Volumetrics - Measuring Free Volumes
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Volumetrics - Measuring Free Volumes
André Neves de Almeida Roque Carreira
Thesis to obtain the Master of Science Degree in
Electrical and Computer Engineering
Examination Committee
Chairperson: Professor João Fernando Cardoso Silva Sequeira
Supervisor: Professor José António da Cruz Pinto Gaspar
Member of committee: Professor Paulo Jorge Coelho Ramalho Oliveira
October 2013

This dissertation was performed under the supervision of:
Professor José António da Cruz Pinto Gaspar
Professor Rodrigo Martins de Matos Ventura

Acknowledgements Ao Professor José António da Cruz Pinto Gaspar, pela sua valiosa ajuda e disponibilidade no decorrer deste trabalho. Aos meus pais, pelo incentivo, apoio e paciência durante esta e todas as outras fases, a eles dedico este trabalho. Aos meus avós, tios e primas, um enorme obrigado pela força que me dão. À Jovana, um agradecimento especial por todo o carinho, suporte e cumplicidade. À Marta, Zé e Miguel, amigos que o provaram ser.
ii

Resumo
Novas aplicações surgem à medida que novas tecnologias 3D, mais baratas e precisas, se tornam
acessı́veis no mercado. A camara Kinect da Microsoft, lançada recentemente, baseada no sensor
Prime Sense é um excelente exemplo destas tecnologias de análise 3D. Embora tenha sido
desenhada para um mercado de videojogos, com ela é possı́vel desenvolver com sucesso várias
aplicações industriais com boa relação qualidade-preço.
O objectivo deste trabalho é a criação de duas aplicações industriais, usando esta tecnolo-
gia para (i) Verificação de caixas vazias e (ii) Estimação de volume livre. Mais precisamente,
a aplicação (i) engloba um sistema que detecta se contentores que passam num tapete rolante
têm algum tipo de resı́duo. A aplicação (ii) tem como objectivo permitir a determinação au-
tomática do volume desperdiçado, durante o carregamento dos contentores de camião. As duas
aplicações têm em comum a estimação da pose do contentor e a procedente análise do seu vol-
ume livre. Abordamos a estimação da pose com base no registo de uma nuvem de pontos 3D
com um modelo 3D representado também como um colector de pontos. A metodologia de reg-
isto é baseada no algoritmo Iterated Closest Point. A fiabilidade da aplicação (i) é estudada com
base numa lista de testes. A precisão e incerteza associada à aplicação de estimação de volume
livre também é estudada. Testes foram desenvolvidos para ambas as aplicações, envolvendo
informação real e simulada.
Palavras chave: Camara de análise 3D, estimação de pose 3D ,estimação de volume.
iv

Abstract
Novel applications emerge as new, more precise and lesser expensive technologies of 3D scan-
ning are becoming available in the market. The recently launched Microsoft-Kinect camera,
based on the Prime Sense sensor, is an excellent example of such a 3D scanning technology.
Despite having been designed for the computer games market, it can launch a number of suc-
cessful, cost-effective and industrial applications.
The information provided by these depth cameras is commonly fused with well known tools,
like the Iterative Closest Point (ICP) algorithm and volumetric computational algorithms. The
objective of this work is therefore the application of these tools in the creation of two industrial
applications (systems), using geometric information in order to speed up their computation and
increase their precision.
The first application encompasses the development of a system that detects if the containers
transported by a conveyor belt have some kind of residues. Normal information is used in
this application for increasing computational time of the box identification step while image
processing tools will adjudge its classification. In the second application, an automatic free
volume estimator, normal information will be used in order to increase the system’s precision
as it will regulate the point matching step. A volume computational algorithm will be used and
its precision will be analysed. The reliability of the applications will be studied based on a set
of carried out experiments involving simulated and real data. Experiments have been carried
out involving simulated and real data within both applications.
Keywords: Color-depth camera, 3D pose estimation, 3D volume estimation.
vi
Contents
Acknowledgments i
Resumo iii
Abstract v
1 Introduction 1
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Problem Formulation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Dissertation Outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.5 Acknowledgments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Color-depth Cameras 7
2.1 The Camera Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 From a World Coordinate System . . . . . . . . . . . . . . . . . . . . 10
2.1.2 From Meters to Pixels . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2 Depth Image to Point Cloud . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3 Getting the Point Cloud of Interest 17
3.1 Preprocessing the Depth Image . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2 Obtaining the Point Cloud . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3 Computing the Normal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.3.1 Fast Sampling Plane Filter Algorithm . . . . . . . . . . . . . . . . . . 20
3.3.2 Sampling Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3.3 Partial Derivatives Method . . . . . . . . . . . . . . . . . . . . . . . . 25
3.4 Filtering the Point Cloud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25viii CONTENTS
4 Finding Boxes in Point Clouds 27
4.1 Overview of the ICP Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.2 Stages of the ICP Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.2.1 Point Selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.2.2 Point Matching . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2.3 Computing the Rigid Transformation . . . . . . . . . . . . . . . . . . 32
5 Application 1: Testing Empty Boxes 37
5.1 Detailed Steps of the Empty Boxes Verification Process . . . . . . . . . . . . . 38
5.1.1 3D Box Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.1.2 On-line Localization of Boxes . . . . . . . . . . . . . . . . . . . . . . 39
5.1.3 On-line Empty Box Verification . . . . . . . . . . . . . . . . . . . . . 41
5.2 Error and Performance Analysis . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.2.1 ROC Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.2.2 Results Given the Selected Thresholds . . . . . . . . . . . . . . . . . . 45
5.2.3 Computational Time . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
6 Application2: Computing Volumes 47
6.1 Total Volume as a Sum of Pyramids . . . . . . . . . . . . . . . . . . . . . . . 49
6.2 Error Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
6.2.1 Dataset Reliability . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
6.2.2 Precision of the Volume Computation Algorithm . . . . . . . . . . . . 53
6.2.3 Resolution of the Kinect Depth Data . . . . . . . . . . . . . . . . . . . 53
6.2.4 Precision of the Depth Measures . . . . . . . . . . . . . . . . . . . . . 55
7 Conclusion and Future Work 59List of Figures
