DecisionHoldem: Safe Depth-Limited Solving With Diverse Opponents for Imperfect-Information Games
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
DecisionHoldem: Safe Depth-Limited Solving With Diverse Opponents for
Imperfect-Information Games
Qibin Zhou1 , Dongdong Bai1∗ , Junge Zhang1† , Fuqing Duan2 , Kaiqi Huang1
1
Institute of Automation, Chinese Academy of Sciences, Beijing, China
2
Beijing Normal University, Beijing, China
zqbagent@gmail.com, baidongdong@nudt.edu.cn, jgzhang@nlpr.ia.ac.cn, fqduan@bnu.edu.can,
kqhuang@nlpr.ia.ac.cn
Abstract Brown et al., 2018; Brown and Sandholm, 2019c], has made
arXiv:2201.11580v1 [cs.AI] 27 Jan 2022
considerable progress in recent years. Texas hold’em is one
An imperfect-information game is a type of game of the most popular poker game in the world. It is an ex-
with asymmetric information. It is more com- cellent benchmark for studying the game theory and technol-
mon in life than perfect-information game. Ar- ogy in imperfect-information games because of the follow-
tificial intelligence (AI) in imperfect-information ing three factors. First, Texas hold’em is a typical imperfect-
games, such like poker, has made considerable information game. Before the game, two private hands invis-
progress and success in recent years. The great ible to the opponent are distributed to each player. Players
success of superhuman poker AI, such as Libra- should predict the opponents’ private hands during decision-
tus and Deepstack, attracts researchers to pay at- making based on the opponents’ historical actions, which
tention to poker research. However, the lack of makes Texas hold’em obtain the characteristics of deception
open-source code limits the development of Texas and anti-deception. Second, the complexity of the Texas
hold’em AI to some extent. This article introduces hold’em game is enormous. The decision-making space for
DecisionHoldem, a high-level AI for heads-up no- heads-up no-limit Texas hold’em (HUNL) exceeds 10160 [Jo-
limit Texas hold’em with safe depth-limited sub- hanson, 2013]. In addition, Texas hold’em has simple rules
game solving by considering possible ranges of op- and moderate difficulty, which considerably facilitates the
ponent’s private hands to reduce the exploitabil- verification of algorithms by researchers.
ity of the strategy. Experimental results show
that DecisionHoldem defeats the strongest openly After decades of research, the poker AI DeepStack de-
available agent in heads-up no-limit Texas hold’em veloped by Matej Moravčı́k et al. [Moravčı́k et al., 2017]
poker, namely Slumbot, and a high-level reproduc- and Libratus developed by Noam Brown and Tuomas Sand-
tion of Deepstack, viz, Openstack, by more than holm [Brown and Sandholm, 2018] successively defeat hu-
730 mbb/h (one-thousandth big blind per round) man professional players in 2017. This event affirms
and 700 mbb/h. Moreover, we release the source the breakthrough for HUNL. Subsequently, the poker AI
codes and tools of DecisionHoldem to promote AI Pluribus, also constructed by Noam Brown and Tuomas
development in imperfect-information games. Sandholm [Brown and Sandholm, 2019c], defeats the human
professional players in six-man no-limit Texas hold’em. Al-
though Science magazine has published the poker AI men-
1 Introduction tioned above [Brown and Sandholm, 2018; Moravčı́k et al.,
The success of AlphaGo [Silver et al., 2016] has led 2017], the relevant code and main technical details have not
to increasing attention to the study of game decision- been made public.
making [Brown and Sandholm, 2018; Moravčı́k et al., 2017;
Brown et al., 2018; Brown and Sandholm, 2019c]. Unlike In addtion, considerable poker AI progress [Brown et
perfect-information games, such as Go, real-world problems al., 2017] [Hartley, 2017] [Brown and Sandholm, 2019a]
are mainly imperfect-information games. The hidden knowl- [Schmid et al., 2019] [Farina et al., 2019c] [Farina et al.,
edge in poker games (i.e., private cards) corresponds to the 2019a] [Farina et al., 2019b] [Li et al., 2020a] is only tested
real world’s imperfect-information. Research on poker arti- in games with small decision space, such as Leduc hold’em
ficial intelligence (AI) can provide means to deal with prob- and Kuhn Poker. These algorithms may not work well when
lems in life, such as financial market tracking and stock fore- applied to large-scale games, such as Texas hold’em.
casting.
