TURNER: The Uncertainty-based Retrieval Framework for Chinese NER
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
TURNER: The Uncertainty-based Retrieval Framework for Chinese NER
Zhichao Geng , Hang Yan , Zhangyue Yin , Chenxin An , Xipeng Qiu∗ , Xuanjing Huang
School of Computer Science, Fudan University
Key Laboratory of Intelligent Information Processing, Fudan University
{zcgeng20,hyan19,xpqiu,xjhuang}@fudan.edu.cn
arXiv:2202.09022v1 [cs.CL] 18 Feb 2022
Abstract
Chinese NER is a difficult undertaking due to
the ambiguity of Chinese characters and the ab-
sence of word boundaries. Previous work on Chi-
nese NER focus on lexicon-based methods to in-
troduce boundary information and reduce out-of-
vocabulary (OOV) cases during prediction. How-
ever, it is expensive to obtain and dynamically
maintain high-quality lexicons in specific domains,
which motivates us to utilize more general knowl-
edge resources, e.g., search engines. In this pa-
per, we propose TURNER: The Uncertainty-based
Retrieval framework for Chinese NER. The idea
behind TURNER is to imitate human behavior:
we frequently retrieve auxiliary knowledge as as-
sistance when encountering an unknown or uncer-
tain entity. To improve the efficiency and effec-
tiveness of retrieval, we first propose two types
of uncertainty sampling methods for selecting the
most ambiguous entity-level uncertain components
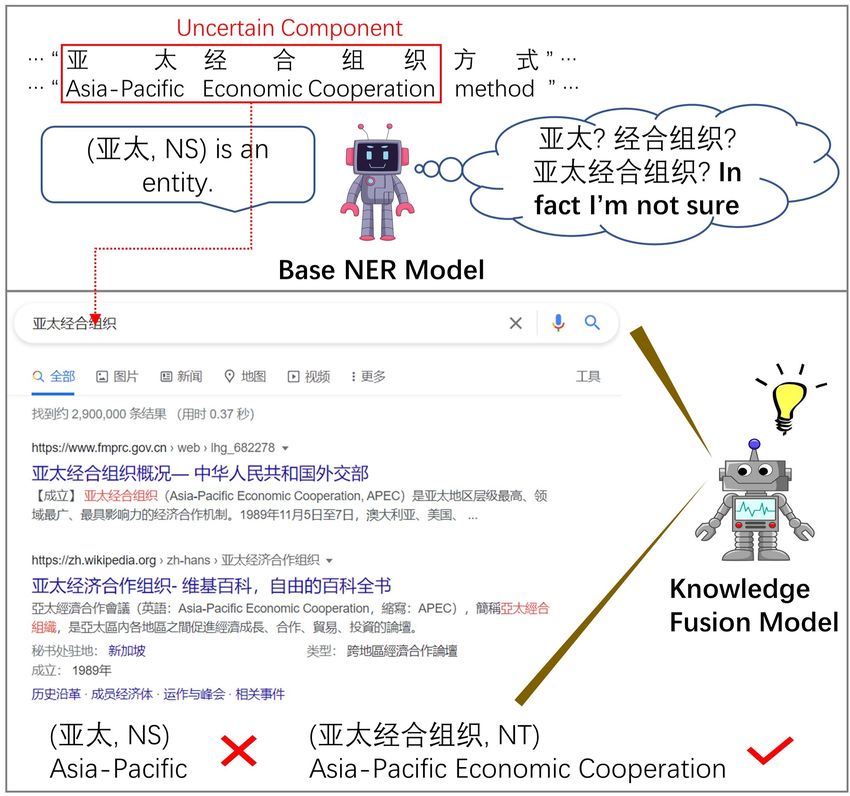
of the input text. Then, the Knowledge Fusion Figure 1: A case of our Uncertainty-based Retrieval framework. The
Model re-predict the uncertain samples by com- base NER model identifies "Asia-Pacific" as an NS entity, but it is
bining retrieved knowledge. Experiments on four uncertain whether "Asia-Pacific Economic Cooperation" is an NT
benchmark datasets demonstrate TURNER’s effec- entity. The Knowledge Fusion Model accurately predicts by retriev-
tiveness. TURNER outperforms existing lexicon- ing knowledge using the query "Asia-Pacific Economic Coopera-
based approaches and achieves the new SOTA. tion" with the search engine.
1 Introduction incorporating the matched items’ boundary and semantic in-
Named Entity Recognition (NER) plays an essential part in formation into the model via a variety of methods. However,
natural language processing. The performance of the NER the lexicon-based approaches have several drawbacks. First,
task has improved dramatically as a result of the recent ad- model performance is highly dependent on the quality of the
vances in deep learning and pre-trained models. In compar- lexicon, yet obtaining and dynamically maintaining a high-
ison to English NER, Chinese NER is more challenging due quality lexicon in a particular application scenario is costly.
to the character ambiguity and absence of word boundaries. Second, existing methods are incapable of utilizing dynam-
ically changing lexicons while introducing semantic knowl-
In recent years, lexicon-based approaches have dominated
edge and vice versa. A line of previous work [Li et al., 2020;
the Chinese NER field [Zhang and Yang, 2018; Li et al.,
Liu et al., 2021] utilizes word embeddings to represent
2020; Liu et al., 2021; Wang et al., 2021a]. Due to their
matched items, but updating the lexicon requires retraining
ability to reduce OOV occurrence during prediction, lexicon-
the model. Another tributary of previous work [Wang et al.,
based approaches have become the necessary element for ob-
2021a] leverages only the word boundary information, which
taining SOTA results in Chinese NER. These approaches be-
enables the usage of a dynamically updated lexicon, but this
gin by matching the input sentence with the lexicon and then
method discards the semantic information of words.
