Navigating to Objects in Unseen Environments by Distance Prediction
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Navigating to Objects in Unseen Environments by Distance Prediction
Minzhao Zhu, Binglei Zhao, Tao Kong
Abstract— Object Goal Navigation (ObjectNav) task is to
navigate an agent to an object instance in unseen environments.
The traditional navigation paradigm plans the shortest path
on a pre-built map. Inspired by this, we propose an object
goal navigation framework, which could directly perform path
planning based on an estimated distance map. Specifically,
our model takes a birds-eye-view semantic map as input, and
arXiv:2202.03735v1 [cs.RO] 8 Feb 2022
estimates the distance from the map cells to the target object
based on the learned prior knowledge. With the estimated
distance map, the agent could explore the environment and
navigate to the target objects based on either human-designed
or learned navigation policy. Empirical results in visually real-
istic simulation environments show that the proposed method Fig. 1. Our method navigates the agent to the target object by predicting
outperforms a wide range of baselines on success rate and the distance to the target. In this example, the agent is required to navigate to
the target "chair". The distance to it can be estimated based on the observed
efficiency.
object "table". A mid-term goal can be selected by finding the shortest path
to the target object based on a predicted distance map. As the agent explores,
I. INTRODUCTION the distance map becomes more and more accurate, and finally, the agent
will reach the target object.
Object Goal Navigation (ObjectNav) [1] is one of the
fundamental embodied navigation tasks. In this task, an By learning to predict the distance to the target given the
intelligent agent is required to move to the location of a target explored semantic map, the model is encouraged to capture
object category in an unseen environment. In traditional the spatial relations between different semantics. Recent
navigation tasks, under normal circumstances, the map of works utilize semantic scene completion to model that prior
the environment is constructed in advance. Therefore, a goal knowledge [41], [42], and have achieved good performance.
location can be given to the agent in the form of coordinates However, it is difficult, even for humans, to predict the exact
on that map. However, in the ObjectNav task, a pre-built map location of related objects. For example, although we know
is unavailable, and the exact goal coordinate is unknown. chairs may be close to tables, we cannot predict the chair’s
Therefore, the agent has to set long/short term goals for itself relative pose to the table accurately, since the chair could be
in order to explore the environment and find the target object. placed anywhere around that table. In contrast, the distance
During searching, there are many possible areas to be between the chairs and tables does not vary too much, which
explored. How to prioritize these candidate goals so as to is relatively easier to learn.
improve exploration efficiency? Obviously, in a new environ- Our navigation framework consists of three parts. First,
ment, the only information we can use is the knowledge we given the RGB-D image and the agent’s pose, a birds-eye-
have learned in other similar environments, like the spatial view semantic map is incrementally built. Then, based on
relations between objects. With this kind of commonsense, the semantic map, a target distance map is predicted. This
humans tend to explore the object that is usually close to distance map is fed to the local policy to get an action.
the target object. For example, if our target is a chair, we Since the model’s output is the estimated distance to the
should explore around a table first, while temporarily skip target, it can be easily integrated into either a traditional path
other regions. This is because we know chairs are often planning algorithm or a learned navigation policy. Although
adjacent to tables; thus, if we move toward the table, it is deep Reinforcement Learning (RL) policy can be used, we
more likely to find a chair in that area than other directions use several simple goal-select strategies and path planning
away from that table. If we are able to incorporate this kind algorithms to show the effectiveness of the distance map.
of prior knowledge into a spatial map, we can transform the We perform experiments in the Matterport3D dataset using
ObjectNav task into a traditional navigation problem. the Habitat simulator. Our method outperforms the baseline
Inspired by this, we propose a navigation framework based [4] method with an improvement of 2.6% success rate and
on target distance prediction. The Target Distance Prediction 0.035 SPL (Success weighted by normalized inverse Path
model, the core module in our system, takes a birds-eye- Length) [5].
view semantic map as input, and estimates the distance from
the map cells to the target object to form a distance map. II. RELATED WORK
A. Active SLAM
Minzhao Zhu and Binglei Zhao contribute equally. ByteDance
AI Lab, Beijing, China. {zhaobinglei, zhuminzhao, Given a specific goal location, the classical navigation
kongtao}@bytedance.com methods [6], [7] focus on building maps using the passive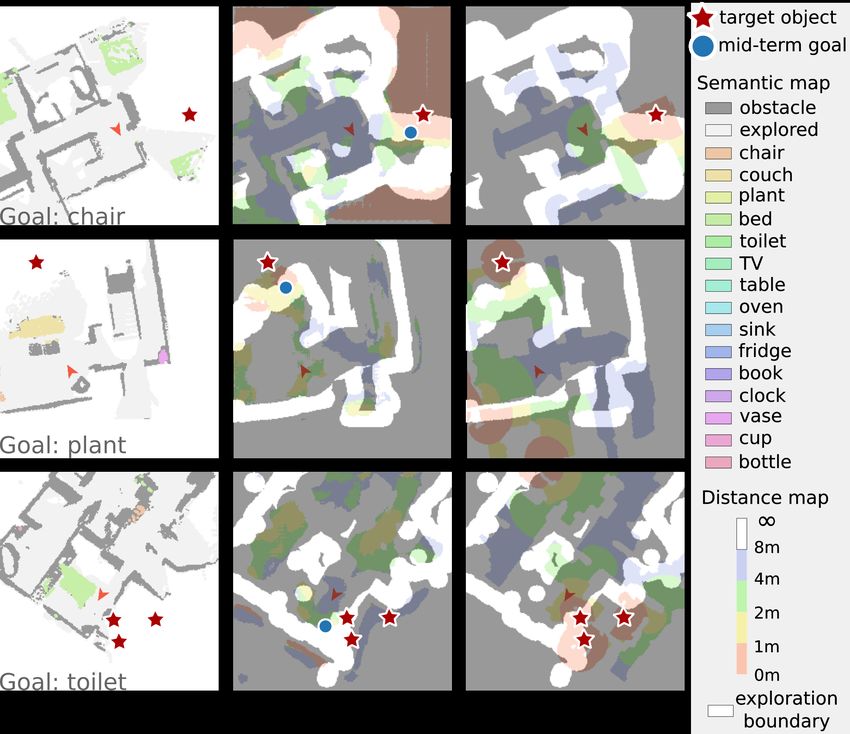
Fig. 2. System Overview. Our method consists of a semantic mapping module, a target distance prediction model, and a local policy. Given the RGB-D
observation and the agent’s pose, the Semantic Mapping Module builds a birds-eye-view semantic map. Then, the Target Distance Prediction Model
predicts the distance to the target object on the cells around the exploration boundaries. Based on the distance map, the Local Policy chooses a mid-term
goal and gets an action.
