proaches employed by (Fan et al., 2018; Yao et al., strated to achieve state-of-the-art results in a range
2018), we also decided to divide the drama scene of NLP tasks such as natural language inference,
generation process into two stages. However, while semantic similarity, text classification as well as
3
Ratio varies from 0 to 1, where 0 means no commonalities question answering. Moreover, GPT-2 has success-
and 1 means identical strings. fully been used for story generation (Wang et al.,2020; See et al., 2019). In addition, as there are no real outlines available
GPT-2, introduced by Radford et al., is an auto- for the plays, we experiment with two summariza-
regressive transformer consisting of 12, 24, 36 tion algorithms to get the gold standard outlines.
or 48 decoder blocks, depending on the size of First, following Wang et al.’s approach we employ
the model. In contrast to BERT (Devlin et al., TextRank, an extractive text summarization algo-
2018), which consists of encoder blocks only, GPT- rithm, to extract the outlines from scenes. We also
2 stacks decoder blocks. Furthermore, an important try abstractive summarization with a BERT2BERT
property of GPT-2 is its autoregressivity, i.e. the model6 trained on MLSUM, a dataset of 1.5M on-
model conditions the next token on the previous line news articles. Upon inspection, we found that
token thus allowing text generation. the BERT2BERT model’s output was unsatisfac-
According to Radford et al., an additional key tory: most of the time the summary consisted of 2-3
feature of GPT-2 is its ability to learn a downstream sentences and was often truncated. Furthermore,
task in a zero-shot manner, i.e. without any need as the format of a play presupposes some form of
for parameter tweaking or modifications to the ar- a dialogue, it is quite different from that of a nor-
chitecture of the model. mal text written in prose. We hypothesize that the
GPT-2 was trained with a slightly modified lan- strange output of the model is due to it having been
guage modeling objective: instead of estimating the trained on news articles. Thus, we proceed with
conditional distribution P (output|input), GPT-2 utilizing the TextRank algorithm for outline gen-
estimates P (output|input, task). But, instead of eration. Prior to performing summarization with
separately modeling this at the architectural level, TextRank, we remove the speakers, and add them
the task can be prepended to the input sequence. back in to each sentence in the outline.
As there is no official GPT2 model for Ger- 4.3 The Outline Generation Model
man, we use the German GPT2 model4 uploaded
to Huggingface. It uses the 12-block setting, result- As the data set we use does not have gold standard
ing in a 117M parameter model. The model was outlines, we decided to follow Wang et al.’s ap-
trained on a 16GB and 2,350,234,427 tokens data proach, in which they use Textrank (add citation to
set consisting of data from the Wikipedia dump, EU extract the outline of the story (or the scene in our
Bookshop corpus, Open Subtitles, CommonCrawl, case). We then utilize these outlines as the ground
ParaCrawl and News Crawl. truth output for our model. As input to the outline
model, we use keywords extracted from the scenes
4.2 Pre-processing & Train/Dev/Test Split and their outlines.
First, we pre-process the Dracor dataset, generating 4.3.1 Keyword extraction
training instances needed for training both models. In the search for a keyword extraction algorithm
As both the outline and the generation models use which could yield a good set of keywords for each
scenes and gold standard outlines as input, we gen- scene/outline, we have experimented with 6 differ-
erate those first. ent algorithms: Yake (Campos et al., 2020), Rake
For both scenes and outlines we create two ver- (Rose et al., 2010), MultiRake 7 , KeyBert (Grooten-
sions: one with speakers left in the text and one dorst, 2020), TextRank(Mihalcea and Tarau, 2004)
without speakers. The first version serves as in- and tf-idf.
put to both models, while the latter is only used
Keyword Extraction Algorithms RAKE first
once during the keyword extraction process. In the
generates a set of candidate keywords for the doc-
first version, each utterance starts with a and is followed by a newline character,
trix from those. In the next step, for each can-
so that the actual utterance is on a separate line.
didate a score, defined as the sum of its member
For the version without speakers, we simply make
word scores, is calculated. The word scores are
sure each utterance is on a separate line. For sen-
calculated using word frequency (freq(w)), word
tence boundary detection, we employ the NLTK
degree (deg(w)),and (3) ratio of degree to frequency
tokenizer for sentences from the NLTK Tokenizer
(deg(w)/freq(w)).
package 5 .