∗
Corresponding author Considering the limits of lexicon-based methods, retrieval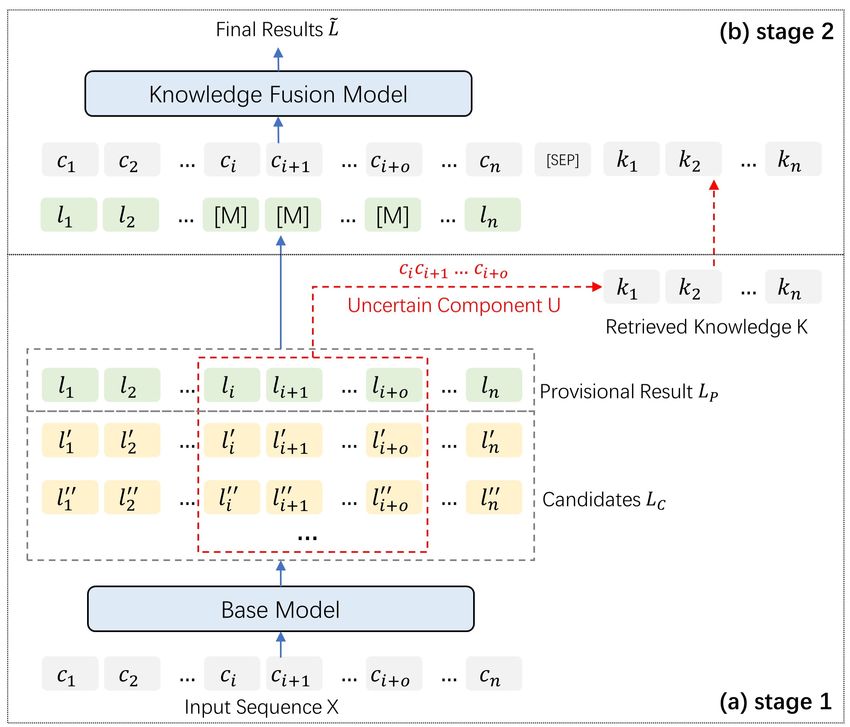
methods, e.g. retrieving with search engines, are more 2.2 Retrieval Methods for Neural Models
generic resources of of knowledge in the NER task. The Retrieving knowledge from the database to enhance neural
retrieved knowledge can help eliminate ambiguity in the in- models has been applied in several NLP tasks [Qiu et al.,
put text and enhance performance. Additionally, the re- 2014; Hashimoto et al., 2018; Gu et al., 2018]. They ei-
trieved knowledge is presented as text, allowing the query- ther use the retrieved text to guide the generation process
knowledge base to be dynamically updated. However, exist- or expand the training set automatically. In the NER task,
ing retrieval methods [Torisawa and others, 2007; Wang et al., some works introduce knowledge from the knowledge graph
2021b] in the NER task retrieve the knowledge using traversal or Wikipedia [Torisawa and others, 2007; He et al., 2020].
strategies, which is inefficient, especially in the case of on- They retrieve knowledge by traversing matches all possible
line retrieval. Moreover, existing pre-trained models are suf- sub-sequences, then encode the knowledge to incorporate
ficiently powerful to handle the majority of NER cases. Re- it into the model. Wang [2021b] chunk the sentence into
trieving knowledge for simple samples that the model could sub-sentences based on punctuation, then utilizes the sub-
have dealt with correctly is ineffective. sentences as queries in the search engine to retrieve external
We notice that in Chinese NER, the model can produce context. The knowledge is chosen from the retrieved items
diverse predictions about some input components, i.e., the that have the highest association with the original text.
model is uncertain about these components. Furthermore,
our statistics demonstrate that the uncertain components are 2.3 Uncertainty
the bottleneck of performance. Therefore, retrieving knowl- The predictive result in the classification task can be uncer-
edge for the uncertain components can provide the maxi- tain even with a high softmax output [Gal and Ghahramani,
mum support for the prediction. In this paper, we propose 2016]. Monte-Carlo Dropout [Gal and Ghahramani, 2016]
TURNER: The Uncertainty Retrieval framework for Chinese (MC Dropout), a Bayesian approximation of the Gaussian
NER. By leveraging Monte-Carlo Dropout [Gal and Ghahra- process, is a general approach to estimate uncertainty. MC
mani, 2016] or parsing the top-K label sequences predicted Dropout keeps dropout active in the prediction phase and
by the base NER model, we can obtain the entity-level un- evaluates the uncertainty according to the difference of sev-
certain components with a high degree of complexity and eral forward passes. In the sequence labeling task, Gui [2020]
uncertainty for the base NER model. Then by querying on employ MC Dropout to create draft labels and locate the un-
the uncertain components, knowledge can be retrieved ef- certain labels. Furthermore, they utilize two-stream attention
ficiently and effectively, eliminating uncertainty, as shown to model long-term dependencies between draft labels and re-
in Figure 1. Afterward, the Knowledge Fusion Model re- fine them, thereby getting rid of Viterbi decoding.
predicts the uncertain samples by integrating the original in-
put text, the retrieved knowledge, and the output of the base 3 Approach
NER model. We conduct experiments on 4 Chinese NER
In this section, we will first introduce our uncertainty sam-
datasets to evaluate the effectiveness of our method. The re-
pling methods for sequence labeling NER models, followed
sults illustrate TURNER significantly outperforms the base
by our framework for Chinese NER utilizing the uncertainty.
