N-Gram Statistical Grammar Checker for an Indian Language - sersc
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
International Journal of Advanced Science and Technology
Vol. 29, No. 3, (2020), pp. 3098- 3106
N-Gram Statistical Grammar Checker for an Indian Language
Leekha Jindal1, Dr, Vijay Rana 2, Dr, Sanjeev Kumar3
1
Research Scholar ,SBBS University
2
Head, Department of Computer Sc.SBBS University
3
Head, Department of Computer Science, DAV University Jalandhar.
Abstract
This study aims to illustrate the author’s findings about the design and the advances that have occurred in the
Statistical Grammar Checker, specifically for a robust, vibrant and a rich morphological language, that is, Punjabi.
Along with this, several other submissions for Grammar Checking have also been discussed. How in a given sentence,
at first the Parts-Of-Speech tags of particular words combining together to build a new sentence are analyzed, and
how then the N-gram based probabilistic strategies are used to conclude whether the sentence stands vague or
conveys a desired meaning, forms the basis of this research article. The system is, however, tested with definite types
of corpus. Additionally, Bigram and Trigram probabilities have also been considered and calculated. As a result of
which, The Recall of Statistical Grammar Checker (92.29) and Precision (93.14) have successfully been achieved.
Introduction
In layman’s language, a software that permits any individual to process a given piece of a work or a text, written in
any language, in order to find out the grammatical errors, is called The Grammar Checker of a particular language.
The software is designed as such that it helps the user to find out the improper sentence structures in the given text,
and then also provides the help to rectify and improve that sentence, without changing its actual meaning and context.
This does not put an end to the benefits of this. To begin with, it lists out the errors in the sentence structure, then
states the reason for its abruptness and at the end; it provides the individual with a new grammatically appropriate and
an acceptable sentence.When we talk about the universal language, that is, English, various respectable and renowned
researchers have made their contributions for the advancement of The Grammar Checkers. But sadly, a minimal
amount of effort has been made in the field of Indian languages. The actual number of these can be counted on our
fingers.For instance, we have Bangla grammar checker [Alam, M. Jahangir et.al (2006) [21], Urdu [Kabir, H. et.al
(2002) [23], Hindi [Bopche, L. et.al (2012) [11] and Punjabi grammar checker [Singh M. et.al (2008) [18].
About Punjabi Language
It is unbelievable that an Indo-Aryan language, such as Punjabi, has more than 125 million native speakers in the
Indian subcontinent and around the world. Punjabi originally developed from Sanskrit through Prakrit languages.
Derived from the word Panjab, this language is famous for its rich literature. It even has acquired an official status via
the Eighth Schedule to the Indian Constitution.
Being the official language of Punjab, this language has spread its wings all around the world. Talking about the
scripts, the natives of eastern Punjab follow the Gurmukhi script, where as the ones in the western part, use
Shahmukhi script.
Literature Review
A system to check the grammar was proposed by S. Rashmi et. Al in the year 2017, in which they made use of a
model of Trigram Language with a probabilistic technique for applying the Parts-Of-Speech Tags onto the text.
Another approach for the advancement of Grammatika (used for the Filipino), was proposed by Matthew Phillip Go
et.al, in the year 2017. He put forth the idea of a Hybrid N-Gram approach. The idea was to use N-grams of different
or similar words, the Parts-Of-Speech Tags and various lexicons selected from the corpus.
In the year 2016, pains were also taken by Sharma, S.K. et.al. Their contribution stands forth for the improvement of
the already existing Grammar Checker of the Punjabi language. They noticed an improvement of about 5-6 percent
approximately in the morphemes and 8-9 percent approximately in the development of Parts-Of-Speech Tags.Another
contribution was made by Lin, C. J. et.al, in the year 2015. He talked about a system that attempted to find out the
accuracy and appropriateness of the Grammar of the sentences that are made by omitting, adding, or interchanging
the words.
