An Efficient Query Recovery Attack Against a Graph Encryption Scheme
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
An Efficient Query Recovery Attack Against a Graph Encryption Scheme Francesca Falzon Kenneth G. Paterson Brown University ETH Zürich University of Chicago Switzerland United States of America kenny.paterson@inf.ethz.ch francesca_falzon@brown.edu ABSTRACT the client to quickly recover the shortest path between and in Ghosh, Kamara and Tamassia (ASIA CCS 2021) presented a Graph . The scheme pre-computes a matrix called the SP-matrix from Encryption Scheme supporting shortest path queries. We show which shortest paths can be efficiently computed, and then creates how to perform a query recovery attack against this GKT scheme an encrypted version of this matrix which we refer to as the en- when the adversary is given the original graph together with the crypted database (EDB). EDB is sent to the server. At query time, leakage of certain subsets of queries. Our attack falls within the se- the client computes a search token for the query ( , ); this token is curity model used by Ghosh et al., and is the first targeting schemes sent to the server and is used to start a sequence of look-ups to EDB. supporting shortest path queries. Our attack uses classical graph al- Each look-up results in a new token and a ciphertext encrypting gorithms to compute the canonical names of the single-destination the next vertex on the shortest path from to . The concatenation shortest path spanning trees of the underlying graph and uses these of these ciphertexts is returned to the client and decrypting this canonical names to pre-compute the set of candidate queries that sequence reveals the vertices in the shortest path. match each response. Then, when all shortest path queries to a The GKT scheme of [12] is very elegant and efficient. For a single node have been observed, the canonical names for the corre- graph on vertices, computing the SP-matrix takes time ( 3 ) sponding query tree are computed and the responses are matched and dominates the setup time. Building a search token involves to the candidate queries from the offline phase. The output is guar- computing a pseudo-random function. Processing a query ( , ) at anteed to contain the correct query. For a graph on vertices, our the server requires look-ups in EDB, where is the length of the attack runs in time ( 3 ) and matches the time complexity of the shortest path from to . Importantly, thanks to the design of the GKT scheme’s setup. We evaluate the attack’s performance using scheme, query processing can be done without interaction with the the real world datasets used in the original paper and on random client, except to receive the initial search token and to return the graphs, and show that for the real-world datasets as many as 21.9% result. This results in EDB revealing at query time the sequence of of the queries can be uniquely recovered and as many as 50% of the labels (tokens) needed for the recursive lookup and the sequence queries result in sets of only three candidates. of (encrypted) vertices that is eventually returned to the client. Ghosh et al. [12] provide a security proof of the GKT scheme KEYWORDS in a simulation-based security model that assumes an honest-but- curious (semi-honest) server. The approach identifies a leakage encrypted databases, leakage-abuse attacks, cryptanalysis profile for the GKT scheme and formally proves that the scheme leaks nothing more than this. The leakage profile comes in two parts: 1 INTRODUCTION setup leakage (available to the server upon receipt of the encrypted Graphs are a powerful tool that can be used to model many prob- data structure) and query leakage (that becomes available to the lems related to social networks, biological networks, geographic server as it processes each query). Specifically, the query leakage relationships, etc. Plaintext graph database systems have already leaks when two queries are equal i.e. the query pattern, the length received much attention in both industry (e.g. Amazon Neptune [2], of the queried path, and how two paths with the same destination Facebook TAO [4], Neo4j [21], GraphDB [22]) and academia (e.g. intersect. Pregel [18], GraphLab [17], Trinity [26]). We exploit the query leakage of the GKT scheme to mount a With the rise of data storage outsourcing, there is an increased query recovery (QR) attack against the scheme. Our attack can be interest in Graph Encryption Schemes (GES). A GES enables a mounted by the honest-but-curious server and requires knowledge client to encrypt a graph, outsource the storage of the encrypted of the graph . This may appear to be a strong requirement, but graph to an untrusted server, and finally to make certain types of is in fact weaker than is permitted in the security model of [12], graph queries to the server. Current GES typically only support where the adversary can even choose . Assuming that the graph one type of query, e.g. adjacency queries [7], neighbor queries [7], is public is a standard assumption for many schemes that support approximate shortest distance queries [19], and exact shortest path private graph queries [12, 20, 25]. This model is perfect for routing queries [12, 27]. and navigation systems in which the road network may easily be In this paper, we analyse the security of the GES of Ghosh, Ka- obtained online via Google Maps or Waze, but the client may wish mara and Tamassia [12] from ASIA CCS 2021. We refer to this to keep its queries private. In such a scenario, the map and traffic scheme henceforth as the GKT scheme. The GKT scheme encrypts information are widely available, but the routing information of a graph such that when a shortest path query ( , ) is issued for individual users is sensitive. some vertices and of , the server returns information allowing 1
Conference ’22, June 2022, Nagasaki, Japan Francesca Falzon and Kenneth G. Paterson Our attack has two phases. First, it has an offline, pre-processing as many as 21.9 % of all queries can be uniquely recovered and as phase that is carried out on the graph . In this phase, we extract many as half of all queries can be mapped to at most 3 candidate from a plaintext description of all its shortest path trees. We then queries. Our experimental results show that query recovery tends process these trees and compute candidate queries for each query to result in smaller sets of candidate queries when the graphs are using each tree’s canonical labels. A canonical label is an encoding less dense, and that dense graphs tend to have more symmetries and of a graph that can be used to decide when graphs are isomorphic; a hence result in larger sets of candidate queries. Note also that our canonical label of a rooted tree can be computed efficiently using the attack is best possible: it always outputs a minimal set of candidates AHU algorithm [1]. This concludes the offline phase of the attack. consistent with the query leakage, and the correct query is always Its time complexity is ( 3 ) where is the number of vertices in included in the set. , and matches the run time of our overall attack and the run time We summarize our core contributions as follows: of the GKT scheme’s setup. Both our attack and the setup are lower bounded by the time to compute the all-pairs shortest paths, which (1) We present the first attack against a GES that supports short- takes ( 3 ) time for general graphs [11]. est path queries, and the second known attack against GESs, The second phase of the attack is online: As queries are issued, to our knowledge. the adversary constructs a second set of trees that correspond to (2) We use the GKT scheme’s leakage to mount an efficient the sequence of labels computed by the server when processing query recovery attack against the scheme. We explain how, each query i.e. the per-query leakage of the scheme. That leakage is for our real world datasets, the set of all query trees can be uniquely determined by the search token that initiates the look-up. recovered with as few as 68.1% of the queries. This description uses the labels of EDB (which are search tokens) as (3) We make use of the classical AHU algorithm for the graph vertices; two labels are connected if the first points to the second in isomorphism problem