SLAM approaches [11], and path planning [8]–[10] based the ObjectNav task as target distance prediction and path
on the previously constructed map. However, Active SLAM planning. Our work explicitly predicts the distance from the
[12], [13] aims to explore unknown experiments and build exploration boundary (the region between the explored and
maps automatically, which is a decision-making problem unexplored area) to the target, and uses this information to
tightly coupled by localization, mapping, and planning. guide the agent to search the target.
Some methods [14], [15] formulate this problem as the
POMDP (Partially Observable Markov Decision Process) III. APPROACH
[49]. Recently, some researchers have designed learning- As shown in Fig. 2, our method consists of three modules:
based policies [17]–[24] to tackle this problem. Chaplot et a semantic mapping module, a target distance prediction
al. [18] propose a novel module that combines a hierarchical model, and a local policy. The input of our system is the
network design and classical path planning, which signif- RGB-D images and the agent pose; the output is the next
icantly improves the sample efficiency and leads to better action. The RGB-D observation and the agent pose are used
performance. at each time step to update the birds-eye-view semantic
map. Then, based on the semantic map and the learned
B. Learning-based Goal Navigation Methods prior knowledge, the distance prediction model estimates the
While Active SLAM is to explore the environment effi- distance from the exploration boundary (the region between
ciently, the task of goal navigation is to find a given target the explored and unexplored area) to the target. According
in an unknown environment [25]. Most of the approaches fall to the distance map, the local policy selects a mid-term goal
into the following three groups: map-less reactive methods, and gets the next action using a path planning method.
memory-based methods, and explicit map-based methods. Although the distance prediction may not be correct
Inspired by deep reinforcement learning [16], Zhu et al. enough in the beginning, as the agent moves and receives
[25] propose a map-less reactive method to produce actions more observation, the semantic map expands, the predicted
using a siamese actor-critic network. In contrast, Dosovitskiy distance map updates and becomes more accurate. With the
et al. [26] construct a network that uses supervised learning update of the distance map, the agent could automatically and
techniques to map the measurements, observed images, and implicitly switch from random exploration to target searching
goal inputs into actions. To fully utilize the long-term history, and approaching, thus reach the target object eventually.
some researchers store information using external memory, In section III-A we briefly describe the Semantic Mapping
such as LSTM [27]–[32], GRU [53], episodic memory [33], module. Section III-B gives the definition of the target
relational memory [34], [35] and transformers [36], [37]. distance map and presents our model. In section III-C, we
Recent works explicitly construct the map to store and describe the details of the local policy.
utilize spatial representations. Most of the works utilize the
semantic grid maps [4], [40]–[42], [48] or topological maps A. Semantic Mapping
[38], [39] to represent spatial information. POMP++ [48] We follow SemExp [4] to build a birds-eye-view semantic
explore the boundary of unknown cells in environment maps map. The semantic map is k × h × w where h × w denotes
to calculate the planning policy based on POMDP [49]. the map size; k = cS + 2, where cS is the total number
Recent works explicitly model scene priors by anticipating of semantic categories and the other 2 channels represent
elements out of sight to guide the agent to explore the target. obstacles and explored area. In practice, we set the size of
Liang et al. [41] design a semantic scene completion module each cell in the semantic map to be 5cm × 5cm.
to complete the unexplored scene. Similar to it, some meth- Given the RGB-D image and the agent’s pose, we use a
ods achieve image-level extrapolation of depth and seman- pre-trained Mask-RCNN to predict semantic categories on
tics [45], high-dimension feature space extrapolation [46], the RGB image and then get a 3D semantic point cloud
semantic scene completion [42], [43], attention probability in the camera coordinate system using depth observation
modeling [44], and room-type prediction [47]. We formulate and camera intrinsics. The point cloud is transformed to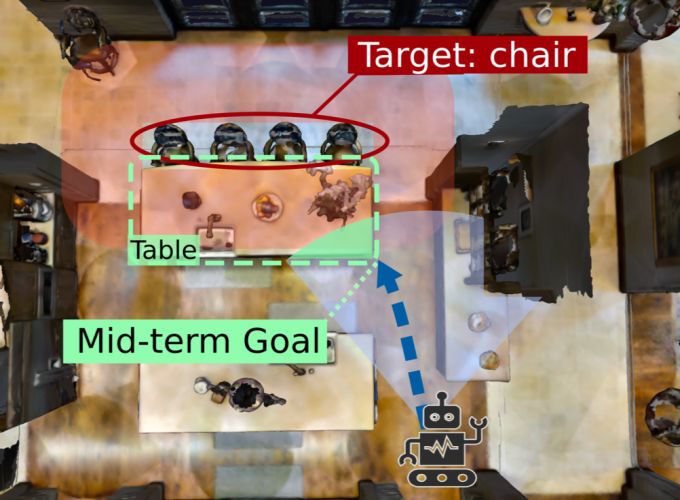
Fig. 3. Terminology Illustration. The red and orange cells denote the
current agent’s position and its previous footprints in both figures. The grey
cells indicate the explored area, and the blue cells represent the boundary
Bexp between the explored and unexplored area. Black cells indicate
obstacles. Left: Integrating Distance Prediction with Path Planning. The
numbers within the boundary Bexp illustrate the target distance predicted by
our model (e.g., the length of the blue dotted line). Based on the predicted
distance values within Bexp , the path planning algorithm can find the
optimal path (green line) to move closer to the target (the red star). Right: In Fig. 4. Target Distance Ground Truth Map Example. The first row is the
the Door-Exploring-First strategy, if the agent observes a door or a passage semantic GT map; the second row is the continuous distance map (darker
(green cells), the intersection of a sector with angle θd and the boundary color corresponds to smaller distance value) and the discrete distance GT
Bexp is defined as Bd (yellow cells). map for goal category ‘TV’.