3098
ISSN: 2005-4238 IJAST
Copyright ⓒ 2019 SERSC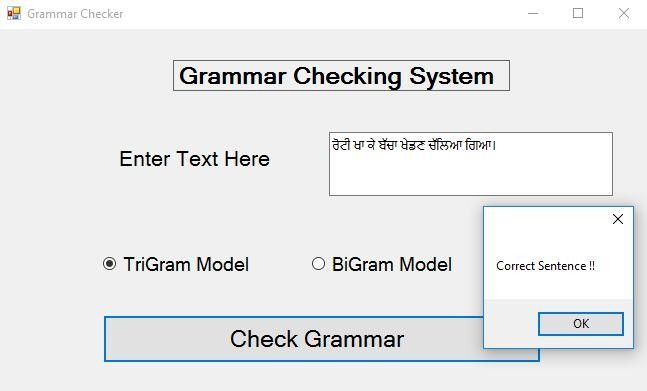
International Journal of Advanced Science and Technology
Vol. 29, No. 3, (2020), pp. 3098- 3106
The description of the outlook and the structure of The Amharic language Checker was brought up by Temegen, A.
et.al, in the year 2013. When Bigram was used for the simple sentence structures, Recall came out to be 82.69 percent
and the Precision was calculated to be 59.72 percent. For similar sentences, when Trigram was used, Recall showed
90.3 percent and the Precision came out to be 59.72 percent.
Another remarkable achievement in this field was portrayed by Joshi, N. et.al in the year 2013. A completely different
approach was used by them to basically improve the use of Parts-Of-Speech tags for the Hindi language. The model
named Hidden Markov was employed to resolve and disambiguate the various combinations of the words forming
sentences. And as a matter of fact, using an unusual approach like this, showed an accuracy of about 92.13 percent of
the data tested.
The year 2012 was none the less. Nazar, R.et.al ascertained that the odds of developing the lexical transitions by
means of a large corpus, are very high.
An approach to detect the errors was also determined by Bopche, L. et.al in the year 2012. This approach basically
aimed to distinguish the grammatical errors in the Hindi language. After conducting several researches, the authors
finally concluded that for the simple and basic sentences of the hindi language, this approach is the best. On top of
that, the rules employed in this approach were manually designed.
The year 2006 was remarkable in its own sense. Alam, M. Jahangir et. Al made use of the N-gram approach combined
with the Parts-Of-Speech Tags. They combined both of these to make sure about the grammatical accuracy of any
sentence in general. They decided to fix a value at first, that is, the threshold value, and then calculated the result. If
the desired result came out to be greater than the threshold value, then the sentence is grammatically accurate, and vice
versa. This method was employed on two languages including English and Bangla.
Grammar Checking Techniques
Many researchers used a variety of techniques and approaches to develop a distinctive Grammar Checker. These
approaches can basically be classified into three categories, namely,
1. Syntax Based: Using this approach, an individual can disintegrate a sentence into its component
parts and then explain their syntactic roles. If a sentence can be broken down into its components
completely, it can be concluded that the sentence is grammatically correct.
2. Statistics Based: This approach centers itself on the probability of getting a grammatically
correct sentence. It involves the generation of Parts-of-Speech Tags from a corpus which is
annotated, that is, every word has a link with the grammar. After the generation, the frequency is
checked carefully and then finally the probability is calculated. Hence, if the calculated tag
sequence turns out to be of greater probability than the pre-determined threshold, the text would be
concluded as grammatically correct.
3. Rule Based: To begin with, the rules are formulated beforehand. Then each sentence is verified
against these rules. If the sentence follows the same pattern as that of the rule, the sentence turns out
to be grammatically correct.
4. Hybrid Based: The combination of the statistical and the rule based methodology is called the
Hybrid Based Approach.
Methodology
When we use the statistical approach, we are able to unravel the many probabilities of any grammatically correct
sentence using the Gram Analysis.
