Supplemental information The global spread of misinformation on spiders
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Supplemental information The global spread of misinformation on spiders Stefano Mammola, Jagoba Malumbres-Olarte, Valeria Arabesky, Diego Alejandro Barrales- Alcalá, Aimee Lynn Barrion-Dupo, Marco Antonio Benamú, Tharina L. Bird, Maria Bogomolova, Pedro Cardoso, Maria Chatzaki, Ren-Chung Cheng, Tien-Ai Chu, Leticia M. Classen-Rodríguez, Iva Čupić, Naufal Urfi Dhiya'ulhaq, André-Philippe Drapeau Picard, Hisham K. El-Hennawy, Mert Elverici, Caroline S. Fukushima, Zeana Ganem, Efrat Gavish-Regev, Naledi T. Gonnye, Axel Hacala, Charles R. Haddad, Thomas Hesselberg, Tammy Ai Tian Ho, Thanakorn Into, Marco Isaia, Dharmaraj Jayaraman, Nanguei Karuaera, Rajashree Khalap, Kiran Khalap, Dongyoung Kim, Tuuli Korhonen, Simona Kralj-Fišer, Heidi Land, Shou-Wang Lin, Sarah Loboda, Elizabeth Lowe, Yael Lubin, Alejandro Martínez, Zingisile Mbo, Marija Miličić, Grace Mwende Kioko, Veronica Nanni, Yusoff Norma-Rashid, Daniel Nwankwo, Christina J. Painting, Aleck Pang, Paolo Pantini, Martina Pavlek, Richard Pearce, Booppa Petcharad, Julien Pétillon, Onjaherizo Christian Raberahona, Philip Russo, Joni A. Saarinen, Laura Segura-Hernández, Lenka Sentenská, Gabriele Uhl, Leilani Walker, Charles M. Warui, Konrad Wiśniewski, Alireza Zamani, Angela Chuang, Catherine Scott
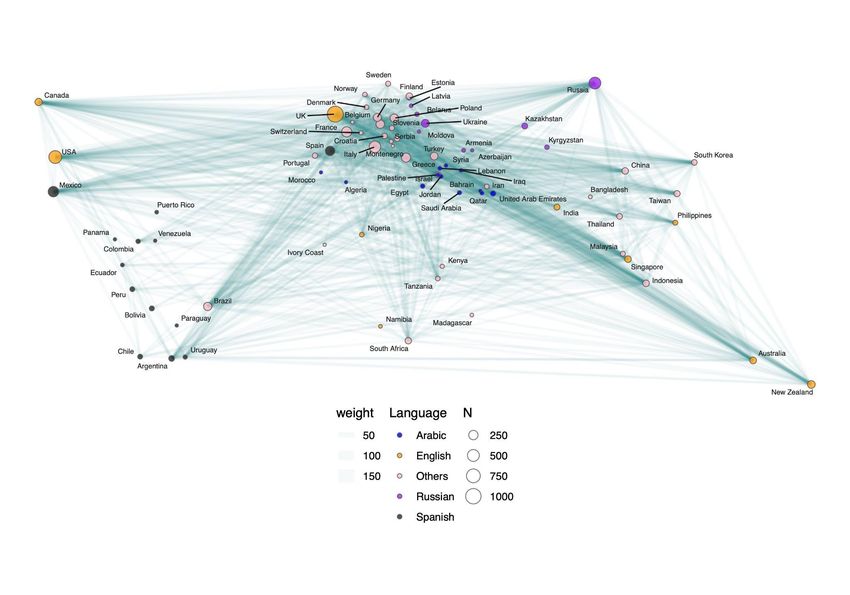
FIGURE S1. Connections among countries in the network. One-mode (or unipartite) network projected from a bi-partite network (Figure 1A) showing relationships among nodes of type 1 (countries). Size of each node is proportional to the number of spider-related news a given country has published between 2010 and 2020. Color coding for nodes refers to the primary language of each country. Connection thickness weights the number of times a given country has reported on human-spider encounters occurring in another country.
