A Statistical and Visual Exploration of the Surveillance, Epidemiology, and End Results (SEER) Database Using SAS
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
SEER Analysis
A Statistical and Visual Exploration of the Surveillance, Epidemiology, and
End Results (SEER) Database Using SAS
Christopher Yim, California Polytechnic State University San Luis Obispo, California
ABSTRACT
Studying the factors affecting the spread and trends of cancer has been a large focus in the medical field for
decades. The Surveillance, Epidemiology, and End Results (SEER) Program has collected detailed data on various
cancer diagnoses since 1973 and has recorded both epidemiological information as well as population statistics for
the United States. This preliminary investigation explores associations between patient characteristics and survival
outcomes for patients diagnosed with breast cancer. We take a look primarily at how country of birth and
race/ethnicity is associated with clinical characteristics such as stage, grade and recurrence. This paper presents
several statistical techniques including survival methods that are explored extensively with PROC LIFETEST and
PROC PHREG. In addition we will discuss the examination of the data visually and interpret the survival and hazard
rates of varying groups.
INTRODUCTION
The goals of this paper are twofold. First, to explore interesting associations found in the expansive SEER database
related to the patient characteristics of race/ethnicity and US versus foreign born. The second is examining outcomes
for these patient characteristics utilizing the survival methods in SAS with visual displays of the survival data. Some
basic understanding of survival analysis is needed to fully understand what was done. The focus of the research
paper only covers breast cancer incidences. Originally, the goal was to cover multiple types of research, but due to
time constraint the paper was refocused to only breast cancer. Breast cancer was chosen due to its prevalence in
research and the large number of incidences. An expert understanding of breast cancer or cancer in general is not
needed or expected for this paper.
METHODS
ABOUT THE DATA
The Surveillance, Epidemiology, and End Results (SEER) Program of the National Cancer Institute collects and
provides information on cancer statistics in order to help discover new and informative research on cancer. Currently
SEER’s database collects and publishes cancer incidence and survival data from population-based cancer registries
that cover approximately 28 percent of the US population. More information can be found at seer.cancer.gov.
VARIABLES OF INTEREST
For this research project, associations between clinical and patient characteristics were examined. The two main
patient characteristics of interest were the patient’s race/ethnicity and country of origin. For ethnicity, there were four
categories; Hispanic, White, Black and Other. In addition the NHIA (Hispanic, Non-Hispanic) variable was
incorporated to determine if patients were Hispanic and from there, the final variable for race/ethnicity was created.
For the other main variable of interest, country of origin was categorized as either US native or foreign born.
Associations between these two patient characteristics and certain clinical and patient characteristics were
individually assessed. Different patient characteristics were considered including insurance, marital status and age at
diagnosis. Age was included as it is a common covariate to investigate and an important adjustment in survival
analysis. Age was classified into meaningful age groups,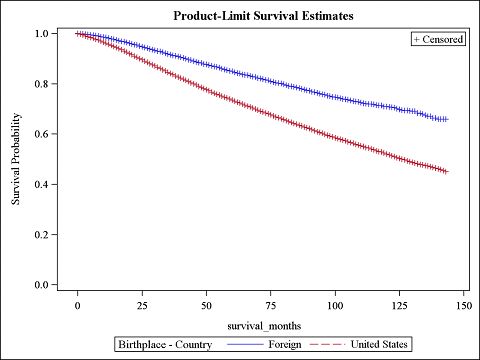
SEER Analysis
DATA PREPARATION
Before diving into the analysis, cohort exclusions and data cleaning were applied in order to properly utilize the data.
All 149 original variables were coded and read in as character data. Age of diagnosis and year of diagnosis were
converted to numeric variables for proper analysis of continuous data. For the breast cancer cases, a new data set
with only the variables of interest was created. The following exclusions were also applied. Because the SEER
database has so much detailed information on many patients, these exclusions allowed for consistency in the cohort.
This ensures that any associations discovered refer to only the population that are of interest.
Exclusion Steps Resulting Sample Size (Original N = 712,319)
Men 707,678
Diagnosed before year 2000 299,315
Did not have 0-IV stage cancer 284,485
Multiple Primaries 208,788
Younger than 18 or older than 90 207,023
Unknown radiation status, ethnicity or birthplace 75,213
No tumor size or an unknown tumor size 75,213
Bilateral or unknown laterality 74,813
Borderline estrogen receptor and progesterone receptor status 74,300
Those whose information came from a hospice, autopsy or 74,275
death certificate
No mastectomy or lumpectomy 68,053
Non-histologically confirmed diagnosis 67,918
Received neoadjuvant radiation 67,407
Table 1. List of Exclusions and the Resulting Sample Size
STATISTICAL METHODS
When attempting to find associations between two categorical variables, chi-squared test for independence evaluates
how likely it is that a difference between sets arose by chance. The null hypothesis states that the frequency
distribution in a sample should be the same as the theoretical distribution. Under the null, events are mutually
exclusive and have a total probability of 1. To determine if there is an association between two covariates, a simple
proc freq statement can be used with the following format
PROC FREQ DATA = BREASTCANCER;
TABLE VARIABLEA*VARIABLEB / CHISQ NOCOL NOPERCENT;
RUN;
The CHISQ option will request the chi-square test of independence based on the chi-square distribution. For this
simple analysis of measures of association, only the Pearson chi-square statistic was considered. Frequencies and
percentages across the main variables of interest were used to provide insight into which group had higher or lower
instance of any particular patient or clinical characteristic.