For instance,
Making use of a Bigram Probabilty for the given sentence,
P( “It is a rainy day”) = P(It|is) * P(is|a) * P(a|rainy) * P(rainy|day)
3099
ISSN: 2005-4238 IJAST
Copyright ⓒ 2019 SERSC
International Journal of Advanced Science and Technology
Vol. 29, No. 3, (2020), pp. 3098- 3106
Here, we can observe that the word-to-word probability occurrence has been made. However, this methodology has a
major con. To understand this, let us imagine that our corpus is devoid of these words – ‘a rainy’. And imagining this
to be true, P(a|rainy) will automatically turn out to be a ZERO, as a result of which the probability of the entire
sentence would turn out to be ZERO.
To avoid this situation, it is always better to make use of the Parts-Of-Speech Tags inspite of using
just the words.
Using POS, the sentence would be improvised as: It/P is/V
a/Det rainy/Adj day/Noun
Based on this structure, it would however be easy to calculate the desired probability or the result
of the sentence, which would be,
P(P V Det Adj Noun) = P(P|V) * P(V|Det) * P(Det|Adj) * P(Adj|Noun)
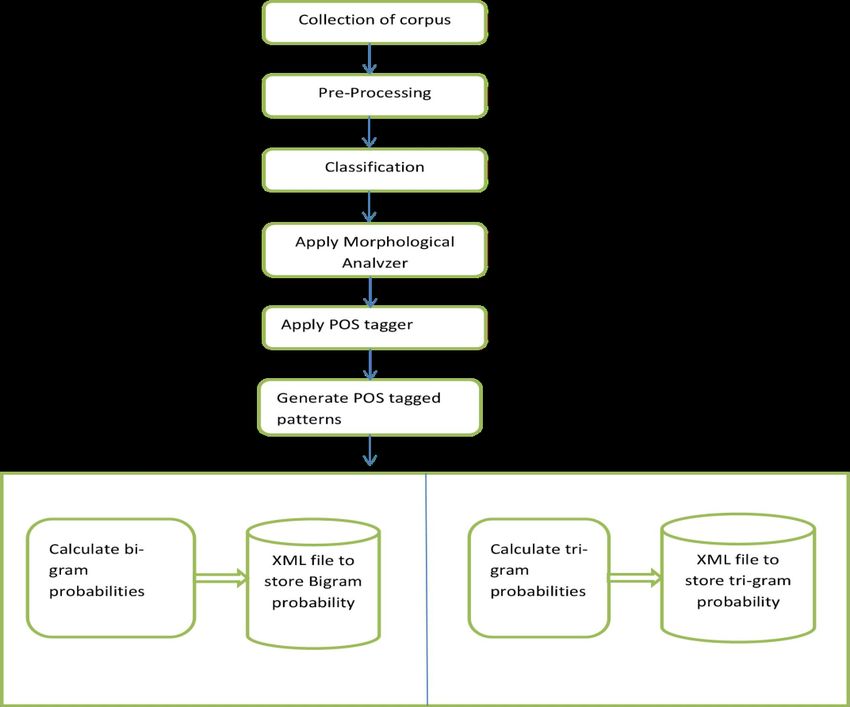
Algorithm 1- Calculating n-gram Probabilities
To calculate the result and check the grammar of a particular sentence, the first requirement is a tagged corpus. The
Indian Language Corpus Initiative Association designed a corpus for the Punjabi language using 36 different
standardized tags of the same. This view or the idea was basically proposed by The Technology Development Of
Indian Languages. This annotated corpus comprised 49319 sentence structures and approximately 63000 inimitable
words.
We have proposed here an algorithm to evaluate the Bigram and the Trigram Probabilities by making use of an
annotated corpus.
Step 1: Collection of an Authenticated annotated Corpus. Step 2:
Tokenize POS tag for each word of a sentence.
Step 3: Extract the Bigram and the Trigram tag pattern.
Step 4: Calculate the Bigram and the Trigram probabilities by using the following formula:
Bigram Probability of tag i and tag j pair i.e.
Nu NberoftiNeta䁞ian䁞ta䁞jpairo ur int耀e orpu
Pij=
Tota nuNberofpair int耀e orpu
Trigram probability of tag i, tag j and tag k
Nu NberoftiNeta䁞i耀 ta䁞jan䁞ta䁞䁓o ur int耀eorpu
Pijk=
Tota nuNberoftri䁞raN int耀e orpu
Step 5: Store these calculated probabilities in database.
