CI-dataset and DetDSCI methodology for detecting too small and too large critical infrastructures in satellite images: Airports and electrical ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

CI-dataset and DetDSCI methodology for detecting too
small and too large critical infrastructures in satellite
images: Airports and electrical substations as case
study
Francisco Pérez-Hernándeza,∗, Jose Rodrı́guez-Ortegaa , Yassir Benhammoua ,
arXiv:2105.11844v2 [cs.CV] 21 Sep 2021
Francisco Herreraa , Siham Tabika
a Andalusian Research Institute in Data Science and Computational Intelligence, University
of Granada, 18071 Granada, Spain
Abstract
The detection of critical infrastructures in large territories represented by aerial
and satellite images is of high importance in several fields such as in security,
anomaly detection, land use planning and land use change detection. However,
the detection of such infrastructures is complex as they have highly variable
shapes and sizes, i.e., some infrastructures, such as electrical substations, are
too small while others, such as airports, are too large. Besides, airports can have
a surface area either small or too large with completely different shapes, which
makes its correct detection challenging. As far as we know, these limitations
have not been tackled yet in previous works. This paper presents (1) a smart
Critical Infrastructure dataset, named CI-dataset, organised into two scales,
small and large scales critical infrastructures and (2) a two-level resolution-
independent critical infrastructure detection (DetDSCI) methodology that first
determines the spatial resolution of the input image using a classification model,
then analyses the image using the appropriate detector for that spatial resolu-
tion. The present study targets two representative classes, airports and elec-
trical substations. Our experiments show that DetDSCI methodology achieves
up to 37,53% F1 improvement with respect to Faster R-CNN, one of the most
influential detection models.
Keywords: Detection, Convolutional Neuronal Networks, Remote sensing
images, Ortho-images
∗ Corresponding author
Email addresses: fperezhernandez@ugr.es (Francisco Pérez-Hernández),
jrodriguez98@correo.ugr.es (Jose Rodrı́guez-Ortega), benhammouyassir2@gmail.com
(Yassir Benhammou), herrera@decsai.ugr.es (Francisco Herrera), siham@ugr.es (Siham
Tabik)
Preprint submitted to Elsevier September 22, 2021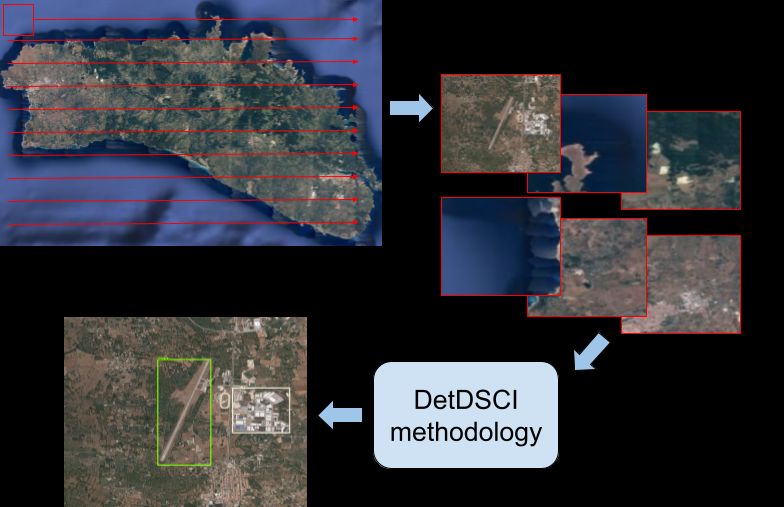
1. Introduction
Critical infrastructures are a type of human land use that are essential for
the functioning of a society and economy [22, 26, 28]. Any threat to these
facilities can cause severe problems. Examples of critical infrastructures include
airports, electrical substations and harbours among others. The detection of
this type of infrastructures in high resolution ortho-images is of paramount
importance in several fields such as security, land use planning and change
detection [5, 12, 20, 29].
Currently, deep CNNs have been largely used in the classification of high
resolution ortho-images [6, 10, 28] as they achieve good accuracies specially in
distinguishing infrastructures of similar scales in images of the same size and
same spatial resolution. Nevertheless, the detection of critical infrastructures
with dissimilar sizes and scales, e.g., electrical substations, which usually cover
a surface area of the order of hundreds m2 , versus airports, which can cover
from few to hundreds km2 , is still challenging.
Such task is addressed using remote sensing data and deep Convolutional
Neural Networks (CNNs). Remote sensing data are high resolution ortho-images
that can be obtained from Unmanned Aerial Vehicle (UAV) (captured at height
< 30km and covers from 0,1 to 100Km2 ), planes (at height < 30km and covers
from 10 to 100Km2 ) or satellites (> 150km 10 to 1000 Km2 ) [25]. Obtaining
large amounts of this type of data is expensive. Fortunately, several sources,
such as Google Earth1 and Bing Maps2 , allow downloading aerial and satellite
images freely for the academic community. In spite of this, most existing land
use datasets are prepared for training classification models and do not include
annotations for training detection models.
This paper presents two-level deep learning Detection for Different Scale
Critical Infrastructures (DetDSCI) methodology in ortho-images. We reformu-
late the problem of detecting critical infrastructures in ortho-images into two
sub-problems, the detection of too small and too large scale critical infrastruc-
tures. DetDSCI methodology detects the type of infrastructure independently
of its scale and consists of two stages:
• The first stage is based on a spatial resolution classification model that
analyses the 2000 × 2000 pixels input image to estimate its zoom level and
hence determine the detector to be used in the next stage.
• The second stage includes two expert detectors, one for small and the
other for large critical infrastructures. Once the zoom level of the input
image is determined by the first stage, the selected detector will analyse
that input image according to its spatial resolution.
Addressing the detection of too small and too large scale critical infrastruc-
tures in remote sensing images independently on the spatial resolution can offer
1 Google Earth: https://earth.google.com/web
2 Bing Maps: https://www.bing.com/maps
2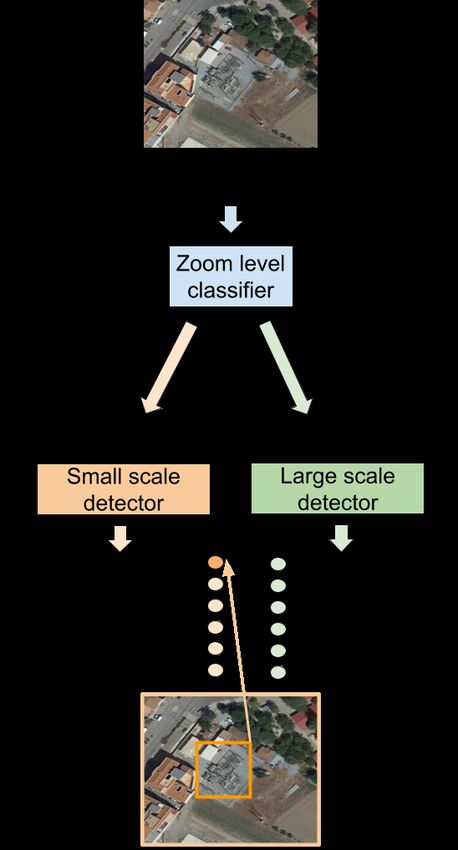
better performance. Our study targets two representative critical infrastruc-
tures, namely airports and electrical substations. As there are no public detec-
tion datasets that include both categories of critical infrastructures, we carefully
built a specialised dataset, Critical Infrastructures dataset (CI-dataset). CI-
dataset is organised into two subsets, Small Scale Critical Infrastructure (CI-SS)
dataset with electrical substation class and Large Scale Critical Infrastructure
(CI-LS) dataset with airport class.