NER model on all datasets, boosting the F1 score by 1.1 on
average. TURNER also outperforms existing lexicon-based 3.1 Uncertainty Sampling and Retrieving
methods on Chinese NER, achieving new SOTA results. To
Sampling Method
the best of our knowledge, we are the first to combine uncer-
tainty sampling and retrieval methods in the NER task. MC Dropout MC Dropout [Gal and Ghahramani, 2016] is
a general approach to obtain the uncertain components. Given
an input sequence for the sequence labeling NER model, we
first obtain the model’s prediction as the provisional result.
2 Related Work and Background Then, we utilize MC dropout to keep dropout active and gen-
erate K candidate label sequences with Viterbi decoding in
2.1 Chinese Named Entity Recognition K forward passes. As illustrated in Table 1, the difference
between the predicted entity set of each candidate label se-
With the advent of deep learning, neural networks have be- quence and the provisional result can be considered uncertain
come a dominant solution to the NER task [Ma and Hovy, entities as the model predict them under mild perturbation.
2016]. In recent years, lexicon-based methods have become The uncertain components can then be obtained by merg-
widespread for Chinese NER. Zhang and Yang [2018] pro- ing all adjacent and overlapping uncertain entities. We sam-
pose lattice LSTM to encode both lexicon information and ple uncertain entities rather than position-level labels because
character information. Li [2020] propose the Flat-Lattice querying at the entity level improves retrieval precision.
Transformer as a way to incorporate lexicon information Top-K Label Sequences MC dropout demands more GPU
into the transformer model without any loss of information. resources as it requires multiple forward passes. As a re-
Liu [2021] make use of the BERT Adapter [Houlsby et al., sult, we also give an alternative strategy for sampling uncer-
2019] to introduce lexicon information to the bottom layers tainty in NER tasks. Given the label probability distribution
of BERT. Wang [2021a] propose DyLex, which utilizes only of an input sequence, we can obtain K legal label sequences
the boundary information of words, allowing models to use with top-K scores based on the variant of the Viterbi algo-
dynamically updating lexicons. rithm [Brown and Golod, 2010]. Previous works rerank the" Asia-Pacific Economic Cooperation method "
Predicted Entities
" 亚 太 经 合 组 织 方 式 "
Provisional Result O B-NS E-NS O O O O O O O (亚太,NS)
Candidate 1 O B-NS E-NS B-NT I-NT I-NT E-NT O O O (亚太, NS), (经合组织, NT)
Candidate 2 O B-NS E-NS O O O O O O O (亚太,NS)
Candidate 3 O B-NT I-NT I-NT I-NT I-NT E-NT O O O (亚太经合组织, NT)
Candidate 4 O B-NS E-NS O O B-NT E-NT O O O (亚太,NS), (组织, NT)
Uncertain Entities: 亚太, 经合组织, 亚太经合组织, 组织 Uncertain Component: 亚太经合组织
Table 1: An example of obtaining the uncertain component of an input sequence. The top part shows the input sequence. The middle part
lists the candidate label sequences and correlated predicted entities. The bottom part contains uncertain entities and the uncertain component.
The candidate label sequences can be obtained from MC Dropout or Top-K label sequences.
top-K label sequences to enhance the performance [Yang et tween ACCcertain and ACCuncertain reveals that the uncer-
al., 2017], but we can also sample the uncertainty from these tain components are real hard samples and become bottle-
sequences. We adopt the top-1 label sequence as the provi- necks for performance. Therefore, by querying about uncer-
sional result and other label sequences as the candidate label tain components, the desired knowledge can be retrieved effi-
sequences. Afterward, we can sample the uncertainty as de- ciently and effectively. Additionally, the proportion of uncer-
scribed before. Additionally, we observe that when the model tain components is inversely proportional to the model’s per-
is highly confident about the prediction, the difference be- formance across datasets, and the number of retrievals is sig-
tween the prediction result and the top-K label sequences is nificantly less than the number of test samples in all datasets.
minor, such as altering a single O label to an S type label.
Retrieving
Because this will minimize the loss of scores when there is
no competing entity in candidates. Therefore, we filter out The search engine is a general resource for acquiring supple-
candidates that differ in a only single position from the provi- mental knowledge for the uncertain components. By query-
sional result to minimize the retrieval times, considering most ing the search engine, we can obtain the context related to
Chinese entity names are longer than one character. the uncertain components as auxiliary knowledge to sup-
port the prediction. Similarly, if available, we can also re-
Preliminary Results trieve knowledge offline from the in-domain encyclopedias or
To verify the importance of the uncertainty components, knowledge graphs using retrieval algorithms such as BM25.
we conduct an investigation on the test set of four bench- When search engines are adopted, the cost of retrieval can
mark Chinese NER datasets utilizing BERT as the base NER be significant. However, for a particular application scenario,
model.1 We generate eight candidate label sequences using the distribution of entities is usually concentrated. Therefore,
MC Dropout, and the results are shown in Table 2. as more query-knowledge pairs are collected, the number of
new requests will continue to decrease.
MSRA Onto Weibo Resume 3.2 Framework
F1 Score 95.92 81.54 70.11 95.78 In this part, we will present the architecture of TURNER. As
Oracle F1 98.09 88.21 81.20 97.50 illustrated in Figure 2, TURNER solves the uncertain compo-
ACCuncertain 69.51 58.02 51.08 50.93 nents via a two-stage pipeline. We employ a base NER model
ACCcertain 99.69 98.12 98.01 98.64 to acquire provisional results and uncertain components in the
Avg UC Num 0.089 0.345 0.507 0.111 first stage and another Knowledge Fusion Model to re-predict
Avg UC Length 4.48 3.74 3.03 11.1 the uncertain samples with retrieved knowledge in the second
stage. The parameters of the Knowledge Fusion Model and
Table 2: The statistical results of the uncertain components. "F1 the base NER model are independent of each other.
