ICDSST 2021 on Decision Support Systems, Analytics and Technologies in response to Global Crisis Management Automated physical document ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
————————————————————————————————————————————————————————
ICDSST 2021 Proceedings – Online Version
The EWG-DSS 2021 INTERNATIONAL CONFERENCE ON DECISION SUPPORT SYSTEM TECHNOLOGY
(editors)
Loughborough, UK, 26-28 May 2021
ICDSST 2021 on
Decision Support Systems, Analytics and Technologies in
response to Global Crisis Management
Automated physical document interpretation and validation via
artificial intelligence
Giulia De Poli, Davide Cui, Manuela Bazzarelli, Leone De Marco, Matteo Bregonzio
3rdPlace SRL
Foro Buonaparte 71, 20121 Milan, Italy
giulia.depoli@3rdplace.com, davide.cui@3rdplace.com, manuela.bazzarelli@3rdplace.com,
leone.demarco@3rdplace.com, matteo.bregonzio@3rdplace.com
web-page: www.3rdplace.com
ABSTRACT
Identity validation and data gathering through physical documents (papers and cards) is still
widely adopted in several sectors including retail banking, insurance, and public
administration. Those tasks generally consist in manually transcribing relevant fields from
physical documents to a dedicated software application. This is due to many reasons such as
the sensitive nature of these operations and the lack of suitable digital alternatives; however,
this process remains time consuming, expensive, and prone to human error. For these reasons,
there is still a strong need for automating physical document interpretation and data extraction,
mainly in the instances where documents could rapidly be digitised (scanned). Therefore, we
devised an innovative A.I. based pipeline for automatically acquire, process, and validate
digitised documents and the related manually extracted fields. Our solution constitutes a
support layer for the human agents enabling faster document processing and drastically reduce
errors in the operations. The proposed pipeline leverages Cloud infrastructure for scalability,
employing several A.I. techniques from Computer Vision to Convolutional Neural Networks.
Despite the accuracy may vary depending on document type and the specific field to recognize,
we observed promising experimental results. On average, it reached 92.6% accuracy for
document recognition tasks and 81.1% for the field extraction tasks. Furthermore, we foresee
a significant reduction in operational time and errors.
Keywords: Document Processing, Document OCR, Intelligent data capture, Machine
learning, Document validation, Object detection, Computer Vision.
1
INTRODUCTION
Nowadays, we are more and more accustomed to quickly validating our identity or sharing
personal data using digital devices and secrets: passwords, digital signatures, fingerprint
readers, or two factor authentications. Despite the global digitalisation process, physical
documents remain still relevant and widely adopted for sensitive tasks such as opening a new
bank account, loan or insurance applications, and public administration enquiries. Although a
significant effort has been made by governments in order to create “digital ready” physical
documents, not all institutions have caught up and, most importantly, a good amount of
circulating documents is still of the old kind. Physical documents are, to this day, processed
manually by agents that have to extract the relevant information and transcribe it within
specialized software applications. In such a landscape, there is a strong need for a way to
automate, at least partially, this pipeline in order to make the process more efficient, quicker
and less error prone. To answer this question, we devised and implemented an innovative
system able to automatically extract the relevant information from scanned documents and
compare it with the data extracted by a human agent. The checks performed by the automated
system support the agents by promptly notifying them if inconsistencies are detected between
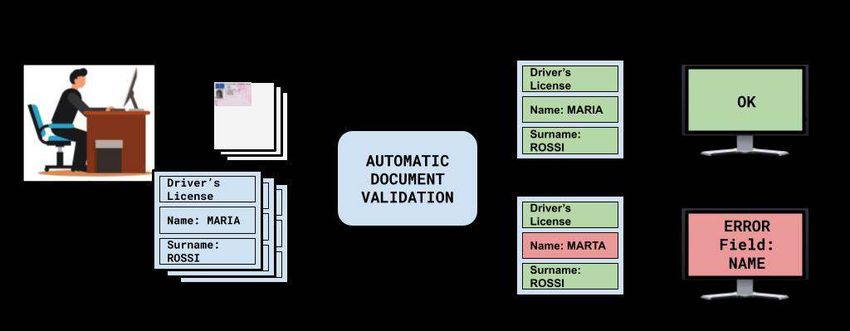
the analysed documents and the entered information, as shown in Figure 1. Given the high
specificity of the proposed system, we could not find in the literature works that encompassed
the entirety of its scope. On the other hand, automatic document processing is a very popular
domain, for obvious reasons. A huge body of work has been devoted to many different aspects
such as Optical Character Recognition [1], document classification employing Natural
Language Processing techniques [2] etc. In brief, the two main problems tackled by our system
are: (1) Identification of document type from its scanned image; with document type we mean
ID card, driver license, passport, etc. (2) For a given document type, extracting a subset of
salient fields such as name, surname, address, expiry date, etc. Regarding the first problem, the
literature is rich with works that either focus on the subtask of identifying and classifying
different parts of the document (such as tables, graphs) [3,4] or methods that focus on a specific
language (usually English) and need a huge amount of training data [5]. In contrast to this, our
application needed methods that were language agnostic, fast and that did not require a large
training set. Additionally, the system needed to be able to identify several types of documents,
including several formats for each type (i.e., paper version ID and plastic card ID). For this
reason, we took inspiration from template matching techniques [6] and Deep Learning with
transfer learning [7] for solving the document object detection task. Similarly, when developing
the information extraction module, we struggled to find relevant literature suitable for our task:
most works were too specific [8]. To this end, we decided to integrate Rusinol et al. [9] method
in our pipeline.