the global coordinate and projected to the ground to get the within the traversable areas are calculated and split into
semantic map. corresponding bins. When collecting the training data, we
randomly initialize the agent’s position and perform random
B. Target Distance Prediction exploration (details are in the baselines part in Sec. IV-A)
Target Distance Map Definition: The target distance map in the environment. The local GT distance map is cropped
has the same map size and cell size as the semantic map. It from the global GT map according to the agent’s pose.
stores the shortest distance the agent will travel to reach the Besides, it is redundant to predict the distance value within
target object. We define the distance value as zero for the the explored area. Since the obstacles and semantics are
cells inside the target object and infinite for the cells inside already known in the explored area, the distance to the target
other obstacles except for those who contain the target (e.g., can be obtained for cells within the explored area if the target
the table where a target object is on it). object is observed. On the other hand, if the target is out of
The input of our target distance prediction model is the view, the distance map within the explored area can also be
local semantic map LS , which is k × 240 × 240. Our model calculated based on the distance value around the exploration
is required to predict a local target distance map LD based boundaries (the blue area in Fig. 3). Therefore, we train our
on LS at each time step. In order to predict the distance to model using the pixel-wise Cross-Entropy loss only between
the target based on the explored semantic map, the model the predicted distance bin category and the ground-truth label
has to learn the spatial relations between different semantics within the exploration boundaries.
(e.g., chairs often near a table). Since estimating the exact C. Local Policy
distance to the target is difficult, we formulate this problem
as a classification problem instead of a direct regression Our local policy consists of two parts: a mid-term goal
problem. We split the distance into nb discrete bins, so each selection strategy and a path planner. At each time step,
bin corresponds to a distance range. In this paper, we set the the goal selection strategy chooses mid-term goals on the
number of discrete bins nb = 5, and the partition detail is local semantic map LS based on the local target distance
shown in Fig. 4. map LDis . Although RL policy can be used, we design
Our model is a fully convolutional neural network with several simple strategies to demonstrate the effectiveness of
3 downsample ResBlocks [50], 3 upsample ResBlocks, and the distance map. Following [4], we use the Fast Marching
concatenating low-level feature map and upsampled feature Method (FMM) [51] algorithm to plan a path based on
map on each level. The output is the local target distance the obstacle channel of LS . Finally, an action is selected
map LD for the target. Although one can also choose to according to the planned path.
predict a nb channel distance map conditioned on the target To obtain a mid-term goal, we design three strategies:
category, in this paper, we set the output channel as nb × nT , 1) Integrating with Path Planning: As we can estimate
where nT is the number of target categories. In this way, the distance to the target for the cells around the exploration
every nb channels form a group, responsible for predicting boundaries, we can plan a path with the smallest length
the distance map of a certain target, so the distance prediction from the current position to the target object. Given the
of all the target categories could be trained simultaneously. distance map LD and the exploration boundary, we can get
Training: As shown in Fig. 4. The ground-truth (GT) the position of the mid-term goal
target distance map is generated based on the GT semantic pgoal = arg min{d(pagent , p) + LDis (p)}, (1)
map and traversable map. The distance values for the cells p∈Bexp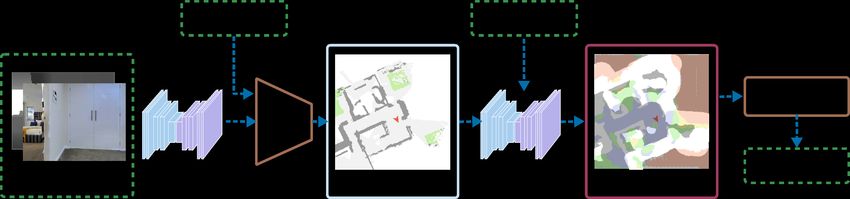
where pagent is the current agent’s position on the local map, [4] to set nT = 6 object goal categories: ‘chair’, ‘couch’,
LDis (p) is the predicted distance value on the position p, ‘plant’, ‘bed’, ‘toilet’, and ‘TV’. Same as [4], the semantic
d(pagent , p) is the distance to the current position, which map has cS = 15 categories; the global semantic map size
can be obtained by the path planning algorithm based on the is 480 × 480 (24m × 24m).
