Transformation of a single-user system into a multi-user system with Swift
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
DEGREE PROJECT IN TECHNOLOGY,
FIRST CYCLE, 15 CREDITS
STOCKHOLM, SWEDEN 2022
Transformation of a
single-user system
into a multi-user
system with Swift
KTH Bachelor Thesis Report
Karl Janrik, Oscar Ekenlöw
KTH ROYAL INSTITUTE OF TECHNOLOGY
Chemistry, Biotechnology and Health

I| Abstract Headlong Developments’ application HeadmasterDev is currently adapted for a single user. To turn their application into a multi-user system the programming language Swift will be used. Furthermore, this thesis will evaluate whether Swift is an appropriate programming language for developing a server application, how to handle concurrency of shared resources and if it is possible to deploy the application on a operative system other than macOS. The result is that the concurrency model is dependent on the system’s needs and that one should not commit to using Swift as the programming language for a server application, with some regard to the size of the application and it’s uses. Keywords Swift, Vapor, Kitura, Perfect, Concurrency Control, Locking
II |
III | Abstrakt Headlong Developments applikation HeadmasterDev är endast anpassad för en användare. För att kunna transformera deras applikation till ett fleranvändarsystem så kommer detta arbete att använda sig av programmeringsspråket Swift. Utöver detta kommer det även undersökas om programmeringsspråket Swift är lämpligt för denna typ av applikation, hur man bäst hanterar samtidighet av delade resurser och om det är möjligt att använda applikationen på en annan plattform än macOS. Resultatet kom att bli att hur man löser samtidighetsproblemen beror på systemets behov och att Swift inte är lämpligt för denna applikation med tanke på dess storlek och användningsområden. Nyckelord Swift, Vapor, Kitura, Perfect, Samtidighetskontroll, Låsning
IV |
V| Acknowledgements This paper is a result of a thesis project within the field of computer engineering, at KTH Royal Institute of Technology, for CDDH Centre for Data Driven Health. We want to thank our supervisor Reine Bergström for his guidance, support, and suggestions during this project.
VI |
VII | Transformation av ett system för en användare till flera användare med hjälp av Swift Kandidatuppsats Karl Janrik Oscar Ekenlöw
VIII |
Authors Karl Janrik and Oscar Ekenlöw Degree Programme in Computer Engineering KTH Royal Institute of Technology Place for Project Stockholm, Sweden Flemingsberg Examiner Ibrahim Orhan Chemistry, Biotechnology and Health KTH Royal Institute of Technology Supervisor Reine Bergström Chemistry, Biotechnology and Health KTH Royal Institute of Technology Trita TRITA-CBH-GRU-2022:051
X|
XI | CONTENTS Contents 1 Introduction 1 1.1 Problem Statement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1.2 Aim and Research Questions . . . . . . . . . . . . . . . . . . . . . . . . 2 1.3 Limitation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 2 Theory and previous work 5 2.1 Concurrency in a Distributed System . . . . . . . . . . . . . . . . . . . 5 2.2 Distributed Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 2.3 Container Technology . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 2.4 Securing A Distributed System . . . . . . . . . . . . . . . . . . . . . . . 14 2.5 Authentication Technologies . . . . . . . . . . . . . . . . . . . . . . . . 17 2.6 Change Detection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 2.7 Version Control . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 2.8 Conflicts when Controlling Multiple Versions . . . . . . . . . . . . . . . 22 3 Methodology 23 3.1 Literary Study and Pre-Study . . . . . . . . . . . . . . . . . . . . . . . . 23 3.2 Swift . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 3.3 Choice of Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 3.4 Development of the Prototype . . . . . . . . . . . . . . . . . . . . . . . 33 4 Result 39 4.1 Version Control of Definitions . . . . . . . . . . . . . . . . . . . . . . . 39 4.2 Concurrency . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40 4.3 Vapor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40 4.4 Security . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41 4.5 Deployment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 4.6 The HeadmasterDev Application . . . . . . . . . . . . . . . . . . . . . . 42 4.7 Headmaster Server Application . . . . . . . . . . . . . . . . . . . . . . . 43
XII | CONTENTS 5 Analysis and Discussion 45 5.1 Swift as a Server Application . . . . . . . . . . . . . . . . . . . . . . . . 45 5.2 Deploying the Application . . . . . . . . . . . . . . . . . . . . . . . . . . 45 5.3 Concurrency Control . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46 5.4 Security . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47 5.5 Economic, Social, Ethical and Environmental Aspects . . . . . . . . . . 47 6 Conclusion 49 6.1 Goals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49 6.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51 References 53
1 | INTRODUCTION 1 Introduction Many applications are designed for single users, i.e. that they allow changes to be made to resources by one user at a time. Recently, however, a need for multiple-user systems has arisen. For instance, as a team collaborates, there is a need for allowing all members to make changes to resources concurrently. One application that allows for a single user experience is the HeadmasterDev application, designed by Headlong Developments. This application intends to create definitions on a variety of different subjects, such as rules, events, phenomenon, and eventually more. Headlong and KTH has together started a center for research and development to make the system work in a healthcare environment. The intention is to make the system work similarly to FASS, which is a database of drugs and medications [1]. The HeadmasterDev application is intended to be used to create unique definitions in all areas related to healthcare. As the application is intended to be used by multiple users collaborating to create different concepts, there is a strong need for the ability to handle multiple concurrent users. This work aims to design a server application for Headlong, which allows for their application to be used by multiple users. 1.1 Problem Statement Headlong is looking for a system with a database, user authentication and conflict management. They want their already existing system to be expanded to allow for a multi-user experience, either by applying the changes directly to their current application or to add a separate server application. This thesis evaluates how to implement these changes and whether these changes can be made in the Swift programming language.
