UCLA UCLA Electronic Theses and Dissertations - eScholarship
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

UCLA
UCLA Electronic Theses and Dissertations
Title
Unsupervised Classification and Network Analysis of the Reddit Communities with Spiking
Neural Network and Exponential-Family Random Graph Model
Permalink
https://escholarship.org/uc/item/2mr761pv
Author
HE, JIE
Publication Date
2021
Peer reviewed|Thesis/dissertation
eScholarship.org Powered by the California Digital Library
University of California
UNIVERSITY OF CALIFORNIA
Los Angeles
Unsupervised Classification and Network Analysis of the Reddit Communities
with Spiking Neural Network and Exponential-Family Random Graph Model
A thesis submitted in partial satisfaction
of the requirements for the degree
Master of Science in Statistics
by
Jie He
2021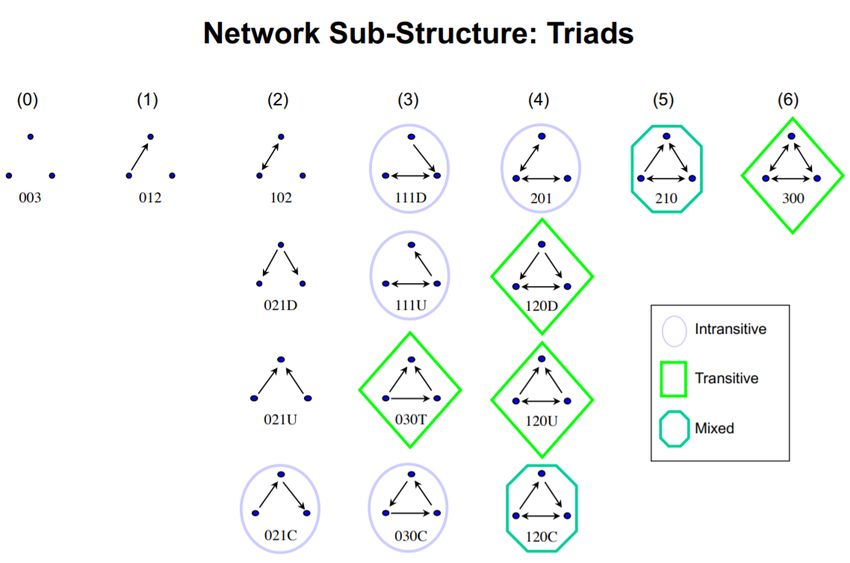
© Copyright by
Jie He
2021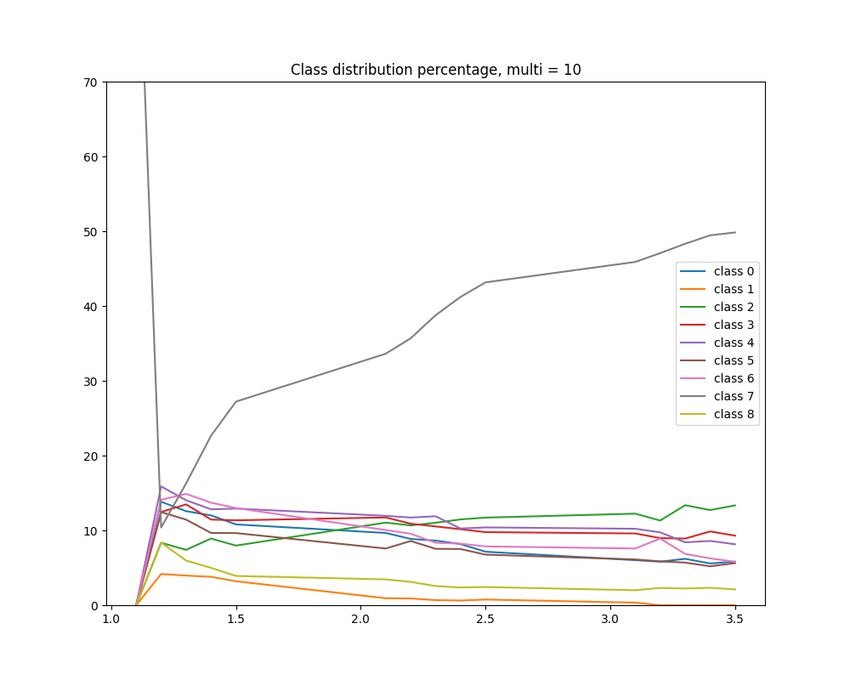
ABSTRACT OF THE THESIS
Unsupervised Classification and Network Analysis of the Reddit Communities
with Spiking Neural Network and Exponential-Family Random Graph Model
by
Jie He
Master of Science in Statistics
University of California, Los Angeles, 2021
Professor Yingnian Wu, Chair
The spiking neural networks (SNNs) are often described as the “third generation” of neural
networks, and they are expected to improve the existing deep neural networks. Recent
advancements of SNNs mainly focused on processing and learning the visual signals, while
SNNs’ potential in classifying non-image data is rarely tested. In this thesis, we extended the
functionality of BindsNET, a popular SNN simulation software, to allow it to process and
classify non-image data. We built an SNN that can efficiently classify the embedding data of
51,278 online communities (“subreddits”) on Reddit.com in an unsupervised fashion. With
the classification result, we further analyzed the social network structure of the subreddit
clusters of video games, using the exponential-family random graph model (ERGM). We
discovered that communities of the same video game genre or same platform are more likely
to be hostile towards each other. The number of subscribers and the availability of online
mode are also significant factors in the hostility of a subreddit.
ii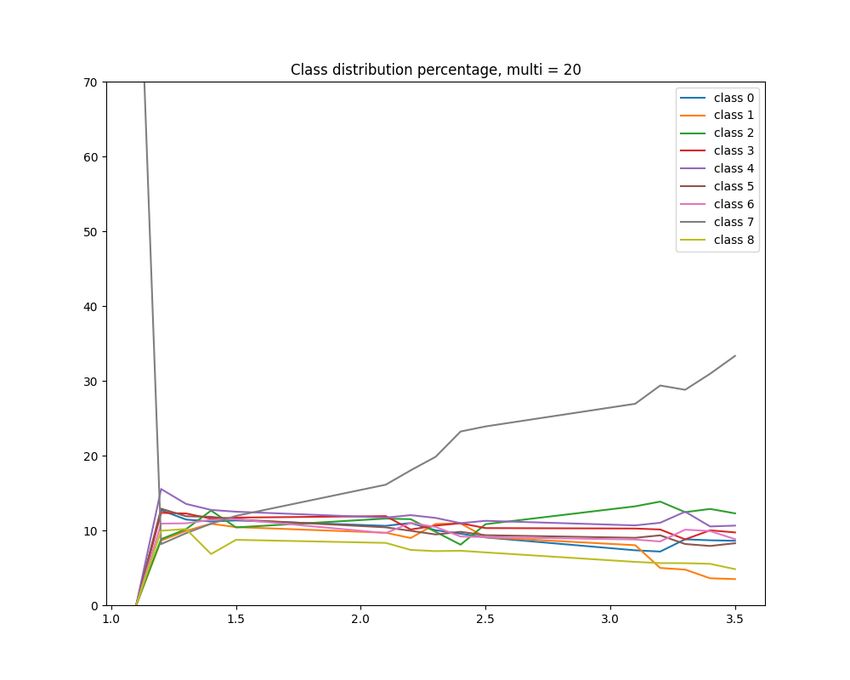
The thesis of Jie He is approved.
