Do Language Models Plagiarize?
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Do Language Models Plagiarize?
Jooyoung Lee Thai Le Jinghui Chen Dongwon Lee
Pennsylvania State University
{jfl5838,tql3,jzc5917,dongwon}@psu.edu
Abstract ponents does lead to performance enhancement
(Kaplan et al., 2020).
Past literature has illustrated that language Amongst various downstream NLP tasks, neu-
models do not fully understand the context and
ral language models are well-known to demon-
arXiv:2203.07618v1 [cs.CL] 15 Mar 2022
sensitivity of text and can sometimes mem-
orize phrases or sentences present in their strate unprecedented performance on neural text
training sets. In this paper, we investigate generation. According to (McCoy et al., 2021),
whether they not only memorize but also pla- model-generated texts can be as novel or even
giarize training samples when generating arti- more novel than human writings. A distinction
ficial texts. Our findings support that they, es- between machine-authored and human-written con-
pecially GPT-2, reuse particular pieces of texts tent has even become quite challenging (Clark et al.,
from the training corpus with or without ob-
2021; Uchendu et al., 2020). Despite their promis-
fuscation. We have four main results: 1) lan-
guage models with more capacity plagiarize ing results, a growing body of literature gave rise
more; 2) fine-tuned language models demon- to privacy violations of a neural language model
strate differing patterns of plagiarism based resulting from data memorization (Carlini et al.,
on characteristics of auxiliary data; 3) sam- 2019; Thakkar et al., 2021; Truex et al., 2018;
pling from truncated language modeling distri- Arpit et al., 2017; Meehan et al., 2020). More
butions tends to heighten the degree of plagia- precisely, through membership inference attacks,1
rism as opposed to temperature sampling, and Carlini et al. (2021) could extract 32 memorized
4) plagiarism in language models can have se-
examples with individuals’ contact information out
rious privacy consequences. Overall, our work
implies that future research on neural language of 604 GPT-2 generated samples. The authors have
models should take precautions to avoid mod- also confirmed that models’ copying behaviors are
els plagiarizing their training datasets. prone to get worse as both the size of LMs and their
training data increase.
A majority of datasets used to train language
1 Introduction models are scraped from the Internet without re-
Language models (LMs) are core elements of ceiving informed consent from content owners
the Natural Language Processing (NLP) field, ex- (Brown et al., 2022). That being said, memoriza-
celling at a wide range of tasks such as natural lan- tion from training samples can be perceived as a
guage generation (NLG), speech recognition, ma- violation of copyright and authorship. Other than
chine translation, and question answering. The pre- copying and pasting training sequences, there are
training objective of a language model is to learn other ways to indirectly exploit training examples
the probability distribution over word sequences. by paraphrasing or summarizing the original con-
Recent trends in language modeling involve large tent. This action generally refers to plagiarism, the
models, large training datasets, and long compute act of reusing another person’s work without refer-
time. For instance, the largest version of GPT- encing the individual as its owner (Ali et al., 2011).
3, trained on 570GB of Internet text, has 175 bil- As shown in Table 1, LMs can further plagiarize
lion parameters and would cost $4.6M for training from training samples. This motivates our main in-
when using a Tesla V100 cloud instance (Li, 2020). quiry subject: To what extent do language models
A heated competition of training and presenting 1
It is a type of adversarial attacks that aims to predict
larger LMs with larger training corpora might be whether or not a particular example was included in a training
explained by the fact that an increase in these com- set, based on a trained modelOriginal Text Plagiarized Text
[...] *** is the second amendment [...] *** is the second amendment
columnist for Breitbart news and host columnist for Breitbart news and host
of bullets with ***, a Breitbart news podcast. of bullets with ***, a Breitbart news podcast.
He is also the political analyst for Armed He is also the political analyst for Armed
American Radio. Follow him on Twitter: @***. American Radio. Follow him on Twitter: @***.
Reach him directly at ***@***.com. Reach him directly at ***@***.com.
REUTERS/Kevin Lamarque U.S. President
REUTERS/Kevin Lamarque U.S. President
Donald Trump, First Lady Melania Trump
Donald Trump and First Lady Melania Trump,
and their son Barron while aboard Air Force
with their son Barron, arrive for a New Year’s Eve
One on their way to Florida, Mar-a-Lago in
party at his Mar-a-Lago club in Palm Beach,
Palm Beach, Florida to spend the holiday at Trump
Florida, U.S. December 31, 2017. [...]
International Golf Club Mar-a-Lago. [...]
The soldier was accused of leaving his post
in Afghanistan in 2009
(CNN) Sgt. Bowe Bergdahl pleaded guilty Wednesday
Bergdahl, who walked off his base in
to misbehavior before the enemy and disobeying orders
Afghanistan in 2009 and was held by the Taliban
, leaving bound and naked prisoners wide-open
for five years, pleaded guilty to desertion
to attack or capture at a training base in Afghanistan.
and misbehavior before the enemy. [...]
[...]
The soldiers who had held Bergdahl captive
for more than five years were also tried by
a judge over their possible actions surrounding Bergdahl’s disappearance.
Table 1: Qualitative examples of plagiarism identified in OpenWebText. Duplicated texts are highlighted in yellow,
and words/phrases that contain similar meaning without text overlaps are highlighted in green. [...] indicate text
omitted for brevity. Personally identifiable information has been replaced with ***.
directly and indirectly exploit phrases or sentences impact plagiarism: 1) Model size: Amongst four
in training samples?. To the best of our knowl- GPT-2 family, larger models (GPT-2 large and xl)
edge, there is no existing literature that has gone plagiarize more from a training set than smaller
beyond the investigation into verbatim plagiarism models; 2) Fine-tuning Data: There is a positive
(also known as memorization) in language models. correlation between document similarity levels be-
tween pre-training and fine-tuning sets and pla-
In this paper, we examine plagiarizing behaviors
giarism; 3) Decoding methods and values of their
of the state-of-the-art language models, specifically
parameters: Plagiarism cases differ depending on
GPT-2 families (small/medium/large/xl), which in-
decoding approaches and parameter values.
volve neural texts that contain not only explicit
Contributions of our work are summarized as
text overlap but also semantically similar informa-
follows:
tion from training data. Our study is guided by
two research questions: (RQ1) Do pre-trained • We establish research inquiries that have not
language models plagiarize? and (RQ2) Do fine- been fully explored. We apply a notion of pla-
tuned language models plagiarize?. We first at- giarism to an NLG task from both pre-trained
tempt to identify three plagiarism categories (ver- and fine-tuned LMs. Moreover, the effects of
batim/paraphrase/idea) from machine-written pas- varying decoding approaches and parameters are
sages generated by pre-train GPT-2 with different understudied in memorization research.
combinations of model size and decoding meth-
ods. For plagiarism type detection, we automate • We develop an automatic plagiarism detection
the process by building a novel pipeline that en- pipeline, which leverages the state-of-the-art
hances the performance of an existing open source BERT-based classifier and Named Entity Recog-
toolkit (Sanchez-Perez et al., 2015). Three GPT-2 nition (NER) approach to reduce error rates of
small models are then fine-tuned using datasets in Sanchez-Perez et al. (2015).
