Mathematics of Data: From Theory to Computation
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Mathematics of Data: From Theory to Computation
Prof. Volkan Cevher
volkan.cevher@epfl.ch
Lecture 8: Double descent curves and overparametrization
Laboratory for Information and Inference Systems (LIONS)
École Polytechnique Fédérale de Lausanne (EPFL)
EE-556 (Fall 2021)
License Information for Mathematics of Data Slides
I This work is released under a Creative Commons License with the following terms:
I Attribution
I The licensor permits others to copy, distribute, display, and perform the work. In return, licensees must give the
original authors credit.
I Non-Commercial
I The licensor permits others to copy, distribute, display, and perform the work. In return, licensees may not use the
work for commercial purposes – unless they get the licensor’s permission.
I Share Alike
I The licensor permits others to distribute derivative works only under a license identical to the one that governs the
licensor’s work.
I Full Text of the License
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 2/ 48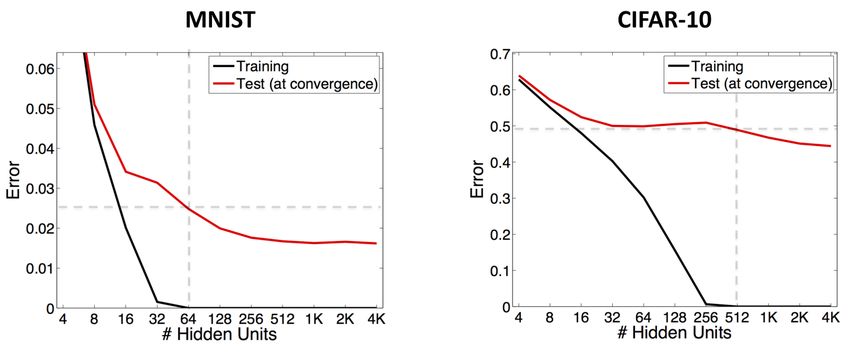
Outline
This lecture :
I The classical trade-off between model complexity and risk
I The generalization mystery in deep learning
I Implicit regularization of optimization algorithms
I Double descent curves
I Generalization bounds based on algorithmic stability
Next lecture :
I Optimization in Deep Learning
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 3/ 48Understanding the trade-off between model complexity and expected risk
Models
Let [Xi : i = 1, . . .] be a nested sequence of parameter domain, i.e.,
Xi ⊆ Xi+1 . For example, let Xi = neural networks with i neurons.
1. Rn (xi? ) = minx∈Xi Rn (x): ERM solution over Xi
2. R(xi? ): True risk of the ERM solution over Xi
3. supx∈Xi |R(x) − Rn (x)|: Worst-case Generalization error of Xi
Practical performance of the ERM estimator
R(xi? ) ≤ min Rn (x) + sup |R(x) − Rn (x)| (1)
x∈Xi x∈Xi
As we increase the index i → i + 1 of the parameter domain, i.e., we choose a larger (more complex) model
1. The minimum empirical risk decreases minx∈Xi Rn (x) ≥ minx∈Xi+1 Rn (x).
2. The generalization error increases. supx∈Xi |R(x) − Rn (x)| ≤ supx∈Xi+1 |R(x) − Rn (x)|.
3. What happens with the true risk R(xi? )?
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 4/ 48The classical trade-off between model complexity and risk
Figure: Bias-variance trade-off [9].
Occam’s Razor: Simple is better than complex.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 5/ 48The dangers of complex function classes: sévère (cevher) overfitting
Degree 3 polynomial funtion
2.0
ground-truth
1.5
1.0
0.5
0.0
0.5
1.0
1.5
2.0
1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00
Figure: Training over a complex function class can lead to overfitting.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 6/ 48The dangers of complex function classes: sévère (cevher) overfitting
Noisy samples
2.0
ground-truth
samples
1.5
1.0
0.5
0.0 minx∈X Rn (x) %
0.5
supx∈X |R(x) − Rn (x)| &
1.0
1.5
2.0
1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00
Figure: Training over a complex function class can lead to overfitting.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 6/ 48The dangers of complex function classes: sévère (cevher) overfitting
Degree 19 polynomial fit
2.0
1.5
1.0
0.5
0.0 minx∈X Rn (x) &
0.5
supx∈X |R(x) − Rn (x)| %
1.0
1.5 ground-truth
model
samples
2.0
1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00
Figure: Training over a complex function class can lead to overfitting.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 6/ 48“Hidden” Regularization in Neural Networks
The complexity vs risk trade-off in practice (I)
• Fitting single-layer neural network with SGD and no regularization:
• Test error continues to go down!?! Where is fundamental trade-off??