Qing Zhou
Guido Fra Montufar Cuartas
Yingnian Wu, Committee Chair
University of California, Los Angeles
2021
iii
To my parents
iv
TABLE OF CONTENTS
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1 Overview of the Spiking Neural Networks . . . . . . . . . . . . . . . . . . . . 1
1.2 Our Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Materials and Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1 Neuron Dynamics and Network Structure . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Leaky Integrate-and-Fire Model . . . . . . . . . . . . . . . . . . . . . 5
2.1.2 Learning Rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.3 Network and Software . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Data Description and Preprocessing . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Data Preprocessing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.2 Video Game Subreddit Attributes . . . . . . . . . . . . . . . . . . . . 12
2.3 Overview of Social Network and ERGM . . . . . . . . . . . . . . . . . . . . 13
3 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.1 SNN Training Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.2 Social Network Analysis on the Video Game Subreddits . . . . . . . . . . . . 28
3.2.1 Undirected Network Analysis . . . . . . . . . . . . . . . . . . . . . . 28
3.2.2 Analysis of Directed Network of Hostile Hyperlinks . . . . . . . . . . 32
3.2.3 ERGM analysis of Directed Hostile Hyperlink Network . . . . . . . . 33
3.2.4 MCMC Diagnostic . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
v
References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
vi
LIST OF FIGURES
2.1 Simplified illustration of the SNN. There are equal numbers of excitatory and
inhibitory neurons. An excitatory neuron receives all input spike trains, and
sends a spike to a unique inhibitory neuron. The corresponding inhibitory neuron
performs lateral inhibition by sending signals to the rest of excitatory neurons. . 8
2.2 Visualization of the subreddit embeddings. Each subreddit is colored based on
the clustering result of K-means algorithm. Point size reflects the number of
subscribers of a subreddit. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.1 Top: training set with multiplier = 1; Bottom: training set with multiplier = 10 18
3.2 Top: training set with multiplier = 30; Bottom: training set with multiplier = 40 19
3.3 Training accuracy over three epochs. . . . . . . . . . . . . . . . . . . . . . . . . 20
3.4 Three-epoch class distribution results with multiplier = 10. The proportion of
class 7 grew very fast, while the proportions of class 1 and class 8 quickly decreased
to zero. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.5 Three-epoch class distribution results with multiplier = 20. The proportion of
class 7 grew slower than the case for multiplier = 10. . . . . . . . . . . . . . . . 22
3.6 Three-epoch class distribution results with multiplier = 30. The network didn’t
overfit to class 7 until the later part of the second epoch. . . . . . . . . . . . . . 23
3.7 Training accuracy with different time setting. A 200ms observation time can
reduce overfitting, at the cost of a much slower training time. . . . . . . . . . . 25
3.8 Training accuracy of 400-neuron SNN. The result shows increasing the number
of neurons make SNN more resistant to overfitting, at the cost of more training
time and more GPU usage. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
vii3.9 Top: confusion matrix of test result after one epoch. Bottom: confusion matrix
of test result after three epochs. . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.10 Clustering result from trained two-layer SNN. . . . . . . . . . . . . . . . . . . . 28
3.11 Undirected network of video game subreddits. Left: Vertices colored by genere
(ACT: red; RPG: green; SIM: blue; STR: cyan); Right: Vertices colored by
platforms (console: red; mobile: green; pc:blue). Size of a vertex indicates the
amount of users. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.12 Left: distributions of degree centrality. Right: histogram of eigenvector centrality. 31
3.13 Visualization of the hostile hyperlink history network. Left: The entire network.
Right: the largest strong component. Vertices are colored by genre. . . . . . . . 32
3.14 Visualization of components of the hostile hyperlink history network. Left: the
largest weak component. Right: the second largest weak component. Vertices
are colored by genre. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.15 Traid Census. Figure from the lecture notes of Prof. Mark S. Handcock at UCLA
[Pro] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.16 MCMC diagnositic of the final model. The chains are mixing well and the simu-
lated statistics are distributed in a bell-shape around the target values. . . . . . 39
viiiLIST OF TABLES
3.1 Top 10 video game subreddits sorted by eigenvector centrality. . . . . . . . . . . 31
3.2 A summary table of the solution path. We built the model with increasing com-
plexity by separately examining the significance of each attributes and then in-
cluding the significant terms into our models. Note that with triad census in-
cluded, the model became worse. *: p-value is significant at 5%; **: significant
at 1%; ***: significant at 0.1%. . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.3 Triad distribution of the hostile subreddit hyperlinks data . . . . . . . . . . . . 37
ixCHAPTER 1
Introduction
1.1 Overview of the Spiking Neural Networks
Since the debut of AlexNet [KSH12] in the ImageNet image recognition competition in 2012,
the convolutional neural networks (CNNs) have become one of the focal points in machine
learning research. A typical convolutional neural network takes a real-valued input vector,
and passes it through multiple hidden layers of neuronal units. At each layer, the neurons
process the information based on the output of its previous layer and a connection weight
matrix. Then, a neuron uses a non-linear function such as ReLU and sigmoid to compute
the final output. As the number of layer increases, a CNN demonstrates impressive ability
to recognize different patterns of images. This architecture is an example of the “second
generation” of neural networks, according to Maass [Maa97]. On the other hand, a “third
generation” of neural network marks a step closer to the neuronal dynamics of human brains:
it integrates discrete input signals called spike trains, and fires its own spike trains to other
neurons. The integrate-and-fire model was first proposed more than a century ago [Lap07].
Since part of the success of the CNN can be attributed to its semblance to the visual receptors
on the human retina, it is reasonable to assume that SNNs, when properly implemented,
should outperform many state-of-the-art deep learning frameworks. Indeed, there are many
advantages of an SNN. For example, the first one is energy efficiency. Spike trains are
sparse signals in nature, and neurons in an SNN, unlike those in a CNN, can remain inactive
unless they receive a large amount of spikes in a short time window. Another benefit is the
additional temporal information encoded in the spike train. It has been observed that even
1a slight variation of the timings of incoming spikes can result in different responses of an
SNN [GKV96]. Consequently, an SNN can process complicated input data at a small cost of
energy, which draws a distinction with the current generation of continuous-real-value-based
neural networks.