Research in imperfect-information games, particularly In this paper, we propose a safe depth-limited subgame
poker AI [Brown and Sandholm, 2018; Moravčı́k et al., 2017; solving algorithm with diverse opponents. To evaluate the al-
gorithm’s performance, we achieve a high-performance and
∗
Dongdong Bai and Qibin Zhou contribute equally. high-efficiency poker AI based on it, namely DecisionHol-
†
Corresponding Author dem. Experiments show that DecisionHoldem defeats the
Round Number of Abstract Hands 1st ∼ 2nd Actions 3rd ∼ 5th Actions Remaining Actions
Pre-Flop 169 F, C, 0.5P, P, 2P, 4P, A F, C, P, 2P, 4P, A F, C, A
Flop 50,000 F, C, 0.5P, P, 2P, 4P, A F, C, P, 2P, 4P, A F, C, A
Turn 5,000 F, C, 0.5P, P, 2P, 4P, A F, C, P, 2P, 4P, A F, C, A
River 1,000 F, C, 0.5P, P, 2P, 4P, A F, C, P, 2P, 4P, A F, C, A
Table 1: The number of abstract hands and actions available for each round (pre-flop, flop, turn and, river) of DecisionHoldem on HUNL. F,
C, 0.5P, P, 2P, 4P, and A represent Fold, Call, 0.5 Pot size, 1.0 Pot size, 2.0 Pot size, 4.0 pot size, and all-in, respectively.
strongest public poker AI, such as Slumbot1 (champion of iteration on the abstracted game tree to calculate blueprint
2018 Annual Computer Poker Competition [ACPC]) and strategy on a workstation with 48 core CPUs for about 3 ∼
OpenStack (a reproduction of DeepStack built-in OpenHol- 4 days with approximately 200 million iterations. The total
dem [Li et al., 2020b]2 , by a big margin. Meanwhile, we computing power cost is about 4,000 core hours.
release DecisionHoldem’s source code, and tools for play- In the real-time search part, we propose a safer depth-
ing against the Slumbot and OpenHoldem [Li et al., 2020b]. limited subgame solving algorithm than modicum’s [Brown
In addition, we also provide a platform to play DecisionHol- et al., 2018] on subgame solving by considering diverse op-
dem with humans (as in Figure 13 ). Our code is available at ponents for off-tree nodes. Since the opponent’s private hand
https://github.com/AI-Decision/DecisionHoldem. range reflects the opponent’s play style and strategy, we pro-
pose a safe depth-limited subgame solving method by explic-
itly modeling diverse opponents with different ranges. This
algorithm can refine the degree of subgame strategy with-
out worsening the exploitability compared with the blueprint
strategy. That is to say, safe depth-limited solving with di-
verse opponents can significantly enhance the AI decision-
making level and ability with changeable challenges. Our
subsequent articles will introduce the details of the algorithm.
3 Experiments and Results
DecisionHoldem plays against Slumbot and OpenStack [Li
et al., 2020b] to test its capability. Slumbot is the champion
of the 2018 ACPC and the strongest openly available agent
in HUNL. OpenStack is a high-level poker AI integrated in
OpenHoldem, a replica AI version of DeepStack. The exper-
Figure 1: Demonstration of AI and human confrontation. imental configurations are as follows.
For the first three rounds of the game, DecisionHoldem
prioritizes using blueprint strategies when making decisions.