2 | INTRODUCTION
This thesis will also evaluate whether it is possible to build a transparent server
application in Swift which can handle multiple concurrent users. To build this
application, an appropriate method to use in order to handle multiple versions
of shared data will be evaluated. How will the changes made affect the current
HeadmasterDev application? Will Swift, as a hybrid of functional and object-oriented
programming language [2], be suitable in a distributed system?
1.2 Aim and Research Questions
This thesis evaluates the maturity of Swift as a programming language as well as ways
of concurrency control of documents. In order to answer these research questions,
four sub-goals were set:
– Examine if it is possible to write an application in the programming language
Swift that can handle multiple users concurrently with version control.
– Test if it is possible to use this application in a container environment, such as
Docker, and if it will run on an operating system other than macOS.
– Investigate how to best handle conflicts from different versions of a document
that need to be merged together. Are there multiple ways to solve this and what
is the best option?
– Examine whether the prototype meets any requirements for security and
efficiency. Does the server block unauthorized access?3 | INTRODUCTION
1.3 Limitation
This thesis will have the following limitations:
– Conflicts will only be detected and not automatically solved.
– The changes made to the existing HeadmasterDev application will only show
that the communication with the server application is possible.
– The work will focus on whether it is possible to develop an application, in the
programming language Swift, with multi-user support, that is secure and able
to handle concurrency issues.4 | INTRODUCTION
5 | THEORY AND PREVIOUS WORK 2 Theory and previous work This chapter will provide theory necessary to understand distributed architectures, version controlling architectures and how to detect changes in different versions of documents. Many components are required to build a system which provides users with a desired service. The complexity of a system increases with its size, and this chapter brings up techniques used to manage and scale these systems while still maintaining a correct and understandable structure. The service, which the system will provide, is the ability to look at and manage different versions of documents simultaneously. This service comes with some difficulties, such as concurrency control and how to detect changes done to a document. In order to provide these services, a study was conducted on how to handle multiple concurrent users and what algorithms can be used to find the difference between documents that have been sent to the system. The security of a system cannot be overlooked and because of this requirement, both techniques and technologies in security were studied. The purpose of these techniques is to validate the authenticity of a user and to assure that their role grants access to system resources. 2.1 Concurrency in a Distributed System There are two main categories used to handle concurrency in a distributed system, divided into optimistic or pessimistic approaches. An optimistic approach is used when the likelihood of conflicts is low and you only check for conflicts in order to handle them when they happen. Pessimistic approaches use different methods prevent conflicts from ever happening [3].
6 | THEORY AND PREVIOUS WORK
2.1.1 Optimistic Concurrency Control
With an optimistic protocol the presumption is that most transactions will not conflict
with each other. Transactions are always allowed to read values and are then
validated if they want to write to memory [3].
Each transaction is validated just before the write phase. A transaction is divided into
three phases;
– Read: The value is read from memory into a private workspace.
– Validation: The modifications to the value are done and ready to be
committed into memory. An algorithm checks whether the commit conflicts
with other concurrent transactions or not. If a conflict exists, the whole
transaction is aborted and restarted. The private workspace is also cleared.
This will continue until the transaction is no longer in conflict with other
transactions.
– Write: The transaction passes the validation phase. The transaction’s private
workspace is copied into memory.
This method has three main problems. For one, the degrees of parallelism is high,
which creates a greater risk of unnecessary restarts. Rather it would be desirable
to avoid restarts of transitions that do not endanger serializability. Secondly, long
transactions also have an increased risk of being subject to restarts because they
take longer than the average transaction. A long transaction should have the same
opportunity as a short transaction to write to memory. Lastly, with the reliance on
rollback, a problem called starvation can occur. This is when the transaction queue
never gets to commit because it is always waiting for other transactions [3].
To solve this, timestamp optimistic concurrency control was developed. It uses the
same three phases - Read, Validation and Write. The data sets, on which an operation
is attempted, need to go through validation before they can be read from or written7 | THEORY AND PREVIOUS WORK
Figure 2.1: Flowchart of the timestamp validation algorithm
to the database. See figure 2.1 for a flowchart description.
Read and write operations impose at least one condition which needs to be validated.
