Detecting Repeatable Performance - (full with appendix) Campbell R. Harvey - Duke University
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

FINANCE 663: International Finance Detecting Repeatable Performance (full with appendix) Campbell R. Harvey Duke University and NBER February 2021
Mistakes 1. Invest in a manager that turns out to be a loser (Type I error or “false positive”) 2. Pass on a manager that turns out to be a winner (Type II error or “false negative”) 3. Retain a manager in your portfolio thinking he has experienced bad luck when really he is a loser. 4. Dump a manager from your portfolio thinking she is a loser when she is a winning manager that just had some bad luck. Campbell R. Harvey 2021 3

Drivers of Mistakes Forces causing mistakes: 1. Failure to account for luck + evolutionary propensity accept Type I errors and avoid costly Type II errors 2. Failure in specifying and conducting scientific tests 3. Failure to take rare effects into account Campbell R. Harvey 2021 4

Perspective Current performance metrics do a poor job of predicting future performance. • This could be a result of all managers lacking skill – or it could be the result of flawed performance metrics. • Goal is to develop a metric that is useful in predicting future manager performance. Campbell R. Harvey 2021 5
A Framework to Separate Luck from Skill Six research initiatives:* 1. Explicitly adjust for multiple tests (“Backtesting”) 2. Bootstrap (“Lucky Factors”) 3. Noise reduction (“Detecting Repeatable Performance”) 4. Dispersion (“Cross-sectional Alpha Dispersion”) 5. Controlling for rare effects (“Scientific Outlook in Financial Economics” AFA Presidential Address) 6. Calibrating error rates (“False (and Missed) Discoveries”) Campbell R. Harvey 2021 6 *Bibliography on last page. All my research at: https://papers.ssrn.com/sol3/cf_dev/AbsByAuth.cfm?per_id=16198
A Framework to Separate Luck from Skill Six research initiatives:* 1. Explicitly adjust for multiple tests (“Backtesting”) 2. Bootstrap (“Lucky Factors”) 3. Noise reduction (“Detecting Repeatable Performance”) 4. Dispersion (“Cross-sectional Alpha Dispersion”) 5. Controlling for rare effects (“Scientific Outlook in Financial Economics” AFA Presidential Address) 6. Calibrating error rates (“False (and Missed) Discoveries”) Campbell R. Harvey 2021 7 *Bibliography on last page. All my research at: https://papers.ssrn.com/sol3/cf_dev/AbsByAuth.cfm?per_id=16198

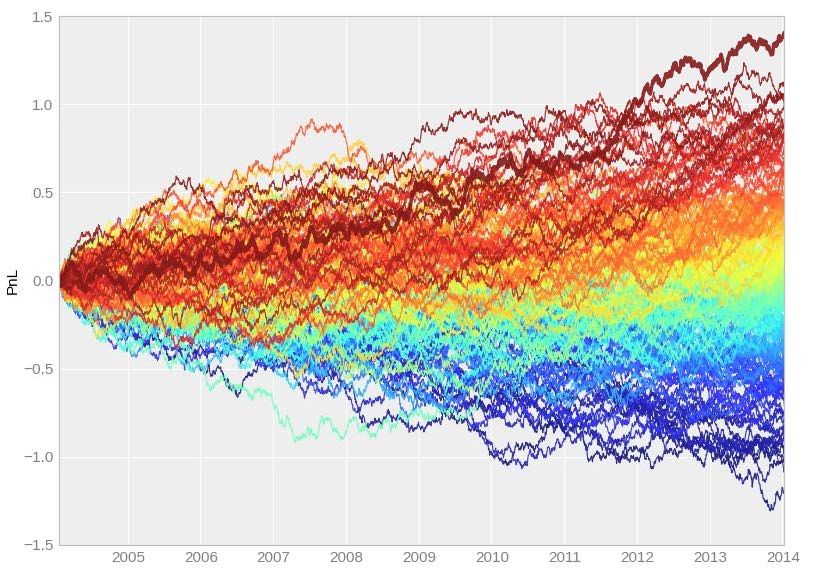
1. Multiple Testing Performance of trading strategy is very impressive. • SR=1 • Consistent • Drawdowns acceptable Source: AHL Research Campbell R. Harvey 2021 8
1. Multiple Testing Sharpe = 1 Sharpe = 2/3 Sharpe = 1/3 200 random time-series mean=0; volatility=15% Source: AHL Research Campbell R. Harvey 2021 10
Lots of factors 5 factors Campbell R. Harvey 2021 11
Lots of factors 15 factors Campbell R. Harvey 2021 12
