RD_FA Risorse di Calcolo - Biagio Di Micco Università degli Studi di Roma Tre e INFN Thanks for the inputs to M. Antonelli, P. Azzi , A. Budano ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
RD_FA
Risorse di Calcolo
Biagio Di Micco
Università degli Studi di Roma Tre e INFN
Thanks for the inputs to M. Antonelli, P. Azzi , A. Budano,
M. Boscolo, N. De Filippis, M. Testa
B. Di Micco RD_FA: Risorse di calcolo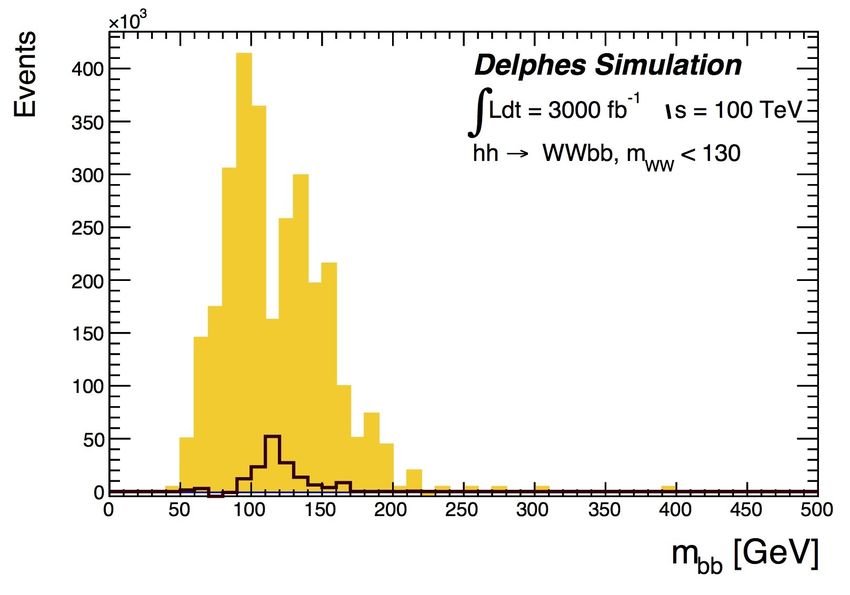
Main activities requiring computing resources
1) Physics studies for FCC-hh at 100/33 TeV
energies
Principal outcome of Rome workshop (April 2016) is to continue
investigation of physics potential of a circular pp collider at 100
TeV energy and compare it with a 33 TeV option.
2) Physics studies for FCC-e+e- at various
energies
Parton level studies and physics potential of lepton collider quite Future Circular Collider Study
in advance, thanks to the linear collider and FCC-ee effort in the GOAL: CDR and cost review for the next ESU (2019)
last decade, it needs now detailed detector design and cost/ International FCC collaboration
(CERN as host lab) to study:
benefit options on the performance side. Also further optimisation• pp-collider (FCC-hh)
of the high energy (higher than the Higgs factory threshold- ZH) main emphasis, defining
infrastructure requirements
options. ~16 T High100 TeVEnergy Muon Accelerator Capabilities
pp in 100 km
Neutrino)Factory)(NuMAX))
3) Machine simulation for Interaction Region • 80-100
in Geneva
km tunnel infrastructure
area(
(((Proton(Driver Front(End( (((Cool?( (((Accelera1on(
ing(
(((! Storage(Ring( ν Factory Goal:
1021 µ+ & µ− per year
#+!
shielding studies • e+e- collider (FCC-ee) as
potential first step 5(GeV(
ν within the accelerator
acceptance
Decay(Channel(
0.2–1( 1–5(
MW?Class(Target(
Phase(Rotator(
ν
Buncher(
Ini1al(Cooling(
Capture(Sol.(
Accumulator(
#−!
SC(Linac(
Buncher(
GeV( GeV(
• p-e (FCC-he) option µ?Collider Goals:
(281m(
126 GeV !
Main Italian activity in this sector is in FCC-ee. • HE-LHC with FCC-hh technology Accelerators:( ~14,000 Higgs/yr
Single?Pass(Linacs(( Multi-TeV !