The main contributions of this paper can be summarised as follows:
• Differently to the traditional process adopted for building most datasets,
we followed a dynamic process for constructing the high quality CI-dataset
organised into two scales, CI-SS for small scale critical infrastructures and
CI-LS for large scale critical infrastructures. This process can be used to
include more types of infrastructures. CI-dataset is available through this
link3 .
• We present DetDSCI methodology, a two-stages deep learning detection
for dissimilar scale critical infrastructures in ortho-images. DetDSCI method-
ology first determines the spatial resolution of the input image then anal-
yses it according to its spatial resolution using the appropriate expert
detector. This methodology overcomes the baseline detectors trained on
our high quality dataset.
This paper is organised as follows. First, a comprehensive review of related
works is provided in Section 2. Our DetDSCI methodology is presented in
Section 3. The dynamic process of building our CI-dataset is provided in Section
4. The experimental analysis carried out for the construction of CI-dataset
and the evaluation of DetDSCI methodology are given in Section 5. Finally,
conclusions and future works are given in Section 6.
2. Related works
Related works that apply deep learning on remote sensing data can be
broadly divided into two types, top-down and bottom-up works:
• Top-down works, first build a large dataset with an important number of
object-classes, mainly objects that can be recognised from remote sensing
images, e.g., vehicles or soccer stadiums. Then, analyse these images using
a deep learning classification or detection models [6, 7, 8, 10, 16, 17, 24, 28].
• Bottom-up works focus on solving one specific problem that involves one
or few object classes, e.g., airports [3, 4, 18, 27, 30], trees [2, 11, 13, 23]
and whales [14].
3 CI-dataset: https://dasci.es/transferencia/open-data/ci-dataset/
3Our work belongs to the second category as our final objective is to build
a good detector of two specific critical infrastructures, namely, airports and
electrical substations. This section provides a brief summary of the current
general datasets that include some critical infrastructures, the so-called top-
down works (Section 2.1) then reviews the deep learning approaches used in
bottom-up works (Section 2.2).
2.1. Top-down works
Most databases provided by top-down works are multi-class datasets that
include some critical infrastructures, annotated for the task of image classifica-
tion, which limits their usefulness. See summary in Table 1 where only a few
datasets are prepared for the task of detection.
Table 1: Characteristics of general datasets that include some critical infrastructures.
#Classes #Images #Image
Dataset Source Resolution Annotation
(#Infrastructure) (#Instances) width
LULC[28] 21 (7) 2100 (2100) 256 National Map 30cm Classification
NWPU
45 (13) 31500 (31500) 256 Google Earth 20cm-30cm Classification
RESISC45[6]
fMoW[10] 62 (25) 523846 (132716) N/A OpenStreetMap 31cm-1.6m Classification
NWPU
10 (4) 800 (3651) ∼1000 Google Earth 15cm-12m Horizontal BB
VHR-10[7]
xView[16] 60 (9) 1400 (1000000) 3000 DigitalGlobe 31cm Horizontal BB
DIOR[17] 20 (11) 23463 (192472) 800 Google Earth 30cm-50cm Horizontal BB
DOTA[24] 15 (6) 2806 (188282) 800∼4000 Google Earth 15cm-12m Oriented BB
For example, in [28], the authors created LULC dataset organised into 21
classes. Each class contains 100 images of size 256 × 256 pixels. The authors
in [6] provide a dataset named NWPU-RESISC45. This dataset is composed of
31.500 images of 256 × 256 pixels, in 45 classes with 700 images in each class.
NWPU-RESISC45 includes images with a large variation in translation, spatial
resolution, viewpoint, object pose, illumination, background, and occlusion. Be-
sides, it has high within-class diversity and between-class similarity. Functional
Map of the World (fMoW) [10] is a dataset containing a total of 523.846 images
with a spatial resolution of 0, 31 and 1, 60 meters per pixel. It includes 62 classes
with 132.716 instances from OpenStreetMap. These datasets are prepared for
the image classification task and hence they are not useful for the detection
task.
Examples of datasets prepared for the task of object detection are NWPU
VHR-10, xView, DIOR and DOTA. NWPU VHR-10 dataset [7] is organised
into 10 classes, each class contains 800 images of width 1000 pixels. It contains
mainly small scale objects such as airplane, ship, storage tank, baseball dia-
mond, tennis court, basketball court, ground track field, harbour, bridge, and
vehicle. Authors on [16] presented xView dataset for detecting 60 object-classes
with over 1 million instances. These classes are focused on vehicles and small
scale objects and the images have a width of 3000 pixels. DIOR, a new dataset
was published on [17], where 23463 images and 192472 instances covered 20
object classes. DIOR dataset has a large range of object size variations and is
4focused on detection with a width on the images of 800 pixels. DOTA dataset
[24] is composed of 15 classes of small scale objects with 2.806 images from
Google Earth where the total instances are 188.282. The size of the images
is between 800 and 4.000 pixels, and they are labelled with oriented bound-
ing boxes. Although the last four datasets are prepared for the task of object
detection, they do not focus on any specific problem as they are all types of vis-
ible objects from space. In addition, none of these datasets includes electrical
substations and only DIOR includes the airport category.
2.2. Bottom-up works
A large number of bottom-up works focus on improving the detection of air-
ports. In [30], the authors propose a method using CNNs for airport detection
on optical satellite images. The proposed method consists mainly of three steps,
namely, region proposal, CNN identification, and localisation optimisation. The
model was tested on an image data set, including 170 different airports and 30
non-airports. All the tested optical satellite images were collected from Google
Earth with a resolution of 8m × 8m and a size of about 3000 × 3000 pixels. The
method proposed in [3] first detects various regions on RSIs, then uses these
candidate regions to train a CNN architecture. The sizes of the airport images
were 3000 × 2000 pixels with a resolution of 1m. A total of 92 images were
collected. In [4], the authors developed a hard example mining and weight-
balanced strategy to construct a novel end-to-end convolutional neural network
for airport detection. They designed a hard example mining layer to automati-
cally select hard examples by their losses and implement a new weight-balanced
loss function to optimise CNN. The authors in [27] proposed an end-to-end
airport detection method based on convolutional neural networks. Addition-
ally, a cross-optimisation strategy has been employed to achieve convolution
layer sharing between the cascade region proposal networks and the subsequent
multi-threshold detection networks, and this approach significantly decreased
the detection time. Once the airport is detected, they use an airplane detector
to obtain these instances. To address the insufficiency of traditional models in
detecting airports under complicated backgrounds from remote sensing images,
authors in [18] proposed an end-to-end remote sensing airport hierarchical ex-
pression and detection model based on deep transferable convolutional neural
networks.
53. DetDSCI methodology: Two-level deep learning Detection for Dif-
ferent Scale Critical Infrastructure methodology in ortho-images
Figure 1: DetDSCI Methodology detection applied to the island of Menorca (Spain). (a) A
sliding window processing approach. (b) Obtained 2000 × 2000 pixels crops. (c) DetDSCI
methodology applied to each crop. (d) Output image with detection results.
This section presents DetDSCI methodology which aims at addressing the
detection of airports and electrical substations of very dissimilar sizes and shapes
in large areas represented by satellite images, see illustration in Figure 1. We
define two broad ranges of spatial resolutions also called zoom levels, see cor-
respondence between zoom level and spatial resolution in Table 2. The first
range includes zoom levels in [14,17] and the second range includes zoom levels
in [18,23]. These intervals have been selected experimentally as described in the
next section.
Table 2: The correspondence between spatial resolution and zoom level.