Despite the promising outlook, the research and development on the SNN are still in
the early stage. The software options for SNN simulations remain limited when compared
to the support for CNN, and there is a lack of effective training algorithms that leverage
the power of the integrate-and-fire dynamics of spiking neurons. BindsNET [HSK18] is a
recently developed software package that incorporates many powerful PyTorch functionalities
into the SNNs. Compared with other simulation softwares such as BRIAN [SGB14] and
AURYN[ZG14], BindsNET offers a more user-friendly interface that allow researchers to
build and test different SNN architectures. More importantly, it utilizes the PyTorch libraries
to transfer the data to GPUs, resulting in more efficient computations. As for training
an SNN, the famous backpropagation [GBC16] algorithm cannot be directly applied to an
SNN, since the discrete signals are non-differentiable. Furthermore, the backpropagation
implies that higher layers in a neural network propagate the error signals through the same
connection used for propagating input signals. This “symmetric feedback” assumption may
not be valid for biological neural networks [LSM20]. Nevertheless, we have seen successes
in converting the discrete spike trains to continuous functions and performing supervised
learning on SNNs [ZG18]. Alternatively, the unsupervised learning rules like the spike-
timing-dependent-plasticity (STDP) [BP98] demonstrated its ability in training a simple two-
layer SNN that can classify the MNIST dataset in 2015 [DC15]. A recent re-implementation
of this network, called DiehlandCook network, is also available in BindsNET.
21.2 Our Work
The first part of our work is extending the functionality of BindsNET, allowing it to use non-
image data as training sets. Currently, BindsNET only supports benchmark datasets in the
popular TorchVision library. We built a new dataloader for BindsNET, which makes any .csv
files compatible with BindsNET. In addition, we provide a series of pre-processing functions
to handle the non-image data before they are sent to BindsNET. While SNNs are mostly
benchmarked on image recognition tasks, they are rarely used for classifying non-image
datasets such as word embeddings. For images, the pixel intensities can be proportional to
the frequencies when an image is encoded to Poisson spike trains, but as we will present
in the next section, the same process cannot be directly applied to the non-image data.
Specifically, we need a series of pre-processing steps, including clustering, cleaning and signal
amplification to make the data ready for training. We performed the pre-processing steps
on the embedding data of 51,278 online communities(“subreddits”) on Reddit.com [KHL18].
Then, we built and trained an SNN based on the DielandCook network, and achieved a
clustering result comparable to the K-mean clustering algorithm.
In addition to our work in data preprocessing and training an SNN, the classification
result is valuable in its own right. Combining our result with the Reddit Hyperlink Network
data [KHL18], we explored the social network structure of the subreddit clusters of video
games.1 Specifically, we are interested in the hostile relations among the video game sub-
reddit clusters. Reddit.com is a popular online discussion website, where registered users
can create and participate in discussions, or “posts”, within a subreddit. Every major video
game has its subreddit, and the interactions among different video game subreddits can be
complicated and often volatile. These interactions can be identified through the hyperlinks.
When a post contains a hyperlink, it is created within a source subreddit, and it points to-
ward the target subreddit. If the overall sentiment of the post is negative, then the hyperlink
1
This part is based on our work in STATS 218 at UCLA, taught by Professor Mark S. Handcock in the
spring of 2020 [Pro].
3indicates an attack from the source to the target subreddit. Otherwise, it may be considered
a peaceful interaction. The Reddit Hyperlink Network data contains the hyperlink history
across 36,000 subreddits from 2014 to 2017. We first selected the top 80 largest video game
subreddits from our clustering results. Next, we create a list of manually-examined attributes
for each subreddit. Then, based on the hostile hyperlinks data, we created a network among
these subreddits and modeled the network using a family of methods called the exponential
random graph models (ERGM) [HHB08].
4CHAPTER 2
Materials and Methods
2.1 Neuron Dynamics and Network Structure
2.1.1 Leaky Integrate-and-Fire Model
Unlike neurons in conventional neural networks, a spiking neuron in an SNN integrates
incoming spikes from connections called synapses. Each spike changes the membrane voltage
of the neuron, and upon reaching a voltage threshold Vthres , the neuron fires a spike to other
neurons. The membrane voltage is then reset to the resting potential Erest and enters a
refractory period during which no more spikes can be triggered. An improvement of such
neuronal model is called the leaky integrate-and-fire (LIF) model [DC15]:
Definition 2.1.1 (LIF model). A leaky integrate-and-fire (LIF) model is a type of biological
neuron model. The membrane voltage dynamics of a LIF model can be described as follows:
dV
τ = (Erest − V ) + ge (Eexc − V ) + gi (Einh − V )
dt
Erest is the resting potential. ge and Eexec are the conductance and equilibrium potential
of excitatory synapses. Similarly, gi and Einh are the conductance and equilibrium potential
of inhibitory synapses. τ is the time-constant. Here, the neuron is “leaky” in the sense that
the membrane voltage decays exponentially down to the resting potential if there is no input
current. A difference of the potentials in the excitatory synapse causes an input current to
increase the membrane voltage, and the inhibitory synapse causes the opposite effect.
5The spiking neurons are connected by synapses. When no spike is present, there is no
current in the synapse, since the potentials at both ends of the synapse are in equilibrium
state. However, when a spike arrives at “sender” side of the synapse (the presynaptic neuron),
the conductance g is instantaneously increased by the presynaptic weight w. The increased
conductance and a change in membrane potential result in an input current to the “receiver”
of the synapse, or the postsynaptic neuron. By default, the conductance decays exponentially
to zero:
dg
τg= −g
dt
where the choice of g and τg depends on whether the synapse is excitatory or inhibitory.
The overall dynamics of the spiking neurons can be describes as follows: input current raises
(or decreases) the membrane potential, the membrane potential causes the neuron to fire a
spike, the spike increases the synaptic conductance and makes neuron output a current to
other neurons.
2.1.2 Learning Rules
The learning of an SNN happens at updating the synaptic weights w of the network. A
famous unsupervised learning rule is the spike-timing-dependent-plasticity (STDP) [BP98].
In essence, the synaptic weights adjust automatically according to the relative timings of
the input and output spikes. If an input spike arrives right before an output spike, then
the synapse that connects the input and output neurons should be made stronger and vice
versa. A modification of the STDP, which was used in building the network in [DC15], can
be described as:
∆w = η(xpre − xtar )(wmax − w)µ
where each synapse contains additional information of recent spike history, or the synaptic
trace x. xpre is the presynaptic trace, recording the number of incoming spikes in the past.
xtar is the target value of synaptic trace when a postsynaptic spike is fired. By default, xpre
decays exponentially and is increased by one whenever a new presynaptic spike arrives. η is
6the learning rate, wmax is the maximum weight, and µ adjusts how much the weight should
update according to the previous weight. The weights are updated when a postsynaptic
spike arrives. If few recent presynaptic spikes are observed before a postsynaptic spike, then
the weight decreases. Hence, this update rule also tends to keep the connection sparse if the
postsynaptic spikes are rarely observed.