6
https://huggingface.co/mrm8488/bert2bert_shared-
4
https://huggingface.co/dbmdz/german-gpt2 german-finetuned-summarization
5 7
https://www.nltk.org/api/nltk.tokenize.html https://pypi.org/project/multi-rake/MultiRake is simply the multilingual version of case. Furthermore, some keywords were simply
the RAKE algorithm which has some additional pa- a concatenation of neighboring tokens which do
rameters such the addition of one’s own stopwords not make much sense when put together, especially
or the possibility to vary the length and number of if the preceding tokens are missing. In addition,
keywords. RAKE and MultiRAKE return lowercased version
KeyBert is based on creating BERT embeddings of the keywords, which can be problematic for Ger-
for both the individual tokens in a document as well man text, as casing signals the POS of a word and
as the document itself. Then, the cosine similarity thus serves an important function, distinguishing
of the embedding of each word and the document in nouns from other parts of speech. As GPT-2 uses
which the word appears is calculated. Those words byte-pair-encoding, the starting vocabulary, i.e. the
that have the highest cosine similarity with the doc- set of all individual characters, consists of both
ument embedding are identified as the keywords of lower and upper case characters. This means that
the document. when the BPE algorithm learns to merge adjacent
TextRank is a graph-based ranking model which characters, it treats AB and ab as different tokens.
takes into account the co-occurrence of words in a In light of our observations, we decided to ex-
window of N words, adding edges between those tract keywords using tf-idf and TextRank and train
nodes and then applying applying a ranking algo- two outline models.
rithm until convergence.
In contrast to the algorithms mentioned above, Keyword extraction As a large number of
tf-idf not only quantifies the importance of a term scenes are quite long and the keyword extraction al-
to a specific document in a collection of documents gorithms often return phrases that are only uttered
but also off-setts it by the number of occurrences once by the speaker, we decided to try out keyword
of this term in other documents in the set. This al- extraction from both whole scenes and outlines of
lows to mitigate the effect of highly frequent terms scenes. We have noticed that keywords extracted
occurring in a large number of documents on the from outlines are often more relevant to the outline.
final score. As a result, our models are trained on keywords
extracted from outlines, where the outline version
f (t, d) is that without speakers.
tf (t, d) = P (1)
f (t0 , d) Another important parameter for our keywords
t0 ∈d input is the number of keywords (k) to be extracted
YAKE differs from the other algorithms in that from the scenes. Our experiments have shown that
it relies on a set of features which are supposed when k > 10, many of the terms in the lower half
to characterize each term. These include casing, of the keyword list are extremely random and unre-
the position of the word in the document, word fre- lated to the outline. As a result, we chose k=10 for
quency, word relatedness to context and frequency both tf-idf and TextRank.
of word in different sentences. Finally, these fea-
tures are combined into a single score which repre- Tf-idf Despite using existing implementations of
sents the word (Sw ). tf-idf 8 and TextRank 9 , we had to apply some pre-
processing steps. In the case of tf-idf, we first apply
Q a SpaCy10 POS tagger with the de_core_news_sm
w∈kw S(w) German model in order to exclude auxiliary verbs,
S(kw) = (2)
T F (kw) ∗ (1 +
P
w∈kw S(w)) particles, adpositions and adverbs. In addition, any
tokens appearing in NLTK’s stopword list for Ger-
Algorithm Comparision In order to select the
man are dropped.
most suitable algorithm for this task, we performed
a qualitative evaluation of the keyword extraction TextRank Similarly, we only keep keywords that
results. We used a small set of 5 randomly chosen are not part of the list of German stopwords. In
scenes. Upon inspection of the extracted keywords, addition, as TextRank extracts sequences of tokens,
we observed that only the keywords obtained us- not individual tokens, repetitions containing tokens
ing tf-idf and TextRank actually yielded acceptable 8
https://scikit-learn.org/stable/modules/generated/sklearn.
results. For example, Rake, MultiRake and YAKE feature_extraction.text.TfidfVectorizer.html
return quite a few repeating keyword or keywords 9
https://pypi.org/project/pytextrank/
10
or keywords that differ only in the grammatical https://spacy.io/that only differ by grammatical case are inevitable. summarizer to produce the prompt for next
In this case, we discard repeated keywords. For iteration.