Large critical infrastructures Small critical infrastructures
Zoom level Spatial resolution(m2 /pixel) Zoom level Spatial resolution(m2 /pixel)
14 6.2 18 0.39
15 3.1 19 0.19
16 1.55 20 0.10
17 0.78 21 0.05
22 0.02
23 0.01
To reduce the number of false positives due to the differences in different
zoom levels, DetDSCI methodology first distinguishes between the two zoom
6level ranges then applies the corresponding detector according to the spatial
resolution of each input image. In particular, DetDSCI is actually a two stages
pipeline as illustrated in Figure 2. The first stage determines whether the input
image belongs to the first or second zoom levels interval. Depending on the
selected zoom level interval, the second stage analyses that image using the
specialised detector on that specific group of critical infrastructures.
Figure 2: DetDSCI methodology.
3.1. Stage 1: Estimating the spatial resolution of the input image
To distinguish between too large and too small critical infrastructures, we
consider two zoom levels intervals, [14,17] and [18,23]. Too large infrastructures
can be visually recognised in 2000 × 2000 pixels images of zoom levels 14, 15,
716 and 17. See an example in Figure 3. While, too small scale infrastructures
can be visually recognised in 2000 × 2000 pixels images of zoom levels 18, 19,
20, 21, 22 and 23. See an example in Figure 4.
Figure 3: Four images of El Hierro airport (latitude: 27.81402o N, longitude: -17.88518o W,
Canary Islands, Spain) with zoom levels 14(a), 15(b), 16(c) and 17(d), obtained from Google
Maps.
8Figure 4: Six images of Guadix electrical substation (latitude: 37.30853o N, longitude: -
3.12997o W, Granada, Spain) with zoom levels 18(a), 19(b), 20(c), 21(d), 22(e) and 23(f),
obtained from Google Maps.
The first stage of DetDSCI distinguishes between these two intervals, large
[14,17] and small [18,23] zoom levels interval. This stage is based on a binary
classification model that analyses the input image to determine its zoom level
interval and hence determines the most appropriate detector to be used in the
second stage.
3.2. Stage 2: Detection of critical infrastructures
The zoom level interval estimated in the first stage will be used to guide the
selection of the detector in the second stage. In particular, this stage is based
on two detection models:
• The first detection model is applied to large scale infrastructures. It con-
siders six infrastructure classes, namely airport, bridge, harbour, indus-
trial area, motorway and train station. Figure 5 shows examples of these
classes.
• The second detection model is applied to small scale infrastructures. It
considers six classes, namely electrical substation, bridge, plane, harbour,
storage tank and helicopter. Figure 6 shows examples of these classes.
It is worth mentioning that the inclusion of new classes in both detectors
was based on the preliminary experimental study explained in the next section.
9Figure 5: Examples of the classes considered by the large infrastructure detection model,
left to right: airport(a), bridges(b), harbour(c), industrial area(d), motorway(e) and train
station(f).
Figure 6: Examples of the classes considered in the small infrastructure detection model,
left to right: electrical substation(a), bridge(b), plane(c), harbour(d), storage tanks(e) and
helicopter(f).
4. CI-dataset construction guided by the performance of Faster R-
CNN
It is well known that building good quality models requires good quality
datasets, also called smart data [21]. The concept of smart data includes all
pre-processing methods that improve value and veracity of data. In the context
of object detection, usually training datasets are first built then analysed using
machine learning models. This classical procedure is suitable only when the
10involved objects are of similar sizes and can be correctly identified at the same
spatial resolution.
To overcome these limitations, we built the critical infrastructures dataset,
CI-dataset, guided by the performance of one of the most robust detectors,
namely Faster R-CNN. We organised CI-dataset into two subsets, one for small
scale, CI-SS and the other one for large scale, CI-LS critical infrastructures. The
construction process of both subsets is dynamic and guided by the performance
of Faster R-CNN detection model on the electrical substation class for CI-SS and
the airport class for CI-LS. This section describes the construction process used
to obtain the final high-quality CI-dataset for detecting electrical substations
and airports.
The dynamic process guided by the detection model is based on three main
steps:
• Step 1: Constructing the initial set for each target class: First,
we selected the combination of zoom levels at which the airports and the
electrical substations can be recognised by the human eye. Then, we
downloaded images for each one of these two classes with different zoom
levels. Afterwards, we selected the most suitable zoom levels combination
guided by the performance of Faster R-CNN.
• Step 2: Extending the dataset with more object classes: We anal-
ysed all the object classes that can be confused with the target class and
hence can cause false positives (FP). All these potential FP are obtained
from public datasets and included in our CI-dataset. Then the perfor-
mance of the model is analysed to select the final object classes to be
included.
• Step 3: Further increasing the size of the training set: We in-
creased the number of instances of the final classes in the training set
using new images from Google Maps.
For simplicity, we named the three different versions of the training, test
datasets and detection model according to the construction step as described in
Table 3. At the end of this process, we obtained the final CI training and test
datasets.
Table 3: The names of the training and test subsets of the CI-dataset and the corresponding
detection model created at each step of the process.
Train Test Detection model
Step 1 CI-SS train alpha CI-SS test alpha CI-SS Det alpha
Step 2 CI-SS train beta CI-SS test stable CI-SS Det beta
Step 3 CI-SS train stable CI-SS test stable CI-SS Det stable
Step 1 CI-LS train alpha CI-LS test alpha CI-LS Det alpha
Step 2 CI-LS train beta CI-LS test stable CI-LS Det beta
Step 3 CI-LS train stable CI-LS test stable CI-LS Det stable
114.1. Step 1: Constructing the initial set for each target class
The first process is to carefully select the zoom levels at which the considered
objects fit in a 2000 × 2000 pixels image and can be recognised by the human
eye. Ortho-images of this size can capture small scale critical infrastructures
within 18 to 23 zoom levels (see Figure 6) and large scale critical infrastructures
within 14 to 17 zoom levels (see Figure 5). For building CI-dataset, we used
two services to visualise then download images from Google Maps, namely, SAS
Planet4 and Google Maps API5 .
Although all selected zoom levels provide useful information for training the
detection model, the lowest, 14 and 18, and highest zoom levels, 17 and 22 and
23, require specific manual pre-processing to fit 2000 × 2000 pixels 6 so that
they can be used for training the detection model. For the test process, no pre-
processing is applied and zoom levels 14 and 17 for large scale (Figure 7 (a))
and 18, 22 and 23 for small scale (Figure 7 (b)) infrastructures are discarded.
That is, we consider zoom levels in [19,21] for the electrical substation and in
[15,16] for the airport class, in the test set. Once the zoom levels are selected
for the training process, the images of the target class are downloaded to build
subsets CI-SS and CI-LS.
4 SAS Planet: //www.sasgis.org/
5 Google Maps API: //https://cloud.google.com/maps-platform
6 Pre-processing includes fusing multiple tiles, cropping a tile and/or resizing the obtained
image to 2000 × 2000 pixels. Notice that this size corresponds to the the input layer of the
detection model.
12Figure 7: Zoom levels discarded for the test. a) Large scale discard 14 for having the objects
too far away and 17 for occupying more of the image. b) Small scale discard 18 for having
the objects too far away and 22 and 23 for occupying more of the image.
Finally, once the target class dataset is constructed, we analysed all the com-
binations of zoom levels to determine which one improves the learning process
of the detection models. Guided by the performance of the Faster R-CNN on
the target class, we discarded the zoom levels that did not help in the learning
process of the detector.
Small Scale: The initial CI-SS dataset, CI-SS train alpha, is built using the
electrical substation images with zoom levels from 18 to 23. We downloaded
550 images with different zoom levels, as shown in Table 4a. For building the
test set, CI-SS test alpha, we downloaded 75 images of the electrical substation
class with zoom levels from 19 to 21, as shown in Table 4b.
13Table 4: Number of instances in the electrical substation class, a) CI-SS train alpha, b) CI-
SS test alpha.
