COMP7705 MSc (CompSc) Project MSP 21050: Virtual Concert in Metaverse Interim Report - UID
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

COMP7705 MSc (CompSc) Project
MSP 21050: Virtual Concert in Metaverse
Interim Report
Supervisor: Prof. Francis Lau
Group Member UID
Zhang Yixing 3035449463
Liang Jingtao 3035911935
Liu Dingrui 3035905340
Wang Yutan 3035905065
Li Wei 3035947180
Abstract This interim report focuses on developing a solution for hosting virtual concerts in the metaverse. The project is based on a system of three components: motion capturing on the performer side, data streaming on the intermediate network layer, and rendering and interaction on the audience side. The facial capture module has already been implemented using iPhone 12 Pro, Rokoko Remote, and Rokoko Studio, and the body capture module will be available once the Rokoko Suit arrives. The scalable streaming server program is under development, and the primitive audience client currently uses Blender, allowing users to view the rendered performances. Ultimately, audiences should be able to use the project to view concerts in a remote metaverse and interact with the performers in an easy-to-use client.

Table of Contents
1. Introduction ............................................................................................................... 1
1.1. Backgrounds.................................................................................................... 1
1.2. Objectives........................................................................................................ 2
2. Methodology.............................................................................................................. 3
2.1. System Framework ......................................................................................... 3
2.2. Motion Capture ............................................................................................... 5
2.2.1. Facial Capture ....................................................................................... 6
2.2.2. Body Capture ........................................................................................ 8
2.3. Lip Movement Generation Based on Speech .................................................. 9
2.4. Model & Rendering ...................................................................................... 10
3. Current Progress ...................................................................................................... 12
3.1. Motion Capture ............................................................................................. 12
3.1.1. Facial Capture ..................................................................................... 12
3.1.2. Body Capture ...................................................................................... 15
3.2. Lip Movement Generation Based on Speech ................................................ 15
4. Future Plan............................................................................................................... 19
References ...................................................................................................................... 20
1. Introduction
1.1. Backgrounds
The metaverse is a hypothetical iteration of the internet as a single, universal and
immersive virtual world that is facilitated by virtual reality (VR) and augmented reality
(AR) headsets. Nowadays, the metaverse development has made a significant and new
revolution to the internet world where people can interact with each other and do lots of
real-life activities virtually. The metaverse expands far and wide because it enhances
people’s chances to interact with others in different locations simultaneously. For instance,
schools are creating virtual classrooms for online learning and better engagement, and
workplaces are making offices in the metaverse for employees to feel like they are in the
office working with co-workers while still working from the conform of their homes.
Virtual concert in the metaverse, an application of metaverse, transforms the real-life
concert into the 3D virtual one where the audiences do not have to present in person. As
the pandemic canceled and delayed real-life concerts, virtual concerts in metaverse can
provide both the star and the fans an alternative method to perform as virtual avatars in
3D spaces and allow fans at home to be immersed in the concert. Furthermore, it all
happens in a virtual world with real-time gaming graphics. This form of concerts is not a
concept only but has been put into practice. The profit from virtual merchandise, brand
sponsorships, and other forms is also considerable. For example, Justin Bieber and Ariana
Grande have already performed full concerts in the metaverse as avatars where people
can directly contribute to what happened during the show. Moreover, merchandise,
including digital items such as virtual clothing for avatars, can be sold in massive amounts
1
because of the better playing form.
1.2. Objectives
The primary aim and targeted output are to realize the real-time collection and
transmission of motion capture data, including the body and the facial parts, for the actor
or the avatar’s performances. In other words, the final output can capture the real-time
actor’s movements by physical equipment like Rokoko and then display the same ones
on the virtual model.
Beyond that, the product should be able to use the mouth motion data generated based on
speech recognition or the so-called automated lip-sync by learning models to assist
motion capture to realize the remote viewing of the audience in the virtual reality of the
concert metaverse. The automated lip-sync can output the real-time 3D lip-sync in the
metaverse when the actor speaks in reality. In addition, a classical and possible situation
of this essential kind of output is that when the virtual avatar’s mouth is blocked by the
microphone or something else, the program can replace the face capture to complete the
realization of the mouth animation in the real-time.
