User Classification and Stock Market-Based Recommendation Engine Based on Machine Learning and Twitter Analysis
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Hindawi Mathematical Problems in Engineering Volume 2022, Article ID 4644855, 9 pages https://doi.org/10.1155/2022/4644855 Research Article User Classification and Stock Market-Based Recommendation Engine Based on Machine Learning and Twitter Analysis Prasad N. Achyutha ,1 Sushovan Chaudhury ,2 Subhas Chandra Bose ,3 Rajnish Kler ,4 Jyoti Surve ,5 and Karthikeyan Kaliyaperumal 6 1 Department of Computer Science and Engineering, East West Institute of Technology, Bangalore, India 2 Department of Computer Science and Engineering, University of Engineering and Management, Kolkata, India 3 Thapar Institute of Engineering and Technology, Patiala, India 4 Motilal Nehru College (Evening), University of Delhi, Delhi, India 5 Department of Information Technology, International Institute of Information Technology, Hinjewadi, Pune, India 6 IT@IoT-HH Campus, Ambo University, Ambo, Ethiopia Correspondence should be addressed to Sushovan Chaudhury; sushovan.chaudhury@gmail.com and Karthikeyan Kaliyaperumal; karthikeyan@ambou.edu.et Received 7 February 2022; Revised 1 March 2022; Accepted 8 March 2022; Published 22 April 2022 Academic Editor: Vijay Kumar Copyright © 2022 Prasad N. Achyutha et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. The stock market prices of the company vary in a daily fashion. The social media pattern usage of the company can be determined to find the sentiment score values. The dependency factor between the social media tweet platform and the performance of an organization can have how much effect on the stock prices is determined. The historical data from the Yahoo Finance APIs are taken for the unique company ID and then the probability of stock being good or bad is determined. Also, the tweets related to the company are scanned and analyzed to find the positive and negative scores. The concentration value connected to growth, the intensity of capital expenditure, and the volume of promotion were among the factors utilized in the stock’s modeling. This paper also takes the yearly finances of the end-user based on LIC payments, medical insurance payments, and average rent and then performs a classification of the user. Based on the user classification, companies are recommended to the end-user based on descending order of stock value. The average volume, average price, average market index, average daily turnover, and sentiment discrepancy index are based on the tweets of a company and the predicted value of its performance. For the classification of the user, we make use of the support vector machine algorithm. For the sentiment analysis of the tweets, the naı̈ve Bayes algorithm is made use of, and then stock classification is done based on mathematical modeling, which includes the sentiment analysis index. 1. Prime Investigation into a set of statements. Each statement is then analyzed to get the sentimental flow of the overall Twitter data and then The communication patterns of the company can be ana- generated into a matrix based on Twitter analysis. Find the lyzed to understand the performance of the company. The unique IDs of the products and then the total sentiment of effect of stock prices will depend upon multiple factors like the products is determined. This data can help change the communication on social media, Twitter, and history related recommendations to end users related to which company to the prices, along with other factors of the stock exchange. stocks are more suitable to trade or purchase. There are The publicly available data related to various companies and interesting flows among users who make use of unique social stock data obtained from Yahoo Finance can be used to media applications [1]. Most of the research in the field of analyze the patterns of stock. The tweets can be converted stock recommendation systems is concentrated in two areas:
2 Mathematical Problems in Engineering stock recommendation systems based on stock commentary 2. Motivation and pricing [2, 3]. The work will help in the prediction of sales along with the computation of price [4]. Currently, Since the market prices of any company have been changing stock recommendations based on price prediction are on a daily basis, it is necessary to find a solution to predict mostly based on numerical and statistical approaches, as well these figures. The novelty of the work lies in the linkage of as a series data model and a machine learning model [5, 6]. the social platforms, i.e., Yahoo with the Baiyes algorithm, There are channels like jabber and Microsoft teams that are and it has been found that Amazon shows the maximum used in the organization for internal communication and prediction rate. The social media platforms have been im- can learn the interests of the members along with other mensely used nowadays and are of great importance for effects on company performance [7]. The incorporation of observing, analyzing, and speculating on the trends of the various technologies, including data mining, deep learning, stock market. As the social platforms are directly linked to herd psychology, and other unorthodox technologies, into the economic, political, and social activities, which directly trade recommendations, has become a hot topic in the impacts their ups and downs in the stock market. Predicting present financial arena. Money net inflow is only utilized as a prices is the most complex task because of the varying nature stock recommendation strategy in a few researches [8, 9]. of prices. The value of a stock price is related to the sentiment Social media and e-mail data will be used by both intra and expressed in the market related to the volatile value for a interorganization communication. The applications help in stock. These values are helpful in finding the best price. capturing the behavior exhibited by mining the events and Trading is responsible for the fall and rise of the economies communications created by the company’s leadership and of the countries. The tools used to advise the customers on employees. Robustness and stability are the few factors that buying or selling stocks are stock brokerage applications. can