scholarly writing and legal domains. We use these
• We empirically highlight that risks related to
models to compare their patterns of plagiarism for
memorization are underestimated. A Language
pre-training corpus and fine-tuning corpus.
model does more than copy and paste training
We discover three attributes that significantly samples; it can further rephrase sentences orsteal ideas from someone else’s writing. To pro- the similarity between overlapping 8-grams. There
tect authorship of original content, our work are diverse ways to measure text similarity with
prompts an urgent need for model-wise solu- segmented document pairs. For example, Küppers
tions apart from data deduplication (Lee et al., and Conrad (2012) calculated the Dice coefficient
2021) or data sanitization (He et al., 2017). between 250 character chunks of passage pairs, and
Shrestha and Solorio (2013) implemented the Jac-
2 Related Work card similarity with n-grams (Shrestha and Solorio,
2013). Euclidean distance clustering is a com-
Memorization in Language Models. There is mon method as well (Palkovskii and Belov, 2014;
a growing body of literature that aims to study Jiffriya et al., 2014).
memorization of neural language models by re- More recent literature (Gharavi et al., 2020;
covering texts in the training text corpus (Salem Nazir et al., 2021) have made continuous efforts in
et al., 2020; Kharitonov et al., 2021; Leino and adopting word embedding and advanced machine
Fredrikson, 2020) or extracting artificially injected learning or deep learning models. Gharavi et al.
canaries (Henderson et al., 2018; Mireshghallah (2016) extracted word vectors using the word2vec
et al., 2021; Zanella-Béguelin et al., 2020). Carlini algorithm and applied two similarity metrics: Co-
et al. (2021, 2019); Brown et al. (2022) has empha- sine similarity, and Jaccard similarity. Instead of
sized that data memorization can intentionally or using well-established similarity scores bounded by
unintentionally lead to sensitive information leak- particular thresholds, Altheneyan and Menai (2020)
age from a model’s training set. Meanwhile, recent has viewed the task as a classification problem and
studies (Lee et al., 2021; Kandpal et al., 2022) have developed a support vector machine (SVM) clas-
shown that training data of language models tend sifier using several lexical, syntactic, and seman-
to contain a large number of near-duplicates, and tic features. Specifically for paraphrase detection,
overlapping phrases included in near-duplicates sig- Agarwal et al. (2018) relied on Convolutional Neu-
nificantly account for memorized text sequences. ral Network (CNN) to obtain the local region in-
They further demonstrate the effectiveness of train- formation from n-grams and Recurrent Neural Net-
ing data deduplication strategy in mitigating the ef- work (RNN) to capture the long-term dependency
fects of memorization. Still, this technique cannot information.
completely eradicate memorization because there
exist memorized sequences that are present only 3 Taxonomy of Plagiarism
once. In order to distinguish rare but memorized
texts, Zhang et al. (2021) has presented a notion Plagiarism occurs when any content including text,
of counterfactual memorization which measures a source code, or audio-visual content is reused with-
difference in expected performance of two models out permission or citation from an author of orig-
trained on with or without a particular training sam- inal work. It has been a longstanding problem,
ple. Unlike other works, McCoy et al. (2021) has especially in educational and research institutions
attempted to analyze models’ memorizing behav- or publishers, given the availability of digital arti-
iors by assessing the novelty of machine-generated facts (Sutherland-Smith, 2008; Clarke, 2006). Pla-
texts. Despite their findings of 1,000 word long giarism can severely damage academic integrity
duplicated passages from a training set, the authors and even hurt individuals’ reputation and morality
imply that neural language models have the ability (East, 2010). To detect such activities, it is neces-
to integrate familiar parts into novel content, rather sary to have extensive knowledge about plagiarism
than simply copying training samples. forms and classes. The most naive approach is to
Plagiarism Detection. An automated extrinsic pla- directly copy segments of others’ documents and
giarism detection, in general, can be divided into paste them into their work. To make plagiarism less
two subtasks: document retrieval and text align- obvious, one may replace original words with syn-
ment. While document retrieval focuses on fetch- onyms or rearrange word orders. Similarly, back
ing all documents that potentially have plagiarized translation, using two independent translators to
an existing document, the text alignment subtask translate sentences back and forth, is common in
detects the location and content of plagiarized texts. paraphrase generation. A more sophisticated ap-
Alzahrani (2015) retrieved candidate documents proach involves rewriting an abstract version of the
that share exact-copied sequences and computed original document while preserving its whole idea,which is more difficult to identify given limited case, scores are computed via the Okapi-BM25 al-
lexical and syntactic similarities. In this work, we gorithm (Robertson et al., 1995), a popular bag-of-
focus on three plagiarism types: words ranking function that Elasticsearch employs
as a default. We specify n as 10 for the sake of time
• Verbatim plagiarism: exact copies of words or efficiency.
phrases without transformation.
4.2 Plagiarism Type Identification
• Paraphrase plagiarism: synonymous substitu-
Baseline. Text alignment algorithms aim at extract-
tion, word reordering, and back translation.
ing and locating similar contiguous text sequences
• Idea plagiarism: reuse of the core idea by short- between two given documents and are applicable
ening or summarizing the original content to a variety of tasks such as information retrieval
(Davis and Ogden, 1997; Semmar and Fluhr, 2007),
These are the most commonly studied categories text-reuse detection (Roostaee et al., 2020; Zhou
in plagiarism literature (Lukashenko et al., 2007; et al., 2020), and translation Alignment (Lin et al.,
Meuschke and Gipp, 2013), and thus we target 2020). Motivated by previous literature, we employ
identification of these types. the open source text alignment tool (Sanchez-Perez
et al., 2015) to identify plagiarized texts from pairs
4 Automatic Detection of Plagiarism in of the original document (from machine-generated
Language Models corpus) and the candidate document (from Open-
WebText). Details on Sanchez-Perez et al. (2015)
In this section, we describe the processes of au-
can be found in Appendix A.3
tomated plagiarism type identification. We store
Improvement. Although this tool was introduced
OpenWebText to our search engine and then apply
in 2015, we choose it because its reported perfor-
text alignment to fetch similar documents.
mance is robust, and it focuses on the longest pla-
4.1 Candidate Document Retrieval giarized substrings unlike existing plagiarism de-
tectors trained and evaluated on labeled sentence
The first step of our approach is to distinguish a list
pairs (Shahmohammadi et al., 2021; Socher et al.,
of candidate OpenWebText documents that have
2011; Yin and Schütze, 2015). Nonetheless, by
high chances of being associated with plagiarism
running a sanity check with 200 documents (50 for
given a synthetic document. Here we utilize a
each plagiarism label) included in our own corpus,
document similarity score as a proxy of plagia-
we discover that the proposed approach (especially
rism. Since modern language models like GPT-
in paraphrase detection subtask) has some flaws;
2 or GPT-3 are known to be trained on volumi-
it labels near-duplicates with one character differ-
nous data consisting of more than millions of doc-
ence as paraphrases and fails to capture little details
uments, it is non-trivial to locally store all doc-
such as numbers or dates. For example, ‘2/5 found
uments and compute similarities and rank them.
it helpful’ and ‘1/5 found it useful’ are not para-
Hence, we generate our search engine using Elastic-
phrases. Therefore, to reduce false positives, we
search2 which is an open source search engine built
add additional restrictions on top of the existing
on Apache Lucene and can provide a distributed
tool. Specifically, a RoBERTa-based paraphrase
RESTful search service with fast response time and
identification model (Morris et al., 2020) and NER4
fine-tuned relevancy.
are applied to potentially paraphrased segments
After storing OpenWebText to Elasticsearch,
identified by the open source. The RoBERTa clas-
we initiate the searching process by setting the
sifier has achieved 91.17% accuracy on the eval-
whole content of the original document (in our
uation set from the MSRP corpus.5 Since the
case, machine-generated document) as queries. As
RoBERTa classifier works best in sentence-level
most queries are lengthy and therefore can slow
comparison, we chunk them using NLTK6 ’s sen-
down the retrieval, we clean them by removing
3
stopwords and lemmatizing. It then automatically For the purpose of this study, random and translation
obfuscation types are grouped as paraphrase plagiarism, and
computes similarities between stored documents summary obfuscation is considered as idea plagiarism.
and the inserted query and fetches top-n documents 4
We use SpaCy library (https://spacy.io).
