High Performance Computing systems - The monte cimone - Prof. Andrea Bartolini
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
High Performance Computing systems – The monte cimone Prof. Andrea Bartolini a.bartolini@unibo.it
Outline HPC & Supercomputing Estimating Supercomputers performance The Monte Cimone – performance Experimental Results

Clusters / Warehouse-scale Computers Clusters: – Composti da una collezione di Desktop Computers and/or Servers detti nodi – I nodi di calcolo sono interconnessi da reti locali «local area networks» – Si comportano all’unisono come un solo computer. – Ciascun nodo esegue il suo sistema operativo e comunicano usando protocolli di comunicazione di rete (es: ethernet, infiniband) Con il termine Warehouse scale computers (ma anche datacenter) sono insiemi di clusters che possono arrivare ad includere ~10/100.000 nodi

Clusters / Warehouse-scale Computers #3 I fattori chiave per i WSC sono legati alla grande dimensione: – Rapporto prezzo/prestazioni – Consumo di potenza, quindi efficienza energetica ma anche costo del raffreddamento/rimozione del calore («Cooling») – Disponibilità («Avviability») Costo: – Ammortamento annuale del costo di acquisto dei clusters («IT») riportato sul tempo di vita del cluster – Ammortamento annuale del costo di costruzione del datacenter e del sistema di raffreddamento («Facility»). – Consumo di potenza dei clusters (PIT) + Consumo di potenza per il raffreddamento (PCOOLING)

Clusters / Warehouse-scale Computers #4 Esempio: – Il costo di ammortamento annuale per il solo IT per un WSC ~40M$/anno siccome sono sostituiti ogni 3-5 anni. – Nell’acquistare questi sistemi bisogna essere attenti – un +10% nel rapporto costo/performance comporta una spesa aggiuntiva di 4M$/anno (10% 40M$) – Una compagnia come Amazon potrebbe avere circa 100 WSC – Efficienza del raffreddamento valutata in termini di Power Usage Efficiency (PUE) ≜ + – PUE sempre maggiore, uguale a 1. Valori tipici sono: • Air cooled, open racks 1.40 • Air cooled, closed racks 1.35 • Direct liquid cooled, low temperatures 1.33 • Direct liquid cooled, high temperatures 1.03

Clusters / Warehouse-scale Computers #4 The Avaiability problem: Amazon.com nel 2016 – ha avuto un volume di vendite pari a 136B$ – Ci sono 8760 ore/anno (364*24h) – Guadagno medio per ora 15.5M$ (136B/8760) – Nel periodo natalizio la potenziale perdita di guadagno per ora è molto più alto (>>16M$/h).

Clusters / Warehouse-scale Computers #5 Scalabilita: Bisogna ricordare che per i WSC la scalabilità è gestita a livello di rete di comunicazione locale e non in termini di risorse di calcolo integrate come succede per i servers. I Supercomputers sono simili ai WSC in termini di costo (~100M$) ma sono diversi in termine di computazione richiesta e modo d’uso: – I supercomputers mettono enfasi nel calcolo a virgola mobile e sono caratterizzati dall’esecuzioni di applicazioni large, pesanti in termine di comunicazione e che possono durare per settimane. – I WSC/Datacenter mettono enfasi sull’interattività delle applicazioni basate su uno storage dei dati a larga scala, con vincoli di affidabilità e necessità di alta banda di comunicazione verso internet.

