Variable selection in high-dimensional genetic data - Sahir ...
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Variable selection in high-dimensional genetic
data
Sahir Rai Bhatnagar
Department of Epidemiology, Biostatistics, and Occupational Health
Department of Diagnostic Radiology
McGill University
sahirbhatnagar.com
Feb. 23, 2021
1 / 76 .
Classical Methods
Betting on Sparsity
A Thought Experiment
Motivating Dataset
Notre proposition
Résultats
Other applications
Extensions
Fonctions de pénalité non convexes
Analyse de survie
Orientations futures
Classical Methods 2 / 76 .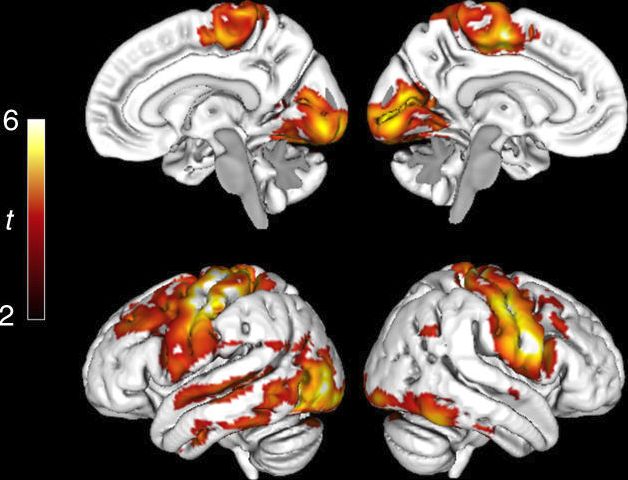
Setting
• We are concerned with the analysis of data in which we are
attempting to predict an outcome Y using a number of explanatory
factors X1 , X2 , X3 , . . ., some of which may not be particularly useful
Classical Methods 3 / 76
Setting
• We are concerned with the analysis of data in which we are
attempting to predict an outcome Y using a number of explanatory
factors X1 , X2 , X3 , . . ., some of which may not be particularly useful
• Although the methods we will discuss can be used solely for
prediction (i.e., as a “black box”), I will adopt the perspective that we
would like the statistical methods to be interpretable and to explain
something about the relationship between the X and Y
Classical Methods 3 / 76
Setting
• We are concerned with the analysis of data in which we are
attempting to predict an outcome Y using a number of explanatory
factors X1 , X2 , X3 , . . ., some of which may not be particularly useful
• Although the methods we will discuss can be used solely for
prediction (i.e., as a “black box”), I will adopt the perspective that we
would like the statistical methods to be interpretable and to explain
something about the relationship between the X and Y
• Regression models are an attractive framework for approaching
problems of this type, and the focus today will be on extending
classical regression modeling to deal with high-dimensional data
Classical Methods 3 / 76 .
Classical Methods
• A nice and powerful toolbox for analyzing the more traditional datasets where
the sample size (N) is far greater than the number of covariates (p):
▶ linear regression, logistic regression, LDA, QDA, glm,
▶ regression spline, smoothing spline, kernel smoothing, local smoothing,
GAM,
▶ Neural Network, SVM, Boosting, Random Forest, ...
Classical Methods 4 / 76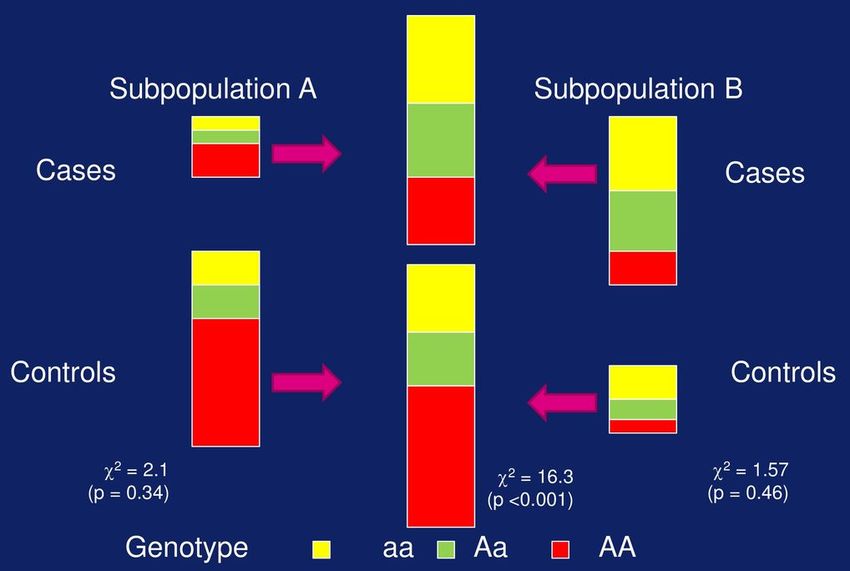
Classical Methods
• A nice and powerful toolbox for analyzing the more traditional datasets where
the sample size (N) is far greater than the number of covariates (p):
▶ linear regression, logistic regression, LDA, QDA, glm,
▶ regression spline, smoothing spline, kernel smoothing, local smoothing,
GAM,
▶ Neural Network, SVM, Boosting, Random Forest, ...
x11 x12 · · · x1p
x21 x12 · · · x1p
x31 x12 · · · x1p
. .. .. ..
.
. . . .
. .. .. ..
.
. . . .
Xn×p =
. .. .. ..
.. . . .
. . . .
. . . .
. . . .
.. .. .. ..
. . . .
xn1 x12 · · · xnp
Classical Methods 4 / 76 .
Classical Methods 5 / 76 .
