C3S Sectoral Applications of Decadal Predictions - Technical Appendix
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
C3S Sectoral Applications of Decadal Predictions – Technical Appendix 1
Contents 1. Introduction 3 2. Technical appendix for insurance case study (MetOffice) 3 2.1 User needs 3 2.2 Model and observation data 3 2.3 Post-processing and evaluation methods 3 2.4 Analysis protocol for product sheet 4 3. Technical appendix for the energy case study (CMCC) 5 3.1 User needs 5 3.2 Model and observation data 5 3.3 Post-processing and evaluation methods 5 3.4 Analysis protocol for product sheet 5 4. Technical appendix for the agriculture case study (BSC) 6 4.1 User needs 6 4.2 Model and observation data 6 4.3 Post-processing and evaluation methods 7 4.4 Analysis protocol for product sheet 7 4.5 Additional information 8 5. Technical appendix for infrastructure case study (DWD) 9 5.1 User needs 9 5.2 Model and observation data 9 5.3 Post-processing and evaluation methods 9 5.4 Analysis protocol for product sheet 9 5.5 Additional information 11 6. Model and observation data 12 6.1 Multi-model prediction ensemble 12 6.2 Observation and reanalysis data 14 7. Post-processing and evaluation methods 15 7.1 Empirical models 15 7.2 Bias correction and calibration 17 7.3 Indices 17 7.4 Evaluation of forecast quality 18 8. Reference list 20 2
1. Introduction This technical appendix is intended to accompany the four decadal climate service prototypes available on the C3S website: https://climate.copernicus.eu/sectoral-applications-decadal-predictions It provides detailed technical information on how the decadal climate prototypes have been made, the datasets used and methods. Note that this technical appendix applies to the latest version of the product sheets, using the decadal forecasts initialized in November 2020. However, most of the content of this document is also valid for the forecasts initialized in November 2019 considering some changes in the multi-model settings and some small modifications in methodology. This document provides the following information: Technical information particular to each of these four prototypes in turn (Section 2 – Insurance, Section 3 – Energy, Section 4 – Agriculture, Section 5 – Infrastructure) Model and observation data (Section 6) Post-processing and evaluation methods (Section 7) 2. Technical appendix for insurance case study (MetOffice) 2.1 User needs (Re)insurers and risk analysts need to quantify near-term risk from hurricanes to inform underwriting decisions. Skilful dynamical forecasts of North Atlantic hurricane activity and resulting US hurricane damage could improve (re)insurers’ decision making processes for US markets. Working with Willis Research Network we have developed probabilistic forecasts of 5-year mean North Atlantic hurricane activity (measured by the accumulated cyclone energy (ACE) index, see section 7.3.3) and resulting 5-year total US damages are provided. 2.2 Model and observation data The dynamical decadal prediction systems used for the forecast are CMCC-CM2-SR5 (6 members), EC-Earth3 (10 members) and DePreSys4 (10 members) (see section 6.1). As observational datasets, for hurricane activity we use seasonal accumulated cyclone energy (ACE; section 7.3.3) from the Atlantic HURDAT2 database (section 6.2.6), and total US damages (section 6.2.7). 2.3 Post-processing and evaluation methods From each ensemble member, June to November near-surface air temperature anomalies for forecast years 1 to 5 are extracted and the respective 5-year means are calculated. The predicted (5-year mean) temperature difference ‘MDR-TROP’ index (section 7.3.4), is calculated on each ensemble member. The ensemble mean MDR-TROP index is calculated from the mean of individual ensemble MDR-TROP anomalies (relative to the whole hindcast period), with each ensemble member having equal weighting. The predicted 5-year mean MDR-TROP index skilfully predicts the observed MDR-TROP index (correlation coefficient: r=0.75). The forecast 5-year mean hurricane activity and 5-year total US damage probability 3
distributions are estimated from the forecast ensemble mean MDR-TROP index (section 7.3.4) using an empirical relationship between the observed hurricane activity/damage and past MDR-TROP forecasts. Ordinary least squares regression is used for the hurricane activity forecast (section 7.1.2.2), whereas the damage estimate needs to take into account the non-linear relationship between damage and forecast MDR-TROP (section 7.1.2.3). These empirical methods implicitly correct for model biases. Deterministic skill is quantified by the rank correlation coefficient, ρ (section 7.4.1.2), between the model central estimate of ACE/damage and the observed values. The rank correlation coefficient is used rather than the Pearson correlation coefficient (section 7.4.1.1) because of the non-Gaussian statistical distribution of US damages about the forecast. For ACE, the central estimate of the forecast is calculated from the linear regression fit. For damage, the central estimate of the forecast is the median of the forecast conditional loss probability distribution. For probabilistic prediction, the Brier skill score (BSS) is used to quantify the skill of the forecast in predicting above or below average ACE/damage (section 7.4.2.1). For ACE, the average value is the mean observed ACE over the entire observed period. For the US damage, due to the skewed distribution, the median observed damage is used. The reference forecast used in the BSS is 5-year persistence, where the forecast probability of above average ACE/damage is equal to 1 if the previous 5 years had above average ACE/damage. Contingency tables for forecasting above or below average ACE/US damage are also presented, to demonstrate forecast reliability, and the corresponding hit rate and false alarm rates are shown (see section 7.4.2.4) The correlations and Brier Skill Scores are tested for statistical significance using the non- parametric block bootstrapping approach as described in Smith et al. (2020), using a block length of 5 years to take into account auto-correlation of the data. All values were found to be statistically significant, at the 95% confidence level, against the null hypothesis of no correlation. 2.4 Analysis protocol for product sheet ● Extraction of June—November near surface temperature for forecast years 1 to 5 from all models and calculation of the 5-year mean. ● Calculation of forecast 5-year mean MDR-TROP index from the multi-model mean of MDR-TROP anomalies. ● Estimation of empirical relationships between observed ACE/US damage and forecast MDR-TROP index from past data. ● Calculation of skill scores based on past forecasts. ● Calculation of forecast 5-year mean MDR-TROP from decadal prediction systems and resulting forecast ACE and US damage probability distributions. ● Generation of figures and contingency tables for product sheet. 4