1.1 Kinect scheme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Environment of application 1 (left) and concept of application 2 (right). . . . . 3
2.1 Thin lens model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Pinhole model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 The camera plane considered in the pinhole model . . . . . . . . . . . . . . . . 9
2.4 Relation between world coordinate system and the camera coordinate system . 11
2.5 3D point clouds arranged as image planes. Each image plane contains X, Y or
Z values. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.1 Data retrieved from Kinect sensor . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 The Filling algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3 3D point cloud stored in three images. . . . . . . . . . . . . . . . . . . . . . . 19
3.4 FSPF search window . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.5 Normal matrices returned by the FSPF Algorithm . . . . . . . . . . . . . . . . 24
3.6 Normal matrices returned by the Sampling Algorithm . . . . . . . . . . . . . . 24
3.7 Normal matrices returned by the partial derivative method . . . . . . . . . . . 25
3.8 Examples of planes with normal components of interest. . . . . . . . . . . . . 26
3.9 Points of interest (in white) computed using the presented algorithms . . . . . . 26
4.1 ICP algorithm I/O scheme . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.2 ICP main steps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.3 Minimizing the error . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.4 Point-to-plane error between two surfaces . . . . . . . . . . . . . . . . . . . . 35
5.1 Application main steps. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.2 Environment where the application is to be implemented (a), example of an
RGB image as seen from the sensor position (b) and captured model (c). . . . . 38x LIST OF FIGURES
5.3 Pruning the background to make clearer the foreground region (box). . . . . . 39
5.4 Box considered undetected as the number of points do no meet the minimum. . 40
5.5 Box localization considered not found as the ICP error is above a threshold. . . 40
5.6 Box considered detected and well localized with ICP. . . . . . . . . . . . . . . 41
5.7 Box bottom face identification and detection of outlying pixels. (a) shows the
original RGB image and (b) shows the identified corners of the box. (c) shows
the cropped RGB image, input of the classification, (d) shows the hue values
accepted as valid for a box, (e) illustrates the hue intensity values and in (f) the
points with values not comprehended between the admitted interval are shown
in white. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.8 Summary of application 1, empty boxes verification. . . . . . . . . . . . . . . 43
5.9 ROC analysis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.10 Influence of the external light in the classification of pixels used to infer empty
vs not-empty box. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
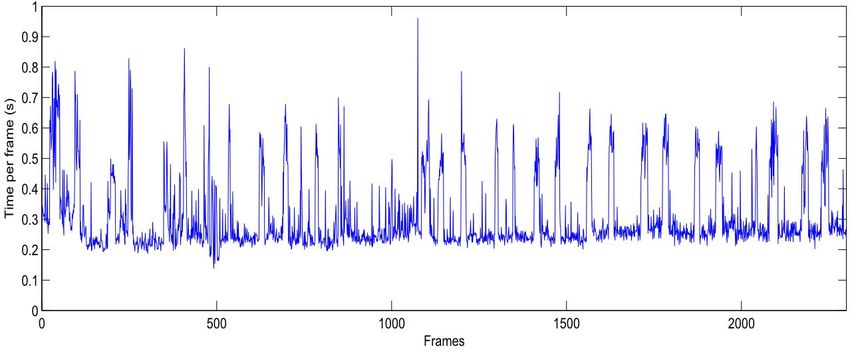
5.11 Computational time of frame classification. . . . . . . . . . . . . . . . . . . . 46
6.1 Input (a) RGB image and (b) depth image . . . . . . . . . . . . . . . . . . . . 47
6.2 Points of interest (black) vs points to exclude (white). . . . . . . . . . . . . . . 48
6.3 Box/container model to image matching. (a) is the model of the sides of the
container. (b) shows in red the points identified as corresponding to the model. . 49
6.4 Computing the volume inside a box. (a) shows the volume of a single pyramid,
(b) illustrates their sum, (c) shows the final result after the subtraction of the
final volume. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
6.5 Experimental results of the volume computation system. . . . . . . . . . . . . 51
6.6 Lost information due to the gap between A and B . . . . . . . . . . . . . . . . 52
6.7 Computationally generated depth with box at (a) 50cm, (b) 80cm and (c) 1m . . 53
6.8 The progression of error in volume computation with the distance with and
without a perfect identification . . . . . . . . . . . . . . . . . . . . . . . . . . 54
6.9 Depth error due to resolution. An increase in resolution, from (a) to (b), de-
creases the error (blue highlight) imposed to depth by the pixel discretization. . 54
6.10 The effect of resolution on the computation error. Three camera resolutions
were considered 480 × 640 (blue), 960 × 1280 (green) and 1440 × 1920 (red). . 55
6.11 theoretical random error of the Kinect . . . . . . . . . . . . . . . . . . . . . . 56
6.12 Computational error using depth with noise. . . . . . . . . . . . . . . . . . . . 56
6.13 Computational error using depth with noise with different resolutions . . . . . 57List of Tables 3.1 Configuration parameters used for FSPF . . . . . . . . . . . . . . . . . . . . . 23 5.1 Empty vs non-empty classification applied to three sequences of images. . . . . 45
xii LIST OF TABLES
Chapter 1
Introduction
Real time 3D recognition has become one of the most important and promising fields of robotics.
Range images obtained from lasers and RGB-D cameras have growth in popularity and found
numerous applications in fields including medical imaging, object modeling and robotics (ob-
stacle avoidance, motion planning, mapping, etc.). One of the factors which led to this popular-
ity was the appearance in the market of the Microsoft Kinect.
The Microsoft Kinect (fig. 1.11 ) has completely changed the world of computer vision due
to its unprecedented low price and its resolution 480x640 of video and depth data captured up to
30 fps. It was initially intended for a natural interaction in a computer game environment. How-
ever, the Kinect came as a low accuracy alternative to the expensive laser scanners. The Kinect
has ever since attracted the attention of researchers and developers and used in indoor mapping,
surveillance, robot-navigation and forensics applications, where accuracy requirements are less
strict.
The Kinect depth sensor is a structured light 3D scanner. Its infrared light source projects
light patterns to the space ahead. The reflected light is then received by an infrared camera and
processed to extract geometric information about object surfaces as the distance to the camera
plane is computed.
The Kinect sensor captures depth and color images simultaneously at a frame rate of up
to 30 fps. By merging this information a colored point cloud can be computed, containing up
to 307200 points per frame. By registering the consecutive depth images, one can not only
obtain an increased point density, but also create in real time a complete point cloud of an
indoor environment. The analysis of the systematic and random errors of the data is indubitably
necessary to realize the full potential of the sensor for mapping and other applications.
1
Taken from Kinect for Windows Sensor Components and Specifications: http://msdn.microsoft.com/en-
us/library/jj131033.aspx2 Introduction
Figure 1.1: Kinect scheme
The work described within this dissertation focuses on the uses of depth sensors to correctly
detect and compute precise information relative to the free volume of known objects. Two
different volume-analyze systems using RGB-D information are here proposed for two unique
industrial applications and their results are analyzed.