Classical Linear Regression
Data: (x1 , y1 ), . . . , (xn , yn ) iid from
y = xT β + ϵ
where E(ϵ|x) = 0, and dim(x) = p. To include an intercept, we can set
x1 ≡ 1. Using Matrix notation:
y = Xβ + ϵ
The least squares estimator
b = arg min ∥y − Xβ∥2
β LS
β
b = (XT X)−1 XT y
β LS
Classical Methods 6 / 76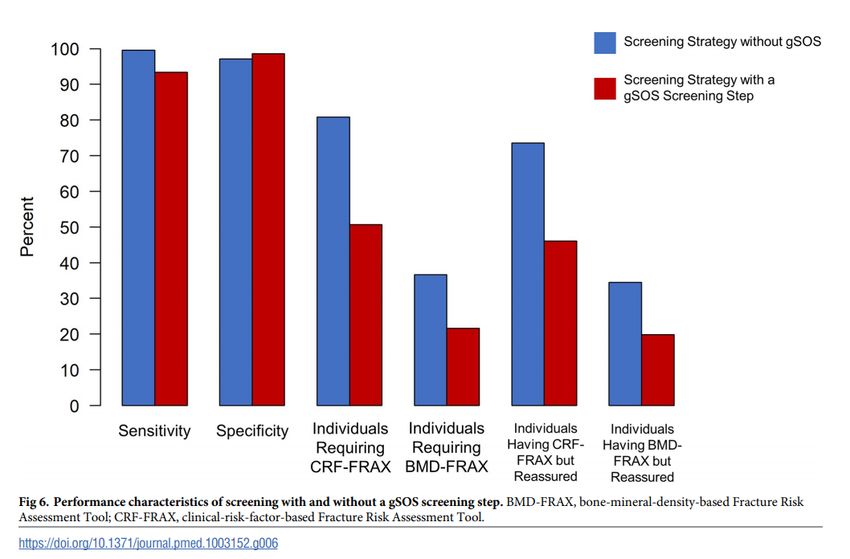
Classical Linear Regression
Data: (x1 , y1 ), . . . , (xn , yn ) iid from
y = xT β + ϵ
where E(ϵ|x) = 0, and dim(x) = p. To include an intercept, we can set
x1 ≡ 1. Using Matrix notation:
y = Xβ + ϵ
The least squares estimator
b = arg min ∥y − Xβ∥2
β LS
β
b = (XT X)−1 XT y
β LS
• Question: How to find the important variables xj ?
Classical Methods 6 / 76 .Best-subset Selection (Beal et al. 1967, Biometrika) Classical Methods 7 / 76 .
Which variables are important?
• Scientists know only a small subset of variables (such as genes) are
important for the response variable.
• An old Idea: try all possible subset models and pick the best one.
• Fit a subset of predictors to the linear regression model. Let S be the
subset predictors, e.g., S = {1, 3, 7}.
RSSS RSSS
Cp = − (n − 2|S|) = 2 + 2|S| − n
σ2 σ
• We pick the model with the smallest Cp value.
Classical Methods 8 / 76 .Model selection criteria
Minimizing Cp is equivalent to minimizing
b ∥2 + 2|S|σ 2 .
∥y − XS β S
which is AIC score.
Many popular model selection criteria can be written as
b ∥2 + λ|S|σ 2 .
∥y − XS β S
p
• BIC uses λ = σ log(n)/n.
Classical Methods 9 / 76 .Remarks
Best subset selection plus model selection criteria (AIC, BIC, etc.)
• Computing all possible subset models is a combinatorial optimization
problem (NP hard)
• Instability in the selection process (Breiman, 1996)
Classical Methods 10 / 76 .Ridge Regression (Hoerl & Kennard 1970, Technometrics)
b = arg min ||y − Xβ||2 + λ||β||2
• β β 2
Pp
• ||β||22 = j=1 βj2
Classical Methods 11 / 76Ridge Regression (Hoerl & Kennard 1970, Technometrics)
b = arg min ||y − Xβ||2 + λ||β||2
• β β 2
Pp
• ||β||22 = j=1 βj2
b
• β ⊤ −1 ⊤
X y → exact solution
Ridge = (X X + λI)
b = (X⊤ X)−1 X⊤ y
• β LS
Classical Methods 11 / 76Ridge Regression (Hoerl & Kennard 1970, Technometrics)
b = arg min ||y − Xβ||2 + λ||β||2
• β β 2
Pp
• ||β||22 = j=1 βj2
b
• β ⊤ −1 ⊤
X y → exact solution
Ridge = (X X + λI)
b = (X⊤ X)−1 X⊤ y
• β LS
• Let X⊤ X = Ip×p
Classical Methods 11 / 76Ridge Regression (Hoerl & Kennard 1970, Technometrics)
b = arg min ||y − Xβ||2 + λ||β||2
• β β 2
Pp
• ||β||22 = j=1 βj2
b
• β ⊤ −1 ⊤
X y → exact solution
Ridge = (X X + λI)
b = (X⊤ X)−1 X⊤ y
• β LS
• Let X⊤ X = Ip×p
β̂j (MCO)
β̂j (Ridge) =
1+λ
Classical Methods 11 / 76 .Least squares vs. Ridge Classical Methods 12 / 76 .
High-dimensional data (n
Why can’t we fit OLS to High-dimensional data? Classical Methods 14 / 76 .