instance, in the case of die gute Oma and der guten
Oma we only keep the lemmatized version of the 2. Dynamic prompt: In our system, the prompt is
first occurrence of the keyword. split into three individual parts: outline, sum-
mary of remote context and local context. The
4.3.2 Model training outline is either drawn from the original play
To fine-tune the German GPT-2 model to produce or generated by the first part of the system,
outlines given keywords as input, we concatenate and remains unchanged in all generative itera-
the keywords K and the corresponding outline O tion. When the outline and generated outputs
extracted using TextRank and separate them with are longer than 924 tokens, only the nearest
the token. In addition, the concatenated 250 tokens are preserved, and the remote con-
sequence C is prepended with a token and text is summarized by a TextRank model. The
a token is attached to the end of the con- three parts are concatenated with a to-
catenated input. ken to form the prompt of each generation
The model is trained for 3 epochs with a training step. In this way, our model can maintain
batch size of 4 and a test batch size of 8. The local coherency as well as memorizing impor-
default optimizer AdamW is used and the number tant information even if it is mentioned far
of warm up steps for the learning rate scheduler is ahead of the current position. The introduc-
set to 500. The model is evaluated every 400 steps. tion of outlines provides a guideline for the
During training, we compute the cross-entropy of plot and guarantees global consistency. Thus,
the tokens in C. the model is provided with dynamic prompt
At test time, the model is fed the sequence with different information in each iteration. A
+ K + and is expected to gener- figure describing the model structure can be
ate the outline tokens. Generation stops once the found below. (Figure ??)
token is generated. We use top p sam-
pling, wherein the next token to be generated is
selected from the vocabulary items that make up
70% (top_p=0.9) of the probability mass. In addi-
tion, repetition_penalty is set to 2.0.
As has been mentioned before, we have trained
two versions of the outline model (using the same
settings): one in which the keywords are extracted
using tf-idf and the other using TextRank. The two
models are evaluated with respect to their perfor-
Figure 2: Model architecture
mance on the downstream task of scene generation,
discussed in Section 5.2.
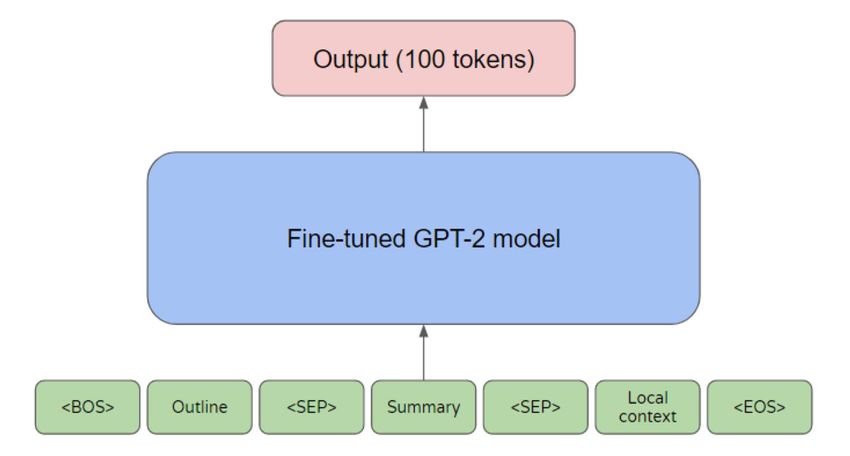
4.4 The Generation Model 3. Automatic post-editing: Despite the improved
performance of our fine-tuned GPT-2 model,
In the second part of our system, another fine-tuned it still fails to produce drama as human ex-
GPT-2 model is leveraged to generate a drama perts. This can be attributed to the inherent
scene from given start and outline. The genera- difficulty of drama generation and the diverse
tion model can be characterized by the following writing styles and formats of our collected
three aspects: training corpora. To address some recurring
format problems, we apply a few automatic
1. Iterative generation: As many drama scenes
post-editing methods. In particular, we have
are longer than the upper length limit of GPT
resolved the following issues:
model (1024 tokens), it is not possible to gen-
erate a whole scene at once. Therefore, we • Repetitiveness: As the input information is rel-
adopt an iterative generation strategy: in each atively little at the beginning of generation, the
iteration, the model only generates 100 tokens, model tends to repeat sentences from prompt
and all generated tokens are then fed into a or generated lines. To counter repetitiveness,we set the repetition penalty to 1.01 and for- with an early stopping patience of 10. The fine-
bid repeated 4-grams during generation. We tuned baseline model is trained on the raw drama
also discard any new lines (excluding charac- scripts directly with the same set of hyperparame-
ter names) that have already been generated. ters as generation model training, except that it is
Since we have a strict penalty for repetition, trained for 10 epochs, as there are fewer optimiza-
it can occur that the model cannot generate tion steps in each epoch compared to generation
a valid line in an iteration. To prevent these model fine-tuning.