Figure: Training (empirical) and test (true) error for one-hidden-layer networks of increasing width, trained with SGD [20].
• There exist global mins with large #hidden units have test error = 1.
Empirical error becomes zero for a wide enough network. What should happen for even wider networks?
– But among the global minima, SGD is somehow converging to “good” ones.
ps://www.neyshabur.net/papers/inductive_bias_poster.pdf
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 7/ 48“Hidden” Regularization in Neural Networks
The complexity vs risk trade-off in practice (II)
• Fitting single-layer neural network with SGD and no regularization:
• Test
Figure: Training (empirical) and test (true) error for one-hidden-layer networks of increasing width, trained with SGD [20].
error continues to go down!?! Where is fundamental trade-off??
• There exist global mins with large #hidden units have test error = 1.
Test error continues to go down even if we keep incresing the complexity of the model!
– But among the global minima, SGD is somehow converging to “good” ones.
ps://www.neyshabur.net/papers/inductive_bias_poster.pdf
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 8/ 48The benefits of overparametrization
Degree 200 polynomial fit
2.0
1.5
1.0
0.5
0.0 minx∈X Rn (x) &
0.5
supx∈X |R(x) − Rn (x)| &
1.0
ground-truth
1.5 model
overparametrized
samples
2.0
1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00
Figure: Overparametrization leads to benign overfitting.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 9/ 48The generalization mystery in deep learning
A gap between theory and practice
◦ In practice, simple algorithms like SGD can
train neural networks to zero error and
achieve low test error.
◦ This happens even for large and complex
neural network architectures.
◦ Complexity measures like the Rademacher
complexity suggest the opposite behaviour
(overfitting)
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 10/ 48Multiple global minimizers of the empirical risk
empirical risk
risk
parameter
?
◦ The global minimum is Rn
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 11/ 48Multiple global minimizers of the empirical risk
empirical risk
risk
global optima
parameter
? , but many parameters can attain such value.
◦ The global minimum is Rn
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 11/ 48Multiple global minimizers of the empirical risk
empirical risk
true risk
risk
global optima
parameter
? , but many parameters can attain such value.
◦ The global minimum is Rn
◦ Each minimizer of the empirical risk might have a different true risk.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 11/ 48Not all global minimizers are the same
◦ Consider a simple 2D classification task, and train a neural network with fixed step-size SGD.
◦ The plots below correspond to two different global minimizers:
5 5
4 4
3 3
2 2
1 1
0 0
0.0 0.5 1.0 1.5 2.0 2.5 3.0 0.0 0.5 1.0 1.5 2.0 2.5 3.0
SGD never lands on the global minimum on the right! Why?
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 12/ 48Understanding the implicit bias of optimization algorithms
◦ SGD seems to be biased towards good global minimizers (low true risk).
◦ Some optimization algorithms have an implicit bias towards certain kinds of global minimizers.
◦ Can we characterize this implicit bias?
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 13/ 48Understanding the implicit bias of optimization algorithms
◦ SGD seems to be biased towards good global minimizers (low true risk).
◦ Some optimization algorithms have an implicit bias towards certain kinds of global minimizers.
◦ Can we characterize this implicit bias?
Definition (Algorithm)
We will refer to a function (deterministic or randomized) A : Z → X , mapping Z 7→ AZ as an algorithm with
input Z ∈ Z and output AZ ∈ X .
Example: Gradient Descent Algorithm
We denote GD(T,α,x0 ,∇f ) := T -steps of GD with stepsize α, starting from x0 , using gradient ∇f .
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 13/ 48What is implicit regularization?
Definition (Implicit Regularization of a Deterministic Algorithm)
Consider a minimization problem
F ? = min F (x)
x∈X
and let A be a deterministic algorithm with input Z ∈ Z and output AZ ∈ X .
We say that A solves problem (2) and has implicit regularization H : X × Z → R if
AZ ∈ arg min H(x, Z).
F (x)=F ?