(a)
Zoom level Electrical substation
18 103
19 103
20 103
21 103
22 103
23 103
Total 618
(b)
Zoom level Electrical substation
19 27
20 27
21 27
Total 81
Large Scale: The initial version of CI-LS dataset, CI-LS train alpha, is
built using only airport images with zoom levels from 14 to 17. We downloaded
160 images of airports from Spain and 80 airports from France, as shown in
Table 5a. To build the initial test set, CI-LS test alpha, we downloaded 32
images of Spanish airports with two zoom levels 15 and 16, as shown in Table
5b.
Table 5: Number of instances for the airport class, a) CI-LS train alpha, b) CI-LS test alpha.
(a)
Zoom level Airport
14 60
15 69
16 251
17 124
Total 504
(b)
Zoom level Airport
15 17
16 16
Total 33
4.2. Step 2: Extending the dataset with more object classes
After a careful analysis of the FP committed by the detection model when
trained on the initial dataset, we determined all potential object classes that
make the detector confuse the target class with other different objects. At this
stage, we analysed the impact of each one of these potential FP on the learning
14of the detector and extended the dataset with more object classes from public
datasets. If the performance improves, that potential FP class is maintained in
the dataset, otherwise it is eliminated from the dataset.
For small scale infrastructure, the DOTA dataset will be added since their
objects are of similar scales. For large scale infrastructures the DIOR dataset
will be used as it contains infrastructures of similar sizes.
Small Scale: Initially, we included in CI-SS train beta all DOTA classes
listed in Table 6. Then we eliminated each DOTA class one by one and evaluated
their impact on the detector performance.
Table 6: Number of instances for small scale critical infrastructures, CI-SS train beta.
Zoom level 18 19 20 21 22 23 DOTA Total
Electrical substation 103 103 103 103 103 103 - 618
Large vehicle 0 3 26 5 3 0 16923 16960
Swimming pool 111 104 62 11 2 0 1732 2022
Helicopter 0 0 0 0 0 0 630 630
Bridge 19 18 5 0 0 0 2041 2083
Plane 0 0 0 0 0 0 7944 7944
Ship 0 0 0 0 0 0 28033 28033
Soccer ball field 4 4 1 0 0 0 311 320
Basketball court 0 0 0 0 0 0 509 509
Ground track field 0 0 0 0 0 0 307 307
Small vehicle 0 0 141 234 68 5 26099 26547
Harbour 0 0 0 0 1 0 5937 5938
Baseball diamond 0 0 0 0 0 0 412 412
Tennis court 6 6 1 0 0 0 2325 2338
Roundabout 25 26 13 1 0 0 385 450
Storage tank 23 39 36 12 0 0 5024 5134
In addition, as we found that the most relevant new classes are bridge, har-
bour, storage tank, plane and helicopter, the detector is trained to discriminate
these classes too. For building CI-SS test stable, we included 132 images of the
five new classes, as summarised in Table 7.
Table 7: Number of instances in the final version of small scale critical infrastructures, CI-
SS test stable dataset.
Electrical Storage
Zoom level Helicopter Bridge Plane Harbour
substation tank
19 27 8 21 68 57 136
20 27 8 15 35 27 50
21 27 6 13 17 12 24
Total 81 22 49 120 96 210
Large Scale: After analysing the FP with Faster R-CNN, we included three
object classes from DIOR dataset into CI-LS train beta, namely train station,
bridge and harbour, and built the motorway and industrial area class, see Table
158. We built a test set, CI-LS test stable, by including 114 new images of the
five classes as it can be seen in Table 9.
Table 8: Number of instances for large scale critical infrastructures, CI-LS train beta dataset.
Zoom level Airport Train station Motorway Bridge Industrial Harbour
14 60 1 566 1 11 1
15 69 2 819 1 14 1
16 251 2 3207 8 34 1
17 124 19 2859 4 50 1
DIOR 1327 1011 - 3967 - 5509
Total 1831 1035 7451 3981 109 5513
Table 9: Number of instances the final version of large scale critical infrastructures, CI-
LS test stable dataset.
Zoom level Airport Train station Motorway Bridge Industrial Harbour
15 17 25 518 115 59 32
16 16 22 303 55 27 20
Total 33 47 821 170 86 52
4.3. Step 3: Further increasing the size of the training set
In this stage, we further increase the number of all the new object classes
added to both training subsets using new images from Google Maps.
Small Scale: As the CI-SS Det beta trained model confuses electrical sub-
station with several elements from urban areas, we included urban areas as
context in the new training images in the rest of the classes. Namely, we
downloaded a total of 1173 new images. The characteristics of the resulting
CI-SS train stable are shown in Table 10.
Table 10: Number of instances for small scale critical infrastructures, final CI-SS train stable
dataset.
Zoom level 18 19 20 21 22 23 DOTA 19 20 21 Total
Electrical substation 103 103 103 103 103 103 - 175 164 144 1101
Swimming pool 111 104 62 11 2 0 1732 807 308 130 3267
Helicopter 0 0 0 0 0 0 630 20 17 17 684
Bridge 19 18 5 0 0 0 2041 70 34 19 2206
Plane 0 0 0 0 0 0 7944 13 8 2 7967
Soccer ball field 4 4 1 0 0 0 311 142 64 40 566
Basketball court 0 0 0 0 0 0 509 91 49 35 684
Ground track field 0 0 0 0 0 0 307 4 0 0 311
Harbour 0 0 0 0 1 0 5937 1 0 0 5939
Baseball diamond 0 0 0 0 0 0 412 2 0 0 414
Tennis court 6 6 1 0 0 0 2325 120 45 27 2530
Roundabout 25 26 13 1 0 0 385 77 25 7 559
Storage tank 23 39 36 12 0 0 5024 499 213 61 5907
Large Scale: We further increased the size of CI-LS train beta dataset by
16including 768 new images. The characteristics of the resulting CI-LS train stable
are shown in Table 11.
Table 11: Number of instances for large scale critical infrastructures, final CI-LS train stable
dataset.
Zoom level Airport Train station Motorway Bridge Industrial Harbour
14 60 5 1012 37 69 17
15 69 6 1280 37 71 17
16 251 6 3947 57 116 27
17 124 27 4805 168 291 23
DIOR 1327 1011 - 3967 - 5509
Total 1831 1055 11044 4266 547 5593
5. Experimental study
This section provides all the performed experimental analysis to obtain CI-
dataset and the evaluation of DetDSCI methodology. Section 5.1 summaries the
experimental setup for the analysis. Section 5.2 provides all the detection model
results obtained during the CI-dataset construction process. Finally, Section 5.3
provides the analysis and comparison of the proposed DetDSCI methodology.
5.1. Experimental setup
The dynamic construction of the dataset requires the use of a good detection
model. After a careful experimental analysis, we found that Faster R-CNN is
the most suitable for this study as it achieves a good speed accuracy trade-off
[15].
For training the detection models, the images were resized to 2000 × 2000
pixels image, which represents the required size of the input layer of modern
detectors. A careful selection of the zoom level is necessary so that the entire
object can fit in the image.
In the experiments carried out in the next sections, we used Keras [9] as a
deep learning framework for classification and TensorFlow [1] as a deep learning
framework for detection.
For evaluating and comparing the performance we will use these metrics:
Precision, Recall and F1 (equation 1).
TP
P recision =
TP + FP
TP
Recall = (1)
TP + FN
P recision × Recall
F1 = 2 ×
P recision + Recall
where the number of true positives (TP), false positives (FP), and false
negatives (FN) is computed for each class.
17The detection performance is evaluated in terms of mAP (equation 2) and
mAR (equation 3) standard metrics for object detection tasks [19] given 100
output regions.
PK Z 1
i=1 APi 1 X
mAP = APi = p(r)dr (2)
K 10 0
r∈[0.5,...,0.95]
PK Z 1
i=1 ARi
mAR = ARi = 2 recall(o)do (3)
K 0.5
where given K categories of elements, p represents the precision and r recall
defines the area under the interpolated precision-recall curve for each class i.
