Dictionary Based Spelling Corrector System: The Case of Six Ethiopian Languages
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
Dictionary Based Spelling Corrector System: The
Case of Six Ethiopian Languages
Wubetu Barud Demilie
Department of Information Technology, Wachemo University, Hossana, Ethiopia, P.O. Box: 667
ABSTRACT
A dictionary-based spelling correctorisa system that can directly identify what natural language is being
dealt with and shifts to the proper spelling corrector for the languages that system users are interested to
do so. Spelling corrector systems for languages would be used to check errors for any kind of spelling
mistakes and are fairly reliant on the words in the lexicon dictionary. Some words may have very few
words spelled similarly, so even numerous faults will recover the accurate word. Other words will have
many likewise spelled words, so one error may make alteration problematic or unbearable. A dictionary-
based model is used in noticing and modifying diverse classes of spelling errors. The main features of
the planned model can be précised in giving the proposals for noticed errors and providing the
correction automatically using the first suggestion. Furthermore, the planned model is calculated using
dictionary-based data sets for all languages that the researcher has been selected for the study. This
research work is based on a model dictionary-based which detects and corrects errors for six Ethiopian
languages including Amharic, Afan Oromo, Tigrinya, Hadiyyisa, Kambatissa, and Awngi. The used
corpora have been collected from balanced sources that contain economic, political, social, and related
newspapers. Finally, after a successful evaluation of the proposed model, precision, recall, and f-
measures have been calculated for each language.
Keywords: Dictionary, Error Correction, Error Detection, Suggestion, Spelling Corrector
1868
International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
1. Introduction
Language is a medium of communication and which helps human beings to exchange ideas and
information accordingly. Spelling corrector systems for languages would be used to check spellings for any
kind of spelling errors. The working principles of spelling corrector including error detection have been
clearly described in the work of (Demilie, 2020b)(Demilie, 2020a)and the words from the dictionary are
suggested to the user who chooses the word that was intended. Spelling corrector systems are used in
various Natural Language Processing Applications (NLPAs) including parts of speech tagger (Demilie,
2019)(TEKLAY, 2010) and as grammar checkers (Tesfaye, 2011).
In this research paper, the researcher has designed, implemented, and evaluated an end-to-end
system that performs spelling corrector and auto-correction for six Ethiopian languages.
2. Literature Review
There have been extensive researches on the problem of spelling error correction without a widely
used common benchmark. Each publication uses its benchmark and compares it to a (usually small) subset
of methods.
According to(Kumar et al., 2018), researchers have been concluded that the performance of the
spelling corrector system can be improved by using the n-gram model and it can be used for many
languages. Those researchers have been suggested that “n-grams can be used in two ways, either without a
dictionary or together with a dictionary”. As the conclusions to the researchers, the performance of the spell
corrector without a dictionary is limited. Its main advantage is its simplicity and does not require any
dictionary. Here, if they are together, it can be used to define the distance between words, and the words are
always checked against the dictionary. Finally, they have concluded that the implementation of both
models together will improve the performance of the spelling corrector.
According to (Atawy, 2018), developed a language-independent spelling corrector that was based
on n-gram techniques. It was used in detecting and correcting spelling errors. The researcherhas concluded
that the "n-gram model provides correction and suggestions by selecting the most suitable suggestions from
a list of corrective suggestions based on lexical resources and n-gram statistics." Finally, the researcher
has achieved and concluded an overall performance of 93%.
According to (Demilie, 2020b), the proposed model can be summarized in giving the proposals for
noticed errors and providing the correction automatically using the first suggestion. Here, the researcher
had concluded his work with precision (86.6%, 85.3% ,83.9%, 82.8% and 84.7%), recall
(84.7%,81.9%,82.4%,81.6% and 81.9%) and f-measure (85.65%,83.6%,83.15%,82.2% and 83.3%) for
languages Amharic, Afan Oromo, Tigrinya, Hadiyyisa and Awngi respectively.
The spelling correction that the researcher has been implemented in the state-of-the-art algorithm
that different researchers have been recommended to be used for correction of spelling mistakes which will
be implemented for all languages accordingly (Demilie, 2020b) which is dictionary lookup.