be determined by analysis of the communication [10]. The tools make use of technical data and perform time series Data on stock market values is created in vast numbers on it. The media-related texts contain comments that have a and changes on a daily basis. The stock market is a complex commercial nature; the emotional data will then be analyzed and tough system in which people may either profit or lose to find the sentiments. Web crawler tools like twitter4j can their whole life savings [11]. In general, we believe that a be used to get comments specific to companies and then stock’s rise with significant trading volumes is related to a analyze the data to generate the sentiments for each of the high order to buy shares. In order to determine the massive tweets. Then, across all the tweets, a total sentiment score is order net flow of stock, we must study the stock trading computed for each of the companies. volume and churn. Cash net flow and money flow are sep- The various disadvantages in the existing system which arate concepts [12, 13]. As per the theory suggested in can be rectified are communication, the failure or success of a critical business (i) History data from Yahoo Finance API are used for function will depend upon the communication of employees. performing the recommendations and does not take This will also have an impact on the performance of em- into consideration the public sentiments expressed ployees contributing to the success or failure of the product by the company profiles or employees, as well as the [14]. It has been noted that money flow is often greater than general public. zero, while money net flow is less than zero. Separately, the money net flow is more than zero, but the huge order net (ii) The users for whom suggestions are made are not movement is below zero [15, 16]. The model is created based classified, so even if a middle-income group is on the merging of the company with another and new startup suggested, very high-value stocks are suggested, and acquisitions, process changes, and bankruptcy can be studied hence it is not adaptive in nature. Hence, based on to find the performance of the company on the stock trade the monetary spending of the end users, the clas- platform [17]. A stock price prediction is significant since it is sification is not performed. utilized by both businessmen and ordinary people. People who participate in stock market activities will either make 3. Background money or lose their whole life savings. It is a broken system. Because price fluctuations are influenced by a wide range of The variables used in modeling the stock include concen- elements such as news, social media data, fundamentals, tration value related to growth, the intensity of capital in- corporate output, government bonds, historical pricing, and vestment, and the amount of advertising. These factors will national economics, building an appropriate model is tough help in the classification of the high-attractive or low-at- [18]. The historical data analysis of stocks [19] and rule-based tractive company. The profit or loss of the company can be stock formation [20]. Multiple variables are created for determined based on the firm’s variables computation. The modeling the stock performance, namely, pattern flow, behavior of study for employees can take into account feedback provided by employees and the public, and specific factors like formal entity, informal entity, planning nature, events. The performance model involves a survey on job rewarding points, along with skills and manager influence, analysis, the performance of an employee, and the produc- are important for an organization’s success [23]. tivity of an individual as well as a group [21]. A few more The technical performance of the projects will depend models work on communication from subordinates, the upon two models of communication. The first model is supervisor of a team, quality of information, and autocor- direct communication with the project team, and the second relation computed between the set of employees [22]. model consists of an intermediate person who
Mathematical Problems in Engineering 3 communicates on behalf of the team. The communication 4.2. Login. This module is responsible for authentication of values will involve the type of code used, communication the end user. If the validation is successful, then the user can between products, and models followed for collaboration access the application. It can be either a customer or an within the organization and outside the organization [24]. admin. If t is a customer, based on the financial data for the Real-world settings are used in financial markets for pre- end-user, the classification of the user and recommendations diction of stock performance. The weblogs are taken, the of the stock are made. For an admin, the sentiment analysis estimation of various emotions is done, and then stock is done, company-wise stock classification, and then the market prices are determined. A variety of characteristics classification of companies, and finally price-based recom- like anxiety value, worry level, and fear diagnostics can be mendations are made. used in finding the stock influence [25]. The development project groups will vary in terms of group longevity, which is defined as the amount of time 4.3. Classification Using Random Forest. The various fi- people work together [26]. This information can be nancial factors like expenses, medical insurance, PF, life revealed inside or outside the organization. Both the insurance, child education, and cost to the company are used technical as well as the communication performance are as the input factors along with the training data set present in very important for the tenure composition of groups and user finance.arff and then random forest application with will affect the stock performance of the company [27]. The five different decision trees are executed with the C4.5 al- quality of service for the organization will depend upon the gorithm to predict the output class as either GOLD, SILVER, profits. The stock price changes and its good impression is PLATINUM, or BRONZE. created by using communication and control processing of The figure shows the proper steps for the presented the efficient