TABLE S1. Estimated regression parameters. Model estimates in equation 1 (eq. 1) are based
on a Bernoulli generalized linear mixed model (eq. 1), testing the relationships between whether
an article is sensationalistic or not and different predictors. Model estimates in equation 2 (eq. 2)
are based on an exponential random graph model, expressing the influence of the different
predictors on the probability of network nodes to form connections. SE = Standard error; CI = 95%
confidence interval; p = p-value based on the z test.
Model Predictor Estimate ± SE CI z p
Intercept -1.49 ± 0.37 -2.22 – -0.76 - -
Year of Publication 0.02 ± 0.05 -0.06 – 0.11 0.54 0.588
Type_of_newspaper [Magazine] 0.04 ± 0.15 -0.25 – 0.34 0.28 0.778
Type_of_newspaper [Online newspaper] -0.01 ± 0.09 -0.18 – 0.16 -0.11 0.910
Circulation [International] 0.35 ± 0.12 0.11 – 0.60 2.84 0.005
Circulation [National] 0.51 ± 0.09 0.34 – 0.67 5.87Expert_doctor [yes] 0.04 ± 0.12 -0.19 – 0.26 0.31 0.759
Expert_arachnologist [yes] -0.49 ± 0.10 -0.69 – -0.29 -4.81SUPPLEMENTAL EXPERIMENTAL PROCEDURES
News article data and news-level attributes
We analyzed a global database of news articles on human-spider encounters published online by
newspapers and magazines in 2010–2020S1. The database is unique in that it covers a global scale
while providing an in-depth expert-based assessment of each news article's content and its quality.
S1
We refer to Mammola et al. (ref. ) for a lengthy description of the database, data collection
methodology, and data validation. We also report essential information below.
We retrieved news articles across 81 countries and 40 languages using Google News. We
included news articles that referred to an encounter between a human and a spider (which may or
may not have resulted in a biting event). We disregarded all media articles reporting general
information about spiders, arachnophobia, and research findings on spider biology. The total
sample size was 5,348 unique news articles, reporting 6,204 human-spider encountersS1. However,
many of these human-spider encounters were reported by multiple news sources, leaving a total of
2,644 unique encounters—of which 1,121 are classified as bites and 147 as deadly bites. For each
news article, we collected the following news-level attributes:
1) date of publication (“Year” and “Month”);
2) language (“Language”);
3) newspaper circulation (“Circulation”; categorical variable with three levels: “Regional”,
“National”, and “International”);
4) country in which the news was published (“Country”)
5) type of human-spider encounter (“Type_event”; categorical variable with three levels:
“Encounter”, “Bite”, and “Deadly bite”);
6) genus of the species involved in the event (“Genus”);7) longitude and latitude coordinates of the human-spider encounter (“x” and “y”);
8) presence/absence of photos of the species and the bite (variables “Photo_”);
9) consultancy of spider experts, doctors, or other professionals (variables “Expert_”); and
10) quality of the article, measured as presence/absence of errors and an assessment of
sensationalism (see details in the next section).
Assessment of sensationalism and errors
For a given news article, it is possible to assess the quality of information along two axes. A first
axis pertains to the correctness, measuring whether the content is factually right or wrongS2. A
second axis pertains to sensationalism, measuring whether the content contains cognitive attraction
stimuli to clickbait viewers and spread more efficientlyS3.
In assessing sensationalism and errors, we followed standard approaches for content
analyses of newspaper articlesS3–S7. We assessed each article as sensationalistic or neutral by
evaluating the title, subheadings, main text, and photographs/video content. Sensationalistic
articles consistently use emotional words and imagesS4 (e.g., referring to exaggerated spider body
sizeS8–S10 or hairinessS9). In our case, frequent words associated with sensationalistic content were
‘alarm’, ‘agony’, ‘attack’, ‘boom’, ‘deadly’, ‘creepy crawly’, ‘devil’, ‘fear’, ‘hell’, ‘killer’,
‘murderer’, ‘nasty’, ‘nightmare’, ‘panic’, ‘terrible’, ‘terrifying’, and ‘terror’.
Furthermore, we evaluated the title, subheadings, main text, and photographs/video content
assessing four types of errors, namely: i) errors in images (photographs/figures), when the species
depicted did not correspond to the species mentioned in the text, or when the attribution was not
possible (e.g., blurry photographs); ii) errors pertaining to incorrect taxonomic information (e.g.,
‘spiders are insects’); iii) errors pertaining to unrealistic outcomes of envenomations, in thedescription of venom toxicity, and other physiological or medical aspects or terminology; and iv)
errors in spider’s anatomy (e.g., “spider sting”).