Given the input Z ∈ Z, the algorithm outputs a global minimizer of F that, additionaly, minimizes H(·, Z).
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 14/ 48Implicit bias of gradient descent for linear regression
◦ Consider for example an underdetermined linear system
Ax = b, with A ∈ Rn×p , nSame problem and same initialization vs different algorithms and different solutions
Consider the following simple 2D example :
h x1 i
1 2 =5
x2
Ax = b Different Solutions
Gradient Descent and AdaGrad converge to different
points on the line.
Gradient 102
Descent GD
AdaGrad
AdaGrad 100
10 2
Initialization
10 4
|Axt b|22
10 6
Euclidean norm
ball
10 8
10 10
10 12
0 10 20 30 40 50 60
t
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 16/ 48Implicit bias of gradient descent for linear regression
◦ Gradient descent seems to converge to the closest one in terms of `2 -norm.
Theorem (Implicit bias of Gradient Descent [10])
For the underdetermined, realizable linear system
1
F ? = min F (x) = kAx − bk22
x∈X 2
the gradient descent algorithm GD(T,α,x0 ,∇F ) , for T = ∞ and for any x0 ∈ Rp , and valid step-size α, has
implicit bias H(x) = kx − x0 k2 , i.e.,
GD(T =∞,α,x0 ,∇F ) = arg min kx − x0 k2 .
F (x)=F ?
Remark: ◦ The theorem also holds for stochastic gradient descent, see [2].
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 17/ 48Same problem and same initialization vs different algorithms and different solutions
Proof : For simplicity, take x0 = 0.
Ax = b I The gradient of F is AT (Ax − b).
I This implies that ∀x, ∇f (x) ∈ colspan(AT ).
GD iterates stay in the rowspan
Gradient
Descent Gradient Descent is therefore constrained to the space
AdaGrad
colspan(AT ) = rowspan(A)
Initialization
So its limit point at T = ∞ is in rowspan(A).
Euclidean norm I Note that because of the preconditionning,
ball
AdaGrad can get out of the rowspan(A).
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 18/ 48Same problem and same initialization vs different algorithms and different solutions
Proof (continued):
I The minimum norm solution
x̂candidate x̂candidate = arg min kxk22
x:Ax=b
is also in rowspan(A).
x\
I So both x̂candidate and the limit point of GD are
solutions of Ax = b that are in the rowspan(A)
I Since nullA ∩ rowspan(A) = {0}, there can only
be one solution in the rowspan(A), so
?
xGD = x̂candidate
x\ + h, h 2 null(A)
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 19/ 48Implicit bias for linear models
◦ We can extend this analysis to linear models:
n
X
arg min F (x) := L(hx, ai i, bi ).
x∈Rp
i=1
◦ If the observations are realizable and there are many global minima Glob = {x : F (x) = 0}, then
Theorem (Implicit Bias of Gradient Descent [10])
If the loss L is convex and has a unique (attained) minimum, then the iterates xt of Gradient Descent converge
to the global minimum that is closest to initialization x0 in the `2 -distance :
xt −−−−→ arg min kx − x0 k2
t→∞ x∈Glob
Proof : (Sketch) The assumption on L implies the problem reduces to a linear system: If x is a global
minimum, we must have hx, ai i = bi for all i ∈ {1, .., n}. We can recycle the results we have just seen.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 20/ 48Implicit bias for linearly separable datasets
◦ For linearly separable datasets, we know of an algorithm capable of finding a separating hyperplane.
◦ It maximizes the margin (i.e., distance between the boundary and the nearest training-data point).
Hard-margin Support Vector Machines
The hard margin Support Vector Machine solves the
following optimization problem :
arg min kxk2 subject to yi hx, ai i ≥ 1.
x∈Rp
It finds a hyperplane that maximizes the margin. It
does so by design.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 21/ 48Implicit bias for linearly separable datasets
◦ What happens if we do not explicitly enforce margin maximization?
Theorem (Implicit Bias of Gradient Descent on Separable Data [23, 10])
For the logistic loss (and some other strictly monotonically decreasing losses) and for linearly separable datasets,
the direction of the iterates xt of Gradient Descent for any initialization converges to the hard-margin SVM
direction:
?
xt xSVM ?
t
−−−−→ ?
where xSVM = arg min kxk2 subject to yi hx, ai i ≥ 1
kx k2 t→∞ kxSVM k2 x∈Rp
Remarks: ◦ Here, without explicit instructions, gradient descent maximizes the margin.