2.1.3 Network and Software
Here, we used a similar two-layer network as in [DC15]. As shown in Fig 2.1, there are two
hidden layers of LIF neurons. The first layer contains excitatory neurons and the second
layer contains an equal amount of inhibitory neurons. The excitatory layer is connected
to the input layer in an all-to-all fashion. This design is particularly useful for classifying
our non-image data, as a neuron in a typical CNN or a convolutional-style SNN [KGT18]
often has a much smaller receptive field. Each excitatory neuron sends signal to a unique
inhibitory neuron in a one-to-one fashion, and each inhibitory neuron sends signal to all
excitatory neurons except the one it receives signal from. The inhibitory neurons can prevent
excitatory neurons from being responsive to only one type of patterns in the input signal.
This mechanism is called lateral inhibition.
During the training period, each sample is presented to the network for a period of
time (100ms in our case). A batch of 32 samples are processed at the same time, and the
network is updated regularly. During the update period, each excitatory neuron is assigned
a label based on its the highest response to the different classes of inputs. The learning is
unsupervised, but we still need to provide labels for the training samples since they are used
to label the neurons in the SNN. Here, the word “unsupervised” means that at the final
layer, no error or loss function is computed, and no such information is sent back to the
hidden layers to adjust their connection weights. On the other hand, “supervised” means
the difference between predictions and true values help the hidden layers to adjust their
weights, usually by backpropagation. Through training, each neuron itself can learn various
7x1
x2
x3
x4
x5
Figure 2.1: Simplified illustration of the SNN. There are equal numbers of excitatory and
inhibitory neurons. An excitatory neuron receives all input spike trains, and sends a spike to
a unique inhibitory neuron. The corresponding inhibitory neuron performs lateral inhibition
by sending signals to the rest of excitatory neurons.
patterns by responding with different spike frequencies. The labels are used only to find
which pattern it receives can cause the most frequent spikes. To predict a class, the learning
is turned off, and the SNN classifies the input based on the highest response of different
classes of excitatory neurons.
We built our SNN in BindsNET, [HSK18] a recently developed SNN simulation software
that incorporates the strong functionalities of the PyTorch machine learning library. One
major improvement of the BindsNET is that it can transform the data into tensors and
use GPU to speed up the computation, while traditional SNN simulators only use CPU.
Additionally, BindsNET offers a more user-friendly interface and streamlines the process of
encoding image data to spike trains. Currently, it only supports loading the existing datasets
such as MNIST [LBB98] and CIFAR-10 [KH09] from the TorchVision library. We built a
custom dataloader that allows any data saved in .csv format to be processed into spike trains
and used for training an SNN.
82.2 Data Description and Preprocessing
We used two sets of data in our thesis. The 300-dimensional subreddit embedding data
were first introduced by Kumar et al. [KHL18] in their paper investigating the conflicts
and interactions in the web. Embedding is a feature learning technique that can transform
objects into vectors in high-dimensional spaces. For text data, a common embedding method
is the GloVe word-embeddings [PSM14]. Here, the author used the information from both
the users and communities to generate the embeddings of subreddits. The data can be then
visualized as in Figure 2.2 by principle component analysis(PCA) and t-SNE [MH08]. We
chose 70 principle components in the PCA step, which captured 95% of the total variance
of the data. Then, we performed t-SNE with perplexity equal to 100. The data points
were grouped and colored into 10 clusters based on the K-means algorithm [Llo82]. We
can observe from Figure 2.2 that the subreddits are naturally clustered into groups. The
clustering results are also used to help training the SNN.
The Reddit Hyperlink data were also created by Kumar et al. The data contain 137,113
hyperlinks between 36,000 subreddits from January 2014 to April 2017 [Pus]. The sentiment
of each hyperlink is classified by a random forest classifier into either hostile or neutral.
There are very few posts that show a clear friendly intent and as a consequence, the original
authors decided to merge the neutral and positive posts together into the neutral category.
Therefore, posts that are neutral are labelled as 1 and the direct attacks are labelled as −1.
2.2.1 Data Preprocessing
Preprocessing non-image data into spike trains suitable for our SNN model built in BindsNET
is a non-trivial task. Here, we describe a general scheme for preprocessing our subreddit
embedding data:
1. Performs a pre-training clustering. While the learning process is unsupervised, we still
need the labels to assign neurons in our network.
9Figure 2.2: Visualization of the subreddit embeddings. Each subreddit is colored based on
the clustering result of K-means algorithm. Point size reflects the number of subscribers of
a subreddit.
102. If the data contain both negative and positive values, create a positive part and a
negative part that only store non-negative values. This means the dimension of the
input is doubled.
3. For each cluster, examine the distribution of numerical values by creating a histogram.
Remove the cluster that contains only very small values. A sample in this cluster is
similar to a “white image” and our SNN cannot identify it.
4. For the remaining clusters, multiply the values by a number n, and convert them
into integers of range [0, 255]. Any value greater than 255 is set to be 255. n can
be arbitrary, but we should expect to see around 30% of values in most clusters are
greater than 200.
5. Check for imbalance in the training data, and apply balancing techniques such as
oversampling and undersampling.
6. Encode the data into Poisson spike trains and train the network.
As noted before, we still need labels to train the SNN, despite the fact that the learning
process is unsupervised. Hence, the first step is necessary. The second step is required
because the existing Poisson encoder in BindsNET only supports non-negative data. In fact,
one of many challenges facing the SNN today is that it can only read non-negative inputs
[PP18]. During our research, we discovered that simply adding a value to make all values
positive resulted in very poor performance of classification. Consequently, we traded space
for preserving more information of the data, and split each dimension into the positive and
negative parts.
The third step is important because we found that our SNN couldn’t identify input that
contains no signal. While our SNN architecture is proved to be able to recognize patterns
in images, there is not a default label for “nothing”. If the input contains essentially no
signal, then no spike is fed into the network, and hence no classification can be done. Such
11a sample is useless, and can be easily detected if it is an image. When it is not image, we
can use histogram to find which cluster of inputs contains no information. For the subreddit
embedding data, we identified that one cluster of size 32,336 contains very small values.
Including this cluster severely impacted the accuracy of our network, since all inputs from
this cluster were given a default label of class 7, according to the random initialization of
our network.