2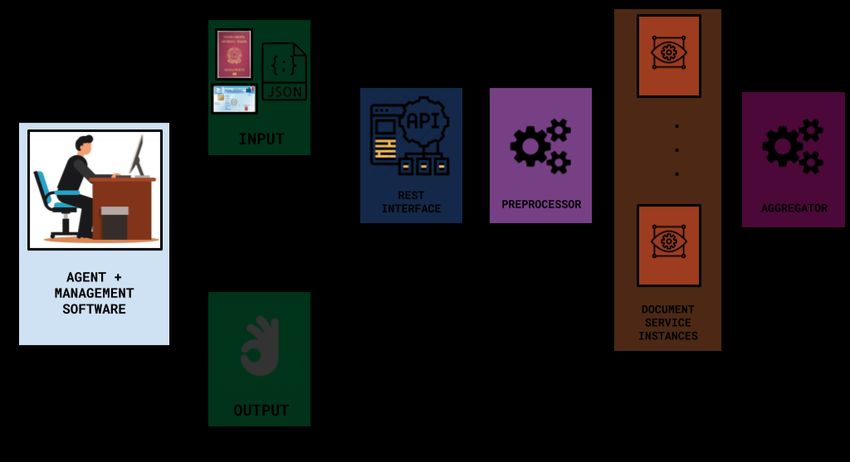
Figure 1. Support system for physical document fields extraction. Scenario a: the agent
correctly transcribes relevant fileds from physical documents to a dedicated software
application; the file is successfully submitted. Scenario b: a field is erroneously transcribed
hence the agent promptly receives a message indicating the mistake enabling him/her to
quickly fix it and resubmit the file.
SYSTEM FLOW AND ARCHITECTURE
In a nutshell, our system is a support layer for the human agents in charge of manually
processing documents and entering data in specialized software applications. This support on
one hand aims to drastically speed up and reduce operational errors; on the other it needs to be
highly compatible with legacy applications. To deliver quasi-real-time outputs, the proposed
architecture exploits Google Cloud Platform technologies such as Functions, Compute Engine,
Pub Sub, Storage, and Cloud Run.
To better express the complexity of the problem, it is important to mention that each input
scanned image may contain more than one document (i.e., identity card and driver license) and
the system is not notified with the kind of documents contained in the image. Additionally, the
key-value pairs transcribed by the human agent are provided as input in a JSON, without
specifying from which document they were extracted from. As presented in Figure 2, the
architecture is composed of 4 logical modules:
REST Interface - allows the system to receive both the scanned documents (images) and
the information extracted by the human agent (JSON payload). Saves both images and
information on the cloud and activates a preprocessor instance.
Preprocessor - Standardizes all images without compromising quality by converting them
to grayscale png format, and subsequently, for each image it invokes one Document Service
instance for each possible document type.
Document Service - Each document service instance will try to detect a specific document
type and, if successful, process the image in order to crop it, straighten it and perform Optical
Character Recognition and field key-value assignment on it.
Aggregator - Finally, the aggregator receives the outputs of all Document Service
instances: for each instance, either a document was recognized, processed and its field values
recognized and extracted, or not (in this case the output is “not recognized”). Based on these
results, the aggregator is able to determine which fields and documents were recognized and
can compare the field key-values pairs extracted with the ones sent by the agent. If any
documents could not be recognized and/or any fields were not consistent with the input, an
3error message with the details is generated. The message is sent by the aggregator to the REST
Interface that will in turn relay the message to the agent.