3. Technical appendix for the energy case study (CMCC) 3.1 User needs ENEL-GP is an international company providing electrical power from renewable sources such as solar, wind and hydropower. It is involved in this case study as a stakeholder in the hydropower energy sector. ENEL-GP is interested in predictive information associated with the precipitation in three drainage basins in Europe: Ebro and Guadalquivir in Spain, and Po in northern Italy. 3.2 Model and observation data In this study we use three decadal prediction systems (29 members in total): 9 members from CMCC-CM2 (section 6.1.1); 10 members from EC-Earth3 (section 6.1.2) and 10 members from DePreSys4 (section 6.1.3). As reference datasets we use the E-OBS (section 6.2.4) for precipitation and the HadSLP2r (section 6.2.5) for mean sea level pressure (mslp). 3.3 Post-processing and evaluation methods We focus on extended cold season (Nov–March, NDJFM) precipitation predictions of 1–10 forecast years temporal aggregation. We compute the model anomalies using a fixed 30- year reference period (1981–2010, following WMO recommendations) for each lead year, using different initialization years (for each lead year) so as to target the above-mentioned period. We produce the multi-model ensemble by computing the single-model ensemble mean anomalies and then take their average across the different models. This way each model (decadal predictive system) receives the same weight. We compute the NAO (see section 7.3.1) and adjust its variance (see section 7.2.2) in order to match the predictable component of the observed NAO. The forecasted precipitation is computed using a linear regression model based on the observed relationship between the NAO and precipitation in each basin (see section 7.1.2.1). The precipitation anomalies are presented as percent deviations from the 1981–2010 climatology. Concerning the verification of the ensemble mean prediction, we use the Pearson correlation coefficient (see section 7.4.1.1) due to Gaussian distribution. We test the statistical significance of the correlation at 95% level against the null hypothesis of not- positive correlation using a one-sided t-test. Since in decadal timeseries there is, typically, non-negligible auto-correlation violating the hypothesis of independence in the data, we compute the effective degrees of freedom accounting for auto-correlation in the time series (following Bretherton et al.,1999). This approach has been used extensively in the literature. For the probabilistic prediction, the Brier Skill Score (BSS, see section 7.4.2.1) is employed for three different categories: below lower-tercile, above upper-tercile, between the lower and upper tercile. The reference forecast is defined as the climatology of the period 1981- 2010. 3.4 Analysis protocol for product sheet ● Remapping of the observed and model mean-sea-level pressure fields to 1x1 degree regular grid (using bilinear interpolation). ● Remapping of the observed and model precipitation (using a conservative interpolation method) to a 0.5x0.5 degree regular grid 5
● Calculation of the monthly averages of the observed precipitation. ● Computation of mean-sea-level pressure anomalies for each ensemble member and the multi-model ensemble mean. ● Computation of the observed anomalies of precipitation and mean-sea-level pressure. ● Computation of the extended cold season (Nov–March) NAO index for forecast years 1–10, both for observations and model. Regarding the model computation, first we find the multi-model ensemble mean mean-sea-level pressure anomalies and then we calculate the NAO index. For the probabilistic forecasts, the NAO index is computed for each ensemble member separately. ● Variance adjustment of both the multi-model ensemble mean NAO timeseries and the respective timeseries of each individual member. ● Calculation of the spatially aggregated observed precipitation of the NDJFM seasonal mean for each basin. Calculate the mean for forecast years 1–10. ● Linear model: Regress the observed precipitation anomalies on the observed NAO. Use this linear model and the multi-model ensemble mean NAO to predict the precipitation anomalies in each basin (see section 7.1.2.1) ● Calculation of skill scores: The prediction skill of precipitation (derived by the linear model) and NAO is evaluated through the correlation coefficient (see section 7.4.1.1) in respect to the observations (deterministic skill score), as well as through the Brier Skill Score (section 7.4.2.1) compared to climatology (probabilistic skill score) ● Visualisation of the results for inclusion in the product sheet. 4. Technical appendix for the agriculture case study (BSC) 4.1 User needs The presented prototype for the agriculture sector is developed in close collaboration with the Joint Research Centre (JRC) of the European Commission. JRC provides independent scientific and technical advice and supports the European Commission's agriculture and food security policies through its monitoring and economic analysis of agricultural resources and farm systems. In recent years, they are actively involved in exploring the added value of decadal climate information for building a reliable climate service for agricultural needs on a multi-annual to decadal timescale. In this context, JRC is interested in knowing the skill of predictive information on decadal variations in the risk of drought conditions over the global wheat harvest areas. 4.2 Model and observation data In this study we use four decadal prediction systems (42 members in total): 6 members from CMCC-CM2 (section 6.1.1); 10 members from EC-Earth3 (section 6.1.2); 10 members from DePreSys4 (section 6.1.3) and 16 members from MPI-ESM1-2-LR (section 6.1.4). The considered models were run by explicitly prescribing the contemporaneous state of the climate system at the start of the simulation (November 1 of each year from 1960 to 2020), 6
while also accounting for changes in radiative forcings (both natural and anthropogenic). For forecast quality assessment of agro-climatic indices, we use ERA5 (Bell et al., 2020; Hersbach et al., 2020, see section 6.2.3) as a reference dataset. This dataset is selected due to its temporal and geographical coverage and spatial resolution and has been used to obtain the monthly temperature and precipitation globally for Standardized Precipitation Evaporation Index (SPEI, see section 7.3.2.2) estimation. The information of the local wheat harvesting month is retrieved from the MIRCA2000 dataset (Portman et al., 2010). In order to compare the datasets, the values of the climate variables and the wheat harvesting month are interpolated using the first-order conservative remapping approach, from their original grid to a grid with nominal 1 degree spatial resolution. 