for rooted trees and develop a new al- EDB. When an entire tree has been constructed, then the adversary gorithm for deciding when a path in one tree can be mapped can run the AHU algorithm again to compute the canonical names onto a path in another under an isomorphism. Our support- associated with this query tree. An entire query tree can be built ing graph theoretic theorems may be of independent interest. when all queries to a particular destination have been issued. In (4) We evaluate our attack against real-world datasets and ran- practice, this is a realistic routing scenario where many trips may dom graphs. share a common popular destination (e.g. an airport, school, or (5) We motivate the need for detailed cryptanalysis of GESs. distribution center). By correctness of the scheme, there exists a collection of iso- 1.1 Prior and Related Work morphisms mapping to at least one tree computed in the offline We now describe prior and related work concerning graph encryp- phase. Such isomorphisms also map shortest paths to shortest paths. tion schemes and leakage abuse attacks on structured encryption. We thus perform a matching between the paths in the trees from the online phase to the trees in the offline phase. This can be done Graph Encryption. Chase and Kamara present the first graph efficiently using a modified AHU algorithm [1] that we develop encryption scheme that supports both adjacency queries and fo- and which decides when one path can be mapped to another by cused subgraph queries [7]. Poh et al. give a scheme for encrypting an isomorphism of trees. This yields two look-up tables which, conceptual graphs [23]. Meng et al. present three schemes that when composed, map each path in the first set of trees to a set of support approximate shortest path queries on encrypted graphs, candidate paths in the second set. We use the search token of the each with a slightly different leakage profile [19]. To reduce storage queries associated with to look up the possible candidate queries overhead, their solution leverages sketch-based oracles that select in the tables computed in the online phase, and output them. The seed vertices and store the exact shortest distance from all vertices runtime of this phase is ( ′ · 2 ) where ′ ≤ is the number of to the seeds; these distances are then used to estimate shortest complete query trees computed in the online phase. The output is paths between any two vertices in the graph. Ghosh et al. [12] and guaranteed to contain the correct query. Wang et al. [27] present schemes that supports exact shortest path In general, the leakage from a query can be consistent with queries on encrypted graphs. many candidates for that query, and the correct candidate cannot be Other solutions for privacy preserving graph structures use other uniquely determined. Graph theoretically, this is because there can techniques like secure multiparty computation and private informa- be many possible isomorphisms between pairs of trees in our two tion retrieval (e.g. [15, 28]) and differential privacy (e.g. [24]). These sets. If we consider the chosen graph setting, it is easy to construct approaches have different security goals from encrypted database a graph where, given any query tree of , its isomorphism is schemes that are built on symmetric encryption. uniquely determined and there is a unique candidate for each query Attacks. The leakage of graph encryption schemes was first an- of , i.e. we can achieve what we call full query recovery (FQR). alyzed by Goetschmann [13]. The author considers schemes that For such graphs, the GKT scheme offers almost no protection to support approximate shortest path queries that use sketch-based queries. In other cases, the query leakage may result in one or only a distance oracles (e.g. [19]), presents two methods for estimating few possible query candidates, which may be damaging in practice. distances between nodes, and gives a query recovery attack that In order to explore the effectiveness of our attack, we support it aims to recover the vertices in an encrypted query; the experimen- with experiments on 8 real-world graphs (6 of which were used tal evaluation demonstrates that with auxiliary knowledge on some in [12]) and on random graphs with varying graph sizes and edge queries, the adversary can distinguish among candidate vertices probabilities. Our results show that for the given real-world graphs, which vertex was queried. Our attack is also a query recovery attack, 2
An Efficient Query Recovery Attack Against a
Graph Encryption Scheme Conference ’22, June 2022, Nagasaki, Japan
but uses knowledge of the graph rather than partial knowledge The AHU Algorithm. In this paper, we use a modified AHU algo-
of some queries. rithm, which we denote as ComputeNames, to compute the canon-
ical names of rooted trees (and their subtrees) and determine if
2 PRELIMINARIES they are isomorphic. ComputeNames takes as input a rooted tree
= ( , , ), a vertex ∈ , and an empty dictionary Names. It out-
Notation. For some integer , let [ ] = {1, 2, . . . , }. We denote
puts the canonical name of the subtree [ ] (which we also refer to
concatenation of two strings and as || .
as the canonical name of ) and a dictionary Names that maps each
Graphs. A graph is a pair = ( , ) consisting of a vertex set descendent of to the canonical name of [ ]. The algorithm pro-
of size and an edge set of size . A graph is directed if the ceeds from the leaves to the root. It assigns the name ‘10’ to all leaves
edges specify a direction from one vertex to another. Two vertices of the tree. It then recursively visits each descendent of and
, ∈ are connected if there exists a path from to in . In assigns a name by sorting the names of its children in increasing
this paper, we assume that all graphs are connected for simplicity lexicographic order, concatenating them into an intermediate name
of presentation. However our attack and its constituent algorithms ℎ _ and assigning the name ‘1|| ℎ _ ||0’ to
directly apply to multi-component graphs too. (see Figure 1b for an example). The canonical name of , Name( ),
A tree is a connected, acyclic graph. A rooted tree = ( , , ) is the name assigned to the root by this algorithm. Pseudocode
is a tree in which one vertex has been designated the root. For for ComputeNames is given in Appendix A.
some rooted tree = ( , , ) and vertex ∈ we denote by [ ]
the subtree of induced by and all its descendants. 3 THE GKT GRAPH ENCRYPTION SCHEME
Given a graph = ( , ) and some vertex ∈ , we define In this section, we give an overview of the graph encryption scheme
a single-destination shortest path (SDSP) tree for to be a di- of Ghosh et al. [12] and describe its leakage.
rected spanning tree such that is a subgraph of , is the only
sink in , and each path from ∈ \ { } to in is a shortest 3.1 GKT Scheme Overview
path from to in . An example of an SDSP tree can be found in
The GKT scheme supports single pair shortest path (SPSP) queries.
Figure 1c.
The graphs may be directed or undirected, and the edges may be
We also define two binary options on graphs. Given two graphs
weighted or unweighted. An SPSP query on a graph = ( , )
= ( , ) and = ( ′, ′ ), the union of and is defined as
takes as input a pair of vertices ( , ) ∈ × , and outputs a path
∪ = ( ∪ ′, ∪ ′ ). Given a graph = ( , ) and a subgraph
, = ( , 1, . . . , ℓ , ) such that ( , 1 ), ( 1, 2 ), . . . , ( −1, ) ∈
= ( ′, ′ ) such that ′ ⊆ , ′ ⊆ , the graph subtraction of
. We require that this path is of minimal length in , i.e. there does
from is defined as \ = ( \ ′, \ ′ ).
not exist a sequence of edges ( , 1′ ), ( 1′ , 2′ ), . . . , ( ′−1′ , ) ∈
Dictionaries. A dictionary D is a map from some label space L such that ′ < .
to a value space V. If lab ↦→ val, then we write D[lab] = val. SPSP queries may be answered using a number of different data
Hash functions. A set of functions → [ ] is a universal structures. The GKT scheme makes use of the SP-matrix [8]. For a
hash function family if, for every distinct , ∈ the hash graph = ( , ), the SP-matrix is a | | × | | matrix defined as
function family satisfies the following constraint: follows. Entry [ , ] stores the second vertex along the shortest
path from vertex to ; if no such path exists, then it stores ⊥.
Pr [ℎ( ) = ℎ( )] ≤ 1/ .