Given that the assessments of sensationalism and errors entails a degree of subjectivity,
whenever possible (articles in English, French, Spanish, and Italian) two to three authors assessed
each news item independently. For each article, the assessors classified errors and sensationalism
independently and compared their scores. We estimated inter-rater agreement between multiple
raters via Cohen’s kappa statistic (ranging from –1 to 1, with values above 0.8 indicating very high
to near-perfect agreements among scorers)S11. In our case, all values were above 0.8, thus we
assumed the effect of subjectivity was trivial across our database (details on the analysis in ref. S1).
Furthermore, discrepancies in scores were discussed to reach a consensus on the final scores.
Country-level attributes
For each country for which we found spider-related news, we further collected country-level
attributes that could be relevant predictors for the importance in driving the flow of news articles
on spiders in the network. The variables and sources are described in the following subsections.
Note that we discuss here all variables that we originally considered potentially relevant for
explaining the observed patterns of information spread across countries; some of these variables
were later removed due to multicollinearity or high prevalence of missing data (see details in the
section “Data exploration”).
News-related variables
Based on the original database, we calculated the number of news published in each country
between 2010–2020 (“N° of news”), the proportion of sensationalistic news (“Sensationalism”;see pie charts in Figure 1A), and the proportion of news containing errors (“Errors”). We also
extracted the most widely spoken language in each country (“Language”).
Spider-related variables
For each country, we derived the known number of spiders (“N° of spiders”) and the number of
deadly spiders (“N° of deadly spiders”) to test our hypothesis that countries with more spiders,
especially medically important species, would have a higher degree of centrality and
connectedness. It must be noted that information on the number of species by country introduces
some bias—e.g., more information is available and more species are described in temperate
regionsS12—and therefore these variables represent only a rough estimate of the actual species
diversity in those countries.
We first downloaded the daily species export from the World Spider Catalog (WSC)S13 on
01 September 2021. We translated the distribution (country, continent, or range of countries) given
by the WSC for each species into a list of corresponding 3-letter ISO country codes. For example,
we translated “North America” to the list “CAN, MEX, USA,” and “Egypt to Yemen” to “EGY,
SAU, YEM.” We used this dataset to extract the total number of species present in each country
in our spider news database. We then searched for published checklists of spider species for each
country. For countries with checklists (n = 53), we compared the total number of species reported
from the checklist to the estimate generated from the WSC and used the larger estimate for
analyses. For countries without a checklist (n = 28), we used the WSC estimate. To estimate the
number of ‘deadly’ spiders (i.e., species capable of fatal envenomations), we used the WSC dataset
described above to extract records of spider species in all genera considered to be medically
important (Atrax, Hadronyche, Hexopthalma, Illawarra, Latrodectus, Loxosceles, Phoneutria, andSicariusS14) for each country. We then inspected all published country checklists for records of
species in these genera and added them to the dataset if they were missing from the WSC data.
Finally, we checked the literature (including country checklists and the primary taxonomic
literature) to determine whether each ‘deadly’ species in the WSC dataset had been recorded from
each country. If we found no evidence that a species had been recorded from a given country, it
was scored as ‘not present’ unless it had been recorded from neighboring countries, in which case
it was scored as ‘presumed present’. We included records of introduced species that had been
recorded even from a single specimen.
Furthermore, we calculated the number of spider experts (arachnologists) working in each
country to test our hypothesis that news articles that interviewed arachnologists were less likely to
be sensationalist and have factual errors. We approximated this number from the anonymized
member list by country of the International Society of Arachnology (“ISA”;
https://arachnology.org/) in 2021. This information was provided to us by the secretary of the
society (Dunlop J.A., personal communication on 1 September 2021).
Degree of arachnophobia across different countries would also be important to include as
a predictor although we excluded this information because reports of phobias were not available
in a standardized way that would be comparable across the globe.