High-dimensional data (n
High-dimensional data (n n Classical Methods 15 / 76
High-dimensional data (n n
▶ However, the ideas we discuss in this course are also relevant to many
situations in which p < n; for example, if n = 100 and p = 80, we
probably don’t want to use ordinary least squares
Classical Methods 15 / 76 .A fundamental picture for data science
ESL, Hastie et al. 2009
Classical Methods 16 / 76 .Classical Methods
Betting on Sparsity
A Thought Experiment
Motivating Dataset
Notre proposition
Résultats
Other applications
Extensions
Fonctions de pénalité non convexes
Analyse de survie
Orientations futures
Betting on Sparsity 17 / 76 .Bet on Sparsity Principle
X X19 X18 X17
X22 X21 20 X16
X23 X15
X24 X14
X25 X13
X26 X12
X27 X11
X28 X10
X29 X9
X30 X8
X31 X7
X32 X6
X33 X5
X34 X4
X35 X3
X36 X2
X37
YY X1
X38 X72
X39 X71
X40 X70
X41 X69
X42 X68
X43 X67
X44 X66
X45 X65
X46 X64
X47 X63
X48 X62
X49 X61
X50 X60
X51 X59
X52 X X58
53 X54 X55 X56 X57Bet on Sparsity Principle
X X19 X18 X17
X22 X21 20 X16
X23 X15
X24 X14
X25 X13
X26 X12
X27 X11
X28 X10
X29 X9
X30 X8
X31 X7
X32 X6
X33 X5
X34 X4
X35 X3
X36 X2
X37
YY X1
X38 X72
X39 X71
X40 X70
X41 X69
X42 X68
X43 X67
X44 X66
X45 X65
X46 X64
X47 X63
X48 X62
X49 X61
X50 X60
X51 X59
X52 X X58
53 X54 X55 X56 X57
Betting on Sparsity 18 / 76 .Bet on Sparsity Principle
Use a procedure that does well in sparse problems, since
no procedure does well in dense problems.1
1 The elements of statistical learning. Springer series in statistics, 2001.
Betting on Sparsity 19 / 76Bet on Sparsity Principle
Use a procedure that does well in sparse problems, since
no procedure does well in dense problems.1
• We often don’t have enough data to estimate so many parameters
• Even when we do, we might want to identify a relatively small
number of predictors (k < N) that play an important role
• Faster computation, easier to understand, and stable predictions on
new datasets.
1 The elements of statistical learning. Springer series in statistics, 2001.
Betting on Sparsity 19 / 76 .Classical Methods
Betting on Sparsity
A Thought Experiment
Motivating Dataset
Notre proposition
Résultats
Other applications
Extensions
Fonctions de pénalité non convexes
Analyse de survie
Orientations futures
A Thought Experiment 20 / 76 .How would you schedule a meeting of 20 people? A Thought Experiment 21 / 76
How would you schedule a meeting of 20 people? A Thought Experiment 21 / 76 .
Classical Methods
Betting on Sparsity
A Thought Experiment
Motivating Dataset
Notre proposition
Résultats
Other applications
Extensions
Fonctions de pénalité non convexes
Analyse de survie
Orientations futures
Motivating Dataset 22 / 76 .UKBiobank
• Données de génotypage sont issues de 500 000 individus d’origine
caucasienne recrutés au Royaume-Uni
• La puce UKBioBANK comporte plus de 800 000 SNPs
• Grand nombre de variables réponses (ex. maladie, densité minérale
osseuse)
• Objectif: Quelles variables explicatives sont associées à la variable
réponse?
Motivating Dataset 23 / 76 .Un échantillon
ID Response Gene1 Gene2 Gene3 Gene4 Gene5 Gene6
1 2610781 −1.255 1 2 0 0 0 1
2 4114347 −0.339 1 2 0 2 0 1
3 4399930 −0.6 1 2 1 1 0 1
4 2081319 0.809 1 2 0 1 0 2
5 1347380 0.279 2 2 0 0 0 0
6 3262449 −0.421 2 2 0 1 0 1
7 4870063 −0.454 2 2 0 0 0 2
8 1141212 1.383 2 2 1 1 1 0
9 2997954 −2.29 1 2 0 0 0 1
10 5805218 2.289 1 2 0 1 1 1
Motivating Dataset 24 / 76 .Reviews
GWAS
a Genome-wide association b Functional characterization
Disease Trait
Chromatin
Population accessibility
Controls Cases Unselected sample
Histone
modification
Genotyping method
DNA
Meta-analysis SNP array and methylation
imputation WGS
4
–log10(P value)
3
Transcription
factor binding
Statistical 2
association
1
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Chromosome
Conservation
SNP 10
SNP 11
SNP 14
SNP 16
SNP 18
SNP 19
SNP 20
SNP 21
SNP 1
SNP 2
SNP 3
SNP 5
SNP 6
SNP 7
SNP 8
SNP 9
Linkage Block 1 Block 1 Block 3 Block 4
disequilibrium
eQTL
Genomic region
1 Tam V. et al. Benefits and limitations of genome-wide association studies. Nat Rev Genet (2019)
c Experimental validation d GWAS variants
Motivating Dataset 25 / 76 .Confounding Motivating Dataset 26 / 76 .
pedigree. In contrast, association studies are used to tude finer resolution than a comparable linkage study
Population structure
search for loci at which there is a significant associ
ation between the phenotypes and genotypes of unre
(Morris and Cardon, 2007; Altshuler, Daly and Lan
der, 2008). GWAS are preferred for detecting com
lated individuals. These associations arise because of mon causal variants (say, population fraction > 0.05),
correlations in transmissions of phenotypes and geno which typically have only a weak effect on phenotype,
• Les
types over manyGWAS comparent
generations, des analy
but association individus nonlinkage
whereas apparentés, mais
studies remain «nonfor the detec
superior
apparentés» en fait signifie que lestion
ses do not model these transmissions directly, whereas relations sont of
of rare variants inconnues et these ef
large effect (because
fects are more strongly concentrated within particular
linkage analyses do. The relatedness of study subjects
présumées éloignées. families).
is therefore central to a linkage study, whereas the re
Time Association
(generations) Relatedness:
Linkage - unknown
Relatedness: - distant
- known - nuisance
- recent
- useful
?