ℎ← An SPSP query ( , ) is answered by computing [ , ] = to
obtain the next vertex along the path and then recursing on ( , )
2.1 Graph Isomorphisms until ⊥ is returned.
Our approach will make heavy use of graph isomorphisms and At a high level, the GKT scheme proceeds by computing an SP-
automorphisms. matrix for the query graph and then using this matrix to compute
a dictionary SPDX ′ . This dictionary is then encrypted using a dic-
Definition 2.1. An isomorphism of graphs 1 = ( 1, 1 ) and tionary encryption scheme (DES) such as [5, 7]. To ensure that
2 = ( 2, 2 ) is a bijection between vertex sets : 1 → 2 such the GKT scheme is non-interactive, the underlying DES must be
that for all , ∈ 1, ( , ) ∈ 1 if and only if ( ( ), ( )) ∈ 2 . If response-revealing. Since it is germane to our analysis, we provide
such an isomorphism exists, we write 1 2 . the syntax of a DES next.
Definition 2.2. An isomorphism of rooted trees 1 = ( 1, 1, 1 ) Definition 3.1. A dictionary encryption scheme (DES) is a tu-
and 2 = ( 2, 2, 2 ) is an isomorphism from 1 to 2 (as graphs) ple of four algorithms DES = (DES.Gen, DES.Encrypt, DES.Token,
such that ( 1 ) = 2 . DES.Get) with the following syntax:
• DES.Gen is probabilistic and takes as input a security pa-
2.2 Canonical Names rameter , and outputs a secret key sk.
A canonical name Name(·) is an encoding mapping graphs to • DES.Encrypt takes as input a key sk and dictionary D, and
bit-strings such that, for any two graphs and , Name( ) = outputs an encrypted dictionary ED.
Name( ) if and only if . For rooted trees Aho, Hopcraft, and • DES.Token takes as input a key sk and a label lab, and out-
Ullman (AHU) [1] describe an algorithm for computing a specific puts a search token tk.
canonical name in ( ) time. We refer to this as the canonical name • DES.Get takes as input a search token tk and an encrypted
and describe it next. dictionary ED, and returns a plaintext value val.
3Conference ’22, June 2022, Nagasaki, Japan Francesca Falzon and Kenneth G. Paterson
Correctness for a DES DES states that for all dictionaries D, for all also appear in the values in EDB that are revealed to the server at
keys sk output by DES.Gen and for pairs (lab, val) in D, executing query time, that is, in the entries (tk, ).
DES.Get on input tk = DES.Token(sk, lab) and dictionary ED = In turn, the query leakage reveals to the server the token used
DES.Encrypt(sk, D) results in output val. to initiate a search, as well as all the subsequent pairs (tk, ) that
Note that while the GKT scheme itself is response-hiding (i.e. are obtained by recursively processing such a query. Let us denote
the shortest path is not returned in plaintext to the client), the the sequence of search tokens associated with the processing of
underlying DES used in the scheme is response-revealing, that is, some (unknown) query for a shortest path of length as =
the values in its encrypted dictionary ED are revealed at query time. tk1 ∥tk2 ∥ . . . ∥tk +1 ∈ {0, 1}∗ . We refer to this string as the token
The response-revealing property of the DES is necessary to enable sequence of . Since the search tokens correspond to the sequence
the GKT scheme to operate in a non-interactive manner. of vertices in the queried path, there are as many tokens in the
Now we provide a detailed description of the GKT scheme. At sequence as there are vertices in the shortest path for the query.
setup, the client generates two secret keys: one for a symmetric Note that, by correctness of DES used in the construction of EDB,
encryption scheme SKE, and one for a dictionary encryption scheme no two distinct queries can result in the same token sequence (in
DES. It takes the input graph and computes the SP-matrix [ , ]. fact no two distinct queries can produce the same first token tk1 ,
It then computes a dictionary SPDX such that for each pair of since each such first token must be used to derive a unique label in
vertices ( , ) ∈ × , we set SPDX[( , )] = ( , ) if ≠ EDB identifying the beginning of a specific shortest path).
and in the SP-matrix we have [ , ] = for some vertex . Notice also that token sequences for different queries can be
The client then computes a second dictionary SPDX ′ as follows. overlapping; indeed since the tokens are computed by running
For each label-value pair (lab, val) in SPDX the following steps are DES.Token on inputs lab = ( , ) where is the final vertex of a
carried out. A search token tk is computed from val using algo- shortest path, two token sequences are overlapping if and only if
rithm DES.Token and a ciphertext is computed by encrypting val they correspond to queries (and shortest paths) having the same
using SKE.Encrypt. Then SPDX ′ [lab] is set to (tk, ). The resulting end vertex. Hence, given the query leakage of a set of queries, the
dictionary SPDX ′ is then encrypted using DES.Encrypt to produce adversary can compute all the token sequences and construct from
an output EDB, which is given to the server. them ′ ≤ directed trees, { } ∈ [ ′ ] , each tree having at most
Now the client can issue an SPSP query for a vertex pair ( , ) by vertices and a single root vertex. The vertices across all ′ trees
generating a search token tk for ( , ) and sending it to the server. are labelled with the search tokens in EDB and there is a directed
The server initializes an empty string resp and uses tk to search EDB edge from tk to tk ′ if and only if tk and tk ′ are adjacent in some
and obtain a response . If =⊥, then it returns resp. Otherwise, it token sequence. (Each tree has at most vertices because of our
parses as (tk ′, ), updates resp = resp|| and recurses on tk ′ until assumption about being connected.)
⊥ is reached on look-up. The server returns resp, a concatenation We call this set of trees the query trees. Each query tree cor-
of ciphertexts (or ⊥) to the client. The client then uses its secret key responds to the set of queries having the same end vertex. Each
to decrypt resp, obtaining a sequence of pairs val = ( , ) from tree has a single sink (root) that corresponds to a unique vertex
which the shortest path from to can be constructed. ∈ . The tree paths correspond to the shortest paths from vertices
Complexity. The GKT scheme’s setup takes time ( 3 ) and is ∈ \ { } to , such that and are connected in . We note that
dominated by the cost of computing the SP-matrix. Token gen- Ghosh et al. [12] also discuss these trees but they do not analyze
eration takes time (1) (assuming use of an efficient DES) and the theoretical limits of what can be inferred from them.
querying EDB takes time ( ) where is the maximum length of a We denote the leakage of the GKT scheme on a graph after
shortest path in . The server storage is ( 2 ). issuing a set of SPSP queries Q as L ( , Q). For a formal proof of
security that establishes the leakage profile of the GKT scheme
please refer to [12]. We stress that our attacks are based only on the
3.2 Leakage of the GKT Scheme leakage of the scheme, as established above, and not on breaking
the underlying cryptographic primitives of the scheme.