obstacle map, Bexp is the area around the current exploration During training, we use 1.2 million steps to train our
boundary (see Fig. 3). At each time step, the exploration area model. We use pixel-wise Cross-Entropy loss within the
is expanded as the agent moves, so a new mid-term goal is area of 1m distance to the exploration boundaries. The loss
selected on the new Bexp based on the updated LDis (p). If weight for the distance bins from 1m to infinite is set as
all the predicted distance values in Bexp are infinite , the from 5 to 1. Adam optimizer is used with a learning rate of
random exploration is adopted. If there is a target object on 0.00001. During evaluation, we split the scene into several
the semantic map (meaning that the target object is found), floors according to the scene graph label of MP3D. For each
the area of the target object is selected as the mid-term goal. scene, we first uniformly sample a floor, and then sample
2) Closest-First Strategy: This strategy makes a little the goal among all the targets categories available on this
change to the above strategy by simply choosing the mid- floor. The agent is randomly initialized at the position with
term goal a distance margin to the target. In this way, we sample a
pgoal = arg min LDis (p), (2) total of 1200 test episodes. The maximum length for each
p∈Bexp
episode is 500 steps, and the success threshold is 1m. We
which means we tend to go to the position where the use 2 metrics to evaluate the performance of ObjectNav:
predicted distance value is the smallest, regardless of the • Success Rate: The ratio of the episode where the agent
agent’s current position. successfully reaches the goal;
3) Door-Exploring-First Strategy: When an agent faces a • SPL [5]: Success weighted by normalized inverse Path
door or a passage leading to another room, it is more efficient Length, which measures the efficiency of finding the
to explore that room if the distance value in that room is goal.
smaller (which means the agent might see some objects We compare our method with the following baselines:
related to the target through the opened door). Considering 1) Random Exploration: Instead of random walk, we
that, we design the door-exploring-first strategy based on the design a simple strategy to urge the agent to explore the
closest-first strategy. The strategy first classifies whether a environment randomly. We set the mid-term goal as one of
door or a passage is in the observed RGB image through a the corners of the local map. With the change of local map
classification network based on ResNet50. If true, we obtain boundaries due to the agent’s movement, the mid-term goal
the area that the door (passage) might lead to, that is, the also changes with the boundaries. This goal is periodically
area where the angle between the current orientation of the switched clockwise among four corners per 100 steps. We
agent is less than θd , as demonstrated in Fig. 3. Then we also adopt this method to collect our training data, and it
obtain the intersection of this area and the boundary Bexp , also serves as a supplement to our goal select strategy as
which is defined as Bd . Then we select the mid-term goal mentioned in section III-C.
arg minp∈Bd LDis (p) pdoor ≥ 0.5, Bd 6= ∅ 2) SemExp [4]: SemExp consists of a semantic mapping
pgoal = , module, an RL policy deciding mid-term goals based on the
arg minp∈Bexp LDis (p) others
semantic map, and a local path planner based on FMM [51].
where pdoor means the probability of containing a door The difference between it and our method is the way to select
(passage). During training, we use the cross-entropy loss to mid-term goals. Specifically, we utilize the target distance
train the door classifier. In the experiment, we find that when map rather than the semantic map and an RL policy.
θd is small, the agent may change its heading direction after 3) Semantic Scene Completion (SSCExp): Following
reaching the door, leading to walking back and forth at the SSCNav [41], we utilize 4 down-sampling residual blocks
same position. Therefore, in practice, we set θd as 120°. and 5 up-sampling residual blocks to build the scene com-
After generating a mid-term goal with one of the strate- pletion and confidence estimation module. It predicts the full
gies, we use the FMM [51] algorithm to get the path, semantic map and confidence map from the observed map
because the distance map used in this algorithm can be constructed by the semantic mapping module. We add this
easily obtained based on our target distance map LDis . One semantic scene completion module to SemExp [4]. Then the
can also use other path planning algorithms like A∗ [52]. RL policy generates a mid-term goal based on the completed
Note that if LDis is accurately predicted, the ObjectNav maps.
task will become a traditional navigation task, since the goal
coordinate can be viewed as known. B. Main Results
Tab. I shows the ObjectNav result of our method. Ours-PP
IV. EXPERIMENTS
indicates the strategy integrating with Path Planning, Ours-
A. Experimental Setup CF is the Closest-First strategy, Ours-DEF corresponds to the
We perform experiments on the Habitat [2] platform with Door-Exploring-First strategy. Ours-GT indicates using local
Matterport3D (MP3D) [3] dataset. The training set consists ground-truth semantic maps instead of the constructed map
of 54 scenes and the test set consists of 10 scenes. We follow and Closest-First strategy. Ours-PP has the highest success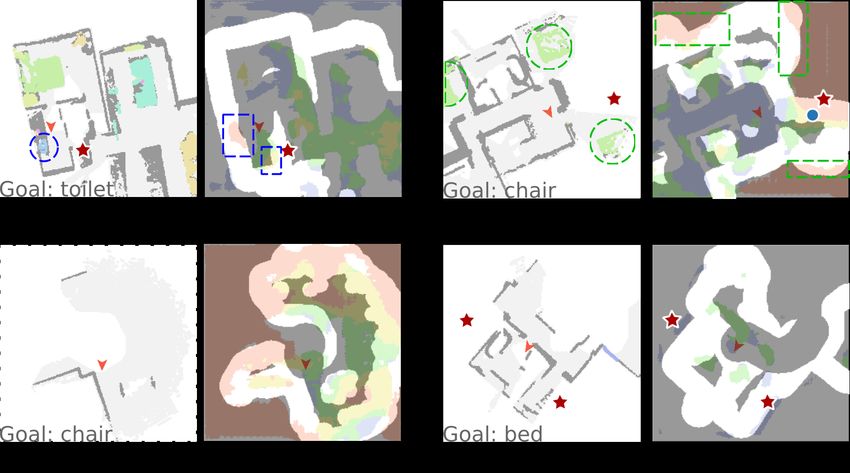
TABLE I
O BJECT G OAL NAVIGATION R ESULT (S UCCESS R ATE↑ / SPL↑). -GT: USING LOCAL GT SEMANTIC MAPS . -PP: INTEGRATING WITH PATH P LANNING ,
-CF: C LOSEST-F IRST STRATEGY, -DEF: D OOR -E XPLORING -F IRST STRATEGY. † MEANS OUR REIMPLEMENTATION .