The first condition which needs to be true in order to execute the operation is checking
if the current transaction is in serial position of the last made transaction, i.e was
the transaction made after the last made transaction. Should this not be the case,
two more conditions are introduced. The first of these checks whether there are any
write-to-write conflicts, and the second checks whether there are any read-to-write
conflicts. If the validation comes out successfully, the read or update operation takes
place [3].8 | THEORY AND PREVIOUS WORK 2.1.2 Pessimistic Concurrency Control A Pessimistic Concurrency Control (PCS) works under the assumption that transactions will be in conflict with each other. They check for a conflict very early in the execution process of an operation, or they try to prevent there ever being conflict in the first place. Lock-based concurrency is a pessimistic approach in which one operation may proceed with a transaction if there is no other transaction holding the lock. A writing- lock may only be kept by one transaction at a time. A reading-lock may be kept by several transactions, but there may not be any transactions holding a writing- and reading-lock at the same time. When the transaction holding the lock is done with its conflicting operation, the lock is released allowing the next transaction to proceed. For a system in which there are many transactions, this means that there will be a great chance for each transaction being blocked and having to wait for the lock to be released. This wastes a great deal of time in a system with low chance of conflicts [3]. Timestamp ordering can also be used in a pessimistic approach to concurrency control. The difference between the optimistic and pessimistic approach to timestamp ordering is that in the pessimistic approach, the transaction is immediately aborted upon detection of conflicts [4]. 2.1.3 Real-time Concurrency When multiple users are looking and changing a document there are, as presented, multiple ways to handle the change. If there is a need for users to change parts simultaneously, a locking strategy will not give users access. Jung et al. suggest to use a View-centric Operational Transformation [5]. View-centric Operational Transformation solves problems that pure Operational Transformation encounters. When the size of the document or file grows and the
9 | THEORY AND PREVIOUS WORK number of users editing grows, the number of changes or operations increases. Scalability is limited due to the increase in operations needed. Jung et al. suggests adding a history buffer for operational transformation for each user connected and instantly accept the invoked operation related to where they are watching. Other operations are put in to a low priority buffer [5]. 2.2 Distributed Architecture A distributed system is a system in which two or more processes communicate with each other in order to provide the service desired by a user. Today there are many techniques to choose from when designing a distributed system. The following sections will describe some architecture patterns in order to design a distributed system, such as Server Oriented Architecture, Three Tier Architecture and Serverless Architecture. 2.2.1 Service Oriented Architecture Service oriented architecture (SOA) is an area in which much progress has been made, especially in web services. SOA could be described as a high level platform, but it could also be described as an approach when developing a system. These types of architectures are typically used in distributed systems, in which this architecture describes where each of the different units of a system should apply their functionalities, and how to separate them [6]. The concept of a service is not to be described as a component, since the service is supposed to be separated from technical frameworks and their programming languages. The definition of a service is dependent upon the perspective of the one who describes it. As a consumer of the system, the service is a series of transactions and business rules providing one with the desired functionality. From a technical perspective, the service is a functionality accessible as unit or interface. [6]. The services could be called a packaged format of the software resources, where these
10 | THEORY AND PREVIOUS WORK resources are modules which provide the necessary business functionality. Each service is isolated from other services’ states. Through SOA, one can describe the system’s design in order for the customer to receive the requested services. Large enterprises can use SOA in order to design, develop and maintain their applications in an efficient and cost-effective manner [7]. 2.2.2 Three Tier Architecture The Three Tier Architecture is one of many architecture patterns which describes the general structure of an application. This pattern, visualized in figure 2.2, is characterized by its three tiers; presentation-, business- and data tier. Each tier holds its own responsibilities towards the application’s functions. The presentation tier is responsible for presenting an interface towards the user. The business tier holds the business rules, the logic behind a specific function and the core of the application. The last tier, the data tier, is responsible for data persistence. It is responsible for retrieving the data from a data source, and in that manner, hiding the implementation from the business tier. By dividing the application into these tiers, the business- and data tiers are hidden from the users and the business tier has no connection to how the persistence is implemented [8]. 2.2.3 Monolith Architecture A monolithic application is an application in which the entire system can be found in a single executable. These monolithic applications are usually very large, as they offer several services - many with different interfaces. The application can be under very heavy pressure during peak periods, as all the services come through the same application. Since all services and their codes are in the same repository, when a change is made, it has to be guaranteed not to interfere with other services. As more services are added, this becomes hard to assure and the complexity of the application increases.
11 | THEORY AND PREVIOUS WORK
Figure 2.2: Visualization of Three Tier Architecture
This can then become limiting when trying to implement new features. Should
one implementation crash the service, all other services will go down at the same
time.
To scale a monolithic application can be very challenging, since they usually provide
several services, where some are more popular than others. This means that when
one scales up the services with more traffic the other services are scaled up as well,
regardless of whether they need it or not. Monolithic applications also have the
drawback that, when the application is deployed, all services become unavailable as
the whole application needs to be built. This in turn also affects the total build-time
[9].
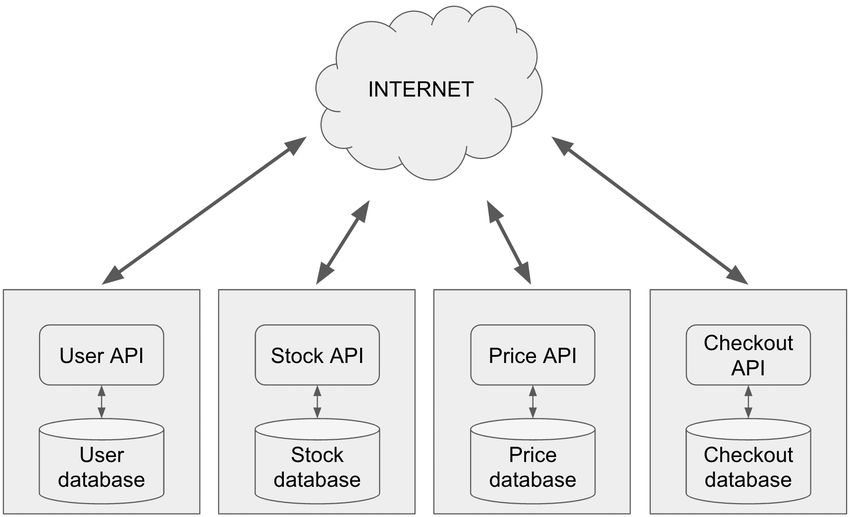
2.2.4 Microservice Architecture
Microservice applications is a design pattern in which the application is separated
into different services, all responsible for a single area of the complete system. Each
application is a small standalone program that is self-controlled. Each service is able
to evolve independently from each other and chooses its own architecture, platform,12 | THEORY AND PREVIOUS WORK
hosting provider et cetera [10]. For example as seen in figure 2.3, in an online store,
checkout workflow could be an independently managed entity, completely separate
from the microservice in control of the stock and prices.