Ghosh et al. [12] provide a formal specification of their scheme’s
leakage. Informally, the setup leakage of their scheme is the number
of vertex pairs in that are connected by a path, while the query 3.3 Implications of Leakage
leakage consists of the query pattern (which pairs of queries are Suppose that all queries have been issued and that we have con-
equal), the path intersection pattern (the overlap between pairs of structed all query trees { } ∈ [ ] , each tree having vertices.
shortest paths seen in queries), and the lengths of the shortest paths We observe that there exists a one-to-one matching between the
arising in queries. See [12, Section 4.1] for more details. query trees { } ∈ [ ] and the SDSP trees { } ∈ of such that
Recall that in the GKT scheme, the server obtains EDB by en- each matched pair of trees is isomorphic. The reason is that the
crypting the underlying dictionary SPDX ′ , in which labels are of query trees are just differently labelled versions of the SDSP trees;
the form lab = ( , ) and values are of the form val = (tk, ), using in turn, this stems from the fact that paths in the query trees are in
a DES. Here tk is a search token obtained by running DES.Token 1-1 correspondence with the shortest paths in .
on a pair ( , ) and is obtained by running SKE.Encrypt also This now reveals the core of our query recovery attack, devel-
on ( , ). Since EDB is obtained by running DES on SPDX ′ , this oped in detail in Section 4 below. The server with access to first
means that the labels in EDB are derived from tokens obtained by computes all the SDSP trees offline. As queries are issued, it then
running DES.Token on inputs lab = ( , ). Moreover, these tokens constructs the query trees one path at a time. Once a complete query
4An Efficient Query Recovery Attack Against a
Graph Encryption Scheme Conference ’22, June 2022, Nagasaki, Japan
tree is computed (recall that each query tree must have vertices
since is connected) the server finds all possible isomorphisms
between and the SDSP trees. Then, for each token sequence in ,
it computes the set of paths in the SDSP trees to which that token
sequence can be mapped under the possible isomorphisms. This
set of paths yields the set of possible queries to which the token
sequence can correspond. This information is stored in a pair of
dictionaries, which can be used to look up the candidate queries.
To illustrate the core attack idea, Figure 1 depicts (1a) a graph
(a) Original graph .
, (1b) its SDSP tree for vertex 1 (with vertex labels and canonical
names), and (1c) the matching query tree (without vertex labels). 1 10 10 10 1100 0
It is then clear that the leakage from the unique shortest path of 1
length 2 in Figure (1c) can only be mapped to the corresponding 10 10
6 2
path with edges (4, 5), (5, 1) in Figure (1b) under isomorphisms, and
similarly the shortest path of length 1 that is a subpath of that path
of length 2 can only be mapped to path (5, 1). On the other hand, the
3 remaining paths of length 1 can be mapped under isomorphisms 5 3
to any of the length 1 paths (2, 1), (3, 1), or (6, 1) and so cannot be 1100 10
4
uniquely recovered.
10
Since the adversary only learns the query trees and token se- (b) SDSP tree for vertex 1. (c) The inferred leakage.
quences from the leakage, the degree of query recovery that can
be achieved based on that leakage is limited. In particular, without Figure 1: (a) Original graph , (b) its corresponding SDSP tree
auxiliary information, the adversary can only recover the candidate for vertex 1 in with the canonical names labeling all the
queries up to symmetries arising from the isomorphisms between vertices of the tree, and (c) the the matching query tree that
the query trees and the SDSP trees. In section 5, we show that in is leaked during setup (without any vertex labels).
practice this is often not an issue since many queries result in only
a very small number of candidate queries. assumption is reasonable as the adversary knows and many short-
est path algorithms are deterministic, including Floyd-Warshall [11]
and many of its adaptations.
4 QUERY RECOVERY
4.2 Formalising Query Recovery Attacks
4.1 Threat Model and Assumptions
Query recovery (QR) in general is the goal of determining the
We consider a passive, persistent, honest-but-curious adversary plaintext value of queries that have been issued by the client. The
that has compromised the server and can observe the initial search notion of query recovery was introduced by Islam et al. [14] in
token issued, all subsequent search tokens revealed during the query the context of leakage abuse attacks on SSE schemes and has been
processing, and the response. In particular, this adversary could extensively studied in the context of SSE and related schemes since.
be the server itself. In Appendix B we briefly outline a modified We study the problem of query recovery in the context of GESs,
version of our attack in which we assume that the adversary has specifically, the GKT scheme: given , the setup leakage of the
only compromised the communication channels between the client GKT scheme and the query leakage from a set of SPSP queries,
and server, and can thus only see the search tokens used to initiate our adversary’s goal is to match the leakage for each SPSP query
the recursive look-up and the server responses. with the corresponding start and end vertices ( , ) of a path in .
We assume that the adversary knows the graph that has been As noted above, there may be a number of candidate queries that
encrypted to create EDB. As noted previously, this is a strong as- can be assigned to the leakage from each query. We now formally
sumption, but fits within the security model used in [12] (where describe the adversary’s goals.
can even be chosen) and is realistic in many routing/navigation sce-
narios. We further assume that the adversary sees enough queries Definition 4.1. (Consistency) Let = ( , ) be a graph, Q =
to construct a subset of the query trees. We emphasize that com- { 1, . . . , } be the set of SPSP queries that are issued, and =
puting all trees does not require observing all possible queries; { 1, 2, . . . , } be the set of token sequences of the queries issued.
in the real world datasets we tested, we were able to construct An assignment : → × is a mapping from token sequences
all query trees with as few as 68.1% of the possible queries. This to SPSP queries. An assignment is said to be consistent with the
is because constructing a query tree that corresponds to only leakage L ( , Q) if it satisfies L ( , Q) = L ( , ( )).
requires observing the queries that start at the leaf nodes of and
Informally, consistency requires that, for each ∈ , the query
end at . In SDSP trees with few leaves, only a small fraction of
( ) specified by assignment could feasibly result in the observed
queries is needed.
leakage L ( , Q).
We assume that the all-pairs shortest path algorithm used in
constructing the SP-matrix from during setup is deterministic. Definition 4.2. (QR) Let = ( , ) be a graph, Q = { 1, . . . , }
We assume that this algorithm is known to the adversary. Such an be a set of SPSP queries, and the corresponding set of token
5Conference ’22, June 2022, Nagasaki, Japan Francesca Falzon and Kenneth G. Paterson
sequences. Let Π be the set of all assignments consistent with Proof. By assumption ( ) = and by definition of isomor-
L ( , Q). The adversary achieves query recovery (QR) when it phism of rooted trees we also have that ( ) = ′ . Since is a tree,
computes and outputs a mapping: ↦→ { ( ) : ∈ Π} for all ∈ . then we know that there exists a unique path between and , and
between and ′ . Isomorphisms of graphs must be edge preserving,
Informally, the adversary achieves query recovery if, for each
and so must map the subgraph , to , ′ . These two paths
∈ (a set of token sequences resulting from queries in Q), it
can only be isomorphic if they are the same length and thus = ℓ.
outputs a set of query candidates { ( ) : ∈ Π} containing every
Putting together these two facts we have that
query that is consistent with the leakage. Note that this implies that
the output always contains the correct query (and possibly more). ( ( ), ( 1 )) = ( , 1′ ), ( ( 1 ), ( 2 )) = ( 1′ , 2′ ),
This is the best the adversary can do, given the available leakage. . . . , ( ( ), ( )) = ( , ′ )
There is some information not conveyed in this mapping. In
which concludes the proof. □
particular, by fixing an assignment for a given token sequence,
we may fix or reduce the possible assignments for other query Given a rooted tree = ( , , ) and any ∈ , let PathName ( )
responses. We give such an example below. denote the concatenation of the canonical names of vertices along
Example 4.3. Suppose we observe the set of token sequences { : the path from to in , separated by semicolons:
∈ [5]} such that 1, 2, 3, 4 correspond to paths of length 1 and 5 PathName ( ) = Name( [ ])∥“; ”∥Name( [ 1 ]) ∥“; ”∥
corresponds to a path of length 2, with 4 a subsequence of 5 , and
. . . ∥“; ”∥Name( [ ])∥“; ”∥Name( [ ]). (1)
which allows us to construct the query tree in Figure 1c. Further sup-
pose that the resulting query tree is not isomorphic to any other query Computing path names will form the core of our QR attack.
tree, so we know that all queries in are rooted at 1. An adversary Before we explain how we use them, we prove a sequence of results
achieving QR must output the following mappings: about the relationship between path names and isomorphisms. In
Section 4.5 we explain how to apply a universal hash function to
{ 1 : {(6, 1), (3, 1), (2, 1)}, 2 : {(6, 1), (3, 1), (2, 1)},
the path names to compress their length from ( 2 ) to (log )
3 : {(6, 1), (3, 1), (2, 1)}, 4 : {(5, 1)}, 5 : {(4, 1)}}. bits, thereby reducing storage and run time complexity.