1.1 Motivation
The application of RGB-D technology for industrial purposes is recent. Companies are moti-
vated and see this technology as a useful tool to control and support their information systems.
Two applications for this technology were purposed by two different companies:
Empty boxes verification: a system that verifies if a passing container is empty or partially
filled. These systems are commonly used in many industries as they are able to safely transport
materials from one level to another which, when done by human labor, would be strenuous and
expensive. RGB-D cameras can be used in order to study efficiently and autonomously the
properties of the passing objects.
This application addresses the design of an automatic, fast and efficient system to adjudge
if small containers moving in a conveyor system are empty.
Free volume computation: a system that allows a precise measurement of the free vol-
ume of a truck container. Transporting goods using trucks is ubiquitous. The traditional pack-
age sending by postal offices is nowadays widely spread among numerous cargo transporters.
Commonly, cargo transporters provide the trucks and rely on local warehouses to perform cargo
loading / unloading at their own loading docks. Cargo transporters are constantly seeking for
ways of optimizing their business by augmenting the transported volume per truck. Assessing
the empty volume of a truck container is therefore a key tool for business optimization. This ap-
plication addresses the design of an automatic free volume estimator applied to truck containers1.2 Related Work 3
using recent high resolution cameras or depth sensors. For purposes of testing, the Kinect will
be used in the first phase of the project.
Figure 1.2: Environment of application 1 (left) and concept of application 2 (right).
1.2 Related Work
In order to compute a colored cloud point, a previous calibration of the cameras is required
since there’s a physical distance between them. [2] provides Kinect calibration tools for a Mat-
lab environment. [7] provides an insight into the factors influencing the accuracy of the data is
provided and experimental results are shown, proving that the random error of depth measure-
ments increases with increasing distance to the sensor, and ranges from a few millimeters up to
about 4cm at the maximum range of the sensor. [10] proposes an algorithm for correcting gaps
created due to errors in scanning.
Due to the heavy sheer volume of data generated by depth cameras, processing this data in
real time has become a challenge. For this purpose, sampling methods are used in order to prune
the non-relevant data from the depth image. [16] introduces the Fast Sampling Plane Filtering
(FSPF), a method which samples points from the depth image, classifying local grouped set of
points as belonging to planes in 3D. Other sampling methods were used in this work in order
to filter points which belong to planes of interest. This sampling methods allow the use of
computationally expensive 3D localization and model recognition algorithms. The most known
of these algorithms, the Iterative closest point (ICP) algorithm is used in this work to compute
the location of known objects in the observable environment, allowing to explore their volume
properties thereafter [1], [3]. The ICP algorithm presented in the early 1990s has become the
most popular algorithm to infer the change in 6D pose of a camera and the rigid transformation
between two point clouds. It has been the target of intense research and many variants have
been developed [12], [8], [11], [13], [17]. Some variants of this algorithm are hereby explained
and compared in chapter 4.4 Introduction
1.3 Problem Formulation
Although being substantially different, the two applications studied and developed in our work
have a significantly common overlap in terms of the required algorithms. In both cases the depth
image provided by the RGB-D cameras is filtered for spurious data and the ICP algorithm is
then applied to the result in order to identify the position of an open container. Finally, after
having identified the position of the container, the volume properties are analyzed.
This thesis proposes a solution for both applications and analyzes the efficiency and preci-
sion of the used algorithms. The main steps of the work are therefore the following: (1) data
acquisition of depth maps;(2) filtering the non-relevant data; (3) 3D recognition of an open con-
tainer; (4) implementation of the empty box verification system (5) Precision analysis empty
box verification system (6) Implementation of the free volume estimator (7) Precision analysis
of the free volume estimator.
1.4 Dissertation Outline
In Chapter 1 we start by introducing the objective of this dissertation and by presenting a short
introduction of the state of the art on depth cameras. Next, in chapter 2, we proceed to present
the pinhole model as the model considered in this work. Here we describe the relation between
3D spatial coordinates of an object and its projection unto the screen coordinates. Chapter 3
describes the methods used to filter the point cloud in order to identify the points that are likely
to belong solely to the top, down, right and left side of the container. Here, the depth image
blank spaces are filled by applying a simple filling algorithm, the points with desirable normals
are identified and their 3D coordinates are obtained. Furthermore, after having pruning the
points of interest, in Chapter 4 we present an overview of the ICP algorithm as well as some
variations used to identify the container in the frame. Here it is described the first application,
which finds a container in space and adjudges if it is empty. An analysis of its performance
is here also presented. The algorithm used in order to compute the free volume is presented
in Chapter 5, as well as the experiment results and precision analysis. Chapter 6 summarizes
the work performed and highlights the main achievements in this work. Moreover, this chapter
proposes further work to extend the activities described in this document.1.5 Acknowledgments 5 1.5 Acknowledgments This work has been partially supported by the FCT project PEst-OE / EEI / LA0009 / 2013, and by the FCT project PTDC / EEACRO / 105413 / 2008 DCCAL.
6 Introduction
Chapter 2
Color-depth Cameras
Color-depth cameras, also know as RGB-D cameras, provide real-time color and depth data
which can be useful in many applications. The depth data is returned as a matrix whose en-
tries represent the distance between the image plane and the corresponding point in the 3D
environment.
There is a geometric relationship between the coordinates of a 3D point and its projection
onto the image. In this chapter this relation is explained with the pin hole model.
The projective matrix P describes the mathematical relationship between the coordinates
of a 3D point and its projection u, v onto the Depth image and it’s value d. In this chapter this
relation between 3D points and their respective projection is explained with the pin-hole camera
model.
2.1 The Camera Model
The light model dictates that the light rays, which diverge from any point at a limited distance
in space (xo , yo , zo ) and pass through the lens, will converge in a single point behind the lens,
(x1 , y1 , z1 ). The points (xo , yo , zo ) and (x1 , y1 , z1 ) are called conjugate pairs (fig. 2.1).
Although real cameras have a lens that focuses light and therefore are better approximated
by the thin lens camera model, throughout this work we will consider a pinhole camera model,
in which no lenses are used to focus light.
The pinhole camera model describes the mapping between the 3D coordinates of a feature
and the feature’s projection into the image plane of an ideal pinhole camera, where the camera’s
aperture is described as a single point (optical center) which every light ray goes through. This
model, even though disregarding effects like geometric distortions of real cameras, is a good8 Color-depth Cameras
Figure 2.1: Thin lens model
approximation to how the projection works.
