A/b testing at Glassdoor - Vikas Sabnani @vsabnani
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

a/b testing at Glassdoor
Vikas Sabnani
Sr. Director, Data Science & Analytics
@vsabnani
We help people everywhere
find jobs and companies
they love
24M
members
19M
Unique visitors
7M
content
12M
jobs 2
Facebook
501 Reviews 97%
“Experience of a lifetime” 93% of employees recommend this company to a friend
Free Food, Smart Moving Fast, Long
Software Engineer in Menlo Park Pros
People, Move Fast
Cons
Hours, Free Food
Marketing Interview Question
“What are you least proud of on your resume?
Product Designer $124K
Based on 36 employee salaries
23M
members
18M
Unique visitors
6M
content
12M jobs 3
we’ll discuss + why test + types of a/b tests @ Glassdoor + conducting a test + learnings - dos & don’t’s

why test?
“The fascinating thing about intuition is that a fair percentage of the time it’s
fabulously, gloriously, achingly wrong”
John Quarto-von Tivadar, FutureNow
why test? because, on the internet, we can • We have a tendency to build a product for ourselves • Less time debating… more time building • Inspires us to think of wildly different ideas • Forces us to clearly define our goals & metrics • Kill HiPPO culture
why test?
lean startup model
experiments
assumptions metrics
types of A/B tests @ Glassdoor + Traditional split tests + Fake data tests + 404 tests + Fake HTML tests + ML weights tests


Traditional Split Tests
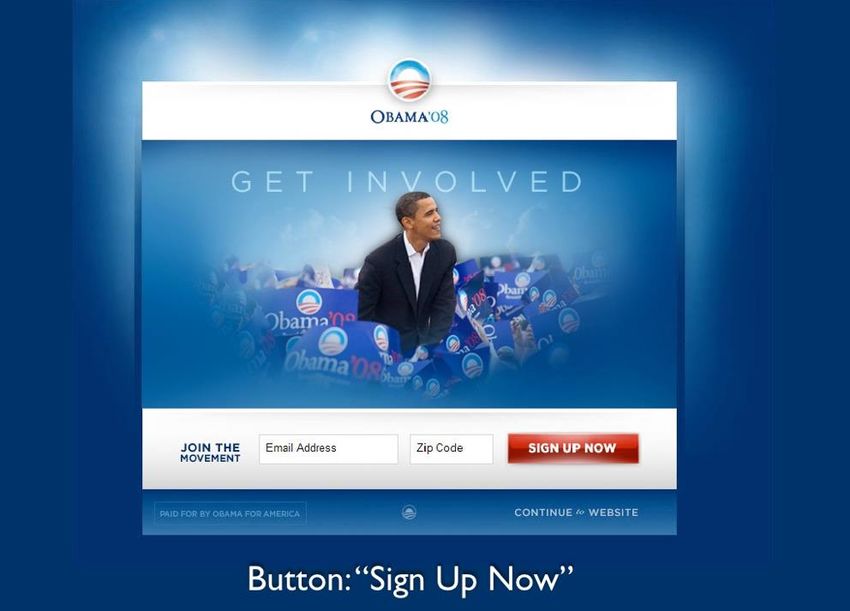
UI tweaks - examples and what we have learned Obama test
UI tweaks - examples and what we have learned Obama test
26
+4.5 % 27
-7 % 28
Split tests - what have we learnt
Sometimes, less is more
sign-up or sign-in to access your resume
-6 %Split tests - what have we learnt Links should look like links Sign up vs Sign up +5 % but be careful
Split tests - what have we learnt
users are extremely averse to losses
Be the first to get new jobs like these
vs
Do not miss new jobs like these +3 %split tests - what have we learnt
social proof is powerful
+22 %split tests - what have we learnt
social proof is powerful
-3 %split tests - what have we learnt free is totally different price point
split tests - what have we learnt colors don’t matter (generally) Google’s “41 shades of blue” Test
Fake Data Tests
should we build a real-time data stream?