FlG. 1. Schematic illustration of differences between linkage studies, which
ciation studies which assume "unrelated" individuals. Open circles denote stu
lines denote observed parent-child relationships. Dotted lines indicate unobs
tions,1 and filled circles indicate the common ancestors at which these lineages
Astle and Balding. Population structure and cryptic relatedness in genetic association studies.
founders of a linkage study, but these have little impact on inferences and are
Statistical Science (2009)
association analysis and constitute an important potential confounder.
Motivating Dataset 27 / 76 .Les observations ne sont pas indépendants
• Les observations sont corrélées, mais cette relation est souvent
inconnue
• Cependant, elle peut être estimé à partir des données
ID Response Gene1 Gene2 Gene3 Gene4 Gene5 Gene6
1 2610781 −1.255 1 2 0 0 0 1
2 4114347 −0.339 1 2 0 2 0 1
3 4399930 −0.6 1 2 1 1 0 1
4 2081319 0.809 1 2 0 1 0 2
5 1347380 0.279 2 2 0 0 0 0
6 3262449 −0.421 2 2 0 1 0 1
7 4870063 −0.454 2 2 0 0 0 2
8 1141212 1.383 2 2 1 1 1 0
9 2997954 −2.29 1 2 0 0 0 1
10 5805218
Powered by TCPDF (www.tcpdf.org)
2.289 1 2 0 1 1 1
Motivating Dataset 28 / 76 .La matrice de parenté (kinship)
• Soit kinship une liste de SNP utilisée pour estimer la matrice de
parenté
• Soit Xkinship une matrice de génotype normalisée n × q.
• Une matrice de parenté (Φ) peut être calculée comme:
1
Φ= Xkinship X⊤
kinship (1)
q−1
Motivating Dataset 29 / 76 .Test d’association avec un modèle mixte linéaire (LMM)
p
X
Y= βj · SNPj + P + ε (2)
j=1
P ∼ N (0, ησ 2 Φ) ε ∼ N (0, (1 − η)σ 2 I)
• σ 2 est la variance totale du phénotype
• η ∈ [0, 1] est l’héritabilité du phénotype
• Y|(η, σ 2 ) ∼ N (0, ησ 2 Φ + (1 − η)σ 2 I)
Motivating Dataset 30 / 76 .Régression ridge (Hoerl & Kennard 1970, Technometrics),
Lasso (Tibshirani 1996, JRSSB)
[
• β ridge
= arg minβ ||y − Xβ||2 + λ||β||22
Pn Pp 2 Pp
b lasso = arg min
• β yi − |βj |
j=1 xij βj
1
β 2 i=1 +λ j=1
Lasso, ridge, ect. ne sont pas directement applicable au LMM
Motivating Dataset 31 / 76 .Procédure en deux étapes
• Étape 1: Ajuster un LMM sous l’hypothèse nul avec un seul effet
aléatoire
Y=P+ε
P ∼ N (0, ησ 2 Φ) ε ∼ N (0, (1 − η)σ 2 I)
Motivating Dataset 32 / 76Procédure en deux étapes
• Étape 1: Ajuster un LMM sous l’hypothèse nul avec un seul effet
aléatoire
Y=P+ε
P ∼ N (0, ησ 2 Φ) ε ∼ N (0, (1 − η)σ 2 I)
• Étape 2: Utilisez les résidus de l’étape 1 comme nouvelle réponse
indépendante
Motivating Dataset 32 / 76 .Procédure en deux étapes
X_
kinship
Motivating Dataset 33 / 76 .Procédure en deux étapes
X_
kinship
X_kinship X_kinship T
Motivating Dataset 34 / 76 .Procédure en deux étapes
X_
kinship
X_kinship X_kinship T
+ E
͠
Y
Motivating Dataset P 35 / 76 .Procédure en deux étapes
Y P
Step 1: + E 1
͠
Step 2: Residuals + E
from Step 1 ͠ 2
Motivating Dataset 36 / 76Procédure en deux étapes
Y P
Step 1: + E 1
͠
Step 2: Residuals + E
from Step 1 ͠ 2
• Dans les tests d’association, on sait qu’il souffre d’énormes pertes de
puissance (Oualkacha et al. Gene. Epi. (2013))
Motivating Dataset 36 / 76 .Classical Methods
Betting on Sparsity
A Thought Experiment
Motivating Dataset
Notre proposition
Résultats
Other applications
Extensions
Fonctions de pénalité non convexes
Analyse de survie
Orientations futures
Notre proposition 37 / 76 .Notre proposition
• Nous proposons, ggmix, une procédure en une seule étape qui
contrôle simultanément les populations structurées et effectue une
sélection de variables dans les modèles mixtes linéaires
PLOS GENETICS
RESEARCH ARTICLE
Simultaneous SNP selection and adjustment
for population structure in high dimensional
prediction models
Sahir R. Bhatnagar ID1,2*, Yi Yang3, Tianyuan Lu ID4,5, Erwin Schurr ID6, JC Loredo-Osti7,
Marie Forest ID8, Karim Oualkacha ID9, Celia M. T. Greenwood ID1,4,5,10,11
1 Department of Epidemiology, Biostatistics and Occupational Health, McGill University, Montréal, Québec,
Canada, 2 Department of Diagnostic Radiology, McGill University, Montréal, Québec, Canada, 3 Department
of Mathematics and Statistics, McGill University, Montréal, Québec, Canada, 4 Quantitative Life Sciences,
a1111111111 McGill University, Montréal, Québec, Canada, 5 Lady Davis Institute, Jewish General Hospital, Montréal,
a1111111111 Québec, Canada, 6 Department of Medicine, McGill University, Montréal, Québec, Canada, 7 Department of
a1111111111 Mathematics and Statistics, Memorial University, St. John’s, Newfoundland and Labrador, Canada, 8 École
a1111111111 de Technologie Supérieure, Montréal, Québec, Canada, 9 Département de Mathématiques, Université du
a1111111111 Québec à Montréal, Montréal, Québec, Canada, 10 Gerald Bronfman Department of Oncology, McGill
University, Montréal, Québec, Canada, 11 Department of Human Genetics, McGill University, Montréal,
Québec, Canada
* sahir.bhatnagar@mcgill.ca
OPEN ACCESS
Abstract
Citation: Bhatnagar SR, Yang Y, Lu T, Schurr E,
1 R package: sahirbhatnagar.com/ggmix, https://cran.r-project.org/package=ggmix
Loredo-Osti J, Forest M, et al. (2020) Simultaneous
Notre
SNP selection and adjustment for population
proposition
structure in high dimensional prediction models.