5
that acquire the highest similarity score. In our https://www.microsoft.com/en-us/
download/details.aspx?id=52398
2 6
https://www.elastic.co/elasticsearch/ https://www.nltk.orgtence tokenizer and feed sentence pairs to both on our own, we use GPT-2 Output Dataset9 which
RoBERTa and NER models. If there is at least contains 250,000 texts generated by four ver-
one sentence pair whose probability ranges from sions of the GPT-2 model with three decoding ap-
0.5 to 0.997 and have matching entities, we accept proaches.10 Owners of the gpt-2-output-dataset
the PAN 2015’s result regarding paraphrase plagia- repository have informed us that they used a ‘’ token as a prompt and set t=1, k=40,
tim or idea plagiarism because reported results in 0.8 < p < 1. In total, there are 12 (4 model
Sanchez-Perez et al. (2015) matches well with ours. size * 3 decoding methods) combinations, and we
According to annotation results of 200 documents, only analyze the first 10,000 examples in each com-
accuracy scores of our detection method are as fol- bination.
lows: 0.92% for no plagiarism, 1.0% for verbatim
plagiarism, 0.88% for paraphrase plagiarism, and 5.2 Experimental Results
0.62% for idea plagiarism.
Verbatim
xl (top-p) Paraphrase
5 RQ1: Pre-trained GPT-2 and Idea
large (top-p)
Plagiarism medium (top-p)
small (top-p)
In this section, we primarily investigate plagiarism
Model (Decoding) xl (top-k)
of four different versions (small/medium/large/xl)
large (top-k)
of OpenAI GPT-2 model (Radford et al., 2019).
medium (top-k)
Our experimental environment is based on a small (top-k)
Google Colab Pro+ with Tesla V100-SXM2-16GB xl (temp)
and 55 GB of RAM. large (temp)
medium (temp)
5.1 Experimental Setup small (temp)
Dataset. GPT-2 is pre-trained on WebText, con- 0.0 0.5 1.0 1.5 2.0 2.5
Document Percentage
taining the text subset of 45 million links from Red-
dit (Radford et al., 2019). After data de-duplication Figure 1: Distribution of Plagiarism Categories w.r.t.
and some heuristic-based cleaning, its final size Model Size and Decoding methods
is over 8 million documents for a total of 40 GB
of text. Since OpenAI has not publicly released Document distribution of three plagiarism types
WebText, we use OpenWebText which is an open- based on different model sizes and decoding strate-
source recreation of the WebText corpus.8 Given gies is displayed in Figure 1. For GPT-2 with tem-
that the size of OpenWebtext corpus matches the perature setting, the larger the model size became
size described in Radford et al. (2019), we assume the higher occurrences of plagiarism were observed.
it is a reliable source. This finding is consistent with previous memoriza-
Model. GPT-2 is a transformer-based language tion literature (e.g., Carlini et al. (2021), Levy et al.
model which comes in 4 different sizes — small, (2021), Carlini et al. (2022)). We also find that not
medium, large, and xl, with 124M, 355M, 774M, limited to verbatim plagiarism which is equivalent
and 1.5B parameters, respectively. According to to memorized substrings, the other two types of pla-
Radford et al. (2019), the smallest model is equiva- giarism surged alongside the model size. However,
lent to the original GPT (Radford et al., 2018), and our observations do not hold when GPT-2’s word
the second smallest is same as the largest model token is sampled from a truncated distribution such
from BERT (Devlin et al., 2018). GPT-2 has shown as top-k and top-p: plagiarism frequencies were the
outstanding efficacy of pre-trained language mod- highest when GPT-2 large models were used, not
els on various natural language processing (NLP) xl. Moreover, top-k and top-p decoding methods
tasks, particularly coherent text generation. are more strongly associated with plagiarism than
Text Generation. Instead of creating neural texts setting temperature regardless of the model size.
7 9
We specified 0.99 as the upper bound to avoid near- https://github.com/openai/
duplicate pairs. gpt-2-output-dataset
8 10
https://skylion007.github.io/ Detailed explanations of decoding methods used for our
OpenWebTextCorpus/ analyses are included in Appendix B.5.3 Analyses of Plagiarized Examples 6 RQ2: Fine-trained GPT-2 and
Plagiarism
6.1 Experimental Setup
Dataset. We use three new corpora to fine-tune
pre-trained GPT-2 models. Our corpora comprise
scholarly writing and legal domains, in which pla-
giarism studies have rigorously explored with re-
spect to ethical writing and authorship (Pecorari,
2008; Shahabuddin, 2009; Mahmood, 2010) and
plagiarism itself is deemed more sensitive. The
first corpus includes 250,000 randomly selected
abstracts on arxiv.org, from the start of the site in
1993 to the end of 2019 (Geiger, 2019). The second
corpus, on the other hand, is a subset (n=200,000)
of the CORD-19 dataset (Wang et al., 2020), con-
sisting of scholarly articles about the COVID-19
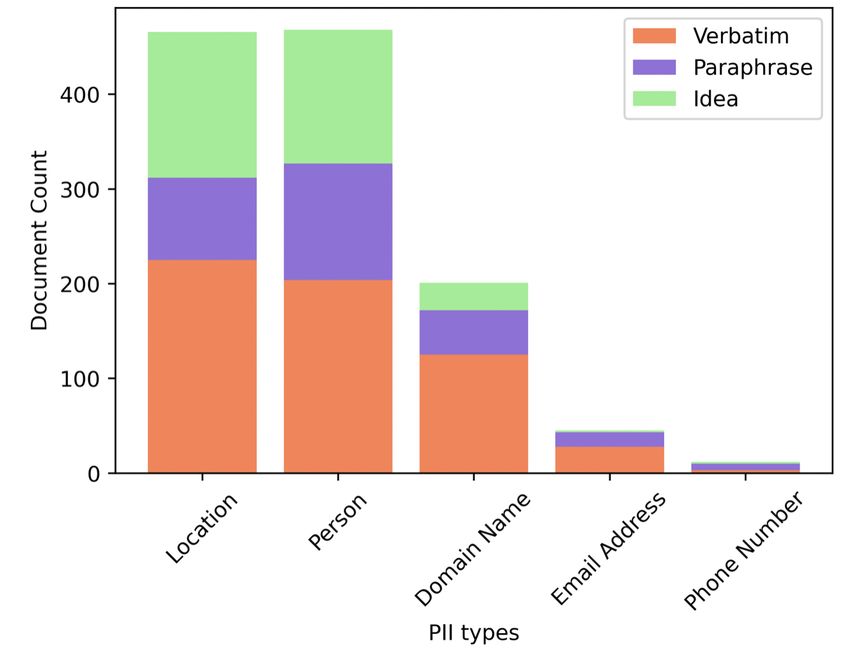
Figure 2: Total Number of PII-Exposing Documents virus. Since most articles in CORD-19 exceed the
w.r.t. Plagiarism Categories
length of 1024 tokens, we only consider the first
five paragraphs starting from the ‘Introduction’ sec-
tion. While the former covers a wide range of
We now turn our attention to the content of se-
disciplines (e.g., Physics, Computer Science, Eco-
quences associated with three plagiarism types.11
nomics), the latter predominantly includes papers
Many studies (Carlini et al., 2021; Kandpal et al.,
in Medicine (55%), Biology (31%), and Chemistry
2022; Zhu et al., 2021; Meehan et al., 2020) have
(3%). Lastly, Lee and Hsiang (2020)’s 290,000
raised a concern towards memorization of large
patent claims are acquired for our experiment.