1
◦ The rate of this convergence is O log t
.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 22/ 48Implicit bias for linearly separable datasets
◦ A similar result can be established for stochastic gradient descent for the logistic loss on separable datasets.
Theorem (Implicit Bias of Stochastic Gradient Descent on Separable Data [18])
The direction of the iterates xt of Stochastic Gradient Descent for any initialization and for a small enough
fixed step-size, converges almost surely to the hard-margin SVM direction:
?
xt xSVM 1
t
− ?
=O
kx k2 kxSVM k2 log t
2
Remarks: ◦ This result is particularly interesting as it establishes convergence of fixed step-size SGD.
◦ Both SGD and GD have the same implicit bias towards maximizing margins.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 23/ 48Implicit bias for non-convex objectives
◦ Characterizing implicit bias of stochastic gradient descent for non-convex objectives is an active research area.
◦ Some papers study deep matrix factorization as a first step towards getting results for neural networks.
Deep Matrix Factorization
Deep matrix factorization consists of parametrizing a matrix M as a product of N matrices:
M = XN XN −1 . . . X1
which can be understood as parametrizing M by a depth N “linear neural network,” i.e., a neural network with
no activations and with weight matrices X.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 24/ 48Implicit bias for deep matrix completion
◦ The matrix completion problem consists of filling the missing entries of a partially observed matrix.
◦ The deep matrix factorization approach consists of solving the following problem with gradient descent:
X
arg min ([XN XN −1 . . . X1 ]i,j − bi,j )2 .
XN ,XN −1 ...,X1
(i,j)∈Ω
◦ It was conjectured in 2017 [11] that gradient descent was biased towards solutions with small nuclear norm.
Theorem (Implicit Regularization May Not Be Explainable by Norms (2020) [22])
For deep matrix completion the implicit bias can not be expressed as a function of a norm or semi-norm.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 25/ 48Double descent
◦ A failure of conventional wisdom
A B
Fig. 1. Curves for training risk (dashed line) and test risk (solid line). (A) The classical U-shaped risk curve arising from the bias–variance trade-off. (B) The
double-descent risk curve, which incorporates the U-shaped risk curve (i.e., the “classical” regime) together with the observed behavior from using high-
Figure: The classical U-shaped risk curve vs. double-descent risk curve. source: [7].
capacity function classes (i.e., the “modern” interpolating regime), separated by the interpolation threshold. The predictors to the right of the interpolation
threshold have zero training risk.
I classicalnetworks
large-sample limit setting:
and kernel machines n → ∞theunder
trained to interpolate training fixed
applypto regression and also does not predict the second descent
data obtain near-optimal test results even when the training data beyond the interpolation threshold. Recently, there has been an
I high dimensional setting:
are corrupted with nofand
high levels noisep(5,comparably
6). large emerging recognition that certain interpolating predictors (not
The main finding of this work is a pattern in how perfor- based on ERM) can indeed be provably statistically optimal or
mance on unseen data depends on model capacity and the near optimal (11, 12), which is compatible with our empirical
mechanism underlying its emergence. This dependence, empir- observations in the interpolating regime.
ically witnessed with important model classes including neural In the remainder of this article, we discuss empirical evidence
networks and a range of datasets, is summarized in the “double- for the double-descent curve and the mechanism for its emer-
descent” risk curve shown in Fig. 1B. The curve subsumes the gence and conclude with some final observations and parting
classical U-shaped risk curve from Fig. 1A by extending it beyond thoughts.
the point of interpolation.
MathematicsWhen function
of Data class capacity
| Prof. Volkan is below the “interpolation
Cevher, volkan.cevher@epfl.ch Neural
Slide 26/Networks
4860
Test
Train
Zero-one loss (%)
Double descent curve in practice (I) 40
Typical examples:
I linear/nonlinear regression [13] 20
I random features, random forest, and shallow neural networks [7]
0
Zero-one loss Squared loss
88 1709 0.6 Test
RFF RFF
Min. norm solution hn, Min. norm solution hn, Train
(original kernel) (original kernel)
100
Squared loss
0.4
Test (%)
15
Test
10
0.2
1
4
2 0 0.0
0 10 20 30 40 50 60 0 3 10 2010 30 4040 50 10060 300 800
Number of Random Fourier Features (×103) (N) 10 Number
20 of parameters/weights
30 40 50 (×103)
Number of Random Fourier Features (×103) (N)
(a) Random features model (b) A fully connected neural network
Figure: Experiments on MNIST. Source: [7].