Complex traits are known to be influenced by a combination of environmental factors and 38 / 76 .ggmix: une procédure en une seule étape
Y X P
+ +E
͠
1 R package: sahirbhatnagar.com/ggmix, https://cran.r-project.org/package=ggmix
Notre proposition 39 / 76 .Data and Model
• Phenotype: Y = (y1 , . . . , yn ) ∈ Rn
• SNPs: X = (X1 ; . . . , Xn )T ∈ Rn×p , where p ≫ n
• Twice the Kinship matrix or Realized Relationship matrix: Φ ∈ Rn×n
• Regression Coefficients: β = (β1 , . . . , βp )T ∈ Rp
• Polygenic random effect: P = (P1 , . . . , Pn ) ∈ Rn
• Error: ε = (ε1 , . . . , εn ) ∈ Rn
• We consider the following LMM with a single random effect:
Y = Xβ + P + ε
P ∼ N (0, ησ Φ)
2
ε ∼ N (0, (1 − η)σ 2 I)
• σ 2 is the phenotype total variance
• η ∈ [0, 1] is the phenotype heritability (narrow sens)
• Y|(β, η, σ 2 ) ∼ N (Xβ, ησ 2 Φ + (1 − η)σ 2 I)
Notre proposition 40 / 76 .Likelihood
• The negative log-likelihood is given by
n 1 1
−ℓ(Θ) ∝ log(σ 2 ) + log (det(V)) + 2 (Y − Xβ)T V−1 (Y − Xβ)
2 2 2σ
V = ηΦ + (1 − η)I
• Assume the spectral decomposition of Φ
Φ = UDU⊤
• U is an n × n orthogonal matrix and D is an n × n diagonal matrix
• One can write
V = U(ηD + (1 − η)I)U⊤ = UWU⊤
with W = diag (wi )ni=1 , wi = ηDii + (1 − η)
Notre proposition 41 / 76 .Likelihood
• Projection of Y (and columns of X) into Span(U) leads to a simplified
correlation structure for the transformed data: Ỹ = U⊤ Y
• Ỹ|(β, η, σ 2 ) ∼ N (X̃β, σ 2 W), with X̃ = U⊤ X
• The negative log-likelihood can then be expressed as
1∑
n
n 1 ( )T ( )
−ℓ(Θ) ∝ log(σ 2 ) + log (wi ) + 2 Ỹ − X̃β W−1 Ỹ − X̃β
2 2 i=1 2σ
Notre proposition 42 / 76Likelihood
• Projection of Y (and columns of X) into Span(U) leads to a simplified
correlation structure for the transformed data: Ỹ = U⊤ Y
• Ỹ|(β, η, σ 2 ) ∼ N (X̃β, σ 2 W), with X̃ = U⊤ X
• The negative log-likelihood can then be expressed as
1∑
n
n 1 ( )T ( )
−ℓ(Θ) ∝ log(σ 2 ) + log (wi ) + 2 Ỹ − X̃β W−1 Ỹ − X̃β
2 2 i=1 2σ
• For fixed σ 2 and η, solving for β is a weighted least squares problem
Notre proposition 42 / 76 .Penalized Maximum Likelihood Estimator
• Define the objective function:
X
Qλ (Θ) = −ℓ(Θ) + λ pj (βj )
j
• pj (·) is a penalty term on β1 , . . . , βp
b λ is obtained by
• An estimate of the model parameters Θ
b λ = arg min Qλ (Θ)
Θ
Θ
Notre proposition 43 / 76 .Block Relaxation (De Leeuw, 1994)
To solve for the optimization problem we use a block relaxation technique
Set k ← 0, initial values for the parameter vector Θ(0) and ϵ;
for λ ∈ {λmax , . . . , λmin } do
repeat
(k)
(k+1) (k)
For j = 1, . . . , p, βj ← arg min Qλ β −j , η (k) , σ 2
βj
(k)
η (k+1)
← arg min Qλ β (k+1) , η, σ 2
η
2 (k+1)
σ ← arg min Qλ β (k+1) , η (k+1) , σ 2
σ2
k←k+1
until convergence criterion is satisfied: ||Θ(k+1) − Θ(k) ||2 < ϵ;
end
Algorithm 1: Block Relaxation Algorithm
Notre proposition 44 / 76 .Coordinate Gradient Descent Method
• We take advantage of smoothness of ℓ(Θ)
• We approximate Qλ (Θ) by a strictly convex quadratic function (using
gradient)
• We use CGD to calculate a descent direction
• To achieve the descent property for the objective function, we employ
further line search
1 Tseng P& Yun S. Math. Program., Ser. B, (2009)
Notre proposition 45 / 76Coordinate Gradient Descent Method
• We take advantage of smoothness of ℓ(Θ)
• We approximate Qλ (Θ) by a strictly convex quadratic function (using
gradient)
• We use CGD to calculate a descent direction
• To achieve the descent property for the objective function, we employ
further line search
Theorem [Convergence] 1 :
If {Θ(k) , k = 0, 1, 2, . . .} is a sequence of iterates generated by the iteration
map of Algorithm 1, then each cluster point (i.e. limit point) of
{Θ(k) , k = 0, 1, 2, . . .} is a stationary point of Qλ (Θ)
1 Tseng P& Yun S. Math. Program., Ser. B, (2009)
Notre proposition 45 / 76 .Choice of the tuning parameter
• We use the BIC:
b σ
BICλ = −2ℓ(β, b
b2 , ηb) + c · df λ
b is the number of non-zero elements in β
• df b plus two 1
λ λ
• Several authors 2 have used this criterion for variable selection in
mixed models with c = log n
• Other authors 3 have proposed c = log(log(n)) ∗ log(n)