During training the network, we also discovered that the SNN required strong and sparse
signals to make a prediction. Strong and non-sparse input spike trains result in a random
guess of our network, since too many neurons in the hidden layers are activated. As for the
bound of [0, 255], this is the requirement of the toTensor function in the PyTorch library.
The toTensor function converts a dataset with integer values in [0, 255] to a tensor with
real values in [0, 1]. The tensor can then be sent to the GPU device for fast computation.
As a result, we have to multiply the remaining data by a large value, so that the desired
distribution of values is obtained. Unfortunately, doing so causes a loss of information, but
it turns out that by removing the cluster in step 3, we can multiply the inputs by a much
smaller number, and then preserve more information of the data.
If the training data are imbalanced, we can use standard techniques for data balancing.
Here, we used a simple resampling method to generate enough training samples for each class.
The Poisson encoder is available in BindsNET, and we incorporated it into our dataloader.
2.2.2 Video Game Subreddit Attributes
Once the data were classified, we focused our analysis on a particular cluster: the cluster
of video game subreddits. It’s important to include as much information about each video
game as possible. We selected the top 80 largest video game subreddits and added four main
attributes for each subreddit. All values were manually examined:
1. Count: numerical. The amount of registered users within the subreddit.
122. Genere: categorical. We classify the games into four main categories: action game(ACT),
role-playing game(RPG), simulation game(SIM) and strategy game(STR). The classi-
fication is based on the popular tags related to each game in major gaming websites
such as steam, metacritics and ign. When a game has multiple tags, we chose the most
popular tag.
3. Score: numerical. We used the review scores from metacritics. When a score is absent,
we estimate the score based on other review platforms such as google store, steam or
ign.
4. Platform: categorical. The platform each game supports. There are three categories:
console, pc and mobile. When a game has multiple platforms, we chose the earliest
platform a game supports.
5. Multiplayer: categorical whether a game supports multiplayer mode.
2.3 Overview of Social Network and ERGM
A network, or graph, can be described by two main components: an edge list and a vertex
set. In our networks, a vertex corresponds to a subreddit, and an edge corresponds to a
hyperlink between two subreddits. If all edges have directions, then the graph is directed.
Otherwise, it is undirected. We can better describe each vertex within a network by the
centrality measures. There are four common centrality measures for each vertex: degree
centrality, closeness centrality, betweenness centrality and eigenvector centrality:
1. Degree centrality: the number of edges connected to a vertex. When a graph is directed,
each vertex has an indegree and an outdegree, corresponding to the number of edges
pointing towards it or out from it. High degree indicates that a vertex is connected to
many other vertices.
132. Betweenness: the number of paths a pair of vertices must pass through a given vertex.
High betweenness indicates that a vertex lies in the shortest paths of many pairs of
vertices and it may have a strong control over the flow of information in a network.
However, this measure is less important in our network since the flow of information
among the gaming subreddits does not depend on the edges we defined.
3. Closeness: the distance of between a vertex and other vertices. High closeness value
indicates that a vertex is overall far from other vertices.
4. Eigenvector centrality: the eigenvector centrality measures the relative influence of a
vertex compared to other vertices. It is computed in a recursive fashion such that if
a vertex is connected to vertices with high eigenvector centralities, then it has high
eigenvector centrality as well. High eigenvector centrality value indicates that a vertex
is more important to the network, or receives more attention.
The ERGM, or exponential random graphical model, is a method that models network data.
Specifically, the model assumes that the probability of a given graph y, over the set of all
possible graphs Y is determined by
PK
exp( 1 θk gk (y))
P (Y |θ) =
c(θ)
where θk are parameters, gk (y) are statistics of the graph, and c(θ) is a normalizing constant.
To interpret θ, we can look at the log-odds ratio of a tie (or an edge) between vertices i and
j:
K
P (Yij = 1)
= exp( θk (gk (yij+ ) − gk (yij− )))
X
P (Yij = 0) 1
where yij+ is the graph that has an edge between yi and yj , with everything else fixed, and
yij− is the graph where there is no edge between yi and yj . Therefore, θk implies the impact
on the log-odds of a tie.
Once the formula is defined, we can use tools such as maximum likelihood estimation to
obtain the estimated values for each θk . However, a common problem in estimating ERGM
14is the so-called model degeneracy [HRS03]. Sometimes, we may obtain a set of parameters
that can’t correctly recreate the desired graph. Instead, only a small set of graphs with
extreme values are simulated. Without simulation we may fail to capture such problem
because the means of summary statistics can be close to the ones for the target graph. The
problem of degeneracy also shows the importance of simulation and verification for ERGMs.
One solution for the model degeneracy is the tapered ERNM [FH12]. In addition to ERGM,
penalty terms are included:
PK PK
exp( 1 θk gk (y) − 1 βk2 [µk (θ, β) − gk (y)]2 )
P (Y = y|θ, β) =
c(θ)
where β > 0 are vectors of hyperparmeters. When β = ∞, the model is the same as ERGM.
In practice, the tapered version is almost always preferred. We used the R packages ergm
and ergm.tapered for our analysis.
15CHAPTER 3
Results
3.1 SNN Training Results
We performed a K-means clustering on the 300-dimensional embeddings of 51,278 subreddits.
The data were clustered into ten classes, covering topics such as politics, entertainment and
gaming. The 300-dimensional embeddings were then converted to 600-dimensional vectors
containing only non-negative values. One cluster, which contains 32,336 samples which
contained values all very close to zero, was removed. For comparison, when the data are
scaled to real values in [0, 5], all values in this cluster are less than 1, while other clusters
contain values greater than 1. A clearer illustration can be seen in Figure 2.2. Data points
in the large cluster on the right side of the figure are loosely grouped, while the left portion
of the figure shows clear signs of clustering. Next, we reserved 10% of the remaining data as
our test set, and balanced the training set, resulting in a train set of 45,000 samples. Some
samples from the smaller clusters may repeat nine, or ten times in the balanced training set.
Next, we multiplied the training data by 1, 2, 5, 10, 15, 20, 30, 40 to obtain eight training sets
of different signal strengths. The class-wise distribution of some training sets are shown in
Figure 3.1 and Figure 3.2. From the figures, it is immediately obvious that the original data,
when scaled directly to integers in [0, 255], will result in poor classification accuracy since
none of the input sample can generate enough spikes to trigger responses from the excitatory
neurons. With a scaling factor of 10, some classes, namely class 2 and class 3 begin to show
moderate signals, while the values in the rest of the classes are still small. When we increases
the scaling factor to 30, most of the classes have around 30% of their values greater than
16200. However, increasing it further to 40 can be counter-productive, as strong signals (those
values greater than 200) are too dominant.
