How Fast Do Algorithms Improve? - By YASH SHERRY - MIT Initiative on the Digital ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
How Fast Do Algorithms
Improve?
By YASH SHERRY
MIT Computer Science & Artificial Intelligence Laboratory, Cambridge, MA 02139 USA
NEIL C. THOMPSON
MIT Computer Science & Artificial Intelligence Laboratory, Cambridge, MA 02139 USA
MIT Initiative on the Digital Economy, Cambridge, MA 02142 USA
should be interpreted.
Is progress faster in most
algorithms? Just some? How
much on average?
A variety of research has
quantified progress for partic-
ular algorithms, including for
maximum flow [5], Boolean
satisfiability and factoring [6],
and (many times) for linear
solvers [4], [6], [7]. Others in
academia [6], [8]–[10] and the
private sector [11], [12] have
looked at progress on bench-
marks, such as computer chess
ratings or weather prediction,
that is not strictly comparable to
algorithms since they lack either
mathematically defined problem
statements or verifiably optimal
A
answers. Thus, despite substan-
lgorithms determine which calculations computers use to solve tial interest in the question,
problems and are one of the central pillars of computer science. existing research provides only
As algorithms improve, they enable scientists to tackle larger a limited, fragmentary view of
problems and explore new domains and new scientific tech- algorithm progress.
niques [1], [2]. Bold claims have been made about the pace of algorithmic In this article, we provide the
progress. For example, the President’s Council of Advisors on Science and first comprehensive analysis of
Technology (PCAST), a body of senior scientists that advise the U.S. President, algorithm progress ever assem-
wrote in 2010 that “in many areas, performance gains due to improvements in bled. This allows us to look
algorithms have vastly exceeded even the dramatic performance gains due to systematically at when algo-
increased processor speed” [3]. However, this conclusion was supported based rithms were discovered, how
on data from progress in linear solvers [4], which is just a single example. With they have improved, and how
no guarantee that linear solvers are representative of algorithms in general, it is the scale of these improvements
unclear how broadly conclusions, such as PCAST’s, compares to other sources of
innovation. Analyzing data from
57 textbooks and more than
This article has supplementary downloadable material available at
https://doi.org/10.1109/JPROC.2021.3107219, provided by the authors.
1137 research papers reveals
Digital Object Identifier 10.1109/JPROC.2021.3107219 enormous variation. Around half
This work is licensed under a Creative Commons Attribution 4.0 License. For more information, see https://creativecommons.org/licenses/by/4.0/
P ROCEEDINGS OF THE IEEE 1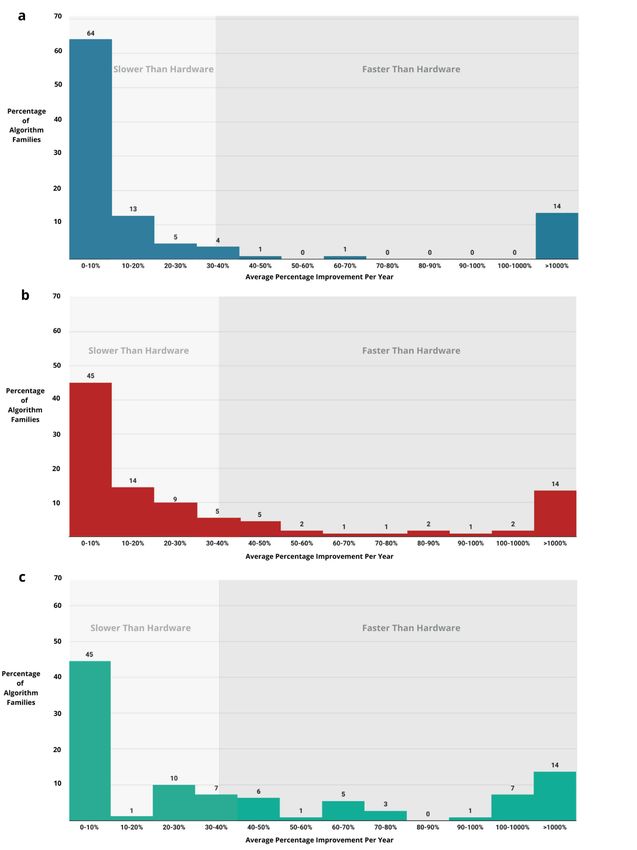
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Point of View
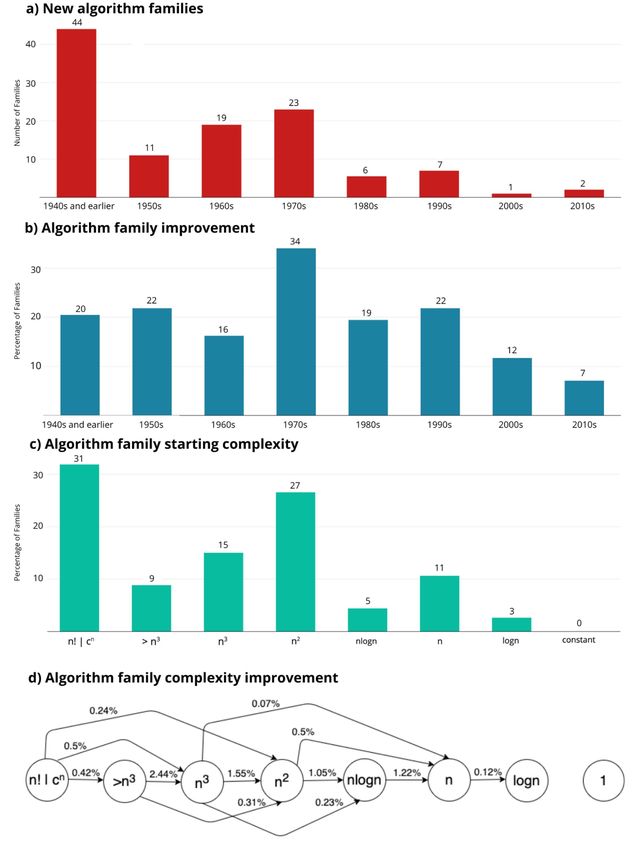
of all algorithm families experience enough to discuss. Based on these class transition into another because
little or no improvement. At the inclusion criteria, there are 113 algo- of an algorithmic improvement. Time