Score" denotes the F1 score of the base NER model on the test
Stage One: Provisional Result and Uncertainty Sampling
dataset. "Oracle F1" denotes the F1 score obtained by the base NER
model when all uncertain labels are corrected. "ACCuncertain " and In the first stage, we use a base NER model to predict on the
"ACCcertain " denote the position-wise label accuracy of the predic- input sequence to get provisional results and uncertain com-
tion results for the uncertain components and the confident compo- ponents. The base NER model can be any sequence labeling
nents, respectively. "Avg UC Num" denotes the average number of NER model, such as BERT+MLP.
uncertain components in each input sequence. "Avg UC Length" Formally, given input sequence X = [c1 , c2 , ..., cn ], we
denotes the average number of tokens in each uncertain component. apply the base NER model to obtain the provisional results
LP and candidate label sequences LC with dropout active.
The base NER model obtains high oracle F1 scores indi- If there is no uncertain component in all candidates, the
cating that it possesses considerable promise. Even while base NER model is highly confident about the current sam-
the base NER model achieves an impressive level of accu- ple, then LP is the final result. Otherwise, we take LP as
racy on the confident components, the significant gap be- the provisional result and obtain the uncertain component
U = [ci , ci+1 , ..., ci+o ] using the method in Section 3.1. Af-
1
More details of our settings can be found in Section 4. terward, we can utilize U as query to retrieve the knowl-where label embedding and character embedding are train-
able parameters. The self-attention mechanism ensures that
all information is fully integrated and the knowledge is effi-
ciently utilized. Ultimately, we decode D̃ using the Viterbi
algorithm to obtain the final result L̃. If there are multiple un-
certain components in one input sequence, we process them
separately in the second stage and sum all obtained D̃ before
Viterbi decoding.
3.3 Training of TURNER
Since the parameters of the base NER model and the Knowl-
edge Fusion Model are independent, the two-stage training
procedure can be undertaken independently. The training of
the base NER model is trivial, and we will focus on the train-
ing of the Knowledge Fusion Model.
To minimize the gap between training and prediction, the
uncertainty of training data must be sampled. Therefore, we
conduct N-fold jackknifing to divide the training data into N
equal parts. In each step, we train the base NER model with
Figure 2: The architecture of TURNER. (a) The base NER model N-1 pieces of data and then use the base NER model to sam-
makes predictions on the input sequence. This enables TURNER ple uncertainty for the remaining one piece of data. Addi-
to identify uncertain components and then retrieve pertinent knowl-
edge. (b) The Knowledge Fusion Model produces predictions based
tionally, we conduct data augmentation by leveraging various
on the retrieved knowledge and the provisional result. checkpoints of the base NER model when generating training
data for the second stage. For a given training sample, we ap-
pend the sampled components of all checkpoints sequentially
edge text K = [k1 , k2 , ..., km ]. If there are multiple non- and discard the components that are significantly overlapped
continuous uncertain components in one input sequence, we with existing uncertain components.
retrieve the knowledge separately and process them indepen- However, the data augmentation strategy will result in the
dently in stage two. repetition of some training samples, which may lead to over-
fitting on several input sequences. Therefore, we introduce
Stage Two: Knowledge Fusion Prediction
the position-wised weighted average for the cross-entropy
In the second stage, We employ K as auxiliary knowledge to loss. By decreasing the weight assigned to the confident com-
re-predict the sample with uncertain component U using the ponent, the model can concentrate on the uncertain compo-
Transformer-based Knowledge Fusion Model. To introduce nents rather than overfitting the simple cases. Formally, We
the retrieved knowledge without losing any information, we calculate the loss L as follows:
concatenate K behind X to obtain the knowledge-enhanced
input sequence X̃ = [c1 , c2 , ..., cn , [SEP ], k1 , k2 , ..., km ]. 1 if ci ∈ U
λi = , (6)
Considering the base NER model’s excellent accuracy in α if ci ∈
/U
the confident components, we incorporate the label informa- P1≤i≤n
tion of the provisional result to support the Knowledge Fusion ·λi · lossi
L = i P1≤i≤n , (7)
Model. To avoid confusion or misleading, we mask the un- i ·λi
certain labels in the provisional result and obtain the modified
where λi is the weight coefficient at position i; lossi is the
provisional result L˜P as follows: cross-entropy loss at position i; α is a hyper parameter ranges
li if i ≤ n and ci ∈ /U [0, 1]. And we do not calculate loss for the knowledge text.
l˜i = [mask] if ci ∈ U , (1)
4 Experiments
[pad] if i > n
We conduct comprehensive experiments to evaluate the ef-
˜ ˜ ˜ ˜ ˜ , ..., ln+m+1
LP = [l1 , l2 , ...ln , ln+1 ˜ ], (2) fectiveness of TURNER. We use the BIESO label set and
employ the standard F1-score as the evaluation metric. All
where li is the i-th label of the provisional result and l˜i is the experiments are conducted on 8 GeForce RTX 3090.