Real time click activity
404 tests
404 tests
“a good way for a consumer facing, web-based business to
capture what your visitors really want is to run a live test
with a non-working link”
Stephen Kaufer, CEO, TripAdvisor
40404 tests are great for small feature ideas
View results on a map
41Fake HTML Tests
Fake HTML tests
“If you clicked on a 42Floors ad for new york office space a while
back, there’s an 89% chance that you landed on one of these eight
versions of the site.
They’re all fake: just throwaway static HTML mockups”
http://blog.42floors.com/we-test-fake-versions-of-our-site/
4342 floors tried wildly different variations
4445
46
Site redesigns are hard to test
• Very expensive to code and maintain different variants of the site
• Limits number of variations we can test
• Cannot control for consistency in user experience
• SEO implications are hard to predict and impossible to test
47what we did
1. Made several variations of radically different concepts. Created
mockups - translate to static HTMLs (with real data)
2. Choose 2 pages to focus on - Overview & Salaries page
3. Select a single metric to assess performance - bounce rates
4. Iterate on winning version through traditional Split tests - to be
launched
48Learning ML weights thru’ testing
Traditional ML systems
X
data
cleansing
SiteLogs
Site Logs Training Data
Site Logs
v, B
x, e
Machine
Learning
y_hat
Estimator
y = f(x, v, B)
ML
ML“models”
“models”
Predictive ML models
Structure &&
Model Structure
(Structure &
weights
weights
weights)
50Traditional ML systems
Feature extraction, model Tuning &
Data extraction & cleansing
training learning
~ 50% ~ 40% ~ 10%
1. Site data is messy and imperfect. Make best assumptions of
user behavior
2. Site data is biased; and we cannot simulate a lab environment at
scale. Focus on de-biasing
3. Significant effort spend on estimating the best model structure.
And then on training weights
4. Constantly learning through prediction errorAn alternative ML system
Site data is imperfect Start with a good enough data- set
Fine. We’ll test & measure in the
Site data is biased
same environment
Parameters are more important
Focus on estimating the best than model structure. Start with a
model structure and parameters
flexible structure. Estimate initial
parameters
Constant learning through re- Constantly A/B test parameters
fitting and learn through MAB
Maximize Revenue or Conversion
Minimize Prediction Error
on SiteA reduced ML system
X
data
cleansing
SiteLogs
Site Logs Training Data
Site Logs
v, B
Machine
y_hat, B
Learning
Estimator
y = f(x, v, B)
ML
ML“models”
“models”
Predictive ML models
Structure &&
Model Structure
(Structure &
weights
weights
weights)
53A reduced ML system
Data extraction & Feature extraction, Tuning &
Data extraction & cleansing Feature extraction, Tuning
model & learning
training
cleansing model training learning
performance
learning / tuning
data cleansing
data cleansing
timetypes of A/B tests @ Glassdoor + Traditional split tests + Fake data tests + 404 tests + Fake HTML tests + ML weights tests
So…
a/b testing can do
just about
anything, but
don’t make a mess
of itofcourse there are skeptics…
“The ultimate outcome
of all A/B tests is
porn”
- someone on twitterwhat’s an A/B test
A/B testing at high level
Site
traffic
Control (A) Test (B)
Instrumentation
& tracking
Analyze
ResultsAnalyzing results
Control ~ N(2.0%, 0.2%, c)
mean = 2.0%
1s
16%
Stdev = 0.2%
2s
2.5% 2.5%Analyzing results
Control ~ N(2.0%, 0.2%, 1000)
mean = 2.0% 2.1% Test ~ N(2.1%, 0.2%, 1000)
Stdev = 0.2% 0.2%Analyzing results + Difference in Mean 2.1% - 2.0% = 0.1% “The expected improvement from Test treatment is 0.1% points” + Stdev of the difference sqrt(sc2 + st2) = sqrt(0.22 + 0.22) = 0.282% “The difference of 0.1% is within 1-s deviation of the mean. So, it is not statistically significant” + For most site metrics, the decision variable is a Bernoulli (ex. Did the user buy? Did the user bounce?). For large n - a Bernoulli variable follows a Normal distribution + Mean of a Bernoulli distribution (m) = simple average + Stdev (s) = sqrt(m*(1-m)/n)
conducting a test
Conducting a Test
1. Clearly state your hypotheses
ex. “By adding this feature, we expect conversions to improve & user
experience to not be worse”
64Conducting a test
2. State your metrics and goals
metrics -
“this should generally be “desired action” / input”
conversion = purchases / users
user experience = ??