other extreme, 14% experience rithm families. On average, there are complexity classes, as defined in
transformative improvements, rad- eight algorithms per family. We con- algorithm theory, categorize algo-
ically changing how and where sider an algorithm as an improvement rithms by the number of operations
they can be used. Overall, we find if it reduces the worst case asymp- that they require (typically expressed
that, for moderate-sized problems, totic time complexity of its algorithm as a function of input size) [15].
30%-43% of algorithmic families had family. Based on this criterion, there For example, a time complexity of
improvements comparable or greater are 276 initial algorithms and sub- O(n 2 ) indicates that, as the size of
than those that users experienced sequent improvements, an average the input n grows, there exists a
from Moore’s Law and other hardware of 1.44 improvements after the initial function Cn 2 (for some value of C)
advances. Thus, this article presents algorithm in each algorithm family. that upper bounds the number of
the first systematic, quantitative operations required.2 Asymptotic time
evidence that algorithms are one is a useful shorthand for discussing
of the most important sources of A. Creating New Algorithms algorithms because, for a sufficiently
improvement in computing. Fig. 1 summarizes algorithm large value of n, an algorithm with
discovery and improvement over a higher asymptotic complexity will
time. Fig. 1(a) shows the timing for always require more steps to run.
I. R E S U L T S when the first algorithm in each fam- Later, in this article, we show that,
In the following analysis, we focus on ily appeared, often as a brute-force in general, little information is lost by
exact algorithms with exact solutions. implementation (straightforward, our simplification to using asymptotic
That is, cases where a problem state- but computationally inefficient), complexity.
ment can be met exactly (e.g., find the and Fig. 1(b) shows the share of Fig. 1(c) shows that, at discovery,
shortest path between two nodes on a algorithms in each decade where 31% of algorithm families belong
graph) and where there is a guarantee asymptotic time complexity improved. to the exponential complexity
that the optimal solution will be found For example, in the 1970s, 23 new category (denoted n!|cn )—meaning
(e.g., that the shortest path has been algorithm families were discovered, that they take at least exponentially
identified). and 34% of all the previously more operations as input size grows.
We categorize algorithms into discovered algorithm families were For these algorithms, including
algorithm families, by which we improved upon. In later decades, the famous “Traveling Salesman”
mean that they solve the same under- these rates of discovery and improve- problem, the amount of computation
lying problem. For example, Merge ment fell, indicating a slowdown in grows so fast that it is often infeasible
Sort and Bubble sort are two of the progress on these types of algorithms. (even on a modern computer) to
18 algorithms in the “Comparison It is unclear exactly what caused compute problems of size n = 100.