Whereas o is IoU (intersection over union) in recall(o) is the corresponding recall
under the recall-IoU curve for each class i.
The performance of the detection models can be improved with the use of
several optimisation techniques, namely data augmentation (DA) and analysing
different feature extractors (FE). The eight DA techniques used to this task are
listed in Table 12 and their impact will be study on the performance of each
detector.
Table 12: Data augmentation techniques by model.
Model name Data augmentation technique
DA1 Normalize image
DA2 Random image scale
DA3 Random rgb to gray
DA4 Random adjust brightness
DA5 Random adjust contrast
DA6 Random adjust hue
DA7 Random adjust saturation
DA8 Random distort colour
Besides, we consider six feature extractors (FE) listed in Table 13 and train
the models with or without the best DA techniques. We will analyse the impact
of all these factors on the performance of each detection model.
Table 13: Configuration of feature extractors for different models.
Model name Region Proposal ResNet model with DA
FE1 Faster R-CNN ResNet 101 V1 No
FE2 Faster R-CNN ResNet 101 V1 Yes
FE3 Faster R-CNN ResNet 152 V1 No
FE4 Faster R-CNN ResNet 152 V1 Yes
FE5 Faster R-CNN Inception ResNet V2 No
FE6 Faster R-CNN Inception ResNet V2 Yes
185.2. Experimental study for the construction of the CI-dataset
Section 4 provided a detailed description of the construction process of CI-
dataset. This subsection provides the experimental results of the detection
model at each stage of that process. The performance obtained in steps 1, 2,
and 3 are respectively analysed in Section 5.2.1, 5.2.2 and 5.2.3. Finally, the
experimental analysis of the use of DA techniques and different FE is provided
in Section 5.2.4.
5.2.1. Analysis of step 1: Construction of the target class dataset
Once the initial CI-dataset of the target class is constructed, we analysed all
the combinations of zoom levels to determine which one improves the learning
process of the detection models. Guided by the performance of the detection
model on the target class, we discarded the zoom levels that did not help in the
learning process of the detector.
Small Scale: The performance of the first detector, CI-SS Det alpha, trained
on different zoom level combinations shows similar results as it can be seen from
Table 14. We selected the combination that provides the highest number of im-
ages, which is the one that includes all the zoom levels, 18, 19, 20, 21, 22 and
23.
Table 14: Performance of CI-SS Det alpha when trained on different zoom level combinations
of CI-SS train alpha and tested on CI-SS test alpha dataset.
mAP 0.5 mAP mAR
Zoom level
Precision Recall F1 electrical 0.5-0.95 0.5-0.95
combination
substation mean mean
18,19,20,21,22,23 96,49% 67,90% 79,71% 87,45% 48,30% 60,70%
19,20,21,22,23 93,44% 70,37% 80,28% 86,23% 51,70% 60,40%
18,19,20,21,22 91,94% 70,37% 79,72% 89,90% 48,70% 59,00%
20,21,22,23 92,31% 59,26% 72,18% 79,35% 43,50% 55,80%
19,20,21,22 89,39% 72,84% 80,27% 89,18% 51,60% 62,60%
21,22,23 82,76% 29,63% 43,64% 57,90% 28,10% 38,40%
20,21,22 89,29% 61,73% 72,99% 80,55% 44,50% 54,40%
21,22 82,35% 17,28% 28,57% 51,11% 24,50% 34,70%
Large Scale: The performance of the detection model, CI-LS Det alpha, in
different zoom level combinations shows that the best and most stable results
are obtained by the combination of these zoom levels, 14, 15, 16 and 17, as it
can be seen in Table 15.
19Table 15: Performance of CI-LS Det alpha when trained on different zoom level combinations
of CI-LS train alpha and tested on CI-LS test alpha dataset.
mAP mAR
Zoom level mAP 0.5
Precision Recall F1 0.5-0.95 0.5-0.95
combination airport
mean mean
14,15,16,17 87,76% 86,00% 86,87% 89,52% 61,30% 69,10%
14,15,16 78,85% 82,00% 80,39% 84,67% 55,50% 62,10%
15,16,17 68,42% 78,00% 72,90% 87,89% 54,50% 64,20%
15,16 87,23% 82,00% 84,54% 82,66% 51,00% 57,90%
5.2.2. Analysis of step 2: Extending the number of classes
Once the CI-dataset is extended with new classes from public datasets, we
analysed whether the new classes improve the performance of the detection
models.
Small Scale: As it can be seen from Table 16, eliminating the three DOTA
classes, small vehicle, large vehicle and ship, improves the F1 of CI-SS Det beta
detection model. Therefore, the final dataset CI-SS train stable contains 13
classes, tennis court, baseball diamond, ground track field, basketball court,
soccer-ball field, roundabout and swimming pool in addition to bridge, harbour,
storage tank, helicopter, plane and electrical substation.
Table 16: Results of different classes to delete from DOTA dataset trained on CI-SS train beta
and tested on CI-SS test stable dataset.
Classes deleted Precision Recall F1
None 88,28 % 58,38 % 70,22 %
- Small vehicle 92,61 % 59,64 % 72,53 %
- Large vehicle 90,30 % 62,44 % 73,81 %
- Ship 90,67 % 67,53 % 77,35 %
- Tennis court 88,09 % 63,00 % 73,39 %
- Baseball diamond 89,97 % 66,33 % 76,31 %
- Ground track field 87,02 % 65,77 % 74,84 %
- Basketball court 91,19 % 63,80 % 74,99 %
- Soccer-ball field 93,47 % 66,64 % 77,74 %
- Roundabout 90,48 % 65,28 % 75,70 %
- Swimming pool 90,74 % 66,55 % 76,73 %
Large Scale: The results of the detection model, CI-LS Det beta, trained
on CI-LS train beta, are shown in Table 17. As it can be observed from this
table, including some DIOR classes increases the mAP of the detection model
on the airport class to 85,73%.
20Table 17: Performance of CI-LS Det beta when trained on CI-LS train beta and tested on
CI-LS test stable.
CI-LS Det beta
Mean 22,03%
Airport 85,73%
Train station 6,98%
mAP 0.5 Motorway 4,30%
Bridge 31,97%
Industrial 2,87%
Harbour 0,31%
Mean 12,20%
Small 2,00%
mAP 0.5-0.95
Medium 4,70%
Large 14,40%
mAR 0.5-0.95 22,10%
5.2.3. Analysis of step 3: Increasing the size of the dataset
Once the final classes are determined, new images are included to further
improve the performance of the models.
Small Scale: A comparison between CI-SS Det beta and the new CI-
SS Det stable, trained on the CI-SS train stable (Table 10), tested on the CI-
SS test stable (Table 7) dataset, is shown in Table 18. The performance of
CI-SS Det alpha trained and tested only on the electrical substation is included
in the table as reference as well. These results show clearly that the performance
of CI-SS Det stable improves when increasing the size of the training dataset.
Table 18: Performance of CI-SS Det beta and CI-SS Det stable, trained on CI-SS train stable,
tested on CI-SS test stable. CI-SS Det alpha is trained and tested only on the electrical
substation class.