cases, the model returns 10 sequences each
time for the post-editing module to select, and 5.1 Evaluation Metrics
it is backed off to generation without outline To evaluate the performance of our approach, we
when none of the 10 returns include any valid adopt several automatic quantitative evaluation met-
lines. rics as well as a manual qualitative analysis. 100
• Bad character names: In most cases the model scenes from test set are generated by each model
is able to identify characters in the play and given start of the scene (approximately 100 tokens)
continues the dialogue with their names. How- as well as an outline (approximately 200 tokens,
ever, it sometimes misspells names or adds set to NULL for baseline models) and their perfor-
new characters abruptly, which harms the plot mance is measured and compared by the following
consistency. In our system we identify mis- metrics.
spelling by its edit distance from any given
• Average number of sentences per speech:
character name. If the edit distance is small
In general, drama is comprised of conversa-
(less than or equal to 2), it is considered as
tions, which means each character is supposed
misspelling and the wrong name is corrected
to take turns to give their speeches. Thus, it
to a given character name. Otherwise, the new
is important that the model should not gener-
name is seen as an invalid character and will
ate a text where only one or two characters
be removed along with its speech.
give very long speeches. Average number
• Empty speeches: The model may output char- of sentences per speech is a metric reflecting
acter names at the start of a new line but does how well the generated plays resemble a hu-
not assign any speech to them. We manage to man written play in format. Abnormally high
resolve this problem by identifying character value in this metric indicate that model fails
names followed immediately by another name to capture the format features of drama.
and discarding the lines.
• Average sentence length: Average sentence
5 Experiments and Results length is a simple yet effective measurement
To study the effectiveness of our proposed ap- of performance of generative models(Kincaid
proach, we compare our models with baseline GPT- et al., 1975; Roemmele et al., 2017). While
2 models. In particular, we have two baseline mod- too long sentences might harm readability, too
els: a not fine-tuned GPT-2 model and a GPT-2 short sentences are more likely to be incor-
model fine-tuned on the same training set but with rect or illogical in the context. In our experi-
no outline or summarization (-dynamic prompt). ment, we compare the average sentence length
All models are based on a German-language GPT- of generated texts to that of human written
2 model named german-gpt2 from HuggingFace.11 scripts, to evaluate and compare how each
For generation model training, we first extract model performs in generating fluent and read-
prompt-generated output pairs from collected cor- able sentences.
pora and fine-tune our model on them. In particular, • Perplexity: We also measure the perplexity
the outline part in the prompt is extracted from the score of the generated scenes from each model
original scene using TextRank. We run the training (including human written plays) using german-
for 3 epochs with a batch size of 8, evaluating on gpt2. Perplexity is usually assigned by a to-
the dev set every 400 steps. A default optimizer is be-evaluated language model on a real text
used with 500 warm-up steps and the checkpoint (Jelinek et al., 1977), while in our case we
with the lowest perplexity on dev set is chosen, reverse the process and leverage a pre-trained
11
https://huggingface.co/dbmdz/german-gpt2 language model to evaluate the fluency andModels w/o fine-tuning w/o outline w extracted outline w TextRank outline w TF-IDF outline Human
Sentences per speech 64.74 5.40 4.47 5.97 6.04 3.21
Sentence length 4.60 6.89 6.16 6.82 6.60 8.82
Perplexity 20.58 18.90 19.18 18.82 19.46 17.13
1-gram overlap 0.11 0.19 0.20 0.17 0.18 0.10
2-gram overlap 0.012 0.028 0.040 0.020 0.022 0.009
3-gram overlap 0.0007 0.0053 0.0109 0.0024 0.0032 0.0013
Topic drift (2-gram) -8.33% 34.3% 18.2% 27.3% 42.3% 20.0%
Topic drift (3-gram) 28.6% 66.3% 23.0% 34.6% 79.2% 57.1%
Distinct-1 0.503 0.433 0.463 0.438 0.443 0.576
Distinct-2 0.880 0.842 0.860 0.846 0.846 0.921
Distinct-3 0.969 0.963 0.966 0.962 0.960 0.982
Table 7: Automatic evaluation results on 100 test set.
coherency of generated texts. In particular, to perform reasonably well in average number of sen-
balance the evaluation efficiency and accuracy, tences per speech. The human-written scripts have
we use a stride of 100. Lower perplexity score the lowest value.
indicates better coherency. Similar patterns can be observed in average sen-
tence length and perplexity. Human-written scripts
• N-gram overlap: For n=1,2,3, we measure demonstrate the best readability and coherency.
the F1 score of n-gram overlap between the Among the machine generation approaches, despite
start of scene and generated text. Low value the gap being trivial, the model with no outline
means lower similarity between the generated and the model with outline generated by keywords
text and start of the scene. (TextRank) display superiority to the model with
• Topic drift: In addition to n-gram overlap, extracted outlines in terms of fluency.