Sorting” family. In theory, an infi- this. One possibility is that some Another 50% of algorithm families
nite number of such families could algorithms were already theoretically begin with polynomial time that is
be created, for example, by subdi- optimal, so further progress was quadratic or higher, while 19% have
viding existing domains so that spe- impossible. Another possibility is that asymptotic complexities of n log n or
cial cases can be addressed sepa- there are decreasing marginal returns better.
rately (e.g., matrix multiplication with to algorithmic innovation [5] because Fig. 1(d) shows that there is con-
a sparseness guarantee). In general, the easy-to-catch innovations have siderable movement of algorithms
we exclude such special cases from already been “fished-out” [13] and between complexity classes as algo-
our analysis since they do not repre- what remains is more difficult to rithm designers find more efficient
sent an asymptotic improvement for find or provides smaller gains. The ways of implementing them. For
the full problem.1 increased importance of approximate example, on average from 1940 to
To focus on consequential algo- algorithms may also be an explanation 2019, algorithms with complexity
rithms, we limit our consideration to if approximate algorithms have O(n 2 ) transitioned to complexity O(n)
those families where the authors of a drawn away researcher attention with a probability of 0.5% per year,
textbook, one of 57 that we examined, (although the causality could also as calculated using (3). Of particular
considered that family important run in the opposite direction, with note in Fig. 1(d) are the transitions
slower algorithmic progress pushing
1 The only exception that we make to this researchers into approximation) [14]. 2 For example, the number of operations
rule is if the authors of our source text- Fig. 1(c) and (d), respectively, needed to alphabetically sort a list of 1000 file-
books deemed these special cases important show the distribution of “time com- names in a computer directory might be
enough to discuss separately, e.g., the distinc- plexity classes” for algorithms when 0.5(n 2 + n), where n is the number of file-
tion between comparison and noncomparison names. For simplicity, algorithm designers typ-
sorting. In these cases, we consider each as its they were first discovered, and the ically drop the leading constant and any smaller
own algorithm family. probabilities that algorithms in one terms to write this as O(n 2 ).
2 P ROCEEDINGS OF THE IEEE
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Point of View
Fig. 1. Algorithm discovery and improvement. (a) Number of new algorithm families discovered each decade. (b) Share of known algorithm
families improved each decade. (c) Asymptotic time complexity class of algorithm families at first discovery. (d) Average yearly probability
that an algorithm in one time complexity class transitions to another (average family complexity improvement). In (c) and (d) “>n3 ” includes
time complexities that are superpolynomial but subexponential.
from factorial or exponential time One algorithm family that has properties of weighted edges to
(n! | cn ) to polynomial times. These undergone transformative improve- bring the time complexity to cubic.
improvements can have profound ment is generating optimal binary Hu and Tucker [17], in the same year,
effects, making algorithms that search trees. Naively, this problem improved on this performance with a
were previously infeasible for any takes exponential time, but, in 1971, quasi-linear [O(n log n)] time solution
significant-sized problem possible for Knuth [16] introduced a dynamic using minimum weighted path length,
large datasets. programming solution using the which remains the best asymptotic
P ROCEEDINGS OF THE IEEE 3This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Point of View
time complexity achieved for this much more rapidly than hard- As these graphs show, there are two
family.3 ware/Moore’s law, while others, such large clusters of algorithm families
as self-balancing tree creation, have and then some intermediate values.
not. The orders of magnitude of The first cluster, representing just
B. Measuring variation shown in just these four under half the families, shows little
Algorithm Improvement of our 113 families make it clear to no improvement even for large
Over time, the performance of why overall algorithm improvement problem sizes. These algorithm fam-
an algorithm family improves as estimates based on small numbers ilies may be ones that have received
new algorithms are discovered that of case studies are unlikely to be little attention, ones that have already
solve the same problem with fewer representative of the field as a whole. achieved the mathematically optimal
operations. To measure progress, An important contrast between implementations (and, thus, are
we focus on discoveries that improve algorithm and hardware improve- unable to further improve), those that
asymptotic complexity—for example, ment comes in the predictability of remain intractable for problems of this
moving from O(n 2 ) to O(n log n), improvements. While Moore’s law led size, or something else. In any case,
or from O(n 2.9 ) to O(n 2.8 ). to hardware improvements happening these problems have experienced
smoothly over time, Fig. 2 shows that little algorithmic speedup, and
Fig. 2(a) shows the progress over algorithms experience large, but infre- thus, improvements, perhaps from
time for four different algorithm quent improvements (as discussed in hardware or approximate/heuristic
families, each shown in one color. more detail in [5]). approaches, would be the most
In each case, performance is normal- The asymptotic performance of an important sources of progress for
ized to 1 for the first algorithm in algorithm is a function of input size these algorithms.