1869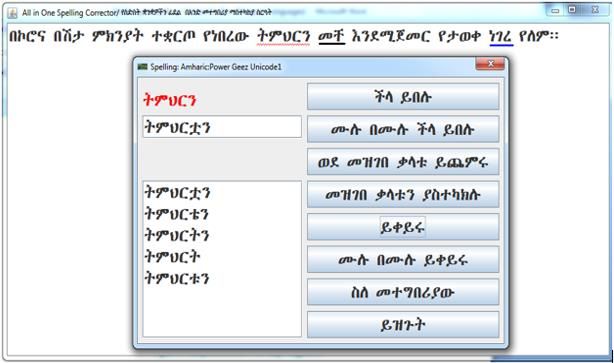
International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
3. Significance of the Study
Learning to spell helps to adhesive the relation and/or linkage between the letters and their
resonances, and learning high occurrence to mastery level progresses both in reading and writing. The more
intensely and carefully an operator identifies a word, the more probable he or she is to identify it, spell it,
define it, and use it properly in speech and script (Spelling, n.d.). Many researchers of the area have
developed different spelling correctors for foreign and Ethiopian languages. From those researchers
especially, Ethiopian researchers no one has been developed a spelling corrector for more than three
Ethiopian languages except (Demilie, 2020b) within one system (Gezmu et al., 2014)(Ganfure & Midekso,
2014)(Jeldu & Mehta, 2018). This study had an option that informs system users to select the language
accordingly. Here, the researcher acknowledged the researchers who have done different studies for
Ethiopian languages including grammatical rules, word formation, sentence structure, and other related
concepts for foreign and Ethiopian languages (TEKLAY, 2010)(University), n.d.)(Tamirat, n.d.)(Hadiyya
(Hadiyyisa) Language Orthography - Alphabet and Writing - Themes on the Hadiya People of Ethiopia,
n.d.)(Kambaata language - Wikipedia, n.d.)(Samuel et al., 2018)(Misikir, 2013).
4. Methodology
There are many methodologies for identifying and correcting spelling errors in written texts. For the
study, the researcher has used a dictionary-based method that is engaged to relate and detect input strings in
a dictionary, a lexicon, a corpus, or an amalgamation of lexicons and corpora. The datasets or lexicon files
for the six Ethiopian languages have been collected from different genres that have balanced corpora and/or
lexicon with the help of linguistic experts of each language. To serve the purpose of spelling error detection
and correction, exact string matching mechanisms have been used. If any string or word is not present in
the chosen lexicon or corpus, it is considered to be a misspelled or worthless word. At this stage, the
researcher considers that all words in the lexicon or corpus are morphologically complete, i.e. all inflected
forms are included in the dictionary. The attention on dropping dictionary search time via effective
dictionary-based and/or pattern corresponding tactics, via dictionary partitioning structures and
morphological processing ways. The most substantial dictionary-based tactics are hashing binary search
trees and finite state automata. From those listed approaches, the researcher has used hashing since it is a
well-known and efficient dictionary lookup strategy.
5. Result and Discussion
To evaluate the performance, the approach that the researcher has selected and to demonstrate its
easy portability to all six Ethiopian languages. To evaluate the system with improved performance than the
work of (Demilie, 2020b), he has collected corpora that are greater than (Demilie, 2020b), from balanced
sources and within detail linguistic analysis of each language. After the preprocessing stages of the study,
all languages have been evaluated based on the corpora that have been collected.Firstly, the researcher
made an evaluation based on Amharic language test data which are in the dictionary file list. Secondly, he
made an evaluation based on Afan Oromo language test data which are in the dictionary file list. Thirdly,
he made an evaluation based on Tigrinya language test data which are in the dictionary file list. Fourthly,
1870
International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
he made an evaluation based on the Hadiyyisa language test data which are in the dictionary file list.
Fifthly, he made an evaluation based on Kambatissa language test data which are in the dictionary file list.
Finally, he made an evaluation based on Awngi language test data which are in the dictionary file list. To
evaluate the spelling error detection capability of the selected approach for all six languages, precision,
recall, and f-measure were used as metrics. The comparative locations of the correct spellings in the
reasonable suggestions list were used to evaluate spelling error correction.
6. Test Data
The study used manually prepared spelling error test corpora with the help of linguistic experts of
each language for evaluation of the performances. For the study, the researcher has used a test corpus that
has been collected from different sources that are balanced.
Table 1: Word dictionaries for all languages
No Language Amount of words (dictionary files)
1. Amharic 1,009,072
2. Afan Oromo 882,328
3. Tigrinya 1,003,176
4. Hadiyyisa 982,328
5. Kambatissa 879,328
6. Awngi 693,121
Here, to evaluate and compute the actual scores manually compiled test data have been used as the
gold standard/ balanced data set for the evaluation.
-----------(1)
---------------(2)
------(3)
The excellence of suggestions obtainable by a spelling corrector is dignified by the virtual locations
of the accurate spellings in the suggestions list that has been prepared in the dictionary suggestions list. In
the best situation, the right correction always appears on the topmost of the list accordingly.
