TweeMe: A Multimodal Approach to Detect Memes on Twitter Platform - Paschalis Frangidis
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

ARISTOTLE UNIVERSITY OF THESSALONIKI
TweeMe: A Multimodal Approach to
Detect Memes on Twitter Platform
Paschalis Frangidis
Elaboration of dissertation as part of
Web and Data Science M.Sc. Programme
MSc Student
Computer Science Department
March 6, 2021
Statement Of Authorship
I, Paschalis Frangidis, declare that the thesis with title “TweeMe: A Multimodal
Approach to Detect Memes on Twitter Platform” and the work presented in it are a
genuine work of mine. I ensure that:
This work has taken place wholly or mainly during my candidacy for graduate
studies at this university.
Wherever any part of this dissertation has previously been used for the acquisition
of a degree or other qualification in this or another university, this is clearly stated.
Wherever I have consulted the third-party work published, this is correctly at-
tributed.
Wherever I have cited from third-party work, the source is always given. With the
exception of these quotes, this thesis is entirely my personal work
I have cited all the utility sources.
Wherever this thesis is based on collaborative work of my own and of others, I have
made it clear which pieces have been made by others and how I contributed.
Signature: Frangidis Paschalis
Date: March 12, 2021
i
If something is true, no amount of wishful thinking will change it.
Richard Dawkins
Aristotle University of Thessaloniki
Abstract
MSc Student
Computer Science Department
Master’s Degree
Frangidis Paschalis - Student Registration Number: 51
Every day thousands of social media users appear online to post their thoughts or
see their news feed. Meme images or for simplification memes, which are images that
contain sarcastic content in top of a commonly used image template, are very common
entities on social networks and widely used from most users. This thesis addresses the
task of meme detection on social networks using a multimodal approach that is based
on image features along with post and user metadata.
The current dissertation addresses meme detection by overtaking the simple usage
of state-of-the-art models for image classification that is mainly the case in all of the
previous works. The proposed approach introduces features from the metadata of the
post and from the historic record of the user to surround the image ones. More specif-
ically, features like sentiment scores and part of speech (POS) counts and ratios are
extracted from every Tweet, while for every user, his last 75 Tweets are retrieved and
then popularity scores are extracted for the combination of them. Additionally, word
vectors are created for every Tweet’s text in order for the textual features to be included
in the proposed approach. Text and metadata features enhance the predictions of image-
only models regarding meme detection, hence state-of-the-art or competitive models are
exploited to utilize them. The total proposed architecture is more robust and able to
be applied in a social media platform as it combines all these characteristics that make
memes so commonly used.
In particular, Chapter 1 describes the task at hand analyzing the main concept that
this thesis is based on highlighting the amount of information that is embedded in a
meme image and its multiple usages in most contemporary social networks. Nowadays,
most people have an active account in at least one social media platform and use them
in order to share their thoughts and concerns, to communicate with their friends and
acquaintances or even learn the news. A main way that they do that is by posting meme
images, images that use humor, sarcasm, or other positive and negative emotions as the exchange channel. The detection of these images can provide supplementary information in other topics like event detection and hate mitigation. Overall, here are presented all the traits that make memes so commonly used in social networks, while the open issues regarding meme detection are emphasized. Last, the contributions that advance the relevant literature are displayed. In Chapter 2, fundamental concepts that are later required are described. In this scope, all the different definitions and equations that are needed to understand neural networks - which are the main building blocks of architecture that this dissertation proposes - are included. Chapter 3 presents the related work, all the researches that are most associated with the topic addressed here. Previous works that cope with meme detection or meme analysis in general are underlined, while works that cope with image or text classification are also included as they form the basis of the proposed architecture. These works are compared with each other, while the open issues which the current dissertation aims at addressing are also highlighted. Moreover, in Chapter 4 the end-to-end architecture that is proposed for meme detec- tion is displayed and analyzed. This architecture can be broken in three individual parts or modules based on the features that they process and harness. The first one takes as input the containing images of the Twitter post and classifies them into memes or not (Image Classification Module). Three pretrained image classification neural networks that achieve state-of-the-art results or ones that can be compared with them have been put to test. The other two modules utilize the text and metadata from the Tweet itself. Text Classification Module takes as input the text that user includes in their post. The text is preprocessed by removing unnecessary strings and then a vector representation is created for it. This representation is subsequently fed into the model that makes the prediction of whether the original text should belong to a post with a meme or not. The final module, which is called Metadata Classification Module, is associated with the metadata extracted by both the user and the Tweet. These features are concatenated in a single vector and used to test two proposed models for this module. Finally, these modules are all tested either each one by itself or in different combinations and the one with the highest results is the one selected. Chapter 5 reviews the results defined by the previous described modules. These results verify the proposed multimodal approach on detecting memes on social media networks. First, for each proposed module all the candidate models are tested and the best one for each of them is extracted. Next, the modules are merged together into four different combinations, three that contain two modules at a time and one that joins all
the modules. As it is shown from the reported results, the two modules of metadata and text classification yield better results than the image-based module when they are joined with it in a single architecture. Additionally, the combination of all three modules also edges out the image-only models, although it is less accurate than the other two presented combinations. Finally, in Chapter 6, the current research comes to an end with a discussion over the results, the presentation of the limitations that affected it and some potential directions for future research that will cope with meme detection.