that family. Whenever an algorithm for the problem. As the input grows, The second cluster of algorithms,
is discovered with better asymptotic so does the scale of improvement from consisting of 14% of the families, has
complexity, it is represented by moving from one complexity class to yearly improvement rates greater than
a vertical step up. Inspired by the next. For example, for a problem 1000% per year. These are algorithms
Leiserson et al. [5], the height of each with n = 4, an algorithmic change that are benefited from an expo-
step is calculated using (1), repre- from O(n) to O(log n) only repre- nential speed-up, for example, when
senting the number of problems that sents an improvement of 2 (=4/2), the initial algorithm had exponential
the new algorithm could solve whereas, for n = 16, it is an improve- time complexity, but later improve-
in the same amount of time as the ment of 4 (=16/4). That is, algorith- ments made the problem solvable
first algorithm took to solve a single mic improvement is more valuable for in polynomial time.6 As this high
problem (in this case, for a problem larger data. Fig. 2(b) demonstrates improvement rate makes clear, early
of size n = 1 million).4 For example, this effect for the “nearest-neighbor implementations of these algorithms
Grenander’s algorithm for the max- search” family, showing that improve- would have been impossibly slow for
imum subarray problem, which is ment size varies from 15× to ≈4 even moderate size problems, but the
used in genetics (and elsewhere), million× when the input size grows algorithmic improvement has made
is an improvement of one million × from 102 to 108 . larger data feasible. For these families,
over the brute force algorithm. While Fig. 2 shows the impact of algorithm improvement has far out-
To provide a reference point for algorithmic improvement for four stripped improvements in computer
the magnitude of these rates, the fig- algorithm families, Fig. 3 extends hardware.
ure also shows the SPECInt bench- this analysis to 110 families.5 Instead Fig. 3 also shows how large
mark progress time series compiled of showing the historical plot of an effect problem size has on
in [20], which encapsulates the effects improvement for each family, Fig. 3 the improvement rate, calculated
that Moore’s law, Dennard scaling, presents the average annualized using (2). In particular, for n = 1
and other hardware improvements improvement rate for problem sizes thousand, only 18% of families
had on chip performance. Throughout of one thousand, one million, and had improvement rates faster than
this article, we use this measure as the one billion and contrasts them with hardware, whereas 82% had slower
hardware progress baseline. Fig. 2(a) the average improvement rate in rates. However, for n = 1 million and
shows that, for problem sizes of n = hardware as measured by the SPECInt n = 1 billion, 30% and 43% improved
1 million, some algorithms, such as benchmark [20]. faster than hardware. Correspond-
maximum subarray, have improved ingly, the median algorithm family
3 There are faster algorithms for solving 4 For this analysis, we assume that the lead- improved 6% per year for n = 1
this problem, for example, Levcopoulos’s lin- ing constants are not changing from one algo- thousand but 15% per year for n = 1
ear solution [18] in 1989 and another linear rithm to another. We test this hypothesis later
solution by Klawe and Mumey [19], but these in this article.
5 Three of the 113 families are excluded
are approximate and do not guarantee that they
will deliver the exact right answer and, thus, from this analysis because the functional forms 6 One example of this is the matrix chain
are not included in this analysis. of improvements are not comparable. multiplication algorithm family.
4 P ROCEEDINGS OF THE IEEEThis article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Point of View
Fig. 2. Relative performance improvement for algorithm families, as calculated using changes in asymptotic time complexity. The
comparison line is the SPECInt benchmark performance [20]. (a) Historical improvements for four algorithm families compared with the first
algorithm in that family (n = 1 million). (b) Sensitivity of algorithm improvement measures to input size (n) for the “nearest-neighbor
search” algorithm family. To ease comparison of improvement rates over time, in (b) we align the starting periods for the algorithm family
and the hardware benchmark.
million and 28% per year for n = 1 bil- improvement affects computer improvement can. Second, as prob-
lion. At a problem size of n = 1.06 tril- science. First, when an algorithm lems increase to billions or trillions of
lion, the median algorithm improved family transitions from exponential to data points, algorithmic improvement
faster than hardware performance. polynomial complexity, it transforms becomes substantially more important
Our results quantify two impor- the tractability of that problem in than hardware improvement/Moore’s
tant lessons about how algorithm a way that no amount of hardware law in terms of average yearly
P ROCEEDINGS OF THE IEEE 5This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination. Point of View Fig. 3. Distribution of average yearly improvement rates for 110 algorithm families, as calculated based on asymptotic time complexity, for problems of size: (a) n = 1 thousand, (b) n = 1 million, and (c) n = 1 billion. The hardware improvement line shows the average yearly growth rate in SPECInt benchmark performance from 1978 to 2017, as assembled by Hennessy and Patterson [20]. improvement rate. These findings has been particularly important in machine learning, which have large suggest that algorithmic improvement areas, such as data analytics and datasets. 6 P ROCEEDINGS OF THE IEEE
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Point of View
Fig. 4. Evaluation of the importance of leading constants in algorithm performance improvement. Two measures of the performance
improvement for algorithm families (first versus last algorithm in each family) for n = 1 million. Algorithmic steps include leading constants
in the analysis, whereas asymptotic performance drops them.