Table 1:Six Ethiopian languages spelling error detection result
Metric Languages
Amharic Afan Oromo Tigrinya Hadiyyisa Kambatissa Awngi
Precision 91.88% 89.29% 90.33% 87.83% 83.13% 89.17%
Recall 87.37% 85.91% 86.37% 85.85% 80.49% 86.06%
F-measure 89.57% 87.57% 88.31% 86.83% 81.83% 87.59%
Different experiments have been done for the selected languages independently to evaluate the
spelling corrector as of evaluating the quality of the proposed system. To achieve this, the evaluation was
1871
International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
done on all languages as shown above. Here, languages including Amharic, Tigrinya, and Awngi use the
Ge'ez script and the researcher has included font identifier into the system. But the remaining three
languages use Latin script and it is possible to use it as it is without font modification.
We can consider the following common java source code for the model (source:(Demilie, 2020b)):
“import javax. swing. JEditorPane;
import javax.swing.JFrame;
import javax.swing.JTextPane;
import com.inet.jortho.FileUserDictionary;
import com.inet.jortho.SpellChecker;
import java.awt.Font;
public class SampleApplication extends JFrame{
public static void main(String[] args){
new SampleApplication().setVisible( true );
}
private SampleApplication(){
super(" Dictionary Based Spelling
Corrector/የስድስትቋንቋዎችንፊደልበአንድመተግበሪያማስተካከያስርዓት ");
JEditorPane text = new JTextPane();
Font font = new Font("", Font.BOLD, 44);
text.setText( " Dictionary Based Spelling Corrector "
+ "/የስድስትቋንቋዎችንፊደልበአንድመተግበሪያማስተካከያስርዓት " );
add( text );
text.setFont(font);
setSize(250, 180);
setDefaultCloseOperation( EXIT_ON_CLOSE );
setLocationRelativeTo( null );
SpellChecker.setUserDictionaryProvider(new FileUserDictionary() );
SpellChecker.registerDictionaries( null, null );
SpellChecker.register( text );
}
}”
The above fragment code will let us select the language that the users are interested to do so.
Accordingly, figure 1 shows the sample GUI for the "Amharic" language.
1872
International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
Figure 1: GUI for the Amharic Language
After this, if the user has selected “Amharic” language with Amharic texts
(„የመንግሥትተቋምመዘጋትበተገቢውሚዲያይፋመደረግአለበት፡፡‟).
1873
International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
Figure 2: List of words that are not in Amharic dictionary files
From figure 2, the words are underlined in a red zigzag line. It indicates that all are not in dictionary
file lists. So, the user should have to click on the underlined word (can use "F7" from the computer
keyboard) to display the list of alternatives. After this, the system user will get figure 3.
1874
International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
Figure 3: Sample GUI for words that are not in the dictionary
From figure 3, words that are not in the dictionary file list will be written in red color. Here, the user
can select any of the operations accordingly. For example, if the user adds all words to the dictionary (click
on "ወደመዝገበቃላቱይጨምሩ ") or if the words are already in the dictionary files list, it will not be
underlined with a red zigzag line and it looks like as figure 4.
1875Figure 4: Sample GUI for words that are free from any spelling error
The researcherhas tested the proposed system by creating commonly known errors of the
languages for users of it accordingly. Since the collected and used dictionary files of each language are
from different genres with the help of linguistic experts of each language, the system checks the errors
easily and suggests the best alternative from the given list of words that have been provided in the
dictionary. For example, if the user wants to replace the missing character from the word “ትምህርን” and
if the word is not in the dictionary file list, the following are a list of suggestions.
Figure 5: Sample GUI for word suggestionsInternational Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
Here, if the system user wants to edit the dictionary files, he/she can click on
“መዝገበቃላቱንያስተካክሉ” then he/she will get figure 6 and he/she can do the remaining operations
accordingly.
Figure 6: Sample GUI model to edit the dictionary
Here, if the user selects “ትምህርት” according to the meanings of the sentence
“በኮሮናበሽታምክንያትተቋርጦየነበረውትምህርንመቸእንደሚጀመርየታወቀነገረየለም”፡፡, the corrected sentence
looks like “በኮሮናበሽታምክንያትተቋርጦየነበረውትምህርትመቸእንደሚጀመርየታወቀነገርየለም”:: Accordingly,
as we know the wordsመቸ and “ነገረ” are not spelled correctly, but looks a word which has been spelled
properly.Such kind meaningless sentences may come due to incorrect addition of words to dictionary
(this is maybe due to system user‟s error).
1877International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
Figure 7: Sample GUI model with a list of suggestions for a single word
Finally, figure 8 indicates words that are free from any kind of spelling error except the
incorrectly added words መቸ and“ነገረ”.