( Long Baseline NF
Lumi > 1034cm-2s-1
FutureShare
Circular same complex
Collider Study
4) Physics studies for the muon collider options Michael Benedikt
Muon)Collider)
nd
2 FCC Week, Rome, April 2016
(((Proton(Driver( Front(End( (((Cooling( (((Accelera1on(
4
(((Collider(Ring(
Typically doesn’t need huge computing resources, main Italian #+!
ECoM:(
activity is on the test-beam and accelerator side at the moment. (
Higgs(Factory(
Charge(Separator(
Decay(Channel(
MW?Class(Target(
Phase(Rotator(
Ini1al(Cooling(
Buncher(
Capture(Sol.(
#−! to(
Final(Cooling(
Accumulator(
Combiner(
6D(Cooling(
Buncher(
6D(Cooling(
SC(Linac(
~10(TeV(
Merge(
Bunch(
#+! #−!
We will discuss at this workshop the physics studies that needs to Accelerators:(((((
Linacs,(RLA(or(FFAG,(RCS(
be started.
4 Discussion of the Scientific Potential of Muon Beams Nov 18, 2015
B. Di Micco RD_FA: Risorse di calcolo
Physics potential
Higgs of an FCC-hh collider in the hh channel
pair production
SM Dihiggs Dihiggs + 1j Dihiggs + 2j BSM Dihiggs
Effective
Higgs pair Lagrangian
production
Main status discussed at the last 1 ↵s Roma
a
Workshop in April, summarised in the Physics at
a µ⌫
Effective Lagrangian Leff = G G log(1 + h/v )
4 3⇡ µ⌫
FCC-hh collider book: 1https://twiki.cern.ch/twiki/bin/view/LHCPhysics/FutureHadroncollider
↵s a a µ⌫
Leff = Gµ⌫ G log(1 + h/v )
4 3⇡
1 ↵s a a µ⌫ 1 ↵s a a µ⌫ 2
Main interest from 1theL Italian
+ G G
community
µ⌫ h (Bari,
2
G G
Bologna
µ⌫ h , Frascati, Roma Tre)
↵s a a4µ⌫3⇡v 1 ↵s 4 6⇡v
L + G G h Ga Ga µ⌫ h2
3⇡v →
is the study of the4pp µ⌫
hh production
4 6⇡v 2 µ⌫ mechanism.
g g g g
t, b h t, b h
t, b self-coupling
t, b h h
box t, b t, b t, b λ
t, b triangle
t, b h t, b h
t, b h h
g t, b h g t, b
g t, b h g
(a) (b)
2 (a) 4
h h (b)
Higgs potential shape and spontaneous symmetry breaking
In the SM: V (h) = µ2 +
2 4 fix the self-interaction couplings:
h20 ⌘ 2 + ⌘ 4 + h0 ⌘ 3 Measuring the Higgs self-
V(h) 4
m2h =2 h20 coupling is the only way to
h probe the last missing SM
h h h piece: the Higgs potential
h h h
Im(h)
Re(h) di-Higgs production
B. Di Micco RD_FA: Risorse di calcolo
hh decays
hh decay channels
hh→XY branching fractions
The Higgs boson can decay to different final states:
4b, WWbb are the dominant ones
γγbb, ZZbb are the cleanest one
• 4b, γγbb have been already studied in the present
physics-report
• For WWbb there is a feno-paper in the 1-lepton final
state: PRD87 (2013) 0011301 claiming for 4σ
observation with 600 fb-1 @14 TeV, preliminary CMS
results with 3.2 fb-1 of 13 TeV data in the 2-lepton
final state find much worse results [CMS-PAS-
HIG-16-024]
● BR lνjj bb ~ 7% of the total γγbb looks quite strong, but more
30 ab -1
● 4j channel also interesting to exploit,
realistic studies are needed:
results from the
but report
physics overwhelmingΔσ/σ
QCD background
Δλ/λ hh
- full multi-jet background not considered
γγbb 1.3% 2.5% - effect of pile-up on photon isolation
● Main background: 25% not considered
4b 200% - 30 ab-1 could be difficult to achieve
with same final state
(S/B ~2%)
- what about 33 TeV?