Figure 2. System architecture of the proposed support system. The system input is
composed of scanned images of physical documents and a JSON with the human agent field
transcriptions. A REST interface is employed to interact with the application used by the
agent. Preprocessor, Document Service, and Aggregator are used to process input images
and validate the agent transcriptions.
MATERIALS & METHODS
Dataset
The training dataset is composed of (1) document images and (2) the related information
extracted by the agents which is stored as keys-value pairs within a JSON file. The analysed
documents belong to six types: fiscal code card, NHS card, identity card (three versions),
driving licence (three versions), passport and residence permit. Some documents appear in
more than one version due to layout changes over time, making a total of ten document layouts.
In addition, each document layout has both front and back side. Document layouts are not
equally represented in the dataset; for instance, paper driving licences, which were released
until 1999, have much fewer samples compared to modern card driver licenses.
Document Service
The Document Service module is composed of two submodules responsible for: i)
document recognition ii) field recognition and text extraction.
The document recognition submodule identifies the area in the image (box) where the
document is present, crops it and straightens it. Like its parent module, each document
recognition instance is specific for a document type and it is trained to recognize its front and
back side. We developed two methods, Method1 for documents for which we had at least 100
4samples in our training set, and Method 2 otherwise.
In Method 1 an AutoML [10] Vision model based on Convolutional Neural Networks is
trained specifically for each document type that met the training quota; in our experiment it
resulted in four models. Each trained model detects three bounding box classes: front template,
back template or other (for document types different from the one recognized by the model).
Finally, bounding boxes are straightened using image registration. Image registration [11] is
achieved by comparing phase cross correlation on a reference template and t he selected
bounding box Discrete Fourier Transform (DFT). The Method 1 end -to-end is depicted in
Figure 3.
Figure 3: Method 1 used to detect, crop and straighten documents
Method 2 is instead used with document types having fewer training samples. Basically, it
consists in a template matching approach based on SIFT [12] (Scale-Invariant Feature
Transform). The SIFT output allows to automatically align the detected box against a reference
template.
Once all document bounding boxes are extracted Google Vision API [14] Optical Character
Recognition (OCR) is applied. In order to improve OCR performances, super-resolution [13]
is applied to enhanced the image quality of the boxes. The OCR returns a set of text-bounding
box pairs utilised in the downstream steps.
In our application, given a document type, we select only the bounding boxes corresponding
to the relevant fields (such as “Name”, “Surname”, etc). Furthermore, for each document type
a geometric template is created in order to define distances of relevant fields from selected
reference boxes. Reference boxes are non-varying portions of the document used as anchors to
understand the position of relevant fields within the image. Geometric template is the strategy
adopted to then extract relevant field values.
Field text validation
The Aggregator module receives the document service’s outputs and performs two tasks.
The first involves comparing the results from the different document services and determines
whether one or more documents are present and which type they belong to. Secondly, it
compares the extracted relevant fields with the human agent input and checks for
inconsistencies. Comparison tolerance depends on the field type, e.g., some fields like
document number have to be a perfect match, while for others like addresses where it happens
that the same address is reported in a slightly different way (e.g., M.L. King St. vs Martin
Luther King Street), a larger tolerance is applied. Finally, a response is delivered highlighting
5missing and inconsistent fields in order for the agent to perform a second check and resubmit.
Differently, if everything is consistent, an OK message is returned to the agent.
RESULTS
We tested the system using a set of 100 randomly selected procedure submissions composed
of a total of 218 documents. Evaluation was based on two metrics:
1. Document recognition accuracy: percentage of documents correctly identified
2. Field extraction accuracy: percentage of correctly extracted fields on the identified
documents.
The overall document recognition reported an accuracy of 92.6%. It is worth mentioning that
document recognition via Method 1 performed far better than Method 2, as shown in Table1
In general, the system found some difficulties processing blurry images such as scans of
photocopied documents. Field extraction, with an average accuracy of 81.1%, presented
different performances based on the specific fields to be detected as shown in Table 2. Some
fields such as name, surname which are always in the same position within the document
template reported an accuracy around 90% while others, such as province, with a variable
position had a lower accuracy. Moreover, the proposed system appears reliable for certain
document layouts such as NHS cards where fields are always printed in the same position. On
the contrary, for paper identity cards, in which fields can be printed in slightly different
positions, field extraction did not achieve such a high accuracy.