Socio-economic descriptors
We derived a number of socio-economic descriptors for each country, based on the UNESCO
Institute of Statistics (UIS) and other sources (specified below). The UIS provides free data on
more than 1,000 indicators which may be found in the UIS Data Centre (all data from UIS were
last updated on 24 October 2016; we last accessed them on 21 July 2021). We hypothesized thatcountries with a higher education level (including education index, reading score, and science
score), degree of communication (i.e. internet users), development index (including the Human
Development Index and the number of researchers), as well as press freedom, would have a higher
degree of connectedness among countries (Figure S1).
As proxies for education level in the country, we extracted the country education index
(“Education”), the Programme for International Student Assessment (PISA) score in reading
(“PISA reading”), and the PISA score in science (“PISA science”). The education index is an
average of mean years of schooling of adults and expected years of schooling of children, both
expressed as an index obtained by scaling with the corresponding maxima. We derived this index
based on expected years of schooling and mean years of schooling from UIS
(http://hdr.undp.org/en/data). PISA scores are obtained by testing skills and knowledge of 15-year-
old students in reading and science; we sourced these indices from the Organisation for Economic
Cooperation and Development, PISA results for 2018 (www.oecd.org/pisa; accessed on 8
September 2020).
As a proxy for the degree of development in communication, we calculated the number of
internet users (“Internet users”), namely the number of people with access to the worldwide
network by country. We sourced internet users from the International Telecommunication Union
(www.itu.int/en/ITU-D/Statistics/Pages/stat/; accessed on 2 September 2021).
As a proxy for country development, we calculated the Human Development Index
(“HDI”) and the number of researchers in the country (“N° of Researchers”). HDI is a composite
index measuring average achievement in three basic dimensions of human development—a long
and healthy life, knowledge, and a decent standard of living. We expressed the number of
researchers per million inhabitants in full-time equivalent from the UIS(http://data.un.org/Explorer.aspx?d=UNESCO&f=series%3aC_N_500032; accessed on 2
September 2021).
Finally, we derived two variables related to journalism, The World Press Freedom Index
(“Press Freedom”) by Reporters without Borders (https://rsf.org/en/ranking_table; accessed on 2
September 2021) and the number of newspapers (“N° of Newspapers”) from the UIS
(http://data.un.org/Data.aspx?d=UNESCO&f=series%3aC_N_500032#UNESCO; accessed on 2
September 2021).
Data exploration
For data exploration, we followed the general protocol by ref. S15.
Handling of missing data
Most country-level socio-economic descriptors had missing data (i.e., we could not derive
information for some countries). Depending on the variables, the proportion of missing data ranged
from 1 to 30%. Since exponential random graph models (see below) do not allow missing data and
considering the high level of multicollinearity (the existence of a high correlation between
covariates) among socio-economic descriptors, we decided to impute missing data. We used data
imputation based on multiple linear regressions, as implemented in the function fill of the R
package ‘BAT’ version 2.7.1S16,S17. The predicted value for missing observations is obtained by
regressing the missing variable on other variables. This preserves relationships among variables
involved in the imputation model, but not variability around predicted values. Therefore, it is
recommended to perform imputation only when the number of missing data is low. Based on
evidence from trait-based ecologyS18, we decided to exclude any variable with >4% missing data,namely PISA reading (30.86% missing data) and PISA science (29.63%). Note that both PISA indexes were positively correlated with HDI and Education (all Pearson’s r > 0.65). We performed imputation for Education (2.47% missing data), Internet users (2.47%), N° of Newspapers (3.7%), Press Freedom (1.23%), and HDI (2.47%). Variable distribution and outliers We inspected variable distribution and the presence of outliers using Cleveland’s dot plots. Following this visual inspection, we log-transformed N° of news, ISA, and N° of newspapers to homogenize their distributions. We also scaled all continuous variables to facilitate model convergence. Furthermore, we checked the balance of the number of observations for levels in the variable Language. To balance factor levels, we grouped all Languages with less than 10 observations in the category ‘Others’. Since English is the most widely used language internationally, we set ‘English’ as the baseline. Collinearity We explored collinearity among covariates using Pearson’s r correlations, setting the threshold for collinearity at |r| > 0.5. The introduction of highly correlated predictors in a regression model often leads to a confusing statistical analysis where, for example, dropping one covariate can make others significant or change the sign of estimatesS15. As a result of this analysis, we excluded ISA and N° of newspapers as they were reciprocally correlated (r = 0.7) and both positively correlated with N° of news (both r > 0.6). We excluded HDI and Education as they were reciprocally correlated (r = 0.95) and both correlated with Internet users (both r > 0.8). Finally, we excluded N° of spiders as it was collinear with N° of deadly spiders (r = 0.52).