process to maintain the company, and the method. This begins with the registration and then the login second is the results that the new process is producing. with credentials. The negative and positive score of the These steps help in securing a better market position in the company depends on the tweets related to any company. stock market [28]. The search for information on the web is The following are the steps involved in random forest done by making use of accounting and market-based process: random forest is a flexible, user-friendly machine measures in order to compute the risk. The strategy is learning approach that, in most circumstances, produces generally communicated to the stakeholders. Few com- great results even when no hyperparameters are adjusted. It panies, for example, general electric had a variety of di- is also one of the most commonly utilized algorithms due to visions, which was very difficult for the analysts to perform its simplicity and adaptability (it can be used for both influence on the stock market and had negative effects on its classification and regression tasks). price [29]. Communication within a large organization has (1) Read all the datasets from the history data with the an impact on the stock price behavior. The properties and following attributes: the datasets are collected in the structure of the data can be used for training of the model. format of having expenses, medical insurance, PF, From the model, it is evident that there is more diverse life insurance, child education, and cost to the communication. Mutual, interpersonal communication company. The admin will be able to view the data will affect the organizational crisis and can lead to failure in sets. the organization [30, 31]. (2) Calculate the number of instances of historical data. (3) Divide the entire data set into multiple groups 4. Methodology randomly. The methodology involves the classification of users into (4) For each of the subsets, execute the C4.5 algorithm. various categories: GOLD, SILVER, PLATINUM, and (5) After executing the decision tree, the output of the BRONZE. The classification is done based on annual gross decision tree which corresponds to the maximum income, health insurance, rent, and other financial factors. class is treated as the user class. The financial data from Yahoo Finance is taken for the companies. The Twitter data is taken and then found company-wise positive and negative scores. After that, the 4.4. Hashtag Storage. This module is responsible for the price computation is done, along with the classification of storage of the hashtag. The hashtag will be stored against the companies. For each kind of user, the different classes of company name. The hashtag must be a valid one that belongs companies are recommended. The different modules can be to the Twitter data along the path. described as follows, as shown in Figure 1. 4.5. OAuth API for Twitter. The OAuth API for Twitter is 4.1. Registration. This module is executed by the end cus- responsible for communication with respect to our appli- tomer. Different entries like username, password, demo- cation and the Twitter application. This communication will graphic details, gender, and if the username or password happen based on a secret key and an OAuth token. The does not already exist, then the user is allowed to register, Twitter application will then validate the OAuth token and, otherwise registration fails. if it is valid, only communication will happen.
4 Mathematical Problems in Engineering Classification Registration Login User Finance Using Random Forest Real Time Stock Hash Tag OAuth API Data Collection History Data sets Storage for Twitter Using Twitter from Yahoo Finance Positive & Negative Keywords User Interface Polarity Company Sentiment Sentiment Computation Based Polarity Index Discrepancy Tweet wise Computation Computation Index Recommendation Classify stock companies Stock Price System into four categories based on Prediction stock value Figure 1: Methodology for the proposed system. 4.6. Data Collection Using Twitter. The set of hashtags stored 4.11. Company-Based Polarity Computation. This module in the application is scanned. The count of hashtags is taken. will find the total positive and total negative sentiment for For each of the hashtags, the list of tweets corresponding to the entire company based on each individual tweet senti- the hashtag is taken and then stored in a valid format against ment for the company. The company-based sentiments can the company name. be computed using the process described in Algorithm 2. 4.7. Real-Time Stock History Datasets from Yahoo Finance. 4.12. Sentiment Index Computation. The sentiment index The real-time stock history datasets are obtained by calling the computation is performed based on the following equation Yahoo Finance API. The Yahoo Finance API will be called by for each of the tweets: passing the unique Yahoo Finance API key and the output will be real data obtained from the finance API average over 1 + Npositive the year with the values of volume, marketing index, daily SI � ln . (1) 1 + Nnegative turnover, and price. In a similar fashion, the process is re- peated for all the keys related to the Yahoo Finance API. 4.13. Sentiment Discrepancy Index. This module is re- 4.8. Positive Keywords. This is a set of keywords that are used sponsible for computing the sentiment discrepancy index for training positive sentiments. for the stocks of the companies based on the following equation: 4.9. Negative Keywords. This is a set of keywords responsible (Npositive − Nnegative) for training the negative sentiments for the naı̈ve Bayes SDI � 1 − . (2) method. Npositive + Nnegative 4.10. Polarity Computation Tweet Wise. This module will be used to provide the training of the naı̈ve Bayes algorithm 4.14. Real-Time Yahoo Stocks for Company. This is respon- with respect to positive and negative classes. The output will sible for retrieving the real-time stocks for the company be a class that can be either POSITIVE or NEGATIVE. The based on its unique company name and then finding average Algorithm 1 used for the classification of tweets is described values of various stock attributes like volume, market index, as follows: daily turnover, and price.