Figure 2.3: Example of a Microservice design
Each application must independently scale and deploy, they cannot share containers,
caches or datastores with other applications. The goal of a microservice architecture
is to have applications that are not tied to other applications and therefore be able to
scale independently and when necessary [10].
Microservices are communicating using internet communication protocols, such as
HTTP, and follows the REST standard to provide APIs to others in the network. Each
application is normally constructed according to the three-tier architecture with an
interface layer, a business layer and a data persistence layer, and with a much smaller
bounded context than a SOA implementation [10].13 | THEORY AND PREVIOUS WORK 2.2.5 Serverless Architecture As cloud computing rises in popularity, serverless computing is used more frequently. The architecture of a serverless application can be separated into triggers and actions, i.e events and functions. The execution of the application is on a separate platform, which provides seamless hosting. The developer can then expose the application through an API. The developer needs no concern for the run time environment or the server itself. The term serverless comes from the fact that the price is only increased as the resources are in use. The resources are consumed at the point of execution, which are released after the function has completed [11]. 2.3 Container Technology A container is an isolated environment in which an entire application is held. As the application is run in several different environments, the isolation removes the issues of migrating between different operating systems, software and hardware which they achieve by virtualization of the operating system itself. The virtualization provides the application with a completely separate area of execution [12]. The Open Container Initiative (OCI) was founded June 22nd 2015. It was founded by leading companies in the container industry, such as Docker and CoreOS. The OCI has two specifications, one controlling the runtime and one controlling the image specifications. The runtime specification describes how the file system should run and the image specification describes how an image should be created [13]. 2.3.1 Docker Docker is an open-source platform. Its main purpose is to place packages and applications into a container. A container is an isolated environment in which an entire application is held. The application inside the container is completely
14 | THEORY AND PREVIOUS WORK separated from the machine’s running operating system. A docker image is the underlying requirements in order for the docker container to run. A base image is an operating system such as Ubuntu or Fedora. These base images can be built upon with applications or other to get an image with a purpose. The image can be built by using a read-only template or to create a docker file. The docker file contains instructions on what to download when the image is loaded [14]. 2.3.2 Kubernetes Kubernetes is a container management system designed by Google, which adopted the Cloud Native Computing Foundation’s standard in cloud computing. Kubernetes is built to be used on a large scale, where each machine is connected to a cluster, called a node, which can host multiple PODs. A POD is the minimal management unit and can maintain one or more containers. Containers inside can share resources with each other, and it is generally a good idea to keep applications that are highly connected inside one POD [15]. Kubernetes comes with a web server that is the management unit for the cluster. An operator can interact with a web page to check on different PODs, network traffic and other health status [15]. 2.4 Securing A Distributed System As the system grows in size, it exposes more endpoints. These endpoints need to be secured in order to verify the authenticity of a user. Should the user not be authorized, or even authenticated, they should not be permitted to collect resources. Verifying the authenticity of a user and/or system is not an easy task and usually requires a combination of different techniques. By using tokens, one reduces the opportunity for a third party gaining access to restricted resources as they have to have be verified
15 | THEORY AND PREVIOUS WORK by either the system they are trying to access or via an external system. Tokens have an important role in many of the technologies described in the next section. 2.4.1 Token Tokens were created as a secondary authentication method, instead of user-password authentication. Tokens contain a cryptographic key, which is used in order to authenticate a user’s identity. This secret key is challenged in order for the user to be verified to the system. The challenge creates a response which either authenticates or denies the user, and if the key is accessed from the token, the token should be immediately destroyed [16]. A user can authenticate themselves to their token by, for example, a personal identification number (PIN), but some systems even use a biometric authentication in which the user is prompted to enter their signature, fingerprint or even a voice line [16]. There are several ways one could implement a token in a system, the following sections discuss some of these implementations. 2.4.2 JSON Web Token A JSON Web Token (JWT) is a JSON object which contains the information needed between two communicating parties. The information contained in the JSON is represented by a string which contains a header, payload and a signature. To compute the signature, the header is used as it contains the required information about the computation of the signature, such as the hash algorithm. The payload of the JSON is used to store information about the user, such as their identification number or email. The signature can then be computed by using a combination of the header and payload as the input of the algorithm [17]. A JWT can be used to authenticate a client as it is communicating with a server. This method of authentication is secure, but it can become vulnerable if the token is continuously used until expiration without updates, as it can be used by attackers
16 | THEORY AND PREVIOUS WORK trying to attack the system. To authenticate a client to a server, the client first send their credentials. The credentials could be an input from the client, such as username and password. After the credentials have been verified, the server creates the JWT which is then returned to the client as a response. As the client stays connected to the server, they can use this token to keep requesting secured resources from the server. When the client receives the token from the server, there is no way for the client to actually change any of the information contained in the token [17]. JWT is suitable for large decentralized distributed systems with scalability. The client can keep using the same token as long as they do not log out from the system, or as long as the token stays valid [17]. 2.4.3 Single Sign-on Single Sign-on (SSO) is a method which enables a client to log in once and keep access to shared secure resources without a log in prompt at every request. The SSO system creates one account for the client to log in to instead of unifying a multiplicity of accounts. This account contains information that the system accepts, even if the system contains various applications. There are systems which uses SSO to create a token based system in which the client submits their credentials, and after validation receives a token. The client can then access the resources based on this token. This token could be implemented as a pure token method, such as JWT, or it could be implemented as a cookie. In the implementation as a cookie, the client stores the token in a cookie in their browser, which can be encrypted in order for it to remain secure. The cookie consists of a set of information that the web server provides the client with. As the client keeps communicating with the server, the cookie can be used as authentication [18]. To implement SSO, one could go with either a centralized or decentralized approach. In the centralized approach, the identifications of users are stored in a centralized server which distributes the identification when requested. This approach, however,
