Towards Heterogeneous Clients with Elastic Federated Learning
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Towards Heterogeneous Clients with Elastic Federated Learning
Zichen Ma1,2 , Yu Lu1,2 , Zihan Lu3 , Wenye Li1 and Jinfeng Yi2 , Shuguang Cui1
1
The Chinese University of Hong Kong, Shenzhen
2
JD AI Lab
3
Ping An Technology
arXiv:2106.09433v1 [cs.LG] 17 Jun 2021
Abstract While there are many variants of FedAvg and they have
shown empirical success in the non-IID settings, these algo-
Federated learning involves training machine learn- rithms do not fully address bias in the system. The solutions
ing models over devices or data silos, such as edge are sub-optimal as they either employ a small shared global
processors or data warehouses, while keeping the subset of data [Zhao et al., 2018] or greater number of mod-
data local. Training in heterogeneous and poten- els with increased communication costs [Karimireddy et al.,
tially massive networks introduces bias into the sys- 2020b; Li et al., 2018; Li et al., 2019]. Moreover, to the best
tem, which is originated from the non-IID data and of our knowledge, previous models do not consider the low
the low participation rate in reality. In this pa- participation rate, which may restrict the potential availabil-
per, we propose Elastic Federated Learning (EFL), ity of training datasets, and weaken the applicability of the
an unbiased algorithm to tackle the heterogeneity system.
in the system, which makes the most informative In this paper, we develop Elastic Federated Learning
parameters less volatile during training, and uti- (EFL), which is an unbiased algorithm that aims to tackle the
lizes the incomplete local updates. It is an effi- statistical heterogeneity and the low participation rate chal-
cient and effective algorithm that compresses both lenge.
upstream and downstream communications. Theo- Contributions of the paper are as follows: Firstly, EFL is
retically, the algorithm has convergence guarantee robust to the non-IID data setting. It incorporates an elastic
when training on the non-IID data at the low partic- term into the local objective to improve the stability of the
ipation rate. Empirical experiments corroborate the algorithm, and makes the most informative parameters, which
competitive performance of EFL framework on the are identified by the Fisher information matrix, less volatile.
robustness and the efficiency. Theoretically, we provide the convergence guarantees for the
algorithm.
1 Introduction Secondly, even when the system is in the low participation
Federated learning (FL) has been an attractive distributed ma- rate, i.e., many clients may be inactive or return incomplete
chine learning paradigm where participants jointly learn a updates, EFL still converges. It utilizes the partial informa-
global model without data sharing [McMahan et al., 2017a]. tion by scaling the corresponding aggregation coefficient. We
It embodies the principles of focused collection and data min- show that the low participation rate will not impact the con-
imization, and can mitigate many of the systemic privacy vergence, but the tolerance to it diminishes as the learning
risks and costs resulting from traditional, centralized machine continuing.
learning [Kairouz et al., 2019]. While there are plenty of Thirdly, the proposed EFL is a communication-efficient
works on federated optimization, bias in the system still re- algorithm that compresses both upstream and downstream
mains a key challenge. The origins of bias are from (i) the sta- communications. We provide the convergence analysis of the
tistical heterogeneity that data are not independent and identi- compressed algorithm as well as extensive empirical results
cally distributed (IID) across clients (ii) the low participation on different datasets. The algorithm requires both fewer gra-
rate that is due to limited computing and communication re- dient evaluations and communicated bits to converge.
sources, e.g., network condition, battery, processors, etc.
Existing FL methods empower participants accomplish 2 Related Work
several local updates, and the server will abandon struggle Federated Optimization Recently we have witnessed signif-
clients, which attempt to alleviate communication burden. icant progress in developing novel methods that address dif-
The popular algorithm, FedAvg [McMahan et al., 2017a], ferent challenges in FL; see [Kairouz et al., 2019; Li et al.,
first allows clients to perform a small number of epochs of lo- 2020a]. In particular, there have been several works on var-
cal stochastic gradient descent (SGD), then successfully com- ious aspects of FL, including preserving the privacy of users
pleted clients communicate their model updates back to the [Duchi et al., 2014; McMahan et al., 2017b; Agarwal et al.,
server, and stragglers will be abandoned. 2018; Zhu et al., 2020] and lowering communication cost
[Reisizadeh et al., 2020; Dai et al., 2019; Basu et al., 2019; Algorithm 1 EFL. N clients are indexed by k; B is the local
Li et al., 2020b]. Several works develop algorithms for the mini-batch size, pk is the probability of the client is selected
homogeneous setting, where the data samples of all users are ,ητ is the learning rate, E is the maximum number of time
sampled from the same probability distribution [Stich, 2018; steps each round has, and 0 ≤ skτ ≤ E is the number of local
Wang and Joshi, 2018; Zhou and Cong, 2017; Lin et al., updates the client completes in the τ -th round.