Method Chair Couch Plant Bed Toilet TV Avg.
SemExp-GT [4] 0.888/0.627 0.730/0.518 0.585/0.409 0.597/0.411 0.790/0.476 0.910/0.666 0.755/0.522
SSCExp-GT [41]† 0.854/0.625 0.717/0.526 0.623/0.432 0.572/0.415 0.783/0.484 0.899/0.694 0.744/0.531
Ours-GT 0.880/0.687 0.735/0.590 0.637/0.478 0.610/0.393 0.841/0.514 0.876/0.635 0.768/0.566
RandomExp 0.566/0.257 0.398/0.174 0.358/0.157 0.421/0.246 0.305/0.158 0.000/0.000 0.403/0.193
SemExp [4] 0.622/0.289 0.385/0.220 0.344/0.141 0.415/0.213 0.280/0.124 0.000/0.000 0.410/0.197
SSCExp [41]† 0.560/0.294 0.292/0.146 0.349/0.175 0.308/0.138 0.229/0.138 0.000/0.000 0.354/0.177
Ours-PP 0.639/0.290 0.389/0.179 0.387/0.119 0.490/0.252 0.312/0.109 0.011/0.021 0.438/0.190
Ours-CF 0.611/0.353 0.412/0.254 0.387/0.156 0.421/0.238 0.338/0.147 0.011/0.002 0.428/0.231
Ours-DEF 0.630/0.346 0.438/0.258 0.368/0.162 0.447/0.240 0.312/0.154 0.011/0.003 0.436/0.232
Fig. 6. Prediction Failure Cases Example. The left images of each
example are the semantic maps. The images on the right show the predicted
distance map. Upper left: based on the observed object "sink" (blue dot
circle), the direction prediction of the target "toilet" is wrong (blue dot box).
Upper right: it also predicts the target "chair" has a "< 1m" distance (green
dot box) around the other two beds (green dot circle), because it can not
decide whether there is a chair near a bed unless having explored all the area
around the bed. Bottom row: our model is not able to predict the distance
Fig. 5. Prediction Example. Our model can guide the agent to the target due to the lack of semantic prediction (no object around the agent (bottom
object since the predicted directions are correct. From left to right are: local left), or the semantic model can not detect the object (bottom right)).
semantic maps, predicted local distance maps, and local distance GT maps.
The red star denotes target objects. The blue dot corresponds to the mid-
term goal. The red arrow denotes the agent’s pose. The non-shaded area in larger than [41] (6m × 6m), causing it difficult to complete
the distance map indicates the area of exploration boundaries Bexp . the scene in the local map.
How does the target distance map work? We test the
rate but low SPL; this is because the noise of the distance quantitative performance of our model during the whole
map makes the agent follow a zigzag route, increasing the process of navigation. As shown in Tab. II, the performance
total path length. Ours-DEF has a good success rate and the is surprisingly low. Nevertheless, our model can still guide
best efficiency. the agent to the target object because the predicted directions
Comparison with Baseline Methods. As shown in Tab. to the target are correct (see Fig. 5). If the model predicts
I, our method outperforms the baseline method SemExp a relatively small distance in the direction toward the target
[4] (+2.6% in success rate, +3.5% in SPL). The result compared with other directions, the agent can still reach the
demonstrates that the target distance map can guide the agent target.
to the target object more efficiently. It can be seen that all We further studied some wrong predictions. In Fig. 6 upper
methods’ success rates and SPL of target ’TV’ are close left, based on the observed object "sink" (blue dot circle), the
to 0. Comparing with the performance using GT semantic direction of the target "toilet" is wrong (blue dot box). In
maps, we can attribute this phenomenon to the unsatisfying Fig. 6 upper right, it predicts the target "chair" has a "< 1m"
performance of the semantic model. As mentioned in [48], distance (green dot box) around the other two beds (green
the 3D reconstruction quality in some MP3D scenes is not dot circle), but in fact, there are no chairs around them.
gratifying. After eliminating the factor of semantic mapping It demonstrates that our model has successfully learned the
by using GT semantic maps, the SPL of our method exceeds knowledge that "chairs may be close to beds." Nevertheless,
SemExp [4] by 4.4%. As for the baseline based on semantic unfortunately, we can not decide whether there is a chair near
scene completion, the performance of SSCExp is relatively a bed unless we have explored all the area around the bed.
poor in our experiment. Note that our setting is different from On the contrary, determining a target object is NOT near an
[41] in camera angle, semantic map size, semantic categories, unrelated object is much easier. This may, to some extent,
target categories, etc. We suscept the reason for the poor explain why the performance for the categories " 8m" category in Tab.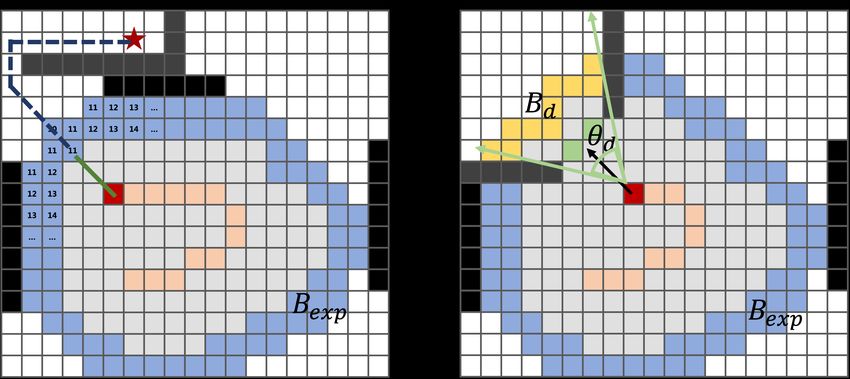
TABLE II
P ERFORMANCE OF D ISTANCE P REDICTION M ODEL
Distance 8m Avg.