Furthermore, if possible, a much more advanced output is to enable the two-way
interaction between the audience and actors in our project’s virtual reality. There are
many different possible two-way interactions. In our final version of the virtual metaverse
concert, the audience may applaud, cheer, and even shake the cheering sticks while the
actors are performing.
2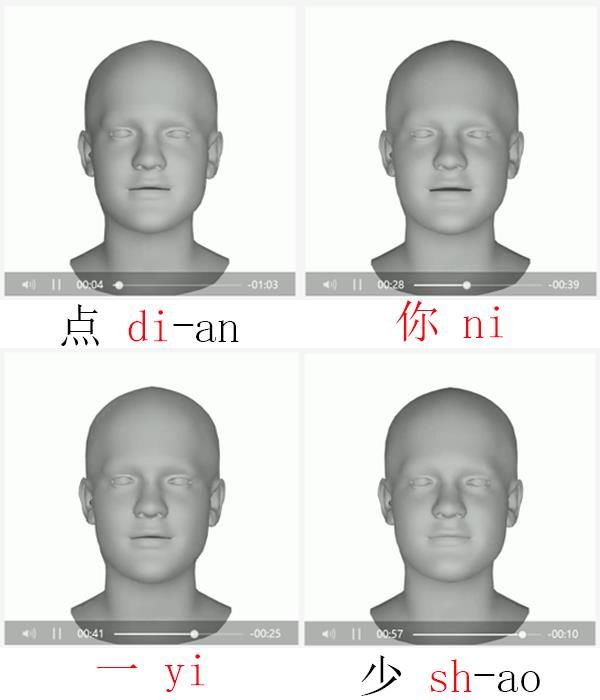
2. Methodology
2.1. System Framework
Fig 1 shows the overview structure of this project’s final product. As illustrated in the
graph, the overall architecture of the whole virtual concert system is divided into three
parts: performer side, network intermediate, and audience side.
Fig 1. Overall system framework
The performer side is responsible for processing the performer’s operations. To begin
with, the actor should wear the motion capture equipment, including a Rokoko Suit and
3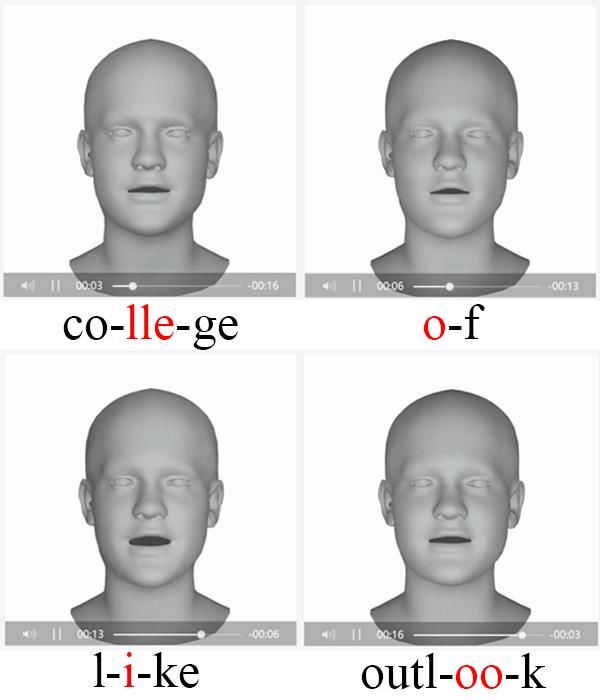
an iPhone with ARKit. Moreover, they should be connected to the performer’s local
machine to send the captured raw motion data for processing. The local machine should
run the Rokoko Studio to convert the raw data into solved motion data in a standard
format (to be explained in the next section) readable for audiences’ clients. Finally, after
processing, it will transmit the solved data and actor’s voice to the streaming server in
the network intermediate layer and receive audiences’ feedback for interaction.