2018]. More related to our paper, there are several works Server executes:
that study statistical heterogeneity of users’ data samples in initialize ω0 , each client k is selected with probability pk ,
FL [Zhao et al., 2018; Sahu et al., 2018; Karimireddy et R0G , R0k ← 0.
al., 2020b; Haddadpour and Mahdavi, 2019; Li et al., 2019; for each round τ = 1,2, ... do
Khaled et al., 2020], but the solutions are not optimal as they Sτ ← (random subset of N clients)
either violate privacy requirements or increase the communi- for each client k ∈ St in parallel do
cation burden. ∆ωτkE , ukτ , vτk ← ClientUpdate(k, ST (∆ω(τ G
−1)E ),
Lifelong Learning The problem is defined as learning sep- P k P k
arate tasks sequentially using a single model without forget- u
k τ −1 , v
k τ −1 )
∆ωτGE = R(τ G
P k k
ting the previously learned tasks. In this context, several pop- −1)E + k pτ ∆ωτ E
ular approaches have been proposed such as data distillation G G G
Rτ E = ∆ωτ E − ST (∆ωτ E )
[Parisi et al., 2018], model expansion [Rusu et al., 2016; G
ω(τ G G
+1)E = ωτ E + ∆ωτ E
Draelos et al., 2017], and memory consolidation [Soltog- end for
gio, 2015; Shin et al., 2017], a particularly successful one is return ST (∆ωτGE ), k ukτ , k vτk to participants
P P
EWC [Kirkpatrick et al., 2017], a method to aid the sequen- end for
tial learning of tasks. G
P k P k
ClientUpdate(k, ST (∆ω(τ −1)E ), k uτ −1 , k vτ −1 ):
To draw an analogy between federated learning and the
problem of lifelong learning, we consider the problem of ξ ← split local data into batches of size B
learning a model on each client in the non-IID setting as a sep- for batch ξ ∈ B do
arate learning problem. In this sense, it is natural to use simi- ωτkE = ω(τk G
−1)E + ∆ω(τ −1)E
lar tools to alleviate the bias challenge. While two paradigms for j = 0, ..., skτ − 1 do
share a common main challenge in some context, learning ωτkE+j+1 = ωτkE+j − ητ gτkE+j
tasks in lifelong learning are serially carried rather than in end for
parallel, and each task is seen only once in it, whereas there ∆ωτkE = R(τ k k
− ωτkE
−1)E + ωτ E+sk
is no such limitation in federated learning. τ
RτkE = ∆ωτkE − ST (∆ωτkE )
Communication-efficient Distributed Learning A wide
variety of methods have been proposed to reduce the amount ukτ = diag(Iτ,k )
of communication in distributed machine learning. The sub- vτk = diag(Iτ,k )ωτkE+sk
τ
stantial existing research focuses on (i) communication de- end for
lay that reduces the communication frequency by performing return ∆ωτkE , ukτ , vτk to the server
local optimization [Konečnỳ et al., 2016; McMahan et al.,
2017a] (ii) sparsification that reduces the entropy of updates
by restricting changes to only a small subset of parameters where N is the number of participants, pk denotes the proba-
[Aji and Heafield, 2017; Tsuzuku et al., 2018] (iii) dense bility of k-th client is selected. Here ω represents the param-
quantization that reduces the entropy of the weight updates eters of the model, and Fek (ω) is the local objective of k-th
by restricting all updates to a reduced set of values [Alistarh client.
et al., 2017; Bernstein et al., 2018]. Assuming there are at most T rounds. For the τ -th round,
Out of all the above-listed methods, only FedAvg and the clients are connected via a central aggregating server, and
signSGD compress both upstream and downstream commu- seek to optimize the following objective locally:
nications. All other methods are of limited utility in FL set-
ting, as they leave communications from the server to clients N
λ X
uncompressed. Feτ,k (ω) = fk (ω)+ (ω−ωτi −1 )T diag(Iτ −1,i )(ω−ωτi −1 ),
2 i=1
(2)
3 Elastic Federated Learning where fk (ω) is the local empirical risk over all available sam-
3.1 Problem Formulation ples at k-th client. ωτi −1 is the model parameters of i-th client
in the (τ − 1)-th round. Iτ −1,i = I(ωτi −1 ) is the Fisher infor-
EFL is designed to mitigate the heterogeneity in the system, mation matrix, which is the negative expected Hessian of log
where the problem is originated from the non-IID data across likelihood function, and diag(Iτ −1,i ) is the matrix that pre-
clients and the low participation rate. In particular, the aim is serves values of diagonal of the Fisher information matrix,
to minimize: which aims to penalize parts of the parameters that are too
N
X volatile in a round.
min F (ω) = pk Fek (ω), (1) We propose to add the elastic term (the second term of
ω Equation (2)) to the local subproblem to restrict the most in-
k=1
formative parameters’ change. It alleviates bias that is origi- Algorithm 2 Compression Method ST . q is the sparsity, ten-
nated from the non-IID data and stabilizes the training. Equa- sor T ∈ Rn , T̂ ∈ {−µ, 0, µ}n
tion (2) can be further rearranged as ST(T ):
λ XN k = max(nq, 1); e = topk (|T |)
Feτ,k (ω) = fk (ω) + ω T diag(Iτ −1,i )ω mask = P(|T | ≥ e) ∈ {0, 1}n ; T mask = mask × T
2 i=1
1 n
µ = k i=1 |Timask |
(3)
N
X T̂ = µ × sign(T mask )
− λω T diag(Iτ −1,i )ωτi −1 + Z, return T̂
i=1
where Z is a constant. Let ukτ−1 = diag(Iτ −1,k ), and vτk−1 =
low participation rate, which are not yet well discussed pre-
diag(Iτ −1,k )ωτk−1 . viously: (i) incomplete clients that can only submit partially
Suppose ω ∗ is the minimizer of the global objective F , and complete updates (ii) inactive clients that cannot respond to
denote by Fek∗ the optimal value of Fek . We further define the the server.
degree to which data at k-th client is distributed differently The client k is inactive in the τ -th round if skτ = 0, i.e. it
than that at other clients as Dk = Fek (ω ∗ ) − Fek∗ , and D = does not perform the local training, and the client k is incom-
plete if 0 < skτ < E. skτ is a random variable that can follow
PN k
k=1 p Dk . We consider discrete time steps t = 0, 1, ....