17 | THEORY AND PREVIOUS WORK requires application integration with the SSO server. Another approach is the distributed approach in which the application keeps localized identifications of the users. These identifications are then synchronized to another central server. This approach does not require the application to make changes to integrate with the SSO server, and if there would be an attack on the system, the attacker would only gain access to the information on users within that particular application or component [19]. 2.5 Authentication Technologies The following sections will describe some of the technologies used in order to secure a system. These systems differ in some regards to implementation but they are all widely used technologies. The following sections will describe them briefly. 2.5.1 Security Assertion Markup Language The Security Assertion Markup Language (SAML) is an open standard within authorization and authentication. SAML is XML-based and provides security between domains. Upon authentication of a user, the system uses SAML to contact an online identification provider. SAML is not a service which authenticates the user, rather it is a standard on how to exchange the information used by the system to communicate the authentication or authorization data once another part of the system has authenticated them. The data exchanged contains information on the authentication status of the user, their rights or roles and how they can used the data and resources available on the system based on which roles or rights they have. These messages are known as assertions and SAML uses an abundance of protocols, such as HTTP and FTP, to transmit them [18].
18 | THEORY AND PREVIOUS WORK 2.5.2 OAuth OAuth 2.0 was released in 2012 and is used by many web applications such as Facebook, Google, Microsoft, etc. It is a framework standard for delegated authorization to allow a user to grant limited access to his/her own resources to other APIs or services. Example of this is sign in with Google [20]. 2.5.3 OpenID Connect OpenID Connect (OIDC) is a framework for exchanging authentications on RESTful APIs. OIDC launched in 2014 and was based on OAuth 2.0. It is seen as an extension of OAuth rather than a separate protocol. OIDC uses tokens, ID tokens and access tokens, in their authentication and authorization processes. The ID token is a JWT and contains information on the authenticated user, which comes from the identity provider. The access token contains information on which resources should be available to the user. When a user makes a request for resources a Relying Party (RP) makes the API request. A Token Endpoint then retrieves the authorization data in order for it to be validated. The token is returned to the user after validation and then sent to the OAuth protected resources, which only returns the requested resource when the user can present a valid token [21]. 2.5.4 Keycloak Keycloak is an open source identity management system to handle authentication for modern applications such as mobile applications, REST APIs, single page applications and others. It supports a wide range of protocols such as OAuth 2.0, OpenID Connect, and SAML 2.0 [22, 23]. Keycloak provides a login handler, where its layout can be changed to adhere to a different style. It also has features as password recovery, update of password schedule and other key features of an authentication system [22].
19 | THEORY AND PREVIOUS WORK 2.6 Change Detection To compute the difference made to two different files, such as source code or text files, delta algorithms can be used. These algorithms are useful since they reduce the amount of disk space required to save the different revisions as there is no need to store the complete file. In the following sections, some of the algorithms used will be described [24]. 2.6.1 Delta Encoding Version Control Systems need to store data efficiently. One way to achieve a more efficient storage is to use delta encoding. Delta encoding consists of saving the changes made to a file. One can then recreate the entire file by using the same reference point as the delta encoding. This allows a system to only store the changes made instead of a complete file for each version [25]. 2.6.2 Change in Hierarchical Structures When searching for change in hierarchically structured data, the problem is finding a ”minimum-cost edit script”. This is the point which transforms one data tree into another. To find change in hierarchical data is to find changes in nested information, since there may be values without keys [26]. 2.6.3 Myers Algorithm The Myers algorithm is used in detecting changes in the source code. The algorithm finds lines which are equal in two documents, these documents would be the modified and unmodified files. It starts by scanning the lines from both documents in order to find an exact match between lines. These matches are the unmodified lines. It then continues down the document until it has completed the reading of both documents. Each unpaired line is then considered removed in the first document, and added in the second document [27].
20 | THEORY AND PREVIOUS WORK This algorithm has a weakness, as it could produce an incorrect position for changes in both documents. It’s also incapable of identifying a unique line’s change of position as code is added above it. Such changes are marked as removal at its original position and seen as added code in the second document [27]. 2.6.4 Histogram Algorithm To find the difference in two files, this algorithm creates a histogram to find the candidates of Longest Common Subsequence (LCS). The histogram is created by counting the occurrences of each line in the first document. The histogram is then compared to the second document find each occurrence and then count them in order to determine which lines have changed and which lines are from the original version. If a match is found and the line’s occurrence is unique, meaning it has been counted once, or if that line has the lowest occurrence in both documents, that line is marked as a separator. A line marked as a separator is consider to be unchanged between the two documents, meaning that the lines above and below have either been added, if they are in the second document, or removed if they are in the first document [27].