CI-SS Det alpha CI-SS Det beta CI-SS Det stable
(only ele. sub.) (six classes) (six classes)
Mean 87,45% 54,21% 65,98%
Electrical substation 87,45% 78,88% 85,00%
Plane 0,00% 82,94% 85,30%
mAP 0.5 Helicopter 0,00% 33,83% 10,39%
Bridge 0,00% 18,33% 63,16%
Storage tank 0,00% 83,07% 92,28%
Harbour 0,00% 58,66% 59,75%
Mean 48,30% 32,30% 38,60%
Small 0,00% 15,30% 25,90%
mAP 0.5-0.95
Medium 31,80% 23,50% 27,90%
Large 49,70% 36,80% 43,40%
mAR 0.5-0.95 60,70% 47,80% 53,10%
For a further analysis, we analysed the TP, FP, FN, Precision, Recall and
F1 as shown in Table 19. As it can be observed, CI-SS Det stable reduces
substantially the number of FP and achieves the best F1 value. Therefore, the
CI-SS Det stable model will be used in the rest of the paper as it provides the
highest performance on our target class, electrical substation.
21Table 19: TP, FP, FN, Recall, Precision and F1 in CI-SS test stable. CI-SS Det stable is
trained on CI-SS train stable and CI-SS Det beta is trained on CI-SS train beta. For com-
parison purposes, CI-SS Det alpha is trained only on airports.
TP FP FN Precision Recall F1
CI-SS Det alpha(only ele. sub.) 117 449 7 20,67% 94,35% 33,91%
CI-SS Det beta(six classes) 75 124 49 37,69% 60,48% 46,44%
CI-SS Det stable(six classes) 112 62 12 64,37% 90,32% 75,17%
Large Scale: A comparison between CI-LS Det beta and the new CI-
LS Det stable, trained on CI-LS train stable (Table 11), tested on CI-LS test stable
(Table 9) dataset, is shown in Table 20. The mAP of CI-LS Det alpha trained
and tested only on the airport class is included in the table as reference as well.
As it can be seen from these results, CI-LS Det stable shows very similar mAP
on airports than CI-LS Det beta but much better mAP on the rest of potential
FP.
Table 20: Performance of CI-LS Det stable and CI-LS Det beta tested on CI-LS test stable
and CI-LS Det alpha trained and tested only on the airport class.
CI-LS Det alpha CI-LS Det beta CI-LS Det stable
(only airports) (six classes) (six classes)
Mean 89,52% 22,03% 36,48%
Airport 89,52% 85,73% 85,37%
Train station 0,00% 6,98% 26,45%
mAP 0.5 Motorway 0,00% 4,30% 5,16%
Bridge 0,00% 31,97% 40,53%
Industrial 0,00% 2,87% 20,96%
Harbour 0,00% 0,31% 40,40%
Mean 61,30% 12,20% 18,80%
Small 0,00% 2,00% 2,40%
mAP 0.5-0.95
Medium 0,00% 4,70% 6,50%
Large 61,30% 14,40% 23,00%
mAR 0.5-0.95 69,10% 22,10% 33,90%
A comparison with CI-LS Det stable trained on CI-LS train stable and tested
on CI-LS test stable is provided in Table 21. In general, CI-LS Det stable pro-
vides the highest F1.
Table 21: Comparison of TP, FP, FN, TN, Precision, Recall and F1 of CI-LS Det stable
trained on CI-LS train stable and tested on CI-LS test stable with CI-LS Det beta and CI-
LS Det alpha. CI-LS Det alpha is trained and tested only on the airport class.
TP FP FN Precision Recall F1
CI-LS Det alpha (only airports) 29 19 1184 60,42% 2,39% 4,60%
CI-LS Det beta (six classes) 236 35 977 87,08% 19,46% 31,81%
CI-LS Det stable (six classes) 334 39 879 89,54% 27,54% 42,12%
225.2.4. Analysis of the improvement of the detection models
The selection of the right DA techniques and FE can surely further improve
the performance of the detection model. We consider eight DA techniques listed
in Table 12 and study their impact on the performance of each detector. Besides
we consider six FE listed in Table 13 and train the models with or without
the best DA techniques. We analyse the impact of all these factors on the
performance of each detection model.
Small scale: Table 22 shows the performance of CI-SS Det stable when
applying individually different DA techniques on CI-SS train stable. As it can
be observed from this table, applying DA8, random distort colour, achieves the
best results in this model.
Table 22: Results of the different models with a DA technique in CI-SS train stable and
CI-SS test stable.
DA1 DA2 DA3 DA4 DA5 DA6 DA7 DA8
Mean 22,26% 67,85% 66,84% 68,07% 66,45% 64,83% 64,67% 69,07%
Electrical substation 0,01% 84,89% 83,65% 83,36% 82,35% 83,23% 82,81% 82,30%
Plane 41,34% 83,23% 88,72% 88,08% 82,35% 88,06% 85,69% 86,70%
mAP 0.5 Helicopter 0,02% 19,82% 16,48% 14,39% 14,99% 12,42% 10,32% 24,52%
Bridge 15,83% 64,90% 61,18% 65,86% 62,84% 55,08% 60,38% 64,96%
Storage tank 64,28% 90,25% 89,44% 91,66% 91,16% 91,29% 91,47% 89,88%
Harbour 12,11% 64,02% 61,55% 65,05% 65,03% 58,79% 57,32% 66,07%
Mean 12,80% 38,70% 39,20% 39,30% 39,20% 38,80% 38,40% 39,50%
Small 0,00% 23,30% 14,10% 24,40% 23,80% 21,80% 31,00% 13,50%
mAP 0.5-0.95
Medium 2,60% 26,50% 25,60% 27,50% 28,70% 28,20% 26,20% 26,60%
Large 18,90% 43,70% 44,90% 44,70% 44,30% 43,60% 43,70% 45,60%
mAR 0.5-0.95 23,50% 54,20% 54,40% 53,50% 54,70% 54,10% 52,80% 54,20%
Table 23 shows the impact of the different FE and DA on the performance of
CI-SS Det stable. As it can be seen, in mean, the best mAP is obtained when
using FE2. This detection model will be the new CI-SS Det stable.
Table 23: Results of different FE with or without DA techniques in CI-SS train stable and
CI-SS test stable.
FE1 FE2 FE3 FE4 FE5 FE6
Mean 65,98% 68,97% 63,16% 65,39% 65,83% 63,96%
Electrical substation 85,00% 85,19% 83,05% 87,55% 82,73% 87,78%
Plane 85,30% 84,43% 85,81% 80,91% 86,29% 84,96%
mAP 0.5 Helicopter 10,39% 23,14% 6,83% 12,48% 48,03% 6,23%
Bridge 63,16% 62,38% 48,45% 50,31% 60,54% 39,71%
Storage tank 92,28% 88,97% 91,01% 90,89% 90,93% 91,82%
Harbour 59,75% 69,70% 63,82% 70,22% 69,71% 73,29%
Mean 38,60% 40,20% 36,70% 37,60% 36,50% 37,60%
Small 25,90% 13,30% 4,70% 3,10% 2,70% 3,90%
mAP 0.5-0.95
Medium 27,90% 29,90% 23,60% 21,50% 29,70% 28,60%
Large 43,40% 46,30% 42,20% 44,50% 40,70% 42,10%
mAR 0.5-0.95 53,10% 54,10% 51,20% 53,10% 50,70% 51,30%
Large Scale: Table 24 shows the performance of CI-LS Det stable when
applying different DA techniques on CI-LS train stable. These results show that
applying DA3, random rgb to gray, achieves the best detection results.
23Table 24: Results of the different models with a DA technique in CI-LS train stable and
CI-LS test stable.