Model weights are aggregated and synchronized when t is a an arbitrary distribution. It can generally be time-varying, i.e.,
multiple of E, i.e., each round consists of E time steps. In it may follow different distributions at different time steps.
the τ -th round, EFL, presented in Algorithm 1, executes the EFL also allows the aggregation coefficient pkτ to vary with
following steps: τ , and in the next subsection, we explore different schemes
Firstly, the server broadcasts the of choosing pkτ and their impacts on the model convergence.
G
Pcompressed
k
latest
P kglobal
weight updates ST (∆ω(τ −1)E ), u
k τ −1 , and k vτ −1 to
EFL also incorporates the sparsification and quantization
participants. Each client then updates its local weight: ωτkE = to compress both the upstream (from clients to the server)
k G and the downstream (from the server to clients) communica-
ω(τ −1)E + ∆ω(τ −1)E . tions. It is not economical to only communicate the fraction
Secondly, each client runs SGD on its local objective Fek of largest elements at full precision as regular top-k sparsi-
for j = 0, ..., skτ − 1: fication [Aji and Heafield, 2017]. As a result, EFL quan-
tizes the remaining top-k elements of the sparsified updates
ωτkE+j+1 = ωτkE+j − ητ gτkE+j , (4) to the mean population magnitude, leaving the updates with
a ternary tensor containing {−µ, 0, µ}, which is summarized
where ητ is a learning rate that decays with τ , 0 ≤ skτ ≤ E is in Algorithm 2.
the number of local updates the client completes in the τ -th
round, gtk = ∇Fek (ωtk , ξtk ) is the stochastic gradient of k-th 3.2 Convergence Analysis
client, and ξtk is a mini-batch sampled from client k’s local
data. g kt = ∇Fek (ωtk ) is the full batch gradient at client k, and Five assumptions are made to help analyze the convergence
behaviors of EFL algorithm.
g kt = Eξtk [gtk ], ∆ωτkE = R(τ k k
−1)E + ωτ E+sk − ωτkE , where
τ
each client computes the residual as Assumption 1. (L-smoothness) Fe1 , ..., FeN are L-smooth,
and F is also L-smooth.
RτkE = ∆ωτkE − ST (∆ωτkE ). (5)
Assumption 2. (Strong convexity) Fe1 , ..., FeN are µ-strongly
ST (·) is the compression method presented in Algorithm 2. convex, and F is also µ-strongly convex.
Client sends the compressed local updates ST (∆ωτkE ), ukτ ,
and vτk back to the coordinator. Assumption 3. (Bounded variance) The variance of the
Thirdly, the server aggregates the next global weight as stochastic gradients is bounded by Eξ ||gtk − g kt ||2 ≤ σk2
G G G Assumption 4. (Bounded gradient) The expected squared
ω(τ +1)E = ωτ E + ∆ωτ E norm of the stochastic gradients at each client is bounded
N
X by Eξ ||gtk ||2 ≤ G2 .
= ωτGE + R(τ
G
−1)E + pkτ ∆ωτkE
Assumption 5. (Bounded aggregation coefficient) The ag-
k=1 (6)
gregation coefficient has an upper bound, which is given by
k
N
X sτ
X pkτ ≤ θpk .
= ωτGE + G
R(τ −1)E − pkτ ητ gτkE+j , PN
k=1 j=0
Assuming E[pkτ ], E[pkτ skτ ], E[(pkτ )2 skτ ], and E[ k=1 pkτ −
PN
2 + k=1 pkτ skτ ] exist for all rounds τ and clients k, and
where RτGE = ∆ωτGE − ST (∆ωτGE ). PN
E[ k=1 pkτ skτ ] 6= 0. The convergence bound can be derived
As mentioned in Section 1, clients’ low participation rate
as
in a federated machine learning system is common in real-
ity. EFL mainly focuses on two situations that lead to the Theorem 1. Under Assumptions 1 to 5, for learning rateTable 1: Number of communication rounds required to reach -accuracy. SC refers to strongly convex, NC refers to non-convex, and δ in
MIME bounds Hessian dissimilarity. EFL preserves the optimal statistical rates (first term in SCAFFOLD) while improves the optimization.
Algorithm Bounded gradient Convexity # Com. rounds
G2 G L
SCAFFOLD X µ-SC µS + √
µ
+ µ
2
G δ
MIME X µ-SC µS + µ
N σ2 N
VRL-SGD × NC S2 +
2
G G L2
FedAMP X NC LS + 23 +
√
G2 L
EFL X µ-SC µS + µ
√
16E P
ητ = µ((τ +1)E+γ)E[ N k k , the EFL satisfies Suppose a client a is inactive with the probability 0 < y a <
k=1 pτ sτ ]
1 in each round, and let f0 (τ ) be the convergence bound if we
Cτ Hτ J keep the client, f1 (τ ) be the bound if it is abandoned at τ0 .