1878International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
Figure 8: Sample GUI for correctly spelled words
If the system user selects "Afan Oromo" language with sample text, for example, “Mana kadhata
bira jiraatti.” which means “She lives near the church.” it looks like this:
Figure 9: Sample GUI for word suggestions from the Afan Oromo dictionary file
Figure 9 indicates that the word “mana” is in the dictionary file and the words next to “mana" are
not on the list. Here, the system user can see a list of the suggestions by pointing to the specific word
which has been underlined with a red zigzag line. For example, the word “jiraatti” has sample
suggestions like:
1879International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
Figure 10: Sample suggestion for the word "jiraatti"
Finally, figure 11 shows the sentence “mana kadhata bira jiraatti.” which has been spelled
correctly.
1880International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
Figure 11: Sample GUI for correctly spelled words
Here, system users can follow the same procedure to compute all spelling-related issues for all of
the languages that have been selected.
Conclusion
Spelling correctors are fairly reliant on the words in the lexicon dictionary. It is a tool that
needs to be developed for all kinds of system users and is one of the applications of natural language
processing that detect and corrects errors in different natural language applications. Some words may
have very few words spelled similarly, so even numerous faults will recover the accurate word. Other
words will have many likewise spelled words, so one error may make alteration problematic or
unbearable. The proposed model was based on a dictionary-based method. It is used in noticing and
modifying diverse classes of spelling errors. The main features of the planned model can be précised in
giving the proposals for noticed errors and providing the correction automatically using the first
suggestion. Furthermore, the planned model is calculated using dictionary-based data sets for all
languages that the researcher has been selected for the study.
The proposed system yields better performance than the work of (Demilie, 2020b) due to the
number of corpora that have been collected, the way of preprocessing mechanisms, the places that the
corpora have been collected, and the number of linguistic experts that have been participated.
Generally, the number of corpora that have been collected, the way of preprocessing mechanisms,
the places that the corpora have been collected and the number of linguistic experts that have been
participated will determine the performance of dictionary-based systems.
1881International Journal of Aquatic Science
ISSN: 2008-8019
Vol 12, Issue 02, 2021
References
[1] Atawy, S. M. El. (2018). Automatic Spelling Correction based on n-Gram Model. 182(11), 5–9.
[2] Demilie, W. B. (2019). Parts of Speech Tagger for Awngi Language. 9(9).
[3] Demilie, W. B. (2020a). Analysis of implemented part of speech tagger approaches The case of
Ethiopian languages. Indian Journal of Science and Technology, 13(48), 4661–4671.
https://doi.org/10.17485/ijst/v13i48.1876
[4] Demilie, W. B. (2020b). Multilingual spelling checker for selected Ethiopian languages.
International Journal of Advanced Science and Technology, 29(7), 2641–2648.
[5] Ganfure, G. O., & Midekso, D. (2014). Design And Implementation Of Morphology Based Spell
Checker. 3(12), 118–125.
[6] Gezmu, A. M., Nürnberger, A., & Seyoum, B. E. (2014). Portable Spelling Corrector for a Less-
Resourced Language : Amharic. 4127–4132.
[7] Hadiyya (Hadiyyisa) Language Orthography - Alphabet and Writing - Themes on the Hadiya
People of Ethiopia. (n.d.).
[8] Jeldu, M. D., & Mehta, R. (2018). Rule-based afan Oromo analyzer for spell checker 1 1,2. 7, 36–
39.
[9] Kambaata language - Wikipedia. (n.d.).
[10] Kumar, R., Bala, M., & Sourabh, K. (2018). A study of spell checking techniques for Indian
Languages. March, 105–113.
[11] Misikir, T. (2013). A thesis submitted to the school of graduate studies of Addis Ababa University
in partial fulfillment of the requirement for the degree of master of science in information science.
[12] Samuel, J., Teferra, S., Samuel, J., Teferra, S., Samuel, J., & Teferra, S. (2018). Designing A
Rule-Based Stemming Algorithm for Kambaata Language Text. 9, 41–54.
[13] Spelling, I. of. (n.d.). Importance of Spelling.
[14] Tamirat, W. T. A. D. (n.d.). Afan Oromo Sentence Structure.
[15] TEKLAY, G. (2010). Part of Speech Tagger for Tigrigna Language. 98.
[16] Tesfaye, D. (2011). A rule-based Afan Oromo Grammar Checker. 2(8), 126–130.
[17] University), P. dr. B. Y. (Addis A. (n.d.). A Typology of Verbal Derivation in Ethiopian Afro-
Asiatic Languages.
1882You can also read

















