DA1 DA2 DA3 DA4 DA5 DA6 DA7 DA8
Mean 3,61% 35,91% 37,11% 36,98% 36,62% 35,04% 36,34% 36,98%
Airport 19,54% 85,71% 90,31% 85,75% 90,87% 91,50% 88,18% 85,84%
Train station 0,07% 20,72% 27,98% 26,12% 23,53% 15,84% 19,50% 23,39%
mAP 0.5 Motorway 0,36% 4,89% 6,19% 5,92% 6,36% 5,20% 5,81% 6,63%
Bridge 0,35% 39,44% 37,78% 40,44% 36,33% 35,92% 36,35% 45,05%
Industrial 0,11% 17,05% 21,02% 21,05% 15,85% 15,53% 22,06% 15,04%
Harbour 1,22% 47,64% 39,37% 42,62% 46,76% 46,24% 46,13% 45,94%
Mean 1,60% 18,50% 19,30% 18,20% 18,30% 18,50% 17,90% 17,70%
Small 0,10% 3,40% 3,00% 7,00% 2,20% 3,50% 2,30% 5,20%
mAP 0.5-0.95
Medium 0,00% 6,20% 7,30% 6,60% 6,30% 6,70% 6,30% 6,00%
Large 3,00% 20,70% 22,40% 21,10% 21,70% 20,80% 21,50% 23,00%
mAR 0.5-0.95 13,10% 34,80% 34,50% 35,40% 33,40% 34,20% 34,50% 34,70%
Table 25 shows the impact of the different FE and DA on CI-LS Det stable.
One can see that FE5 obtains the best performance with Inception ResNet V2
without DA techniques. This model will be the new CI-LS Det stable in the
rest of the paper.
Table 25: Results of different FE with or without DA techniques in CI-LS train stable and
CI-LS test stable.
FE1 FE2 FE3 FE4 FE5 FE6
Mean 36,48% 37,52% 37,67% 38,05% 42,34% 40,98%
Airport 85,37% 86,46% 84,03% 87,70% 86,01% 87,21%
Train station 26,45% 24,17% 34,20% 22,31% 27,76% 22,43%
mAP 0.5 Motorway 5,16% 5,53% 4,80% 5,77% 5,95% 8,01%
Bridge 40,53% 47,81% 36,69% 48,86% 57,27% 54,25%
Industrial 20,96% 17,43% 23,53% 17,54% 23,64% 22,38%
Harbour 40,40% 43,71% 42,78% 46,13% 53,41% 51,63%
Mean 18,80% 18,30% 18,80% 18,50% 20,30% 20,10%
Small 2,40% 5,70% 3,20% 6,50% 9,70% 7,70%
mAP 0.5-0.95
Medium 6,50% 7,30% 6,30% 6,70% 8,50% 7,20%
Large 23,00% 21,60% 22,00% 22,90% 22,50% 22,40%
mAR 0.5-0.95 33,90% 36,30% 35,10% 35,20% 35,20% 37,70%
5.3. Experimental study of DetDSCI methodology
Once CI-dataset is constructed and the final models are trained on the small
and the large scale critical infrastructures, we develop the zoom level classifier
for the DetDSCI methodology. The construction of the zoom level classifier is
presented in Section 5.3.1 and the analysis of DetDSCI methodology is shown
in Section 5.3.2.
5.3.1. Construction of the zoom level classifier
In the first stage of DetDSCI methodology, a zoom level classifier analyses
the input image and determines the scale of this input. This stage can be
addressed either by identifying the specific zoom level of each input image or
by identifying intervals of zoom levels.
In particular, we developed and analysed two classification models, the first
one is trained on ten zoom level classes, from 14 to 23, and the second classifi-
cation model is trained on two zoom level intervals, interval [14,17] and [18,23].
24Table 26 shows the number of images used to train and test these two classifi-
cation models. The used images were selected from datasets CI-SS train stable,
CI-SS test stable, CI-LS train stable and CI-LS test stable.
Table 26: Number of images by zoom level used for training and evaluating the classifiers.
14 15 16 17 18 19 20 21 22 23
Train 252 400 1256 2984 200 591 1080 2268 6406 663
Test 19 52 52 19 44 304 304 304 19 19
The confusion matrix for the classification by individual zoom level is shown
in Table 27. The overall accuracy of this model is 68,31%, which is very low.
Table 27: Confusion matrix for the classifier by zoom level individually.
Zoom level 14 15 16 17 18 19 20 21 22 23
14 0 13 5 0 0 0 0 0 1 0
15 0 14 34 2 0 0 0 2 0 0
16 0 0 25 26 0 0 1 0 0 0
17 0 0 1 18 0 0 0 0 0 0
18 0 0 0 33 0 8 2 0 1 0
19 1 0 0 9 0 209 69 12 4 0
20 0 0 0 0 0 12 224 57 11 0
21 0 0 0 2 0 1 6 268 25 2
22 0 0 0 0 0 0 0 2 17 0
23 0 0 0 0 0 0 0 1 18 0
The confusion matrix for the classification by interval is shown in Table 28.
This model obtains an accuracy of 96,83%, which is substantially higher than
the classification by individual zoom level. Therefore, we selected this classifier
to be included in our DetDSCI methodology.
Table 28: Confusion matrix for the classifier by zoom level by group.
Zoom level [14,17] [18,23]
[14,17] 134 8
[18,23] 28 966
5.3.2. Analysis of DetDSCI methodology
In this section, we analyse and compare the performance of DetDSCI method-
ology against the baseline detectors CI-LS Det stable and CI-SS Det stable and
a baseline detector, Base Det, trained on all the data and zoom levels.
The characteristic of each model is:
• Base Det: is a Faster R-CNN ResNet 101 V1 trained on all the data at
all zoom levels from CI-SS train stable and CI-LS train stable.
25• CI-LS Det stable: is a Faster R-CNN Inception ResNet V2 trained on
the CI-LS train stable dataset.
• CI-SS Det stable: is a Faster R-CNN ResNet 101 V1 with DA tech-
niques trained on the CI-SS train stable dataset.
• DetDSCI methodology: is the methodology by which each input image
is classified by the zoom level classifier and based on the output of this
classifier, the detector to be used is selected between CI-LS Det stable or
CI-SS Det stable.
We tested the four models on the images of the target classes, electrical sub-
station from CI-SS test stable and airport from CI-LS test stable. The results
in terms of TP, FP, FN, Precision, Recall and F1 are shown in Table 29.
Table 29: Performance comparison between DetDSCI methodology, Base Det, CI-
LS Det stable and CI-SS Det stable when tested on the fusion of CI-SS test stable and CI-
LS test stable.
TP FP FN Precision Recall F1
Base Det 70 35 44 66,67% 61,40% 63,93%
CI-LS Det stable 27 3 88 90,00% 23,48% 37,24%
CI-SS Det stable 71 32 44 68,93% 61,74% 65,14%
DetDSCI methodology 83 24 32 77,57% 72,17% 74,77%
As it can clearly see from this table, DetDSCI methodology overcomes
Base Det, CI-SS Det stable and CI-LS Det stable in all the aspects by achiev-
ing the highest performance. In particular, DetDSCI methodology achieves an
improvement in F1 of up to 37,53%.
6. Conclusions and future work
The detection of critical infrastructures in satellite images is a very chal-
lenging task due to the large scale and shapes differences, some infrastructures
are too small, e.g., electrical substations, while others are too large, i.e., air-
ports. This work addressed this problem by building the high quality dataset,
CI-dataset, organised into two subsets, CI-SS and CI-LS and using DetDSCI
methodology. The construction process of CI-SS and CI-LS was guided by the
performance of the detectors on electrical substations and airports respectively.
DetDSCI methodology is a two-stage based approach that first identifies the
zoom level of the input image using a classifier and then analyses that image
with the corresponding detection model, CI-LS Det stable or CI-SS Det stable.
DetDSCI methodology achieves the highest performance with respect to the
baseline detectors not only in the target objects but also in the rest of infras-
tructure classes included in the dataset.
26As conclusions, the proposed datasets and methodology are the best solution
for addressing the problem of different and dissimilar scale critical infrastruc-
tures detection in remote sensing images. This approach can be easily extended
to more critical infrastructures.
As a future work, we will extend the dataset and methodology to more
critical infrastructures and design a strategy to group sets of classes according
to their zoom level and shared features, with the objective to achieve more
robust detection models.