● Main discriminant variables:
ZZbb, 4l ~30% ~40%
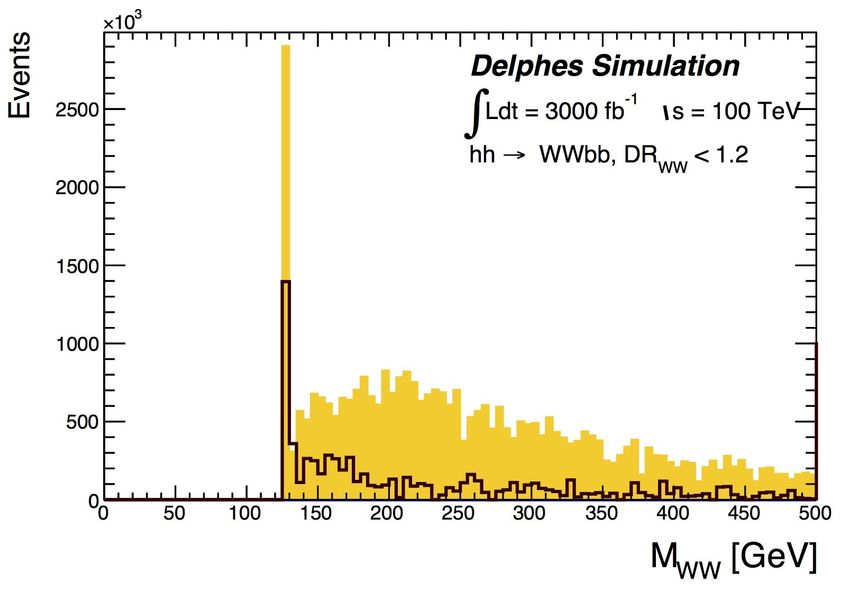
Mbb, ∆Rbb, ∆RWW
● Kinematics can be closed
B. Di Micco RD_FA: Risorse di calcolo
miss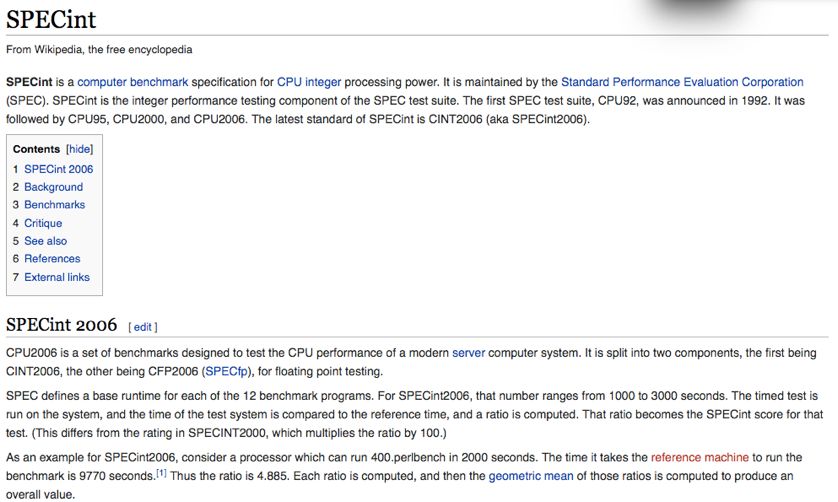
Present experience with computing needs: the hh → WWbb channel
B. Di Micco, M. Testa: FCC-hh workshop, April 2016 Rome [http://fccw2016.web.cern.ch/fccw2016/]
l ν
mW W b ΔRb
b b̄
ΔRW
h
t m mh
h
t W(*)
ΔRb m
m
m l
W(*)
W
ν m
m
ΔRW
q q
q q
• Final state very close to the ttbar background, possible to disentangle only
through the use of many variables.