2 Methods For off-tree nodes, DecisionHoldem starts a real-time search.
In this study, we use the counterfactual regret minimization For the first two rounds of poker (preflop, flop), the real-time
(CFR) algorithm [Zinkevich et al., 2007], the primary way of search iterations are 6,000 times; for the third round (turn),
the Texas hold’em AI, and combine it with safe depth-limited the real-time search iterations are 10,000 times.
subgame solving to achieve the high-performance and high- While for the last round (river), DecisionHoldem employs
efficiency poker AI — DecisionHoldem. DecisionHoldem is the safe depth-limited subgame solving algorithm for real-
mainly composed of two parts, namely the blueprint strategy time search with 10,000 iterations directly.
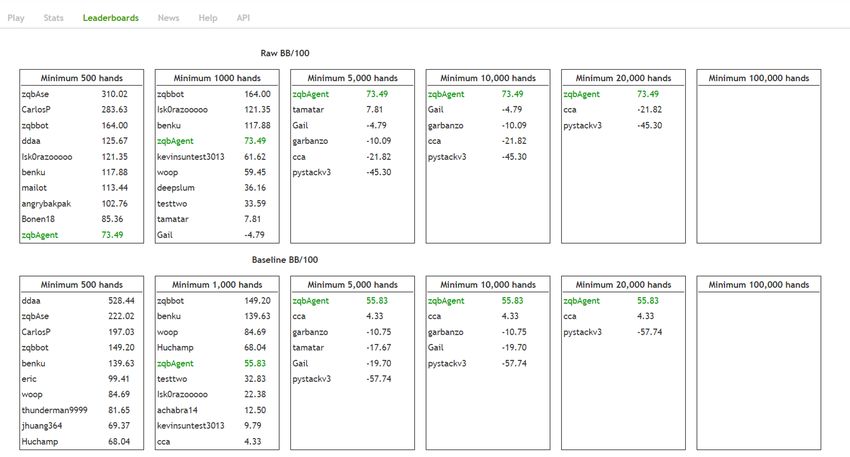
and the real-time search part. In approximately 20,000 games against Slumbot, Deci-
In the blueprint strategy part, we partially follow the idea sionHoldem’s average profit is more remarkable than 730
of Libratus but adjusted the parameters of the abstract num- mbb/h (one-thousandth big blind per round). It ranked first in
ber of actions and hands. The abstract parameters of Deci- statistics on November 26, 2021 (DecisionHoldem’s name on
sionHoldem’s hands and actions are shown in Table 1. Deci- the leaderboard is zqbAgent4 ), as the Figure 2 and 3. With ap-
sionHoldem first employs the hand abstraction technique and proximately 2,000 games against OpenStack, DecisionHol-
action abstraction to obtain an abstracted game tree. Then, we dem’s average profit is greater than 700 mbb/h, and the com-
use the linear CFR algorithm [Brown and Sandholm, 2019b] petition records are available in the Github repository of De-
1 cisionHoldem.
www.slumbot.com
2
holdem.ia.ac.cn
3 4
https://github.com/ishikota/PyPokerGUI https://github.com/ericgjackson/slumbot2017/issues/11Figure 2: DecisionHoldem’s ranking on the Slumbot leaderboard on November 26, 2021.
[Brown and Sandholm, 2019a] Noam Brown and T. Sand-
holm. Solving imperfect-information games via dis-
counted regret minimization. In AAAI, 2019.
[Brown and Sandholm, 2019b] Noam Brown and Tuomas
Sandholm. Solving imperfect-information games via dis-
counted regret minimization. In Proceedings of the AAAI
Conference on Artificial Intelligence, volume 33, pages
Figure 3: Statistics for DecisionHoldem vs. Slumbot. 1829–1836, 2019.