The network intermediate is designed to stream data between performers and audiences
by the standalone streaming servers that accept registrations from clients. Separating
streaming servers from performer’s machines can save resources for IK solving and
rendering on the local machines, which will speed up both the motion data processing
and the data transmission. It is also easier to scale the streaming servers when the
number of the audience reaches the limits compared to running the streaming server on
the performer’s local machines. The servers’ tasks are to transmit solved motion data
and audio from the performers to the registered audiences and the audiences’ feedback
interactions on the reverse.
The audience side renders the virtual concert and accepts the audience’s interactions
with the performers. The client software running on the audiences’ local machines
should be a rendering software (e.g., Blender) or a game-like program developed in
Unity or Unreal that accepts the standard motion data from Rokoko Studio. We are now
using Blender because it is easy to get hands-on. However, in the future, we will
consider developing our customized client software by Unity for lower streaming and
rendering delay and easier interaction for the audiences.
4
2.2. Motion Capture
Motion capture is the process of transforming the movements of a person or object in
reality into a digital dataset that describes the motion electronically. It is the project’s
foundation, which allows authentic persons to host virtual concerts in the metaverse or
virtual reality by acting as virtual characters. In other words, motion capture is the
bridge linking the virtual models in the concerts and the actual performers playing them.
After this process, the motion data captured will be transmitted to the rendering
software and applied to the models with rigged skeletons to display the performers’
movements. The general solution for motion capture is:
⚫ Hardware:
◼ Any Apple device with a TrueDepth front-facing camera: The product list can
be found on Apple’s official website (basically iPhone X and newer), and this
project uses iPhone 12 pro.
◼ Rokoko phone mount (see Fig. 2) or other phone rigs that holds the iPhone
(optional).
Fig 2. Rokoko phone mount attached to an actor
(Obtained from Rokoko’s tutorials) [1]
5◼ Rokoko suit and gloves: a motion capture suit integrated with 9-DoF IMU
motion sensors connected to the hub collecting all tracking data. It supports a
2.4 & 5G Wi-Fi connection of up to 100 meters with a 200fps frame rate.
⚫ Software:
◼ Rokoko Studio: The software can process the raw data captured by iPhone and
Rokoko suit into a standard format that the rendering program can use. It can
also export the motion animation into a .fbx file or live stream it by add-ons to
other software.
◆ Version:
1.19
◆ System Minimum Requirements:
OS: Windows 10 (64-bit)
CPU: Intel Core i5 3.00GHz
Memory: 8GB
GPU: NVIDIA GTX 980
◼ Rokoko Remote: This is an ios app that captures the facial movement data by
ARKit and sends the raw motion data to the Rokoko Studio running on the
computer within the local network.
◆ Version:
1.2
◆ Compatibility:
iPhone with a TrueDepth front-facing camera and iOS 12.0 or later
Specifically, in this project, we mainly focus on capturing people rather than objects,
and their faces and bodies are captured in different methods.
2.2.1. Facial Capture
To capture facial movements, we first need to launch the Rekoko Remote on our iPhone
12 pro and connect it to the Rokoko Studio running on a machine in the local network.
The Rokoko Remote’s captured data should be in the format of blendShapes designed in
ARKit. There are 52 named coefficients in blendShapes (e.g., jawOpen describing the
6lower jaw opening, and eyeBlinkLeft describing the eyelids’ closure over the left eye)
representing the detected facial expression in terms of the movement of specific facial
features [2]. The corresponding value for each key is a floating-point number indicating
the current position of that feature relative to its neutral configuration, ranging from 0.0
(neutral) to 1.0 (maximum movement). More details can be found in Apple’s ARKit
documentation. Another requirement is that the character models used in the concert must
also have the 52 blendShapes on their facial meshes to support this motion data.