4.3 Post-processing and evaluation methods We have assessed the skill of the climate model at forecasting drought conditions over the wheat harvesting region for the forecast years 1 to 5. The drought conditions are estimated using the Standardized Precipitation Evapotranspiration Index aggregated over six months (SPEI6, see section 7.3.2.2) index. The computed index is bias-adjusted using the calibration approach presented in Doblas-Reyes et al. (2005, see section 7.2.3). After the calibration, we construct a large multi-model ensemble by pooling all the members of each individual forecast system together. We use the ranked probability skill score (RPSS, see section 7.4.2.2) and relative operating characteristic (ROC, see section 7.4.2.3) skill score as a measure of predictive skill, to assess the forecast quality of predicted probabilities of tercile categories by decadal forecasts. The climatological forecast is considered as a baseline while estimating the RPSS. 4.4 Analysis protocol for product sheet Preparation of model and observational data: Interpolated the essential climate variables from their original grid to a grid with nominal 1 degree spatial resolution for all the considered forecast systems and the reference dataset. Estimation of monthly climate water balance: Computed the potential evapotranspiration (PET) and monthly climatic water balance (defined as the difference between monthly precipitation and PET). In our case, PET is estimated using the classical temperature-based Thornthwaite method (Thornthwaite 1948), owing to its simplicity and limited data requirements. Six-month accumulation of the estimated climate water balance: For each grid, the wheat harvesting month information is gathered and the monthly climate water balance values are summed over six months prior to the wheat harvesting month (inclusive) for individual years. For example, the accumulated value for the region with wheat harvest in June is obtained as the sum of January to June climate water balance values for a specific year. Multi-annual averaging of the accumulated values: The accumulated values are then averaged over five years for each harvest month. For example, the multi-annual average of accumulated climate water balance value (forecast years 1–5) for the month of June for the forecast initialized in November 1960 is the average of the 7
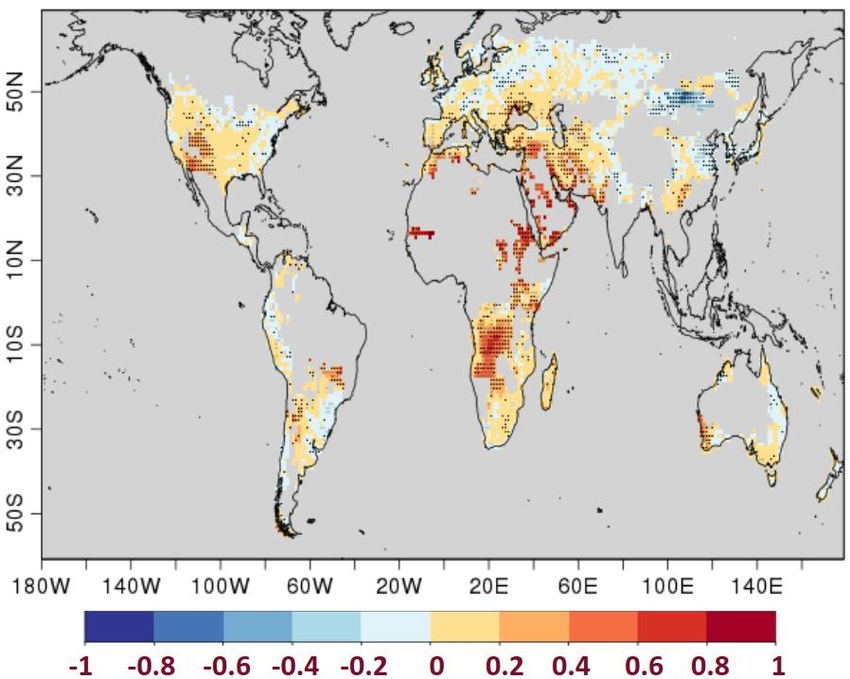
1961–1965 June accumulated values, and for the forecast initialized on November 1961, the average is obtained with the 1962–1966 June accumulated values and so on. Estimation of multi-annual SPEI6: The multi-annual averaged accumulated values are then fitted to a suitable parametric probability distribution and standardized to obtain SPEI6. Three-parameter shifted log-logistic distribution is used to fit the climate water balance values for SPEI6 in our case. We use the entire hindcast period (1961-2014) as a reference for standardization. Calibration and multi-model combination of SPEI6: The computed index of the individual forecast system is calibrated. Following this, a large multi-model ensemble is constructed by pooling individual forecast system members together. Calculation of skill scores of the probabilistic decadal forecast Generation of images: The predicted likelihood map (in %) of the most likely tercile categories over winter wheat harvesting regions along with the illustration of the performance of decadal predictions in forecasting the most likely category of multi- year averaged SPEI6 in the past years over Granada, Spain are presented. 4.5 Additional information Forecast skill of SPEI6: Evaluating the quality of the predictions is considered a fundamental step in climate prediction because it assesses whether the prediction system can be trusted to forecast certain event categories and/or whether it offers an improvement with respect to the climatological forecast. In this study, the quality of the predictions over global wheat harvesting regions are investigated using the Ranked Probability Skill Score (RPSS, see section 7.4.2.2). Figure 1 shows the RPSS applied in the product sheet. A positive and significant value of RPSS is found over several regions, particularly over the Mediterranean, Middle East, and South Africa. This indicates that the decadal predictions exhibit an added value with respect to a simple climatological multi-year approach in predicting terciles of SPEI6 distribution. The forecast in the product sheet is presented only for the areas that exhibit positive skill. Figure 1: Forecast quality assessment of SPEI6. Ranked Probability Skill Score (RPSS) of calibrated SPEI6 forecast averaged over years 1–5 during the wheat harvest month in each area (presented in Fig. 1 of the product sheet) for the period 1961–2014. Dots indicate the areas where decadal predictions provide significantly better forecasts than the reference forecast at the 95% confidence level based on a random walk test (DelSole and Tippett, 2016) which checks whether the simulations outperform the reference forecast during a significant number of years. The areas over which the wheat is not grown is represented in grey. 8
5. Technical appendix for infrastructure case study (DWD) 5.1 User needs The Wupperverband manages water level and quality of the Wupper catchment in north- western Germany. It is interested in decadal predictions of drought indices, which correlate to dam water levels, such as the Standardized Precipitation Index (SPI) and the Standardized Precipitation Evaporation Index (SPEI). The Wupperverband needs decadal predictions at high spatial resolution because it manages 14 dams in a total catchment area of 813 km². Different temporal aggregations influencing different water management processes were explored: annual means as well as multi-year seasonal means of hydrological seasons (February-March-April FMA, May-June-July MJJ, August-September-October ASO, November-December-January NDJ) for forecast years 1-3. 5.2 Model and observation data In order to fulfil the user need for high-resolution predictions the statistical downscaling EPISODES (see section 7.1.1) has been applied to downscale input data of the sixteen member decadal prediction system MPI-ESM-LR (see sections 6.1.4) to a spatial resolution of ~11 km. The other three global models could not be used since necessary input data for statistical downscaling was not available. HYRAS and HoStRaDa/ TRY basic data are applied as high-resolution observational data for Germany (see section 6.2.1 and 6.2.2). 5.3 Post-processing and evaluation methods Both drought indices SPI and SPEI, the latter based on the Penman-Monteith method, have been considered (see section 7.3.2), because the Wupperverband have extensive experience in correlating those indices to water levels of dams of different sizes since SPI and SPEI describe different aspects of the water cycle. The Decadal Climate Forecast Recalibration Strategy (DeFoReSt, see section 7.2.1) has been performed for precipitation before calculating the SPI since it has been shown to improve prediction skill for this variable in Germany. For SPEI, a recalibration could not be performed because the time period of the available HoStRaDa/ TRY basic observation data is too short. The skill of probabilistic decadal predictions in reproducing past observations is assessed by the correlation coefficient (see section 7.4.1.1) as well as the RPSS (see section 7.4.2.2.) in comparison to the reference prediction observed climatology in the reference time period. A significance test based on 500 non-parametric block bootstraps (considering autocorrelation) and a significance level of 95% is applied to verify whether the skill comparison between hindcasts and the reference prediction is subject to accidental variations due to small sample sizes. Accidental variations can be excluded if the correlation or the RPSS are significantly above or below zero. 5.4 Analysis protocol for product sheet 5.4.1 Analysis of SPI at different temporal aggregations Preparation of EPISODES data and HYRAS observations for recalibration: The means over the four hydrological seasons as well as the annual means have been calculated for precipitation. The Wupper catchment study area in north-western Germany has 9