Mathematical Problems in Engineering 5
Input: tweet description, positive keywords, and negative keywords
Steps
(1) Obtain the tweets related to registered companies
(2) Measure the count of the tweets
(3) For each of the tweet
(a) Obtain the tweet description
(b) Convert the description into a set of statements using a delimiter
(c) Measure the sentiment score for each statement based on the probability of positive or negative sentiment based on words of
specific sentiment class
(d) If the positive sentiment score is higher than or equal to the negative sentiment, then the positive sentiment is incremented by a
factor of 1, otherwise negative sentiment is increment
(e) Like this, the total sentiment for the entire tweet is determined by doing a summation from all statements
(4) For each tweets, the storage is done based on a total score of sentiment in the format of {TweetId, Positive Sentiment, Negative
Sentiment, Company Name}.
ALGORITHM 1: Tweet sentiment analysis.
Input: tweet-based sentiment analysis
Output: company-based sentiment score process
(1) Find the unique company names from the tweet sentiment matrix
(2) For each of the companies, compute the following: PS(c) � nk�0 PS(k) and PS(c) � nk�0 PS(k)
where PS(k) is the positive sentiment of kth tweet for company c, NS(k) is the negative sentiment of kth tweet for company c, PS(c)
is the total positive sentiment for the company, and NS(c) is the total negative
(3) The total sentiment for each company will be computed as {Company Name, Total Positive, Total Negative}
ALGORITHM 2: Company-based sentiments.
4.15. Stock Price Prediction. The stock price prediction for 5. Experimental Results
the company is done based on various real-time Yahoo stock
parameters along with sentiment index values. The stock This section describes the application snapshots for the
price is computed using the following formula: developed methodology. Figure 2 shows the end consumer
performing the registration. The input will be user id, first
Pi � 0.6238 ∗ Pi − 1 + 0.0455 ∗ Vi − 1 + 0.0213 ∗ TRi − 1 name, last name, e-mail, username, and password. If no two
+ 0.0316 ∗ Mi − 1 + 0.0423 ∗ S DI + β. consumers have the same user ID or same e-mail, then the
registration process will be completed; otherwise, the reg-
(3)
istration process will fail. Figure 3 shows the sign-in process.
This module is responsible to allow either the admin-
istrator or the consumer to perform valid authentication for
4.16. Classification of Company into Different Categories. the end consumer. If the authentication fails, then a role-
The stock price is computed for each company level. The based user is allowed to access various functionality of
sorting of the company names is performed based on the application; otherwise, failure happens.
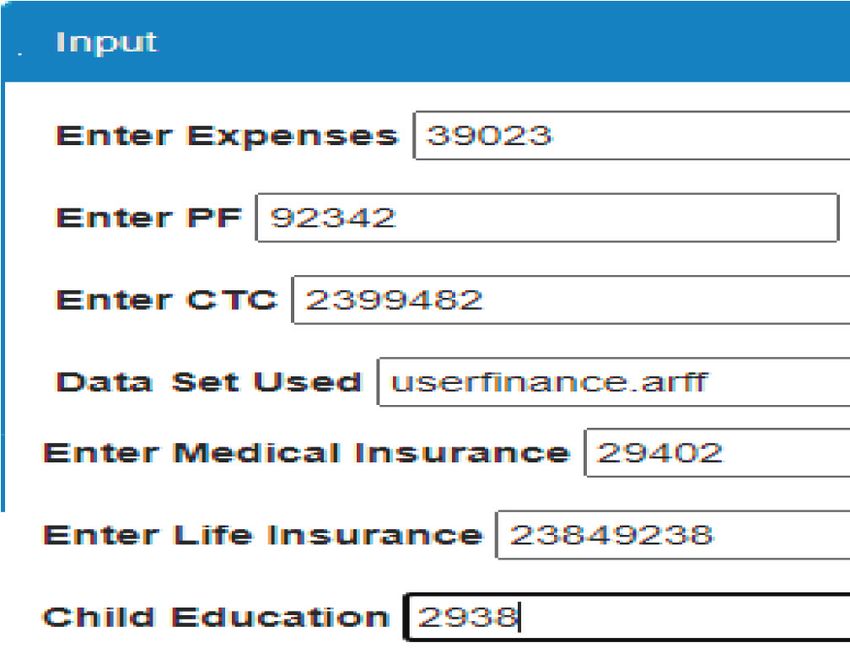
stock price value. After that, the company is segmented into Figure 4 shows the input for user classification. The
four different categories, namely, GOLD, SILVER, PLATI- classification includes expenses, PF, cost to company.
NUM, and BRONZE. Dataset used will be defaulted to userfinance.arff, which
contains the training data in the class path, medical in-
surance, life insurance, and child education.