we also calculate the overlap for the first half When it comes to n-gram overlap, the model
and second half of generated texts separately, with extracted outlines has by far the highest over-
and measure the proportion of decrease in F1 lap with the given start of the scene, followed by the
as a metric for topic drift. We assume that, if model with no outlines. The models with generated
a story is globally consistent, the topic drift outlines do not reach a decent result, probably be-
should be relatively small, while a story lack- cause of the poorer quality of outlines. It is worth
ing plot consistency tends to have larger topic mentioning that the real drama scripts have the
drift. lowest overlap score. We attribute this to the out-
standing ability of human experts of rephrasing and
• Distinct-n: To examine the model’s ability of controlling the flow of plot, thus it is not directly
producing diverse words and phrases, we also comparable to machine generation approaches.
compute the average proportion of unique n- Besides, we notice that introducing extra out-
gram in the whole generated text (Li et al., line information indeed contributes to a better
2015). Higher proportion of unique n-grams global consistency: models using both extracted
reflects that the model is highly capable of outlines and outlines generated by TextRank key-
generating unseen words or phrases, either by words show competitive or even better performance
rephrasing existing expressions or introducing than the human-written plays in topic drift, while
new contents. model that do not leverage such information suffer
severely from topic drift.
5.2 Quantitative Results Finally, no significant difference is observed in
the ability of using diverse vocabulary among ma-
Table 7 shows the results of our automatic evalu-
chine generation models. Human playwrights, as
ation. It is obvious that the model without fine-
we have expected, show their irreplaceable advan-
tuning fails to produce texts that are formally sim-
tage in diction.
ilar to drama: each speech consists of on average
64.74 sentences and each sentence is composed 5.3 Qualitative Analysis
of only 4.6 words, indicating it just start a speech
randomly and many sentences are only one phrase 5.3.1 Qualitative Evaluation of Outlines
or even one word. For this reason, it will not be Firstly, in most of the cases, only the first line of the
analyzed later in this section. All other models outline contains a speaker. Naturally, this makesit impossible for the subsequent generation model a challenging task even for human experts, and in
not to come up with random characters that do not our work, there are still some problems remaining
appear in the outline. Furthermore, after the first unresolved:
couple of sentences, the generated outline quite
often consists of direct speech followed by a report- 1. Abrupt ending: Although a special token
ing clause (i.e. "sagte der Mann" - "a man said", is added to the end of each scene
"fragte er" - "he said"), as can be seen in both gener- and used for training, we notice that in most
ated outlines in Table A1 in the Appendix. This is cases the generation only stops when a max-
quite surprising, considering that the gold standard imum iteration number is reached. This will
outlines do not contain any such text, as all of the lead to an abrupt ending problem. A better
drama pieces are in dialogue format. A possible method should be explored to provide more
explanation for this could be that the amount of control over the story ending without dramati-
drama texts used for training is insignificant com- cally harming the conciseness of drama.
pared to the large amounts of news data the model 2. Non-uniform format: Despite an extra post-
was pre-trained on. editing process during generation, some in-
5.3.2 Qualitative Evaluation of drama texts consistency in format is still not completely
Manual evaluation reveals that none of the models avoided. Some bad names are not detected as
were able to produce coherent and meaningful texts. well and are thus kept in the text and compro-
On average the texts created by the model with no mise readability.
outline are shorter compared to the texts from other 3. Instability: While some previous works (Rosa
models, which mostly end after a maximum itera- et al., 2020, 2021) rely on manual interven-
tion number is reached. Though all of the models tion to detect and prevent unsatisfactory gen-
produced texts that ended with the repetition of eration results, we decided to adopt a more
mildly changed words or phrases, the model using convenient fully automatic approach, which
an extracted outline did so more frequently. This inevitably induces accumulated errors and re-
can be seen quite well in the generated example sults in instability in generation.
text found in Table A2 Part 3/3 given in the ap-
pendix and might explain the extremely low topic 4. Incompetence of generating a whole play: The
drift values for this model. The two models using proposed model can only generate one scene
generated outlines did not introduce as many new at a time and cannot produce a whole play. Fu-
characters and did not switch between speakers as ture work can focus on this more challenging
often as the other two models, creating mostly long task, for example by introducing an additional
monologues instead of dialogues. All of the models layer to the hierarchy, aiming to generate out-
overused ’»’ and ’«’ in normal dialog and started lines for each scene based on a outline of the
a lot of sentences with a hyphen. Since this is a whole play and summary of previous scenes.