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 27/ 48identify certain regimes where increasing (even quadrupling) the number of train
samples actually hurts test performance.
Double descent curve in practice (II)
1 I NTRODUCTION
Figure 1: Left: Train and test error as a function of model size, for ResNet18s of varying width
Figure: Left: Train and test error as a function of model size, for ResNet18s of varying width on CIFAR-10 with 15% label noise.
on CIFAR-10
Right: Test error, shownwith 15% label
for varying trainnoise. Right:
epochs. Test
source: error, shown for varying train epochs. All models
[19].
trained using Adam for 4K epochs. The largest model (width 64) corresponds to standard ResNet18.
The bias-variance trade-off is a fundamental concept in classical statistical learning theory (e.g.,
Hastie et al. (2005)). The idea is that models of higher complexity have lower bias but higher vari-
ance. According to this theory, once model complexity passes a certain threshold, models “overfit”
with the variance term dominating the test error, and hence from this point onward, increasing model
complexity will only decrease performance (i.e., increase
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch
test error). Hence conventional wisdom
Slide 28/ 48Underparametrized regime
Figure: Low generalization but high empirical error Figure: Sweet spot for the model complexity
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 29/ 48Interpolation threshold
Figure: The unique degree 19 polynomial that can fit 20 samples.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 30/ 48Benign overfitting in the over-parametrized regime
106
105
104
error
103
2
102
Figure: A degree 200 polynomial that can harmlessly fits noisy 20 points. 101
0 200 400 600 800 1000
Degree of polynomial fit
Figure: Double descent for polynomial fits
Benign Overfitting [6]: good prediction with zero training error for regression loss
I Statistical wisdom: a predictor should not fit too well.
I deep networks fit perfectly on noisy data and generalize well on test data.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 31/ 48A simple case: linear regression with Gaussian data
Problem setting
◦ linear model:
I training data {ai }n with ai ∼ N (0, Ip ) such that A = [a1 , a2 , · · · , an ]>
i=1
I label bi = hx\ , ai i + wi with the target vector x\ ∼ N (0, 1 Ip ), noise wi ∼ N (0, σ 2 )
p
◦ min-norm solution:
I x? = arg minx {kxk2 : Ax = b} = (A> A)† A> b
◦ excess risk: for a test point a
I R(x? ; x\ ) = E[(ha, x? i − ha, x\ i)2 |A]
Theorem [13]
Under the above problem setting, assume that kx\ k22 = r2 , as n, p → ∞, and p/n → γ, then we have
2 γ
σ 1 − γ , for γ < 1
R(x? , x\ ) →
r2 1 − 1 + σ2 1 , for γ > 1 .
γ γ−1
Remark: The asymptotic risk curves depend on γ and the SNR r2 /σ 2 .
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 32/ 48Alternatives to complexity-based generalization bounds
◦ So far we have seen that complexity based generalization bounds:
I characterize worst-case scenario
I not tight in practice
I disregard the effect of the optimization algorithm
Can we understand generalization as a property of an optimization algorithm?
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 33/ 48Alternatives to complexity-based generalization bounds
◦ So far we have seen that complexity based generalization bounds:
I characterize worst-case scenario
I not tight in practice
I disregard the effect of the optimization algorithm
Can we understand generalization as a property of an optimization algorithm? YES!
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 33/ 48Formal definition of stability (I)
Definition (Uniform Stability [12])
Let A : Z → H be a randomized algorithm with input a finite sample S, and output a function AS ∈ H.
The algorithm A has uniform stability (βn )n≥1 with respect to the loss function L if for all subsets
S, S 0 ⊆ A × B such that |S| = |S 0 | = n and S and S 0 differ in at most one sample:
sup E|L(AS (a), b) − L(AS 0 (a), b)| ≤ βn
(a,b)∈A×B
The expectation is taken with respect to the randomness in the algorithm A .
Misnomer: Lower stability (small values of βn ) means the difference in the output of the algorithm is smaller.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 34/ 48Formal definition of stability (II)
Figure: Algorithm B is less stable than algorithm A .