been selected (50.5-53.5°N, 6.5-11°E), and all data have been interpolated onto the same regular 0.1 degree grid. Recalibration of precipitation: The averages of the hydrological seasons and annual means of precipitation have been recalibrated. The time period 1962-2020 has been chosen as training and adjustment time period. The observational data for recalibration are the same as those used for the calculation of the skill scores. Preparation of EPISODES data for the calculation of SPI: The annual means and means over hydrological seasons for forecast years 1-3 as well as ensemble means have been constructed for the study area and the long-term evaluation period 1962- 2020 (1962-2019 for NDJ due to restricted data availability) plus the actual forecast year. Preparation of HYRAS observations for the calculation of SPI: The annual means and means over hydrological seasons for forecast years 1-3 have been constructed for the study area and the long-term evaluation period. Calculation of SPI for EPISODES and HYRAS observations: The SPI has been calculated for the whole EPISODES hindcast set and HYRAS observations in standardizing precipitation over the long-term evaluation period. Calculation of skill scores and decadal predictions: The ensemble mean and probabilistic decadal predictions of SPI have been calculated in constructing ensemble mean anomalies as well as probabilities of different tercile categories (high, medium, low SPI) with respect to the WMO reference period 1981-2010. The prediction skills of SPI have been evaluated based on the correlation to HYRAS observations as well as the RPSS compared to the reference prediction observed climatology in the long-term evaluation period. Generation of images: Combined map plots of probabilistic forecasts (presented by colours of dots) and the RPSS forecast skill (presented by sizes of dots) of SPI in the study area as well as RPSS and correlation skill map plots have been drawn for the product sheet. 5.4.2 Analysis of SPEI at different temporal aggregations ● Calculation of PET for EPISODES and observations: The PET has been calculated from temperature, humidity, solar radiation, wind speed and elevation of the EPISODES predictions as well as the HYRAS and HoStRaDa/ TRY basic data observations on a common regular 0.1 degree grid. All data have been selected for the Wupper catchment study area in north-western Germany (50.5-53.5°N, 6.5-11°E). ● Preparation of EPISODES data for the calculation of SPEI: The difference between precipitation and PET has been calculated. The annual means and means over hydrological seasons for forecast years 1-3 as well as ensemble means have been constructed for the study area and the short-term evaluation period 1995-2012 (1995-2011 for NDJ due to restricted data availability) plus the actual forecast. This shorter period has been chosen due to restricted availability of HoStRaDa/ TRY basic data observations. 10
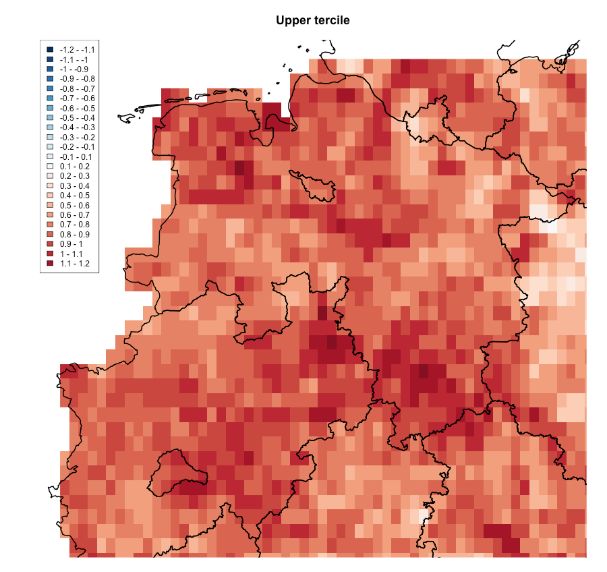
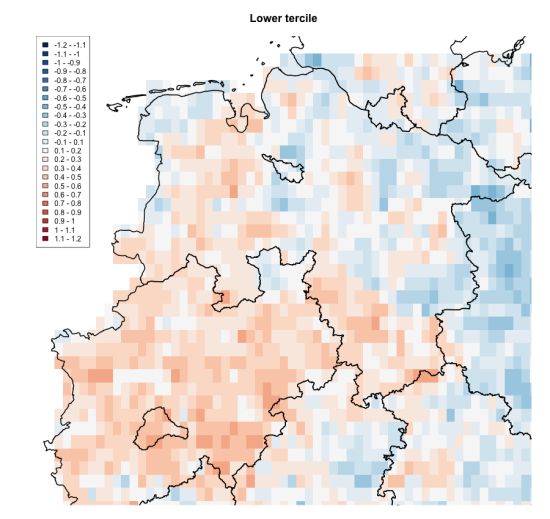
● Preparation of observations for the calculation of SPEI: The difference between precipitation and PET has been calculated. The annual means as well as means over hydrological seasons for forecast years 1-3 have been constructed for the study area and the short-term evaluation period. ● Calculation of SPEI for EPISODES and observations: The SPEI has been constructed for the whole EPISODES hindcast set and observations by standardising the difference between precipitation and PET over the short-term evaluation period. ● Calculation of skill scores and decadal predictions: The ensemble mean and probabilistic decadal predictions of SPEI have been calculated in constructing ensemble mean anomalies as well as probabilities of different tercile categories (high, medium, low SPEI) with respect to the reference period which is similar to the short-term evaluation period and thus, shorter than the standard reference period 1981-2010. The prediction skills of SPEI have been evaluated based on the correlation to HYRAS and HoStRaDa/ TRY basic data observations as well as the RPSS compared to the reference prediction observed climatology in the short-term evaluation period. ● Generation of images: Combined map plots of probabilistic forecasts (presented by colours of dots) and the RPSS forecast skill (presented by sizes of dots) of SPEI in the study area as well as RPSS and correlation skill map plots have been drawn for the product sheet. 5.5 Additional information Deterministic and probabilistic skill scores showed that the high-resolution statistical downscaling EPISODES is generally able to preserve the prediction skill of the MPI-ESM global prediction system. For SPI and SPEI, skill analyses have been evaluated for the annual means and the four hydrological seasons of forecast years 1-3. The product sheet has been constructed for the SPI prediction for forecast years 1-3 since this decadal prediction showed highest skill of all analyses. Multi-year seasonal SPI skill has been found promising for some regions and seasons in Germany, e.g. in early spring and autumn (relevant to the Wupperverband and other German water managers). To deliver high-resolution SPEI predictions observational datasets at high resolution and with longer time periods are needed, especially for radiation and wind, to reach more robust statistical results. First analyses to find higher prediction skills based on multi-model predictions of large-scale circulation have been promising but the teleconnection of Central Europe to the NAO is not strong enough. Further teleconnections are investigated. In addition to the product sheet, the map in Figure 2 shows the thresholds of the categories of the probabilistic SPI prediction for forecast years 1-3 per grid box, i.e. high, normal and low SPI. The thresholds are based on tercile values (33%, 66%) from observations in the reference period. 11
Figure 2: Maps of thresholds of the categories (high, normal, low SPI) of the probabilistic SPI prediction for forecast years 1-3 shown in the product sheet, based on observed terciles. 6. Model and observation data 6.1 Multi-model prediction ensemble 6.1.1 CMCC-CM2-SR5 The Euro - Mediterranean Centre on Climate Change coupled Climate Model Standard Resolution (CMCC-CM2-SR5) is documented in Cherchi et al., 2019. The atmospheric component is the Community Atmosphere Model (CAM5, Neale et al., 2012 ) and has a spatial resolution of approximately 100 km and 30 levels in the vertical. The oceanic component, Nucleus for European Modelling of the Ocean version 3.6 (NEMOv3.6, Madec and the NEMO team, 2016), uses a tripolar grid of 1 degree nominal resolution (ORCA1, Madec and Imbard, 1996) and has 50 levels in the vertical. The sea ice component is the Community Ice CodE version 4 (CICE4, Hunke and Lipscomb, 2008), while the land component is the Community Land Model version 4.5 (CLM4.5, Oleson et al., 2013). Full-field estimates of the observed state were used for the initialization procedure. For the initialization of the atmosphere we use ERA40 from 1960 until 1978, ERA-Interim from 1979 to 2018 and ERA5 afterwards. For the ocean and sea-ice initialization, an ensemble of three global ocean reanalyses was used (Yang et al., 2016). The land-surface initial conditions were obtained from a land-only CLM4.5 offline simulation. The decadal hindcasts/forecasts of the CMCC-CM2 consist of 7 members, initialized every year on the 1st of November, following the CMIP6 DCPP-A protocol (Boer et al., 2016). 6.1.2 EC-Earth3 The EC-Earth3 forecast system is composed of the IFS36R4 atmospheric model and the NEMO3.6 ocean model. The atmospheric model includes the HTESSEL land-surface component, while the ocean model has embedded the LIM3 sea-ice model. The atmospheric resolution is ~80 km while the ocean is run at a nominal resolution of 1 degree. The atmospheric initial conditions were taken from ERA40 from 1960 to 1978, from ERA- 12