[Brown and Sandholm, 2019c] Noam Brown and Tuomas
Sandholm. Superhuman ai for multiplayer poker. Science,
4 Conclusions 365(6456):885–890, 2019.
This paper introduces the safe depth-limited subgame solv- [Brown et al., 2017] Noam Brown, Christian Kroer, and
ing algorithm with the exploitability guarantee. It achieves T. Sandholm. Dynamic thresholding and pruning for re-
the outstanding AI DecisionHoldem for HUNL with the pro- gret minimization. In AAAI, 2017.
posed subgame solving algorithm for real-time search and [Brown et al., 2018] Noam Brown, Tuomas Sandholm, and
suitable abstraction methods for blueprint strategy. Decision- Brandon Amos. Depth-limited solving for imperfect-
Holdem defeats the current typical public high-level poker information games. arXiv preprint arXiv:1805.08195,
AI, namely Slumbot and OpenStack. To our best knowl- 2018.
edge, DecisionHoldem is the very first open-source high-level
AI for HUNL. Meanwhile, we also provide toolkits against [Farina et al., 2019a] Gabriele Farina, Christian Kroer,
Slumbot and OpenStack, and a platform to play DecisionHol- Noam Brown, and T. Sandholm. Stable-predictive
dem with humans to assist researchers in conducting further optimistic counterfactual regret minimization. ArXiv,
research. abs/1902.04982, 2019.
[Farina et al., 2019b] Gabriele Farina, Christian Kroer, and
T. Sandholm. Optimistic regret minimization for
References extensive-form games via dilated distance-generating
[Brown and Sandholm, 2018] Noam Brown and Tuomas functions. In NeurIPS, 2019.
Sandholm. Superhuman ai for heads-up no-limit poker: [Farina et al., 2019c] Gabriele Farina, Christian Kroer, and
Libratus beats top professionals. Science, 359(6374):418– T. Sandholm. Regret circuits: Composability of regret
424, 2018. minimizers. In ICML, 2019.[Hartley, 2017] M. Hartley. Multi-agent counterfactual re- gret minimization for partial-information collaborative games. 2017. [Johanson, 2013] Michael Johanson. Measuring the size of large no-limit poker games. arXiv preprint arXiv:1302.7008, 2013. [Li et al., 2020a] Hui Li, Kailiang Hu, Zhibang Ge, Tao Jiang, Yuan Qi, and L. Song. Double neural counterfac- tual regret minimization. ArXiv, abs/1812.10607, 2020. [Li et al., 2020b] Kai Li, Hang Xu, Meng Zhang, Enmin Zhao, Zhe Wu, Junliang Xing, and Kaiqi Huang. Openholdem: An open toolkit for large-scale imperfect-information game research. arXiv preprint arXiv:2012.06168, 2020. [Moravčı́k et al., 2017] Matej Moravčı́k, Martin Schmid, Neil Burch, Viliam Lisỳ, Dustin Morrill, Nolan Bard, Trevor Davis, Kevin Waugh, Michael Johanson, and Michael Bowling. Deepstack: Expert-level artifi- cial intelligence in heads-up no-limit poker. Science, 356(6337):508–513, 2017. [Schmid et al., 2019] Martin Schmid, Neil Burch, Marc Lanctot, Matej Moravcik, Rudolf Kadlec, and Michael H. Bowling. Variance reduction in monte carlo counterfactual regret minimization (vr-mccfr) for extensive form games using baselines. ArXiv, abs/1809.03057, 2019. [Silver et al., 2016] David Silver, Aja Huang, Chris J Maddi- son, Arthur Guez, Laurent Sifre, George Van Den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Pan- neershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature, 529(7587):484–489, 2016. [Zinkevich et al., 2007] Martin Zinkevich, Michael Johan- son, Michael Bowling, and Carmelo Piccione. Regret min- imization in games with incomplete information. In Ad- vances in Neural Information Processing Systems 20, vol- ume 20, pages 1729–1736, 2007.
You can also read

















