i-th label in L˜P . Afterward, we incorporate X̃ and L˜P us-
ing the Transformer-based Knowledge Fusion Model to ob- 4.1 Datasets
tain the knowledge-enhanced probability distribution D̃: We conduct experiments on four benchmark Chinese NER
datasets to evaluate TURNER, including MSRA [Levow,
HL˜P = Label Embedding(L˜P ), (3) 2006], Ontonotes 4.0 [Weischedel et al., 2011], Re-
HX̃ = Character Embedding(X̃), (4) sume [Zhang and Yang, 2018] and Weibo [Peng and Dredze,
2015]. MSRA and Ontonotes are annotated using data from
D̃ = Transformer Encoder(HL˜P + HX̃ ), (5) the news domain; Weibo is annotated from the Internet blogs;Resume is annotated from the resumes. We follow the MSRA Ontonotes Weibo Resume
same train, dev, test split of the official version and previ-
ous work [Li et al., 2020]. The statistical information of each BiLSTM+CRF 91.87 71.81 56.75 94.41
dataset is shown in Table 3. TENER 93.01 72.82 58.39 95.25
ERNIE 94.82 77.65 67.96 95.08
Type Train Validation Test Lattice-LSTM 93.18 73.88 58.79 94.46
FLAT+BERT 96.09 81.82 68.55 95.86
Size 46364 - 43.65
MSRA LEBERT 95.7 82.08 70.75 96.08
Lengthavg 46.8 - 39.5
DyLex+BERT 96.49 81.48 71.12 95.99
Size 15724 4301 4346
Ontonotes BERT Baseline 95.91 81.54 70.10 95.78
Lengthavg 31.3 46.6 47.9 TURNERMC 96.85 83.56 70.78 96.36
Size 1350 270 270 TURNERTop-K 96.54 83.91 71.22 96.36
Weibo
Lengthavg 54.7 53.7 55
Table 4: The overall performance of TURNER. "BERT Baseline"
Size 3821 463 477 is the base NER model we utilize in the 1-st stage. "TURNERM C "
Resume
Lengthavg 32.5 30 31.7 and "TURNERT op−K " denote TURNER sampling uncertainty with
MC Dropout or Top-K label sequences, respectively.
Table 3: Dataset statistics. "Size" denotes the number of samples in
the sub-set. "Lengthavg " denotes the average length of samples.
2021], DyLex+BERT [Wang et al., 2021a]. In the bottom
part, we show the performance of TURNER with two un-
certainty sampling methods. The results demonstrate that
4.2 Settings TURNER significantly enhances the base NER model’s per-
Models and Training We implement a strong base NER formance, boosting the average F1 score by 1.1 with both two
model using BERT2 +MLP in the first stage of TURNER. uncertainty sampling methods and achieving new SOTA re-
We do not use CRF because we observe that the same per- sults. Although lexicon-based baselines are obviously supe-
formance can be obtained by relying just on the Viterbi al- rior to lexicon-free baselines, TURNER outperforms existing
gorithm to constrain that there is no illegal transition in the lexicon-based methods in each dataset, proving the potential
predictive result. The Knowledge Fusion Model is also ini- of lexicon-free methods in Chinese NER.
tialized using BERT. We search the learning rate in {2e-5, TURNER makes more substantial advancements in MSRA
3e-5} and the weight coefficient α in {0.1, 1}, and other hy- and Ontonotes, which belong to the news domain, because
perparameters we used are listed in Appendix A. We use the entities referenced in the news are more likely to be retrieved
validation set to select the best checkpoint and report its per- by search engines. The improvement on Weibo is relatively
formance on the test set. limited, as many entities are usernames or nicknames, mak-
ing it more challenging to retrieve related information using
Uncertainty and Retrieval During prediction, We gener-
the search engine. It can be inferred that the effectiveness
ate eight candidates for MC Dropout and four candidates for
of TURNER is directly proportional to the relevance of the
the top-K method. To generate training data for the second
retrieved knowledge.
stage of TURNER, we use MC Dropout for uncertainty sam-
pling. The statistical results of the uncertainty sampling on
4.4 Ablation Study
four datasets are listed in Appendix B. For retrieving, we use
Baidu, which is a widely used Chinese search engine. We We conduct ablation experiments to verify the contribution
prioritize the retrieved items belonging to the encyclopedia of each component of TURNER. The settings of the abla-
category and do not change the order of other retrieved items. tion experiment are shown as follows: (a) W/o retrieve:
Furthermore, each retrieved item is limited to a title and up We do not retrieve knowledge for the uncertain components,
to 50 characters of content, and all items are concatenated in i.e., the input for the Knowledge Fusion Model X̃ equals X.
order. The retrieved knowledge is limited to 400 characters. (b) W/o uncertainty: We abandon the two-stage architec-
ture and do not sample the uncertainty. As a result, we use
4.3 Overall Performance sentence-level queries to retrieve knowledge for each sam-
Table 4 shows the overall performance of TURNER in four ple like Wang[2021b]. The knowledge is also concatenated
benchmark datasets of Chinese NER. In the top part of ta- behind the original input text. (c) W/o LE: We do not use
ble we show the performance of lexicon-free baselines, in- the label embedding to provide the provisional results to the
cluding BiLSTM+CRF [Huang et al., 2015], TENER [Yan Knowledge Fusion Model. (c) W/o WL: We use the un-
et al., 2019] and ERNIE [Sun et al., 2019]. In the sec- weighted average method to calculate the loss for the Knowl-
ond part of table we provide several latest strong lexicon- edge Fusion Model, which is equivalent to setting α to 1.