language models due to data privacy leakage. Mo-
Model. For fine-tuning, we utilize a Python pack-
tivated by their findings, we apply Microsoft’s Pre-
age called GPT-2-simple.13 Due to constraints of
sidio analyzer,12 a Python toolkit for personally
computing resource, we only fine-tune the GPT-2
identifiable information (PII) entity detection (e.g.,
small variation. For simplicity’s sake, three in-
credit card information, email address, phone num-
dividual models trained on each dataset will be
ber), to GPT-2 generated texts. Precisely, there are
denoted as ArXivAbstractGPT, Cord19GPT, and
total 2,168 unique substrings (verbatim: 863 / para-
PatentGPT. In our experiment, we maintain hyper-
phrase: 524 / idea: 349) plagiarized by pre-trained
parameters that are suggested in public repositories:
GPT-2. We set a confidence threshold to 0.7. A
learning rate as 1e-4, temperature as 1.0, top-k as
total number of plagiarized documents that reveal
40, and batch size as 1. Three models are trained
PII entities is displayed in Figure 2. Of 1,736 pla-
for 30,000, 44,000, and 32,300 steps respectively.
giarized sequences, nearly 26% include at least one
Text Generation. For three fine-tuned models, we
element of location information and a person’s full
manually create 10,000 synthetic texts using the
name. Although none of the highly sensitive in-
same prompt and parameter information as GPT-2
formation, including individuals’ driver’s license
Output Dataset.
number, credit card information, bank number, so-
cial security number, and IP address, are revealed, 6.2 Experimental Results
the results show a possibility of machine-generated
We observe overall frequencies of verbatim plagia-
texts disseminating personal data such as phone
rism have significantly diminished after fine-tuning
number and email address not only through exact
(Table 2). This finding aligns with GPT-2’s out-
copying but also through paraphrasing.
standing adaptability to the writing styles of new
data. Still, not all fine-tuned models are not com-
pletely free from plagiarism. While ArxivAbstract-
11
Due to page constraints, further details on identified pla- GPT had nearly zero plagiarism cases, Cord19GPT
giarized content are illustrated in Appendix D.
12 13
https://microsoft.github.io/presidio/ https://github.com/minimaxir/
analyzer/ gpt-2-simplePre-Training Data Fine-Tuning Data
Verbatim Paraphrase Idea Verbatim Paraphrase Idea
temp 0 0.04 0.16 0 0.07 0.17
PatentGPT top-k 0 0.31 1.5 0 0 0
top-p 0 0.07 0.79 0 0.02 0
temp 0.01 0.01 0.06 0.42 0.3 0.35
Cord19GPT top-k 0.01 0.51 1.25 0.51 1.79 3.72
top-p 0.06 0.34 0.73 0.62 1.43 1.72
temp 0 0 0 0 0.03 0
ArxivAbstract
top-k 0 0 0.01 0 0 0
GPT
top-p 0 0.02 0 0 0.01 0
Table 2: Distribution of Plagiarism Categories w.r.t. Model and Decoding Methods. All numbers indicate the
percentage of document.
substantially reuse the content of OpenWebText claims included in the OpenWebText dataset.
through paraphrase or idea plagiarism. Taking into We further study fine-tuned models’ plagiarism
account a strong correlation of memorization and regarding fine-tuning data. Our results highlight
data duplication, we speculate that the observed dis- that Cord19GPT was strongly affiliated with plagia-
crepancies may have been caused by different lev- rism as opposed to ArxivAbstractGPT and Patent-
els of similarity between each fine-tuning dataset GPT (Table 2). Although all fine-tuned models
and OpenWebText. For example, if CORD-19 and are trained for a similar duration and are likely to
OpenWebText have multiple similar or duplicated underfit,14 nearly 6% of CORD19GPT-generated
content, the fine-tuned model would have been im- texts using top-k sampling plagiarize its fine-tuning
mensely exposed to it and may have started to re- corpus. We speculate that this phenomenon can be
member it. That being said, we attempt to measure explained by the different characteristics of each
relevancy between all three fine-tuning corpora and dataset. CORD-19 consists of full scholarly pa-
pre-training corpus independently. In order to sim- pers that already include multiple references unlike
plify the task, we recycle some part of Section patent- or abstract-related data. Also, while topics
4.1 by: 1) selecting arbitrary 500 documents in a of patent or abstract documents are diverse, the
fine-tuning dataset; 2) using document segments CORD-19 dataset is more specific to the coron-
as queries in Elasticsearch and retrieving similarity avirus, and its discipline is centered on Medicine
scores of 10,000 most relevant OpenWebText doc- and Biology.
uments, and 3) aggregating averaged scores. As
BM25 is sensitive to a query length, we only use 7 Discussion and Limitations
the first 300 characters of each document for a fair
comparison. Larger LMs plagiarize more. Consistent with
(Carlini et al., 2021) and (Carlini et al., 2022), we
Indeed, patent data (score=21369.60) obtained find that larger models (large and xl) generally gen-
the highest summation of similarity scores to Open- erate plagiarized sequences more frequently than
WebText, followed by Cord-19 (score=19818.82) smaller ones. Based on the decoding approaches,
and Arxiv abstract (score=17904.18) dataset. In however, the model size that yields the largest
addition, we perform a manual inspection on pla- amount of plagiarism seems to change: when the
giarized examples and find that they are highly next token is sampled from truncated distribution,
domain-specific. For instance, sentences such as the GPT-2 large model plagiarizes the most. On the
‘Written informed consent was obtained from the other hand, the GPT-2 xl becomes more strongly
involved participants’ or ‘Clinical data from ani- associated with plagiarism than the GPT-2 large
mal care facilities were in strict accordance with when temperature setting without truncation is em-
National Institutes of Health-approved guidelines.’ ployed. This discrepancy may be attributable to
are relatively common expressions used in med- 14
We kept the training steps relatively small and trained
ical scholarly writing. Many PatentGPT-written models while a gap between training and test losses is below
instances that are plagiarized are also from patent 20% of training loss.error rates of our paraphrase and idea plagiarism deep neural language models. We discover multi-
detection tool. Regardless, it is evident that larger ple plagiarized examples where users’ sensitive or
models plagiarize significantly more training data. private data such as phone number or email address
Considering LMs’ performance improvement with is exposed. Although all identified content were
larger model sizes, this finding sheds light on a publicly available on the Web, it does not give a
trade-off between models’ performance and author- right for LMs to reveal their personal information
ship or copyright protection of training samples. without consent. Our research overall has raised
Fine-tuning with an auxiliary dataset has vary- a concern towards the growing use of a language
ing impacts on plagiarism of LMs based on its model, considering its potential harm on both our
characteristics. To the best of our knowledge, privacy and authorship.