Figure 2.2: Pinhole model
The relative size of projected objects depends on their distance to the focal point and the
overall size of the image depends on the focal distance, f, between the image plane and the
focal point. The resulting image is upside down, rotated 180◦ .
To simplify and avoid confusions, it is common in computer graphics to consider an image
plane that lies between the optical center and the 3D scene (see fig. 2.2). This way the result is
an unrotated image, which is what we expect from a camera. This virtual image plane is placed
so that it intersects the Z axis at f instead of at -f. This image plane is virtual and cannot be
implemented in practice, but provides a theoretical camera which is simpler to analyze than the2.1 The Camera Model 9
real one (fig. 2.3).
Figure 2.3: The camera plane considered in the pinhole model
Analyzing fig.2.3 by triangle symmetry we get the relations:
X x Y y
= and = (2.1)
Z f Z f
or {
x = fX Z
(2.2)
y = f YZ
A more practical characterization is:
x=fλ
X
y = f Yλ (2.3)
λ=Z
where λ denotes the distance of the point to the image plane. The new characterization of the
projection model can be expressed in the matrix form by:
C
λx f 0 0 X
λy = 0 f 0 Y (2.4)
λ 0 0 1 Z10 Color-depth Cameras
C C
X X
where C fC
Y = Y = M are the coordinates of the point in the camera coordinates
Z ZC
system expressed in Cartesian coordinates.
Generally, eq. 2.4 is used with homogeneous coordinates in order to simplify future trans-
formations: C
X
λx f 0 0 0
Y
λy = 0 f 0 0
Z
. (2.5)
λ 0 0 1 0
1
Despite having introduced λ to characterize the depth Z of a specific 3D point M =
[X Y Z]T , in the process of imaging M as a 2D point [x y]T , in fact λ can be any non-zero
value. Given [λx λy λ]T = [m1 m2 m3 ]T one has [x y]T = [m1 /m3 m2 /m3 ]T , showing that λ
is canceled in the divisions m1 /m3 and m2 /m3 . In other words, λ can be characterized as an
arbitrary (non-zero) scale factor.
Conceptually, thinking of λ as free value is convenient for example in a back-projection
operation. Given x, y and f , one can rewrite eq.2.4 as:
C
X x/f
Y = λ y/f (2.6)
Z 1
which shows that a 2D point [x y]T can be the image of infinite 3D points, a straight line passing
through the image center and the 3D point [x/f y/f 1]T .
2.1.1 From a World Coordinate System
In order to compute the coordinates of a point in the image not from its 3D coordinates in the
camera referential C, but in the world coordinates system W (fig. 2.4), when W ̸= C initially,
one needs to apply a 3D rigid transformation to the coordinates in the world referential:
M g
gC = R C gW + tf
C
WM W (2.7)2.1 The Camera Model 11
Figure 2.4: Relation between world coordinate system and the camera coordinate system
where Rg C fC g W refers
W and tW represent the rotation and translation between the referentials and M
to the 3D coordinates of the point expressed in the world coordinate system W , all expressed
in cartesian coordinates. As previously mentioned, due to its advantages which include simpler
and more symmetric formulas, by convention these transformations are expressed in homoge-
neous coordinates (see eq.2.8).
W
XC X
[ ] W
Y C C
tC Y
RW W
= (2.8)
ZC 0 1 Z W
1 1
where RW C
∈ R3×3 , tC
W ∈ R
3×1
and the 0 represents a zero matrix inR1×3 . By using eq. 2.5
and eq. 2.8 we obtain the relationship between 3D point (in world coordinates) of a feature of
an object and the coordinates of its projection into the image frame:
W
X
λx f 0 0 0 [ ] W
C C Y
λy = 0 f 0 0 RW tW
. (2.9)
0 1 ZW
λ 0 0 1 0
1
The image frame coordinates are here given in meters, the same unit used for the 3D coor-
dinates. We will now proceed to compute its coordinates in pixels.12 Color-depth Cameras
2.1.2 From Meters to Pixels
In order to compute the image plane projection in screen coordinates, some adjustments are
needed. Here the parameters, necessary to link the pixel coordinates of an image point with
the corresponding coordinates in the camera reference frame, do not depend on the camera’s
location, but on it’s own specifications, like Focal length, CCD dimensions and principal point.
The lens distortion will not be considered either since it cannot be included in the linear
camera model described by the intrinsic parameter matrix.
If the origin of the 2D image coordinate system does not coincide with where the Z axis
intersects the image plane (principal point), we need to translate the projection of the point P
to the desired origin. This translation will be defined by (u0 , v0 ).
Moreover, if the pixels are square, the resolution will be identical in both u and v directions
of the camera screen coordinates. However, for a more general case, we assume rectangular
pixels with resolution αu and αv pixels/meter in u and v direction respectively. Therefore, to
measure the point in pixels, its u and y coordinates will be multiplied by the scale factors αu
and αv . Thus:
{
u = αu x + u0
(2.10)
v = α v y + v0
Being the skew coefficient,γ, between the x and the y axis often 0, we will not consider it in
the model.Thus, Eq. 2.10 can be expressed in matrix form as:
u αu 0 u0 x
v = 0 αv v0 y . (2.11)
1 0 0 1 1
We can now update eq. 2.9 so that we obtain the projection equation from world coordinates
to the image screen coordinates:
W
X
u αu 0 u0 f 0 0 0 [ ] W
RW
C
tC Y
W
λ v = 0 α v v0 0 f 0 0 . (2.12)
0 1 Z
W
1 0 0 1 0 0 1 0
1
Considering the projective camera, the column which multiplies with and the line itself of
the rotation and translation matrix can be occluded to simplify the model itself. Hence the2.2 Depth Image to Point Cloud 13
projective Matrix P ∈ R3×4 is given by:
f αu 0 u0 0
[ ]
C C
P = 0 f αv v0 0 RW tW . (2.13)
0 0 1 0
We finally obtain [ ]
λm = K C C M . (2.14)
RW tW
[ ]
C
where the matrix K is the intrinsic matrix specific to every camera and RW tC
W is the
extrinsic camera which defines the location and orientation of the camera reference frame with
respect to the known world reference frame. This equation is often mentioned in it’s most
simplified form:
λm = P M . (2.15)
2.2 Depth Image to Point Cloud
Cameras project 3D points into the image plane. This transformation is not reversible unless
we have some additional information about the point location in space.