After the data processing in Rokoko Studio, a pack of motion data is available and can be
exported as .pbx files for use in other software. However, we prefer real-time streaming
instead of offline rendering in this project. Therefore, we need to enable the live-stream
function of Rokoko Studio and connect the software to the IP addresses and ports that we
want to stream via UDP. The format of the data transmitted is in JSON, and part of the
JSON’s structures containing the general information and facial data are listed below.
{
version: 3,
fps: 60,
scene: {
timestamp: 0,
actors: [{
name: "Alan", //arbitary size
color: {r, g, b}, // bytes
meta: {hasGloves: true, //Indicates if fingers are controlled
hasLeftGlove: true, //Indicates if left fingers are controlled
hasRightGlove: true, //Indicates if right fingers are controlled
hasBody: true, //Indicates if body is controlled
hasFace: true //Indicates if face is controlled}
face: { // optional section
leftEyeBlink: 0, // 0-100, different from 0-1 in the ARKit
... // Other 52 blendShapes data}
}]
}
}
72.2.2. Body Capture
This project will capture the body movement of actors through Rokoko smart-suit and
gloves. The Rokoko bundle is a motion capture tool based on an inertial sensor system.
It collects the posture and orientation of body parts, restores the kinematics motion model,
and presents the data in the analysis software through wireless transmission.
Compared with traditional optical motion capture, inertial sensors are more popular with
lower prices, higher environmental adaptability, and higher accuracy. It is necessary to
wear inertial sensor devices, including integrated accelerometers, gyroscopes, and
magnetometers, at important joints of moving objects during motion capture. A 3D
coordinate system will be established after initializing the device. The accelerometer
monitors the acceleration and direction of motion caused by human motion while
compensating it with the angular velocity calculated by the gyroscope. The precise
direction measured by the magnetometer is used to track the object’s motion [3]. These
technologies solve the shortcomings of limited monitoring areas and the occlusion failure
in optical motion capture. Due to the extensive range, high sensitivity, and good dynamic
performance of the obtained posture information, inertial capture is used chiefly for real-
time attitude tracking tasks, which is suitable for this project.
Rokoko smart suit and other inertial motion capture systems generally apply an Inertial
Measurement Unit (IMU) composed of some MEMS (Micro-Electro-Mechanical System)
equipment [3]. However, the sensor motion parameters measured by the IMU are
interfered with by noise, and the MEMS device has a noticeable drift. As a result, the
motion capture system cannot accurately track the human posture for an extended period.
The official software Rokoko Studio solves this problem by noise interference filter and
8algorithm calibration. It supports combining facial capture with body motion and
simultaneously streaming output to other rendering software. Moreover, the built-in
motion library of the software can also support performance diversity for this project.
2.3. Lip Movement Generation Based on Speech
The design of Sync Lip based on speech refers to the work of Cudeiro D, Bolkart T,
Laidlaw C, et al. in 2019 [4]. The model is trained on a dataset called VOCASET,
including 480 sequences of 3-4s and 12 different subjects, each of which has a 3D scan
at 60fps and is aligned to a standard face template mesh on the top of the FLAME head
model [5]. This method makes the training data subject-independent so that our model
can easily generalize the output to any other unseen subject. The original model, VOCA,
takes the sound stream as input and outputs a list of 5023 ×3 dimensional arrays of vertex
displacements from the FLAME model’ s zero pose T. The output is the face shape
predictions on each sound frame, and we can recover the face meshes from the model
output.
The VOCA model is like an encoder-decoder network. The encoder encodes the audio to
a low-dimensional vector at some specific frequency. It uses DeepSpeech [6] first to
capture the main feature of the audio and adds four convolution layers and two fully
connected layers. The decoder uses fully connected layers to convert the vector to a 5023
×3 dimensional vector as the output. After that, the original trained model will convert it
to the face meshes based on the FLAME model and generalize it to our subject’s face.
However, because the subject’s model we are currently using will be in Apple’s ARKit
blendShapes model, we must try to modify the VOCA into a model that outputs the
9blendShapes values. During modification, tests should be carried out to test the real-time
performance and reduce the resolution if necessary.