C. Algorithmic Step Analysis To estimate the fidelity of our of improvements to the number of
Throughout this article, we have asymptotic complexity approxi- algorithmic steps and asymptotic
approximated the number of steps mation, we reanalyze algorithmic performance is nearly identical.7
that an algorithm needs to perform improvement, including the leading Thus, for the majority of algorithms,
by looking at its asymptotic complex- constants (and call this latter to there is virtually no systematic infla-
ity, which drops any leading constants construct the algorithmic steps of tion of leading constants. We cannot
or smaller-order terms, for example, that algorithm). Since only 11% of assume that this necessarily extrapo-
simplifying 0.5(n 2 + n) to n 2 . For any the papers in our database directly lates to unmeasured algorithms since
reasonable problem sizes, simplifying report the number of algorithmic higher complexity may lead to both
to the highest order term is likely steps that their algorithms require, higher leading constants and a lower
to be a good approximation. How- whenever possible, we manually likelihood of quantifying them (e.g.,
ever, dropping the leading constant reconstruct the number of steps based matrix multiplication). However, this
may be worrisome if complexity class on the pseudocode descriptions in analysis reveals that these are the
improvements come with inflation in the original papers. For example, exception, rather than the rule. Thus,
the size of the leading constant. One Counting Sort [14] has an asymptotic asymptotic complexity is an excellent
particularly important example of this time complexity of O(n), but the approximation for understanding how
is the 1990 Coppersmith–Winograd pseudocode has four linear for- most algorithms improve.
algorithm and its successors, which, loops, yielding 4n algorithmic steps
to the best of our knowledge, have in total. Using this method, we are
no actual implementations because able to reconstruct the number of
II. C O N C L U S I O N
“the huge constants involved in the algorithmic steps needed for the
Our results provide the first systematic
complexity of fast matrix multiplica- first and last algorithms in 65% of
review of progress in algorithms—
tion usually make these algorithms our algorithm families. Fig. 4 shows
one of the pillars underpinning com-
impractical” [21]. If inflation of lead- the comparison between algorithm
puting in science and society more
ing constants is typical, it would step improvement and asymptotic
broadly.
mean that our results overestimate complexity improvement. In each
the scale of algorithm improvement. case, we show the net effect across 7 Cases where algorithms transitioned from
On the other hand, if leading con- improvements in the family by taking exponential to polynomial time (7%) cannot be
the ratio of the performances of the shown on this graph because the change is too
stants neither increase nor decrease, large. However, an analysis of the change in
on average, then it is safe to ana- first and final algorithms (kth) in the their leading constants shows that, on average,
lyze algorithms without them since family (steps1)/(stepsk ). there is a 28% leading constant deflation. That
said, this effect is so small compared to the
they will, on average, cancel out when Fig. 4 shows that, for the cases asymptotic gains that it has no effect on our
ratios of algorithms are taken. where the data are available, the size other estimates.
P ROCEEDINGS OF THE IEEE 7This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Point of View
We find enormous heterogene- cited frequently in algorithm research tiple processors or allows it to run
ity in algorithmic progress, with papers, on Wikipedia pages, or in on a GPU would not count toward
nearly half of algorithm families other textbooks. For textbooks from our definition. Similarly, an algorithm
experiencing virtually no progress, recent years, where such citations’ that reduced the amount of mem-
while 14% experienced improvements breadcrumbs are too scarce, we also ory required, without changing the
orders of magnitude larger than hard- use reviews on Amazon, Google, total amount of work, would simi-
ware improvement (including Moore’s and others to source the most-used larly not be included in this analy-
law). Overall, we find that algorith- textbooks. sis. Finally, we focus on worst case
mic progress for the median algo- From each of the 57 textbooks, time complexity because it does not
rithm family increased substantially we used those authors’ categoriza- require assumptions about the distri-
but by less than Moore’s law for tion of problems into chapters, sub- bution of inputs and it is the most
moderate-sized problems and by more headings, and book index divisions widely reported outcome in algorithm
than Moore’s law for big data prob- to determine which algorithms fami- improvement papers.