Depths cameras provide the depth value for every pixel. This depth information, along with
the camera intrinsics (horizontal field of view fh , vertical field of view fv , image width w and
height h in pixels) can be used to reconstruct a 3D point cloud.
Let the depth image of size w × h pixels provided by the camera be d, where d(u, v) is
the depth of a pixel at the location (u, v). We intend to find the corresponding 3D point p =
(px , py , pz ).
Using eq. 2.5 and eq. 2.11 we obtain the projective system which relates the pixel position
in the image frame with its position in the 3D coordinate system of the camera itself,
XC
u αu 0 u0 f 0 0 0
C
Y
λ v = 0 α v v0 0 f 0 0 . (2.16)
ZC
1 0 0 1 0 0 1 0
1
Let λ = d for one pixel (u, v). Hence:14 Color-depth Cameras
XC
du αu f 0 u0 0
Y C
dv = 0 αv f v0 0
Z
C
(2.17)
d 0 0 1 0
1
or
du = αu f X + u0 Z
du = αv f Y + v0 Z (2.18)
d=Z
Finally, we get:
du−u0 Z
X = αu f
Y = dv−v 0Z
(2.19)
αv f
Z=d
In order not to lose the relative projected spatial information between the 3D points, their
coordinates can be created in three different matrices, all with the same size as the depth frame
(scheme in fig. 2.5).
Z zij
Y yij
X
xij
Figure 2.5: 3D point clouds arranged as image planes. Each image plane contains X, Y or Z
values.
Concluding, each 3D point forming the point cloud, is associated to a pixel, and is recon-
structed using the depth value d(u, v):2.3 Summary 15
u−u0
X(u, v) = d(u, v) αu f
Y (u, v) = d(u, v) v−v 0
. (2.20)
αv f
Z(u, v) = d(u, v)
2.3 Summary
In this chapter we have described the so called RGB-D cameras. In essence we use a pin-hole
model to characterize the geometry of the camera.
The information available for each pixel is the most important difference between RGB and
RGB-D cameras. While in a RGB camera one has three components:
I⃗RGB (u, v) = (r(u, v), g(u, v), b(u, v)) (2.21)
for the RGB-D camera the number of components is four:
I⃗RGBD (u, v) = (r(u, v), g(u, v), b(u, v), d(u, v)) (2.22)
where r, g and b denote red, green and blue color components, and d denotes scene depth.
The fact that the RGB-D camera provides depth information, combined with the geometric
model of the camera (intrinsic parameters), allows obtaining point-clouds. In this case one has
that the image representation is:
I⃗RGBD (u, v) = (r(u, v), g(u, v), b(u, v), X(u, v), Y (u, v), Z(u, v)) (2.23)
where X, Y and Z are 3D coordinates of points.16 Color-depth Cameras
Chapter 3
Getting the Point Cloud of Interest
In this chapter we explain the means to obtain a filtered point cloud which contains the points
of interest which will be analyzed later in order to find the correct box position.
The output of the Ms Kinect camera consist of a RGB image and a matrix in which each
pixel value is the distance between the corresponding 3D point and the camera plane. Errors in
readings by the Ms Kinect cameras can be presented as areas of no information on the depth
image (as seen in fig. 3.1). These shadows are caused by the unsuccessful observation of the
projected pattern, either from its absorption or due to the point of view of the IR camera being
occluded. Moreover, the perpendicular angles of the objects boundaries can also result in noise.
RGB image Depth image
Figure 3.1: Data retrieved from Kinect sensor
An estimation of its lost information must be obtained in order to compute the volume.
A simple estimation method will be proposed based on the specific geometry of the problem.
Inpaiting algorithms for these shadows have been a subject of research,[10] provides a noise18 Getting the Point Cloud of Interest
filtering option founded on the work of A. Telea [14] which was designed for generic hole-
filling in colored images.
Afterwords, in order to apply recognition methods we need a point cloud of the area of
interest, thus such, in this chapter we explain how to obtain a point cloud from the depth matrix.
Finally, in order to find areas of interest, we filter the point cloud by normal properties. Three
methods are presented to this purpose.
3.1 Preprocessing the Depth Image
Structured light sensor’s measurements, such as the Microsoft Kinect’s, are affected by noise
due to multiple reflections, transparent objects or scattering in particular surfaces. One of the
most important noise effects on the accuracy of the Kinect depth maps is due to the presence of
regions for which the camera is not able to correctly estimate the depth. These gaps are mainly
originated from the presence of object occlusions and concave objects, but they can be found
also in homogeneous regions as they can be caused by several optical factors. Noise-related
issues have to be solved in order to improve the measurements accuracy and to broaden its
future applicability.
In our work the method used to estimate the information of blank spaces from the known
depth data, yet simple, produces good results with the specific geometry of the dataset involved.
This application was experimented on boxes with continuous slopes along their sides and
that do not contain highly irregular volumes.
For each set of points in the shadow, the length of both horizontal and vertical vectors which
contains no information, was computed. By choosing the direction in which the vector was
shorter, a linearly spaced vector would take its place taking into account the depth intensity of
both extremities and their size.
A scheme of the algorithm can be observed in fig 3.2: two vectors are considered to be used
to fill the information gap in the center, the green one will be the one which will be chosen
since it is the shorter one and presents a smaller lack of information. In (b) the resulted image
is shown after applying the filling algorithm to the raw image.
3.2 Obtaining the Point Cloud
In chapter 2 the perspective projection of a 3D point in space onto the image plane was described
under the pin-hole model. We use this model throughout the whole project. As noted, also in3.2 Obtaining the Point Cloud 19
(a) Scheme Output of the filling algorithm
Figure 3.2: The Filling algorithm
chapter 2, an RGB-D camera acquires depth information which can be converted to a 3D point
cloud. As the depth information is already organized to conform with the image pixels, we
maintain also for the point cloud the image format, and use three image planes to store the X,
Y and Z coordinates of the points of the point cloud (see section 2.2). An example of these 3D
matrices can be observed in fig. 3.3 (a), (b) and (c).
(a) X coordinates (b) Y coordinates (c) Z coordinates
Figure 3.3: 3D point cloud stored in three images.
At this point of our project, we have 3D point clouds where the gaps (from the point of view
of the camera) have been filled. From these point clouds we want to find objects, more precisely
boxes, using a robust and fast methodology. In particular we consider some priors associated to
boxes. An example of a prior is that the directions of the local normals to the planar surfaces of
the box can be clustered into a small set of directions.20 Getting the Point Cloud of Interest
3.3 Computing the Normal
Most computers cannot process the full 3D data acquired by a Kinect at a high enough frame
rate. A naive solution would be subsampling the 3D cloud although some information of the
scene can end up as being lost.