What is a supercomputer? • High-performance computing (HPC) is the use of parallel processing for running advanced application programs efficiently, reliably and quickly • Typical users: scientific researchers, engineers, data analysts 8
Supercomputer an example… https://www.exscalate.eu/en/assets/images/Ligen_plus_antarex.mp4 COVID-19 drug design 9

Top500 – Green500
Top500 – Green500 Rpeak: Theoretical Maximum Performance # DP Flops/cycle * # DP FPUs * Nominal Core’s Frequency * # Cores [Tflop/s] Rmax: Measured DP Flating point operation per second durign an HPL (DGEMM) run [Tflop/s] Cores: # of cores Power: Power consumpiton during the HPL run [KW]
Top500 – Green500
Peak performance – computation https://www.intel.com/content/www/us/en/products/sku/212282/intel-xeon-platinum-8358-processor-48m-cache-2-60-ghz/specifications.html https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-nvidia-us-2188504-web.pdf
Computing FLOPs • How to compute the Flop/s
Monte Cimone: Paving the Road for the First Generation of RISC-V High-Performance Computers Andrea Bartolini, Federico Ficarelli, Emanuele Parisi, Francesco Beneventi, Francesco Barchi, Daniele Gregori, Fabrizio Magugliani, Marco Cicala, Cosimo Gianfreda, Daniele Cesarini, Andrea Acquaviva, Luca Benini University of Bologna DEI, Italy CINECA SCAI, Italy E4 Computer Engeneering s.p.a., Italy
RISC-V and HPC New ISA & HPC: – 1° MONT-BLANC eu project (2012) – 2012 – 2020 many projects – 2020 Fukaku - 1° Top500 w. 415PFLOPs https://www.riken.jp/
RISC-V and HPC New ISA & HPC: – 1° MONT-BLANC eu project (2012) – 2012 – 2020 many projects – 2020 Fukaku - 1° Top500 w. 415PFLOPs RISC-V ISA relatively new (10 years) – Few RV64G commercial available – Several announced w. Vector-extensions: • SiFIVE, Ventana, Esperanto, Semidynamics, … – Rich OpenHW ecosystem SW ecosystem provided by the RISC-V foundation – rich but initially focused on AI/embedded
riscv.org Why RISC-V? Courtesy of Andrea Marongiu
RISC-V vs CISC x86 = Complex Instruction Set Computer (ClSC) RISC-V = Reduced Instruction Set Computer (RlSC) • > 1000 instructions, 1 to 15 bytes each • ≈ 200 instructions, 32 bits each, 4 formats • operands in dedicated registers, general purpose • all operands in registers registers, memory, on stack, … • almost all are 32 bits each • can be 1, 2, 4, 8 bytes, signed or unsigned • ≈ 1 addressing mode: • 10s of addressing modes Mem[reg + imm] e.g. Mem[segment + reg + reg*scale + offset] CISC RISC Emphasis on hardware Emphasis on software Includes multi-clock complex instructions Single-clock, reduced instruction only Memory-to-memory: "LOAD" and "STORE" Register to register: "LOAD" and "STORE" incorporated in instructions are independent instructions Small code sizes, high cycles per instruction Low cycles per istruction, large code sizes Transistors used for storing complex instructions Spends more transistors on memory registers 19
Work continues on new RISC-V extensions • Example of the process: • Vector Operation – V extension Q Quad-precision Floating-Point • Frozen, not yet ratified L Decimal Floating Point B Bit Manipulation T Transactional Memory P Packed SIMD Dynamically Translated J Languages GitHub - riscv/riscv-v-spec: Working draft of the proposed RISC-V V Vector Operations V vector extension https://wiki.riscv.org/display/HOME/Recently+Ratified+Extensi N User-Level Interrupts ons Working with RISC-V