Statistical analyses We performed all analyses and calculations in R version 4.1.0 S19. We used the package “ggplot2” version 3.3.4S20 for visualizations. In all regression-type analyses, we followed ref. S21 for model construction and validation. In discussing model results, we adopted an evidence- based languageS22, referring to effect sizes, directions of effects, and variance explained rather than significanceS23. Exact model estimates and p-values can be found in Tables S1. Relationships between sensationalism, errors, and news-level attributes First, we explored the role of different news-level attributes in explaining the probability of a given piece of news being sensationalistic. We fitted generalized linear mixed models with the package lme4 version 1.1-27.1S24. Given that the response variable is incidence data (sensationalist or not), we chose a Bernoulli family distribution (0–1, discrete). The structure of the model, in R notation, was: (eq. 1) Sensationalism ~ Year + Type_of_newspaper + Circulation + Type_event + Photo_species + Photo_bite + Expert_doctor + Expert_arachnologist + Expert_others + Errors + (1 | Genus) + (1 | Language) + (1 | Country_search) + (1 | ID_Event) Note that the variable presence of errors in a news article (“Errors”) was included as a predictor to check whether there was covariation between sensationalism and errors. Given that the two variables turned out to be tightly associated (Figure 1B), we did not run an additional model with Error as a response variable, as it would have yielded comparable results. The random part of the
models allowed us to control for publication language, the country of the search, and the taxonomic
identity of the species involved in the human-spider encounter. In other words, by the design of
the study, we assumed that articles from the same countries and language, and dealing with
congeneric species, should be more similar to one another in their news-level attributes than
expected from random. Treating these variables as fixed factors would have consumed too many
degrees of freedom given the high number of levels for each of these factors. Furthermore, we
include a fourth random factor (“ID_event”) to account for pseudo-replication, namely the fact
that multiple articles may refer to the same human-spider encounters. We corrected for this source
of data non-independency under the assumption that articles on the same human-spider encounter
may be, on average, more similar to one another than expected from random. We introduced all
random effects as random-intercept factors because we did not expect them to influence the
direction of effects.
In the model, the final sample size after removing missing data was 5,816 observations.
We validated models by constructing standard validation plots with the R package performance
version 0.7.2S25. We also checked for spatial and temporal dependency by plotting model residuals
against the year and month of publication and the longitude and latitude of the centroid of the
country in which the news was published. Inspection of these plots revealed no obvious spatial
and temporal patterns.
Global flow of spider-related information
We used network analyses to visualize and model the flow of spider-related information among
countries. We constructed and manipulated networks with the packages ‘igraph’ version 1.2.6 S26
and ‘tidygraph’ version 1.2.0 S27. First, we constructed a bipartite directed network to link eachcountry with each spider-related event reported by the online press. In the network, the first node
type represented individual countries, and the second node type represented the identifier for
each human-spider encounter reported in the press (ID_event) (Figure 1A). We then projected
the bipartite network as a one-mode network (or unipartite network) with the ‘igraph’ function
bipartite.projection. This allowed us to visualize the relationships amongst the nodes of type 1
(countries). In the one-mode network, all nodes are treated as the same type, and directionality is
lost (Figure S1).