E||ωτGE − ω ∗ ||2 ≤ + , (7) For f0 with sufficiently many steps, the first term in Equation
(τ E + γ)2 τE + γ
(7) shrinks to zero, and the second term converges to y a J.
2 32E(1+θ)L
where γ = max{ min E[4E PNθ k k , PN k k }, Thus, f0 ≈ y a J, and we can obtain that f1 τ = (E(τ −τ C
eτ
τ k=1 pτ sτ ] µ minτ E[ k=1 pτ sτ ] γ )2
0 )+e
Pτ −1
Hτ = t=0 E[rt ], rt ∈ {0, 1} indicates the ra- for some Cτ and γ
e e, thus we have
E[pk k
τ sτ ]
tio pk
has the same value for all k, Cτ = Corollary 1. An inactive client a should be abandoned if
Pτ −1 E[Bt ]
2
max{γ E||ω0 G
− ω ∗ ||2 , ( 16E
µ )
2
t=0 (E[ N pk
P k 2 }, y a J > f1 (T ). (8)
k=1 t st ])
PN k 2 k 2 N
2(2 + θ)L k=1 pkt skt Dk +
P
Bt = k=1 (pt ) st σk + P Assuming Cτ ≈ C eτ = τ C and γ ≈ γ e, i.e., the removed client
µ N PN
(2 + 2(1+θ)L )E(E − 1)G ( k=1 pkt skt + θ( k=1 pkt −
2
does not significantly affect the overall SGD variance and the
PN k K 2
PN (pkt )2 k degree of non-IID, then Equation (8) can be formulated as
2) + k=1 pt st ) + 2EG k=1 pk st , J =
32E
PN k k
E[pτ sτ ] C
maxτ { D /µE[k=1PN k k }. y k > O( ). J
(9)
k k=1 pτ sτ ]
TE
Based on Theorem 1, Cτ = O(τ ), which means ωτGE
will From Corollary 1, the more epochs the training on the local
finally converge to a global optimal as τ → ∞ if Hτ increases client, the more sensitive it is to the in-activeness.
sub-linearly with τ . Table 1 summaries the required num-
ber of communication rounds of SCAFFOLD[Karimireddy 4.2 Incomplete Client
et al., 2020b], MIME [Karimireddy et al., 2020a], VRL-
Based on Theorem 1, the convergence bound is controlled
SGD[Liang et al., 2019], FedAMP[Huang et al., 2021] and
by the expectation of pkτ and its functions. EFL al-
EFL. The proposed EFL algorithm achieves tighter bound
lows clients to upload partial work with adaptive weight
comparing with methods which assume µ-strongly convex. k
The proof of Theorem 1 is summarized in the supplementary pkτ = Ep sk
. It assigns a greater aggregation co-
τ
material. efficient to clients that complete fewer local epochs,
and turns out to guarantee the convergence in the non-
4 Impacts of Irregular Clients IID setting. The resulting convergence bound follows
τ −1 τ −1
E5 N
pk E[1/sk ]+E 2 N
(pk σ )2 E[1/sk ]
P P P P
k
In this section, we investigate the impacts of clients’ different O( t=0 k t t=0
(τ E+E 2 )2
k t
).
behaviors including being inactive, incomplete, new client ar- The reason for enlarging the aggregation coefficient lies in
rival and client departure. Equation (6) that increasing pkτ is equivalent to increasing the
learning rate of client k. By assigning clients that complete
4.1 Inactive Client fewer epochs a greater aggregation coefficient, these clients
If there exist inactive clients, the convergence rate changes effectively run further in each local step, compensating for
P τ −1
t y J less epochs.
to O( τ t=0
E+E 2 ). yt indicates if there are inactive clients in
the t-th round. Furthermore, the term converges to zero if 4.3 Client Departure
yt ∈ O(τ ), which means that a mild degree of inactive client If k-th client quits at τ0 < T , no more updates will be re-
will not discourage the convergence. A client can frequently ceived from it, and skτ = 0 for all τ > τ0 . As a result, the
become inactive due to the limited resources in reality. Per- E[pk sk ]
manently removing the client in this case may improve the value of ratio pτk τ is different for different k, and rτ = 1
model performance. Specially, we will remove the client if for all τ > τ0 . According to Theorem 1, ωτGE cannot con-
the system without this client leads to a smaller training loss verge to the global optimal ω ∗ as HT ≥ T − τ0 . Intuitively,
when it terminates at the deadline T . a client should contribute sufficiently many updates in orderFigure 1: Testing Accuracy-Communication Rounds comparisons of VGG11 on CIFAR100 and Resnet50 on EMNIST in a distributed setting
for IID and non-IID data. In the non-IID cases, every client only holds examples from exactly m classes in the dataset. All methods suffer
from degraded convergence speed in the non-IID situation, but EFL is affected by far the least.
Table 2: BMTA for the non-IID data setting to fully address the new client.