Precision 0.045 0.193 0.078 0.109 0.844 0.254
Recall 0.354 0.081 0.064 0.047 0.842 0.278
TABLE III
NAVIGATION R ESULTS OF D IFFERENT R EPRESENTATIONS
Representation Partition (m) Success Rate↑ SPL↑
[1,2,4,8,∞] 0.428 0.231
[1,2,4,∞] 0.416 0.226
Discrete [1,2,∞] 0.417 0.231
[1,∞] 0.405 0.226
[2,4,8,12,∞] 0.390 0.209
Continuous - 0.412 0.204
II is satisfying. Fig. 6 bottom row shows the cases that our
model is not able to predict the distance due to the lack of
semantic prediction. This often happens when there is no
object around the agent (Fig. 6 bottom left), or the semantic
model can not detect the object (Fig. 6 bottom right). This
is also a reason for the low performance in Tab. II.
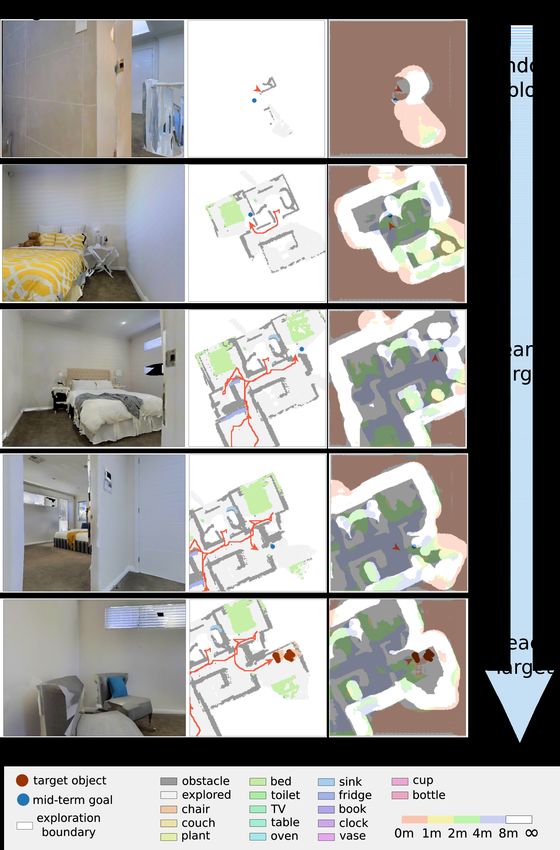
Fig. 7 illustrates how our method navigates to the target
object with the help of the target distance map. In the
beginning, the target distance prediction is random or invalid
(Fig. 7 row 1), because there are few objects on the semantic
map, or because the target is far from the agent. The agent
can be seen as random exploration during this phase. As the Fig. 7. ObjectNav demonstration. With the help of the target distance
agent explores and receives more observation, the predicted map, the agent first randomly explores, then searches the target around
distance map begins to predict the target distance distribution related objects (bed), and finally reaches the target (chair). From left to
right are RGB observations, semantic map, and predicted distance map.
more accurately and guide the agent toward the direction of The red arrow indicates the agent pose. The red line denotes the navigation
the potential target to search (in Fig. 7 row 2-3, the agent is path.
looking for chairs around beds). If there is no target in the
supposed direction, the distance map is corrected based on random exploration in the beginning. If it chooses a wrong
the new semantic map, and the agent will head to another direction, it will take considerable steps to get back, leading
direction with a low target distance. If the distance map is to failure to reach the target within 500 steps. Besides, the
correct, the agent will reach the target (Fig. 7 row 4-5). global map (24m × 24m) can not cover the whole area of
Continuous or Discrete Representation for Target Dis- the scene, so the agent may go out of the map boundary and
tance Map. In the target distance prediction model, we causes planning failure. Thirdly, sometimes the agent gets
formulate it as the category classification problem. We also stuck, which may happen when there are obstacles invisible
design a regression framework to predict the continuous on the depth image. Finally, we also find some cases similar
distance. Tab. III shows the result of different representations to the failure modes "Goal Bug," "Void" mentioned in [53].
using the Closest-First Strategy. The best result of discrete
representation achieves a higher Success Rate and SPL than V. CONCLUSIONS
predicting the continuous distance. The result indicates that
although the distance to a target is continuous, predicting This paper presents a navigation framework based on
a precise value is not easy. Besides, the result of different predicting the distance to the target object. In detail, we
distance partitions indicates that bins of larger distance play design a model which takes a birds-eye-view semantic map
a less important role than smaller distance. as input, and estimates the distance from map cells to the
target. Based on the distance map, the agent could navigate
C. Failure Cases to the target objects with simple goal selection strategies and
Firstly, most failure cases are due to low semantic map a path planning algorithm. Experimental results on the MP3D
accuracy. Sometimes the semantic model can not detect the dataset demonstrate that our method outperforms baselines
object, and sometimes there is wrong detection or wrong methods on success rate and SPL. Future work would focus
projection to the ground due to the semantic segmentation on predicting the target distance map more accurately, like
noise or depth image noise. Secondly, it is hard to success- using the room-type prediction as auxiliary tasks. We believe
fully find the target in large environment. The reasons are that with a more powerful target prediction model and RL
two folds. As mentioned above, the agent tends to perform policy, our method will achieve much better performance.R EFERENCES [25] Y. Zhu, R. Mottaghi, E. Kolve, J. J Lim, A. Gupta, Li Fei-Fei, and A.