However, if the adversary could fix the assignment 1 to (1, 6) (for ex- Proposition 4.6. Let = ( , , ) and ′ = ( ′, ′, ′ ) be iso-
ample, by using auxiliary information) then 2 could only be mapped morphic rooted trees and let and ′ denote the set of children of
to either (1, 3) or (1, 2). and ′ , respectively. There is an isomorphism from to ′ if and only
We now define a special type of query recovery when there if there is a perfect matching from to ′ such that for each matched
exists only one assignment consistent with the query leakage, i.e. pair ∈ , ′ ∈ ′ , there exists an isomorphism : [ ] → [ ′ ].
all queries can be uniquely recovered. Proof. To see the forwards direction, let denote an isomor-
Definition 4.4. (FQR) Let = ( , ) be a graph, Q = { 1, . . . , } phism from to ′ and note that if ( ) = ′ for ∈ , then by
be a set of SPSP queries, and the corresponding set of token the edge-preservation property of isomorphisms, must map the
sequences. Let Π be the set of assignments consistent with L ( , Q). vertices of [ ] to the vertices of [ ′ ], and thus [ ] [ ′ ]. For
We say that the adversary achieves full query recovery (FQR) the backwards direction, we construct an isomorphism from to
when it (a) achieves QR, and (b) |Π| = 1. ′ . Let be the trivial isomorphism that takes to ′ and let
That is, there is a unique assignment of token sequences to = 1 ∪ 2 ∪ · · · ∪ ∪ .
queries consistent with the leakage. Whether FQR is always possible Let ( , ) ∈ . If ( , ) is an edge in [ ] for some ∈ then it is
(i.e. for every possible set of queries Q) depends on the graph . easy to see that by restricting to the vertices in [ ], we have
Specifically, we will see that FQR is always possible if and only if that ( ( ), ( )) is an edge in ′ [ ′ ] ⊆ ′ . If ( , ) = ( , ) for
each SDSP tree arising in is non-isomorphic and every path in some ∈ , then ( ( ), ( )) = ( ′, ′ ). Since ′ is a child of ′
each SDSP tree is fixed by all automorphisms of the tree. It is easy to then ( ( ), ( )) ∈ ′ . A similar argument holds for showing that
construct graphs for which these conditions hold (see Section 4.10). if ( , ) ∈ ′ , then ( −1 ( ), −1 ( )) ∈ . □
For such graphs, our QR attack always achieves FQR.
Lemma 4.7. Let = ( , , ) and ′ = ( ′, ′, ′ ) be isomorphic
4.3 Technical Results rooted trees. Let and be children of and ′ , respectively. Suppose
that is an isomorphism from [ ] to ′ [ ]. Then there exists an
We develop some technical results concerning isomorphisms of isomorphism from to ′ such that | [ ] = and ( ) = .
trees and the behaviour of paths under those isomorphisms that
Proof. Let and ′ denote the set of children of and ′ , re-
we will need in the remainder of the paper.
spectively. Since is an isomorphism and is edge preserving, then
For any rooted tree = ( , , ) and any ∈ , let [ ] ⊆
it must map to ′ and we necessarily have that = | | = | ′ |.
denote the subtree induced by and all its descendants in .
Lemma 4.5. Let = ( , , ) and ′ = ( ′, ′, ′ ) be rooted trees. We now use Proposition 4.6 to prove the lemma. Let ˆ be any
Let , = ( , 1, . . . , , ) and , ′ = ( , 1′ , . . . , ℓ′, ′ ) be paths isomorphism from to ′ . If ˆ maps to then we are done.
in and ′ , respectively. If there exists an isomorphism : → ′ Otherwise, ˆ ( ) = ′ ≠ and ˆ −1 ( ) = ≠ for some ′ ∈ ′
such that ( ) = , then = ℓ and ( ) = ′ for all ∈ [ ]. and ∈ . By Proposition 4.6 we have that [ ] ′ [ ′ ] and
6An Efficient Query Recovery Attack Against a
Graph Encryption Scheme Conference ’22, June 2022, Nagasaki, Japan
[ ] ′ [ ], and by assumption we also know that [ ] ′ [ ]. M that maps each path name arising in the to the set of
Thus, by transitivity, we conclude that [ ] ′ [ ′ ]. Let be the SPSP queries whose start vertices have the same path name.
vertices in \ ( [ ] ∪ [ ]) and let be an isomorphism from [ ] (1) Compute the query trees online. The trees are constructed
to ′ [ ′ ]. Then = ˆ | ∪ ∪ is a collection of isomorphisms from the token sequences as the queries are issued.
on all the trees rooted at the children of the roots. Thus is an (2) Process the query trees (Algorithm 3). Compute a dictio-
isomorphism from to ′ that maps to . □ nary D that maps each token sequence to the path name of
the start vertex of the path.
We now come to our main technical result:
Note that steps 0 and 2 are trivially parallelizable. In the case that
Theorem 4.8. Let = ( , , ) and ′ = ( ′, ′, ′ ) be rooted the APSP algorithm is randomized, the adversary can simply run
trees and let ∈ and ∈ ′ . There exists an isomorphism : → the attack multiple times to account for different shortest path trees.
′ mapping to if and only if PathName ( ) = PathName ′ ( ). In practice, the attack can output a single large table matching
token sequences to sets of queries. However, storing this large
Proof. The forwards direction follows from Lemma 4.5.
table will be more expensive than storing D and M when has
For the backwards direction, suppose that PathName ( ) =
high symmetry. Moreover, D can be indexed by the first token tk in
PathName ′ ( ). Since a path name includes the canonical name of
each token sequence (since tk uniquely determines the sequence).
the entire tree, we deduce that Name( [ ]) = Name( ′ [ ′ ]); it fol-
In the following subsections, we expand on each of the steps in
lows that ′ . Similarly we deduce that [ ] ′ [ ]. More gen-
the above overview.
erally, let , = ( , 1, . . . , −1, ) and , ′ = ( , 1′ , . . . , ′−1, ′ )
be paths in and ′ , respectively. Then for all ∈ [ − 1] we have
4.5 Computing the Path Names
that Name( [ ]) = Name( ′ [ ′ ]).
We now prove the result inductively on the vertices along the Before diving into our attack, we describe our algorithm for com-
path from to . For the base case, take any isomorphism 0 from puting path names which we use as a subroutine of our attack.