problem occurring in all of the models, it can be
assumed that the varying formalization across dif- 7 Conclusion
ferent dramas used in the training process caused This paper compares the quantitative results of dif-
this issue. In multiple drama texts two or more fol- ferent models attempting the generation of German
lowing hyphen were used to mark pauses in speech. drama texts. Furthermore it explores the oppor-
One example of an excessive use of hyphen in the tunity of generating German drama texts with ex-
original drama texts can be found in the excerpt tracted outlines. While the quantitative results of
from ’Die Pietisterey im Fischbein-Rocke’ given the models suggested sensible outcomes, qualita-
in Figure A1 in the appendix. The models tend to tive analysis of the generated texts found them to
overuse hyphens in a way, that hinders meaningful be lacking in regards of coherency, meaning and
text generation instead. form. A lot of issues can be hypothesized to stem
from the varying formalization in the drama texts
6 Discussion and Outlook
used in the training of the models and the poor qual-
Our proposed method described above is able to ity of the generated outlines. A bigger and cleaner
handle some known issues like lack of global infor- dataset of German drama texts would be desirable
mation. However, drama generation/completion is for further testing of generational models.References J Peter Kincaid, Robert P Fishburne Jr, Richard L
Rogers, and Brad S Chissom. 1975. Derivation of
Amal Alabdulkarim, Siyan Li, and Xiangyu Peng. new readability formulas (automated readability in-
2021. Automatic story generation: Challenges and dex, fog count and flesch reading ease formula) for
attempts. arXiv preprint arXiv:2102.12634. navy enlisted personnel. Technical report, Naval
Technical Training Command Millington TN Re-
Arwa I Alhussain and Aqil M Azmi. 2021. Automatic
search Branch.
story generation: a survey of approaches. ACM
Computing Surveys (CSUR), 54(5):1–38.
Stefanie Lethbridge and Jarmila Mildorf. 2004. Basics
Ricardo Campos, Vítor Mangaravite, Arian Pasquali, of english studies: An introductory course for stu-
Alípio Jorge, Célia Nunes, and Adam Jatowt. 2020. dents of literary studies in english. Tübingen: Uni-
Yake! keyword extraction from single documents versity of Tübingen.
using multiple local features. Information Sciences,
509:257–289. Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao,
and Bill Dolan. 2015. A diversity-promoting objec-
Yun-Gyung Cheong and R Michael Young. 2014. Sus- tive function for neural conversation models. arXiv
penser: A story generation system for suspense. preprint arXiv:1510.03055.
IEEE Transactions on Computational Intelligence
and AI in Games, 7(1):39–52. Ling Liu and M Tamer Özsu. 2009. Encyclopedia of
database systems, volume 6. Springer.
Deutsches Textarchiv. 2022. Grundlage für ein
Referenzkorpus der neuhochdeutschen Sprache. Rada Mihalcea and Paul Tarau. 2004. TextRank:
Herausgegeben von der Berlin-Brandenburgischen Bringing order into text. In Proceedings of the 2004
Akademie der Wissenschaften, Berlin. URL: Conference on Empirical Methods in Natural Lan-
https://www.deutschestextarchiv.de/. [link]. guage Processing, pages 404–411, Barcelona, Spain.
Association for Computational Linguistics.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2018. BERT: pre-training of Nanyun Peng, Marjan Ghazvininejad, Jonathan May,
deep bidirectional transformers for language under- and Kevin Knight. 2018. Towards controllable story
standing. CoRR, abs/1810.04805. generation. In Proceedings of the First Workshop on
Storytelling, pages 43–49.
Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hi-
erarchical neural story generation. In Proceedings Alec Radford, Jeff Wu, Rewon Child, David Luan,
of the 56th Annual Meeting of the Association for Dario Amodei, and Ilya Sutskever. 2019. Language
Computational Linguistics (Volume 1: Long Papers), models are unsupervised multitask learners.
pages 889–898, Melbourne, Australia. Association
for Computational Linguistics. Melissa Roemmele, Andrew S Gordon, and Reid Swan-
son. 2017. Evaluating story generation systems us-
Angela Fan, Mike Lewis, and Yann Dauphin. 2019. ing automated linguistic analyses. Technical re-
Strategies for structuring story generation. arXiv port, UNIVERSITY OF SOUTHERN CALIFOR-
preprint arXiv:1902.01109. NIA LOS ANGELES.