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 35/ 48Generalization bounds based on uniform stability — definitions
Definition (Empirical Risk on a set)
Let S := [(a1 , b1 ), . . . , (an , bn )] be an i.i.d. sample drawn from a distribution on A × B. Let L : B × B → R be
a loss function and H be a class of functions h : A → B. The empirical risk of h ∈ H on the set S is defined as:
n
1 X
RS (h) := L(h(ai ), bi )
n
i=1
(Almost) same definition as before. Makes explicit the dependence on the set S.
Definition (Expected Generalization Error)
Let A : Z → H be a randomized algorithm that takes as input a finite sample S of arbitrary size, and outputs a
function AS ∈ H. Suppose that S = [(a1 , b1 ), . . . , (an , bn )] is an i.i.d. sample form probability distribution on
A × B. The expected generalization error on a sample of size n is the value
E[RS (AS ) − R(AS ))]
the expectation is taken with respect to the draw of the sample S and the randomness of A .
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 36/ 48Generalization bounds based on uniform stability — Fundamental theorem (I)
Theorem (Hardt et al. 2016 [12])
Let A be uniformly stable with stability (βn )n≥1 , then for a random i.i.d. sample S of size n, the expected
generalization error is bounded as follows
E[|RS (AS ) − R(AS ))|] ≤ βn
Proof.
Let S = [(a1 , b1 ), . . . , (an , bn )] and S 0 = [(a10 , b01 ), . . . , (an
0 , b )] be two i.i.d. samples of size n. Denote
n
S (i) := [(a1 , b1 ), . . . , (ai−1 , bi−1 ), (ai0 , b0i ), (ai+1 , bi+1 ), . . . , (an , bn )]
the sample that results from replacing (ai , bi ) by (ai0 , b0i ) in S.
" n
# " n
#
1 X 1 X
E[RS (AS )] = E L(AS (ai ), bi ) =E L(AS (i) (ai0 ), b0i )
n n
i=1 i=1
" n n
# " n
#
1X 1X 1 X
=E L(AS (i) (ai0 ), b0i ) − L(AS (ai0 ), b0i ) +E L(AS (ai0 ), b0i )
n n n
i=1 i=1 i=1
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 37/ 48Generalization bounds based on uniform stability — Fundamental theorem (II)
Proof. (continued).
We have
" n n
# " n
#
1 X 1 X 1 X
E[RS (AS )] = E L(AS (i) (ai0 ), b0i ) − L(AS (ai0 ), b0i ) +E L(AS (ai0 ), b0i )
n n n
i=1 i=1 i=1
Note that S and S (i) only differ in one sample: uniform stability allows bounding the first term as:
" n n
# n
1 X 1 X 1 X
=E L(AS (i) (ai0 ), b0i ) − L(AS (ai0 ), b0i ) = E L(AS (i) (ai0 ), b0i ) − L(AS (ai0 ), b0i ) ≤ βn
n n n
i=1 i=1 i=1
Finally note that because the samples (ai , bi ) are independent of S we have:
" n
#
1 X
E L(AS (ai0 ), b0i ) = R(AS )
n
i=1
analogously we can show E [R(AS ) − RS (AS )] ≤ βn .
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 38/ 48The stability of SGD
◦ Let hx ∈ HX be an element of a parametric function class. Consider the ERM optimization objective:
n
1 X
f (x) := fi (x), fi (x) := L(hx (ai ), bi ).
n
i=1
◦ The SGD iterates for t = 0, . . . , T are xt+1 = xt − αt ∇x fi (xt ), for i ∼ Unif[n].
Algorithm Assumptions on fi Stability
β 2 PT
SGD convex, L-smooth, β-Lipschitz, αt ≤ 2/L α
t=0 t
n
β2
SGD µ-str convex, L-smooth, β-Lipschitz, αt ≤ 2/L
nµ
1 β 2 + Lρ
SGD µ-str convex, L-smooth, β-Lipschitz, αt =
µt nµ
β2T
SGD avg. iterate convex, L-smooth, β-Lipschitz
nL
1 + 1/β L+1 2 L
SGD non-convex, L-smooth, β-Lipschitz, αt = 1/t β T L+1
n
Table: Summary of stability upper bounds for different assumptions on the objective function [12]
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 39/ 48Effect of the number of iterations on the stability of SGD and the generalization error
Figure 4: Parameter distance versus generalization error on Cifar10.