Table 1: Document recognition accuracy reported for a subset of relevant documents
Relevant Document Method Accuracy
NHS Card 1 95.4%
Identity Card (card version) 1 93.7.%
Identity Card (paper version) 1 92.1%
Driving Licence 1 91.6%
Driving Licence (paper version) 2 89.2%
Passport 2 88.4%
Residence Permit 2 78.1%
Table 2: Field extraction accuracy reported for a subset of relevant fields
Relevant Field Accuracy
Citizenship 94.6%
Surname 89.9%
Document Number 89.4%
Name 88.3%
Release Place 82.7%
Date of Birth 81.4%
Release Date 71.5%
Province 70.3%
Address 61.7%
CONCLUSIONS
This paper proposes a support system for automatically processing scanned documents,
identifying relevant information and validating it against manually extracted ones. We
demonstrated that the proposed system handles multiple challenges including (1) working with
6a variety of document types, (2) each document type may have different layouts, (3) presence
of multiple documents in an image (4) handling different acquisition methods (e.g., smartphone
pictures, scanned photocopy, etc.).
The presented pipeline delivers a quasi-real-time output benefitting from Cloud high
flexibility and scalability. Experimental results on real world documents show promising
results in both document recognition and field extraction with an average accuracy of 92.6%
and 81.1% respectively.
Future improvements can be achieved by integrating in the pipeline deep learning models
for field recognition and improving recognition for blurry and low-quality images.
REFERENCES
1. Islam, N., Islam, Z., & Noor, N. (2017). A survey on optical character recognition
system. arXiv preprint arXiv:1710.05703.
2. Yesenia, O., & Veronica, S. F. (2021, February). Automatic Classification of Research
Papers Using Machine Learning Approaches and Natural Language Processing. In
International Conference on Information Technology & Systems (pp. 80-87). Springer,
Cham.
3. Tran, D. N., Tran, T. A., Oh, A., Kim, S. H., & Na, I. S. (2015). Table detection from
document image using vertical arrangement of text blocks. International Journal of
Contents, 11(4), 77-85.
4. Saha, R., Mondal, A., & Jawahar, C. V. (2019, September). Graphical object detection
in document images. In 2019 International Conference on Document Analysis and
Recognition (ICDAR) (pp. 51-58). IEEE.
5. Xu, Y., Xu, Y., Lv, T., Cui, L., Wei, F., Wang, G., ... & Zhou, L. (2020). LayoutLMv2:
Multi-modal Pre-training for Visually-Rich Document Understanding. arXiv preprint
arXiv:2012.14740.
6. Tang, F., & Tao, H. (2007, February). Fast multi-scale template matching using binary
features. In 2007 IEEE Workshop on Applications of Computer Vision (WACV'07)
(pp. 36-36). IEEE.
7. Yabuki, N., Nishimura, N., & Fukuda, T. (2018, June). Automatic object detection from
digital images by deep learning with transfer learning. In Workshop of the European
Group for Intelligent Computing in Engineering (pp. 3-15). Springer, Cham.
8. Chatelain, C., Heutte, L., & Paquet, T. (2006, February). Segmentation-driven
recognition applied to numerical field extraction from handwritten incoming mail
documents. In International Workshop on Document Analysis Systems (pp. 564-575).
Springer, Berlin, Heidelberg.
9. Rusinol, M., Benkhelfallah, T., & Poulain d’Andecy, V. (2013, August). Field
extraction from administrative documents by incremental structural templates. In 2013
12th International Conference on Document Analysis and Recognition (pp. 1100-
1104). IEEE.
10. https://cloud.google.com/vision/automl/docs
11. Guizar-Sicairos, Manuel, Samuel T. Thurman, and James R. Fienup. "Efficient
subpixel image registration algorithms." Optics letters 33.2 (2008): 156-158.
12. Lowe, David G. "Distinctive image features from scale-invariant keypoints."
International journal of computer vision 60.2 (2004): 91-110.
13. Dong, C., Loy, C. C., & Tang, X. (2016, October). Accelerating the super-resolution
convolutional neural network. In European conference on computer vision (pp. 391-
407). Springer, Cham.
714. https://cloud.google.com/vision/docs/ocr
15. Yu, Wenwen, et al. "Pick: processing key information extraction from documents using
improved graph learning-convolutional networks." arXiv preprint arXiv:2004.07464
(2020).
8You can also read

















































