What we Learned About the Data Science Life Cycle: Best Practices and Open Research Challenges - Andreas Ruckstuhl and Kurt Stockinger Zurich ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
What we Learned About the Data Science Life Cycle:
Best Practices and Open Research Challenges
Andreas Ruckstuhl and Kurt Stockinger
Zurich University of Applied Sciences
Swiss Data Science Conference 2021
June 9, 2021
1
ZHAW Datalab: Est. 2013
Forerunner:
• One of the first interdisciplinary data science initiatives in Europe
• One of the first interdisciplinary labs at ZHAW
Foundation:
• People: ca. 130 researchers from 11 institutes and centers across 4 departments
• Vision: Nationally leading and internationally recognized center of excellence
• Mission: Generate projects through critical mass and mutual relationships
• Competency: Data product design with structured and unstructured data
Success factors:
• Lean organization and operation à geared towards projects
• Years of successful pre-Datalab collaboration
• Founders of Swiss Data Science Conference in 2014
2
Brief History of Data Analysis Phases
Daniel & Wood (1971) CRISP-DM (2000) Team Data Science Process
Life Cycle, Mircosoft (2017)
3
Characteristics of Data Analysis Phases
• From the beginning it was clear that the phases interact
• Central is the understanding of these phases as an iterative process
• They are passed through several times
• The knowledge gained up to that point is incorporated at each iteration step.
• There is also a mutual influence between the business goal and the deployment.
• How to go through the four phases depends on
• the (business) objective of the project,
• the reality in the data (access, quality, ...),
• the modeling approaches, and
• what is needed for the deployment
4
Analytics as another Driver for Data Quality
and Business Understanding
Accident insurance claims
• When analyzing/modeling the data, it has been detected that
• the definition of claim amount changed a few years ago and now includes
administrative costs as well
à Data quality issue
à This change is not recorded in the data warehouse
à Definition of “claim amount” must be unified
• a certain business process was not implemented as intended
à Data quality problems in some variables
• This resulted in the (business) process being adjusted, …
… but some of the variables no longer had the same content as before
• "stationarity" break
Use your data and you improve its quality 5
Dynamic Business Processes Require
Adaptive Design
• Business understanding includes knowledge of business processes
• If your Data Science products are based on your own business processes, be
aware that business processes are subject to constant changes
(Continuous Process Improvement)
• Data acquisition might change:
• Dynamic warehouse vs. dynamic data marts for modelling
• Data input into models might change:
• Which data can be used for modelling?
• We need a kind of “stationarity”, i.e. the relationships must hold in future
Continuous process improvement is a major challenge for data science
7
Vision: Talking To Data Like to Humans -
Across the Entire Data Science Lifecycle
• Current data access modes are typically built for experts and require a steep
learning curve:
• Understanding of the data and the structure of data (data models)
• The data interfaces (relational database, graph database, text documents, ...)
• Using machine learning technology (machine learning models)
• Need to talk to data like to a human to understand data and our business better
• The "intelligent" system needs to talk back when it does not understand the
human
8
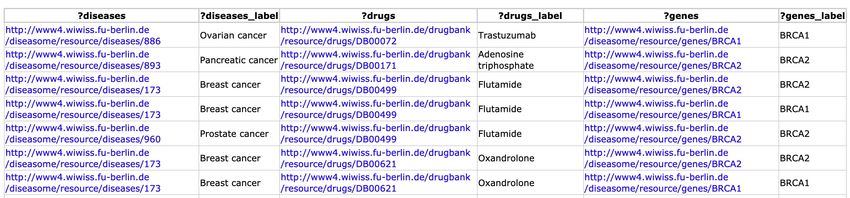
The Current Way of Querying Graph Databases
Assume that we have a graph database about drugs and diseases
A typical question could be:
• What are the drugs for diseases associated with the brca1 genes?
• Answering the question would require the following SPARQL2 query:
1brca refers to breast cancer
2SPARQL = SPARQL Protocol and RDF Query Language for graph databases
9
The Bio-SODA Way of Querying Graph Databases
Question
Answer
1
QALD-4: Benchmark for Question Answering over Linked Data
10
07.06.21
Natural Language Interfaces to Data:
Building Data Systems with Academia and Industry
• SODA – Search Over Data Warehouse:
• ("Future ZHAW employee" + Credit Suisse + ETH Zurich)
• Accessing business data warehouses in natural language
• Bio-SODA:
• (ZHAW + Swiss Institute of Bioinformatics)
• Accessing bioinformatics databases in natural language
• NQuest - Natural Language Query Exploration System:
• (ZHAW + Zurich Startup Veezoo)
• Accessing databases and (partially) machine learning in natural language
• INODE – Intelligent Open Data Exploration System
• (ZHAW + 8 partners in Europe)
• Exploring structured and unstructured data in natural language
Note: References are given after the conclusions
11INODE – Intelligent Open Data Exploration
http://www.inode-project.eu/
• Users should interact with data in a more
dialectic and intuitive way similar to a dialog with a
human
• Services for exploration of open data sets that help
users:
• Link and leverage multiple datasets
• Access and search data using natural language,
using examples and using analytics
• Get guidance from the system in understanding the
data and formulating the right queries
• Explore data and discover new insights through
visualizations
12Artificial Intelligence vs. Human Non-Intelligence?
• Building intelligent systems is not only fun but also enables access to data for a
wide range of (non)-technical users
• We understand data faster and can also use it faster to generate business value
• However, how well do we understand the complex processes/answers really?
• AI provides "answer to everything"
• Does AI also explain how the results are achieved?
• Do humans understand the answer or do we simply accept them?
• If all access to data is simplified via AI, do we end up with superficial
knowledge (non-intelligent human)?
13Conclusions
• The data analysis phases interact heavily …
and their interaction structure depends on the task
• Analytics is another driver for data quality and business
understanding
• Continuous process improvement is a major challenge for
data science
• Data science skills and technology needs to be applied
intelligently and holistically across the entire data science
lifecycle.
14References
• Amer-Yahia, S., Koutrika, G., Bastian, F., Belmpas, T., Braschler, M., Brunner, U., ... & Stockinger, K.
(2021). INODE: Building an End-to-End Data Exploration System in Practice [Extended Vision]. arXiv
preprint arXiv:2104.04194.
• Sima, A. C., de Farias, T. M., Anisimova, M., Dessimoz, C., Robinson-Rechavi, M., Zbinden, E., &
Stockinger, K. (2021). Bio-SODA: Enabling Natural Language Question Answering over Knowledge
Graphs without Training Data. Scientific and Statistical Database Management Systems
(SSDBM), Tampa, Florida, USA, July 2021
• Brunner, U., & Stockinger, K. (2021). ValueNet: a natural language-to-SQL system that learns from
database information. In International Conference on Data Engineering (ICDE), Chania, Greece, April
2021.
• Liang, S., Stockinger, K., de Farias, T. M., Anisimova, M., & Gil, M. (2021). Querying knowledge graphs
in natural language. Journal of Big Data, 8(1), 1-23.
• Affolter, K., Stockinger, K., & Bernstein, A. (2019). A comparative survey of recent natural language
interfaces for databases. The VLDB Journal, 28(5), 793-819.
• Blunschi, L., Jossen, C., Kossmann, D., Mori, M., & Stockinger, K. (2012). SODA: Generating SQL for
business users. Proceedings of the VLDB Endowment, 5(10), 932-943.
15You can also read

















