Acknowledgements
This work was partially supported by projects P18-FR-4961 (BigDDL-CET)
and A-TIC-458-UGR18 (DeepL-ISCO). S. Tabik was supported by the Ramon
y Cajal Programme (RYC-2015-18136).
References
[1] Martı́n Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng
Chen, Craig Citro, Greg S Corrado, Andy Davis, Jeffrey Dean, Matthieu
Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous
distributed systems. arXiv preprint arXiv:1603.04467, 2016.
[2] Kristian Skau Bjerreskov, Thomas Nord-Larsen, and Rasmus Fensholt.
Classification of nemoral forests with fusion of multi-temporal sentinel-1
and 2 data. Remote Sensing, 13(5):950, 2021.
[3] Ümit Budak, Abdulkadir Şengür, and Uğur Halici. Deep convolutional neu-
ral networks for airport detection in remote sensing images. In 2018 26th
Signal Processing and Communications Applications Conference (SIU),
pages 1–4. IEEE, 2018.
[4] Bowen Cai, Zhiguo Jiang, Haopeng Zhang, Danpei Zhao, and Yuan Yao.
Airport detection using end-to-end convolutional neural network with hard
example mining. Remote Sensing, 9(11):1198, 2017.
[5] Manuel Carranza-Garcı́a, Jorge Garcı́a-Gutiérrez, and José C Riquelme.
A framework for evaluating land use and land cover classification using
convolutional neural networks. Remote Sensing, 11(3):274, 2019.
[6] Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sensing image scene
classification: Benchmark and state of the art. Proceedings of the IEEE,
105(10):1865–1883, 2017.
[7] Gong Cheng, Junwei Han, Peicheng Zhou, and Lei Guo. Multi-class geospa-
tial object detection and geographic image classification based on collection
of part detectors. ISPRS Journal of Photogrammetry and Remote Sensing,
98:119–132, 2014.
27[8] Gong Cheng, Peicheng Zhou, and Junwei Han. Learning rotation-invariant
convolutional neural networks for object detection in vhr optical remote
sensing images. IEEE Transactions on Geoscience and Remote Sensing,
54(12):7405–7415, 2016.
[9] François Chollet et al. Keras, 2015.
[10] Gordon Christie, Neil Fendley, James Wilson, and Ryan Mukherjee. Func-
tional map of the world. In Proceedings of the IEEE Conference on Com-
puter Vision and Pattern Recognition, pages 6172–6180, 2018.
[11] Neil Flood, Fiona Watson, and Lisa Collett. Using a u-net convolutional
neural network to map woody vegetation extent from high resolution satel-
lite imagery across queensland, australia. International Journal of Applied
Earth Observation and Geoinformation, 82:101897, 2019.
[12] Daniel Guidici and Matthew L Clark. One-dimensional convolutional neu-
ral network land-cover classification of multi-seasonal hyperspectral im-
agery in the san francisco bay area, california. Remote Sensing, 9(6):629,
2017.
[13] Emilio Guirado, Domingo Alcaraz-Segura, Javier Cabello, Sergio Puertas-
Ruı́z, Francisco Herrera, and Siham Tabik. Tree cover estimation in global
drylands from space using deep learning. Remote Sensing, 12(3):343, 2020.
[14] Emilio Guirado, Siham Tabik, Marga L Rivas, Domingo Alcaraz-Segura,
and Francisco Herrera. Whale counting in satellite and aerial images with
deep learning. Scientific reports, 9(1):1–12, 2019.
[15] Jonathan Huang, Vivek Rathod, Chen Sun, Menglong Zhu, Anoop Ko-
rattikara, Alireza Fathi, Ian Fischer, Zbigniew Wojna, Yang Song, Sergio
Guadarrama, et al. Speed/accuracy trade-offs for modern convolutional ob-
ject detectors. In Proceedings of the IEEE conference on computer vision
and pattern recognition, pages 7310–7311, 2017.
[16] Darius Lam, Richard Kuzma, Kevin McGee, Samuel Dooley, Michael
Laielli, Matthew Klaric, Yaroslav Bulatov, and Brendan McCord. xview:
Objects in context in overhead imagery. arXiv preprint arXiv:1802.07856,
2018.
[17] Ke Li, Gang Wan, Gong Cheng, Liqiu Meng, and Junwei Han. Object
detection in optical remote sensing images: A survey and a new bench-
mark. ISPRS Journal of Photogrammetry and Remote Sensing, 159:296–
307, 2020.
[18] Shuai Li, Yuelei Xu, Mingming Zhu, Shiping Ma, and Hong Tang. Remote
sensing airport detection based on end-to-end deep transferable convolu-
tional neural networks. IEEE Geoscience and Remote Sensing Letters,
16(10):1640–1644, 2019.
28[19] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona,
Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco:
Common objects in context. In European conference on computer vision,
pages 740–755. Springer, 2014.
[20] Shengjie Liu, Zhixin Qi, Xia Li, and Anthony Gar-On Yeh. Integration
of convolutional neural networks and object-based post-classification re-
finement for land use and land cover mapping with optical and sar data.
Remote Sensing, 11(6):690, 2019.
[21] Julián Luengo, Diego Garcı́a-Gil, Sergio Ramı́rez-Gallego, Salvador Garcı́a,
and Francisco Herrera. Big data preprocessing. Cham: Springer, 2020.
[22] Barak Oshri, Annie Hu, Peter Adelson, Xiao Chen, Pascaline Dupas,
Jeremy Weinstein, Marshall Burke, David Lobell, and Stefano Ermon. In-
frastructure quality assessment in africa using satellite imagery and deep
learning. In Proceedings of the 24th ACM SIGKDD International Confer-
ence on Knowledge Discovery & Data Mining, pages 616–625, 2018.
[23] Anastasiia Safonova, Emilio Guirado, Yuriy Maglinets, Domingo Alcaraz-
Segura, and Siham Tabik. Olive tree biovolume from uav multi-resolution
image segmentation with mask r-cnn. Sensors, 21(5):1617, 2021.
[24] Gui-Song Xia, Xiang Bai, Jian Ding, Zhen Zhu, Serge Belongie, Jiebo Luo,
Mihai Datcu, Marcello Pelillo, and Liangpei Zhang. Dota: A large-scale
dataset for object detection in aerial images. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition, pages 3974–3983,
2018.
[25] Tian-Zhu Xiang, Gui-Song Xia, and Liangpei Zhang. Mini-uav-based re-
mote sensing: techniques, applications and prospectives. preprint, 2018.
[26] Zhifeng Xiao, Yiping Gong, Yang Long, Deren Li, Xiaoying Wang, and
Hua Liu. Airport detection based on a multiscale fusion feature for optical
remote sensing images. IEEE Geoscience and Remote Sensing Letters,
14(9):1469–1473, 2017.
[27] Yuelei Xu, Mingming Zhu, Shuai Li, Hongxiao Feng, Shiping Ma, and Jun
Che. End-to-end airport detection in remote sensing images combining
cascade region proposal networks and multi-threshold detection networks.
Remote Sensing, 10(10):1516, 2018.
[28] Yi Yang and Shawn Newsam. Bag-of-visual-words and spatial extensions
for land-use classification. In Proceedings of the 18th SIGSPATIAL inter-
national conference on advances in geographic information systems, pages
270–279, 2010.
[29] Ce Zhang, Isabel Sargent, Xin Pan, Huapeng Li, Andy Gardiner, Jonathon
Hare, and Peter M Atkinson. Joint deep learning for land cover and land
use classification. Remote sensing of environment, 221:173–187, 2019.
29You can also read

















