lems. Collectively, our results high- lies were important to the field (e.g.,
light the importance of algorithms as “comparison sorting”) and which
an important, and previously largely algorithms corresponded to each fam- B. Historical Improvements
undocumented, source of computing ily (e.g., “Quicksort” in comparison We calculate historical improve-
improvement. sorting). We also searched academic ment rates by examining the initial
journals, online course material, and algorithm in each family and all sub-
III. M E T H O D S Wikipedia, and published theses to sequent algorithms that improve time
A full list of the algorithm textbooks, find other algorithm improvements complexity. For example, as discussed
course syllabi, and reference papers for the families identified by the text- in [23], the “Maximum Subarray in
used in our analysis can be found books. To distinguish between serious 1D” problem was first proposed
in the Extended Data and Supple- algorithm problems and pedagogical in 1977 by Ulf Grenander with a
mentary Material, as a list of the exercises intended to help students brute force solution of O(n 3 ) but
algorithms in each family. think algorithmically (e.g., Tower was improved twice in the next two
of Hanoi problem), we limit our years—first to O(n 2 ) by Grenander
analysis to families where at least and then to O(n log n) by Shamos
A. Algorithms and one research paper was written that using a Divide and Conquer strat-
Algorithm Families directly addresses the family’s prob- egy. In 1982, Kadane came up with
To generate a list of algorithms and lem statement. an O(n) algorithm, and later that
their groupings into algorithmic fami- In our analysis, we focus on exact year, Gries [24] devised another lin-
lies, we use course syllabi, textbooks, algorithms with exact solutions. That ear algorithm using Dijkstra’s stan-
and research papers. We gather a list is, cases where a problem statement dard strategy. There were no further
of major subdomains of computer can be met exactly (e.g., find the complexity improvements after 1982.
science by analyzing the coursework shortest path between two nodes on Of all these algorithms, only Gries’ is
from 20 top computer science univer- a graph), and there is a guaran- excluded from our improvement list
sity programs, as measured by the QS tee that an optimal solution will be since it did not have a better time
World Rankings in 2018 [22]. We then found (e.g., that the shortest path complexity than Kadane’s.
shortlist those with maximum overlap has been identified). This “exact algo- When computing the number of
amongst the syllabi, yielding the rithm, exact solution” criterion also operations needed asymptotically,
following 11 algorithm subdomains: excludes, amongst others, algorithms we drop leading constants and smaller
combinatorics, statistics/machine where solutions, and even in theory, order terms. Hence, an algorithm
learning, cryptography, numerical are imprecise (e.g., detect parts of an with time complexity 0.5(n 2 + n)
analysis, databases, operating sys- image that might be edges) and algo- is approximated as n 2 . As we
tems, computer networks, robot- rithms with precise definitions but show in Fig. 4, this is an excellent
ics, signal processing, computer where proposed answers are approx- approximation to the improvement
graphics/image processing, and imate. We also exclude quantum algo- in the actual number of algorithmic
bioinformatics. rithms from our analysis since such steps for the vast majority of
From each of these subdomains, hardware is not yet available. algorithms.
we analyze algorithm textbooks— We assess that an algorithm has To be consistent in our notation,
one textbook from each subdomain improved if the work that needs to we convert the time complexity for
for each decade since the 1960s. be done to complete it is reduced, algorithms with matrices, which are
This totals 57 textbooks because not asymptotically. This, for example, typically parameterized in terms of
all fields have textbooks in early means that a parallel implementa- the dimensions of the matrix, to being
decades, e.g., bioinformatics. Text- tion of an algorithm that spreads the parameterized as a function of the
books were chosen based on being same amount of work across mul- input size. For example, this means
8 P ROCEEDINGS OF THE IEEEThis article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Point of View
that the standard form for writing the We calculate the average per-year tions to calculate the improvement
time complexity of naive matrix multi- percentage improvement rate over t because newer algorithms scale dif-
plication goes from N 3 , where N × N years as ferently because of output sensitiv-
is the dimension of the matrix, to an ity and, thus, cannot be computed
1.5 algorithm when n is the size of
n input directly with only the inputs parame-
YearlyImprovement i→ j
the input and n = N × N . ters. In three instances, the functional
1/t
In the presentations of our results Operationsi (n) forms of the early and later algorithms
in Fig. 1(d), we “round-up”—meaning = − 1. (2) are so incomparable that we do not
Operations j (n)
that results between complexity attempt to calculate rates of improve-
classes round up to the next highest ment and instead omit them.
category. For example, an algorithm We only consider years since
that scales as n 2.7 would be between 1940 to be those where an algorithm D. Transition Probabilities
n 3 and n 2 and so would get rounded was eligible for improvement. This
avoids biasing very early algorithms, The transition probability from
up to n 3 .8 Algorithms with subex-
e.g., those discovered in Greek times, one complexity class to another is
ponential but superpolynomial time
toward an average improvement calculated by counting the number of
complexity are included in the >n 3
rate of zero. transitions that did occur and divid-
category.