21 | THEORY AND PREVIOUS WORK 2.7 Version Control Version Control is a technique to keep track of files and their history of changes. There are two main Version Control Systems (VCS), Centralized or Distributed. The following sections will describe the two models in more details. 2.7.1 Centralized Version Control System Centralized Version Control System (CVCS) works by having a master file on a storage server, which a team can access to make changes. They fetch a local copy of the file to work on and when they are done they commit their changes to the server. The user only has the latest version of the file on their computer and not the whole history of changes [28]. To add to the repository, it is common that only a small group of approved users have write permission to avoid problems such as changes not working as intended. To build larger projects, branches can be used to separate the changing files from the working directory. Branches are copies of the repository that, when changed, move forward independently [29]. 2.7.2 Distributed Version Control System In a Distributed Version Control System (DVCS), there are local copies of the entire repository on each local machine. Thus, the user can still work and commit changes while not connected to the internet. This also means that if the server is unavailable, the user can still make changes to the the local repository. To synchronize changes to other developers, a network connection is required. However, the changes can be synchronized without a centralized server, since the clients can communicate with each other and decide which changes to exchange [28].
22 | THEORY AND PREVIOUS WORK 2.8 Conflicts when Controlling Multiple Versions When changes are made by several people in collaboration, there are bound to be conflicts. Some of these conflicts are easier than others to identify and they can be categorized into different sections. These categories will be explained in the following subsections. 2.8.1 Textual Conflicts When comparing changes to a textual representation, conflicts may arise in a line, or several lines, of texts. The conflicts occur as the modifications made to a file are on the same line, which in turn makes the system unable to automatically choose which modification to commit to. Such conflicts requires a user to manually resolve [30]. 2.8.2 Syntactical Conflicts When users make changes to the same class, for instance, and add different properties, an algorithm could detect those changes as syntactic conflict in that specific class. However, not all syntactical conflicts need to be resolved by a user. A syntactical conflict could be classified as a conflict which may be detected by comparing the structure of the artifacts. To make comparisons, the artifacts could be represented as a tree or a graph [30]. 2.8.3 Semantic Conflicts Semantic conflicts arise when users modify resources with dependencies for each other. Semantic conflicts are an important type of conflict, they are however very hard to detect. The changes made are to the attributes, such as refactoring or refinements, which in turn makes the previous attributes invalid while overall the file is syntactically and textually correct [30].
23 | METHODOLOGY 3 Methodology This chapter will describe the methods and work that was done to enable development of a prototype for a server application. The first section will present what was done during the pre-study phase. Following is a comparison of different frameworks for Swift that exists, continued by a presentation for two options of the system’s structure. Last in the chapter development of the chosen prototype are presented. 3.1 Literary Study and Pre-Study A literary study was conducted during the first two weeks to acquire knowledge of several technologies in concurrency control and distributed systems, which enables an analysis in order to move forward in the development of a prototype. The study of Swift as a back-end application served as the backbone in the choice of approach and implementation. The HeadmasterDev project was studied in order to reveal what changes could be made and what kind of technique was the most suitable in order to build the requested application. The analysis will be used when deciding whether there will be a separate server application or an extension to the existing application. 3.2 Swift The client application HeadmasterDev, to which this server application was created for, is written in Swift. Headlong, who develops and maintains HeadmasterDev, is a small company with a team of three people. To keep a high language comprehension with a deep knowledge of specific aspects, all programming, where possible, should be written in Swift. Hence this thesis’ problem statement and exploration. If there is a possibility to develop and maintain an application written in Swift, the choice of programming language is easy.
24 | METHODOLOGY In order to construct a server in Swift, there are a number of different frameworks. The following sections will present which frameworks are available for this project to use in order for a decision to be made in section 3.2.4 Apple launched its own programming language at the Worldwide Developers Conference (WWDC) in 2014 called Swift. The year after, Apple launched version 2 and made it open source. The language’s main purpose is to develop iOS and macOS applications [2]. Since Swift 5, Apple declared Swift’s Application Binary Interface (ABI) as stable which means that in theory, code written in version 5 will work with future versions. With the release of Swift 5.3, Swift was given support for Windows 10, and the Swift team stated that they are evaluating the stabilization of ABI for the Linux platform [31]. Swift is a hybrid of functional and object oriented programming [2]. SwiftNIO is an Apple supported and open source library for asynchronous event- driven network applications that works cross platform. It is similar to how Netty works with event loops. Apple does not recommend using SwiftNIO to build a web application. Rather, they suggest to use a framework built for this [32, 33]. To facilitate easy workflows for developers, frameworks are used to abstract problems and speed up development. Following sections will present current frameworks that utilizes SwiftNIO to deliver a web framework. Each section will cover: – Web routing – Database management – Security
25 | METHODOLOGY 3.2.1 Vapor Vapor is a modular web framework that supports the most common features deployed on the web. It is broken down into several packages to facilitate modularity [34]. Vapor launched in 2016, soon after Apple made Swift open source. Vapor’s structure patterns are loosely based on Laravel (PHP) framework and has had great development in the six years it has been released [35]. The latest version, which is now Vapor 4, was released in March 2020 [36]. Webrouting Web traffic routing is handle by the Vapor framework itself. It is based on SwiftNIO’s low level implementation of networking. Each request is handle asynchronously to deliver fast response time [35]. Database management Vapor has an object–relational mapping service to handle database queries. The service is based on FluentKit and is called Fluent. Fluent has support for both SQL and NoSQL databases with PostgreSQL, SQLite, MySQL and MongoDB as the officially supported applications [37]. Security Vapor has support to handle token technologies, such as those mentioned in section 2.4 Securing A Distributed System, with JSON Web Token, Refresh tokens and other access protocols. HTTPS is also available with a configuration file and a certificate [35]. 3.2.2 Kitura Kitura is an open-source web framework for Swift. It was launched by IBM in 2016 and in August 2020 IBM released ownership of the framework to an official community driven project [38]. In terms of commits to the GitHub project, there has been a decline in activity since the framework were moved to a community