Interim from 1979 to 2018 and ERA5 afterwards, using the full-field initialization method. The land-surface initial conditions were obtained from an offline simulation performed with the same HTESSEL version of the forecast system forced by atmospheric reanalyses. The ocean initial conditions were taken from ORAS4 until 2018 and ORAS5 afterwards, the sea ice initial conditions obtained from a reconstruction performed with the ocean model using atmospheric fluxes from reanalyses and nudging to the surface and subsurface ocean to ORAS4 and ORAS5. The decadal hindcasts/forecasts of the EC-Earth version 3 (EC-Earth3, Bilbao et al., 2021) were performed with 10 members, initialization every year on the first of November and using CMIP6 forcings, with the SSP2-4.5 scenario after 2014. 6.1.3 DePreSys4 The decadal hindcasts/forecasts of the Met Office Decadal Prediction System version 4 (DePreSys4). The DePreSys4 system is based on the HadGEM3-GC3.1 coupled climate model (Williams et al 2017). The atmosphere has a horizontal resolution of approximately 60 km (and 85 levels in the vertical) and an ocean resolution of 0.25 degree (75 levels in the vertical). Ten full-field data assimilating simulations are performed to obtain initial conditions for each of the 10 ensemble members. Here the model is nudged in the ocean, atmosphere and sea-ice components towards observations. In the ocean, temperature and salinity are nudged towards ten different monthly analyses created using global covariances (Smith and Murphy 2007), with a 10 day relaxation timescale. In the atmosphere, temperature and zonal and meridional winds are nudged towards the ERA40/Interim (Dee et al 2011) reanalysis with a six hourly relaxation timescale. Sea ice concentration is nudged towards monthly values from HadISST (Rayner et al 2003) with a one day relaxation timescale. Hindcasts are then started from 1st November initial conditions of this assimilation simulation and using CMIP6 forcings, with the SSP2-4.5 scenario after 2014. 6.1.4 MPI-ESM-1-2-LR The Max Planck Institute for Meteorology Earth System Model Low Resolution (MPI-ESM- LR) comprises the coupled atmosphere-ocean model ECHAM6/MPIOM revealing a spatial resolution of approximately 200 km with 47 levels in the vertical in the atmosphere and a GR15 (∼1.5 degree) resolution with 40 levels in the ocean (Jungclaus et al., 2013; Pohlmann et al., 2013; Stevens et al., 2013). The initialization procedure consists of a full-field nudged atmosphere and an ocean state consisting of assimilated observations via an Ensemble Kalman filtering method. The atmosphere is nudged by ERA40 reanalysis data (Uppala et al., 2005) until 1978 and ERA5 reanalysis data (Hersbach et al., 2020) from 1979 to today. Temperature and salinity anomalies for the ocean have been included from the EN4 observations (Good et al., 2013). An Ensemble Kalman filtering method (Brune et al., 2015) is used to assimilate the observations into the ocean. Based on the MPI-ESM-1-2-LR assimilation run, global decadal predictions (hindcasts, CMIP6 forcing), have been initialized on 1st November each year from 1960 to 2020 for the next 10 years (simulation period). The ensemble, initialized by different ocean states, consists of 16 members. 13
6.2 Observation and reanalysis data 6.2.1 HYRAS The high-resolution HYRAS observations (see papers in https://www.dwd.de/DE/leistungen/hyras/hyras.html (German), no public download, contact via hydromet@dwd.de) provide data for precipitation, temperature and humidity. The data cover the period 1951 – 2015 (2020 for precipitation) for Germany at a spatial resolution of 0.11 degree and are available on a daily basis. 6.2.2 HoStRaDa/ TRY basic data The high-resolution HoStRaDa/ TRY basic data set (ftp://opendata.dwd.de/climate_environment/CDC/grids_germany/hourly/Project_TRY/) provides data for radiation and surface winds in Germany. The data have a spatial resolution of 0.01 degree and are available on a daily basis for 1995 until 2012. 6.2.3 ERA5 ERA5 Reanalysis (Bell et al., 2020; Hersbach et al., 2020) are produced and updated in near real time by the European Centre for Medium-Range Weather Forecasts (ECMWF). The data cover the period 1950-present at a spatial resolution of 0.25 degree. It is important to point out that we use the preliminary release version of the ERA5 reanalysis back extension for the years prior to 1978. 6.2.4 E-OBS The gridded observational dataset E-OBS (Cornes et al. 2018; http://surfobs.climate.copernicus.eu/dataaccess/access_eobs.php) provides data for precipitation, temperature, sea level pressure and global radiation in Europe (25°N-71.5°N x 25°W-45°E). The data are available on a 0.1 and 0.25 degree regular grid, on a daily basis and cover the period from 1950-present. 6.2.5 HadSLP2r The Hadley Centre Sea Level Pressure dataset (HadSLP2, Allan and Ansell, 2006; https://www.esrl.noaa.gov/psd/data/gridded/data.hadslp2.html) provides global data for monthly sea level pressure. The data cover the period from 1850-present at a spatial resolution of 5 degrees. 6.2.6 HURDAT2 HURDAT2 is the current ‘best track’ database compiled by the US National Hurricane Center, and gives post-storm analyses of the intensity, central pressure, position, and size of Atlantic and eastern North Pacific basin tropical and subtropical cyclones (National Hurricane Center HURDAT2, accessed 2019; Landsea and Franklin 2013). 6.2.7 US damages US hurricane damages, including both insured and un-insured losses, are compiled from the NOAA NCEI U.S. Billion-Dollar Weather and Climate Disasters database (Smith and Katz 2013, https://www.ncdc.noaa.gov/billions/time-series; database accessed 2021) for the 14