Lots of factors 82 factors Campbell R. Harvey 2021 13 Source: The Barra US Equity Model (USE4), MSCI (2014)
Lots of factors 400 factors Source: https://www.capitaliq.com/home/who-we-help/investment-management/quantitative-investors.aspx Campbell R. Harvey 2021 14
Lots of factors 450 factors Source: https://www.capitaliq.com/home/who-we-help/investment-management/quantitative-investors.aspx Campbell R. Harvey 2021 15
Lots of factors 500+ factors Source: https://www.spglobal.com/marketintelligence/en/solutions/alpha-factor-library Campbell R. Harvey 2021 16
Lots of factors 18,000 factors! Yan and Zheng (2017) Campbell R. Harvey 2021 17
Lots of factors 2.1 million! Campbell R. Harvey 2021 18
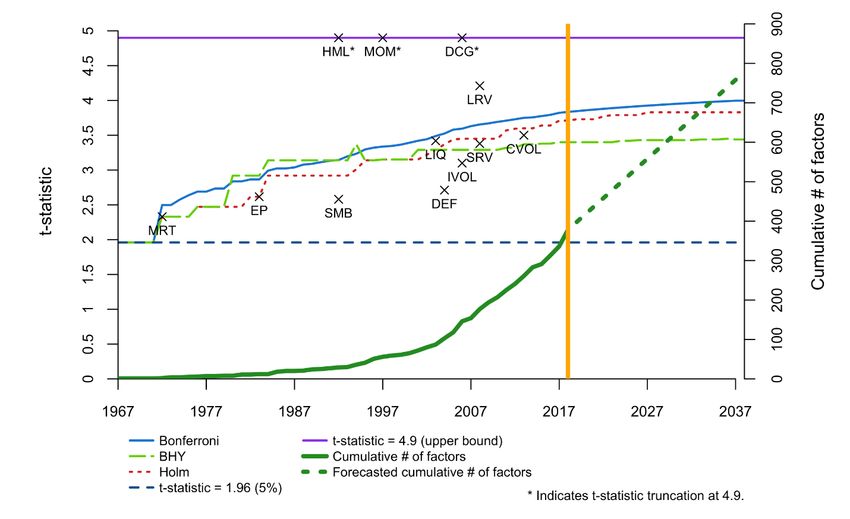
1. Multiple Testing • Allows for correlation among strategy returns • Allows for missing tests • Review of Financial Studies, 2016 Campbell R. Harvey 2021 20
1. Multiple Tests Campbell R. Harvey 2021 21
1. Multiple Tests Results: Percentage Haircut is Non-Linear Journal of Portfolio Management Campbell R. Harvey 2021 22
2. Bootstrapping Multiple testing approach has drawbacks • Need to know the number of tests • Need to know the correlation among the tests • With similar sample sizes, this approach does not impact the ordering of performance *Note Tstat = SR√T Campbell R. Harvey 2021 23
2. Bootstrapping • Technique builds on pioneering paper by Foster, Smith and Whaley (1997) • Addresses data mining directly • Allows for cross-correlation of the fund strategies because we are bootstrapping rows of data • Allows for non-normality in the data (no distributional assumptions imposed – we are resampling the original data) • Potentially allows for time-dependence in the data by changing to a block bootstrap. • Answers the questions: • How many funds out-perform? • Which ones were just lucky? Campbell R. Harvey 2021 24
2. Bootstrapping • Take the actual fund manager returns • Strip out all skill (make each fund’s alpha exactly equal to zero) • Bootstrap alternative histories to see what you can get by pure chance sampling from a null distribution of no skill • Fund managers need to beat what could be possible purely by luck Campbell R. Harvey 2021 25
Insert animation here Campbell R. Harvey 2021 26
3. Noise reduction Observed performance consists of four components: • Alpha • True factor premia • Unmeasured risk (e.g., low vol strategy having negative convexity) • Noise (good or bad luck) Campbell R. Harvey 2021 27
3. Noise reduction Current approaches do a poor job of stripping out the noise component • As a result, past performance metrics fail to predict future realized performance • Notice that the above is a cross-sectional statement: Do low or high past metrics predict low or high future performance? Campbell R. Harvey 2021 28
3. Noise reduction R2=0% T-statistic=0 Past performance does not predict future performance Campbell R. Harvey 2021 29 Source: Adam Duncan, Cambridge Associates.