2SEER Analysis PRIMARY RESEARCH QUESTION: DESCRIPTIVE ASSOCIATIONS RESULTS The total sample size was 67,407. However, not all information was present for each patient, so the effective sample size varies across each test. For the simple descriptive statistics, US born versus Foreign born was considered as the main variable of interest. Table 2 displays all comparisons with birthplace. In addition associations between the secondary variable of race/ethnicity are shown in Table 3. Percentages are displayed as of column percents. Variable of Interest US Born N(%) Foreign N(%) P-value Marital Status
SEER Analysis Table 2 shows that all tests were significant. The percentage of married people born outside of the US (63.33%) was significantly higher than those born in the US (55.11%). The percentage of people born outside the US that has insurance (78.80%) is much lower however than those born in the US (90.95%). The percentage of people born outside of the US diagnosed at an age younger than 50 years (31.20%) is higher than those born inside the US (24.07%). The percentage of people born outside the US that were diagnosed with In Situ cancer (19.36%) was slightly higher than those born inside the US (16.78%). The percentage of people born outside the US that were diagnosed with grade I cancer (18.51%) was slightly lower than those born in the US (19.65%). The percentage of Her2+/HR+ patients born outside the US (14.39%) was higher than those born in the US (10.25%). The percentage of patients who took radiation born outside the US (60.66%) was higher than those born in the US (55.63%). Variable of Interest White N(%) Hispanic N(%) Black N(%) Other N(%) P-value Marital Status
SEER Analysis
Table 3 shows that again, all tests were significant. Each comparison was not individually tested, therefore only the
biggest difference between the three main races will be stated. The percentage of patients that are black and are
married (36.09%) is much lower than the percentage of married white patients (58.31%). The percentage of Hispanic
patients that have insurance (73.45%) is much lower than the percentage of white patient who have insurance
(92.88%). The percentage of white patients diagnosed at an age less than 50 (21.95%) is much lower than the
percentage of Hispanic patients (35.61%). The percentage of white patients diagnosed with Stage I cancer (39.60%)
is much higher than the percentage of black patients diagnosed with Stage 1 cancer (28.77%). The percentage of
white patients diagnosed with grade III cancer (35.27%) is much lower than black patients (50.60%). The percentage
of black patients that are triple negative (21.22%) is much higher than white patients (11.48%). The percentage of
Hispanic patients that had radiation treatment (59.96%) is higher than white patients (55.32%).
SECONDARY RESEARCH QUESTION: SURVIVAL ANALYSIS
The secondary focus was analyzing the time to death for different groups. As before, race/ethnicity and country of
origin are the two main factors to analyze. First, race/ethnicity was analyzed by itself and then country of origin by
itself. After that a model was created that took into consideration the other variables of interest in order to see how
race/ethnicity and country of origin were associated with survival.
STATISTICAL METHOD
In order to analyze the survival of different patients, two different procedures were used. The first procedure used
was PROC LIFETEST. This procedure uses the Kaplan-Meier method to estimate survival. For each patient there are
two different variables that are key in analyzing survival: The number of months from date of diagnosis to either date
of death, last contact or end of study, and whether or not the patient’s death was known. If a patient's death is
unknown, then they are considered to be right censored. The number of months is recorded in the variable
survival_months and the indicator variable censrec recorded whether or not the patient is right censored.
PROC LIFETEST DATA = SURVIVALSET;
TIME SURVIVAL_MONTHS*CENSREC(0);
STRATA ETHNICITY / TEST = LOGRANK ADJUST = SIDAK;
RUN;
The first line includes a specification of the dataset. The TIME statement includes the time to death/last contact
(months) and then the censoring variable. A value of 1 is coded if the patient dies and a value of 0 is coded if the
patient does not die during the time observed. 0 was put into the parentheses to indicate that this is the value used
for the censored patients. The STRATA statement is used to analyze the covariate of interest. To run tests on the
differences among the Kaplan-Meier curves, the log-rank test was used which can be done by specifying
TEST=LOGRANK as an option. If the covariate has multiple levels, the ADJUST=SIDAK option can be used to adjust
for multiple comparisons.