1 Zou et al. The Annals of Statistics, (2007)
2 Bondell et al. Biometrics (2010)
3 Wang et al. JRSS(Ser. B), (2009)
Notre proposition 46 / 76 .Classical Methods
Betting on Sparsity
A Thought Experiment
Motivating Dataset
Notre proposition
Résultats
Other applications
Extensions
Fonctions de pénalité non convexes
Analyse de survie
Orientations futures
Résultats 47 / 76 .Simulation study
• We simulated data from the model Y = Xβ + P + ε
• We used heritability η = {0.1, 0.3}, number of covariates p = 5, 000,
number of kinship SNPs k = 10, 000, percentage of causal SNPs
c = {0%, 1%} and σ 2 = 1.
• In addition to these parameters, we also varied the amount of overlap
between the causal list and the kinship list:
1. None of the causal SNPs are included in kinship set.
2. All of the causal SNPs are included in the kinship set.
• These were meant to contrast the model behavior when causal SNPs
are included in both the main effects and random effects vs. when the
causal SNPs are only included in the main effects.
• These scenarios are motivated by the current standard of practice in
GWAS where the candidate marker is excluded from the calculation of
the kinship matrix.
• This approach becomes much more difficult to apply in large-scale
multivariable models where there is likely to be overlap between the
variables in the design matrix and kinship matrix.
Résultats 48 / 76 .Simulation study results
• Both the lasso+PC and twostep selected more false positives
compared to ggmix
• Overall, we observed that variable selection results and RMSE for
ggmix were similar regardless of whether the causal SNPs were in the
kinship matrix or not.
• This result is encouraging since in practice the kinship matrix is
constructed from a random sample of SNPs across the genome, some
of which are likely to be causal, particularly in polygenic traits.
• In particular, our simulation results show that the principal
component adjustment method may not be the best approach to
control for confounding by population structure, particularly when
variable selection is of interest.
Résultats 49 / 76 .Real data applications
1. UK Biobank
▶ 10,000 LD-pruned SNPs (Essentially un-correlated variables) to predict
standing height in 18k related individuals
▶ Standing height is highly polygenic (many variables associated with
response)
Résultats 50 / 76Real data applications
1. UK Biobank
▶ 10,000 LD-pruned SNPs (Essentially un-correlated variables) to predict
standing height in 18k related individuals
▶ Standing height is highly polygenic (many variables associated with
response)
2. GAW20 Simulated dataset
▶ 50,000 SNPs (all on chromosome 1) to predict high-density lipoproteins
in 679 related individuals
▶ Not much correlation between causal SNP and others
▶ Very sparse signals (only 1 causal variant)
Résultats 50 / 76Real data applications
1. UK Biobank
▶ 10,000 LD-pruned SNPs (Essentially un-correlated variables) to predict
standing height in 18k related individuals
▶ Standing height is highly polygenic (many variables associated with
response)
2. GAW20 Simulated dataset
▶ 50,000 SNPs (all on chromosome 1) to predict high-density lipoproteins
in 679 related individuals
▶ Not much correlation between causal SNP and others
▶ Very sparse signals (only 1 causal variant)
3. Mouse Crosses
▶ Find loci associated with mouse sensitivity to mycobacterial infection
▶ 189 samples, and 625 microsatellite markers
▶ Highly correlated variables
Résultats 50 / 76 .Results: UK Biobank
(A) (B)
1.3 1.000
●
RMSE in model selection set
1.2
0.975
RMSE in test set
1.1
0.950
1.0
0.925
0.9
●●
●
0.8 0.900
0 25 50 75 100 9 10 11 12
λ index log2(Number of active variables)
twostep lasso ggmix ● twostep ● lasso ● ggmix ● bslmm
Résultats 51 / 76 .Results: GAW20
Method Median number RMSE (SD)
of active variables
(Inter-quartile range)
twostep 1 (1 - 11) 0.3604 (0.0242)
lasso 1 (1 - 15) 0.3105 (0.0199)
ggmix 1 (1 - 12) 0.3146 (0.0210)
BSLMM 40,737 (39,901 - 41,539) 0.2503 (0.0099)
Table: Summary of model performance based on 200 GAW20 simulations. Five-fold
cross-validation root-mean-square error was reported for each simulation replicate.