26 | METHODOLOGY project, and there is no clear roadmap as this thesis is written. Kitura web framework offers support for REST APIs, database connections, WebSocket’s and more. Kitura offers support both for using Docker and Kubernetes as a container management platform. Both are widely used in server applications to easily scale. See 2.3 Container Technology [39]. Webrouting Kitura has support for creating RESTful APIs. There are two types of routing available with Kitura, Raw Routing and Codable Routing. In Raw Routing, the developer is able to fetch the request parameters and create the response to the client, all asynchronously and with the ability to use multiple handlers for the same request. In the Codable Routing, any type which conforms to the Codable protocol can be used as a parameter for the route. By using the Kitura-OpenAPI library, developers can use OpenAPI for their projects [39]. Database management According to the official documentation of Kitura, there exists three APIs to handle databases. Two APIs for SQL applications and one for a NoSQL database. Since Kitura was an IBM Cloud focused product, most of the integration is catered towards the different storage products IBM has to offer. One of the APIs for SQL is an object relational mapping service that builds on top of the other services [39]. Security Kitura supports HTTPS with TLS via OpenSSL. To authenticate a user, Kitura supports basic authentication with a passphrase, JWT or OAuth 2.0 via Google or Facebook as a service provider [39]. 3.2.3 Perfect Perfect is a tool developed for Swift 4.0. Perfect allows for Swift to be used in building applications and servers in both macOS and Linux. Perfect is another framework that is built upon SwiftNIO. As of 2020, Perfect was on par with Vapor 3 in the amount
27 | METHODOLOGY of requests handled per second [35]. However, since then, there has been very little activity in the development of Perfect [40], whereas Vapor has released Vapor 4. This means that the comparison made in 2020 no longer holds today as Vapor will most likely be able to handle a different amount of requests per second. Webrouting Perfect uses its own library for the routing process. The routing is able to handle RESTful request, and it is able to do it all asynchronously. With its .next function, Perfect is able to handle multiple requests on the same route, and by calling its .completed function, the data is returned to the requester [41]. Database management Perfect allows for connections to be made to databases by developing a Swift wrapper on clients, such as the monogo-c client library. Other supported databases are PostgreSQL, MySQL, SQLite, and others. Perfect also have an object–relational mapping API called StORM, which is layered on top of Perfect. Together with the mongo-c client and StORM, Perfect allows for the project to connect to a number of different databases [41]. Security With OAuth2.0, Perfect provides authentication with drivers for Facebook, Google and GitHub. TLS is available by configuring a JSON file which is used, among other settings, to point to the certification and key for the server. One can also use an HTTPServer object to customize the server [41]. 3.2.4 Conclusion and choice of framework During the research of what available frameworks there are for Swift, it has become clear that most up to date documentation and development of features are from the Vapor framework. With great support of JSON Web Tokens and middleware solutions, the continued work will be in Vapor. Kitura lost IBM backing in September of 2020 and is now a community driven project with an unclear development road
28 | METHODOLOGY map. As of the last update from the developers in 2021, there is still no support for using SwiftNIO as the connection framework. To be able to use this on Linux, there is an environment variable that the user can set. This, however, will not work in Xcode which is used in this project [42]. Perfect has seen very few contributions to their project since 2019. The latest supported version of Swift is 5.2, which makes it uncertain whether a project with Perfect as the framework will be able to be regularly updated. In conclusion, to have a stable and somewhat future proof technology stack, Vapor is the best candidate. Since Vapor supports both JSON Web Token and other middleware to reach an acceptable security level. Therefore the candidates will be developed with Vapor as its framework. 3.3 Choice of Approach There will be two options proposed for the construction of the server application. After both options are presented, there will be a conclusion on which option the server application will be constructed with. The first section will discuss which techniques and frameworks that will be used for both of the options. Before a prototype will be constructed, there are two main options that needs to be considered. The first option, Option A - Server Based Control, will consider the scenario in which the server owns the data, and the client will be responsible for pushing the changes made to the server. The second option, Option B - Client Based Control, will consist of a server which stores the data. In this scenario, the client will be the owner of the data and the server will be responsible for the version information and storage of the entire document. 3.3.1 Frameworks and Techniques MongoDB will be chosen as the database for the server. This database allows for storing entire documents and nested documents, which makes it suitable for both
29 | METHODOLOGY Option A - Server Based Control and Option B - Client Based Control. A relational database may not be able to perform as well, since each parent definition in the document can have several children, and there is the possibility that as the entire document grows in size, there will be too many references. One requirement from Headlong is that the user should not be able to edit the definitions unless they are connected to the internet. This makes the choice of whether to construct a distributed or centralized version control system easier, since the centralized version requires the user to be connected to the internet as they fetch the most current version from the server. Both these options are presented in 2.7. Alterations to the existing application will be made in order to support functions for a user to log in and asserting that an authenticated user has the correct authorization to perform the requested action. Because Vapor allows for third party authentication, it allows for the use of authentication technologies to be used. The server application will be using the token provided by Keycloak to authenticate users, since this allows for a token to be made with the information of both roles and authenticity. Keycloak also conforms to SAML and uses SSO, which will be beneficial to this project as a prototype can be constructed both faster and more reliably. Keycloak can be hosted on a number of different services. Cloud IAM will be the host for this projects authentication and authorization. Only certain users with permission are allowed to alter the definitions, and only the administrator should be able to view the commitment history of the document. Different authentication techniques are presented in 2.5. Docker allows for the application to be run in a number of different operating systems, such as macOS and Linux, and to be used in various load balancing technologies, such as Kubernetes and Nginx. Because of the benefits of deploying the application in a container environment, the server application will be delivered as a docker container.