The second procedure used for analysis was PROC PHREG. This procedure was used due to its ability to test the
significance of continuous variables and create a model to test. This procedure uses the Cox Proportional Hazard
Model and with this model comes certain assumptions. The first is that linearity is satisfied between a covariate and
the Cox Proportional Hazards Model outcome and that over time hazard ratios are maintained. The following is an
example of the type of statement used.
PROC PHREG DATA = SURVIVALSET;
CLASS ETHNICITY (REF = ‘WHITE’) / PARAM = REF;
MODEL SURVIVAL_MONTHS*CENSREC(0) = ETHNICITY AGE
/ SELECTION = STEPWISE SLS = 0.05 SLE = 0.05;
ASSES VAR = (AGE) PH / RESAMPLE SEED 54321;
RUN;
The first line specifies the dataset that is desired. The CLASS statement names the categorical variables to be used
in the analysis. The PARAM = REF specifies that the parameterization method for the categorical variables use the
reference cell coding. After naming the variable, enclosed in parenthesis is the REF option which specifies the
reference level to be used in the parameterization. The next line uses the MODEL statement to determine which
variables to analyze. All covariates come after the equal sign in the MODEL statement. In order to select the
variables that are significant, one can use stepwise selection to create a model that includes all significant covariates.
In order to specify this, it is necessary to include SELECTION = STEPWISE. In addition, it is necessary to specify the
entry (SLE) and stay (SLS) criteria.
5SEER Analysis The ASSESS statement checks for issues with the two assumptions, linearity and proportional hazards. To check the linearity assumption, all continuous variables are put into parentheses after the VAR. To check the proportional hazard assumption, place PH in the ASSESS statement. The way to check for proportional hazards it to check the Martingale residuals. Using the RESAMPLE option produced p-values for the maximum residual. These plots are based on simulations using a random number generator, which you can set the SEED to any number in order to reproduce similar plots later. If linearity seems to be violated, an alternative is to code the quantitative variable as categorical. In addition, the ASSESS statement in PROC PHREG is very resource heavy and when the sample size is very large, SAS struggles with producing output. The research done for this paper utilized SAS Studio 3.1 University Edition, and as a result the assess statement could not be run. As an alternative, the Schoenfeld residuals were saved and then plotted for each variable of interest. If there is an obvious trend to the Schoenfeld residuals than there is evidence of lack of proportional hazard. RESULTS The first test looked at how country of origin was related with survival. The output is provided below. Figure 1. Kaplan-Meier Survival Curves for Country of Origin Test Chi-Square DF Pr>Chi-Square Log-Rank 700.3171 1
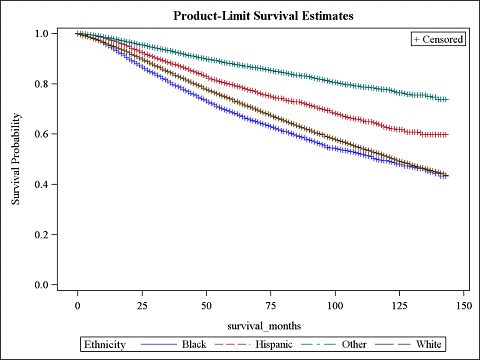
SEER Analysis The second test looked at the relationship between survival and country of origin. The output is provided below. Figure 2. Kaplan-Meier Survival Curves for Race/Ethnicity Test Chi-Square DF Pr>Chi-Square Log-Rank 1,214.2123 3
SEER Analysis Parameter Reference Pr>ChiSQ Hazard Ratio Standard Error 95% Confidence Interval Age 50-
SEER Analysis
DISCUSSION
The primary research tested associations related to the patient characteristics of race/ethnicity and US versus foreign
born. Even after adjusting for familywise error rate, every test produced significant results. This is not surprising
however as the sample size is very large. When looking at US born vs. foreign born, some interesting trends
appeared. The percentage of the population born in the United States diagnosed with breast cancer that are less than
50 years of age is lower than the percentage of the population born outside of the United States. In addition, the
percentage born in the United States that are older than 70 years of age is much higher than the percentage born
outside of the United States. This indicates that those born in the United States are diagnosed later on in life
compared to those born outside of the United States. This could be attributed to that people born outside of the
United States either develop breast cancer earlier or get check more frequently. Of those diagnosed with noninvasive
(In Situ) cancer, there are more patients that are not born in the US than what is expected. This may indicate that
those who are not born in the US get checked more often and are more proactive in finding out if they have breast
cancer, thus they are diagnosed with earlier stages of cancer. At the same time however, there is evidence that those
born outside the US are diagnosed at a much earlier age. It is hard to say which factor is contributes to this
phenomenon. The percentage of the population born in the United States that are triple negative is high than the
percentage of the population born outside of the United States. This suggests that those born outside of the United
States have a better genetic makeup and as a result have more treatment options than those born in the United
States.