we’re the first to inspect either memorization or Limitations First, our findings are based on one
plagiarism issues of fine-tuned language models. particular language model, GPT-2, and thus may
Our findings highlight that fine-tuning a model not generalize to other models such as GPT-3 and
with an auxiliary data can mitigate memorization T5. We acknowledge that language models may
from the pre-training dataset. Still, other types of demonstrate different patterns of plagiarism. Fu-
plagiarism cases have surged, in case of Patent- ture work can revisit the proposed research ques-
GPT and Cord19GPT, alongside similarity levels tions on more diverse neural language models. Sec-
between pre-training and fine-tuning corpora. Inter- ond, our plagiarism type detection pipeline em-
estingly, this does not influence plagiarism from the ploys additional strict restrictions, especially on
pre-trained corpus: only the CORD19GPT demon- paraphrase detection, to minimize false positives.
strates intensified degree of plagiarism where pla- This could have limited us from capturing nuanced
giarized documents make up to 6%. We are uncer- plagiarism and led to missing some examples. For
tain why CORD19GPT behaves differently, but we instance, the NER library will fail to distinguish
assume this is due to the specificity of the CORD- a sentence pair (‘Trump has arrived in Seoul at
19 dataset. As part of future work, we will quantita- 11:00AM on March 12th.’,‘Trump has arrived in
tively compare topical variations of these datasets Seoul in the morning of March 12th, 2018’) as para-
and validate our assumption. phrases because extracted entities do not directly
match. Moreover, we only identify one type of
Decoding methods and parameters affect pla-
plagiarism given two documents. It is possible that
giarism. Varying effects of decoding methods and
a document pair may contain multiple plagiarism
their parameters on text quality and diversity have
categories.
been extensively studied (DeLucia et al., 2020; Dou
et al., 2021; Basu et al., 2020), but not from the
8 Conclusion
plagiarism perspective. In particular, top-p sam-
pling is reported to be the most effective decod- Our work presents the first holistic and empirical
ing method in various generation settings (Ippolito analyses of plagiarism in large language models by
et al., 2019a; Zhang et al., 2020). Our analyses constructing a novel pipeline for the automatic iden-
show increased plagiarism frequencies when us- tification of plagiarized content. We conclude that
ing top-p and top-k decoding strategies as opposed GPT-2 can regenerate phrases, sentences, and even
to the temperature setting. That is, sampling the ideas that are originally included in OpenWebText,
next token from truncated LM distributions can a pre-training corpus. Worryingly, this behavior
lead to more plagiarism cases. Our supplementary tends to exacerbate as model size increases. We
finding reported in Appendix C further confirms have also shown their plagiarism patterns are more
that altering decoding parameters including t and complicated than expected: 1) depending on prop-
p can significantly affect models’ plagiarism as it erties of fine-tuning data such as corpus similarities
does for novelty and quality sides. It therefore is or topical variations, fine-tuned LMs can either be
critical to carefully choose decoding strategies and plagiarism-free or intensely plagiarize from both
parameters not only through the lens of quality and pre-training and fine-tuning corpora; 2) top-k and
diversity but also through plagiarism aspects. top-p sampling exploit more of training data with-
Plagiarism can pose privacy harms. Our find- out crediting content creators compared to temper-
ings add value to ongoing discussions around pri- ature sampling. To sum up, careful examination of
vacy breaches resulting from the memorization of datasets used to pre-train or fine-tune and deploy-ment of decoding approaches is of necessity when that directly controls perplexity. arXiv preprint
performing NLG tasks. arXiv:2007.14966.
While effort has also been made towards pre- Hannah Brown, Katherine Lee, Fatemehsadat
serving privacy in LMs by filtering out sensitive Mireshghallah, Reza Shokri, and Florian Tramèr.
information from a training set or adopting Dif- 2022. What does it mean for a language model to
ferential Privacy (DP) algorithms (Dwork et al., preserve privacy? arXiv preprint arXiv:2202.05520.
2006; Dwork, 2008), there has been less progress Nicholas Carlini, Daphne Ippolito, Matthew Jagielski,
towards resolving memorization and plagiarism is- Katherine Lee, Florian Tramer, and Chiyuan Zhang.
sues. The most common solution is to apply data 2022. Quantifying memorization across neural lan-
deduplication techniques to training data (Lee et al., guage models. arXiv preprint arXiv:2202.07646.
2021; Kandpal et al., 2022), which are computa- Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej
tionally exhaustive and do not completely eradi- Kos, and Dawn Song. 2019. The secret sharer: Eval-
cate verbatim text sequences. Most importantly, it uating and testing unintended memorization in neu-
is uncertain if these methods can reduce cases of ral networks. In 28th USENIX Security Symposium
(USENIX Security 19), pages 267–284.
paraphrase or idea plagiarism. Prior to indiscrimi-
nate data collection and gigantic model training, we Nicholas Carlini, Florian Tramer, Eric Wallace,
should focus on the development of LMs that are Matthew Jagielski, Ariel Herbert-Voss, Katherine
trained exclusively on sanitized and consented data Lee, Adam Roberts, Tom Brown, Dawn Song, Ul-
far Erlingsson, et al. 2021. Extracting training data
and further do not emit exact or rephrased copies from large language models. In 30th USENIX Secu-
of them. rity Symposium (USENIX Security 21), pages 2633–
2650.
References Elizabeth Clark, Tal August, Sofia Serrano, Nikita
Haduong, Suchin Gururangan, and Noah A Smith.
David H Ackley, Geoffrey E Hinton, and Terrence J Se- 2021. All that’s’ human’is not gold: Evaluating hu-
jnowski. 1985. A learning algorithm for boltzmann man evaluation of generated text. arXiv preprint
machines. Cognitive science, 9(1):147–169. arXiv:2107.00061.
Basant Agarwal, Heri Ramampiaro, Helge Langseth, Roger Clarke. 2006. Plagiarism by academics: More
and Massimiliano Ruocco. 2018. A deep network complex than it seems. Journal of the Association
model for paraphrase detection in short text mes- for Information Systems, 7(1):5.
sages. Information Processing & Management,
54(6):922–937. Mark W Davis and William C Ogden. 1997. Free re-
sources and advanced alignment for cross-language
Asim M El Tahir Ali, Hussam M Dahwa Abdulla, and text retrieval. In TREC, volume 1997, pages 385–
Vaclav Snasel. 2011. Overview and comparison of 395. Citeseer.
plagiarism detection tools. In Dateso, pages 161–
172. Alexandra DeLucia, Aaron Mueller, Xiang Lisa Li, and
João Sedoc. 2020. Decoding methods for neural nar-
Alaa Saleh Altheneyan and Mohamed El Bachir Menai. rative generation. arXiv preprint arXiv:2010.07375.