3100
ISSN: 2005-4238 IJAST
Copyright ⓒ 2019 SERSC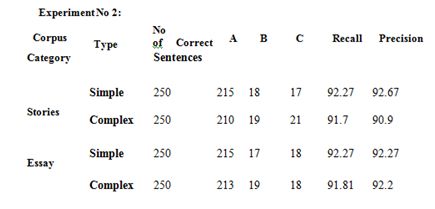
International Journal of Advanced Science and Technology
Vol. 29, No. 3, (2020), pp. 3098- 3106
Figure 1: Proposed model for calculating N-gram probabilities.
Algorithm 2: To Check the correctness of sentence:
Step 1: Input Punjabi sentence. Step 2:
Tokenize the text.
Step 3: Apply morphological analyzer and POS tagger to assign single part of speech tag to each
word.
Step 4: Generate the Bigram and the Trigram tag pattern.
Step 5: Search for the Bigram and the Trigram Probabilities for the generated tag patterns from the
database.
Step 6: Overall probability of sentence P s will be calculated as:
Here P ij and P ijk are bigram and trigram probabilities.
Step 7: The base threshold to be set ZERO. After carrying out the experiment, if the final value exceeds the threshold
set, only then the sentence would be considered to be grammatically correct.
The complete architecture of this result has been shown in the figure 2.
3101
ISSN: 2005-4238 IJAST
Copyright ⓒ 2019 SERSC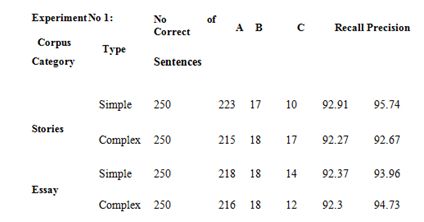
International Journal of Advanced Science and Technology
Vol. 29, No. 3, (2020), pp. 3098- 3106
Figure 2: Checking Correctness of Input Punjabi Sentence
Results and Critical Evaluation
This portion explains the execution of the algorithm proposed above. The setup for carrying out the experiment was
3102
ISSN: 2005-4238 IJAST
Copyright ⓒ 2019 SERSCInternational Journal of Advanced Science and Technology
Vol. 29, No. 3, (2020), pp. 3098- 3106
made using C# platform. To conduct the experiment without any bias and accurately, variety of Corpus was used. And
for a better and an efficient result, the Trigram Model has been used, as it gives out the precise and the most accurate
result using the two tags at a time.
Example 1 :
The Bigram Model: (considers only one previous tag) - To find out the probability of the tag sequence and then
conclude about the grammatical appropriateness and accuracy of the sentence.
P(N_NN|NONE)= 0.000386049951201500
P(V_VM_VF|N_NN) 0.000022587592582912
P(V_VM_VNF|V_VM_VF)0.000735409991070022
P(N_NN|V_VM_VNF) 0.000630351420917161
P(V_VM_VNF|N_NN) 0.002157587855229296
P(V_VM_VF|V_VM_VNF) 0.000367704995535011
P(V_VM_VF|V_VM_VF ) 0.003256815674738607
P(RD_PUNC|V_VM_VF) 0.010045394320114320
Thus, the probability turns out to be greater than the threshold. Hence the
result: It is a Correct Sentence.
The Trigram Model (considers two previous tags) - To find out the probability of the tag sequence and lastly
conclude that whether the given sentence is grammatically appropriate or not.
(b�Ȁ◌ੀ\N_NN Œ†\V_VM_VF §`\V_VM_VNF B˘b†\N_NN Œ`ð7\V_VM_VNF
b˘f⺁W\V_VM_VF f⍰W\V_VM_VF l\RD_PUNC )
P(N_NN|None None) = 0.001230010255350021
P(V_VM_VF|NoneN_NN)=0.000367704995535011 P(V_VM_VNF| N_NN
V_VM_VF )= 0.000262646425382151 P(N_NN|V_VM_VF V_VM_VNF) =
0.00036770499553501 P(V_VM_VNF| V_VM_VNF N_NN) =
0.000141829069706361 P(V_VM_VF|N_NN V_VM_VNF )=
0.010361656425282021 P(V_VM_VF|V_VM_VNF
V_VM_VF)=0.000034561120001003 P(RD_PUNC | V_VM_VF V_VM_VF
)=0.000121378210000100
Here, the probability calculated of the tag sequence exceeds the threshold. Hence, the
result: It is a Correct Sentence.