[ ] to ′ [ ] and note that this must necessarily map to . Algorithm 1 (ComputePathNames) takes as input a rooted tree
We can now extend this reasoning level-by-level upwards, at = ( , , ) and outputs a dictionary mapping each vertex ∈
each stage using the equalities of components of the two path names to its path name. First, we call Algorithm 4 (ComputeNames) on
to extend the isomorphism. Suppose that for ≤ − 1 there exists tree , its root , and an empty dictionary Names, and obtain a
an isomorphism from [ ] to ′ [ ′ ] such that ( ) = . By dictionary Names that maps each vertex ∈ to the canonical
equality of path names we have that [ +1 ] ′ [ +1 ′ ]. Note name of subtree [ ].
We will use a function ℎ drawn from a universal hash function
also that and are children of +1 and +1 , respectively.
′ ′
family to compress the path names from ( 2 ) to (log ). We
Applying Lemma 4.7, we see that there exists an isomorphism +1
initialize an empty dictionary PathNames and set PathNames[ ] =
from [ +1 ] to ′ [ +1 ′ ] such that
+1 | [ ] = . Since
ℎ(Names[ ]). We then traverse in a depth first search manner;
is a vertex in [ ], it follows that +1 ( ) = ( ) = . This
when a new vertex is discovered during the traversal, we set
completes the induction and with it the proof. □
PathNames[ ] to the hash of the concatenation of the name of
Theorem 4.8 also gives us a method for identifying when there and the path name of its parent i.e.
exists only a single isomorphism between two rooted trees. Suppose PathNames[ ] = ℎ(Names[ ] ∥PathNames[ ]). (2)
that = ( , , ) and ′ = ( ′, ′, ′ ) are isomorphic rooted trees
When all vertices have been explored, PathNames is returned. The
and that every vertex ∈ has a distinct path name; then there
pseudocode for ComputePathNames can be found in Algorithm 1.
exists exactly one isomorphism from to ′ . Intuitively, a vertex
in can only be mapped to a vertex in ′ with the same path name. Theorem 4.10. Let = ( , , ) be a rooted tree and PathNames
So if path names are unique, then each vertex in can only be be the output of running Algorithm 1 on . Let be a universal hash
mapped to a single vertex in ′ , meaning there is only a single function family mapping {0, 1}∗ → {0, 1}6 log . Then for randomly
isomorphism available. The converse also holds: if there exists sampled ℎ ← the expected number of collisions in PathNames is
exactly one isomorphism from to ′ , then every vertex ∈ at most (1/ 3 ).
necessarily has a distinct path name. This observation will be useful
in characterizing when query reconstruction results in full query Proof. Let , ∈ be distinct and let ( , 1, . . . , , = +1 )
recovery. We summarise with: and ( , 1′ , . . . , ′ ′ , = ′ +1 ) be paths in . We thus have
Corollary 4.9. Let = ( , , ) and = ( ′, ′, ′ ) be isomor- PathNames[ ] = ℎ(Names[ ] ∥ℎ(Names[ 1 ] ∥ℎ(Names[ 2 ] ∥...)))
phic rooted trees. Every vertex ∈ has a unique path name in if and similarly for PathNames[ ]. For there to be a collision between
and only if there exists a single isomorphism from to ′ . their path names then either: (1) Names[ ] ∥PathNames[ 1 ] and
Names[ ] ∥PathNames[ 1′ ] collide or (2) for some ∈ [min{ , ′ }]
4.4 Overview of the Query Recovery Attack and , ′ ≤ − 2, we have that Names[ ] ∥PathNames[ +1 ]
Our QR attack takes as input the graph , a set of token sequences and Names[ ′ ] ∥PathNames[ +1 ′ ] collide. Recall that a canonical
corresponding to the set of issued queries, and comprises of the name is unique up to isomorphism of the rooted tree.
following steps: Let denote the event that the path names of and collide,
(0) Preprocess the graph offline (Algorithm 2). Compute the and let denote the event that the -th nested hash of ’s and
SDSP trees { } ∈ of graph . Then compute a multimap ’s path names collide. A collision on the path names occurs when
7Conference ’22, June 2022, Nagasaki, Japan Francesca Falzon and Kenneth G. Paterson
any of the at most pairs of nested hash values (used to compute Algorithm 1: ComputePathNames
the path names of and ) collide. By definition of universal hash Input: Rooted tree = ( , , ).
function we have E[ ] < 1/ 6 . Thus, by linearity of expectation,
Output: Dictionary PathNames.
min{ +1, ′ 1: // Compute the canonical name of [ ] for all ∈ .
Õ +1} 1
2: Initialize empty dictionaries Names and PathNames
E[ ] = E[ ] < 6 = 5 .
3: Initialize empty stack
=1
4: Names ← ComputeNames( , , Names)
Let denote the event of any collision of path names in . Then 5: ℎ ←
by linearity of expectation the expected number of collisions is 6:
7: // Concatenate the canonical names into path names.
ÕÕ 2 1 8: .push( )
E[ ] = E[ ] < 5 = 3 .
9: Mark as explored
□ 10: PathNames[ ] ← ℎ (Names[ ])
11:
Corollary 4.11. Let = ( , ) be a graph and let { } ∈ 12: while ≠ ∅ do
be the set of SDSP trees of . Let PathNames be the union of the 13: ← .pop( )
14: if is not explored then
outputs of running Algorithm 1 on each tree in { } ∈ . Let be a
15: Let be the parent of
universal hash function family mapping {0, 1}∗ → {0, 1}6 log . Then 16: PathNames[ ] = ℎ (Names[ ] ∥“; ” ∥PathNames[ ])
for randomly sampled ℎ ← the expected number of collisions in 17: Mark as explored
PathNames is at most (1/ ). 18: for children of do
19:
We note that to achieve a smaller probability of collision, one
.push( )
20: return PathNames
can choose a hash function family whose output length is log
where > 6. For simplicity we invoke the universal hash function
using SHA-256 truncated to 128 bits.
vertices have the same path name. We leverage Theorem 4.8 to
Lemma 4.12. Let = ( , , ) be a rooted tree on vertices and construct this map and describe the steps in detail below.
be a universal hash function family mapping {0, 1}∗ → {0, 1}6 log . We initialize an empty multimap M. For each ∈ we compute
Upon input of , Algorithm 1 returns a dictionary of size ( log ) PathNames by running Algorithm 1 (ComputePathNames) on .
mapping each ∈ to a hash of its path name in time ( 2 ). For each vertex in we compute ℎ_ ← PathNames[ ],
and check whether ℎ_ is a label in M. If yes, M[ ℎ_ ]
Proof. Correctness follows easily from Theorem 4.10 and by a ← M[ ℎ_ ]∪{( , )}. Otherwise M[ ℎ_ ] ← {( , )}.
recursive argument. The pseudocode for computing M can be found in Algorithm 2.