period 1980-2020. Damages from 1961 to 1979 are compiled from the Annual Summaries of North Atlantic Storms (National Hurricane Center, 1961-1979, https://www.aoml.noaa.gov/general/lib/lib1/nhclib/mwreviews.html). The damages are adjusted to 2020 US dollars, taking into account inflation and changes in wealth and population, using the method described in Pielke and Landsea (1998). US population data is used as a proxy for population of the counties affected by hurricanes, so the correction equation in Pielke and Landsea (1998) simplifies to NL 2020=Ly*GDP2020/GDPy, where NL2020 is the annual damage normalised to 2020, L y is the loss recorded in year y, and GDP2020 and GDPy are the nominal gross domestic products in 2020 and year y respectively. Gross domestic product data is from the Bureau of Economic Analysis (https://www.bea.gov/data/gdp/gross-domestic-product Supplemental Information & Additional Data, accessed 31/3/21). Use of US population rather than that of the affected counties has very little effect on the correction factor: the correlation coefficient between the losses in this work and those used in Pielke and Landsea (1998) for the overlapping period is 0.96 for the annual losses, and 0.99 for the 5-year total losses. 7. Post-processing and evaluation methods 7.1 Empirical models 7.1.1 Statistical downscaling method EPISODES In order to reach sufficient spatial resolution the MPI-ESM predictions have been statistically downscaled with EPISODES (Kreienkamp et al., 2018) to ~11 km over Germany. The statistical downscaling method builds statistical relationships between large-scale variables in Central Europe and local variables in Germany for observations and reanalyses and applies these to simulated large-scale predictions. It is divided into two parts, the detection of analogue days with subsequent regression and the construction of daily time series. In the first step, the geopotential height, temperature and relative humidity in 1000, 850, 700 and 500 hPa of the reanalysis and model data are interpolated to a 100 km grid. For each model day, the 35 most similar days are filtered out of the reanalysis (‘perfect prognosis’ approach). Based on these days linear regressions between large-scale and small- scale variables (e.g. temperature or precipitation) are calculated. In the second step, daily time series are generated matching the resolution of the observations. Based on the short-term variability of temperature and precipitation, the most similar day from the observations is detected for each model day and used for all variables. Finally, the observed daily climatology, the climate change guidance (low-pass filtered results of the first step) and the short-term variability of the detected day from the observations are added, revealing a high-resolution dataset, which is consistent for all variables. 15
7.1.2 Regression Models Large-scale modes of climate variability can be used as predictors of regional climate variability. Regression model can be constructed to relate the model forecast large-scale mode of variability to the observed regional variability of interest. This both utilizes the often more predictable large-scale circulation and relates it directly to the observed regional surface climate variability, removing the need to rely on the model’s simulation of these teleconnections. Such regression models were developed in two of the decadal prototypes: 7.1.2.1 Estimation of precipitation from the NAO index In the Energy prototype, to predict the precipitation in the basins we combine the observed relationship between the NAO index and the aggregated precipitation in each basin with the model-predicted NAO index. The observed relationship between the NAO index and precipitation is obtained by a linear regression (least squares method) of the decadal components of the two time series. The decadal components are derived from the 10-year running average of the time series from 1961 to 2019. 7.1.2.2 Estimation of the ACE index from forecast MDR-TROP In the Insurance prototype, the relationship between observed 5-year mean ACE index and 5-year mean forecast MDR-TROP is quantified using ordinary least squares linear regression on past data. The forecast ACE probability distribution is estimated from the residuals of the linear regression fit (Wilks 2019, equation 7.23). The linear regression fit is performed on non-overlapping 5-year mean data, to avoid over-confidence in the prediction intervals. Since there are 5 sets of non-overlapping 5-year means (for example the first set is the means of 1961-1965, 1966-1970,1971-1975, etc; the second set is the means of 1962-1966, 1967-1971, 1972-1976, etc), the linear-regression is performed on each set separately, and we use the mean fit coefficients for the line of best fit and prediction interval estimation. 7.1.2.3 Estimation of US damages from forecast MDR-TROP index The relationship between observed 5-year total US hurricane damage and forecast MDR- TROP is non-linear, and further complicated by single extreme damage events in a season such as hurricanes Andrew (1992) and Katrina (2005). To overcome this issue, we remove the losses attributed to Andrew and Katrina from the data and perform linear regression of log(US damage) onto forecast MDR-TROP. We then assume that extreme single events can occur randomly at the climatological frequency (2 events in 61 years of data). To incorporate this into the predicted probability distributions, for a given MDR- TROP we estimate the ‘base’ probability distribution from the linear regression, then randomly sample a ‘base’ total loss for the 5-year period. We then loop through each of the 5 years in the period, randomly sampling whether an extreme event occurs. If an extreme is selected, then its loss is added to the base loss. This is repeated 5000 times to build up a probability distribution for a given forecast MDR-TROP. 16
7.2 Bias correction and calibration 7.2.1 DeFoReSt recalibration The Decadal Forecast Recalibration Strategy (DeFoReSt, Pasternack et al., 2018) corrects bias, drift and conditional bias and adjusts the ensemble spread in cross validation. It applies the parametric drift correction of Kruschke et al. (2015) considering the drift along forecast years by means of a third order polynomial (Gangstø et al., 2013) and also third order polynomial parameters over start years to allow for non-stationary model drifts (Kharin et al., 2012). This mean bias and drift adjustment has been extended by a similar third order parametric adjustment of the conditional bias, i.e. the bias depending on the magnitude, and a quadratic parametric recalibration of the ensemble spread. A cross validation approach leaves out all decadal predictions initialized within the 10-year prediction period as training data for the estimation of the correction parameters of a particular 10-year decadal prediction. The method reveals an improved prediction skill compared to the simple forecast time dependent bias adjustment. 7.2.2 Variance adjustment The variability of the ensemble mean signal is lower than the observed. For this reason, after computing e.g. the NAO index, we follow Eade et al. (2014) to adjust the ensemble mean NAO variability as well as the variance of each ensemble member in order to match the variance of the predictable component in observations. 7.2.3 Variance Inflation The technique of variance inflation is presented in Doblas-Reyes et al. (2005). This calibration approach adjusts the forecasted variables to have a similar interannual variance to that of the reference dataset at every grid point and by preserving the ensemble-mean correlation between the forecast and reference dataset. 7.3 Indices 7.3.1 NAO index The NAO index is computed by the differences of the zonally averaged sea level pressure anomalies over the longitudes 80°W–30°E, between the latitudes 35°N and 65°N (Jianping and Wang, 2003). This method allows for longitudinal migration of the NAO centres of action (Barnston and Livesey, 1987). 7.3.2 Drought indices Droughts are characterized by a shortage of available water. They can be quantified by means of drought indices describing the anomalies of water availability compared to a long- term climatology (Palmer, 1965). Various indices have been developed based on different purposes and datasets: 7.3.2.1 SPI The Standardized Precipitation Index (SPI) is defined by dividing the precipitation anomaly by its standard deviation (McKee et al., 1993). The parametric standardization of precipitation applies the Gamma distribution function for parameter estimation. The 17