2020. Automatic plagiarism detection in obfuscated
text. Pattern Analysis and Applications, 23(4):1627– Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
1650. Kristina Toutanova. 2018. Bert: Pre-training of deep
bidirectional transformers for language understand-
Salha Alzahrani. 2015. Arabic plagiarism detection us- ing. arXiv preprint arXiv:1810.04805.
ing word correlation in n-grams with k-overlapping
approach. In Proceedings of the Workshops at Yao Dou, Maxwell Forbes, Rik Koncel-Kedziorski,
the 7th Forum for Information Retrieval Evaluation Noah A Smith, and Yejin Choi. 2021. Scarecrow:
(FIRE), pages 123–125. A framework for scrutinizing machine text. arXiv
preprint arXiv:2107.01294.
Devansh Arpit, Stanisław Jastrz˛ebski, Nicolas Ballas,
David Krueger, Emmanuel Bengio, Maxinder S Kan- Cynthia Dwork. 2008. Differential privacy: A survey
wal, Tegan Maharaj, Asja Fischer, Aaron Courville, of results. In International conference on theory and
Yoshua Bengio, et al. 2017. A closer look at mem- applications of models of computation, pages 1–19.
orization in deep networks. In International confer- Springer.
ence on machine learning, pages 233–242. PMLR.
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and
Sourya Basu, Govardana Sachitanandam Ramachan- Adam Smith. 2006. Calibrating noise to sensitivity
dran, Nitish Shirish Keskar, and Lav R Varshney. in private data analysis. In Theory of cryptography
2020. Mirostat: A neural text decoding algorithm conference, pages 265–284. Springer.Julianne East. 2010. Judging plagiarism: a prob- Eugene Kharitonov, Marco Baroni, and Dieuwke Hup-
lem of morality and convention. Higher Education, kes. 2021. How bpe affects memorization in trans-
59(1):69–83. formers. arXiv preprint arXiv:2110.02782.
Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hi- Robin Küppers and Stefan Conrad. 2012. A set-based
erarchical neural story generation. arXiv preprint approach to plagiarism detection. In CLEF (Online
arXiv:1805.04833. Working Notes/Labs/Workshop).
R. Stuart Geiger. 2019. ArXiV Archive: A tidy and Jieh-Sheng Lee and Jieh Hsiang. 2020. Patent claim
complete archive of metadata for papers on arxiv.org, generation by fine-tuning openai gpt-2. World
1993-2019. Patent Information, 62:101983.
Erfaneh Gharavi, Kayvan Bijari, Kiarash Zahirnia, and Katherine Lee, Daphne Ippolito, Andrew Nystrom,
Hadi Veisi. 2016. A deep learning approach to per- Chiyuan Zhang, Douglas Eck, Chris Callison-Burch,
sian plagiarism detection. FIRE (Working Notes), and Nicholas Carlini. 2021. Deduplicating training
34:154–159. data makes language models better. arXiv preprint
arXiv:2107.06499.
Erfaneh Gharavi, Hadi Veisi, and Paolo Rosso. 2020.
Scalable and language-independent embedding- Klas Leino and Matt Fredrikson. 2020. Stolen mem-
based approach for plagiarism detection considering ories: Leveraging model memorization for cali-
obfuscation type: no training phase. Neural Com- brated {White-Box} membership inference. In 29th
puting and Applications, 32(14):10593–10607. USENIX Security Symposium (USENIX Security 20),
pages 1605–1622.
Zaobo He, Zhipeng Cai, and Jiguo Yu. 2017. Latent-
data privacy preserving with customized data utility Sharon Levy, Michael Saxon, and William Yang
for social network data. IEEE Transactions on Ve- Wang. 2021. Investigating memorization of con-
hicular Technology, 67(1):665–673. spiracy theories in text generation. arXiv preprint
arXiv:2101.00379.
Peter Henderson, Koustuv Sinha, Nicolas Angelard-
Gontier, Nan Rosemary Ke, Genevieve Fried, Ryan Chuan Li. 2020. Openai’s gpt-3 language model: A
Lowe, and Joelle Pineau. 2018. Ethical challenges technical overview.
in data-driven dialogue systems. In Proceedings of
the 2018 AAAI/ACM Conference on AI, Ethics, and Zehui Lin, Xiao Pan, Mingxuan Wang, Xipeng Qiu,
Society, pages 123–129. Jiangtao Feng, Hao Zhou, and Lei Li. 2020. Pre-
training multilingual neural machine translation by
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and leveraging alignment information. arXiv preprint
Yejin Choi. 2019. The curious case of neural text arXiv:2010.03142.
degeneration. arXiv preprint arXiv:1904.09751.
Romans Lukashenko, Vita Graudina, and Janis Grund-
Daphne Ippolito, Daniel Duckworth, Chris Callison- spenkis. 2007. Computer-based plagiarism detec-
Burch, and Douglas Eck. 2019a. Automatic detec- tion methods and tools: an overview. In Proceedings
tion of generated text is easiest when humans are of the 2007 international conference on Computer
fooled. arXiv preprint arXiv:1911.00650. systems and technologies, pages 1–6.
Daphne Ippolito, Daniel Duckworth, Chris Callison- Sheikh Tariq Mahmood. 2010. Intellectual property
Burch, and Douglas Eck. 2019b. Human and auto- right and patent: Conceptual awareness of phd stu-
matic detection of generated text. dents about plagiarism. In 2010 International Con-
ference on Education and Management Technology,
MAC Jiffriya, MAC Akmal Jahan, and Roshan G pages 694–700. IEEE.
Ragel. 2014. Plagiarism detection on electronic text
based assignments using vector space model. In R Thomas McCoy, Paul Smolensky, Tal Linzen, Jian-
7th International Conference on Information and Au- feng Gao, and Asli Celikyilmaz. 2021. How much
tomation for Sustainability, pages 1–5. IEEE. do language models copy from their training data?
evaluating linguistic novelty in text generation using
Nikhil Kandpal, Eric Wallace, and Colin Raffel. raven. arXiv preprint arXiv:2111.09509.
2022. Deduplicating training data mitigates pri-
vacy risks in language models. arXiv preprint Casey Meehan, Kamalika Chaudhuri, and Sanjoy Das-
arXiv:2202.06539. gupta. 2020. A non-parametric test to detect data-
copying in generative models. In International Con-
Jared Kaplan, Sam McCandlish, Tom Henighan, ference on Artificial Intelligence and Statistics.
Tom B Brown, Benjamin Chess, Rewon Child, Scott
Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Norman Meuschke and Bela Gipp. 2013. State-of-the-
2020. Scaling laws for neural language models. art in detecting academic plagiarism. International
arXiv preprint arXiv:2001.08361. Journal for Educational Integrity, 9(1).Fatemehsadat Mireshghallah, Huseyin A Inan, Mar- Approaches to Semitic Languages: Common Issues
cello Hasegawa, Victor Rühle, Taylor Berg- and Resources, pages 73–80.