Figure: Normalized parameter distance between two networks trained on two datasets S, S 0 differing only in one sample,
training error, test error and generalization error (0-1 loss) on CIFAR10 [12].
◦ Parameter distance is a stronger notion than stability.22
◦ More iterations ⇒ Parameter distance increases (we expect stability to increase).
◦ Generalization error follows the same behavior as the parameter distance (proxy for stability).
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 40/ 48Wrap up!
◦ The visualizations can be deceiving to understand the high-dimensional behavior
◦ Are we really in the interpolation regime in machine learning?
Theorem (Probability of interpolation [5])
Given a p-dimensional dataset An = {a1 , . . . , an } with i.i.d. samples, where ai ∼ N (0, I) for all i = 1, . . . , n,
the probability that a new sample a ∼ N (0, I)is in the interpolation regime (i.e., within the convex hull of An )
has the following limiting behavior
1 if n > 2p/2 /p;
lim p(a ∈ convex hull(An )) =
p→∞ 0 if n < 2p/2 /p.
◦ We are most likely in the extrapolation regime [4]
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 41/ 48Wrap up!
◦ The visualizations can be deceiving to understand the high-dimensional behavior
◦ Are we really in the interpolation regime in machine learning?
Theorem (Probability of interpolation [5])
Given a p-dimensional dataset An = {a1 , . . . , an } with i.i.d. samples, where ai ∼ N (0, I) for all i = 1, . . . , n,
the probability that a new sample a ∼ N (0, I)is in the interpolation regime (i.e., within the convex hull of An )
has the following limiting behavior
1 if n > 2p/2 /p;
lim p(a ∈ convex hull(An )) =
p→∞ 0 if n < 2p/2 /p.
◦ We are most likely in the extrapolation regime [4]
◦ Recitation 4 on Friday!
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 41/ 48?
From neural networks to random features model [14, 21]
1-hidden-layer neural network with m neurons (fully-connected architecture):
Let X1 ∈ Rm×p , a ∈ Rp , X2 ∈ Rm , and µ2 ∈ R
weight input
activation
bias
bias
↓ ↓ ↓ ↓
y
" # " #" # " # " #
hx (a) := X2 σ
X1 a + µ1 + µ2 ,
x := [X1 , X2 , µ1 , µ2 ]
| {z }
hidden layer = fixed random features
I X1 : Gaussian initialization and then fixed
I X2 : to be learned
I over-parameterized model: #neurons m > #training data n
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 42/ 48?
Double descent: random features model (I)
◦ high dimensions: #training data n, #neurons m, feature dimension p are comparably large
(a) SGD vs. min-norm solution (b) Bias . B1 + B2 + B3 (c) Variance . V1 + V2 + V3
Figure: Test MSE, Bias, and Variance of RF regression as a function of the ratio m/n on MNIST data set (digit 3 vs. 7) for
p = 784 and n = 600 across the Gaussian kernel. Source: [16].
I random features regression solved by SGD: interplay between excess risk and optimization
I bias variance decomposition for understanding multiple randomness sources
I monotonic decreasing bias and unimodal variance ⇒ double descent
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 43/ 48?
Double descent: random features model (II)
Algorithm data assumption solution type Result on risk curve
[13] Gaussian closed-form variance % &
[17] i.i.d on sphere closed-form variance, bias % &
[8] Gaussian closed-form refined decomposition on variance
[1] Gaussian closed-form fully decomposition on variance
[15] general closed-form %&
[3] Gaussian GD variance % &
[16] sub-exponential SGD variance % &, bias &
Table: Comparison of representative random features on double descent.
◦ multiple randomness sources: data sampling, label noise, initialization
◦ phase transition due to non-monotonic variance
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 44/ 48References I
[1] Ben Adlam and Jeffrey Pennington.
Understanding double descent requires a fine-grained bias-variance decomposition.
In Advances in neural information processing systems, 2020.
[2] Navid Azizan and Babak Hassibi.
Stochastic gradient/mirror descent: Minimax optimality and implicit regularization.
[3] Jimmy Ba, Murat A. Erdogdu, Taiji Suzuki, Denny Wu, and Tianzong Zhang.