We modeled connections among countries within the network using exponential random
graph models. These are a family of regression-like models that can infer how network
relationships are formed, using the network itself as a response variable. To model the
probability of each node to form connections, we introduced the one-mode network with binary
edge weights as a response variable in an exponential random graph model fitted within the R
package ‘ergm’ version 4.1.2S28,S29. We selected as covariates the non-collinear predictors
selected after data exploration (see section “Data exploration”). However, in contrast to the
previous analysis (eq. 1), we included Language as a fixed term because random effects are not
implemented in exponential random graph models yet. Also, we excluded press freedom from
the model, as the variable was not identifiable in the model. The structure of the model had the
formula (in R notation):
(eq. 2) Network ~ edge + nodeCov(“Sensationalism”) + nodeCov(“Errors”) + nodeCov(“Internet
users”) + nodeCov(“N° of deadly spiders”) + nodeMatch(“Language”) +
nodeFactor(“Language”)Where edge is the intercept-like term; nodeCovariate and nodeFactor test the overall probability
of the node types forming connections with any other nodes based on the continuous and
categorical covariates, respectively; and nodeMatch tests whether node types have a greater
probability of forming connections within the levels of a given grouping factor. The model
sample size was 79 observations, namely the number of nodes (countries) in the network. As a
means of model validation, we generated an empty network with the same dimensionality as our
response network and used the final model to simulate, over 1,000 runs, whether the model was
able to converge to the edge probability of the real network.
SUPPLEMENTAL REFERENCES
S1. Mammola, S. et al. (2022). An expert-curated global database of online newspaper articles
on spiders and spider bites. Sci. Data 9, 109.
S2. Lazer, D., Matthew, B., Benkler, Y., Adam, B., Greenhill, K., Menczer, F., Miriam, J.,
Nyhan, B., Pennycook, G., Rothschild, D., et al. (2018). The science of fake news.
Science 359, 1094–1096.
S3. Acerbi, A. (2019). Cognitive attraction and online misinformation. Palgrave Commun. 5,
15.
S4. Mammola, S., Nanni, V., Pantini, P., and Isaia, M. (2020). Media framing of spiders may
exacerbate arachnophobic sentiments. People Nat. 2, 1145–1157.
S5. Nanni, V., Caprio, E., Bombieri, G., Schiaparelli, S., Chiorri, C., Mammola, S., Pedrini,
P., and Penteriani, V. (2020). Social media and large carnivores: Sharing biased news on
attacks on humans. Front. Ecol. Evol. 8, 71.
S6. Bombieri, G., Nanni, V., Delgado, M. del M., Fedriani, J.M., López-Bao, J.V., Pedrini, P.,
and Penteriani, V. (2018). Content analysis of media reports on predator attacks on
humans: Toward an understanding of human risk perception and predator acceptance.
Bioscience 68, 577–584.S7. Nanni, V., Mammola, S., Macías-Hernández, N., Castrogiovanni, A., Salgado, A.L.,
Lunghi, E., Ficetola, G.F., Modica, C., Alba, R., Spiriti, M., et al. (2022). Global response
of conservationists across mass media likely constrained bat persecution due to COVID-
19. Biol. Conserv. 272, 109591.
S8. Leibovich, T., Cohen, N., and Henik, A. (2016). Itsy bitsy spider?: Valence and self-
relevance predict size estimation. Biol. Psychol. 121, 138–145.
S9. Zvaríková, M., Prokop, P., Zvarík, M., Ježová, Z., Medina-Jerez, W., and Fedor, P.
(2021). What makes spiders frightening and disgusting to people? Front. Ecol. Evol. 9,
424.
S10. Frynta, D., Janovcová, M., Štolhoferová, I., Peléšková, Š., Vobrubová, B., Frýdlová, P.,
Skalíková, H., Šípek, P., and Landová, E. (2021). Emotions triggered by live arthropods
shed light on spider phobia. Sci. Rep. 11, 22268.
S11. Fleiss, J.L., Cohen, J., and Everitt, B.S. (1969). Large sample standard errors of kappa and
weighted kappa. Psychol. Bull. 72, 323–327.
S12. Titley, M.A., Snaddon, J.L., and Turner, E.C. (2017). Scientific research on animal
biodiversity is systematically biased towards vertebrates and temperate regions. PLoS One
12, e0189577.
S13. World Spider Catalog (2022). World Spider Catalog. Version 23.0. Nat. Hist. Museum
Bern. Online at: https://wsc.nmbe.ch/
S14. Vetter, R.S., and Isbister, G.K. (2008). Medical Aspects of Spider Bites. Annu. Rev.
Entomol. 53, 409–429.
S15. Zuur, A.F., Ieno, E.N., and Elphick, C.S. (2009). A protocol for data exploration to avoid
common statistical problems. Methods Ecol. Evol. 1, 3–14.