• Needs simulation of huge amount of ttbar background, difficult to
efficiently filter out the main backgrounds
B. Di Micco RD_FA: Risorse di calcolo
Main production channel cross section at 100 TeV
• gg induced processes show a huge
Nev. expectations at 30 ab-1 cross section increase at 100 TeV;
σ (fb) Nevt • ttbar inclusive statistics is just
t t-bar 3.2⋅107 9.6⋅1011 prohibitive, filter need to be applied at
gg→H 7.4⋅105 2.22⋅1010 Parton Shower level to filter single-
VBF-H 82⋅103 2.46⋅109 lepton events;
ttH 3.8⋅104 1.14⋅109 • present filter efficiencies at ~0.1 level,
hh 1.75⋅103 5.2⋅107 need to exploit tighter filters to reach
hh-WWbb 430 1.29⋅107 a sample size of ~100 M, difficult to
hh-ZZbb 53 1.6⋅106 believe we will be able to do better
than that without affecting
performance studies
Focus on WWbb and ZZbb because in these
channels is the interest of the italian
community
• ~1M -10M events even for the signal only process
B. Di Micco RD_FA: Risorse di calcolo
Pile-up conditions.
Pile-up at FCC-hh
LHC condition FCC-hh condition
at FCC-hh
FCC-hh condition Optimizing integrated luminosity of future hadron colliders, M. Benedikt et. al.
For bunch spacing of 25 ns
Forof 5future
minosity nshadron
bunch spacing
colliders, Pile-up
M. Benedikt et. al. → Pileup / 5
-1
30 ab can be reached
• with 188 pile-up events, 5 ns inter-bunch
Configurations chosen for this study:
spacing in ~10 years
Pile-up = 50 Pile-up at Phase 1 at 5 ns
• with 940 pile-up events, with a 25 ns inter-bunch 6
Pile-up
in ~10 = 200 Pile-up at Phase 1 at 25 ns OR Phase 2 at 5 ns
years
B. Di Micco RD_FA: Risorse di calcolo
→ Pileup / 5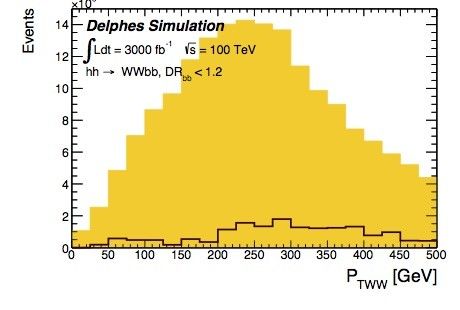
Pile-up simulation in Delphes.
Sampling the minimum-bias file
Minimum bias events
distributing and overlapping
(typically di-jet events with low
particles from each vertex in the
thresholds)
same event
Track all particles build objects
evaluate performances of
apply Pile Up suppression and
several detector configuration/
subtraction technique
reconstruction algorithms
Computing time scales proportionally to the number of simulated pile-up vertices.
Add a factor ~200 -1000 to the baseline ( single-vertex) CPU time simulation needs.
Simulating ~1000 pile-up events is not an unlikely scenario for a 30 ab-1 int. luminosity.
At present, pile-up file with 100.000 minibias events simulated has size: 20 GB, implies the use of the
same events each 100 events for PU~1000.
B. Di Micco RD_FA: Risorse di calcolo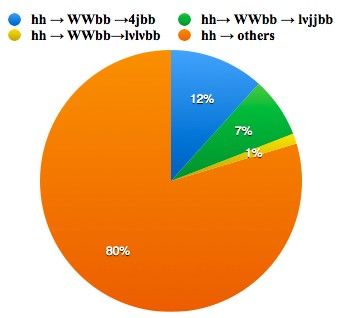
Configuration multipcations Detector parameter varia
Detector parameter variations: Calorimeter resolution Tracks from Pileup are rejected if | z
Need to study different detector configurations and layouts, so manyExpect
simulations are needed.