Generalization of two-layer neural networks: an asymptotic viewpoint.
In International Conference on Learning Representations, pages 1–8, 2020.
[4] Randall Balestriero, Jerome Pesenti, and Yann LeCun.
Learning in high dimension always amounts to extrapolation.
arXiv preprint arXiv:2110.09485, 2021.
[5] Imre Bárány and Zoltán Füredi.
On the shape of the convex hull of random points.
Probability theory and related fields, 77(2):231–240, 1988.
[6] Peter L Bartlett, Philip M Long, Gábor Lugosi, and Alexander Tsigler.
Benign overfitting in linear regression.
Proceedings of the National Academy of Sciences, 117(48):30063–30070, 2020.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 45/ 48References II
[7] Mikhail Belkin, Daniel Hsu, Siyuan Ma, and Soumik Mandal.
Reconciling modern machine-learning practice and the classical bias–variance trade-off.
Proceedings of the National Academy of Sciences, 116(32):15849–15854, 2019.
[8] Stéphane d’Ascoli, Maria Refinetti, Giulio Biroli, and Florent Krzakala.
Double trouble in double descent: Bias and variance (s) in the lazy regime.
pages 2280–2290, 2020.
[9] Stuart Geman, Elie Bienenstock, and René Doursat.
Neural networks and the bias/variance dilemma.
Neural computation, 4(1):1–58, 1992.
[10] Suriya Gunasekar, Jason Lee, Daniel Soudry, and Nathan Srebro.
Characterizing implicit bias in terms of optimization geometry.
[11] Suriya Gunasekar, Blake E Woodworth, Srinadh Bhojanapalli, Behnam Neyshabur, and Nati Srebro.
Implicit regularization in matrix factorization.
In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,
Advances in Neural Information Processing Systems 30, pages 6151–6159. Curran Associates, Inc.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 46/ 48References III
[12] Moritz Hardt, Ben Recht, and Yoram Singer.
Train faster, generalize better: Stability of stochastic gradient descent.
In International Conference on Machine Learning, pages 1225–1234. PMLR, 2016.
[13] Trevor Hastie, Andrea Montanari, Saharon Rosset, and Ryan J Tibshirani.
Surprises in high-dimensional ridgeless least squares interpolation.
arXiv preprint arXiv:1903.08560, 2019.
[14] Guang-Bin Huang, Qin-Yu Zhu, and Chee-Kheong Siew.
Extreme learning machine: theory and applications.
Neurocomputing, 70(1-3):489–501, 2006.
[15] Zhenyu Liao, Romain Couillet, and Michael Mahoney.
A random matrix analysis of random fourier features: beyond the gaussian kernel, a precise phase transition,
and the corresponding double descent.
In Neural Information Processing Systems, 2020.
[16] Fanghui Liu, Johan A.K. Suykens, and Volkan Cevher.
On the double descent of random features models trained with sgd.
arXiv preprint arXiv:2110.06910, 2021.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 47/ 48References IV
[17] Song Mei and Andrea Montanari.
The generalization error of random features regression: Precise asymptotics and double descent curve.
arXiv preprint arXiv:1908.05355, 2019.
[18] Mor Shpigel Nacson, Nathan Srebro, and Daniel Soudry.
Stochastic gradient descent on separable data: Exact convergence with a fixed learning rate.
[19] Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever.
Deep double descent: Where bigger models and more data hurt.
[20] Behnam Neyshabur, Zhiyuan Li, Srinadh Bhojanapalli, Yann LeCun, and Nathan Srebro.
The role of over-parametrization in generalization of neural networks.
In International Conference on Learning Representations, 2019.
[21] Ali Rahimi and Benjamin Recht.
Random features for large-scale kernel machines.
In Advances in Neural Information Processing Systems, pages 1177–1184, 2007.
[22] Noam Razin and Nadav Cohen.
Implicit regularization in deep learning may not be explainable by norms.
[23] Daniel Soudry, Elad Hoffer, Mor Shpigel Nacson, Suriya Gunasekar, and Nathan Srebro.
The implicit bias of gradient descent on separable data.
Mathematics of Data | Prof. Volkan Cevher, volkan.cevher@epfl.ch Slide 48/ 48You can also read

















