4.17. Recommendation System. The recommendation sys- Figure 5 shows the output for the user classification. As
tem is responsible for providing the names of the com- shown in Figure 5, the successful message for the end
panies to the end consumers based on customer consumer, which is the prediction of the category, is suc-
classification and company classification. The user classi- cessful. The second panel is the label associated with the class
fication data is first obtained based on classification using which has been predicted as the output, and the third panel
random forest and then classification of company. First, is the details of each class number along with the class label.
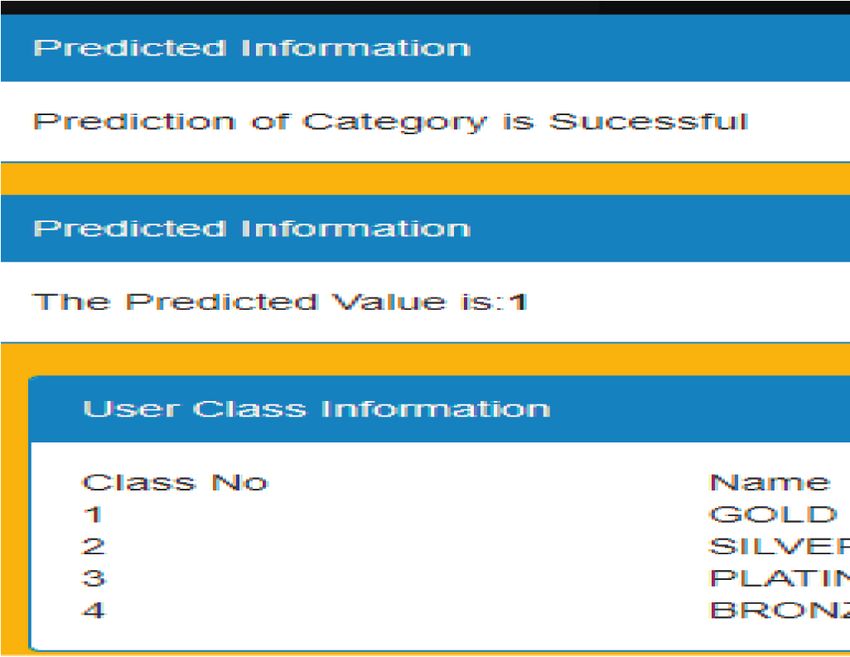
based on the session, the user class is obtained. The Figure 6 shows the grid in which an end user can see the
companies related to the user class are filtered. After that, class associated with him/her after the classification algo-
the recommendations of the companies are performed for rithm has been executed.
the specific class based on the descending order of total Figure 7 shows the Yahoo Finance output for real-time data
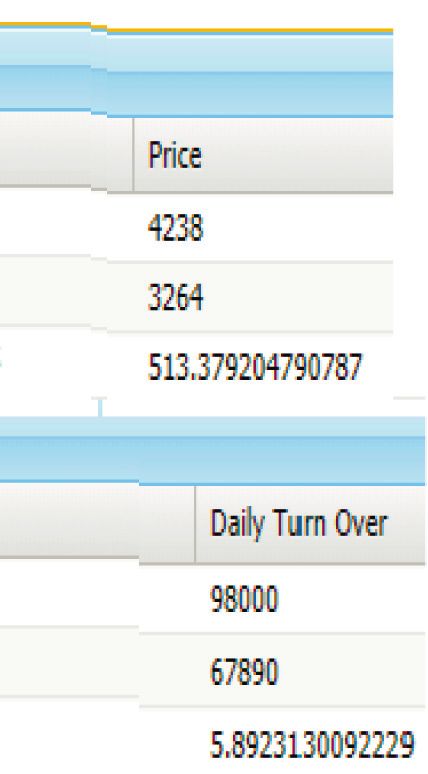
stock price. retrieval for various companies like YATRA, Amazon, and
6 Mathematical Problems in Engineering Figure 2: Registration consumer. Figure 3: Sign-in process. Figure 4: Input for user classification.