3. Noise reduction By and large, current methods largely focus on fund by fund evaluation, e.g., 100% time series analysis • For example, equation by equation OLS is estimated to get an “alpha” and time-series R2 is maximized (the objective of OLS). • This R2 has nothing to do with the most important issue: the prediction of future performance. • Indeed, we argue that the focus on time-series R2 has led to overfitting: Cross-sectional predictability is destroyed because the overfit performance metrics contain too much noise. Campbell R. Harvey 2021 30
3. Noise reduction We offer a new approach: Noise-reduced alpha (NRA) • We weight both the cross-section of alphas as well as the usual time series in developing a new fund-by-fund performance metric. • Following the literature on “regularization” which is popular in the machine learning applications, we impose a parametric distribution on the cross-section of alphas. • This will result in lower time-series R2 • This should also lead to higher cross-sectional R2s – and that’s exactly what we find. Campbell R. Harvey 2021 31
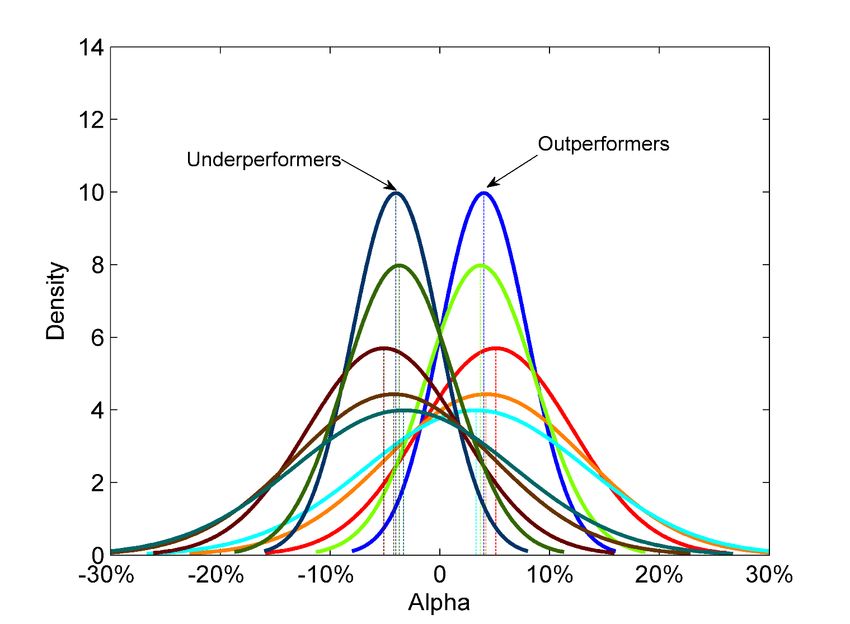
Our intuition: Example 1 • t-stat = 3.9%/4.0% = 0.98 < 2.0 • alpha = 0 cannot be ruled out Campbell R. Harvey 2021 32
Our intuition: Example 1 • Both t-stats < 2.0 • alpha = 0 cannot be rejected for either Campbell R. Harvey 2021 33
Our intuition: Example 1 • t-stat < 2.0 for all funds • alpha = 0 cannot be excluded for all • However, population mean seems to cluster around 4.0%. Should we declare all alphas as zero? Estimated alphas cluster around 4.0% Campbell R. Harvey 2021 34
Our intuition: Example 1 • Although no individual fund has a statistically significant alpha, the population mean seems to be well estimated at 4.0%. • This might suggest grouping all funds into an index and estimating the alpha for the index. However, the index regression does not always work, as the next example shows. Campbell R. Harvey 2021 35
Our intuition: Example 2 • Again, no fund generates a significant alpha individually • An index fund that groups all funds together would indicate an approximately zero alpha for the index • Fund alphas cluster into two groups. The two group classification seems more informative than declaring all alphas zero Campbell R. Harvey 2021 36
What we do We assume that fund alphas are drawn from an underlying distribution (regularization) • In Example 1, the distribution is a point mass at 4.0%; in Example 2, the distribution is a discrete distribution that has a mass of 0.5 at -4.0% and 0.5 at 4.0% • We search for the best fitting distribution that describes the cross- section of fund alphas using a generalized mixture distribution Campbell R. Harvey 2021 37
What we do We refine the alpha estimate of each individual fund by drawing information from this underlying distribution • In Example 1, knowing that most alphas cluster around 4.0% would pull our estimate of an individual fund’s alpha towards 4.0% and away from zero. • In Example 2, knowing that alphas cluster at -4.0% and 4.0% with equal probabilities would pull our estimate of a negative alpha towards -4.0% and a positive alpha towards 4.0%, and both away from zero. Campbell R. Harvey 2021 38
Our framework Key idea: • We assume that true alphas follow a parametric distribution. We back out this distribution from the observed returns and use it to aid the inference of each individual fund. Main difficulty: • We do not observe the true alphas. We only observe returns, which provide noisy information on true alphas. Our approach: • We treat true alphas as missing observations and adapt the Expectation- Maximization (EM) algorithm to uncover the true alphas. Campbell R. Harvey 2021 39