general interpretation of the SPI (Lloyd-Hughes and Saunders, 2002) represents normal conditions as values between −1 and 1, higher values correspond to wet conditions, and smaller values to droughts. 7.3.2.2 SPEI The Standardized Precipitation Evaporation Index (SPEI, Vicente-Serrano et al., 2010) standardizes the climatic water balance, i.e. the difference between precipitation and potential evapotranspiration (PET), applying a Log Logistic distribution function for parameter estimation. The PET can be defined by different methods depending on the kind of application, e.g. the parametrization of Thornthwaite (1948) based on temperature and astronomical data or the Penman-Monteith method based on FAO-56 methodology (Allen et al., 1998) using 2m temperature, humidity, solar radiation, wind speed and elevation. 7.3.3 ACE Hurricane activity is measured by the seasonal accumulated cyclone energy (ACE). ACE is defined as the sum of the squares of the maximum sustained surface wind speed (in knots) measured every six hours for all storms while they are at least tropical storm intensity (1- minute average wind speed of 34 knots or greater). 7.3.4 MDR-TROP The MDR-TROP index is defined as the difference between the near-surface temperature of the hurricane main development region (MDR; 10oN to 25oN in latitude, 80oW to 20oW in longitude) and the tropics (-30oN to +30 o N, sea only) as a whole. 7.4 Evaluation of forecast quality 7.4.1 Deterministic skill scores 7.4.1.1 Correlation coefficient (Pearson) The correlation coefficient ( , Ernste 2011) indicates the strength of the linear relationship between hindcasts of a certain forecast year period over all start years (X) and observations (Y) based on anomalies against the long-term climatology: ∑ =1 ( − )( − ) = 2 √∑ 2 =1 ( − ) ∑ =1 ( − ) where N is the number of all objects, i presents the individual values and µ the mean of the hindcasts and observations. The correlation coefficient is dimensionless and ranges between -1 (high negative correlation) and 1 (high positive correlation). If the correlation equals zero there is no relationship between hindcasts and observations. 7.4.1.2 Rank correlation coefficient (Spearman) The Spearman rank correlation coefficient between two variables is equal to the Pearson correlation coefficient (section 7.4.1.1) between the ranks of those variables. The Spearman rank correlation coefficient quantifies whether there is a monotonic 18
relationship between two variables (i.e. when one increases, so does the other), but does not assume linearity. As with the Pearson correlation coefficient, the values range between -1 (perfect negative monotonic relationship) and +1 (perfect positive monotonic relationship). 7.4.2 Probabilistic skill scores 7.4.2.1 Brier Skill Score (BSS) The BSS indicates to what extent the forecasts can predict the occurrence of a specific observed category (e.g. below/above average) in comparison to a reference forecast. The reference forecast usually is the climatology with equal probabilities for each event or the persistence. A BSS equal to one (1.0) indicates a perfect forecast, while a BSS equal to zero indicates skill that is no better than the reference forecast. If the BSS is negative, the forecast is less skilful than the reference forecast. − = =1− ( ≤ 1) 0 − where BS is the Brier Score and the mean squared error of the probability forecasts. A perfect forecast exhibits BS=0. 1 = ∑ ( − )2 (0 ≤ ≤ 1) =1 where n equals the number of the observed–forecasted pairs, f the forecasted probability (range 0-1) and o the observed occurrence (o=0 if it didn’t happen, o=1 if it happened). 7.4.2.2 Ranked Probability Skill Score (RPSS) The RPSS describes the skill of a probabilistic decadal prediction to reproduce the observed variability in the past in comparison to that of an alternative reference prediction, e.g. the observed climatology or the uninitialized climate projection. The anomalies of hindcasts and observations are separated into categories of equal frequency, e.g. describing above normal, normal and below normal conditions based on tercile thresholds, with respect to the reference time period. The ranked probability score RPS P,O defines the squared error between predicted and observed cumulative probabilities Pj,k and Oj,k, respectively, over j = 1, n start years and k = 1, K categories. P j,k results from the distribution of ensemble members, O j,k = 0 if observations lie within a category higher than k and Oj,k = 1 else. The RPSS (Ferro et al., 2008; Wilks, 2011) compares the RPSP,O of decadal predictions to the RPSR,O of a reference prediction: 1 2 , , = 1 − , , with , = ∑ =1 ∑ =1 ( , − , ) , The skill scores give values larger/smaller than 0 if the decadal prediction is more/ less skilful in reproducing past observations than the reference prediction. If the skill score is 0, both are equally skilful. If it is 1, the decadal prediction perfectly matches past observations. 19
7.4.2.3 Relative Operating Characteristic (ROC) skill score ROC skill scores are used in the verification of the probability forecast system, which relate the hit rate to the corresponding false-alarm rate of a particular categorical event (Kharin et al., 2003). For instance, while assessing the above normal temperature events, the hit rate is considered as the fraction of the observed above normal events that were correctly forecast, whereas the corresponding false-alarm rate is the fraction of the predicted above normal events that actually did not occur in reality (i.e., were false alarms). Therefore, this skill measure helps to understand the ability of the forecast system to discriminate between events and non-events of a particular categorical event, in general. The ROC skill score (SSROC) is defined as SSROC = 2 AROC - 1 where, AROC is the area under the ROC curve that is obtained by plotting the resulting hit rates versus the false-alarm rates (see Kharin et al., 2003 for detailed description). A positive SSROC corresponds to a skilful forecast, and a negative score or a score equals to 0 corresponds to a forecast with no-skill. 7.4.2.4 Contingency table, hit rate and false alarm rate A 2x2 contingency table is used to assess the reliability of a forecast in predicting a dichotomous (yes/no) event (Wilks 2020; chapter 9). For probabilistic forecasts, a forecast is designated a ‘yes’ if the probability of forecasting a ‘yes’ event is above a certain threshold. As an example, if we define an event (‘yes’) as above average hurricane activity, then a ‘yes’ forecast will be when the forecast probability of above average hurricane activity is >0.5 (assuming that the forecast probabilities have been well calibrated). The contingency table displays counts of all possible combinations of forecast and observed event pairs as shown below (Table 1). The hit rate is the ratio of correct forecasts to the number of times this event occurred (a/(a+c)) and the false alarm rate is the ratio of false alarms to number of non-occurrences of the event (b/(b+d)). Table 1: Schematic display of a contingency table. Observed Yes No Forecast Yes a (hits) b (false alarms) No c (misses) d (correct rejections) 8. Reference list Allan, R. and T. Ansell (2006): A New Globally Complete Monthly Historical Gridded Mean Sea Level Pressure Dataset (HadSLP2): 1850–2004. J. Climate, 19, 5816–5842, https://doi.org/10.1175/JCLI3937.1. Allen, R., Pereira, L., Raes, D. & Smith, M. (1998). Crop evapotranspiration – Guidelines for computing crop water requirements – FAO Irrigation and drainage paper 56. – FAO – Food and Agriculture Organization of the United Nations, Rome. 20