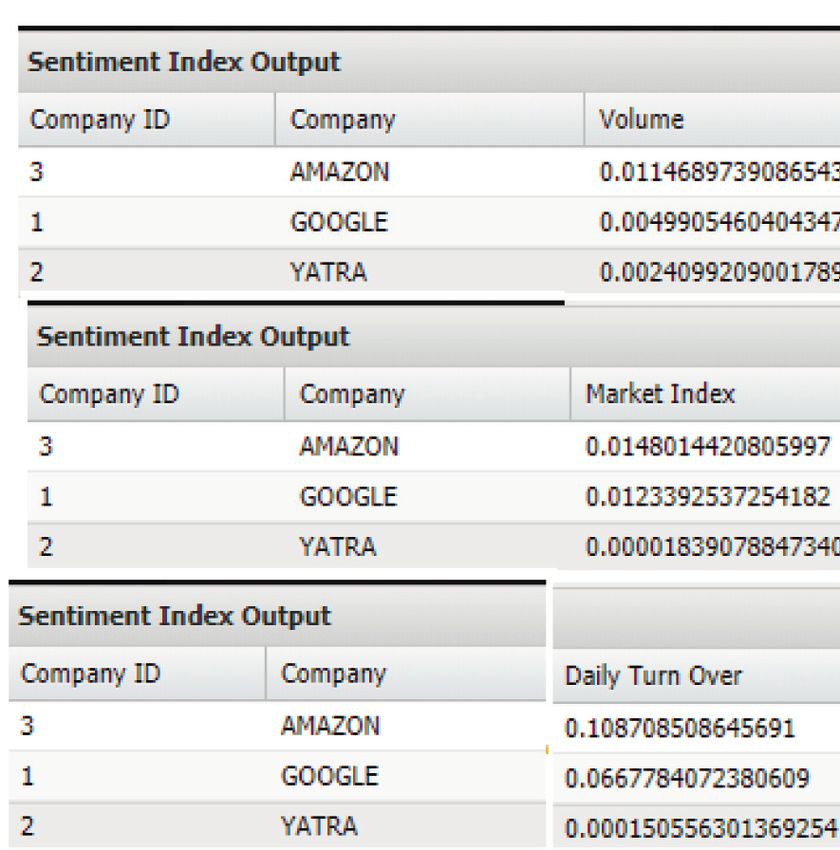
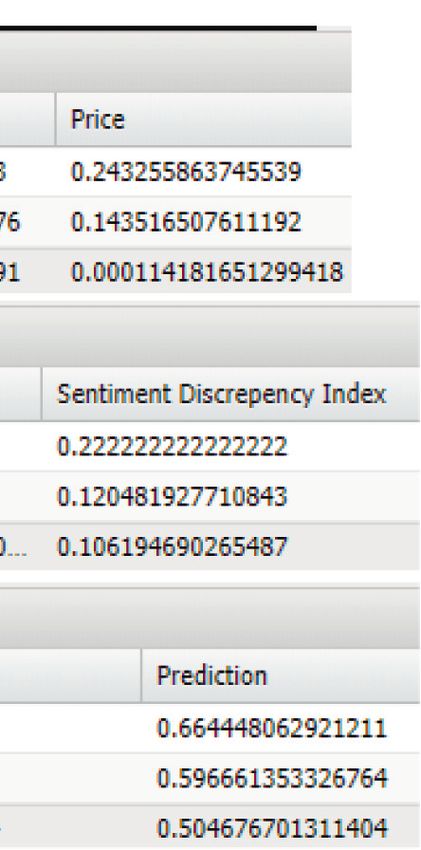
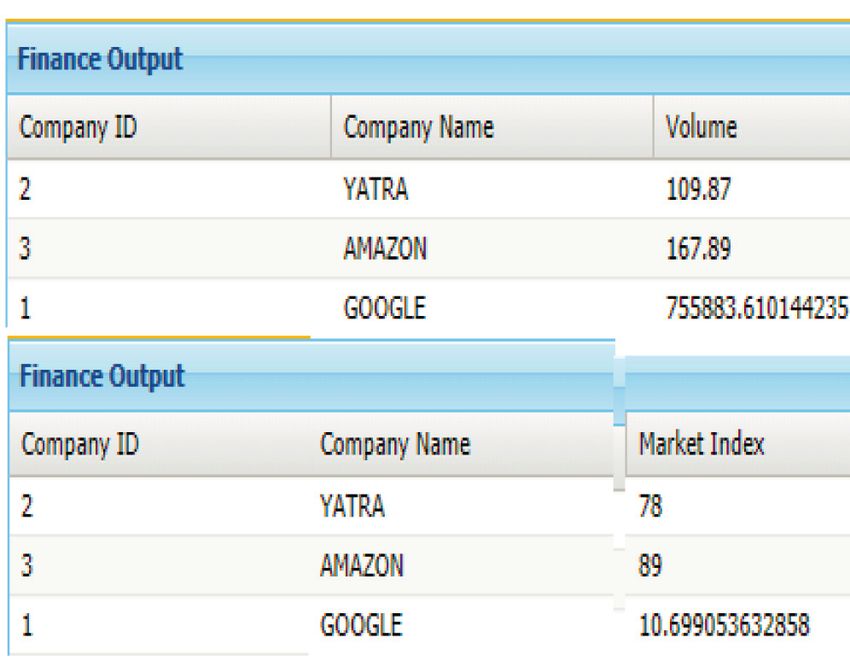
Mathematical Problems in Engineering 7 Figure 5: User classification output from random forest. Figure 6: User class history. Figure 7: Finance output for Yahoo Finance. Google, and the attributes are volume, price, market index, and 5.1. Analysis. Since the company’s stock market values daily turnover. The time cost variables are compared in the fluctuate regularly, to establish the sentiment score values, above figure for three companies. The YATRA has maximum we should look at the company’s social media usage pat- values for all the real-time outputs. These values play a key role terns. How big of an impact the social media tweet platform in predicting the stock market price. has on stock prices are governed by the dependence factor. Figure 8 shows the sentiment recommendations. The A job analysis, employee performance, and individual and average volume, average price, average market index, av- group productivity are all part of the performance model. erage daily turnover, and sentiment discrepancy index based The GOLD, SILVER, PLATINUM, and BRONZE classifi- on the tweets of a company and the predicted value of cations are used in the methodology. The categorization is performance are described. based on a variety of financial parameters, including yearly Figure 9 shows the company’s prediction graphs. The gross income, health insurance, rent, and other expenses. In more horizontal the graph is, the better the company’s the figures, the Yahoo Finance output for real-time data performance. The y axis is the name of the company, and the retrieval for YATRA, Amazon, and Google has been x axis is the value of the prediction. displayed.