goals -
“what is the minimum improvement you’d like to see to make this worth building and testing”
improve conversion by 5%
65Conducting a test
3. Define granularity of analysis
Ex. we’ll break results by country or by new vs repeat
“The more we slice and dice, the more data we need to collect”
66Conducting a test
4. Define a
a = probability that you will incorrectly adopt the test treatment
Choice of a depends on -
(a) how much impact would an incorrect choice have on the business
(b) how difficult it is to find a good alternative
(c) How many test variants you will run
67Conducting a test
4. a - how difficult is it to find a good alternative?
100 # of tests conducted
Experiments with a truly
20 80
good test variant
What we’ll conclude 18 2 72 8
“~30% (8/26) of treatments we’ll adopt in production will be bad”
68Conducting a test
4. a - how many variants are you testing?
Assuming none of them is any better than control
P (test-1 wins) = 5%
P (test-2 wins) = 5%
P (one of them wins) = 1 - P (none wins) = 1- 0.95 * 0.95 = 9.75%
“There’s almost a 2x chance that we’ll replace Control with one of the Test
treatments”
With 5 variants 23% chance of type-1 error
With 40 variants 87% type-1 error
69Conducting a test
5. Determine your test duration
What segments do you want to exclude? US only; Organic only
What % of traffic do you want to include? 20%
What is the baseline Conversion rate? 2.5%
What is the minimum improvement you’d like to see? 3%
How confident do you want to be before rejecting the Control treatment? 95%
How many treatments will you run? 5
70now… things to do and not
do - read results correctly
Control Test-1 Test-2
# Visitors 100,000 100,000 100,000
# transactions 2,000 2,200 2,080
Conversion rate 2.00% 2.20% 2.08%
est. s 0.044% 0.046% 0.045%
conv increase 0.2% 0.08%
P (test > control) 99.9%* 89.7%
We can say -
+ We are more than 95% confident that Test-1 is better than Control
+ We are not 95% confident that Test-2 is better than Control
+ We are only 50% confident that Test-1 will increase conv by 0.1% points
+ Our 50/50 estimate from adopting Test-1 is a 0.1% point improvement
72do - run the test for its full duration
Once you decide the duration upfront, let the test run its full
course
+ there is lots of noise up-front
+ chances are not all segments of population have been properly
represented
73do - run the test for its full duration
Random draws from a black-jack game {P (win) = 48.5%}
Wait, we did it!
Kill it! Oh no, its down again!
74do - be wary of tests that degrade over time
Results from an A/A test
A large majority of tests eventually regress to the mean
Significant?
75do not - change treatment sizes midway
Changing bucket sizes midway changes behavior of the test
100 # of users
Test Bucket 20 80 Regular green Glassdoor
new
WOW – Light Green is so much better. Let’s bump it to 50%
repeat repeat
4 16
40 40
Test 4 + 40 = 44 users 4 repeat users (~ 9% of total)
RG 8 + 40 = 48 users 16 repeat users (~ 29% of total) 76do not - slice and dice data to find winners
Stick to the grain you defined upfront. If you do find a
grain that “appears” to win - retest at that level
77we’ll discuss + why test + types of a/b tests @ Glassdoor + conducting a test + learnings - dos & don’t’s
what a/b testing isn’t
• AB testing is not a substitute for basic research or user testing. It
perfects it
• Testing does not define strategy or direction. It helps get there
faster and more efficiently
• AB testing does not replace ignorance. It replaces ambiguity
• An excuse to test everything. Be curious, not indecisive
• Not a tool to piss off users
79darwin - our internal A/B test framework
Java based framework
• Population Selection
• Treatment Allocation - Ensures stickiness, unbiased
randomization, ramp-up & down
• Multivariate testing and independent experiments
• Bootstrapping & Logging through Google Analytics
80Vikas Sabnani
@vsabnani
www.glassdoor.com/careersYou can also read

















