After obtaining the training sets, we trained our two-layer SNN with lateral inhibition
with a batch size of 32. The update interval is 256 batches. The neurons learn the data from
every batch, but the labels are assigned to them only at the update interval so that they have
seen enough data to adjust their weights. There are 100 excitatory and 100 inhibitory neurons
in the SNN. We ran the SNN on each training sets for three epochs. During each epoch,
a training accuracy was also computed after every 256 batches. As a result, five training
accuracy scores were computed for each epoch. We also enabled the SNN to output the
classification distribution along with the training accuracy to monitor the learning process
more closely. The training accuracy is shown in Figure 3.3. Since the first accuracy update
was computed before the SNN could assign labels to the excitatory neurons, all of our results
started at the same place. From the figure, we can see that the SNN trained on the original
data without any multiplication (or scaling) indeed performed poorly. On the other hand,
the figure indicates that increasing the multiplier (or scaling factor) can significantly improve
the training accuracy. The cost of information loss from multiplication only kicks in when
the multiplier is around 40. This result confirms our previous analysis on the histogram.
Based on the change of training accuracy, the two-layer SNN architecture performs the best
when there are around 30% strong signals, with the rest being close to zero. Additionally,
a multiplier equal to 30 implies that, when the data is scaled to [0, 1], any value greater
than 1/30 is set to maximum. This may seem to be very aggressive in scaling the data, but
according to the histogram in Figure 3.1, those values greater than 1/30 are so few that
ignoring the variance of those values hardly causes any loss of information. Instead, the
small variations of the samples, which are crucial in classification, are sufficiently amplified
so that the SNN can detect them.
One concern from the history of training accuracy is overfitting. Since the learning is
unsupervised, the training accuracy decreased across all datasets since the network overfit
17Figure 3.1: Top: training set with multiplier = 1; Bottom: training set with multiplier = 10
18Figure 3.2: Top: training set with multiplier = 30; Bottom: training set with multiplier =
40
19Figure 3.3: Training accuracy over three epochs.
20Figure 3.4: Three-epoch class distribution results with multiplier = 10. The proportion of
class 7 grew very fast, while the proportions of class 1 and class 8 quickly decreased to zero.
to a certain pattern in our training data instead of the labels. To further investigate the
problem, we collected the class distribution data at each accuracy update. We present the
distribution data for multipliers equal to 10, 20 and 30, as shown in Figure 3.4, 3.5 and 3.6.
Since our training set is balanced, the proportion of each class should stay around 11%.
An important observation from the distribution is that a larger scaling factor n helps pre-
venting the overfitting. The overfitting of the two-layer SNN happens when some classes
are not showing enough differences. This problem is apparent in histograms of Figure 3.1.
Class 1, 7 and 8 all contain few large values, making them seem similar to the SNN. Recall
21Figure 3.5: Three-epoch class distribution results with multiplier = 20. The proportion of
class 7 grew slower than the case for multiplier = 10.
22Figure 3.6: Three-epoch class distribution results with multiplier = 30. The network didn’t
overfit to class 7 until the later part of the second epoch.
23that all neurons were initialized to be class 7 by default. Initially, a slight difference among
these three classes can still be observed, and the excitatory neurons are labelled correctly.
However, due to the unsupervised STDP learning rule, as the training progresses, the strong
signals from other classes further enhance their corresponding synaptic weights between the
input and excitatory layers. On the contrary, the small signals from class 1,7 and 8 decrease
the synaptic weights to the point where excitatory neurons are no longer able to detect the
patterns in class 1 and 8 which they once can. When no sufficient signal is present in a
sample, the neuron will simply classify it to class 7 by default. Multiplying the small signals
in class 1 and 8 helps SNN detecting the pattern, but it seems the overfitting is inevitable.
There is a unique trade-off of overfitting and information loss in the case of our SNN: mul-
tiplying the value too little results in overfitting, but multiplying the value too much can
also cause a drop in accuracy. Our finding also disagrees with the classification result of the
MNIST data obtained by Diehl and Cook [DC15], in which the authors stated that such
SNN is quite robust to the overfitting problem. We attribute the problem to the nature
of data. Each sample in the MNIST contains sparse and strong signals thanks to its pixel
intensity values in a black-and-white image. When the pictures get more complicated, for
example, three-channel RGB images, SNNs with unsupervised learning rules perform much
worse than CNNs in classification task [PP18].
In order to address the overfitting problem, we also tried a few different settings in
training our network. The first parameter is intensity. The intensity parameter controls
the maximum frequency of input spike trains. Larger intensity results in more input spikes,
which is similar effect of our multiplication method. However, increasing the parameter can
reduce the training speed. No upper bound is set for the intensity, and therefore, when the
intensity is too high, the network receives too many input spikes to properly classify the
data. Consequently, instead of tuning the intensity, we recommend multiplying the data
before they are converted to tensors.
The second parameter is time. Time controls how long the neurons in the hidden layer can
24Figure 3.7: Training accuracy with different time setting. A 200ms observation time can
reduce overfitting, at the cost of a much slower training time.
observe a sample before they update their synaptic weights. For comparison, we trained our
SNN on the training set with multiplier = 50 first with time = 100ms (the default setting),
and then with time = 200ms. The result is shown in Figure 3.7. Indeed, the accuracy
increased slightly, and the network is more resistant to overfitting. However, by doubling
the observation time we essentially double the training time. A better device can simulate
an SNN faster, and give each neuron more time for each sample without drastically slowing
down the training. However, another challenge facing the current development of SNN is
the lack of specialized devices. It has been stated that, without the support of specialized
neuromorphic devices, increasing the simulation speed of SNN to more than one-tenth of
real time is difficult [ZG14].
Finally, we tested training the network with different numbers of neurons. Due to the
limit of our GPU device (NVIDIA GTX 1060), we can only train a network with at most
400 neurons in each layer. When comparing with the default setting of 100 neurons, a SNN
with more neurons takes more epochs to train, but are also more resistant to overfitting.
The accuracy history is given in Figure 3.8. Combining the above settings, we found that
25Figure 3.8: Training accuracy of 400-neuron SNN. The result shows increasing the number
of neurons make SNN more resistant to overfitting, at the cost of more training time and
more GPU usage.
the scaling factor n = 30 is the optimal choice for our subreddit embedding data, since it
gave the highest training accuracy throughout the training epochs. Fig 3.2, also suggests
that the factor n = 30 can sufficiently amplify the signals in the data without losing too
much information, as most classes have at least 20% strong signals (values ≥ 200). To reduce
overfitting, we only train the network for one epoch. Intensity, time, and number of neurons
are kept to default settings due to the limitation of devices. The training takes about 6
minutes to complete on a laptop with NVIDIA GTX 1060. The testing accuracy is 72%.