based baselines, including Lattice-LSTM [Zhang and Yang, As shown in Table 5, the two-stage uncertain samples re-
2018], FLAT+BERT [Li et al., 2020], LEBERT [Liu et al., predicting architecture can be regarded as a particular way
of model ensembling, which can boost the performance a
2
https://huggingface.co/hfl/chinese-bert-wwm bit without knowledge. Without uncertainty sampling, theMSRA Ontonotes Weibo Resume the uncertainty sampling process: (a) SAR: since most candi-
dates are duplicate and will be filtered out, we use Sampling
TURNERMC 96.85 83.56 70.78 96.36
Acceptance Ratio (SAR) to denote the ratio of candidates that
w/o retrieve 96.33 81.93 70.15 96.11 can be utilized in uncertainty sampling rather than being fil-
w/o uncertainty 95.85 82.45 70.27 95.87 tered out; (b) VSR: we use Valuable Sampling Ratio (VSR) to
w/o LE 96.70 82.72 69.8 96.0 denote the ratio of candidates that yield a better F1 score than
w/o WL 96.85 82.60 70.78 96.30 the provisional results after the filter. The higher the VSR,
the better the uncertainty sampling recall ability. And the
Table 5: Results of the ablation study. VSR/ASR ratio reflects how much noise is present in the sam-
pling results. As illustrated in Table 7, the top-K method has
stonger ability to recognize uncertain components and yield
contribution of context retrieved via sentence-level queries is
better oracle scores, but there is also more noise, resulting in
limited. By combining uncertainty sampling and retrieval,
more retrieval times.
TURNER can boost the performance to the greatest extent.
The label embedding and weighted-average loss also con-
MSRA Ontonotes
tribute much to the Knowledge Fusion Model.
MC Top-K MC Top-K
5 Discussion SAR 0.013 0.096 0.054 0.416
VSR 0.003 0.009 0.018 0.071
5.1 TURNER With Offline Retrieval
Avg Retrieval 0.089 0.162 0.345 0.764
The time cost of retrieval from search engines is still too Oracle F1 98.09 98.41 88.21 92.3
high in some application scenarios. As a result, we con-
duct experiments with an offline knowledge graph to test Table 7: The statistical results of two uncertainty sampling methods.
TURNER’s generalization capabilities. We use the ownthink3 "Avg Retrieval" denotes the average retrieval times for each sample.
knowledge graph, which contains more than 140 million
(Subject, P redicate, Object) triplets about general knowl-
edge. For each subject in the knowledge graph, we merge all From the perspective of computational efficiency, the addi-
related triplets containing it to generate a descriptive docu- tional GPU cost of two sampling methods can be calculated
ment 4 . Then, for each query, we use the BM25 algorithm as follows:
to retrieve the three most relevant descriptive documents as COSTMC = O((k + β1 (1 + γ)2 ) · C), (8)
auxiliary knowledge in TURNER. COSTTop-K = O(β2 (1 + γ)2 · C), (9)
where k is the number of candidates, β is the retrieval ra-
MSRA Ontonotes Weibo Resume tio, γ is is the ratio of the length of the knowledge text to
BERT Baseline 95.91 81.54 70.10 95.78 the original input text, and C is the cost of the base NER
TURNERMC model, i.e., BERT+MLP. MC Dropout demands more GPU
w/ search engine 96.85 83.56 70.78 96.36 resources in the first stage, while the top-K method results
w/ offline KG 96.59 82.73 70.37 96.17 in more retrieval times and consumes more GPU resources in
the second stage because it samples more uncertain compo-
Table 6: The performance of TURNER with offline retrieval. nents. The ultimate choice should be based on actual details.
As illustrated in Table 6, TURNER with offline re-
6 Conclusion and Future Work
trieval outperforms existing SOTA lexicon-based methods in In this paper, we propose TURNER, a framework for Chi-
MSRA, Ontonotes, and Resume, which can be considered in- nese NER that integrates uncertainty sampling and knowl-
domain datasets for the knowledge graph. Because many in- edge retrieval. TURNER applies MC Dropout or top-K la-
ternet phrases are out-of-domain for the knowledge graph, the bel sequences to identify the uncertain components that lead
offline retrieval does not operate effectively in Weibo. The to ambiguity with a base NER model. Afterward, the uncer-
results indicate the generalization ability of TURNER, which tain components can be utilized as queries to retrieve knowl-
can work with various knowledge bases. The performance of edge efficiently and effectively. Furthermore, the Knowledge
offline retrieval is not as good as the search engines because Fusion Model re-predict the uncertain samples based on the
search engines have broader knowledge and more precise re- retrieved knowledge. Comprehensive experiments on four
trieval. datasets illustrate TURNER significantly outperforms exist-
ing lexicon-based methods and achieves new SOTA results.
5.2 MC Dropout vs. Top-K Label Sequences For existing NLP technologies, it is impossible to dynami-
Because the two uncertainty sampling approaches are on par cally maintain all required knowledge in neural models. The
in performance, we undertake a more detailed analysis to retrieval methods utilizing external knowledge bases can be
compare them. We use two metrics to measure the quality of solutions to this issue, while our uncertainty-based retrieval
paradigm makes retrieval methods more effective and effi-
3
https://www.ownthink.com/knowledge.html cient. In the future, we will try to broadcast the uncertainty-
4
More details can be found in Appendix C. based retrieval paradigm to more NLP tasks and applications.References Meeting of the Association for Computational Linguistics,
[Brown and Golod, 2010] Daniel G Brown and Daniil 2016.
Golod. Decoding hmms using the k best paths: algorithms [Peng and Dredze, 2015] Nanyun Peng and Mark Dredze.
and applications. BMC bioinformatics, 11(1):1–7, 2010. Named entity recognition for chinese social media with
[Gal and Ghahramani, 2016] Yarin Gal and Zoubin Ghahra- jointly trained embeddings. In Proceedings of the 2015
mani. Dropout as a bayesian approximation: representing Conference on Empirical Methods in Natural Language
model uncertainty in deep learning. In International Con- Processing, pages 548–554, 2015.
ference on Machine Learning, 2016. [Qiu et al., 2014] Xipeng Qiu, Chaochao Huang, and Xuan-
[Gu et al., 2018] Jiatao Gu, Yong Wang, Kyunghyun Cho, jing Huang. Automatic corpus expansion for chinese word
and Victor OK Li. Search engine guided neural machine segmentation by exploiting the redundancy of web infor-
translation. In Proceedings of the AAAI Conference on Ar- mation. In International Conference on Computational
tificial Intelligence, volume 32, 2018. Linguistics, 2014.