http://www.fao.org/docrep/X0490E/x0490e00.htm#Contents (accessed at 15.12.2017), ISBN: 92-5- 104219-5, 1998. Barnston, A., and R. Livesey, 1987: Classification, seasonality and persistence of low-frequency atmospheric circulation patterns. Mon. Wea. Rev.,115, 1083–1126. Bell, B., Hersbach, H., Berrisford, P., et al. (2020): ERA5 monthly averaged data on pressure levels from 1950 to 1978 (preliminary version). Copernicus Climate Change Service (C3S) Climate Data Store (CDS). https://cds.climate.copernicus-climate.eu/cdsapp#!/dataset/reanalysis-era5-pressure- levels-monthly-means-preliminary-back-extension?tab=overview Boer, G. J., Smith, D. M., Cassou, C., et al. (2016). The Decadal Climate Prediction Project (DCPP) contribution to CMIP6, Geosci. Model Dev. 9: 3751-3777, https://doi.org/10.5194/gmd-9-3751-2016 Bretherton, C. S., Widmann, M., Dymnikov, V. P., et al. (1999). The effective number of spatial degrees of freedom of a time-varying field. Journal of climate, 12(7), 1990–2009. Bilbao, R., S. Wild, P. Ortega, et al. (2021), Assessment of a full-field initialized decadal climate prediction system with the CMIP6 version of EC-Earth, Earth Syst. Dynam., 12, 173–196, https://doi.org/10.5194/esd-12-173-2021 Brune, S., Nerger, L., & Baehr, J. (2015). Assimilation of oceanic observations in a global coupled Earth system model with the SEIK filter. Ocean Modelling, 96, 254–264. Cherchi, A., Fogli, P. G., Lovato, T., et al. (2019). Global Mean Climate and Main Patterns of Variability in the CMCC‐CM2 Coupled Model. J. Adv. Model. Earth Syst. 11(1): 185–209. Cornes, R., G. van der Schrier, E.J.M. van den Besselaar, and P.D. Jones (2018). An Ensemble Version of the E-OBS Temperature and Precipitation Datasets. J. Geophys. Res. Atmos., 123. doi:10.1029/2017JD02820 Dee, D. P., et al. (2011). The era-interim reanalysis: configuration and performance of the data assimilation system Q. J. R. Meteorol. Soc. 137 553–97 DelSole, T., & Tippett, M. K. (2016). Forecast Comparison Based on Random Walks, Monthly Weather Review, 144(2), 615-626. Doblas-Reyes, F. J., Hagedorn, R., & Palmer, T. N. (2005). The rationale behind the success of multi- model ensembles in seasonal forecasting—II. Calibration and combination. Tellus A: Dynamic Meteorology and Oceanography, 57(3), 234-252. Eade, R., Smith, D., Scaife, A., et al. (2014). Do seasonal‐to‐decadal climate predictions underestimate the predictability of the real world?. Geophysical research letters, 41(15), 5620–5628. Ernste, H. (2011). Angewandte Statistik in Geographie und Umweltwissenschaften, vdf, UTB, Zürich, 569pp. Ferro, C. A. T., Richardson, D. S. & Weigel, A. P. (2008). On the effect of ensemble size on the discrete and continuous ranked probability scores. – Meteor. Appl. 15, 19-24. DOI: 10.1002/met.45. Gangstø, R., Weigel, A. P., Liniger, M. A. & Appenzeller, C. (2013). Methodological aspects of the validation of decadal predictions. – Climate Res. 55, 181–200. DOI:10.3354/cr01135. Good, S. A., Martin, M. J., and Rayner, N. A. (2013), EN4: Quality controlled ocean temperature and salinity profiles and monthly objective analyses with uncertainty estimates, J. Geophys. Res. Oceans, 118, 6704– 6716, doi:10.1002/2013JC009067. Hersbach, H., Bell, B., Berrisford, P., et al. (2020). The ERA5 global reanalysis. Q J R Meteorol Soc., 146: 1999– 2049. https://doi.org/10.1002/qj.3803 21
Hunke, E., & Lipscomb, W. (2008). CICE: The Los Alamos sea ice model, documentation and software, version 4.0. Los Alamos National Laboratory, Technical Report LA‐CC‐06‐012 Jianping, L., & Wang, J. X. (2003). A new North Atlantic Oscillation index and its variability. Advances in Atmospheric Sciences, 20(5), 661–676. Jungclaus, J. H., Fischer, N., Haak, H., et al. (2013). Characteristics of the ocean simulations in MPIOM, the ocean component of the MPI-Earth system model. – J. Adv. Model. Earth Syst. 5, 422– 446. DOI: 10.1002/jame.20023. Kharin, V.V., Boer, G. J., Merryfield, W. J., et al. (2012). Statistical adjustment of decadal predictions in a changing climate. Geophys. Res. Lett. 39, L19705. DOI: 10.1029/2012GL052647. Kharin, V. V., & Zwiers, F. W. (2003). On the ROC Score of Probability Forecasts, Journal of Climate, 16(24), 4145-4150. Kreienkamp, F., Paxian, A., Früh, B., et al. (2018). Evaluation of the Empirical-Statistical Downscaling method EPISODES. – Clim. Dyn. 52, 991–1026 (2019). DOI: 10.1007/s00382-018-4276-2. Kruschke, T., Rust, H. W., Kadow, C., et al. (2015). Probabilistic evaluation of decadal prediction skill regarding Northern Hemisphere winter storms. Meteorol. Z. 25, 721–738. DOI:10.1127/metz/2015/0641. Landsea, C. W., & Franklin, J. L. (2013). Atlantic Hurricane Database Uncertainty and Presentation of a New Database Format, Monthly Weather Review, 141(10), 3576-3592. https://doi.org/10.1175/MWR-D-12-00254.1 Lloyd-Hughes, B. & Saunders, M. A. (2002). A drought climatology for Europe. – Int. J. Climatol. 22, 1571–1592. DOI: 10.1002/joc.846. Madec, G., & Imbard, M. (1996). A global ocean mesh to overcome the North Pole singularity. Climate Dynamics, 12, 381–388. Madec, G., & the NEMO team (2016). NEMO ocean engine—Version 3.6. Tech Rep ISSN 1288–1619 No 27 Pôle de Modélisation, Institut Pierre‐Simon Laplace (IPSL), France Mckee, T. B., Doesken, N. J. & Kliest, J. (1993). The relationship of drought frequency and duration to time scales. – In: Proceedings of the 8th Conference of Applied Climatology, 17-22 January, Anaheim. American Meteorological Society, Boston, 179-184. Neale, R., Conley, A. J., Garcia, R., et al. (2012). Description of the NCAR Community Atmosphere Model (CAM5.0). NCAR/TN‐486+STR, NCAR Technical Note (http://www.cesm.ucar.edu/models/cesm1.0/cam/docs/description/cam5\_desc.pdf) Oleson, K. W., Lawrence, D. M., Bonan, G. B., et al. (2013). Technical description of version 4.5 of the Community Land Model (CLM). NCAR Technical Note, NCAR/TN‐503+STR Palmer, W. C. (1965). Meteorological Drought. – Research paper no. 45, U.S. Weather Bureau, Washington D.C., 65 pp. http://www.ncdc.noaa.gov/temp-and-precip/drought/docs/palmer.pdf (accessed at 15.12.2017). Pasternack, A., Bhend, J., Liniger, M. A., Rust, H. W., Müller, W. A. & Ulbrich, U. (2017). Parametric Decadal Climate Forecast Recalibration (DeFoReSt 1.0). – Geosci. Model Dev., under review. DOI: 10.5194/gmd-2017-162. Pielke , R. A., Jr., & Landsea, C. W. (1998). Normalized Hurricane Damages in the United States: 1925–95, Weather and Forecasting, 13(3), 621-631. https://doi.org/10.1175/1520- 0434(1998)0132.0.CO;2 22
You can also read

















