Intuition Initial step: • Estimate firm by firm parameters: alphas, risk loadings and residual standard deviations. • Form and initial estimates of the cross-sectional distribution of the alphas using a Generalized Mixture Distribution (mixture of normal). For a two component GMD, there are five parameters: two means, two variances and a mixing parameter. Campbell R. Harvey 2021 40
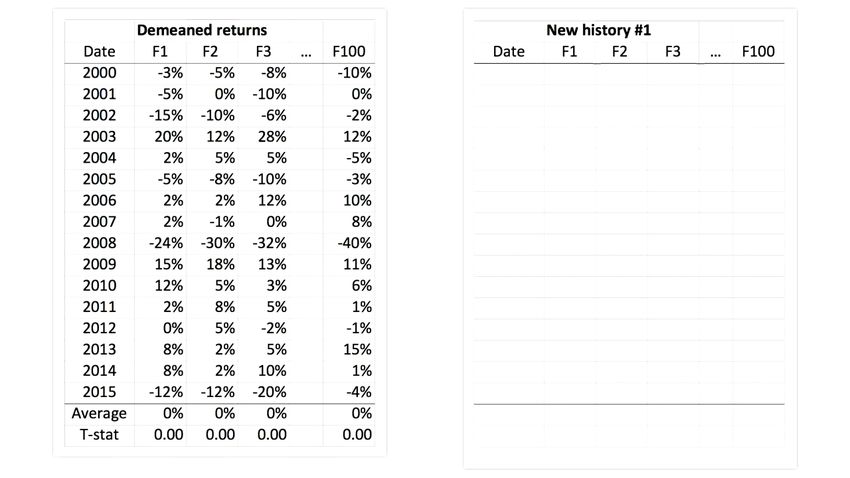
Intuition Expectation step: 1, = 1 + 1 + 1, , = 1, … , . 2, = 2 + 2 + 2, , …… , = + + , . • Starting with OLS betas, residual standard deviations, and an assumed cross- sectional distribution of alpha, we try to fill in the missing values for alphas. Campbell R. Harvey 2021 41
Intuition Expectation step: The alphas: • Combination of OLS alphas and an alpha drawn from the initial GMD. • The weight put on the time-series and cross-section depends on the precision of the OLS estimates (more precise time-series estimate will get larger weight). There is a trade-off: • Time-series: Deviations from OLS alphas will result in a penalty from OLS regressions • Cross-section: Failing to fit the assumed cross-sectional distribution will also incur a penalty • Find the best alphas that balance the tradeoff Campbell R. Harvey 2021 42
Intuition Maximization step: • After we fill in the missing alphas (assuming alphas are known), we update model parameters, which include risk loadings, residual standard deviations, the cross-sectional distribution of alphas. Campbell R. Harvey 2021 43
Intuition Maximization step: 1, = 1 + 1 + 1, , = 1, … , . 2, = 2 + 2 + 2, , …… , = + + , . • Using the previously found alpha values, run equation-by-equation OLS to reestimate betas and residual standard deviations (i.e., constraining the intercepts to be the previous alpha values that adhere to the parametric cross- sectional distribution of alphas). Campbell R. Harvey 2021 44
Intuition Iterations: • With these new parameters, we recalculate the GMD and repeat the process • We iterate between the Expectation Step and the Maximization Step until the changes in parameters that govern the cross-sectional distribution of alphas are very small Campbell R. Harvey 2021 45
Intuition Features of our solution: • Alpha estimate combines information from both time-series and cross-section • This is reflected in the Expectation Step: Optimal alpha estimates strike a balance between fitting the time-series and the cross-section • OLS alphas with large standard errors are adjusted by using information from the cross-section • The cross-sectional alpha distribution is also refined in each iteration by using better alpha estimates. This is the feedback effect. • NRA: noise reduced alpha Campbell R. Harvey 2021 46
Link to Machine Learning Regularization: • Introduce additional constraints to achieve model simplification that helps prevent model overfitting. • Following the literature on “regularization” which is popular in the machine learning applications, we impose a parametric distribution on the cross-section of alphas. Campbell R. Harvey 2021 47
EM link to Bayesian methods Bayesian methods: • Pastor and Stambaugh (2002), Kosowski, Naik and Teo (2007), Baks, Metrick, and Wachter (2001), Jones and Shanken (2005), Busse and Irvine (2006) • We agree with the insights of Bayesian methods. Both Bayesian methods and our approach imply shrinkage or noise reduction. • However, our approach has some advantages: • The prior specification, subjective in nature, may have a dramatic impact on the posterior inference (Busse and Irvine, 2006). We do not need to specify the prior. • In our framework, prior = posterior = “equilibrium” alpha distribution. • Standard conjugate priors (e.g., a normal distribution) may be inadequate to capture salient feature of the alpha population (e.g., one skilled group + one unskilled group, or higher moments). Campbell R. Harvey 2021 48