Résultats 52 / 76 .Results: Mouse crosses
(a) twostep Chr1 Chr2 Chr3 Chr4 Chr5 Chr6 Chr7 Chr8 Chr9 Chr10
150
100
50
19%
0
20 60 100 20 60 100 0 40 80 0 40 80 0 40 80 0 20 60 0 20 50 10 40 70 10 40 70 10 40 70
Chr11 Chr12 Chr13 Chr14 Chr15 Chr16 Chr17 Chr18 Chr19 ChrX
150
81%
100
50
0
0 40 80 0 20 40 60 10 40 70 10 30 50 10 30 50 70 0 20 50 10 30 50 10 30 0 20 40 0 20 50
(b) lasso Chr1 Chr2 Chr3 Chr4 Chr5 Chr6 Chr7 Chr8 Chr9 Chr10
80
60
40
56%
20
0
20 60 100 20 60 100 0 40 80 0 40 80 0 40 80 0 20 60 0 20 50 10 40 70 10 40 70 10 40 70
Chr11 Chr12 Chr13 Chr14 Chr15 Chr16 Chr17 Chr18 Chr19 ChrX
80
60
44%
40
20
0
0 40 80 0 20 40 60 10 40 70 10 30 50 10 30 50 70 0 20 50 10 30 50 10 30 0 20 40 0 20 50
(c) ggmix Chr1 Chr2 Chr3 Chr4 Chr5 Chr6 Chr7 Chr8 Chr9 Chr10
200
150
100
50
0
99% 1% 20 60 100 20 60 100 0 40 80 0 40 80 0 40 80 0 20 60 0 20 50 10 40 70 10 40 70 10 40 70
Chr11 Chr12 Chr13 Chr14 Chr15 Chr16 Chr17 Chr18 Chr19 ChrX
200
150
100
50
0
0 40 80 0 20 40 60 10 40 70 10 30 50 10 30 50 70 0 20 50 10 30 50 10 30 0 20 40 0 20 50
Résultats 53 / 76 .Discussion
• La procédure en deux étapes conduit à un grand nombre de faux
positifs et de faux négatifs
• L’ajustement de la composante principale dans lasso peut ne pas être
suffisant pour contrôler la confusion, en particulier lorsqu’il y a
beaucoup de corrélation entre les observations
• ggmix fonctionne bien même lorsque les variables causales sont
utilisées dans le calcul de la matrice de parenté
• ggmix a montré la plus grande amélioration par rapport à twostep et
lasso quand il y avait des variables hautement corrélées avec
beaucoup de structure (exemple de croix de souris)
Résultats 54 / 76 .ggmix R package
library(ggmix)
data("admixed")
fitggmix R package
hdbicClassical Methods
Betting on Sparsity
A Thought Experiment
Motivating Dataset
Notre proposition
Résultats
Other applications
Extensions
Fonctions de pénalité non convexes
Analyse de survie
Orientations futures
Other applications 57 / 76 .gSOS Other applications 58 / 76 .
gSOS Other applications 59 / 76 .
Classical Methods
Betting on Sparsity
A Thought Experiment
Motivating Dataset
Notre proposition
Résultats
Other applications
Extensions
Fonctions de pénalité non convexes
Analyse de survie
Orientations futures
Extensions 60 / 76 .SCAD (Fan et Li, JASA, 2001), MCP (Zhang, Ann. Stat., 2010) Extensions 61 / 76 .
Computational challenges
• Past approaches for optimization for SCAD/MCP relies upon descent
method, first- or second- order
• e.g., sparsenet (Mazumder et al. 2011) uses coordinate descent with
full step size,
Pn whose coordinate update cycles through
j j P
β̃j = Sγk i=1 yi − ỹi xij , λ ℓ , where ỹi = k̸=j xik β̃k
• However, coordinate descent is difficult to vectorize, and rate of
convergence is difficult of establish – though past literature suggests
O(1/k) rate of convergence for ISTA
Extensions 62 / 76 .Noname manuscript No.
(will be inserted by the editor)
Our proposal: Accelerated gradient (AG) method
Improving Convergence for Nonconvex Composite
Programming
Kai Yang · Masoud Asgharian · Sahir
Bhatnagar
v:2009.10629v2 [math.OC] 12 Oct 2020
Received: date / Accepted: date
Abstract High-dimensional nonconvex composite problems are popular in today’s
machine learning and statistical genetics research. Recently, Ghadimi and Lan [1]
proposed an algorithm to optimize nonconvex high-dimensional problems. There are
several parameters in their algorithm that are to be set before running the algorithm.
It is not trivial how to choose these parameters nor there is, to the best of our knowl-
edge, an explicit rule how to select the parameters to make the algorithm converges
faster. We analyze Ghadimi and Lan’s algorithm to gain an interpretation based on
the inequality constraints for convergence and the upper bound for the norm of the
gradient analogue. Our interpretation of their algorithm suggests this to be a damped
accelerated gradient scheme. Based on this, we propose an approach how to select
the parameters to improve convergence of the algorithm. Our numerical studies us-
ing high-dimensional nonconvex sparse learning problems, motivated by image de-
noising and statistical genetics applications, show that convergence can be made, on
average, considerably faster than that of the conventional ISTA algorithm for such
optimization problems with over 10000 variables should the parameters be chosen
using our proposed approach.