effects on resolution of jets a
Just an example
Constant
●
from
term driven hh workshop
by requirement studies:
on Multi-TeV physics due to enhanced pile-up contribution
● Here stochastic term is varied
● Factor 2 Up and Down, HCal only Down
Compare our choice = z0 resolution de
Z0 resolution
vs official card = z resolution cons
0
Nominal Calorimeter Resolution conf 1
ECAL Energy resolution HCAL Energy resolution z0 resolution
σ E/E = 10% / √E ⊕ 1% σ E/E = 50% / √E ⊕ 3% in |η|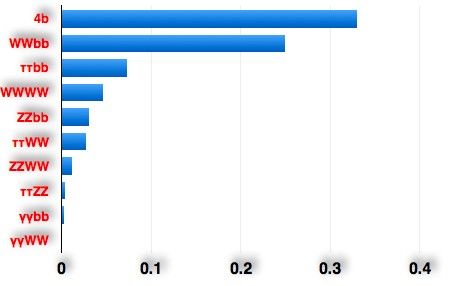
Simulation chain
LHEF: Les Houches
HEPMC file format
Event Files
Madgraph5_aMC@NLO Parton Shower: Pythia8/Herwig++
Delphes: Detector files Root files
W
O
low statistics in ttbar sample,
R
vent selection
present simulation with 12M
K
in of events. Evts LHEF
HEPM root root root
PR C PU50 PU200 PU900
O
G
R
ES t t-bar 10M 5 GB 1.4 Tb 200 GB 1 TB
S
s hh 1M 180M 139 GB 100 GB 100 GB 400 Gb
Multiplying by a factor 10 ttbar and adding
several configurations we get easily ~100 TB per analysis
X 40
Experience in HL-LHC studies:
(N. De Filippis) ~ 10 TB per analysis configuration
Fit to detemine pZν Snowmass physics studies needed ~72 TB
B. Di Micco RD_FA: Risorse di calcoloCPU needs
The whole production was done using Roma Tre Tier-3 cluster, using batch queue system.
Simulation (thanks to A. Budano)
• Typical use 200/300
queued jobs CPU per week, for a
running jobs single analysis
workshop
preparation.
• PU900 simulation just
for signal, for ttbar
would scale by a
factor 10.
• Another factor 10 for
realistic signal
sample simulation.
CPU needs for PU900 simulation ~ 20.000/30.000 cpu per month.
B. Di Micco RD_FA: Risorse di calcoloCPU benchmarks (SpecInt-Wikipedia) A single Roma Tre CPU core has 10 SPECInt, CPU needed is ~200k, 300k SPECInt/month B. Di Micco RD_FA: Risorse di calcolo
The FCC-ee case
The expected yield in this fiducial region, at 240 GeV, is ~ 10 ev/s. The theoretical error, in this angular region, is expected to be at the level of 0.5%. The Z contribution
Thanks to P. Azzi
(interference + Z) at 240 GeV is calculated to be less than 0.2% in the same fiducial region. For sqrt(s)=MZ the Z contribution is 0.47%.
Geometrical effect
Around 5.7 deg (i.e eta ~3.0) the Bhabha cross section varies very steeply: 7% per 0.1 deg. This means that the acceptance region for Bhabha events should be
Many studies already performed in the FCC-ee case, some experience on the size of the
stable/known at the level of 800 um on the front surface of the ECAL endcap in order to stay below 1% systematic uncertainty on luminosity measurement. This can translate
also on the precision with which the vertex position (beam spot) should be known (we are in the region without tracker!): ~1cm.
needed event samples.
Cross sections and resources for production
Studied performed at the Zh resonance: e e → Zh, for 500 fb integrated luminosity.
The cross section at sqrt(s)=240GeV for the main background processes for ZH production are in+
the order
- of 16fb. Dominant are WW and qqbar
production equivalent to 500/fb the resources needs are ~1TB for AOD, 3.5TB for RECO and 16k 8h slots for CPU.