Frank Fischer, Ingo Börner, Mathias Göbel, Ange- Rudolf Rosa, Ondrej Dusek, Tom Kocmi, David Mare-
lika Hechtl, Christopher Kittel, Carsten Milling, and cek, Tomás Musil, Patrícia Schmidtová, Dominik
Peer Trilcke. 2019. Programmable corpora: Intro- Jurko, Ondrej Bojar, Daniel Hrbek, David Kosták,
ducing DraCor, an infrastructure for the research on Martina Kinská, Josef Dolezal, and Klára Vosecká.
european drama. Publisher: Zenodo. 2020. Theaitre: Artificial intelligence to write a the-
Neil M Goldman. 1974. Computer generation of nat- atre play. CoRR, abs/2006.14668.
ural language from a deep conceptual base. Techni-
cal report, STANFORD UNIV CA DEPT OF COM- Rudolf Rosa, Tomás Musil, Ondrej Dusek, Dominik Ju-
PUTER SCIENCE. rko, Patrícia Schmidtová, David Marecek, Ondrej
Bojar, Tom Kocmi, Daniel Hrbek, David Kosták,
Maarten Grootendorst. 2020. Keybert: Minimal key- Martina Kinská, Marie Nováková, Josef Dolezal,
word extraction with bert. Klára Vosecká, Tomás Studeník, and Petr Zabka.
2021. Theaitre 1.0: Interactive generation of theatre
Sepp Hochreiter and Jürgen Schmidhuber. 1997. play scripts. CoRR, abs/2102.08892.
Long short-term memory. Neural computation,
9(8):1735–1780. Stuart Rose, Dave Engel, Nick Cramer, and Wendy
Cowley. 2010. Automatic Keyword Extraction from
Fred Jelinek, Robert L Mercer, Lalit R Bahl, and Individual Documents, pages 1 – 20.
James K Baker. 1977. Perplexity—a measure of the
difficulty of speech recognition tasks. The Journal David E Rumelhart, Geoffrey E Hinton, and Ronald J
of the Acoustical Society of America, 62(S1):S63– Williams. 1986. Learning representations by back-
S63. propagating errors. nature, 323(6088):533–536.Abigail See, Aneesh Pappu, Rohun Saxena, Akhila Yerukola, and Christopher D. Manning. 2019. Do massively pretrained language models make better storytellers? In Proceedings of the 23rd Confer- ence on Computational Natural Language Learning (CoNLL), pages 843–861, Hong Kong, China. Asso- ciation for Computational Linguistics. Wei Wang, Piji Li, and Hai-Tao Zheng. 2020. Con- sistency and coherency enhanced story generation. CoRR, abs/2010.08822. Lili Yao, Nanyun Peng, Ralph M. Weischedel, Kevin Knight, Dongyan Zhao, and Rui Yan. 2018. Plan- and-write: Towards better automatic storytelling. CoRR, abs/1811.05701.
A Appendix
id model Generated outline
Liddy: Ich muß sagen – ich bin entzückt..?« »Do is doch was zu do«, sagte er
zum Käthchel und wies auf die große Verantwortung hin; Herr Littmann
meinte so schön es im Scherz ang’scheckt wie eine Maus in einer Mädl’n oder
Frauenzimmerin des Herrn von der Hellenen-Pensionärsfeuerwehre mit dem
Namen Ihnen ’nen Kauz auszulachen«. „Mein Vater war ein alter Knabe aus
id_ger000018_5 textrank
dem Dorf Der hat sich für einen Berufsstart als Tischler entschieden Aber da
kommt man ja nicht mehr drauf zurück...“ Nun das ist wahrhaftig kein
Wortschatzfehler sondern daß mir auch noch ganz ungebildete Leute zuhören
können Als ob mich mein Sohn nur um seine gute Laune gebeten hätte wenn
meine Tochter einmal über ihm wäre...
