Data Science 101 Arik Pelkey Pentaho Senior Director - Product Marketing, Hitachi Vantara Scott Cooley Pentaho Data Scientist, Hitachi Vantara
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Data Science 101 Arik Pelkey Pentaho Senior Director – Product Marketing, Hitachi Vantara Scott Cooley Pentaho Data Scientist, Hitachi Vantara
Agenda This session will provide an introduction to data science fundamentals. • What is Data Science? • Common Use Cases and Algorithms • The Data Science Process • Building a Data Science Team • The Future

AI, Machine Learning, and Deep Learning
• AI: Getting machines
to do what humans
are good at
• Machine Learning:
Feeding an algorithm
data to learn and
predict something
• Deep Learning: A type
of machine learning
Image from https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/.
Data Science: Solving Problems with Data
Computer science, HACKING MATH AND Algorithms and
data engineering and SKILLS Machine STATISTICS numerical
wrangling, coding Learning KNOWLEDGE techniques to
derive insights
DATA
SCIENCE
Danger Traditional
Zone! Research
Understanding of the
underlying assumptions Domain knowledge,
SUBSTANTIVE business acumen, experience,
EXPERIENCE value to the business
Diagram from Drew Conway: http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram.
What’s all the fuss?
This stuff was created many many years ago
• Bayes Theorem • Thomas Bayes mid 1700’s
• Regression • Legendre, Gauss and Galton
early 1800’s
• Neural Networks • McCulloch and Pitts early 1940s
Here is a sample footnote.
Think about All Our Data and Compute
SKA - 2020
(Square Kilometer Array Telescope)
It is still
GROWING!
Will generate as much data in
a day as the entire PLANET
does in a year!
https://www.computerworld.com.au/article/392735/ska_telescope_generate_more_data_than_entire_internet_2020/.
Types of Machine Learning
✕
Regression – Looking for Classification – Similar to
✕✕
✕ a statistical relationship ✕ regression but looking for
✕ ✕
✕ across variables that △
separations in the data
△
✕ may give us an estimate △
△
△
given predefined classes.
of a particular outcome. (Supervised)
✕
Clustering – Do not have Anomaly Detection –
◇
✕ ◇ predefined classes but △ △△ ? Identification of outliers
✕ △△
◇ △△ △
◇ trying to find groups or △ △
△ △
△
based upon expected
△ △
△ △△
sets based upon data at ranges of data.
?
△ hand. (Unsupervised)
Here is a sample footnote.
Labelled vs Unlabelled
Lets say we want to Classify Houses by Size Supervised
Given Features or Feature Set Learning
Use the labels
to build a
FullBath HalfBath Bedrooms Home Age Size Label model. Model
1 0 2 56 M used to classify
1 1 3 59 L new house size
2 1 3 20 M
based ONLY on
2 1 3 19 S the known
feature set.
Unsupervised
SIZE is missing! We need to look for similarities in the data
and group them into clusters.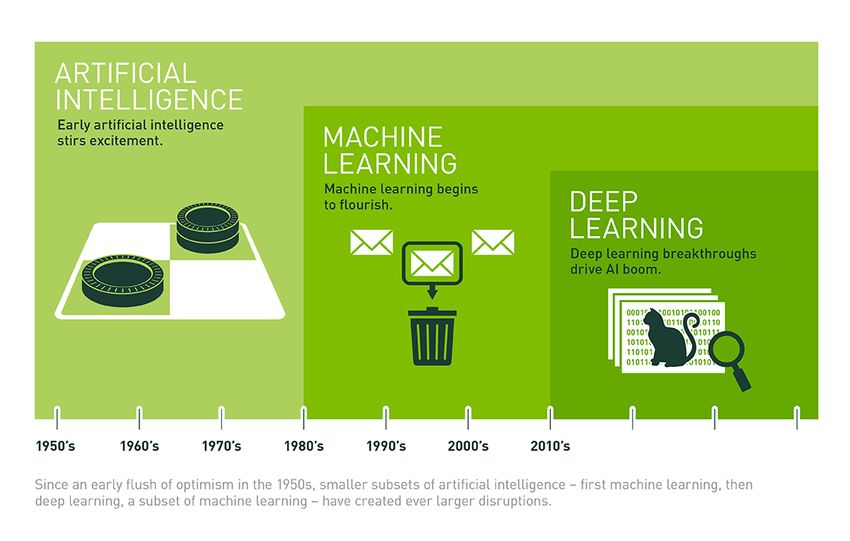
More on Machine Learning
Machine Learning is a methodology to create a model based on sample data and
use the model to make a prediction or strategy using a more algorithmic approach.
SUPERVISED LEARNING MODEL
Historical records that contain
square feet, number of
bathrooms, zip code….
Records that contain the price
the house sold for
Iterate the algorithm over the
combined data to train the model
Use the trained model to predict
outcome on new records
The Data Science Process: Getting from Raw Data to Outcomes
Formal Framework CRISP–DM The Data Science Workflow
Cross Industry Standard Process
for Data Mining
Joe Blizstein and Hanspeter Pfister created for Harvard Data Science course.Specialist Traditional Data Science Team
Data Scientist (DS)
– Prepares data, engineers features, most valuable skill: training models.
Data Engineer (DE)
– Data acquisition focus. Build data pipelines. Not uncommon to have 5:1 ratio
DE:DS
Data Analyst (DA)
– Assist DS with data prep
Application architect (AA)
– Design complete solution; deploy and maintain models in productionMythical Creatures
Trends • Automation • Tools for Citizen Data Scientists • Pre-trained models in the cloud Here is a sample footnote.
Hiring Guidance Here is a sample footnote.
Defining Success
• Easy for the tangible
– Search order optimization
– Recommendation engine or CTR
• Hard for others
– Lead scoring
– Attrition
• Try to measure direct outcomes
• Rarely a silver bullet
• Think ROI
Here is a sample footnote.Typical Data Science Project
DS DS DS DS DS
DE DA
AA AA AA
Understand ID and Prepare data Train Deploy Update
business procure and build model models models
objectives training data new featuresPreventive Maintenance: Caterpillar
Marine Asset Intelligence
Fleet Data via Data Scientist
Satellite Data Mining and
Predictive
Maintenance
Data Data
Integration Integration
Data Business User (COO)
Reporting on
Local Equipment
Marts Operations and
sensor and Efficiency
Server Data
Dashboards and
Reports on Machine
Performance
Cross Department (Onboard and
Operations Data Onshore)
Scheduling/ERPThe Future • Scaling up / enabling more data scientists • Model management • Improved productivity • Support for containerized applications. Here is a sample footnote.
Pentaho ML Orchestration
• Makes data science
teams more productive
• Broad support for open
source libraries in
various languagesSummary • What is Data Science • Common Use Cases and Algorithms • The Data Science Process • Building a Data Science Team • The Future
Next Steps Want to learn more? • Schedule a Meet the Expert • Read Mark Hall’s Machine Learning with Pentaho Blog
You can also read

















