More than 1,500 RISC-V Members across 70 Countries 94 Chip 4 Systems SoC, IP, FPGA ODM, OEM 4 I/O 13 Industry Memory, network, storage Cloud, mobile, HPC, ML, automotive 12 Services 81 Research Fab, design services Universities, Labs, other alliances 40 Software 1,000+ Individuals Dev tools, firmware, OS RISC-V engineers and advocates March 2021 In 2020, RISC-V membership grew 133% 21
RISC-V and HPC New ISA & HPC: – 1° MONT-BLANC eu project (2012) – 2012 – 2020 many projects – 2020 Fukaku - 1° Top500 w. 415PFLOPs RISC-V ISA relatively new (10 years) – Few RV64G commercial available – Several announced w. Vector-extensions: • SiFIVE, Ventana, Esperanto, Semidynamics, … – Rich OpenHW ecosystem SW ecosystem provided by the RISC-V foundation – rich but initially focused on AI/embedded How mature is the RISC-V ecosystem? Is the RISC-V ecosystem mature enough to Question: build HPC production clusters?
Monte Cimone Hardware SiFive HiFive Unmatched board E4 RV007 blade prototypes 4x E4 RV007 1U Custom Server Blades: SiFive U740 SoC w. 7 separated power rails: • 2x SiFive U740 SoC with 4x U74 RV64GCB cores - Core complex, IOs, PLLs, DDR subsystem and PCIe one. • 16GB of DDR4 - Board implements distinct shunt resistors • 1TB node-local NVME storage • PCIe expansion card w/InfiniBand HCAs • Ethernet + IB parallel networks
Monte Cimone Software Stack: Production-level HPC software stack • SLURM job scheduler, NFS filesystem, Nagios The cluster is connected • User-space deployed via Spack package manager to a login node and • Upstream and custom toolchains master node running • Scientific libraries the job scheduler, • Industry-standard HPC benchmarks and network file system and applications (e.g.: quantumESPRESSO suite) system management • The ExaMon datacenter automation and software. monitoring framework On going work w. NVIDIA/Mellanox Monte Cimone: User-facing software stack • All software stack installed w. SPACK with the already present linux-sifive-u74mc • Ubuntu 20.04 Linux O.S. installed with riscv64 image
https://open-src-soc.org/2022-05/media/slides/RISC-V-International-Day- 2022-05-05-11h05-Calista-Redmond.pdf https://www.nextplatform. com/2022/06/09/strong- showing-for-first- experimental-risc-v- supercomputer/ https://arxiv.org/abs/ 2205.03725
HPL Benchmark HPL peak theoretical value of 1.0 GFLOP/s/core, (from the micro-architecture specification) • 4.0 GFLOP/s peak value for a single chip, the upstream HPL benchmark • Sustained value of 1.86 ± 0.04 GFLOP/s on single node (on a N=40704 and NB=192 and a total runtime of 24105 ± 587s ) HPL multinode strong scaling w. 1Gb/s network : • 39.5% of the entire machine’s theoretical peak • 85% of the extrapolated attainable peak in case of perfect linear scaling from the single-node case
Stream Benchmark 8 SiFive U740 RISC-V SoC peak DDR bandwidth 7760 MB/s. Possible causes to be investigate: 7 Stream performance Bandwidth [GB/s] 6 1. L2 prefetcher capable of tracking up to eight streams, then 5 why it is not hiding the DDR latency? 2. STREAM data size currently limited by the RISC-V code model. 4 1. The medany code model requires that every linked 3 symbol resides within a ± 2GiB range from the pc register. 2. Upstream STREAM benchmark uses statically-sized data 2 arrays in a single translation unit preventing the linker to 1 perform relaxed relocations, their overall size cannot exceed 2 GiB. 0 3. The upstream GCC 10.3.0 toolchain isn’t capable of emitting copy scale add triad the Zba and Zbb RISC-V bit manipulation standard extensions STREAM.DDR (1.9 GiB) STREAM.L2 (1.1MiB) nor the underlying GNU as assembler (shipped with GNU Binutils 2.36.1). Experimentally supported on GCC 12 and Binutils 2.37.x .