In order to apply the matching algorithm presented in the next chapter, the points that are
likely not to belong to the box’s sides are removed. This pruning takes into account their
expected geometric properties, namely, their normal vectors.
Considering that the box is in a stable position, where its sides are relatively vertical and its
upper and bottom are relatively horizontal, the normal vector of these sides will surely have a
big horizontal or vertical component, respectively.
In chapter 4, a matching algorithm will use the filtered 3D points and compare them with a
3D model of the box’s sides.
In this section three methods to obtain the 3D normal of the points captured by the depth
camera were considered and compared: The Fast Sampling Plane Filtering, a subsampling
method and a method which makes use of the partial derivatives of the X, Y and Z matrixes.
3.3.1 Fast Sampling Plane Filter Algorithm
In 1981 Martin A. Fischler and Robert C. Bolles [4] introduced RANSAC, an iterative method
to estimate parameters of a mathematical model from a set of data which contain outliers. In this
method, a set of the observable hypothetical inliers is initially selected. Secondly, a parametriza-
tion occurs and the viability of the estimated parameters is measured by the number of points in
the remaining data which obey to the conditions created by the new parameters (inliers). If the
number of inliers created by this model is sufficient, the model is reasonably good and it is now
re-estimated from all the previously found inliers. Finally, the model is evaluated by estimating
the error of the inliers relative to the model. This procedure is repeated a fixed number of times,
each time producing either a model which is rejected because too few points are classified as
inliers, or a refined model together with a corresponding error measure. In the latter case we
keep the refined model if its error is lower than the last saved model.
RANSAC is widely used in image processing as a method to find planes. In our work,
the initial set of observable data consists of only three points and a plane can be estimated as
described in the next paragraphs. [ ]
Considering the plane equation n1 x + n2 y + n3 z + d = 0 in which n = n1 n2 n3
corresponds to the normal vector of the plane and d is the distance to the origin, we can now3.3 Computing the Normal 21
rewrite it as a matrix equation:
MT n + d = 0 (3.1)
X1 ... Xk
where M = Y1 ... Yk ∈ R3×k corresponds to the matrix with the k points considered.
Z1 ... Zk
For this plane estimation only three points are required (kmin = 3). This can be transformed
into the homogeneous linear equation:
[ ]
[ ] nT
MT 1 =0 , (3.2)
d
which can now be solved by a singular value decomposition allowing the computation of the
normal vector n and d of the estimated plane using the chosen k points.
Taking into consideration the maximum distance, dmax , a point can be to the plane so it
can be considered an inlier, the total number of inliers can now be obtained. Generally, all the
remaining points have their distance to the hypothesis plane (the model) tested.
Eq. 3.3 can be used to compute each point’s distance to the plane.
|n1 xi + n2 yi + n3 zi + d|
D= √ . (3.3)
n21 + n22 + n23
If the number of inliers is larger than the pre-established threshold, it is then confirmed that the
model is true and a new plane is then computed taking into consideration all the inliers.
This method can turn out to be, however, a challenge to process in real time if no limitations
for the search window are established.
Having this problem in mind, M.Veloso and J.Biswas [16] proposed the Fast Sampling Plane
Filtering algorithm which performs a RANSAC based plane fitting on the 3D points while also
sampling random neighborhoods in the depth image and in each neighborhood.
In this algorithm three points, distanced by no more than η in the image frame, are randomly
selected and the search window for the inliers w × h varies accordingly to the mean of the dis-
tance of the chosen points to the camera plane (figure 3.4).
This method was used in order to find the boxes sides and its original algorithm is presented
below.
Due to the requirements of the application, the configuration parameters used differ from22 Getting the Point Cloud of Interest
Algorithm 1 Fast Sampling Plane Filtering
P ← {} ◃ Filtered points
R ← {} ◃ Normal to planes
O ← {} ◃ Outlier points
n←0 ◃ Number of plane filtered points
k←0 ◃ Number of neighborhoods sampled
while ( n < nmax ∧ k < km ax ) do
k ←k+1
do ← (rand(0, h − 1), rand(0, w − 1))
d1 ← d0 + (rand(−η, η), rand(−η, η))
d2 ← d0 + (rand(−η, η), rand(−η, η))
reconstruct p0 , p1 , p2 from d0 , d1 , d2
(p1 −p0 )×(p2 −p0 )
r = ∥(p 1 −p0 )×(p2 −p0 )∥
z̄ = p0z +p31z +p2z
w′ = w Sz̄ tan(fh )
h′ = h Sz̄ tan(fv )
[numInliers, P̂ , R̂] ← RAN SAC(d0 , w′ , h′ , l, ε)
if numI nliers > αin l then
add P̂ to P
add R̂ to R
numP oints ← numP oints + numInliers
else
add P̂ to O
end if
end while
Return P, R, O3.3 Computing the Normal 23
Figure 3.4: FSPF search window
Parameter value Description
kmax 350 Maximum number of neighborhoods to sample
l 80 (if w′ × h′ < 80 : l = w′ × h′ ) Number of local samples
η 30 Neighborhood for global samples (in pixels)
S 0.5m Plane size in world space for local samples
ϵ 0.01m Maximum plane offset error for inliers
αin 0.8 Minimum inlier fraction to accept local sample
Table 3.1: Configuration parameters used for FSPF
the ones used in [16]: the maximum total number of filtered points, nmax , was not considered
since, in order to assure a good matching, it is necessary to identify the maximum number pos-
sible of visible points of interest as possible. ϵ, the distance threshold for the identification of
inliers was decreased so as to obtain more precise results. α, the minimum inlier fraction for a
plane to be accepted, was increased with the purpose of decreasing the number of outliers. The
configuration parameters used can be observed in the table 3.1.
By definition, this algorithm will analyze windows and try to find planes in those regions,
as following the output will not show all the extensions of the real world planes, but it consists
only of portions of the real planes, the result of the fast plane algorithm.
The normal values n can be obtained through a singular value decomposition using eq. 3.2,
where M ∈ R3×k contains the 3D coordinates of all the k points in each plane found. These
normals are assigned to all the k points.
In figure 3.5 it can be seen the result of using the Fast Sampling Plane Filtering with the
configuration illustrated in table 3.1, for the 3D information originated from 3.2.24 Getting the Point Cloud of Interest
Normal vector coordinate X Normal vector coordinate Y Normal vector coordinate Z
Figure 3.5: Normal matrices returned by the FSPF Algorithm
3.3.2 Sampling Method
The method hereby used is similar to the one used to compute the plane with three points in the
FSPF chapter.