[Gui et al., 2020] Tao Gui, Jiacheng Ye, Qi Zhang, [Sun et al., 2019] Yu Sun, Shuohuan Wang, Yukun Li,
Zhengyan Li, Zichu Fei, Yeyun Gong, and Xuanjing Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxi-
Huang. Uncertainty-aware label refinement for sequence ang Zhu, Hao Tian, and Hua Wu. Ernie: Enhanced rep-
labeling. In Empirical Methods in Natural Language resentation through knowledge integration. arXiv preprint
Processing, 2020. arXiv:1904.09223, 2019.
[Hashimoto et al., 2018] Tatsunori B. Hashimoto, Kelvin [Torisawa and others, 2007] Kentaro Torisawa et al. Exploit-
Guu, Yonatan Oren, and Percy Liang. A retrieve-and-edit ing wikipedia as external knowledge for named entity
framework for predicting structured outputs. In Neural In- recognition. In Proceedings of the 2007 joint confer-
formation Processing Systems, 2018. ence on empirical methods in natural language processing
and computational natural language learning (EMNLP-
[He et al., 2020] Qizhen He, Liang Wu, Yida Yin, and Hem- CoNLL), pages 698–707, 2007.
ing Cai. Knowledge-graph augmented word representa-
tions for named entity recognition. In Proceedings of the [Wang et al., 2021a] Baojun Wang, Zhao Zhang, Kun Xu,
AAAI Conference on Artificial Intelligence, volume 34, Guang-Yuan Hao, Yuyang Zhang, Lifeng Shang, Linlin Li,
pages 7919–7926, 2020. Xiao Chen, Xin Jiang, and Qun Liu. Dylex: Incorporating
dynamic lexicons into bert for sequence labeling. In Pro-
[Houlsby et al., 2019] Neil Houlsby, Andrei Giurgiu, ceedings of the 2021 Conference on Empirical Methods in
Stanisław Jastrz˛ebski, Bruna Halila Morrone, Quentin Natural Language Processing, pages 2679–2693, 2021.
de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and
Sylvain Gelly. Parameter-efficient transfer learning for [Wang et al., 2021b] Xinyu Wang, Yong Jiang, Nguyen
nlp. In International Conference on Machine Learning, Bach, Tao Wang, Zhongqiang Huang, Fei Huang, and
2019. Kewei Tu. Improving named entity recognition by exter-
nal context retrieving and cooperative learning. In Pro-
[Huang et al., 2015] Zhiheng Huang, Wei Xu, and Kai Yu. ceedings of the 59th Annual Meeting of the Association
Bidirectional lstm-crf models for sequence tagging. arXiv for Computational Linguistics and the 11th International
preprint arXiv:1508.01991, 2015. Joint Conference on Natural Language Processing (Vol-
[Levow, 2006] Gina-Anne Levow. The third international ume 1: Long Papers), pages 1800–1812, Online, August
chinese language processing bakeoff: Word segmenta- 2021. Association for Computational Linguistics.
tion and named entity recognition. In Proceedings of the [Weischedel et al., 2011] Ralph Weischedel, Sameer Prad-
Fifth SIGHAN Workshop on Chinese Language Process- han, Lance Ramshaw, Martha Palmer, Nianwen Xue,
ing, pages 108–117, 2006. Mitchell Marcus, Ann Taylor, Craig Greenberg, Eduard
[Li et al., 2020] Xiaonan Li, Hang Yan, Xipeng Qiu, and Hovy, Robert Belvin, et al. Ontonotes release 4.0.
Xuan-Jing Huang. Flat: Chinese ner using flat-lattice LDC2011T03, Philadelphia, Penn.: Linguistic Data Con-
transformer. In Proceedings of the 58th Annual Meeting sortium, 2011.
of the Association for Computational Linguistics, pages [Yan et al., 2019] Hang Yan, Bocao Deng, Xiaonan Li,
6836–6842, 2020. and Xipeng Qiu. Tener: adapting transformer en-
[Liu et al., 2021] Wei Liu, Xiyan Fu, Yue Zhang, and Wen- coder for named entity recognition. arXiv preprint
ming Xiao. Lexicon enhanced Chinese sequence label- arXiv:1911.04474, 2019.
ing using BERT adapter. In Proceedings of the 59th An- [Yang et al., 2017] Jie Yang, Yue Zhang, and Fei Dong. Neu-
nual Meeting of the Association for Computational Lin- ral reranking for named entity recognition. In Recent Ad-
guistics and the 11th International Joint Conference on vances in Natural Language Processing, 2017.
Natural Language Processing (Volume 1: Long Papers),
pages 5847–5858, Online, August 2021. Association for [Zhang and Yang, 2018] Yue Zhang and Jie Yang. Chinese
Computational Linguistics. ner using lattice lstm. In Meeting of the Association for
Computational Linguistics, 2018.