Farhadi. Target-driven visual navigation in indoor scenes using deep
[1] D. Batra, A. Gokaslan, A. Kembhavi, O. Maksymets, R. Mottaghi, M. reinforcement learning. In International Conference on Robotics and
Savva, A. Toshev, and E. Wijmans. ObjectNav Revisited: On Evalua- Automation(ICRA), 2017.
tion of Embodied Agents Navigating to Objects. In arXiv:2006.13171, [26] Alexey Dosovitskiy, Vladlen Koltun. Learning to Act by Predicting
2020. the Future. In International Conference on Learning Representations
[2] M. Savva, A. Kadian, O. Maksymets, Y. Zhao, E. Wijmans, B. Jain, J. (ICLR), 2017.
Straub, J. Liu, V. Koltun, J. Malik, D. Parikh, and D. Batra. Habitat: [27] Junhyuk Oh, Valliappa Chockalingam, Satinder Singh, Honglak Lee.
A Platform for Embodied AI Research. In International Conference Control of Memory, Active Perception, and Action in Minecraft. In
on Computer Vision, 2019. International Conference on Machine Learning (ICML), 2016.
[3] A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, [28] Piotr Mirowski, Razvan Pascanu, Fabio Viola, Hubert Soyer, et al.
S. Song, A. Zeng, and Y. Zhang. Matterport3D: Learning from RGBD Learning to Navigate in Complex Environments. In International
data in indoor environments. In arXiv:1709.06158, 2017. Conference on Learning Representations (ICLR), 2017.
[4] D. S. Chaplot, D. Gandhi, A. Gupta, and R. Salakhutdinov. Object [29] A. Mousavian, A. Toshev, M. Fiser, J. Kosecka, and J. Davidson.
goal navigation using goal-oriented semantic exploration. In Neural Visual representations for semantic target driven navigation. arXiv
Information Processing Systems (NeurIPS), 2020. preprint arXiv:1805.06066, 2018.
[5] P. Anderson, A. X. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V. [30] J. Zhang, L. Tai, J. Boedecker, W. Burgard, and . Liu. Neural
Koltun, J. Kosecka, J. Malik, R. Mottaghi, M. Savva, and A. R. Zamir. slam: Learning to explore with external memory. arXiv preprint
On evaluation of embodied navigation agents. In ArXiv: 1807.06757, arXiv:1706.09520, 2017.
2018. [31] Y. Wu, Y. Wu, G. Gkioxari, and Y. Tian. Building generalizable agents
[6] Sebastian Thrun, Wolfram Burgard, and Dieter Fox. Probabilistic with a realistic and rich 3d envi- ronment. CoRR, abs/1801.02209,
Robotics. MIT Press, 2005. 2018.
[7] J. Borenstein, B. Everett, and L. Feng. Navigating Mobile Robots: [32] Mitchell Wortsman, Kiana Ehsani, Mohammad Rastegari. Learning to
Systems and Techniques. A. K. Peters, Ltd., Wellesley, MA, 1996. Learn How to Learn: Self-Adaptive Visual Navigation using Meta-
[8] Steven M LaValle. Planning algorithms. Cambridge university press, Learning
2006. [33] Alexander Pritzel, Benigno Uria, Sriram Srinivasan, et al. Neural
[9] P. E. Hart, N. J. Nilsson, and B. Raphael. A formal basis for the Episodic Control. In International Conference on Machine Learning
heuristic determination of minimum cost paths. In IEEE transactions (ICML), 2017.
on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968.
[34] Yi Wu, Yuxin Wu, Aviv Tamar, et al. Bayesian Relational Memory for
[10] S. Karaman and E. Frazzoli.‘ Sampling-based algorithms for optimal Semantic Visual Navigation. In International Conference on Computer
motion planning. In International Journal of Robotics Research (IJRR), Vision (ICCV), 2019.
vol. 30, no. 7, pp. 846–894, 2011.
[35] Yiding Qiu, Anwesan Pal, Henrik I. Christensen. Target driven vi-
[11] J.J. Leonard and H.F. Durrant-Whyte. Simultaneous map building and
sual navigation exploiting object relationships. In IEEE International
localization for an autonomous robot. In IEEE International Workshop
Conference on Intelligent Robots and Systems(IROS), 2020.
on Intelligent Robots and Systems(IROS), 1991.
[36] Kuan Fang, Alexander Toshev, Li Fei-Fei, Silvio Savarese. Scene
[12] A. A. Makarenko, S. B. Williams, F. Bourgault and H. F. Durrant-
Memory Transformer for Embodied Agents in Long-Horizon Tasks. In
Whyte. An Experiment in Integrated Exploration. In IEEE Interna-
IEEE/CVF International Conference on Computer Vision and Pattern
tional Conference on Intelligent Robots and Systems(IROS), 2002.
Recognition (CVPR), 2019.
[13] W. Burgard, D. Fox, and S. Thrun. Active mobile robot localization. In
Proceedings of the 1997 International Joint Conferences on Artificial [37] Tommaso Campari, Paolo Eccher, Luciano Serafini, and Lamberto
Intelligence, pp. 1346–1352, 1997. Ballan. Exploiting Scene-specific Features for Object Goal Navigation.