By selecting a group of k neighbor points of the dataset, we can compute the best fit for a
plane in these 3D points by solving eq. 3.2 through a singular value decomposition. The output
plan will be the best plan fit for the given points and their distance to the plan will be minimized.
Using the 3D information of a moving window of k points, the normal vector n to the plane
will be iteratively attributed to the used points. This way a rough estimate of the normal vector
of all the image points is obtained.
By attributing the same normal vector to all the selected points, instead of only to the cen-
tral point of the analyzed region, the error of the output increases. Nevertheless, this allows the
method to be faster. This error can be tolerated since the ICP algorithm, later presented, can
handle some errors in the input.
Normal vector coordinate X Normal vector coordinate Y Normal vector coordinate Z
Figure 3.6: Normal matrices returned by the Sampling Algorithm3.4 Filtering the Point Cloud 25
The output of this algorithm will therefore be three normal matrices containing the informa-
tion of the normal vector of each point in the frame (fig. 3.6). Small areas with the same normal
can be observed due to the performed sampling.
In order not to greatly increase the error and still manage to create a faster alternative to the
FSPF, the window of sampled points considered had no more than nine points.
3.3.3 Partial Derivatives Method
By computing the gradient of the Z matrix in two orthogonal directions, the resulting values u
and v will correspond to the magnitude in both directions tangent to the surface. In 3D a cross
product between two vectors will return their orthogonal complement. Applying a cross product
to u and v will then give us the intensity value of the Z coordinate of each point. In order to
obtain all the normal coordinates, this method is applied to X and Y. The result is illustrated in
the figures 3.7.
Normal vector coordinate X Normal vector coordinate Y Normal vector coordinate Z
Figure 3.7: Normal matrices returned by the partial derivative method
3.4 Filtering the Point Cloud
Having found the normal vectors of the points in the frame, we can now identify the points of
interest. In this work we considered them to have a normalized horizontal or vertical component
of the normal vector bigger than 0.9. This intensity of the main normal component allows some
versatility of the accepted angles (see fig. 3.8).
The results of the used algorithms can be observed in fig 3.9. The white points of the image
represent the points of interest, points which present a normal horizontal or vertical component
higher than the accepted threshold.26 Getting the Point Cloud of Interest
Figure 3.8: Examples of planes with normal components of interest.
Result of the FSPF Sampling algorithm Partial derivatives method
Figure 3.9: Points of interest (in white) computed using the presented algorithms
The FSPF algorithm is mainly focused on plane identification, it is not suitable for this
application since it neglects some areas of interest. Although the amount of ignored regions
can be decreased and their size can be shrunk by changing the parameters of the FSPF so it
performs more plane search iterations, this would make the method slower and the existence of
non-studied regions would still be possible.
The subsampling algorithm considered has proven to be a faster and more accurate alterna-
tive to the FSPF algorithm for finding the normals of all the frame points. However, the last
algorithm used proved to be more precise and even faster.
As a result of applying the filter, points which do not meet the geometric specifications were
pruned and their 3D coordinates will not be considered for the 3D matching presented in the next
chapter. The depth image captured by the Kinect contains 307200 points (480 × 640). In figure
3.9 (c) he total points of interest identified are 30868, which corresponds to approximately 10%
of the total number of points. This will increase considerably the speed of the match algorithm.Chapter 4
Finding Boxes in Point Clouds
4.1 Overview of the ICP Algorithm
Introduced by Chen and Medioni [3] and Besl and Mckay [1], Iterative Closest Point (ICP) is an
algorithm employed to find the rigid transformations, which minimizes the difference between
two point clouds. It strongly relies on an initial estimate of the relative pose between the two
point clouds in order to achieve the global solution, which minimizes the error metric of the
distance between clouds.
ICP is often used to reconstruct 2D or 3D surfaces from different scans, to localize robots
and achieve optimal path planning (especially when wheel odometry is unreliable due to slip-
pery terrain), to co-register bone models, etc.
Figure 4.1: ICP algorithm I/O scheme28 Finding Boxes in Point Clouds
By giving as inputs to the ICP, a world scan, a 3D model of an object and an estimate of its
initial position, ICP will compute the rigid transformation between them, which minimizes the
error metric (fig 4.1). This way, it will provide us with an hypothesis of the object position in
the world (model based tracking).
Due to its simplicity it has become the dominant method for geometric alignment of three-
dimensional models and many variants of the algorithm have been proposed to each one of its
phases, [12] provides a recent survey of many ICP variants. The main drawback of this algo-
rithm is that it may converge to a local minimum rather than the global one. This means that
the limit may depend on the choice of the initial rigid alignment estimate T0 .
A good initial estimate of the position of the model in the world is therefore essential to the
convergence of the algorithm to a global minimum of the cost function.
The ICP algorithm can be decomposed in three main stages:
1. Selection of the points which will be used in both meshes;
2. Matching the points between both point clouds;
3. Minimizing the error metric in order to achieve a estimate of the rigid transformation given
the matched points.
The transformation, which minimizes the error metric, is then applied to the model point
cloud and this process is repeated cyclically until a stopping criteria is met.
The key to the solution of this problem is to achieve the correct correspondences between
point clouds since their correct relative Rotation/Translation can then be computed in closed
form.
A more detailed analysis of its stages can be observed bellow.
ICP starts by applying an initial estimation to the transformation T between two point
clouds.
Assuming one wants to find a correspondence of the point cloud B ∈ R3×n in the point
cloud A ∈ R3×k , the matching consists in finding for each point T × Bi the nearest point in A,
mi .4.2 Stages of the ICP Algorithm 29
Algorithm 2 regular Icp Algorithm
T ← T0
while ( not converged ) do
for i = 0 to serverIndex.length do
mi ← F indClosestP ointInA(T · bi )
if ∥mi − T · bi ∥ ≤ dm ax then
mi ← 1
else
mi ← 0
end if
end for ∑
arg minx { i wi ∥T · bi − mi ∥2 }
end while
Considering a minimum distance, the found correspondence will only be considered if its
distance is less than the specified threshold.
Finding a transformation between matched points will consist in minimizing the cost func-
tion which varies, and its simplest form is an euclidean distance between two points (as seen in
the algorithm above). Other alternatives are considered in this work taking into account spatial
properties of these matched points.
With the first estimation of the transformation computed, the transformation is applied to B,
the point cloud we desire to match, and the iterative process repeats until a satisfying condition
is met.