What we find Campbell R. Harvey 2021 49
What we find: Individual funds • An exemplar outperforming fund Campbell R. Harvey 2021 50
What we find: Individual funds Campbell R. Harvey 2021 51
What we find: Out-of-sample forecasts • In-sample: 1984-2001; Out-of-sample: 2002-2011 In-sample, NRA forecast OLS forecast # of funds error (%) error (%) (-∞, -2.0) 3.29 6.61 64 [-2.0, -1.5) 3.09 3.70 75 [-1.5, 0) 2.75 2.92 565 [0, 1.5) 2.61 5.54 610 [1.5, 2.0) 2.38 10.47 87 [2.0, +∞) 2.77 12.02 87 Overall 2.71 5.17 1,488 Campbell R. Harvey 2021 52 *Mean absolute forecast errors.
Independent validation R2=0% T-statistic=0 Raw past performance does not predict future performance Campbell R. Harvey 2021 53 Source: Adam Duncan, Cambridge Associates.
Independent validation • Simple noise reduction is dividing alphas by residual volatility R2=7% Past NR performance does T-statistic>17 predict future (unadjusted) performance Campbell R. Harvey 2021 54 Source: Adam Duncan, Cambridge Associates.
Application to hedge funds • More learning/shrinkage in the cross-section • Factor loadings may vary dramatically across funds. Implies a higher level of uncertainty for the alpha estimate at the individual fund level and therefore a greater learning/shrinkage effect in the cross-section. • Need a more complicated GMD (i.e., mixture distribution) to capture the cross-section of hedge fund managers • In mutual funds, there are no superstar managers suggested by our model. In hedge funds, there are some. Campbell R. Harvey 2021 55
4. Rare effects: Presidential address Approach Develop a simple mathematical framework to inject prior beliefs (Minimum Bayes Factor) Here is an example of a top five factor in the 2-million factor paper! (CSHO-CSHPRI)/MRC4 Campbell R. Harvey 2021 56
4. Rare effects: Presidential address Example In words: (Common Shares Outstanding – Common Shares Used to Calculate EPS) Campbell R. Harvey 2021 57
4. Rare effects: Presidential address Example In words: (Common Shares Outstanding – Common Shares Used to Calculate EPS) Rental Commitments – 4th year • New technique adjusts Sharpe ratios by injecting how much confidence you have in the plausibility of the effect. Campbell R. Harvey 2021 58
5. Cross-sectional alpha dispersion Suppose two groups of funds: skilled and unskilled If there was very little dispersion in performance, it should be easy to detect who is skilled and unskilled If funds take on a lot of idiosyncratic risk, the dispersion will increase making it easy for a bad fund to masquerade as a good fund Our evidence shows that investors have figured it out – hurdle for declaring a fund “skilled” increases when lots of dispersion Campbell R. Harvey 2021 59
6. False (and missed) discoveries New approach Explicitly calibrate the Type I (hiring a bad manager) and Type II (missing a good manager) rates Establishes a cutoff for Type I error Able to incorporate the size of the error not just a binary classification Enables a decision rules like “To avoid a bad manager, I am willing to miss five good managers” Campbell R. Harvey 2021 60
6. False (and missed) discoveries Method: Sort the N strategies by t-statistics p0 x N are deemed “skilled” (1-p0) x N “unskilled” Create a new data matrix where we use the p0 x N actual excess returns concatenated with (1-p0) x N returns that are adjusted to have zero excess performance Y=[X0,1 | X0,0] Campbell R. Harvey 2021 61
p0 1 -p0 Skilled X0,1 Unskilled X0,0 Y=[X0,1 | X0,0] Actual Set all assumed unskilled to zero alpha excess returns Campbell R. Harvey 2021 62