In Proceedings of the European Conference on Computer Vision
[14] L. P. Kaelbling, M. L. Littman, and A. R. Cassandra. Planning and act-
(ECCV), 2020.
ing in partially observable stochastic domains. Artificial Intelligence,
101(12):99–134, 1998. [38] Nikolay Savinov, Alexey Dosovitskiy, Vladlen Koltun. Semi-
[15] R. Martinez-Cantin, N. Freitas, E. Brochu, J. Castellanos, and A. Parametric Topological Memory for Navigation. In International Con-
Doucet. A bayesian exploration-exploitation approach for optimal ference on Learning Representations (ICLR), 2017.
online sensing and planning with a visu- ally guided mobile robot. [39] D. S. Chaplot, R. Salakhutdinov, A. Gupta, S. Gupta. Neural Topo-
Autonomous Robots, 2009. logical SLAM for Visual Navigation. In IEEE/CVF International
[16] F Zeng, C Wang, SS Ge. A survey on visual navigation for artificial Conference on Computer Vision and Pattern Recognition (CVPR),
agents with deep reinforcement learning. IEEE Access 8, 135426- 2020.
135442, 2020. [40] Saurabh Gupta, James Davidson, Sergey Levine, et al. Cognitive Map-
[17] T. Chen, S. Gupta, A. Gupta. Learning exploration policies for naviga- ping and Planning for Visual Navigation. In IEEE/CVF International
tion. In International Conference on Learning Representations(ICLR), Conference on Computer Vision and Pattern Recognition (CVPR),
2019. 2017.
[18] D. S. Chaplot, D. Gandhi, S. Gupta, A. Gupta, R. Salakhutdinov. [41] Yiqing Liang, Boyuan Chen, Shuran Song. SSCNav: Confidence-
Learning to Explore using Active Neural SLAM. In International Aware Semantic Scene Completion for Visual Semantic Navigation. In
Conference on Learning Representations(ICLR), 2020. International Conference on Robotics and Automation(ICRA), 2020.
[19] N. Savinov, A. Dosovitskiy, and V. Koltun. Semi-parametric topolog- [42] G. Georgakis, B. Bucher, K. Schmeckpeper, S. Singh, K. Dani-
ical memory for navigation. In International Conference on Learning ilidis. Learning to Map for Active Semantic Goal Navigation. In
Representations (ICLR), 2018. arXiv:2106.15648, 2021.
[20] N. Savinov, A. Raichuk, R. Marinier, D. Vincent, M. Pollefeys, [43] Zhengcheng Shen, Linh Kästner, Jens Lambrecht. Spatial Imagination
Timothy Lillicrap, and Sylvain Gelly. Episodic curiosity through With Semantic Cognition for Mobile Robots. In arXiv:2104.03638,
reachability. In International Conference on Learning Representations 2021.
(ICLR), 2019. [44] Bar Mayo, Tamir Hazan, Ayellet Tal. Visual Navigation with Spatial
[21] A. Tamar, Yi Wu, G. Thomas, S. Levine, and P. Abbeel. Value iteration Attention. In arXiv:2104.09807, 2021.
networks. In Advances in Neural Information Processing Systems, [45] Shuran Song, Andy Zeng, Angel X. Chang, et al. Im2Pano3D: Ex-
pages 2154–2162, 2016. trapolating 360 Structure and Semantics Beyond the Field of View. In
[22] E. Parisotto, R. Salakhutdinov. Neural Map: Structured Memory for IEEE/CVF International Conference on Computer Vision and Pattern
Deep Reinforcement Learning. In International Conference on Learn- Recognition (CVPR), 2018.
ing Representations (ICLR), 2018. [46] S. K. Ramakrishnan, T. Nagarajan, Z. Al-Halah, K. Grauman. Envi-
[23] S. K. Ramakrishnan, Z. Al-Halah, and K. Grauman. Occupancy ronment predictive coding for embodied agents. In arXiv:2102.02337,
Anticipation for Efficient Exploration and Navigation. In Proceedings 2021.
of the European Conference on Computer Vision (ECCV), 2020. [47] M. Narasimhan, E. Wijmans, X. Chen, et al. Seeing the un-
[24] J. A. Placed, J. A. Castellanos. A deep reinforcement learning ap- scene: Learning amodal semantic maps for room navigation. In
proach for active slam. Applied Sciences, 10(23), 8386, 2020. arXiv:2007.09841, 2020.[48] Francesco Giuliari, Alberto Castellini, Riccardo Berra. POMP++:
Pomcp-based Active Visual Search in unknown indoor environments.
In IEEE International Conference on Intelligent Robots and Sys-
tems(IROS), 2021.
[49] L. Kaelbling, M. Littman, and A. Cassandra. Planning and Acting
in Partially Observable Stochastic Domains. Artificial Intelligence,
vol.101, no. 1-2, pp. 99–134, 1998.
[50] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for
image recognition. In Conference on Computer Vision and Pattern
Recognition, June 2016.
[51] James A Sethian. A fast marching level set method for monotonically
advancing fronts. In Proceedings of the National Academy of Sciences,
93(4):1591–1595, 1996.
[52] Hart P E, Nilsson N J, Raphael B. A formal basis for the heuristic de-
termination of minimum cost paths. In IEEE transactions on Systems
Science and Cybernetics, 1968, 4(2): 100-107.
[53] Ye, Joel, et al. Auxiliary Tasks and Exploration Enable ObjectNav. In
arXiv:2104.04112 (2021).You can also read

















