[Ma and Hovy, 2016] Xuezhe Ma and Eduard Hovy. End-to-
end sequence labeling via bi-directional lstm-cnns-crf. InA Hyperparameters
Baseline Model Knowledge Fusion Model
Original Text
Epochs 20 10 实践越来越证明,“亚太经合组织方式”符合本地区
Batch Size 32 32 的实际,有利于各成员的不同权益和要求得到较好
Weight Decay 0 0 的平衡,有助于发挥各个成员的能力,促进共同发
Dropout 0.1 0.1 展。
Learning Rate 2e-5 {2e-5,3e-5}
Uncertain Component
Optimizer AdamW AdamW
Warm Up Ratio 0.1 0.1 亚太经合组织
Max Seq_Len 128 512
α - {0.1,1} Knowledge w/ Search Engine
亚 太 经 合 组 织-百 度 百 科:简 介 : 亚 太 经 合 组 织
Table 8: The hyperparameters we used for training. Other hyperpa- 一般指亚太经济合作组织。亚太经济合作组
rameters are the same as BERT. For the baseline model, we use same 织 ( 英 文 :asia-pacificeco|亚 太 经 合 组 织-asia-
hyperparameters in all datasets. For the Knowledge Fusion Model,
pacificeconomiccooperat...:apecministers’meeting08-
the search range is the same in all datasets.
09november2021vir|亚 太 经 合 组 织 超 额 实 现 悉 尼
林 业 目 标_政 务_澎 湃 新 闻-thepaper:11月9日,亚
太 经 合 组 织 部 长 级 会 议 联 合 发 布 部 长 声 明,对
B Uncertainty Sampling Results 亚 太 区 域 森 林 面 积 增 长2790万 公 顷,如 期 实 现
悉|习 近 平 在 亚 太 经 合 组 织 工 商 领 导 人 峰 会 上
的 主 旨 演 讲(全 文):坚 持 可 持 续 发 展 共 建 亚 太 命
Type Train Validation Test
运共同体在亚太经合组织工商领导人峰会上
MC Dropout 的 主 旨 演 讲 (2021年11月1|亚 太 经 合 组 织 概 况
SizeU 10748 - 335 中 华 人 民 共 和 国 外 交 部:【 成 立 】 亚 太 经 合 组
MSRA
NumU C 13748 - 388 织(asia-pacificeconomiccooperation,ape|习近平在亚
太经合组织第二十八次领导人非正式会议上的讲
Ontonotes
SizeU 4471 1133 1229 话...:很高兴同大家见面。首先,我感谢阿德恩总理
NumU C 6403 1464 1501 和新西兰政府为本次会议作出的努力。本次会议
SizeU 614 86 93 以推动疫后经济复|增加2650万公顷!中国为亚太
Weibo 地区森林增长贡献巨大|亚太经合组织超额实现
NumU C 1027 133 137
悉尼林业目标|澳媒社论:亚太经济合作攸关全球
SizeU 1309 50 38
Resume 进步|悉尼林业目标超额实现,中国森林面积13年
NumU C 1798 53 53
增2650...|携手开创亚太经济合作新篇章
Top-K Label Sequences
Knowledge w/ Knowledge Graph
SizeU - - 615
MSRA
NumU C - - 706 亚太经合组织第二十二次领导人非正式会议宣
言。北京纲领北京纲领:构建融合、创新、互联
SizeU - 2225 2383
Ontonotes 的亚太亚太经合组织第二十二次领导人非正式会
NumU C - 3048 3322
议宣言我们,亚太经合组织各成员领导人聚首北
Weibo
SizeU - 111 125 京雁栖湖畔,举行亚太经合组织第二十二次领导
NumU C - 155 165 人非正式会议。。中文名:亚太经合组织第二十
SizeU - 48 44
二次首届亚太经合组织林业部长级会议。|首届亚
Resume
NumU C - 50 50
太经合组织林业部长级会议,在北京人民大会堂
开幕。。中文名:首届亚太经合组织林业部长级
会议。类别:会议。地点:亚太经合组织。类型:林
Table 9: Statistical results of two uncertainty sampling methods.
"SizeU " denotes the number of samples that contain at least one un- 业部长。标签:社会事件。歧义关系:首届亚太经
certain component. "NumU C " denotes the total number of uncertain 合组织林业部长级会议。歧义权重:1028。|亚太经
components in all samples. 合组织领导人非正式会议。亚太经合组织领导人
非正式会议,是亚太经合组织高级别的会议。。
中文名:亚太经合组织领导人非正式会议。外文
名:theannualapececonomicleaders;meetings。成立时
C Case Study 间:1992年4月。首届
In order to better illustrate the effectiveness of retrieved
knowledge, we give a case of retrieved knowledge in Ta- Table 10: An example of retrieved knowledge.
ble 10.D Analysis on Uncertainty Sampling Methods
We give an investigation about the influencing factors of un-
certainty sampling using the testset of MSRA, and the results
are shown in Table 11. For all influencing factors, the perfor-
mance shows a trend of first rising and then falling, indicating
that there are local optimal choices.
MC Dropout, Candidate Num = 8
Drop Rate 0.05 0.1 0.2 0.4
SAR 0.008 0.013 0.031 0.221
VSR 0.002 0.003 0.005 0.002
F1 Score 96.74 96.85 96.66 96.29
MC Dropout, Drop Rate = 0.1
Candidate Num 2 4 8 16
SAR 0.023 0.018 0.013 0.009
VSR 0.006 0.005 0.003 0.002
F1 Score 96.56 96.79 96.85 96.75
Top-K Method
Candidate Num 1 2 4 8
SAR 0.118 0.104 0.096 0.088
VSR 0.019 0.014 0.009 0.006
F1 Score 96.42 96.50 96.54 96.46
Table 11: The results on MSRA datasets of our investigation.
For MC Dropout, as the dropout rate increases, the model’s
capacity decreases significantly and more noisy candidates
are generated. Therefore, with enough computational re-
sources, finding the optimal forward times is a more general
solution. The Top-K method generates more valuable candi-
dates as well as more noisy candidates.You can also read

















