8 Mathematical Problems in Engineering Figure 8: Sentiment recommendations. Conflicts of Interest YATRA The authors declare that there are no conflicts of interest regarding the publication of this paper. Company ID GOOGLE References [1] G. Miller, “Social scientists wade into the tweet stream,” Science, vol. 333, no. 6051, pp. 1814-1815, 2011. [2] S. Meri Al Absi, A. Hasan Jabbar, S. Oudah Mezan, B. Ahmed AMAZON Al-Rawi, and S. Thajeel Al_Attabi, “An experimental test of the performance enhancement of a Savonius turbine by modifying the inner surface of a blade,” Materials Today 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Proceedings, vol. 42, pp. 2233–2240, 2021. Prediction Value [3] M. K. Loganathan, B. Mishra, C. M. Tan, T. Kongsvik, and Figure 9: Company prediction graphs. R. N. Rai, “Multi-Criteria decision making (MCDM) for the selection of Li-Ion batteries used in electric vehicles (EVs),” Materials Today Proceedings, vol. 41, pp. 1073–1077, 2021. 6. Conclusion [4] W. Duan, B. Gu, and A. B. Whinston, “Do online reviews matter?-an empirical investigation of panel data,” Decision In this paper, random forest has been used in order to Support Systems, vol. 45, no. 4, pp. 1007–1016, 2008. classify the user’s finance. The forecast and various stock [5] M. Demkah and D. Bhargava, “Gamification in education: a attributes are obtained based on real data, which is extracted cognitive psychology approach to cooperative and fun using Yahoo Finance API. The company-based hashtags are learning,” in Proceedings of the Amity International Confer- found and for each hashtag, the Twitter data is obtained. ence on Artificial Intelligence (AICAI), pp. 170–174, IEEE, From the data, the sentiment computation is made on each Dubai, 2019 February. tweet. After that, the total sentiments are found out. The [6] A. Kumar, V. Jagota, R. Q. Shawl et al., “Wire EDM process parameter optimization for D2 steel,” Materials Today Pro- sentiment computation index is found for all companies. ceedings, vol. 37, pp. 2478–2482, 2021. Finally, the prediction is made, which is nice to invest in [7] B. Li, K. C. C. Chan, and C. Ou, ““Public sentiment analysis in based on real stock prices along with Twitter data as well. twitter data for prediction of a company’s stock price Finally, the companies are recommended based on their movements,” in Proceedings of the IEEE International Con- specific classification group. The companies are listed based ference e-Bus. Engineering (ICEBE), pp. 232–239, Guangzhou, on descending order of the company names. China, November 2014. [8] J. Bhola, S. Soni, and G. K. Cheema, “Recent trends for se- Data Availability curity applications in wireless sensor networks–A technical review,” in Proceedings of the 2019 6th International Con- The data used in this study will be available from the author ference on Computing for Sustainable Global Development upon request. (INDIACom), pp. 707–712, IEEE, Delhi, India, 2019 March.