Keywords Accelerated Gradient · Composite Optimization · Nonconvex Optimiza-
tion
K. Yang
McGill University
1 https://arxiv.org/abs/2009.10629
E-mail: kai.yang2@mail.mcgill.ca
ORCID ID: 0000-0001-5505-6886
Extensions M. Asgharian 63 / 76 .Numerical Study for SCAD
10
AG
ISTA
5
0
log(gk − g ∗ )
−5
−10
−15
0 200 400 600 800 1000
k
i.i.d. i.i.d. ∥τ generate ∥
2
xi ∼ N (0, I) , εi ∼ N 0, σ 2 , y = Xτ generate + ε, σ 2 = 3 ,
τ generate ∈ R10006 is a sparse constant vector with 6 values of
1.23(intercept), 3, 4, 5, 6, 59 as true effect coefficients and 10000 values of
0. Start point: τ 0 = 110006 , a = 3.7, λ = 0.6.
Extensions 64 / 76 .Numerical Study for MCP
AG
8 ISTA
6
log(gk − g ∗ )
4
2
0
−2
−4
0 500 1000 1500 2000 2500 3000
k
Simulation settings here is same as before in SCAD, γ = 2.5, λ = 0.6.
Extensions 65 / 76 .casebase
JSS Journal of Statistical Software
MMMMMM YYYY, Volume VV, Issue II. doi: 10.18637/jss.v000.i00
casebase: An Alternative Framework For Survival
Analysis and Comparison of Event Rates
stat.ME] 22 Sep 2020
Sahir Rai Bhatnagar* Maxime Turgeon*
McGill University University of Manitoba
Jesse Islam James A. Hanley Olli Saarela
McGill University McGill University University of Toronto
1 https://arxiv.org/abs/2009.10264, Abstract
https://cran.r-project.org/package=casebase
In epidemiological studies of time-to-event data, a quantity of interest to the clinician
Extensions and the patient is the risk of an event given a covariate profile. However, methods relying 66 / 76 .Case-base sampling
Control group Screening group
75K
Population Size
50K
25K
0
0 5 10 15 0 5 10 15
Follow−up time
Case series Base series
Extensions 67 / 76 .Case-base sampling
• The unit of analysis is a person-moment.
• Case-base sampling reduces the model fitting to a familiar logistic
regression.
• The sampling process is taken into account using an offset term.
• By sampling a large base series, the information loss eventually
becomes negligible.
• This framework can easily be used with time-varying covariates (e.g.
time-varying exposure). We can fit any hazard λ of the following
form:
log λ(t; α, β) = g(t; α) + βX
• Different choices of the function g leads to familiar parametric
families:
▶ Exponential: g is constant.
▶ Gompertz: g(t; α) = αt.
▶ Weibull: g(t; α) = α log t
Extensions 68 / 76 .Classical Methods
Betting on Sparsity
A Thought Experiment
Motivating Dataset
Notre proposition
Résultats
Other applications
Extensions
Fonctions de pénalité non convexes
Analyse de survie
Orientations futures
Orientations futures 69 / 76 .Orientations futures
• ggmix est limité par le nombre d’individus (ne s’applique pas à
l’ensemble de la cohorte UK Biobank de 500k) → approximations de
rang inférieur de la matrice de parenté
• Problèmes de mémoire lorsque le nombre de covariables dans le
modèle dépasse 50k → stratégies de mappage de mémoire (par
exemple biglasso de Zeng et Breheny (2017))
• Extension aux données multivariées, longitudinales, combinaisons de
plusieurs cohortes → Plusieurs effets aléatoires.
Orientations futures 70 / 76 .Remerciements Orientations futures 71 / 76 .
Remerciements Orientations futures 72 / 76 .
Remerciements Orientations futures 73 / 76 .
Remerciements
• Masoud Asgharian (McGill)
• Tianyuan Lu (McGill)
• Yi Yang (McGill)
• Karim Oualkacha (UQÀM)
• Celia Greenwood (Lady Davis
Institute)
• Erica Moodie (McGill)
• James Hanley (McGill)
• Maxime Turgeon (UManitoba)
• Olli Saarela (UofT)
• Luda Diatchenko (McGill)
• UK Biobank Resource under project
number 27449. We appreciate the
generosity of UK Biobank volunteers
Orientations futures 74 / 76 .References
1. Yang K, Asgharian M, Bhatnagar SR (2020+). Improving Rate of
Convergence for Nonconvex Composite Programming. Submitted to
Optimization Letters. https://arxiv.org/abs/2009.10629.
2. Bhatnagar SR, Turgeon M, Islam J, Hanley JA, Saarela O (2020+).
casebase: An Alternative Framework For Survival Analysis and
Comparison of Event Rates. Submitted to Journal of Statistical
Software. https://arxiv.org/abs/2009.10264.
3. Bhatnagar SR, Yang Y, Lu T, Schurr E, Loredo-Osti JC, Forest M,
Oualkacha K, Greenwood CMT (2020). Simultaneous SNP selection
and adjustment for population structure in high dimensional
prediction models. PLoS Genetics 16(5): e1008766. DOI
10.1371/journal.pgen.1008766.
sahirbhatnagar.com
Orientations futures 75 / 76 .Session Info
R version 4.0.2 (2020-06-22)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Pop!_OS 20.10
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.10.so
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggmix_0.0.1 knitr_1.31
loaded via a namespace (and not attached):
[1] lattice_0.20-41 codetools_0.2-16 glmnet_4.1-1 foreach_1.5.1
[5] grid_4.0.2 magrittr_2.0.1 evaluate_0.14 highr_0.8
[9] stringi_1.5.3 Matrix_1.2-18 splines_4.0.2 iterators_1.0.13
[13] tools_4.0.2 stringr_1.4.0 survival_3.2-3 xfun_0.21
[17] compiler_4.0.2 shape_1.4.5
Orientations futures 76 / 76 .You can also read

















