6. False (and missed) discoveries Method: Bootstrap 1 Bootstrap Y=[X0,1 | X0,0] and create a “new history” by randomly sampling (with replacement) rows. By chance, some of the unskilled will show up as “skilled” and some of the skilled as “unskilled” At a various level of t-statistics, we can count the Type I and Type II errors. Repeat for 10,000 bootstrap iterations Campbell R. Harvey 2021 63
Bootstrap iteration #1 By chance, some of the skilled will have bad luck By chance, some of the unskilled will have good luck Campbell R. Harvey 2021 64
6. False (and missed) discoveries Method: Bootstrap 1 Averaging over the iterations, we can determine the Type I error rate at different levels of t-statistic thresholds It is straightforward to find the level of t-statistic that delivers a 5% error rate Type II error rates are easily calculated too Campbell R. Harvey 2021 65
6. False (and missed) discoveries Method: Bootstrap 2 This method is flawed. Our original assumption is that we know the p0 skilled funds and we assign their sample performance as the “truth” – that is, some of the funds we declare “skilled” are not. We take a step back. Campbell R. Harvey 2021 66
6. False (and missed) discoveries Method: Bootstrap 2 With our original data matrix X0, we perturb it by doing an initial bootstrap, i. With perturbed data, we follow the previous steps and bootstrap Yi=[X0,1 | X0,0] This initial bootstrap is essential to control for sampling uncertainty; we repeat it 1,000 times This is what we refer to as “double bootstrap” Campbell R. Harvey 2021 67
6. False (and missed) discoveries Method: Bootstrap 2 Bootstrap allows for data dependence Allows us to make data specific cutoffs Allows us to evaluate the performance of different multiple testing adjustments, e.g., Bonferroni Campbell R. Harvey 2021 68
6. False (and missed) discoveries Application 1: S&P CapIQ factor data At p0=0.02, Type I error is 50% if t=2 used as cutoff 5% Type I error rate achieved at t=3.0 69 Campbell R. Harvey 2021
6. False (and missed) discoveries Application 1: S&P CapIQ factor data Odds = False/Miss At p0=0.20, Type I error is 12% if t=2 used as cutoff 5% Type I error rate Type II achieved at t=2.4 At t=2.4, there is one false signal for every eight misses 70 Campbell R. Harvey 2021
6. False (and missed) discoveries Takeaways We provide a general way to calibrate Type I and Type II errors Double bootstrap preserves the correlation structure in the data Ability to evaluate multiple testing correction methods We also propose an odds ratio (false/missed discoveries) that allows us to incorporate asymmetric costs of these errors into financial decision making Our method also allows us to capture the magnitude of the error (a 3% error is much less important than a 30% error) 71 Campbell R. Harvey 2021
Joint work with References Yan Liu Based on our joint work (except Scientific Outlook): Texas A&M University (1) “… and the Cross-section of Expected Returns” http://ssrn.com/abstract=2249314 • (1b) “Backtesting” http://ssrn.com/abstract=2345489 • (1c) “Evaluating Trading Strategies” http://ssrn.com/abstract=2474755 (2) “Lucky Factors” http://ssrn.com/abstract=2528780 (3) “Detecting Repeatable Performance” http://ssrn.com/abstract=2691658 (4)* “The Scientific Outlook in Financial Economics”, https://ssrn.com/abstract=2893930 (5) “Cross-Sectional Alpha Dispersion and Performance Evaluation”, https://ssrn.com/abstract=3143806 (6) “False (and Missed) Discoveries in Financial Economics”, https://ssrn.com/abstract=3073799 (7) “A Census of the Factor Zoo”, https://ssrn.com/abstract=3341728 (8) “Luck versus Skill in the Cross-Section of Mutual Fund Returns: Reexamining the Evidence”, https://ssrn.com/abstract=3623537 (9) “Panel Instrumented Asset Pricing Tests” *Harvey sole author Campbell R. Harvey 2021 73