Mathematical Problems in Engineering 9 [9] H. Li, M. Shabaz, and R. Castillejo-Melgarejo, “Imple- Conference Weblogs Social Media (ICWSM), pp. 59–65, mentation of python data in online translation crawler Dublin, Ireland, June 2010. website design,” International Journal of System Assurance [26] M. N. Kumar, V. Jagota, and M. Shabaz, “Retrospection of the Engineering and Management, pp. 1–9, 2021. optimization model for designing the power train of a formula [10] B. Collingsworth, R. Menezes, and P. Martins, “Assessing student race car,” Scientific Programming, vol. 2021, Article ID organizational stability via network analysis,” in Proceedings 9465702, 9 pages, 2021. of the IEEE Symposium Computer Intell. Financial Eng., [27] R. Katz, “The effects of group longevity on project commu- pp. 43–50, Nashville, TN, USA, March 2009. nication and performance,” Administrative Science Quarterly, [11] B. Ramzan, I. Sarwar Bajwa, N. Jamil, R. U. Amin, S. Ramzan, vol. 27, no. 1, pp. 81–104, 1982. F. Mirza, and N. Sarwar, “An intelligent data analysis for [28] V. A. Zeithaml, L. L. Berry, and A. Parasuraman, “Com- recommendation systems using machine learning,” Scientific munication and control processes in the delivery of service Programming, vol. 2019, Article ID 5941096, 20 pages, 2019. quality,” Journal of Marketing, vol. 52, no. 2, pp. 35–48, 1988. [12] J. Bhola, M. Shabaz, G. Dhiman, S. Vimal, P. Subbulakshmi, [29] R. B. Higgins and B. D. Bannister, “How corporate com- and S. K. Soni, “Performance evaluation of multilayer clus- munication of strategy affects share price,” Long Range tering network using distributed energy efficient clustering Planning, vol. 25, no. 3, pp. 27–35, 1992. with enhanced threshold protocol,” Wireless Personal Com- [30] C. Dou, L. Zheng, W. Wang, and M. Shabaz, “Evaluation of munications, pp. 1–15, 2021. urban environmental and economic coordination based on [13] V. Jagota and R. K. Sharma, “Interpreting H13 steel wear discrete mathematical model,” Mathematical Problems in behavior for austenitizing temperature, tempering time and Engineering, vol. 2021, Article ID 1566538, 11 pages, 2021. temperature,” Journal of the Brazilian Society of Mechanical [31] Y. S. Sagar and N. Achyutha Prasad, “Charm: a cost-efficient Sciences and Engineering, vol. 40, pp. 1–12, 2018. multi-cloud data hosting scheme with high availability,” In- [14] D. J. Barrett, “Change communication: using strategic em- ternational Journal for Technological Research in Engineering, ployee communication to facilitate major change,” Corporate vol. 5, no. 10, pp. 2347–4718, 2018. Communications: An International Journal, vol. 7, no. 4, pp. 219–231, 2002. [15] M. Sehgal and D. Bhargava, “Knowledge mining: an approach using comparison of data cleansing tools,” Journal of Infor- mation and Optimization Sciences, vol. 39, no. 1, pp. 337–343, 2018. [16] A. Sharma and R. Kumar, “Service-level agreement-energy cooperative quickest ambulance routing for critical healthcare services,” Arabian Journal for Science and Engineering, vol. 44, no. 4, pp. 3831–3848, 2019. [17] K. Yates, “Effective employee communication linked to greater shareholder returns, watson wyatt study finds,” 2003, http://www.watsonwyatt.com/render.asp?catid� 1&id�12092. [18] J. H. Wang and J. Y. Leu, “Stock market trend prediction using ARIMA-based neural networks,” in Proceedings of the In- ternational Conference on Neural Networks (ICNN’96), pp. 2160–2165, IEEE, Washington, DC, USA, June 1996. [19] M. C. Wu, S. Y. Lin, and C. H. Lin, “An effective application of decision tree to stock trading,” Expert Systems with Appli- cations, vol. 31, no. 2, pp. 270–274, 2006. [20] E. Vamsidhar, K. Varma, P. S. Rao, and R. Satapati, “Pre- diction of rainfall using backpropagation neural network model,” International Journal of Computational Sciences and Engineering, vol. 2, no. 4, pp. 1119–1121, 2010. [21] C. W. Down, G. C. Phillip, and A. L. Pfeiffer, “Communi- cation and organizational outcomes,” in Handbook of Or- ganizational Communication, G. Goldhaber and G. Barnett, Eds., Ablex, Norwood, NJ, USA, 1988. [22] P. G. Clampitt and C. W. Downs, “Employee prbetween communication and productivity: a field study,” Journal of Business Communication, vol. 30, no. 1, pp. 5–28, 1993. [23] G. S. Hansen and B. Wernerfelt, “Determinants of firm performance: the relative importance of economic and or- ganizational factors,” Strategic Management Journal, vol. 10, no. 5, pp. 399–411, 1989. [24] W. W. Burke and G. H. Litwin, “A causal model of organi- zational performance and change,” Journal of Management, vol. 18, no. 3, pp. 523–545, 1992. [25] E. Gilbert and K. Karahalios, “Widespread worry and the stock market,” in Proceedings of the 4th International AAAI
You can also read

















