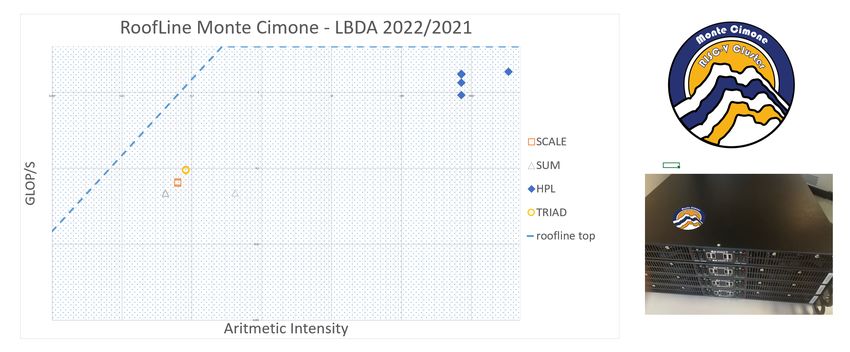
Monte Cimone Roofline * Done by students of the Lab of Big Data Architecture Class
Performance Characterization Monte Cimone vs ARMv8a, ppc64le: Monte Cimone vs ARMv8a, ppc64le 70 65,8 63,2 59,7 60 HPL and Stream benchmarks on two SoA computing nodes: 50 46,5 48,2 • Marconi100 (ppc64le, IBM Efficinecy [%] 40 Power9) • Armida (ARMv8a, Marvell 30 ThunderX2) • Same benchmarking boundary 20 15,5 conditions • Vanilla unoptimized 10 libraries 0 • software stack deployed Monte Cimone ( RV64G, SiFIVE U740) Armida (ARMv8a, Marvell ThunderX2) Marconi100 (ppc64le, IBM Power9) via SPACK package HPL Efficiency [%FPU utilization] Stream Efficiency [% Bandwidth Utilization] manager
Conclusions: With Monte Cimone, the first physical prototype and test-bed of a complete RISC-V (RV64) compute cluster, we demonstrated that it is possible to run real-life HPC applications on a RISC-V system today. Mission: Making high-performance RISC-V processors and accelerators ready for future RISC-V- based HPC systems. Monte Cimone now open to external user to increase the adoption. To get access write to:
TESI disponibili • [CIMONE] Accelerating Monte Cimone w. NVIDIA GPU • [CIMONE] Accelerating Monte Cimone w. FPGAs Clusters • [CIMONE] High-frequency energy-monitoring and security hazard detection • [CIMONE] Porting and benchmarking of HPC codes. • [EPI] Trace driven performance/power model • [CINECA] COUNTDOWN benchmarking • ….. more…write me
Curiosity - Why «Monte Cimone» ? Tallest moutain in the northern Apennines, w. 2.165 m On clear days the crest is visible from the major center italian cities: Bologna, Mantova, Modena, Reggio Emilia, Firenze, Lucca … Considering the spatial resolution of the human eye, the top of Mount Cimone is the geographical point from which the most Italian surface can be seen. In the Monte Cimone’s ski resort, the famous Italian (and Bolognese) worldwide ski champion Alberto Tomba started
Aknowledgment The european-project-initiative has received funding from the European High Performance Computing Joint Undertaking (JU) under Framework Partnership Agreement No 800928 and Specific Grant Agreement No 101036168 (EPI SGA2). The JU receives support from the European Union’s Horizon 2020 research and innovation programme and from Croatia, France, Germany, Greece, Italy, Netherlands, Portugal, Spain, Sweden, and Switzerland. The EUPEX project has received funding from the European High-Performance Computing Joint Undertaking (JU) under grant agreement No.101034126. The JU receives support from the European Union’s Horizon 2020 research and innovation programme and Spain, Italy, Switzerland, Germany, France, Greece, Sweden, Croatia and Turkey. This REGALE-project has received funding from the European High-Performance Computing Joint Undertaking (JU) under grant agreement No 956560. The JU receives support from the European Union’s Horizon 2020 research and innovation programme and Greece, Germany, France, Spain, Austria, Italy. The Spoke Future HPC of the Italian National Center of HPC, Big Data e Quantum Computing is funded by the National Recovery and Resilience Plan (NRRP). 03/05/2022 35
You can also read

















