We also present the bounds of the additional term due to
Methods MNIST CIFAR100 Sent140 Shakes. the objective shift as
FedAvg 98.30 2.27 59.14 51.35 Theorem 2. For the global objective shift F → F̂ , ω ∗ → ω̂ ∗ ,
FedGATE 99.15 80.94 68.84 54.71 let D̂k = Fk (ω̂ ∗ ) − Fk∗ quantify the degree of non-IID data
VRL-SGD 98.86 2.81 68.62 52.33 with respect to the new objective. If the client a quits the
APFL 98.49 77.19 68.81 55.27 system,
FedAMP 99.06 81.17 69.01 58.42 8Ln2a D̂a
EFL 99.10 81.38 68.95 60.49 ||ω ∗ − ω̂ ∗ ||2 ≤ . (10)
µ2 n2
If the client a joins the system,
for its features to be captured by the trained model in the non- 8Ln2a D̂a
IID setting. After a client leaves, the remaining training steps ||ω ∗ − ω̂ ∗ ||2 ≤ , (11)
µ2 (n + na )2
will not keep much memory as it runs more rounds. Thus, the where n is the total number of samples before the shift.
model may not be applicable to the leaving client, especially
when it leaves early in the training (τ0
T ), which indicates It can be concluded that the bound reduces when the data
that we may discard a departing client if we cannot guarantee becomes more IID, and when the changed client owns fewer
the trained model performs well on it, and the earlier a client data samples.
leaves, the more likely it should be discarded.
However, removing the departing client (the a client) from 5 Experiments
the training may push the original learning objective F = In this section, we first demonstrate the effectiveness and effi-
PN PN
ke ke ciency of EFL in the non-IID data setting, and compare with
k=1 p Fk towards the new one F̂ = k=1,k6=a p Fk , and
∗ ∗
the optimal weight ω will also shift to some ω̂ that min- several baseline algorithms. Then, we show the robustness of
EFL on the low participation rate challenge.
imizes F̂ . There exists a gap between these two optimal,
which further adds an additional term to the convergence 5.1 Experimental Settings
bound obtained in Theorem 1, and a sufficient number of up- Both convex and non-convex models are evaluated on a num-
dates are required for ωτGE to converge to the new optimal ω̂ ∗ . ber of benchmark datasets of federated learning. Specifically,
we adopt MNIST [LeCun et al., 1998], EMNIST [Cohen et
4.4 Client Arrival al., 2017] dataset with Resnet50 [He et al., 2016], CIFAR100
The same argument holds when a new client joins in the train- dataset [Krizhevsky et al., 2009] with VGG11 [Simonyan
ing, which requires changing the original global objective to and Zisserman, 2014] network, Shakespeare dataset with an
include the loss on the new client’s data. The learning rate LSTM [McMahan et al., 2017a]to predict the next character,
also needs to be increased when the objective changes. In- Sentiment140 dataset [Go et al., 2009] with an LSTM to clas-
tuitively, if the shift happens at a large time τ0 , where ωτGE sify sentiment and synthetic dataset with a linear regression
approaches to the old optimal ω ∗ and ητ0 is close to zero, re- classifier.
ducing the latest differences ||ωτGE −ω̂ ∗ ||2 ≈ ||ω ∗ −ω̂ ∗ ||2 with Our experiments are conducted on the TensorFlow plat-
a small learning rate is inapplicable. Thus, a greater learning form running in a Linux server. For reference, statistics of
rate should be adopted, which is equivalent to initiate a fresh datasets, implementation details and the anonymized code are
start after the shift, and there still needs more updating rounds summarized in supplementary material.Figure 2: The first row shows Testing Accuracy-Communication Rounds comparison and the second row shows Training Loss-
Communication Rounds comparison in non-IID setting. EFL with elastic term stabilizes and improves the convergence of the algorithm.
be observed also for Resnet50 on EMNIST case, it can be
concluded that the performance loss that is originated from
the non-IID data is not unique to some functions.
Aiming at better illustrating the effectiveness of the pro-
posed algorithm, we further evaluate and compare EFL with
the state-of-the-art algorithms, including FedGATE [Haddad-
pour et al., 2021], VRL-SGD [Liang et al., 2019], APFL
[Deng et al., 2020] and FedAMP [Huang et al., 2021] on
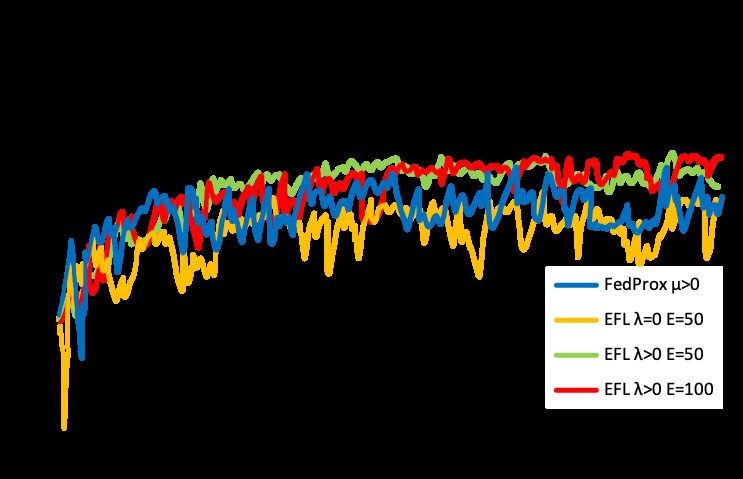
Figure 3: Testing Accuracy-Communication Rounds comparisons MNIST, CIFAR100, Sentiment140, and Shakespeare dataset.