Example 2:
Y� Nd´ð† P§ ⺁ u†Y` UVl
Y�\QT QTC Nd´ð†\N NN P§ ⺁\N NN u†Y\` V VM VFUV\V VAUX l\RD PUNC
3103
ISSN: 2005-4238 IJAST
Copyright ⓒ 2019 SERSCInternational Journal of Advanced Science and Technology
Vol. 29, No. 3, (2020), pp. 3098- 3106
P(QT_QTC|None None) =0.0127100000456832
P(N_NN | None QT_QTC) =0 P(N_NN|QT_QTCN_NN)
= 0.0546304564794873
P(V_VM_VF|N_NNN_NN) =0.0335302500794010
P(V_VAUX|N_NNV_VM_VF) 0.0000301440900123
P(RD_PUNC|V_VM_VFV_VAUX)=0.0000149907650
Thus, the result for the Overall Probability turns out to be ZERO. Hence, the
result: The sentence is Incorrect or Inappropriate.
Figure - 3: Statistical Grammar Checker
From different online sources as well as offline sources, the data was collected in which it was made sure that half of
the total sentences, that is, 2000, were correct and the other half was incorrect. Further they were segregated as either
simple or complex sentences according to their length. Generally, a sentence with either five or less than five words is
termed as a Simple sentence. And a sentence with more than five words is described as a Complex sentence.A couple
of experiments was carried out each containing a thousand sentences from different areas..
3104
ISSN: 2005-4238 IJAST
Copyright ⓒ 2019 SERSCInternational Journal of Advanced Science and Technology
Vol. 29, No. 3, (2020), pp. 3098- 3106
Conclusion
To conclude, it cannot be denied that one of the universally accepted and extensively used functions to process the
words is The Grammar Checker. We, however, have proposed and projected a Statistical Grammar Checker for
specifically Punjabi Language. After carrying out the experiments, the desired results were achieved, that is, Recall
came out to be 92.37 percent and the Precision turned out to be 93.96 percent. The appropriateness and the accuracy of
the carried out experiments using the proposed system were satisfying. It was also determined that if word tag
probabilities will be considered and calculated, the Grammar Checker will show more accurate results.Thus, an
individual can also extend the use of this Statistical Grammar Checker to create the Grammar Checker for all the
other Indian languages including Oriya, Hindi, Marathi, Gujarati and many more.
References
1. Rashmi, S., &Hanumanthappa, M. (2017). Qualitative and quantitative study of syntactic structure: a
grammar checker using part of speech tags. International Journal of Information Technology, 9(2),
159-166.
2. Matthew Phillip Go, NiccoNocon and Allan Borra(2017). Gramatika: A Grammar Checker for the
Low-Resourced Filipino Language. Proc. of the 2017 IEEE Region 10 Conference (TENCON),
Malaysia, November 5-8, 2017
3. Schmaltz, A., Kim, Y., Rush, A. M., &Shieber, S. M. (2017). Adapting sequence models for sentence
correction. arXiv preprint arXiv:1707.09067.
4. Sharma, S. K., &Lehal, G. S. (2016, March). Improving Existing Punjabi Grammar Checker. In
Computational Techniques in Information and Communication Technologies (ICCTICT), 2016
International Conference on (pp. 445-449). IEEE.
5. Schmaltz, A., Kim, Y., Rush, A. M., &Shieber, S. M. (2016). Sentence-level grammatical error
identification as sequence-to-sequence correction. arXiv preprint arXiv:1604.04677.
6. Lin, C. J., & Chen, S. H. (2015, July). NTOU Chinese Grammar Checker for CGED Shared Task. In
Proceedings of The 2nd Workshop on Natural Language Processing Techniques for Educational
Applications (pp. 15-19).