Kirkpatrick, and Robert Sim. 2021. Privacy regu-
larization: Joint privacy-utility optimization in lan- Syed Shahabuddin. 2009. Plagiarism in academia. In-
guage models. arXiv preprint arXiv:2103.07567. ternational Journal of Teaching and Learning in
Higher Education, 21(3):353–359.
John X Morris, Eli Lifland, Jin Yong Yoo, Jake Grigsby,
Di Jin, and Yanjun Qi. 2020. Textattack: A Hassan Shahmohammadi, MirHossein Dezfoulian, and
framework for adversarial attacks, data augmenta- Muharram Mansoorizadeh. 2021. Paraphrase detec-
tion, and adversarial training in nlp. arXiv preprint tion using lstm networks and handcrafted features.
arXiv:2005.05909. Multimedia Tools and Applications, 80(4):6479–
6492.
Azra Nazir, Roohie Naaz Mir, and Shaima Qureshi.
2021. Idea plagiarism detection with recurrent neu-
Prasha Shrestha and Thamar Solorio. 2013. Using a va-
ral networks and vector space model. International
riety of n-grams for the detection of different kinds
Journal of Intelligent Computing and Cybernetics.
of plagiarism. Notebook for PAN at CLEF, 2013.
Yurii Palkovskii and Alexei Belov. 2014. Developing
high-resolution universal multi-type n-gram plagia- Richard Socher, Eric Huang, Jeffrey Pennin, Christo-
rism detector. Cappellato et al.[35]. pher D Manning, and Andrew Ng. 2011. Dynamic
pooling and unfolding recursive autoencoders for
Diane Pecorari. 2008. Academic writing and plagia- paraphrase detection. Advances in neural informa-
rism: A linguistic analysis. Bloomsbury Publishing. tion processing systems, 24.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Wendy Sutherland-Smith. 2008. Plagiarism, the Inter-
Ilya Sutskever. 2018. Improving language under- net, and student learning: Improving academic in-
standing by generative pre-training. tegrity. Routledge.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan,
Om Dipakbhai Thakkar, Swaroop Ramaswamy, Rajiv
Dario Amodei, Ilya Sutskever, et al. 2019. Lan-
Mathews, and Francoise Beaufays. 2021. Under-
guage models are unsupervised multitask learners.
standing unintended memorization in language mod-
OpenAI blog, 1(8):9.
els under federated learning. In Proceedings of the
Stephen E Robertson, Steve Walker, Susan Jones, Third Workshop on Privacy in Natural Language
Micheline M Hancock-Beaulieu, Mike Gatford, et al. Processing, pages 1–10.
1995. Okapi at trec-3. Nist Special Publication Sp,
109:109. Stacey Truex, Ling Liu, Mehmet Emre Gursoy, Lei
Yu, and Wenqi Wei. 2018. Towards demystify-
Meysam Roostaee, Seyed Mostafa Fakhrahmad, and ing membership inference attacks. arXiv preprint
Mohammad Hadi Sadreddini. 2020. Cross-language arXiv:1807.09173.
text alignment: A proposed two-level matching
scheme for plagiarism detection. Expert Systems Adaku Uchendu, Thai Le, Kai Shu, and Dongwon Lee.
with Applications, 160:113718. 2020. Authorship attribution for neural text gener-
ation. In Conf. on Empirical Methods in Natural
Ahmed Salem, Apratim Bhattacharya, Michael Backes, Language Processing (EMNLP).
Mario Fritz, and Yang Zhang. 2020. {Updates-
Leak}: Data set inference and reconstruction attacks Lucy Lu Wang, Kyle Lo, Yoganand Chandrasekhar,
in online learning. In 29th USENIX Security Sympo- Russell Reas, Jiangjiang Yang, Darrin Eide, Kathryn
sium (USENIX Security 20), pages 1291–1308. Funk, Rodney Kinney, Ziyang Liu, William Merrill,
et al. 2020. Cord-19: The covid-19 open research
Miguel A Sanchez-Perez, Alexander Gelbukh, and
dataset. ArXiv.
Grigori Sidorov. 2015. Adaptive algorithm for pla-
giarism detection: The best-performing approach
Wenpeng Yin and Hinrich Schütze. 2015. Convolu-
at pan 2014 text alignment competition. In Inter-
tional neural network for paraphrase identification.
national Conference of the Cross-Language Evalu-
In Proceedings of the 2015 Conference of the North
ation Forum for European Languages, pages 402–
American Chapter of the Association for Computa-
413. Springer.
tional Linguistics: Human Language Technologies,
Miguel A Sanchez-Perez, Grigori Sidorov, and Alexan- pages 901–911.
der F Gelbukh. 2014. A winning approach to text
alignment for text reuse detection at pan 2014. In Santiago Zanella-Béguelin, Lukas Wutschitz, Shruti
CLEF (Working Notes), pages 1004–1011. Tople, Victor Rühle, Andrew Paverd, Olga Ohri-
menko, Boris Köpf, and Marc Brockschmidt. 2020.
Nasredine Semmar and Christian Fluhr. 2007. Arabic Analyzing information leakage of updates to natural
to french sentence alignment: Exploration of a cross- language models. In Proceedings of the 2020 ACM
language information retrieval approach. In Pro- SIGSAC Conference on Computer and Communica-
ceedings of the 2007 Workshop on Computational tions Security, pages 363–375.Chiyuan Zhang, Daphne Ippolito, Katherine Lee, That is, the probability distribution of a word se-
Matthew Jagielski, Florian Tramèr, and Nicholas quence can be calculated through the product of
Carlini. 2021. Counterfactual memorization
conditional next word distributions. In response to
in neural language models. arXiv preprint
arXiv:2112.12938. an arbitrary prompt, GPT-2 could adapt to its style
and content and generate synthetic texts. Decoding
Hugh Zhang, Daniel Duckworth, Daphne Ippolito, and methods can also be applied to GPT-2, which are
Arvind Neelakantan. 2020. Trading off diversity
well known to be critical for performance in text
and quality in natural language generation. arXiv
preprint arXiv:2004.10450. generation (Ippolito et al., 2019b). We primarily
consider the following decoding strategies:
Xuhui Zhou, Nikolaos Pappas, and Noah A
Smith. 2020. Multilevel text alignment with • Temperature (Ackley et al., 1985): control the
cross-document attention. arXiv preprint randomness of predictions by dividing the logits
arXiv:2010.01263. by t before applying softmax
Derui Zhu, Jinfu Chen, Weiyi Shang, Xuebing Zhou, • Top-k (Fan et al., 2018): filter the k most likely
Jens Grossklags, and Ahmed E Hassan. 2021.