-1 production. Aiming for a
Lep3 Xsec and production resource needs:
Process: e+e > Wev, Pythia (ISUB=36), xs = 1.37 pb, generated ~1000000 events (988,000 useable in /store/user/azzi/LEP3/WENU)
Process: e+e > Zee, Pythia (ISUB=35), xs = 3.8 pb, generated ~2000000 events (1,954,000 useable in /store/user/azzi/LEP3/ZEE)
Process: e+e > Zvv, does not exist in Pythia, PJ implementation added to CMSSW, xs = 25 fb (without Z > vv), generated ~15,000 events (15,000 useable in
Typical size < 10 TB
/store/cmst3/user/pjanot/LEP3/ZNNB)
Process: e+e > qqbar, Pythia (ISUB=1), xs = 50 pb, generated 6,000,000 events (5,998,000 useable in /store/cmst3/user/pjanot/LEP3/QQBAR)
Typical cpu needs
Process: e+e > WW, Pythia (ISUB=25), xs = 16 pb, generated 2,000,000 events (1,970,000 useable in /store/cmst3/user/pjanot/LEP3/WW) < 100 per month
Process: e+e > ZZ, Pythia (ISUB=26), xs = 1.3 pb, generated 1,000,000 events (992,000 useable in /store/user/klute/LEP3/ZZ)
Process: e+e > HZ, Hnunu, He+e, HZHA (with SM BR's), xs = 200 fb, generated 100,000 events (100,000 useable in /store/cmst3/user/pjanot/)
Process: e+e > HZ, with H > invisible, HZHA, (without Z > vv): xs = 158 fb, generated 80,000 events (80,000 useable in /store/cmst3/user/pjanot/HINVIS)
Process: e+e > mu+mu, Pythia (ISUB=1), xs = 4.2 pb, generated 500,000 events (498,000 useable in /store/user/klute/LEP3/Zmm)
Probably same needs
Process: e+e > tau+tau, Pythia (ISUB=1), xs = 4.2 pb, generated 500,000 events (498,000 useable in /store/user/klute/LEP3/Ztt)
Process: e+e > e+e, Pythia (ISUB=1), (s channel only): xs = 4.2 pb, generated 500,000 events (500,000 useable in /store/user/klute/LEP3/Zee)
(less?) for muon colliders
Process: e+e > nu nubar, Pythia (ISUB=1), xs = 11.5 pb, generated 10,000,000 events (498,000 useable in /store/cmst3/user/pjanot/LEP3/NUNUBAR)
The fourjet analysis
B. Di Micco RD_FA: Risorse di calcolo
Aims at measuring the e+e > HZ > bbqq cross section, which amounts to 40 per cent of the total Higgs production cross section. The selection cut flow is as follows.
1. Use ak5PFJets (no pt cut) and reject events with NJets < 4The FCC-ee: IR simulation and backgrounds (M. Boscolo)
Actual effort for the Interaction Region simulation and workplan.
MDI(Work(Plan( Beam(Induced(Backgrounds(
Step)1:( ! Luminosity)sources) Some(cause(backgrounds(due(to(direct(
• Design(a(IR(Layout,(main(constraint(is(from(SR( • Beamstrahlung( beam(losses:(parConclusions: open for discussion
Thanks to G. Carlino for the inputs received
CPU
• CNAF can provide a local queue of ~100, 200 CPU cores, useful for analyse large size entuples
and for MDI needs;
• The only reasonable option for a 200.000-300.000 spec-int per month on the CPU side (needed
for large sample simulation) is using Grid: need to build up an Italian Virtual Organisation;
Disk space
• Possible to have ~1-2 TB of disk space at CNAF;
• our needs are around 100 TB, need to iterate such request at CSN1:
• we can found a temporary solution using dismissing (out of maintenance ) disk space, allows
to have resource immediately available at CNAF while waiting for dedicated assignments;
• possibility to centralise the storage at CNAF: MC output repository for all grid jobs;
• use local resources to build up analysis Storage Element to allow each analysis group to
transfer MC job output locally.
B. Di Micco RD_FA: Risorse di calcoloYou can also read

















