30 | METHODOLOGY 3.3.2 Option A - Server Based Control Description The chosen approach for Option A - Server Based Control will separate the created document from the application based on the different parents and children that the document is built upon. Each of these sub-documents can then have their own separate version control. This approach makes it so that should a definition be updated, the other HeadmasterDev applications (referred to as the clients from on) will not be forced to fetch the entire document in order to update a single definition. This allows for efficient communication as the document grows in size over time. In this option, the server will own the data. As such, the client will need to be altered to be able to fetch the version information from the server in order to assure that all the parent definitions are available. As a user expands and selects a definition, another fetch will be sent to the server to assure that the description and information on the definition are all up to date. Should there be a more recent version available, the client will update just that definition, and their available children. Should a new application be started, with no definitions in their local storage, the server will construct and send the definition to the client. When the client edits the definition, there will first be a check on the timestamp of the current definition. Since one desired functionality of the application is that there will be a note on when the definition was last changed and by whom, a timestamp allows for both functionalities, version number and last updated, to be met. As the client starts to edit a document, a lock will be set on the definition to hinder other clients from altering it at the same time, as to avoid concurrency issues. Should the client crash, or the internet connection go down, a timer will be set for the lock to be released.
31 | METHODOLOGY
Benefits
The benefits of this approach are:
– Reduced amount of actions required by the client.
– The possibility of scaling the project as the server application will handle most
of the logic and traffic.
– The possibility of monitoring changes made to each definition and concept.
– As changes are made to a definition, only that specific definition needs to be sent
to the server application, as definitions and concepts are stored separately.
Drawbacks
There are some drawbacks to this approach, such as:
– Depending on the size of the document and the amount of definitions and
concepts stored, there may be a significant delay between a client asking for
the entire document, and actually receiving it.
– This will significantly complicate the development of the application as there
needs to be a clear relation made to each definition and there may be a large
amount of collections required to make the relevant separations.
3.3.3 Option B - Client Based Control
Description
In the second approach, Option B - Client Based Control, the client will be the owner
of the data. As a user makes changes to definitions and concepts, the entire document
is stored in the server application. The only thing the server application will be
responsible for is marking which changes was made by the user, putting a timestamp
on them and keeping a copy of each version. The versions are stored as the application
may change in the future and implement a complete version control.
As the client is the owner of the data, this approach allows for a shorter response time32 | METHODOLOGY
when a new client connects to the system as the backend does not have to rebuild the
entire document based on the different relations that the definitions and concepts
have. However, this also means that each time a change is made to the document,
the entire JSON needs to be uploaded to the backend. Depending on how much the
document grows in size, that may be a substantial amount of data transferred each
time a change is made.
This approach will consist of handling merge conflicts. As one client edits a definition,
another client may already have pushed their changes to the same definition. As they
then attempt to push their own changes to that definition, they will find that there
is a new version available, and have to pull that version to their local storage before
they can commit to the changes they have made. Therefore, the client needs to check
for such merge conflicts before pushing changes to the backend application.
Benefits
Benefits by making the client the owner of the data are:
– This simplifies the backend application as the main purpose will be storing the
definitions and a minimal amount of logical actions need to be performed. As
such, the development time will be reduced.
– When a client asks for the complete definition from the backend application,
there will be no logical operations taking place, as the complete document is
stored. This allows for a fast pull of the document from the database.
Drawbacks
Some drawbacks of this approach include:
– There will be a lot of data traffic as the entire document will be sent to the
backend application.
– There will be quite a lot of focus on the concurrency of the backend application
as the entire document is replaced on commit. Therefore, there will have to be
a check for a new version on the document, and after each update, all clients33 | METHODOLOGY
will need to fetch the entire document. This will not suffice for a large scale
application, but as the amount of concurrent clients stay moderately low, there
will be no issues.
3.4 Development of the Prototype
In order to create a prototype of the server application, a number of decision had to
be made. These discussions will pertain to the chosen approaches. The approaches
on how to operate on documents, handle concurrency and how to rebuild the entire
definition document will be discussed in the following sections.
3.4.1 Choice of approach
Per discussion with Headlong and the supervisor of the project, the choice of
approach were Option A - Server Based Control. The decision to choose a server-
owned approach lies with the ability to let the application scale without having to
impact the client application, and to reduce the required traffic on each request. This
also allows for the pessimistic concurrency protocol to be implemented. Should each
application own their data, there needs to be a check for merge conflicts on the server
application, and the ability to resolve these conflicts on the client.
3.4.2 Operating on Documents
Both approaches are subject to the question of how to handle the complete document
of all definitions. There are two methods seen as available in storing the documents.
The first method will handle the document per definition. The second method will
be a flat representation of the object where the document will be separated per object
in the document. Both methods will take an arbitrary document as input, and store
them in the database. The first choice was chosen as the size of each definition will not
be terribly large, and that allows for the entire definition to be sent over the internet
without a substantial increase in transfer rates. As there is a limit to the time availableYou can also read

















