Both of these measures are inten- ing by the number of transitions
sive, rather than extensive, in which that could have occurred. Specifically,
they measure how many more prob- the probability of an algorithm tran-
C. Calculating Improvement sitioning from class a to b is given as
lems (of the same size) could be
Rates and Transition Values follows:
solved with a given number of oper-
In general, we calculate the ations. Another potential measure
improvement from one algorithm, would be to look at the increase in the prob(a → b)
i , to another j as problem size that could be achieved, 1 ||a → b||t
= (3)
i.e., (n new /n old ), but this requires T ||a||t−1 + c∈C ||c → a||t
t∈T
Operationsi (n) assumptions about the computing
Improvementi→ j = (1)
Operations j (n) power being used, which would where t is a year from the set of possi-
introduce significant extra complex- ble years T and c is a time complexity
where n is the problem size and the ity into our analysis without compen- class from C, which includes the null
number of operations is calculated satory benefits. set (i.e., a new algorithm family).
either using the asymptotic complex- Algorithms With Multiple Parame- For example, say we are interested
ity or algorithmic step techniques. ters: While many algorithms only have in looking at the number of transitions
One challenge of this calculation a single input parameter, others have from cubic to quadratic, i.e., a = n 3
is that there are some improve- multiple. For example, graph algo- and b = n 2 . For each year, we cal-
ments, which would be mathemati- rithms can depend on the number culate the fraction of transitions that
cally impressive but not realizable, for of vertices, V and the number of did occur, which is just the number
example, an improvement from 22n to edges, E, and, thus, have input size of algorithm families that did improve
2n , when n = 1 billion is an improve- V + E. For these algorithms, increas- from n 3 to n 2 (i.e., ||a → b||t ) divided
ment ratio of 21 000 000 000 . However, ing input size could have various by all the transitions that could have
the improved algorithm, even after effects on the number of operations occurred. The latter includes to three
such an astronomical improvement, needed, depending on how much of terms: all the algorithm families that
remains completely beyond the abil- the increase in the input size was were in n 3 in the previous year (i.e.,
ity of any computer to actually calcu- assigned to each variable. To avoid ||a||t−1 ), all the algorithm families
late. In such cases, we deem that the this ambiguity, we look to research that move into n 3 from another class
c∈C ||c →
“effective” performance improvement papers that have analyzed problems (c) in that year (i.e.,
is zero since it went from “too large of this type as an indication of the a||t ), and any new algorithm families
to do” to “too large to do.” In practice, ratios of these parameters that are of that are created and begin in n 3 (i.e.,
this means that we deem all algorithm interest to the community. For exam- ||Ø → a||t ). These latter two are
families that transition from one fac- ple, if an average paper considers included because a family can make
torial/exponential implementation to graphs with E = 5 V, then we multiple transitions within a single
another has no effective improvement will assume this for both our base year, and thus, “newly arrived” algo-
for Figs. 3 and 4. case and any scaling of input sizes. rithms are also eligible for asymptotic
In general, we source such ratios as improvement in that year. Averaging
the geometric mean of at least three across all the years in the sample pro-
8 For ambiguous cases, we round based on studies. In a few cases, such as Con- vides the average transition probabil-
the values for an input size of n = 1 000 000. vex Hull, we have to make assump- ity from n 3 to n 2 , which is 1.55%.
P ROCEEDINGS OF THE IEEE 9This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
Point of View
E. Deriving the Number of Acknowledgment Data Availability and
Algorithmic Steps The authors would like to acknowl- Code Availability
edge generous funding from the Tides
Foundation and the MIT Initiative Data are being made public through
In general, we use pseudocode from on the Digital Economy. They would the online resource for algorithms
the original papers to derive the also like to thank Charles Leiserson, community at algorithm-wiki.org and
number of algorithmic steps needed the MIT Supertech Group, and Julian will launch at the time of this article’s
for an algorithm when the authors Shun for valuable input. publication. Code will be available
have not done it. When that is not at https://github.com/canuckneil/
available, we also use pseudocode Author Contributions IEEE_algorithm_paper.
from textbooks or other sources. Statement
Analogously to asymptotic complex- Neil C. Thompson conceived the
ity calculations, we drop smaller project and directed the data gather- Additional Information
order terms and their constants ing and analysis. Yash Sherry gathered
because they have a diminishing the algorithm’s data and performed The requests for materials should
impact as the size of the problem the data analysis. Both authors wrote be addressed to Neil C. Thompson
increases. this article. (neil_t@mit.edu).
REFERENCES
[1] Division of Computing and Communication Available: https://www.lanl.gov/conferences/ [16] D. E. Knuth, “Optimum binary search trees,” Acta
Foundations CCF: Algorithmic Foundations salishan/salishan2004/womble.pdf Inform., vol. 1, no. 1, pp. 14–25, 1971.