Valeria: Ich wollte dich nicht verlassen. – Ich habe dir es noch gesagt; ich bin
dein Freund und deine Dienerin gewesen!« »Und du hast mich verraten?«,
sagte er zu mir mit dem Augenschmalze auf den Lippen in der Sprache seiner
eigenen Muttersprache so leise als möglich.« Nun komme endlich nach Hause
zurück von diesem Abend hier im Garten meiner Schwester Liddy oder dieser
Ihen Tochter Molly... wenns kein Irrtum ist gegen das Schicksal meines Vaters
für die gute Sache aufzuwarten?’ laß ihn allein sprechen!». ’tschuldigung
Vater, aber da war ein Brief an Sie bei Ihrer Ankunft am Bahnhof : Er kam aus
Wien ohne Ihre Erlaubnis herüber ins Haus Ihres Sohnes Marquis de La Salle
. . . Und nun kommen sie alle wieder hierher um sich ihren Spaß daran gönnen
; denn wie gewöhnlich haben wir beide uns schon einmal unterhalten über
id_ger000018_5 tf-idf einige Dinge zwischen Ihnen beiden.... man muß doch sagen daß diese
Begegnung eine gewisse Wahr heit enthält!!’ Ach was soll nur sein – lassen Sie
mal hören!’.Das wird ja wohl niemand sehen wollen ob Ihr Sohn wirklich
einen Fehler begangen hat unter seinem besten Namen.Herr Baronin, erlauben
Herr Graf Renz-Honau, bitte recht freundlichst unsere Hand deines Mannes
küssend anzubezeigen....binde Fräulein Gräfin Marie wird alles verzeihen
müssen meine Frage wäre jetzt keine Antwort nötig öffne deinen Mund weit
genug.” / So sagt mein Bruder zum Doktor – das tut weh!’, fragt er scherzhaft
nach einer Bemerkung des Herrn Kommissars... vielleicht sei der Mann zu
jung dafür geworden, weil er nicht anders kann tun als seine Frau lieben Zu
machen ihm seinen Kummer verständlich darzustellen als auch seine
Leidenschaften zu zeigen.
Table A1: Examples of outlines generated by the two outline generation models (tf-idf and textrank)id_ger000275_37.txt
START_OF_SCENE Rosamunde: Ja er ist es! Gelobt sei Gott!
Flodoardo: Eure Durchlaucht...
Doge: Seid willkommen, Edler Ritter, tausendmal... Habt Ihr Euer Wort gelöst?
Flodoardo: Alles, wie Ihr mir geboten, Ist erfüllt; die Republik Frei von jeglicher Gefahr; Und der
Himmel lächelt heiter.
Doge: Und der Mörder unserer Freunde?
Flodoardo:
w/o outline Flodoardo: Wir sind gerettet.
Doge: Der Tag wird kommen, Daß er sich uns naht.
Flodoardo: Stimme: Euer Tod ist unser Tod!
Doge: Gelobt ist Gott! ...
Flodoardo: Das Glück ruft nach uns! – Der Ritter Des Todes, Der die Stadt umringt, Der Ritter von
Florenz, Der den Kaiser stürzen will! – Hört mich an!
Flodoardo: O Gott!
Doge: Und er, der den Kaiser stürzen wollen –?
Flodoardo: Er soll sich erheben, Und der Herr ist frei! Weh ihm, daß er es erfährt! Ich bitte Euch,
laßt ihn, er soll nicht mehr Euch, Ihm allein, sprechen. Fluch und Haß und Tod sind für uns Leben.
w extracted outline Flodoardo: Auch dieser Mensch, der mit uns ins Gefängnis kam, Der auf diesen Felsen gesprungen
ist, Und sich vor mir entblößte, so als der Retter der Republik?
Flodoardo: Er war der letzte, der hier saß, bis zum letztenmal. Ich bin, wer er? Dogt mir.
Flodoardo:
Doge: Wer war der erste? O wie Ihr ihn nennt, den ersten.
Flodoardo: Wen nannte der König?
Doge: Mein Herzog. Dogt nicht das Gerücht.
Doge: Die Republik hat ihn ausgerufen.
Flodoardo: Ein Fürst.
Doge: Ein Mann. – Ihr, mein edler Herr Abbate; Ihr, hochfürstlicher Herr Follo liegt bereits in den
Eisen.
Flodoardo: Was wird aus Eurer Freiheit? – Contarini, Euer Oberst Frosso liegt schon In den Eisen;
Es wird von der Nacht so viel geredet, Die ihn verderben und aufhetzen.
Parozzi: seht, daß Ihr, das schwöre ich, Den Prinzen Valerio vor euch schützt.
Flodoardo: Wünschst du, daß der Herzog nicht? –
Doge:
2-3: Wünschest du, daß ich es nicht könne? – Alle anderen? – Die ganze Republik? – – Wir?
Flodoardo: Denselben, den ihr im Dunklen habt?
Doge: So wie sie sind, so muß ich auch das sagen. Wir müssen ihn selbst holen.
Flodoardo: Und der Richter von Florenz?
Doge: Der Herzog kommt mir zu nah.
Flodoardo: Ist die Flucht so ein Glück?
Flodoardo: der Herzog von Parozzi.
Doge: Er wird mich mit seinen Kindern einsperren.
Table A2: Example texts generated by the different models.
Part 1/3. Continued on the next page.You can also read

















