2.4. Model & Rendering
The design and modeling of actor character models involved in this project will be
completed in VRoid Studio, which is a free 3D animation character creation software
invented by Pixiv Inc. Modeling in a way similar to painting, the software provides users
with a platform to easily create their own avatars [7]. It is simple to customize the facial
features, hairstyles, and outfits in different shapes and color designs through intuitive
sliders. The real-time modeling function is supported, and the exported model file can
seamlessly connect the body bones detected in Rokoko Studio in the rendering software.
In order to accurately represent the facial expressions of motion capture actors, the
character models also need to be connected to iPhone ARkit 52 blendShape through the
Faceit 2.0 plugin in Blender (or an alternative called HANATool in Unity). It realizes the
diversification of facial expressions through the Semi-automatic Face Rigging function
and retargeting facial key points to match ARkit performance capture [8].
Currently, we are using Blender 3.1.2 as rendering software, and we have installed the
Rokoko Studio Live Blender Plugin 1.4.0 in the Blender to receive real-time motion data
from Rokoko Studio. Blender has two popular rendering engines: Eevee and Cycles.
Eevee is fast but has lower visual rendering quality and less customized settings, while
Cycles is slow but has more visual effects. Due to the real-time requirement of the project,
the Eevee is selected for fast rendering with the default shaders. Here are some of the
basic engine settings:
10⚫ Engine: Eevee
⚫ Sampling:
◼ Render: 64
◼ Viewport: 16
◼ Viewport Denoising: True
⚫ Ambient Occlusion: True
◼ Distance: 0.2 m
◼ Factor: 1.00
◼ Trace Precision: 0.250
◼ Bent Normals: True
◼ Bounces Approximation: True
⚫ Bloom: True
◼ Threshold: 0.800
◼ Knee: 0.500
◼ Radius: 6.500
◼ Color: H: 0.000, S: 0.000, V: 1.000
◼ Intensity: 0.050
◼ Clamp: 0.000
⚫ Screen Space Reflection: True
◼ Refraction: False
◼ Half Res Trace: True
◼ Trace Precision: 0.250
◼ Max Roughness: 0.500
◼ Thickness: 0.2 m
◼ Edge Fading: 0.075
◼ Clamp: 10.000
⚫ Motion Blur: True
◼ Position: Center on Frame
◼ Shutter: 0.50
◼ Background Separation: 100.00
◼ Max Blur: 32px
◼ Steps: 1
113. Current Progress
3.1. Motion Capture
We are still at the early stage of development and have not decided on the final character
models to use in the concert. Therefore, we adopt a free anime girl model (see Fig. 3)
produced by Lilin_VDaemon using the same methodology introduced in the previous
model section to produce demos. It has skeletons rigged and 52 belndShapes of ARKit
on the facial mesh.
Fig 3. Front of the character model produced by Lilin_VDaemon
3.1.1. Facial Capture
We have successfully connected Rokoko Remote on the iPhone 12 Pro to the Rokoko
Studio running on the desktop in the same local network and started the facial capture
process (see Fig 4). Furthermore, the captured facial expressions appeared in the Rokoko
Studio in real-time, as shown in Fig 5. In the Blender project, we installed the Rokoko
Studio Live Blender Plugin to receive the motion data and bind the input data to the
12model’s blendShapes (see Fig 6). After pressing the start receiving button, the face of the
model began to move.
Fig 4. Rokoko Remote doing facial capture on the iPhone 12 Pro
Fig 5. Rokoko Studio receiving captured facial data
13Fig 6. Blender project with model bound with input facial motion data
Next, we have used the rendering engine introduced in the previous section to render
some facial expressions in real-time, and the results are listed in Fig 7. We have
rendered Six expressions as a showcase: left eye blink, right eye blink, both eyes closed,
mouth open, happy and angry by order.
Fig 7. Six expressions rendered in Blender using facial capture
143.1.2. Body Capture
Due to the impact of the COVID-19, the team has not received the Rokoko smart suit.