However, due to the imbalanced nature of the testing data, we present the confusion matrices
of test results for both epoch = 1 and epoch = 3. The matrices are normalized along the
true label, which are showed in Figure 3.9. In this figure, we can also observe the effect
of overfitting in longer training epochs. The testing result after one epoch shows a better
overall training accuracy than the one after three epochs. For the video game clusters (class
3), the SNN trained for one epoch correctly classified more testing data from this class.
The classification result from our SNN is shown in Figure 3.10, which is very similar
26Figure 3.9: Top: confusion matrix of test result after one epoch. Bottom: confusion matrix
of test result after three epochs.
27Figure 3.10: Clustering result from trained two-layer SNN.
to Figure 2.2. In fact, combing results with the removed cluster, we achieved an overall
accuracy of 89%. This result is quite impressive, considering that our network is trained for
only one epoch.
3.2 Social Network Analysis on the Video Game Subreddits
With the clustering result from both K-means and SNN, we are now ready to perform the
network analysis on the cluster of video game subreddits.
3.2.1 Undirected Network Analysis
While it’s more interesting to analyze the directed versions of the network, we believe the
undirected version shows the general activity pattern among the subreddits, and the amonnt
28Figure 3.11: Undirected network of video game subreddits. Left: Vertices colored by genere
(ACT: red; RPG: green; SIM: blue; STR: cyan); Right: Vertices colored by platforms (con-
sole: red; mobile: green; pc:blue). Size of a vertex indicates the amount of users.
of attentions each community receives. The activity information can be summarized readily
by the four centrality statistics introduced in the previous chapter.
As seen in Figure 3.11, we can already observe some interesting facts about the video
game communities. In both figures, large gaming communities tend to cluster together in the
center of graphs. However, different genres of game have different impacts on the clustering
of the communities. The ACT (red) communities tend to cluster together, while the RPG
(green) communities are more distant to each other. There is almost no clustering among
the SIM (blue) communities, and there is only one large STR (cyan) community, with a few
small STR communities around it.
The difference in clustering can be explained by the similarities among games in different
genres. The action (ACT) games, as the name suggest, are all about fast actions and intense
fighting. While the backstories behind the action games can vary, they do not constitute
the main part of the gameplay. Players who enjoy one fast-paced ACT game can often
29transfer their skills and mechanics (a term used among the gaming communities, meaning
the ability to swiftly perform precise and challenging in-game movements) to other ACT
games. Role-playing games (RPG), on the other hand, are story-driven games. A player
who loves one RPG may not like the plot of another RPG. But the role-playing element
is shared across all RPGs. Then, the simulation games (SIM) have much more variance in
terms of gameplay. For example, City: Skylines and American Truck Simulator are both
simulation games. It’s hard to predict whether a player who loves driving a virtual truck is
also going to find enjoyment in building a city. Lastly, for the strategy games (STR), the
themes can also vary, but the clustering is less obvious on the graph.
For the platforms, a majority of the members in the communities are pc users (blue)
and they tend to stay close to each other. The exclusive console players (red) are more
separated. There is only one large mobile game community (green), the r/clashroyale. This
phenomenon can be explained by the nature of these platforms. Most games can run on pc,
but different consoles have exclusive games, meaning those games can only be played on the
consoles from one company.
The distribution of degree centrality, eigenvector centrality are give in Figure 3.12. A
summary of the the top ten subreddits, ranked by their eigenvector centrality, is given in
Table 3.1.
We can see that there are clear outliers in the distributions of degree centrality and
eigenvector centrality, indicating a few subreddits receive most of the attentions in the video
game communities. From the table, games that have high eigenvector centrality tend to have
a large userbase and generally well-received. However, we need to give special attention to
two games: Overwatch and tf2 (Team Fortress 2). The reddit hyperlinks data were gathered
in 2018, and they include data in the previous 40 months. The game Overwatch was released
in 2016. Thanks to its unique gameplay and detailed character designs, the game received
overwhelmingly positive reviews and became the most popular game in 2016. The gameplay
of Overwatch has its root in Team Fortress 2, a relatively old shooting game. It’s then not
30name degree eigen population genre review platform
overwatch 46 0.29 3,434,718 ACT 91 pc
leagueoflegends 37 0.26 4,913,911 ACT 78 pc
hearthstone 36 0.24 1,738,100 STR 88 pc
dota2 34 0.23 791,740 ACT 90 pc
tf2 31 0.21 507,417 ACT 92 pc
smashbros 30 0.20 848,418 ACT 93 console
wow 25 0.19 2,041,493 RPG 93 pc
globaloffensive 27 0.19 1,224,110 ACT 83 pc
destinythegame 31 0.18 1,960,399 ACT 78 console
smite 21 0.17 267,805 ACT 83 pc
Table 3.1: Top 10 video game subreddits sorted by eigenvector centrality.
Figure 3.12: Left: distributions of degree centrality. Right: histogram of eigenvector cen-
trality.
31Figure 3.13: Visualization of the hostile hyperlink history network. Left: The entire network.
Right: the largest strong component. Vertices are colored by genre.
surprising to see that the relative small community of Team Fortress 2 also received a lot
of attention during the 40-month period. The moral of the story is that our network model
can only summarize the activity patterns generally. When dealing with specific cases, it’s
important to look at the history of those video games. Nevertheless, our undirected network
is a good starting point for finding the outliers.
3.2.2 Analysis of Directed Network of Hostile Hyperlinks
As described in the previous chapter, the Reddit Hyperlink data contain either hostile or
non-hostile (neutral/friendly) hyperlinks. We used the hostile hyperlinks portion of the
data. Then, we created and analyzed the network of the hostile relations among the video
game subreddits. In Figure 3.13, we visualized the entire network(left), the largest strong
component in the network(right). The largest weak component is shown on the left of Figure
3.14 and second largest one is on the right. Overall, the hostile hyerplinks are rare. This
can be seen by the large amount of isolated points in the entire network. Furthermore, it’s
32Figure 3.14: Visualization of components of the hostile hyperlink history network. Left: the
largest weak component. Right: the second largest weak component. Vertices are colored
by genre.
also rare for subreddits to retaliate. Two vertices are connected strongly if they have edges
pointing towards each other, and in our case, meaning two subreddits attacked each other in
the past. Otherwise, two vertices are connected weakly. However, in our component analysis,
the largest weak component contains 40 members, while the largest strong component has
only 11 members. The 11 video game subreddits can be nicely clustered by their genres.
ACT communities are quite volatile, and sometimes a few STR communities join the fight as
well. The large RPG communities tend to stay far from each other, so are pretty peaceful.
One exception is the second-largest weak component shown in Fig 3.14, which is mainly
compirsed of RPG communities. It also seems that SIM players are the most peaceful.