(AF)—National Science Foundation, Nat. Sci. [8] N. Thompson, S. Ge, and G. Filipe, “The [17] T. C. Hu and A. C. Tucker, “Optimal computer
Found., Alexandria, VA, USA. [Online]. Available: importance of (exponentially more) computing,” search trees and variable-length alphabetical
https://www.nsf.gov/funding/pgm_summ.jsp?pims_ Tech. Rep., 2020. codes,” SIAM J. Appl. Math., vol. 21, no. 4,
id=503299 [9] D. Hernandez and T. Brown, “A.I. and efficiency,” pp. 514–532, 1971.
[2] Division of Physics Computational and Data-Enabled OpenAI, San Francisco, CA, USA, Tech. Rep. [18] C. Levcopoulos, A. Lingas, and J.-R. Sack,
Science and Engineering (CDS&E)—National Science abs/2005.04305 Arxiv, 2020. “Heuristics for optimum binary search trees and
Foundation, Nat. Sci. Found., Alexandria, VA, USA. [10] N. Thompson, K. Greenewald, and K. Lee, “The minimum weight triangulation problems,” Theor.
[Online]. Available: https://www.nsf.gov/funding/ computation limits of deep learning,” 2020, Comput. Sci., vol. 66, no. 2, pp. 181–203,
pgm_summ.jsp?pims_id=504813 arXiv:2007.05558. [Online]. Available: Aug. 1989.
[3] J. P. Holdren, E. Lander, and H. Varmus, https://arxiv.org/abs/2007.05558 [19] M. Klawe and B. Mumey, “Upper and lower bounds
“President’s council of advisors on science and [11] M. Manohara, A. Moorthy, J. D. Cock, and on constructing alphabetic binary trees,” SIAM J.
technology,” Dec. 2010. [Online]. Available: A. Aaron, Netflix Optimized Encodes. Los Gatos, CA, Discrete Math., vol. 8, no. 4, pp. 638–651,
https://obamawhitehouse.archives.gov/sites/default/ USA: Netflix Tech Blog, 2018. [Online]. Available: Nov. 1995.
files/microsites/ostp/pcast-nitrd-report-2010.pdf https://netflixtechblog.com/optimized-shot-based- [20] J. L. Hennessy and D. A. Patterson, Computer
[4] R. Bixby, “Solving real-world linear programs: A encodes-now-streaming-4b9464204830 Architecture: A Quantitative Approach, 5th ed.
decade and more of progress,” Oper. Res., vol. 50, [12] S. Ismail, Why Algorithms Are the Future of Business San Mateo, CA, USA: Morgan Kaufmann, 2019.
no. 1, pp. 3–15, 2002, doi: 10.1287/opre.50.1.3. Success. Austin, TX, USA: Growth Inst. [Online]. [21] F. Le Gall, “Faster algorithms for rectangular matrix
17780. Available: https://blog.growthinstitute.com/ multiplication,” Commun. ACM, vol. 62, no. 2,
[5] C. E. Leiserson et al., “There’s plenty of room at the exo/algorithms pp. 48–60, 2012, doi: 10.1145/3282307.
top: What will drive computer performance after [13] S. S. Kortum, “Research, patenting, and [22] TopUniversities QS World Rankings, Quacquarelli
Moore’s law?” Science, vol. 368, no. 6495, technological change,” Econometrica, vol. 65, no. 6, Symonds Ltd., London, U.K., 2018.
Jun. 2020, Art. no. eaam9744. p. 1389, Nov. 1997. [23] J. Bentley, “Programming pearls: Algorithm design
[6] K. Grace, “Algorithm progress in six domains,” [14] T. H. Cormen, C. E. Leiserson, R. L. Rivest, techniques,” Commun. ACM, vol. 27, no. 9,
Mach. Intell. Res. Inst., Berkeley, CA, USA, and C. Stein, Introduction to Algorithms, pp. 865–873, 1984, doi: 10.1145/358234.381162.
Tech. Rep., 2013. 3rd ed. Cambridge, MA, USA: MIT Press, [24] D. Gries, “A note on a standard strategy for
[7] D. E. Womble, “Is there a Moore’s law for 2009. developing loop invariants and loops,” Sci. Comput.
algorithms,” Sandia Nat. Laboratories, [15] J. Bentley, Program. Pearls, 2nd ed. New York, NY, Program., vol. 2, no. 3, pp. 207–214, 1982, doi:
Albuquerque, NM, USA, Tech. Rep., 2004. [Online]. USA: Association for Computing Machinery, 2006. 10.1016/0167-6423(83)90015-1.
10 P ROCEEDINGS OF THE IEEEYou can also read

















