Thus the body movement capture has not yet been thoroughly carried out. The group
members found some adaptable motion modules in the motion library of Rokoko Studio
when facial capturing. The team also attempted to find out dance moves from the internet
to evaluate the performance of the actor model.
Fig 8. Body movement from Rokoko motion library rendered in Blender
3.2. Lip Movement Generation Based on Speech
After studying the methodology, we found that the paper provided a pre-trained model.
We first used the model for basic testing, i.e., input some audio clips to see if the model
can show the correct mouth shapes in a three-dimensional face model. Since the output is
all videos, we only capture a few frames for display here.
Test case 1:
15This audio clip is a simple speech audio and does not have background music or noises.
It is just a speaker reading aloud clearly.
Fig 9. Test case about speech audio
From this test case, we can see the mouth shape generally conforms to the pronunciation
if the audio is about a speaker reading aloud clearly. This trained model has good results
for this kind of simple speech audio.
16Test case 2:
In this audio clip, some singers are singing in Chinese with various loud background
music and noises.
Fig 10. Test case about singing audio
The test result of this case is not ideal. When the singer is singing, especially when the
background music is loud, the final mouth shape does not correspond well to the singing
pronunciation. Therefore, the trained model provided by the official is unsatisfactory to
17apply to the concert, which needs to be further improved or replaced by an optimized
model.
From the audio training datasets provided by the official, we can see they are primarily
clear speech audios, but it does not contain enough singing audios. So this may be the
main reason why the trained model cannot fit well the singing scenarios. Therefore, our
next step is to collect more audios into the dataset, especially those with background
music interference, and train a better model to adapt to various concert scenarios.
184. Future Plan
Objectives Estimated Deadline
Body capture using Rokoko Suit and display the TBA (Due to the uncertainty
motion on the character models of equipment’s shipment)
Modification of lip-sync model to adapt to ARKit 2022/06/15
blendShapes face model
Development of streaming server’s protocol and 2022/06/20
program
Improvement of lip-sync model’s performance in 2022/07/01
singing
Development of an easy-to-use client supporting real- 2022/07/01
time streaming and VR viewing using Unity or Unreal
to replace Blender
Adding interaction-with-performers function to the 2022/07/25
audience’s client
Final report and product deliverables 2022/08/01
19References
[1] Rokoko. (2022, Mar. 21). Setting up and attaching the Rokoko FaceCap Body Mount
[Online]. Available:
https://support.rokoko.com/hc/en-us/articles/4410465175313-Setting-up-and-attaching-
the-Rokoko-FaceCap-Body-Mount
[2] Apple. (2022). ARKit Documentation [Online]. Available:
https://developer.apple.com/documentation/arkit/arfaceanchor/2928251-blendshapes
[3] A. Szczęsna, P. Skurowski, E. Lach, P. Pruszowski, D. Pęszor, M. Paszkuta, at el.,
“Inertial motion capture costume design study,” Sensors, vol. 17, p. 612, Mar. 2017.
[4] D. Cudeiro, T. Bolkart, C. Laidlaw, et al. “Capture, Learning, and Synthesis of 3D
Speaking Styles,” Conference on Computer Vision and Pattern Recognition (CVPR).
IEEE, 2019, pp. 10101-10111.
[5] T. Li, T. Bolkart, M. J. Black, H. Li, and J. Romero, “Learning a model of facial shape
and expression from 4D scans,” ACM Transactions on Graphics, vol. 36, no. 6, pp. 1-17,
2017.
[6] A. Hannun, C. Case, J. Casper, B. Catanzaro, G. Diamos, E. Elsen, et al. “Deep speech:
Scaling up end-to-end speech recognition,” arXiv preprint arXiv:1412.5567, 2014.
[7] “VRoid Studio: 3D character creation software” [Online].
Available: https://vroid.com/en/studio
[8] FBra, “Faceit: Facial expression and performance capture,” Blender Market [Online].
Available: https://blendermarket.com/products/faceit
20You can also read

















