7. Boroș, T., Dumitrescu, S. D., Zafiu, A., Tufiș, D., Barbu, V. M., &Văduva, P. I. (2014). RACAI
GEC–A hybrid approach to Grammatical Error Correction. CoNLL-2014, 43.
3105
ISSN: 2005-4238 IJAST
Copyright ⓒ 2019 SERSCInternational Journal of Advanced Science and Technology
Vol. 29, No. 3, (2020), pp. 3098- 3106
8. Temesgen, A., &Assabie, Y. (2013). Development of Amharic Grammar Checker Using
Morphological Features of Words and N-Gram Based Probabilistic Methods. IWPT-2013, 106.
9. Joshi, N., Darbari, H., &Mathur, I. (2013). HMM based POS tagger for Hindi. In Proceeding of 2013
International Conference on Artificial Intelligence, Soft Computing (AISC-2013).
10. Nazar, R.,&Renau, I. (2012, April). Google books n-gram corpus used as a grammar checker. In
Proceedings of the Second Workshop on Computational Linguistics and Writing (CLW 2012):
Linguistic and Cognitive Aspects of Document Creation and Document Engineering (pp. 27-34).
Association for Computational Linguistics.
11. Bopche, L., Dhopavkar, G., &Kshirsagar, M. (2012). Grammar Checking System Using Rule Based
Morphological Process for an Indian Language. Global Trends in Information Systems and
Software Applications, 524-531.
12. Jiang, Y., Wang, T., Lin, T., Wang, F., Cheng, W., Liu, X., & Zhang, W. (2012, June). A rule based
Chinese spelling and grammar detection system utility. In System Science and Engineering (ICSSE),
2012 International Conference on (pp. 437-440). IEEE
13. Sharma, S. K., &Lehal, G. S. (2011, June). Using hidden markov model to improve the accuracy of
punjabipos tagger. In Computer Science and Automation Engineering (CSAE), 2011 IEEE
International Conference on (Vol. 2, pp. 697-701). IEEE.
14. Tesfaye, D. (2011). A rule-based Afan Oromo Grammar Checker. IJACSA Editorial.
15. Kasbon, R., Amran, N. A., Mazlan, E. M., &Mahamad, S. (2011). Malay language sentence checker.
16. Deksne, D., &Skadiņš, R. (2011). CFG Based Grammar Checker for Latvian. NODALIDA 2011 Conference
Proceedings, pp. 275–278.
17. Henrich, V., & Reuter, T. (2009). LISGrammarChecker: Language Independent Statistical Grammar
Checking. Hochschule Darmstadt & Reykjavík University.
18. Singh, M., &Lehal, G. S. (2008, August). A grammar checking system for Punjabi. In 22nd
International Conference on Computational Linguistics: Demonstration Papers (pp. 149-152).
Association for Computational Linguistics.
19. Kumar, A., & Nair, S. (2007). An artificial immune system based approach for English grammar
che99cking. Artificial immune systems, 348-357.
20. Bal, B. K., Shrestha, P., Pustakalaya, M. P., &PatanDhoka, N. (2007). Architectural and System
Design of the Nepali Grammar Checker. PAN Localization Working Paper.
21. Alam, M. Jahangir, NaushadUzZaman, and Mumit Khan. 2006. N-gram based Statistical Grammar
Checker for Bangla and English. In Proc. of ninth International Conference on Computer and
Information Technology (ICCIT 2006).
22. JonasSjöbergh, J. V. O. (2004, January) Grammar checking for Swedish second language learners.
23. Kabir, H., Nayyer, S., Zaman, J., & Hussain, S. (2002, December). Two pass parsing Implementation
for an Urdu grammar checker. In Proceedings of IEEE international multi topic conference (pp. 1-8).
3106
ISSN: 2005-4238 IJAST
Copyright ⓒ 2019 SERSCYou can also read

















