S16. Cardoso, P., Mammola, S., Rigal, F., and Carvalho, J.C. (2021). BAT: Biodiversity
Assessment Tools. R package version 2.6.0.
S17. Cardoso, P., Rigal, F., and Carvalho, J.C. (2015). BAT – Biodiversity Assessment Tools,
an R package for the measurement and estimation of alpha and beta taxon, phylogenetic
and functional diversity. Methods Ecol. Evol. 6, 232–236.
S18. Johnson, T.F., Isaac, N.J.B., Paviolo, A., and González-Suárez, M. (2021). Handling
missing values in trait data. Glob. Ecol. Biogeogr. 30, 51–62.
S19. R Core Team (2021). R: A Language and Environment for Statistical Computing.
S20. Wickham, H. (2016). ggplot2: Elegant Graphics for Data Analysis. (Springer-Verlag).S21. Zuur, A.F., and Ieno, E.N. (2016). A protocol for conducting and presenting results of
regression-type analyses. Methods Ecol. Evol. 7, 636–645.
S22. Muff, S., Nilsen, E.B., O’Hara, R.B., and Nater, C.R. (2021). Rewriting results sections in
the language of evidence. Trends Ecol. Evol. 37, 203–210.
S23. Wasserstein, R.L., Schirm, A.L., and Lazar, N.A. (2019). Moving to a world beyond p <
0.05. Am. Stat. 73, 1–19.
S24. Bates, D., Mächler, M., Bolker, B., and Walker, S. (2015). Fitting Linear Mixed-Effects
Models Using lme4. J. Stat. Softw. 67, 1–48.
S25. Lüdecke, D., Ben-Shachar, M.S., Patil, I., Waggoner, P., and Makowski, D. (2020).
performance: An R Package for Assessment, Comparison and Testing of Statistical
Models. J. Open Source Softw. 6, 3139.
S26. Csardi, G., and Nepusz, T. (2006). The igraph software package for complex network
research. Complex Syst., 1965.
S27. Pedersen, T.L. (2020). tidygraph: A Tidy API for Graph Manipulation.
S28. Hunter, D.R., Handcock, M.S., Butts, C.T., Goodreau, S.M., and Morris, M. (2008). ergm:
A Package to Fit, Simulate and Diagnose Exponential-Family Models for Networks. J.
Stat. Softw. 24, 1–29.
S29. Hunter, D.R., Handcock, M.S., Butts, C.T., Goodreau, S.M., P, K., and Morris, M.(2021).
ergm: Fit, simulate and diagnose exponential-family models for networks. R package
version 4.1.2.SUPPLEMENTAL STATEMENTS
Author contribution
Conceptualization: SM, JM-O, CS, AC; Data collection & validation: all authors; Data analysis &
visualization: SM; Writing (first draft): SM; Writing, contributions: JM-O, CS, AC; All authors
read the text, provided comments, suggestions, and corrections, and approved the final version.
Inclusion and diversity statement
Our data collection was truly a global collective endeavor, involving researchers speaking over 41
languages and representing diverse cultures and ethnicities. Nearly half of the authors are early
career researchers (including undergraduate students), and our author list is unbiased in terms of
gender and covers all continents (including 28 countries in the Global South).
One or more of the authors of this paper self-identifies as an underrepresented ethnic
minority in science. One or more of the authors of this paper self-identifies as a member of the
LGBTQ+ community. One or more of the authors of this paper self-identifies as living with a
disability. One or more of the authors of this paper received support from a program designed to
increase minority representation in science. The author list of this paper includes contributors from
the location where the research was conducted who participated in the data collection, design,
analysis, and/or interpretation of the work.SUPPLEMENTAL DATA AND CODE AVAILABILITY The database used in the analyses is available in FigShare (doi: 10.6084/m9.figshare.14822301) and fully described in an associated data paperS1. The R code to generate analyses and figures is available in GitHub (https://github.com/StefanoMammola/StefanoMammola-Analysis_Spider- News-Network).
You can also read

















