Although the weights, w ∈ R1×k , are considered in the algorithm presented above, these
were not considered in the work. Their presence, as the name indicates, re-enforce some corre-
spondences forcing the minimization of the error metric to focus more in decreasing the distance
of these matches which are more likely to be valid. The weights addressed to the correspon-
dences can be influenced by the geometric or color properties of one or both points.
4.2 Stages of the ICP Algorithm
As mentioned above, the ICP algorithm can be broken down in the main consecutive steps rep-
resented in fig. 4.2 .30 Finding Boxes in Point Clouds
Each one of these stages has been the focus of research and has its own variants.
Figure 4.2: ICP main steps
Having in mind the key idea that if the correct correspondences are known, the correct rel-
ative Rotation/Translation can be computed in closed form using a Procrustes analysis, some
variants of the algorithm will be presented which provide options in order to achieve the desired
correspondences.
4.2.1 Point Selection
In the original reference to this algorithm, [1] uses all available points in both meshes for the
ICP algorithm while [15], in order to decrease the number of points considered, performs an
uniform sampling of all the available points and [9] performs a random sampling of the existing
points in each iteration.
In order to limit the scope of the problem and avoid a combinatorial explosion of the number
of possibilities, a priori knowledge about the object can be used so as to to prune non-relevant
3D Points from the world scan accordingly to their geometrical or color properties. In [11]
assumptions about the object position and its color/spatial properties are used to increase the
reliability and the speed of the algorithm itself.
The point selection phase was already accomplished in the previous chapter by a normal
space sampling, where only the points which obeyed the spatial condition of belonging to ver-4.2 Stages of the ICP Algorithm 31
tical or horizontal planes were selected. This selection took into account the model used to find
the box which consisted of only its sides, as seen in fig. 6.1. The model was hereby considered
bottomless so it can be used even when the box is partially filled.
Although color or hue features were not used as constraints opposing [17], their considera-
tion is clearly advantageous in environments with insufficient geometric features.
4.2.2 Point Matching
In each iteration for each point T.Bi , we want to find the corresponding closest point in A in
order to compute the new transformation estimate, where B = [p1 , p2 , ..., pn ] ∈ R3×n is the
model point cloud, A = [p1 , p2 , ..., pm ] ∈ R3×m is the world point cloud, result of the previous
pruning, and T is the estimation of the transformation between meshes.
Depending on the number of points generated by the range sensor, it might be reasonable to
make a selection of these points so as to compute the box location in real time.
It also turns out that some matches are more suitable than others as it is more likely to
identify a correct match for them. Which method to use in this selection process is therefore
strongly dependent on the kind of data being used and should be considered for each specific
problem.
In order to decrease the influence of matches with outliers, an user-specified distance thresh-
old can be used for ignoring correspondences between points too far away.
Exhaustive Search
An exhaustive search is the simplest and most computationally expensive method to find a
match in A for each T.Bi . In this method, for each T.Bi , its euclidean distance to all the points
in A is computed (equation 4.1) and the point with smaller distance is therefore chosen.
For each transformed point i ∈ 1...n the closest point k ∗ ∈ 1...m is found by:
k ∗ = argk min∥T.Bi − Ak ∥ . (4.1)
This Nearest Neighbor Search (NNS) method has a complexity of O(k) for k points of
interest and it can clearly be optimized since its comparisons disregard the points properties,
such as the normal vectors in each point.32 Finding Boxes in Point Clouds
Exhaustive Search Having Into Account the Normal
Since the previous chapter the filtered point cloud only contains points of two classes: points
with normalized horizontal normal coordinate > 0.9, and points with normalized vertical nor-
mal coordinate > 0.9.
Following a somehow similar approach to [11], which only matched points with normal
angles within 45◦ of distance, by not allowing points of different classes to be compared the
computational time required by this method is greatly lower than the exhaustive search alone.
It is worth pointing out that even though the speeds of convergence increases so will the
precision, since unlikely matches will decrease in number.
4.2.3 Computing the Rigid Transformation
After the points have been selected and matched, a suitable error metric will be assigned and
minimized in order to find the transformation estimation.
There are several minimization strategies that can be used. In this work two error metrics
were taken into account: the point to point metric and the point to plane metric which considers
the normals of each corresponding point.
As previously mentioned, in order to compute the desired transformation an initial transfor-
mation estimation is required. Although this initial alignment may be achieved using different
methods, in this work such identification algorithms will not be used since in both applications
a rough initial alignment is always present by considering the initial position fixed in space.
Point-to-Point
This straightforward approach considers the sum of squared distances between each pair.
Let B = b1 , b2 , ..., bn be the points in the dataset and A = a1 , a2 , ..., an be the corresponding
match in the previously computed point cloud.
Our goal is to find the transformation T which , for each point i ∈ 1...n, minimizes the error
function (fig. 4.3):
Φ(ai , T.bi ) = ∥ai − T.bi ∥2 (4.2)
Thus,4.2 Stages of the ICP Algorithm 33
Figure 4.3: Minimizing the error
∑
n
∗ ∗
(R , T ) = argmin ∥ai − (R.bi + T )∥2 (4.3)
R,T
i=1
where R ∈ R3×3 is the rotation matrix and t ∈ R3×1 is the translation matrix.
A generalized orthogonal Procrustes analysis (GPA) [5] can be used in order to compute
these two matrices
Generalized Orthogonal Procrustes Analysis
The Generalized Orthogonal Procrustes Analysis was named by Hurley and Cattell [6] in 1962
after a Greek mythology character who stretched and chopped (people) to find the right fit. Pro-
crustes analysis is a rigid shape analysis that determines the scaling, translation and rotation in
order to obtain the best fit between two or more set of points which define shape surfaces.
The algorithm can be decomposed in three main steps:
1. Compute the centroid of each shape;
2. Align both centroids to the origin;
3. Rotate one shape to align it with the second one [5].
Translation
According to the Procrustes Analysis, so as to compute the Rotation Matrix R the starting point
ought to be the removal of the translational components of each one of the two corresponding
point clouds. This can be done by translating them so that their centroids lie at the origin.
To achieve this, we need to subtract each point cloud coordinate x, y and z by the mean of
its coordinates x̄, ȳ and z̄.
The new centered point clouds A’ and B’ (A′ , B ′ ∈ Rn×3 ) are given by:You can also read

















