Deepmemory: Model-based memorization analy- next words and redistribute the probability mass
sis of deep neural language models. In 2021
36th IEEE/ACM International Conference on Au- • Top-p (Holtzman et al., 2019): choose from the
tomated Software Engineering (ASE), pages 1003– smallest possible set of words whose cumulative
1015. IEEE. probability exceeds the probability p
A Details on Sanchez-Perez et al. (2015) Changing decoding parameters can substantially
influence diversity and quality aspects of generated
Sanchez-Perez et al. (2014) initially presented the texts: the novelty can be enhanced by increasing
winning approach at the plagiarism detection com- parameter values (t, k, p), but comes at the cost of
petition of PAN 201415 and further improved its degraded quality (McCoy et al., 2021).
performance by adopting adaptive parameter selec-
tion (Sanchez-Perez et al., 2015). C Experiment with Decoding
Their methods consist of five steps which in- Parameters
clude (1) text-preprocessing (lower-case all charac-
In order to measure how decoding parameters af-
ters, tokenize, and stem; (2) obfuscation type iden-
fect plagiarism, 1000 documents are generated for
tification (verbatim/random/translation/summary
each parameter setting (t=1, k=40, p ∈ [0.7, 0.8,
obfuscation); (3) seeding (given two documents,
0.9]). We experiment with various values only for
deconstruct long passages into smaller segments
the Cord19GPT because there are not many pla-
and finding candidate pairs through sentence-level
giarism cases for the other two fine-tuned models.
similarity measurement); (4) extension (form larger
Figure 3 demonstrates a distribution of plagiarism
text fragments that are similar via clustering); and
types occurred from The CORD19 dataset with
(5) filtering (remove overlapping and short pla-
varying parameter settings. Results indicate that
giarized fragment). In summary, they transform
the higher parameters t and p got the higher number
the suspicious and source sentences as term fre-
of plagiarism tended to occur. Interestingly, param-
quency–inverse document frequency (tf-idf) vector
eter values of top-k sampling did not significantly
weights and then calculate the similarity between
affect CORD19GPT’s plagiarizing attitudes.
the sentence pairs using the Dice coefficient and
cosine measure. Adaptive parameter selection is D Details on Plagiarized Texts
achieved by testing two settings recursively for the
summary obfuscation corpus and the other three We inspect text segments plagiarized from Open-
corpora. Webtext by the pre-trained GPT-2 model, as our
primary focus is understanding plagiarizing behav-
B Decoding Methods iors of GPT-2 itself. See Table 3 to view plagia-
rized content we discovered. We find that longest
GPT-2 is an autoregressive language model predict- memorized texts contain 5,920 characters (Table
ing one token at a time in a left-to-right fashion. 4). Based on our manual inspection of verbatim
15
https://pan.webis.de/clef14/ plagiarism, many sequences are from highly du-
pan14-web/text-alignment.html plicated texts throughout the training corpus: on20.0
Verbatim
Paraphrase
17.5 Idea
15.0
12.5
Document Percentage
10.0
7.5
5.0
2.5
0.0
t=0.8 t=0.9 t=1.0 k=20 k=40 k=60 k=80 k=100 p=0.7 p=0.8 p=0.9
Decoding Parameters
Figure 3: Distribution of Plagiarism Categories w.r.t.
Decoding Parameters (Cord19GPT)
average, memorized texts appeared 205 times (at
most 14,246 times) in 50% of OpenWebText cor-
pus. At the same time, there still exist several
instances where models memorize without seeing
them more than two times (Table 5).Type Neural Text OpenWebText
Verbatim [...] Newsletter Sign Up Continue reading same as neural text
the main story Please verify you’re not a
robot by clicking the box. Invalid email
address. Please re-enter. You must select a
newsletter to subscribe to. [...]
Verbatim [...] This article contains affiliate links, same as neural text
which means we may earn a small commis-
sion if a reader clicks through and makes
a purchase. All our journalism is indepen-
dent and is in no way influenced by any ad-
vertiser or commercial initiative. The links
are powered by Skimlinks. By clicking on
an affiliate link, you accept that Skimlinks
cookies will be set. More information.
Verbatim it reminded me of a feeling I’ve had right same as neural text
there on that road before. It reminded me
of all the times that people have come out
to support the blockade and stood together
to make sure those trees stay standing. And
I wish we didn’t have to do it again, but I
know that if we have to, we can. Yes, we
stopped them logging the Upper Florentine
and we can do it again [...]
Paraphrase [...] Conflict of Interest Disclosures: None [...] Conflict of Interest Disclosures: Both
reported. Funding/Support: Medical Re- authors have completed and submitted the
search Council Biotechnology Programme ICMJE Form for Disclosure of Potential
[...] Conflicts of Interest and none were re-
ported. Funding/Support: This work was
supported by grant [...]
Paraphrase [...] HOWEVER, SOME STATES [...] Some states do not allow the exclusion
DO NOT ALLOW THE EXCLUSION or limitation of liability for consequential
OR LIMITATION OF IMPLIED WAR- or incidental damages so the foregoing lim-
RANTIES, SO THE ABOVE LIMITA- itation may not apply.
TION OR EXCLUSION MAY NOT AP-
PLY TO YOU.
Paraphrase "I’ve got to use some Tic Tacs just in case "I better use some Tic Tacs in case I start
I start kissing her," an apparently angry kissing her," Trump says, with the sound
Trump says in a video obtained by The of mints rattling in a box audible in the
Washington Post. "I’m automatically at- background. "I’m automatically attracted
tracted to beautiful - I just start kissing to beautiful - I just start kissing them. It’s
them. It’s like a magnet. Just kiss. I don’t like a magnet... And when you’re a star,
even wait. And when you’re a star, they they let you do it. You can do anything.
let you do it. You can do anything." Trump
continues.Idea If Horrible Combustion becomes the tar- [...] If that creature deals combat damage
get of a spell or ability that gives it lethal to a player at the same time it’s dealt lethal
damage, Horrible Combustion’s ability will damage (perhaps because it has trample
be activated and the lethal damage will and was blocked), it will die before the
be dealt. Once that occurs, no damage triggered ability resolves and puts +1/+1
can be prevented. (This is known as the counters on it. [...]
"Kai Mauler" effect.) Horrible Combustion
doesn’t deal lethal damage itself. If Hor-
rible Combustion deals lethal damage but
damage it can’t prevent is dealt to a player,
Horrible Combustion will cause that player
to lose life equal to an amount determined
by how much Horrible Combustion was
dealt damage in damage prevention. The
actual amount of life based on the lethal
damage is determined before any damage
is dealt. For example, if an opponent con-
trols Coralhelm Commander, and Horrible
Combustion deals 12/60 damage to a crea-
ture, the half of that damage dealt by the
outsider creature will cause that player to
lose 12 life.
Idea For example, Ontario is leading in the Better Access to Mental Health Services
federal-provincial partnership by using Phase
the Mental Health Reconciliation Strat- One of the Comprehensive Mental Health
egy to increase access to mental health and Addictions Strategy provided more
care across the province. In August 2017, than 50,000 additional children and youth
the government announced 50 million in across Ontario with access to mental health
savings from the partnership strategy by and addictions services.
taking a 6-billion hit to provide men-
tal health care services to Canadians in
Ontario. There are some important high-
lights from this partnership: Provincial
governments—particularly the provincial
Liberal party—will be providing $2.5 bil-
lion over the next three years to strengthen
mental health services and to help build
community-based services at community
and religious meetings The government
committed to using the Canadian Mental
Health Care Act to enhance mental health
services in Ontario to the benefit of Cana-
dian communities This will help to create a
pathway to an accessible and quality, long-
term mental health care systemYou can also read

















