3.2.3 ERGM analysis of Directed Hostile Hyperlink Network
The next step is to fit our network data by ERGM. In particular, we chose the tapered
ergm method to avoid model degeneracy. With the attributes described above, we can start
33count model genre and gwesp platform multiplayer
edges -19.6*** -12.86*** -14.05*** -14.13***
nodecov.count 0.57*** 0.28*** 0.32*** 0.27***
gwesp.fixed.0.5 1.77*** 1.61*** 1.53***
nodematch.genre.ACT 0.71** 0.7** 0.59**
nodematch.genre.RPG 1.06* 1.06*** 1.34***
nodematch.genre.SIM 2.34*** 2.46*** 2.9***
nodematch.genre.STR 1.55* 1.58* 1.49*
nodematch.platform 0.70** 0.75**
nodefactor.multi.t 0.76**
triadcensus.111D
triadcensus.111U
AIC 798.6 732.9 730.5 719.8
Table 3.2: A summary table of the solution path. We built the model with increasing
complexity by separately examining the significance of each attributes and then including
the significant terms into our models. Note that with triad census included, the model
became worse. *: p-value is significant at 5%; **: significant at 1%; ***: significant at 0.1%.
34by determining the significance of each attribute, and then gradually increase the model
parameters by combining the significant attributes. In addition, we included the terms
gwesp and triadcensus. We used the AIC for model selection, and a summary of our
solutions is given in Table 3.2. A detailed explanation of each variable is given as follows:
Count. The population of each community. One problem we encountered during mod-
eling is that the variance of the counts was so large that ergm.tapered() function could
not find an estimation. To solve this problem, we took the natural log of the population.
Then, the parameters for log(count) is almost always significant in our selection of models.
This result should be intuitive, as more registered users indicate a higher overall activity.
However, we have to note that by taking the log, the population has a linear effect on the
odds of a tie, instead of the usual exponential effect.
Review. The review score of each video game. This term is not significant in any of
our models.
Genre. The genre of the game. We checked three types of effect separately: nodefactor,
the effect of forming a tie based on the genre. nodematch checks the homophily effect of
each genre. nodemix checks the effect of forming a tie that links two subreddits of different
genres. During our estimation, we found that nodefactor has a moderate effect(p−value
= 0.04) only for the RPG genre. The coefficients for the nodemix didn’t converge, possibly
due to the limited amount of hyperlinks data. Fortunately, the nodematch coefficients are
always significant, and each genre has a different coefficient. When we ignored the difference
among the genres, the model became less accurate.
Platform. We repeated the same process for the genre variable. Similarly, only the
nodematch appeared to be significant, and the model was better when we ignored the dif-
ference effects of homophily among different platforms.
Multiplayer. Whether a game supports multiplayer mode. This effect appeared to be
significant in all our models.
35gwesp. gwesp stands for geometrically weighted edgewise shared partner distribution.
When two vertices are both connected to a vertex, they have a shared partner. A pair of
vertices can have many shared partners, but they are not necessarily connected themselves.
However, when they connect, they will close out many “triangles” in the network. The
term gwesp measures the effect of shared partners on the probability of forming a tie. The
geometrically weighted part adds a decay factor to the number of shared partners so that
the effect can’t grow out of control. It has been shown that in practice, it’s often beneficial
to include gwesp or similar terms in the model [Hun07]. In our case, the term is always
significant in our models.
Triad census. For directed networks, there are 16 types of triads categorized by David
and Leinhardt [DL67] as 003, 012, 102, 021D, 021U, 021C, 111D, 111U, 030T, 030C, 201,
120D, 120U, 120C, 210, and 300. Graphical representation of these triads is given in Fig 3.15.
A common phenomenon in an hostile relationship network is the large presense of intransitive
triads. These triads are inherently unstable in a friendship network, as friendship is often
mutual. On the other hand, attacks are often initiated from one side and not retaliated. A
summary of the distribution the triads are given in Table 3.3, where we can observe that
after excluding the trivial (or vacuous) triads, most of the triads are intransitive. However,
although they are significant when we model the network with only intransitive triads, they
appear to be non-significant in the final model, and worsened our model fit.
As a result, the final model contained edges, user counts, gwesp with fixed decay, ho-
mophily for genre and platforms, and the multiplayer support. The final model achieved an
AIC score of 719.8 out of the total 24 models we tested.
3.2.4 MCMC Diagnostic
After estimated the coefficients, we tested the goodness-of-fit of our selected model by run-
ning MCMC simulations. The diagnostic graphs are shown in Figure 3.16. Overall, the
chains are mixing well and the simulated statistics are distributed in a bell-shape around
36Figure 3.15: Traid Census. Figure from the lecture notes of Prof. Mark S. Handcock at
UCLA [Pro]
Triads 003 012 102 021D
count 77221 3984 761 27
Triads 021U 021C 111D 111U
count 30 52 40 23
Triads 030T 030C 201 120D
count 1 0 7 1
Triads 120U 120C 210 300
count 4 4 4 1
Table 3.3: Triad distribution of the hostile subreddit hyperlinks data
37the target values. There is no degeneracy found in the model. For deviance, after the model
fit, we obtained a residual deviance of 701.8 on 6311 degrees of freedom. Compared to the
null deviance which is 8761.4 on 6320 degrees of freedom, our model captured most of the
information about the network data with 9 parameters.
38Figure 3.16: MCMC diagnositic of the final model. The chains are mixing well and the
simulated statistics are distributed in a bell-shape around the target values.
39CHAPTER 4
Conclusion
We chose the subreddit embedding data and the Reddit hyperlink data as the foundation of
our research. First, we explore the possibility of classifying the 300-dimensional subreddit
embedding data using a two-layer spiking neural network. During our research, we extended
the functionalities of BindsNET, a PyTorch-based SNN simulation software. We built a two-
layer spiking neural network with lateral inhibition that can load and encode the training data
to tensors for efficient computation. In addition, our network can output various diagnostics
such as class distribution and accuracy that allowed us to select the best settings of the neural
network. We described a scheme that allowed us to preprocess the non-image embedding data
that could be successfully used as a training data for the SNN. We discussed the problems of
overfitting and training speed facing the current version of SNNs with unsupervised STDP
learning rule.
After obtaining the clustering result, we switched our focus to the social network analysis.
Specifically, we selected the top 80 largest video game subreddits from our clustering result,
and added new attributes for each subreddits. First, an undirected network analysis is
performed to explore the structure of network. Then, we applied ERGM to model the hostile
relationship among the subreddits. With AIC as our guide, we selected the best model from
which we concluded that population, subreddits of the same video game genre, same platform
and the multiplayer mode are significant factors in causing a hostile relationship.
40You can also read

















