Contact – Follow me on Linkedin! cam.harvey@duke.edu @camharvey http://linkedin.com/in/camharvey SSRN: http://ssrn.com/author=16198 PGP: E004 4F24 1FBC 6A4A CF31 D520 0F43 AE4D D2B8 4EF4 Campbell R. Harvey 2021 74
Buffett’s Monkeys Shareholders letter, March 2017: Campbell R. Harvey 2021 93
Buffett’s Monkeys How many monkeys do you need to match Buffett’s record: mean(arithmetic) 20.61% vol 33.91% hit rate 35/52 Time period 1965-2016 4,366 Campbell R. Harvey 2021 94
Appendix: Details of NRA Method • Estimate fund-by-fund OLS alphas, betas, and standard errors. • Call these alpha0, beta0, sigma0 (denote square of sigma as var0). • Assume a two component population GMD and fit the GMD0 based on the OLS alphas, i.e. each fund’s alpha0. • This implies one set of five parameters, MU01, MU02, SIGMA01, SIGMA02, P0 (mixing parameter). The first subscript denotes the iteration step. • Also perturb these parameters to have 35 population GMDs for starting values (we want to minimize the chance we hit a local optima). • Note POPULATION PARAMETERS are denoted in UPPER CASE and fund- specific parameters in lower case. Campbell R. Harvey 2021 95
Appendix: Details of NRA Method • Given fund-specific alpha0, beta0 and var0, and the population GMD0 also fit fund-specific GMDs denoted as gmd0 (again, lower case for fund specific). • If the GMD is one component (i.e., a normal distribution), then the alpha for fund 1 also follows a one-component GMD (i.e., a normal distribution). • The mean of gmd0 would be: VAR0 var0 / alpha0 × + GMD MU0 × var0 / + 0 var0 / + 0 • Note that VAR0 is the variance of the population GMD (i.e. cross-sectional variance). Hence, if the alpha0 is precisely estimated (high R2 and low var0/T), there is a greater weight placed on the alpha0. • This will be alpha1 for a candidate fund under a single component GMD. Campbell R. Harvey 2021 96
Appendix: Details of NRA Method • If the GMD is two components, there are five parameters and, again, they will be a weighted average of the fund-specific alpha0 parameters and the GMD0. • The parameters governing this fund specific gmd will be conditional on the fund’s betas, standard error, and the GMD that govern the alpha population. VAR01 var0 / mu01 = alpha0 × + MU01 × var0 / + 01 var0 / + 01 1 1 var01 = 1/ + var0 / VAR 01 VAR02 var0 / mu02 = alpha0 × + MU02 × var0 / + 02 var0 / + 02 1 1 var02 = 1/ + var0 / VAR 02 Campbell R. Harvey 2021 97
Appendix: NRA Intuition Details of method: • There is also a fifth parameter of the gmd, p0 (the drawing probability from the gmd component). • Its formula is a function of the GMD’s P0 and is provided on p. 49 of our paper. • The basic intuition is that we increase the drawing probability to the component that implies a mean that is closer to the mean of the population GMD. For example, we will make p0 larger if alpha0 is closer to MU01 than MU02. Campbell R. Harvey 2021 98
Appendix: NRA Intuition Details of method: • For each fund's gmd, we calculate its mean. We estimate new regressions where we constrain the intercepts to be the calculated means. This will produce different estimates of the fund betas (beta1) and the standard errors (sigma1). Campbell R. Harvey 2021 99
Appendix: NRA Intuition Details of method: • We fit a new GMD based on the cross-section of gmd's. For each fund, we randomly draw n = 10,000 alphas from its gmd. Suppose we have n funds in the cross-section. We will have mn draws from the entire panel. We find the MLE of the GMD that best describes these mn alphas. • Recalculate fund-specific gmds (gmd1) and draw alpha2 • Continue to iterate until there is negligible change in the parameters of the GMD. • Repeat the entire process 35 times with different initial GMD0s to ensure global convergence. Campbell R. Harvey 2021 100
You can also read

















