among different algorithms in low participation rate. EFL utilizes
incomplete updates from stragglers and is robust to the low partici-
The performance of all the methods is evaluated by the best
pation rate. mean testing accuracy (BMTA) in percentage, where the
mean testing accuracy is the average of the testing accuracy
on all participants. For each of datasets, we apply a non-IID
5.2 Effects of Non-IID Data data setting.
We run experiments with a simplified version of the well- Table 2 shows the BMTA of all the methods under non-
studied 11-layer VGG11 network, which we train on the IID data setting, which is not easy for vanilla algorithm Fe-
CIFAR100 dataset in a federated learning setup using 100 dAvg. On the challenging CIFAR100 dataset, VRL-SGD is
clients. For the IID setting, we split the training data ran- unstable and performs catastrophically because the models
domly into equally sized shards and assign one shard to every are destroyed such that the customized gradient updates in
clients. For the non-IID (m) setting, we assign every client the method can not tune it up. APFL and FedAMP train per-
samples from exactly m classes of the dataset. We also per- sonalized models to alleviate the non-IID data, however, the
form experiments with Resnet50, where we train on EMNIST performance of APFL is still damaged by unstable training.
dataset under the same setup of the federated learning envi- FedGATE, FedAMP and EFL achieve comparably good per-
ronment. Both models are trained using SGD. formance on all datasets.
Figure 1 shows the convergence comparison in terms of
gradient evaluations for the two models using different al- 5.3 Effects of the Elastic Term
gorithms. FedProx [Li et al., 2018] incorporates a proximal EFL utilizes the incomplete local updates, which indicates
term in local objective to improve the model performance on that clients may perform different amount of local work skτ ,
the non-IID data, SCAFFOLD [Karimireddy et al., 2020b] and this parameter together with the elastic term scaled by
adopts control variate to alleviate the effects of data hetero- λ affect the performance of the algorithm. However, skτ is
geneity, and APFL [Deng et al., 2020] learns personalized determined by its constrains, i.e., it is a client specific param-
local models to mitigate heterogeneous data on clients. eter, EFL can only set the maximum number of local epochs
We observe that while all methods achieve comparably fast to prevent local models drifting too far away from the global
convergence in terms of gradient evaluations on IID data, they model, and tune a best λ. Intuitively, a proper λ restricts the
suffer considerably in the non-IID setting. From left to right, optimization trajectory by limiting the most informative pa-
as data becomes more non-IID, convergence becomes worse rameters’ change, and guarantees the convergence.
for FedProx, and it can diverge in some cases. SCAFFOLD We explore impacts of the elastic term by setting different
and APFL exhibit its ability in alleviating the data hetero- values of λ, and investigate whether the maximum number
geneity, but are not stable during training. As this trend can of local epochs influences the convergence behavior of thealgorithm. Figure 2 shows the performance comparison on [Bernstein et al., 2018] Jeremy Bernstein, Yu-Xiang Wang,
different datasets using different models. We compare the Kamyar Azizzadenesheli, and Anima Anandkumar.
result between EFL with λ = 0 and EFL with best λ. For signsgd: Compressed optimisation for non-convex prob-
all datasets, it can be observed that the appropriate λ can in- lems. arXiv preprint arXiv:1802.04434, 2018.
crease the stability for unstable methods and can force diver- [Cohen et al., 2017] Gregory Cohen, Saeed Afshar, Jonathan
gent methods to converge, and it also increases the accuracy
Tapson, and Andre Van Schaik. Emnist: Extending mnist
in most cases. As a result, setting λ ≥ 0 is particularly useful
to handwritten letters. In 2017 International Joint Con-
in the non-IID setting, which indicates that the EFL benefits
ference on Neural Networks (IJCNN), pages 2921–2926.
practical federated settings.
IEEE, 2017.
5.4 Robustness of EFL [Dai et al., 2019] Xinyan Dai, Xiao Yan, Kaiwen Zhou, Han
Finally, in Figure 3, we demonstrate that EFL is robust to the Yang, Kelvin KW Ng, James Cheng, and Yu Fan. Hyper-
low participation rate. In particular, we track the convergence sphere quantization: Communication-efficient sgd for fed-
speed of LSTM trained on Sentiment140 and Shakespeare erated learning. arXiv preprint arXiv:1911.04655, 2019.
dataset. It can be observed that reducing the participation
[Deng et al., 2020] Yuyang Deng, Mohammad Mahdi Ka-
rate has negative effects on all methods. The causes for these
negative effects, however, are different: In FedAvg, the actual mani, and Mehrdad Mahdavi. Adaptive personalized fed-
participation rate is determined by the number of clients that erated learning. arXiv preprint arXiv:2003.13461, 2020.
finish the complete training process, because it does not in- [Draelos et al., 2017] Timothy J Draelos, Nadine E Miner,
clude the incomplete updates. This can steer the optimization Christopher C Lamb, Jonathan A Cox, Craig M Vineyard,
process away from the minimum and might even cause catas- Kristofor D Carlson, William M Severa, Conrad D James,
trophic forgetting. On the other hand, low participation rate and James B Aimone. Neurogenesis deep learning: Ex-
reduces the convergence speed of EFL by causing the clients tending deep networks to accommodate new classes. In
residuals to go out sync and increasing the gradient staleness. 2017 International Joint Conference on Neural Networks
The more rounds a client has to wait before it is selected to (IJCNN), pages 526–533. IEEE, 2017.
participate in training again, the more outdated the accumu-
[Duchi et al., 2014] John C Duchi, Michael I Jordan, and
lated gradients become.