Calling ComputeNames (Algorithm 4) takes ( 2 ) time. Read-
ing the name of the root and assigning the hash of its name takes Lemma 4.13. Let = ( , ) be a graph on vertices. Upon input
at most time ( ). Every node is pushed onto the stack once, and of , Algorithm 2 returns a multimap of size ( 2 log ) mapping
thus the while loop on line 12 iterates times. Assigning a new each ∈ to its corresponding path name in time ( 3 ).
path name on line 16 takes time ( ) since Names[ ] is ( ) bits,
PathNames[ ] is (log ) bits, and computing the hash takes con- Proof. For each vertex ∈ we compute a dictionary mapping
stant time. Pushing the children of a given vertex onto the stack each vertex in to its respective path names. The correctness of
takes time ( ) for a total run time of ( 2 ). PathNames maps the path names follows from Lemma 4.12.
vertices to the hash of their path names. Each vertex and its hashed We now analyze the run time. Computing all-pairs shortest path
path name can be encoded with (log ) bits yielding a dictionary takes time ( 3 ). The for loop on line 5 iterates through vertices.
of size ( log ). □ For each vertex in , we run Algorithm 1 (ComputePathNames)
which takes ( 2 ) time and the inner for loop on line 9 takes ( )
time. Thus, the for loop on line 5 takes a total time of ( 3 ).
4.6 Preprocess the Graph The multimap maps hashes of the path names to a list of candi-
date queries. The hashed path names have size (log ) and there
We first preprocess the original graph = ( , ) into the SDSP are at most 2 distinct path names; each query corresponds to only
trees. Since the adversary is assumed to have knowledge of , this one path name and is (log ) bits long. The multimap thus has
step can be done offline. We use the same all-pairs shortest paths total size ( 2 log ). □
algorithm used at setup on to compute the SDSP trees { } ∈ ,
where tree is rooted at vertex . For unweighted, undirected
graphs, we can use breadth first search for a total run time of 4.7 Process the Search Tokens
( 2 + ) where = | |; For general weighted graphs this has We must now process the tokens revealed at query time. Recall that
step has a run time of ( 3 ) [11]. the tokens are revealed such that, the response to any shortest path
Next, we compute the path names of each vertex in { } ∈ , and query can be computed non-interactively. When a search token tk
then construct a multimap M that maps the (hashed) path name is sent to the server, the server recursively looks up each of the
of each vertex in { } ∈ to the set of SPSP queries whose start encrypted vertices along the path. The adversary can thus compute
8An Efficient Query Recovery Attack Against a
Graph Encryption Scheme Conference ’22, June 2022, Nagasaki, Japan
Algorithm 2: PreprocessGraph Algorithm 3: QueryMapping
Input: A graph . Input: A graph and a set of query trees { } ∈ [ ′ ] with ′ ≤ .
Output: A multimap M mapping path names to sets of SPSP queries. Output: A dictionary D mapping search tokens to path names, and a
1: // Compute the set of SDSP trees from . multimap M mapping path names to sets of SPSP queries.
2: Initialize an empty multimap M 1: Initialize empty dictionary
3: Compute { } ∈ by running all-pairs shortest path on 2: for ∈ [ ′ ] do
4: 3: // Compute the path names of each vertex in the query trees.
5: for ∈ do 4: PathNames ← ComputePathNames( )
6: // Compute the path names of each vertex. 5: D ← D ∪ PathNames
7: PathNames ← ComputePathNames( ) 6: return D
8: // Map path names to candidate queries.
9: for ( , ℎ_ ) in PathNames do
10: if ℎ_ is a label in M then Figure 2: An example graph
6 7 5
11: M[ ℎ_ ] ← M[ ℎ_ ] ∪ { ( , ) } for which FQR is always pos-
12: else sible, no matter what set of
13: M[ ℎ_ ] ← { ( , ) } 1 2 3 4 SPSP queries is issued.
14: return M
Let ( , ) be a pair comprised of a non-root vertex and a root
the query trees using the search tokens revealed at query time. First,
vertex in a complete query tree , and let be the token sequence
it initializes an empty graph .
corresponding to ( , ). Let ( ′, ′ ) ∈ M[D[ ]]. By composition of
As label-value pairs (lab, val) are revealed in EDB, the adversary
D and M we must have that PathName ( ) = PathName ′ ( ′ ).
parses tkcurr ← lab and (tknext, ) ← val, and adds (tkcurr, tknext )
Applying Theorem 4.8, there is thus an isomorphism from to ′
as a directed edge to . At any given time, will be a forest com-
that maps to ′ and to ′ .
prised of ′ ≤ trees, { } ∈ [ ′ ] , such that each has at most
We now analyze the run time. Preprocessing (Algorithm 2)
nodes. Identifying the individual trees in the forest can be done in
takes time ( 3 ). Computing the path names (Algorithm 1) of
time ( 2 ). The adversary can compute the query trees online and
′ ≤ trees takes ( 3 ) time, which gives us an upper bound on
the final step of the attack can be run on any set of complete query
the run time of the whole attack. □
trees. A complete query tree corresponds to the set of all queries to
some fixed destination vertex. For ease of explanation, we assume 4.9 Recover the Queries
Algorithm 3 (QueryMapping) takes as input the set of all complete
query trees that have been constructed from the leakage. Once the map between each node (token) in a query tree and its
corresponding path name has been computed, the attacker can use
4.8 Map the Token Sequences to SPSP Queries M and D to compute the candidate queries of all queries in the
complete query trees. Given M and D (outputs of Algorithms 2
In the last step, we take as input the set of complete query trees
and 3, respectively) and an observed token matching a query in
{ } ∈ [ ′ ] constructed from the leakage. We use the path names
the query trees for some unknown query, the adversary can find
of each vertex in the { } ∈ [ ′ ] , to construct a dictionary D that
the set of queries consistent with by simply computing M[D[ ]].
maps each token sequence to the path name of the starting vertex
of the corresponding path in its resspective query tree .
4.10 Full Query Recovery
We first initialize an empty dictionary D. For each complete query
tree , we compute PathNames ← ComputePathNames( ) and
We conclude this section with a discussion of when FQR is
take the union of PathNames and D. The pseudocode for computing
possible. By the correctness of our attack, this is the case for a
D can be found in Algorithm 3.
graph , a set of complete query trees { } ∈ [ ′ ] , and associated
Theorem 4.14. Let = ( , ) be a graph and EDB be an encryp- token sequences when for M ← PreprocessGraph( ), D ←
tion of using the GKT scheme. Let { } ∈ [ ′ ] be the query trees QueryMapping( , { } ∈ ′ ) and all ∈ we have |M[D[ ]] | = 1.
constructed from the leakage of queries issued to EDB. Upon input of We can also phrase a condition for FQR feasibility in graph-
, Algorithm 2 returns a dictionary M mapping each path name to a theoretic terms. Recall Corollary 4.9, which states that given two
set of SPSP queries in time ( 3 ). Upon input of and { } ∈ [ ′ ] , isomorphic rooted trees and ′ , if each vertex in has a unique
Algorithm 3 returns a dictionary D mapping token sequences to path path name, then there exists only one isomorphism from to ′ .
names in time ( 3 ). Moreover, the outputs D and M have the prop- We deduce that FQR is always achievable for any set of complete
erty that, for any token sequence corresponding to a path ( , ) in query trees, when all 2 vertices in the SDSP trees have unique
a query tree and for every query ( ′, ′ ) ∈ M[D[ ]], there exists an path names. Formally, we have the following:
isomorphism from to ′ such that ( ) = ′ and ( ) = ′ .