Moving away from country of origin, some interesting associations between race/ethnicity and patient characteristics
were found. The percentage of white people who were diagnosed before age 50 is much lower than any other race.
In the same vein, the percentage of white people who were diagnosed after age 70 is much higher than any other
race. This could be that those who are white tend to develop breast cancer later in life, or that they get checked for
breast cancer later in life. The percentage of black people who were diagnosed with breast cancer that are married is
much lower than any other race, by a very large margin. No speculation has been made on why this is the case. The
percentage of white people that are diagnosed with In Situ cancer tends to be lower than any other race. However,
the percentage of white people that are diagnosed with stage I breast cancer is much higher than any other category.
This may indicate that those who are white do not get checked as much as other races when the cancer is
noninvasive, but do get it checked when it is at stage I. Another interesting observation that was found was that the
percentage of black people who are diagnosed with grade III is much higher than any other group. In addition, the
percentage of black people that are triple negative is much higher than any other group. It seems that those who are
black not only are diagnosed with grade III breast cancer much more than expected, but they also have less
treatment options.
From the secondary research question, some very interesting associations were found. The results of the log-rank
test provided a p-value of less than 0.0001, indicating that time to death is significantly associated with birthplace.
This is also confirmed with the Kaplan-Meier curves, as there is a lot of separation and no overlap between the two
curves. Based on this information, one can conclude that being born outside of the United States is associated with a
higher survival probability than those born in the United States. There are also significant results when testing
ethnicity and race. The p-value is less than 0.0001 for the entire test and for each individual comparison, even after
adjusting for the multiple tests. There is a lot of separation and very little overlap in the Kaplan-Meier curves. There is
evidence that those who are black are associated with having a lower survival probability than all other groups. Those
who are white have a higher survival probability that those who are black but lower than those who are Hispanic and
other races. Being Hispanic is associated with having a higher survival probability than both black and white people,
but a lower survival probability than other racial groups. The fact that those who are black have a lower probability is
not surprising based on the primary research. It was found that those who were black were associated with having a
higher percentage of grade III cancer and triple negative breast subtype by a large margin.
Lastly, the PROC PHREG model provides what might be considered the most insightful information. Due to the fact
that all hazard ratios are adjusted after taking into consideration the other variables, conclusions and speculations
can be made with less worry of it being due to some other effect. It is well known that the chance of survival
decreases the older a person is. As said before, the survival probability for black patients is lower than other races.
This could be due to the fact that black patients have higher percentages of triple negative patients, and thus have
less treatment options. It could also be due to the low marriage rates. We see that married patients have a higher
survival probability. This could be due to the emotional support that a family provides and the financial support a
spouse sometimes brings. Because black patients tend to be more single than other patients, their survival probability
could be lower. This could also be a contributing factor to the lower hazard that patients born outside the US have.
Patients born outside the US tend to be married more than patients born in the US. In the end, it is most likely a
mixture of cultural and genetic differences that effect survival probabilities in patients.
9SEER Analysis
CONCLUSION
Finding associations between patient and clinical characteristics can provide valuable information to better
understand cancer. This study provides a preliminary look at what is associated with different races and ethnicities. In
addition, the differences between being born in the United States and being born elsewhere might give us an idea of
how different cultures and lifestyles are related to clinical characteristics. The methods detailed in this paper are
somewhat simple in the grand scheme of statistics and is meant to only give a basic idea of different associations.
The next natural progression for research is to expand to other kinds of cancer and see how they compare.
REFERENCES
Surveillance, Epidemiology, and End Results (SEER) Program (www.seer.cancer.gov) Research Data (1973-2011),
National Cancer Institute, DCCPS, Surveillance Research Program, Surveillance Systems Branch, released April
2014, based on the November 2013 submission.
ACKNOWLEDGMENTS
A huge thank you to Rebecca Ottesen, my professor and mentor. This paper could not be possible without her
encouragement, guidance and wisdom. Thank you also to SEER, for allowing me to use their vast database to do my
research.
CONTACT INFORMATION
Your comments and questions are valued and encouraged. Contact the author at:
Name: Christopher Cune Yim
Address: 3345 Par Dr.
City, State ZIP: Oceanside, CA 92056
Phone: 760-716-7483
E-mail: yimcunechris@gmail.com
SAS and all other SAS Institute Inc. product or service names are registered trademarks or trademarks of SAS
Institute Inc. in the USA and other countries. ® indicates USA registration.
Other brand and product names are trademarks of their respective companies.
10You can also read

















