Martin J Wainwright. Privacy aware learning. Journal
of the ACM (JACM), 61(6):1–57, 2014.
6 Conclusion
In this paper, we propose EFL as an unbiased FL algorithm [Go et al., 2009] Alec Go, Richa Bhayani, and Lei Huang.
that can adapt to the statistical diversity issue by making the Twitter sentiment classification using distant supervision.
most informative parameters less volatile. EFL can be under- CS224N project report, Stanford, 1(12):2009, 2009.
stood as an alternative paradigm for fair FL, which tackles [Haddadpour and Mahdavi, 2019] Farzin Haddadpour and
bias that is originated from the non-IID data and the low par- Mehrdad Mahdavi. On the convergence of local de-
ticipation rate. Theoretically, we provide convergence guar- scent methods in federated learning. arXiv preprint
antees for EFL when training on the non-IID data at the low arXiv:1910.14425, 2019.
participation rate. Empirically, experiments support the com-
petitive performance of the algorithm on the robustness and [Haddadpour et al., 2021] Farzin Haddadpour, Moham-
efficiency. mad Mahdi Kamani, Aryan Mokhtari, and Mehrdad
Mahdavi. Federated learning with compression: Unified
References analysis and sharp guarantees. In International Con-
ference on Artificial Intelligence and Statistics, pages
[Agarwal et al., 2018] Naman Agarwal, Ananda Theertha
2350–2358. PMLR, 2021.
Suresh, Felix Yu, Sanjiv Kumar, and H Brendan Mcma-
han. cpsgd: Communication-efficient and differentially- [He et al., 2016] Kaiming He, Xiangyu Zhang, Shaoqing
private distributed sgd. arXiv preprint arXiv:1805.10559, Ren, and Jian Sun. Deep residual learning for image recog-
2018. nition. In Proceedings of the IEEE conference on computer
[Aji and Heafield, 2017] Alham Fikri Aji and Kenneth vision and pattern recognition, pages 770–778, 2016.
Heafield. Sparse communication for distributed gradient [Huang et al., 2021] Yutao Huang, Lingyang Chu, Zirui
descent. arXiv preprint arXiv:1704.05021, 2017. Zhou, Lanjun Wang, Jiangchuan Liu, Jian Pei, and Yong
[Alistarh et al., 2017] Dan Alistarh, Demjan Grubic, Jerry Zhang. Personalized cross-silo federated learning on non-
Li, Ryota Tomioka, and Milan Vojnovic. Qsgd: iid data. In Proceedings of the AAAI Conference on Artifi-
Communication-efficient sgd via gradient quantization cial Intelligence, 2021.
and encoding. In Advances in Neural Information Pro- [Kairouz et al., 2019] Peter Kairouz, H Brendan McMa-
cessing Systems, pages 1709–1720, 2017. han, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Ar-
[Basu et al., 2019] Debraj Basu, Deepesh Data, Can jun Nitin Bhagoji, Keith Bonawitz, Zachary Charles, Gra-
Karakus, and Suhas Diggavi. Qsparse-local-sgd: Dis- ham Cormode, Rachel Cummings, et al. Advances and
tributed sgd with quantization, sparsification, and local open problems in federated learning. arXiv preprint
computations. arXiv preprint arXiv:1906.02367, 2019. arXiv:1912.04977, 2019.[Karimireddy et al., 2020a] Sai Praneeth Karimireddy, Mar- [Lin et al., 2018] Tao Lin, Sebastian U Stich, Kumar Kshitij
tin Jaggi, Satyen Kale, Mehryar Mohri, Sashank J Reddi, Patel, and Martin Jaggi. Don’t use large mini-batches, use
Sebastian U Stich, and Ananda Theertha Suresh. Mime: local sgd. arXiv preprint arXiv:1808.07217, 2018.
Mimicking centralized stochastic algorithms in federated [McMahan et al., 2017a] Brendan McMahan, Eider Moore,
learning. arXiv preprint arXiv:2008.03606, 2020. Daniel Ramage, Seth Hampson, and Blaise Aguera y Ar-
[Karimireddy et al., 2020b] Sai Praneeth Karimireddy, cas. Communication-efficient learning of deep networks
Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebas- from decentralized data. In Artificial Intelligence and
tian Stich, and Ananda Theertha Suresh. Scaffold: Statistics, pages 1273–1282. PMLR, 2017.
Stochastic controlled averaging for federated learning. In [McMahan et al., 2017b] H Brendan McMahan, Daniel Ra-
International Conference on Machine Learning, pages
mage, Kunal Talwar, and Li Zhang. Learning differen-
5132–5143. PMLR, 2020.
tially private recurrent language models. arXiv preprint
[Khaled et al., 2020] Ahmed Khaled, Konstantin arXiv:1710.06963, 2017.
Mishchenko, and Peter Richtárik. Tighter theory for
[Parisi et al., 2018] German I Parisi, Jun Tani, Cornelius We-
local sgd on identical and heterogeneous data. In Interna-
ber, and Stefan Wermter. Lifelong learning of spatiotem-
tional Conference on Artificial Intelligence and Statistics,
poral representations with dual-memory recurrent self-
pages 4519–4529. PMLR, 2020.
organization. Frontiers in neurorobotics, 12:78, 2018.