Corollary 4.15. Let = ( , ) be a graph and let { } ∈ be
Proof. The correctness of { } ∈ [ ] follows from the correct-
Ð
the set of SDSP trees of . Suppose every vertex in ∈ has a
ness of the GKT scheme. Dictionary D contains a map of each vertex unique path name (and in particular, each ∈ { } ∈ has a unique
in ∪ ∈ [ ] to its path name. The correctness of M and D follows canonical name). Then FQR can always be achieved on any complete
from Lemmas 4.13 and 4.12, respectively. query tree(s). The converse is also true.
9Conference ’22, June 2022, Nagasaki, Japan Francesca Falzon and Kenneth G. Paterson
By correctness, our attack achieves FQR whenever it is possible. random and the end vertex was chosen with probability linearly
In Figure 4.10, we show an example graph for which FQR is proportional to its out degree in the original graph. This simulates
always possible. Indeed, each tree { } ∈ [7] has a unique canonical a more realistic setting in which certain “highly connected” des-
name, and for all ∈ [7], each vertex in has a unique path tinations are chosen with higher frequency. The results of these
name. More generally, let G be the family of graphs having one experiments can be found in Table 2. Queries can be reconstructed
central vertex and any number of paths all of distinct lengths with just 75% of the queries. In fact, with high probability, we start
appended to . It is easy to see that our attack achieves FQR for all seeing complete query trees with as few as 20% of the queries for
graphs ∈ G. the facebook-combined dataset.
For the remaining datasets we ran simulations to demonstrate
5 EXPERIMENTS the success that an adversary could achieve given 100% of the
We support our theoretical results with experiments on both real queries. Our simulations were carried out as follows. Given , the
world datasets and random graphs. SDSP trees and the path names for each vertex in these trees were
computed, and then a dictionary mapping each query in to the
5.1 Implementation Details set of candidate queries was constructed by identifying queries
We implemented our attacks in Python 3.7.6 and ran our experi- whose starting vertices have the same path name. The simulations
ments on a computing cluster with a 2 x 28 Core Intel Xeon Gold only used the plaintext graph and the results show the success
6258R 2.7GHz Processor (Turbo up to 4GHz / AVX512 Support), that an adversary would achieve in an end-to-end attack. We ran
and 384GB DDR4 2933MHz ECC Memory. To generate the leakage, simulations for the larger graphs since storing all possible responses
we implemented the GES from [12] and we used the same machine is very memory intensive; In practice, our attack can be run on
for the client and the server. The cryptographic primitives were larger datasets by writing the map out to a back-end key-value
implemented using the PyCryptodome library version 3.10.1 [10]; store. These results can be found in the bottom row of Table 2.
for symmetric encryption we used AES-CBC with a 16B key and In Table 1 we report the percent of uniquely recoverable queries
for collision resistant hash functions we used SHA-256. For the when the attack is run on the set of all query trees. Uniquely
DES, we implemeted Π from [5] and generated the tokens using recoverable queries are queries whose responses result in only
HMAC with SHA-256 truncated to 128 bits. The shortest paths of the one candidate. CA-GrQc had the smallest percentage of uniquely
graphs were computed using the single_source_shortest_path recoverable queries (0.145%) and the p2p-Gnutella04 had the largest
algorithm from the NetworkX library version 2.6.2 [9]. percentage (21.911%). The small percentage for CA-GrQc can be
To implement our attacks, we used used the same shortest path attributed to its high density ( = 0.995), where density is defined
algorithm from NetworkX as in our scheme implementation. We as = 2 /( · ( − 1)). The CA-GrQc graph is nearly complete, and
also used our own implementation of the AHU algorithm (Algo- its SDSP trees display a high degree of symmetry. In fact, many of
rithm 4) to compute canonical names. As mentioned previously, the query trees are isomorphic to the majority of SDSP trees, and
the attack is highly parallelizable, and we exploited this property the majority of SDSP trees have a star shape. Each non-root vertex
when implementing our attack. in a star tree has the same path name, resulting in a large number
of possible candidates per token sequence.
5.2 Graph Datasets In Table 2, we plot the cumulative distribution functions (CDFs)
of our experiments. The four Gnutella data sets exhibit a high
We evaluate our attacks on 6 of the same data sets as [12]; in addition
recovery rate that can be explained by asymmetry and low density.
we use the InternetRouting dataset from the University of Oregon
50% percent of all queries for the p2p-Gnutella08, p2p-Gnutella04,
Route Views Project collected on January 2, 2000 and the facebook-
p2p-Gnutella25, p2p-Gnutella30 data sets result in at most 4, 3, 5, 5
combined dataset. All 8 of these datasets were obtained from [16].
candidate query values, respectively. Details of the 50th, 90th, and
The InternetRouting and CA-GrQc datasets were extracted from
99th percentiles can be found in Table 1. Histograms of the results
the original datasets using the dense subset extraction algorithm
can be found in Appendix C.
by Charikar [6] as implemented by Ambavi et al. [3]. Details about
these datasets can be found in Table 1. Random graphs. We also deployed our attack on random graphs,
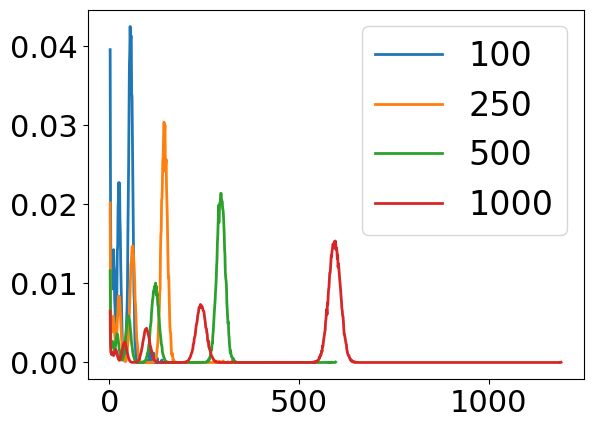
In addition to real world datasets, we deployed our attacks varying the number of nodes ( = 100, 250, 500, 1000) and the edge
on random graphs for = 100, 250, 500, 1000 and edge probabil- probability ( = 0.2, 0.4, 0.6, 0.8). Query recovery was carried out af-
ities = 0.2, 0.4, 0.6, 0.8. The graphs were generated using the ter all possible queries had been issued. For each ( , ) pair we gen-
fast_gnp_random_graph function from NetworkX [9]. erated 50 random graphs, encrypted the graphs using the scheme,
generated the leakage for all possible SPSP queries, and deployed
5.3 Query Reconstruction Results our query recovery attack on the responses. Then for each recov-
ered multimap, mapping the response to the set of candidate queries,
Real world datasets. We carried out our attack on the Internet we computed the average number of queries that had each possible
Routing, CA-GrQc, email-EU-Core, facebook-combined, and p2p- number of candidate queries across all 50 graphs. The CDFs of these
Gnutella08 datasets; The online portion of the attack (Algorithm 3) results can be found in Table 3.
given all queries ran in 0.087s, 0.093s, 5.807s, 102.670s, and 339.957s In general, we see that an increase in and both result in
for each dataset, respectively. For the first four datasets, we also an increase in the size of the maximum query candidate sets. For
ran attacks given 75% and 90% of the queries averaged over 10 runs example, for = 100, = 0.2 we have that 6.3% of all queries are
and sampled as follows: The start vertex was chosen uniformly at
10You can also read

















