[Kirkpatrick et al., 2017] James Kirkpatrick, Razvan Pas-
[Reisizadeh et al., 2020] Amirhossein Reisizadeh, Aryan
canu, Neil Rabinowitz, Joel Veness, Guillaume Des-
jardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Mokhtari, Hamed Hassani, Ali Jadbabaie, and Ramtin
Ramalho, Agnieszka Grabska-Barwinska, et al. Overcom- Pedarsani. Fedpaq: A communication-efficient federated
ing catastrophic forgetting in neural networks. Proceed- learning method with periodic averaging and quantization.
ings of the national academy of sciences, 114(13):3521– In International Conference on Artificial Intelligence and
3526, 2017. Statistics, pages 2021–2031. PMLR, 2020.
[Konečnỳ et al., 2016] Jakub Konečnỳ, H Brendan McMa- [Rusu et al., 2016] Andrei A Rusu, Neil C Rabinowitz,
han, Felix X Yu, Peter Richtárik, Ananda Theertha Suresh, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick,
and Dave Bacon. Federated learning: Strategies for Koray Kavukcuoglu, Razvan Pascanu, and Raia Had-
improving communication efficiency. arXiv preprint sell. Progressive neural networks. arXiv preprint
arXiv:1610.05492, 2016. arXiv:1606.04671, 2016.
[Krizhevsky et al., 2009] Alex Krizhevsky, Geoffrey Hinton, [Sahu et al., 2018] Anit Kumar Sahu, Tian Li, Maziar San-
et al. Learning multiple layers of features from tiny im- jabi, Manzil Zaheer, Ameet Talwalkar, and Virginia Smith.
ages. 2009. On the convergence of federated optimization in hetero-
geneous networks. arXiv preprint arXiv:1812.06127, 3,
[LeCun et al., 1998] Yann LeCun, Léon Bottou, Yoshua 2018.
Bengio, and Patrick Haffner. Gradient-based learning ap-
plied to document recognition. Proceedings of the IEEE, [Shin et al., 2017] Hanul Shin, Jung Kwon Lee, Jaehong
86(11):2278–2324, 1998. Kim, and Jiwon Kim. Continual learning with deep gener-
ative replay. In Advances in neural information processing
[Li et al., 2018] Tian Li, Anit Kumar Sahu, Manzil Zaheer, systems, pages 2990–2999, 2017.
Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith.
Federated optimization in heterogeneous networks. arXiv [Simonyan and Zisserman, 2014] Karen Simonyan and An-
preprint arXiv:1812.06127, 2018. drew Zisserman. Very deep convolutional networks
for large-scale image recognition. arXiv preprint
[Li et al., 2019] Xiang Li, Kaixuan Huang, Wenhao Yang,
arXiv:1409.1556, 2014.
Shusen Wang, and Zhihua Zhang. On the convergence of
fedavg on non-iid data. arXiv preprint arXiv:1907.02189, [Soltoggio, 2015] Andrea Soltoggio. Short-term plasticity as
2019. cause–effect hypothesis testing in distal reward learning.
Biological cybernetics, 109(1):75–94, 2015.
[Li et al., 2020a] Tian Li, Anit Kumar Sahu, Ameet Tal-
walkar, and Virginia Smith. Federated learning: Chal- [Stich, 2018] Sebastian U Stich. Local sgd con-
lenges, methods, and future directions. IEEE Signal Pro- verges fast and communicates little. arXiv preprint
cessing Magazine, 37(3):50–60, 2020. arXiv:1805.09767, 2018.
[Li et al., 2020b] Zhize Li, Dmitry Kovalev, Xun Qian, and [Tsuzuku et al., 2018] Yusuke Tsuzuku, Hiroto Imachi, and
Peter Richtárik. Acceleration for compressed gradient Takuya Akiba. Variance-based gradient compression
descent in distributed and federated optimization. arXiv for efficient distributed deep learning. arXiv preprint
preprint arXiv:2002.11364, 2020. arXiv:1802.06058, 2018.
[Liang et al., 2019] Xianfeng Liang, Shuheng Shen, [Wang and Joshi, 2018] Jianyu Wang and Gauri Joshi. Co-
Jingchang Liu, Zhen Pan, Enhong Chen, and Yifei Cheng. operative sgd: A unified framework for the design and
Variance reduced local sgd with lower communication analysis of communication-efficient sgd algorithms. arXiv
complexity. arXiv preprint arXiv:1912.12844, 2019. preprint arXiv:1808.07576, 2018.[Zhao et al., 2018] Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, and Vikas Chandra. Fed- erated learning with non-iid data. arXiv preprint arXiv:1806.00582, 2018. [Zhou and Cong, 2017] Fan Zhou and Guojing Cong. On the convergence properties of a k-step averaging stochas- tic gradient descent algorithm for nonconvex optimization. arXiv preprint arXiv:1708.01012, 2017. [Zhu et al., 2020] Wennan Zhu, Peter Kairouz, Brendan McMahan, Haicheng Sun, and Wei Li. Federated heavy hitters discovery with differential privacy. In International Conference on Artificial Intelligence and Statistics, pages 3837–3847. PMLR, 2020.
You can also read

















