Αριστοτέλειο Πανεπιστήμιο Θεσσαλονίκης
Περίληψη
Σχολή Θετικών Επιστημών
Τμήμα Πληροφορικής
Μεταπτυχιακό Πρόγραμμα Επιστήμης Δεδομένων και Παγκόσμιου Ιστού
Φραγγίφης Πασχάλης - ΑΕΜ: 51
TweeMe: Μια Πολυτροπική Προσέγγιση στον Εντοπισμό Μιμιδίων στο Twitter
Καθημερινώς, χιλιάδες χρήστες κοινωνικών μέσων χρησιμοποιούν το ίντερνετ για να
δημοσιεύουν τις σκέψεις τους ή να ενημερωθούν για τις τρέχουσες ειδήσεις. Τα μιμίδια
(μτφρ. ‘Memes’) είναι εικόνες που περιέχουν σαρκαστικό περιεχόμενο βασισμένο πάνω σε
ένα ευρέως χρησιμοποιούμενο πρότυπο εικόνας. Ο όρος μιμίδιο αποτελεί αντιδάνειο από
τον αγγλικό όρο meme και δημιουργήθηκε από τον διάσημο ΄Αγγλο βιολόγο και συγγραφέα
Ρίτσαρντ Ντόουκινς στο βιβλίο του “Το Εγωιστικό Γονίδιο” (1976). Στο συγκεκριμένο
έργο, ο Ντόουκινς, θέλοντας να αντιπαραβάλλει την πολλαπλασιαστική συμπεριφορά των
γονιδίων (μτφρ. ‘Genes’) με το μεγάλο βαθμό μίμησης που απαντάται στις τέχνες και τον
πολιτισμό, δημιούργησε τη συγκεκριμένη λέξη. Η χρήση των μιμιδίων είναι αρκετά συνήθης
στα κοινωνικά δίκτυα και αξιοποιούνται άρδην από τους περισσότερους χρήστες. Αυτή η
διατριβή ασχολείται με το έργο της ανίχνευσης μιμιδίων σε κοινωνικά δίκτυα χρησιμοποιών-
τας μια πολυτροπική προσέγγιση που βασίζεται τόσο στα χαρακτηριστικά μιας εικόνας όσο
και στα μεταδεδομένα των δημοσιεύσεων και των χρηστών στις οποίες ανήκει.
Η τρέχουσα διατριβή προσεγγίζει την ανίχνευση μιμδίων πέρα από την απλή χρήση
state-of-the-art μοντέλων για την ταξινόμηση εικόνας που συμβαίνει κυρίως σε όλες τις
προηγούμενες εργασίες. Η προτεινόμενη προσέγγιση εισάγει χαρακτηριστικά από τα μεταδε-
δομένα των δημοσιεύσεων καθώς και από το πρόσφατα αναρτημένο ιστορικό του χρήστη
για να προσεγγίσει το είδος της εικόνας. Πιο συγκεκριμένα, λειτουργίες όπως βαθμολογίες
συναισθημάτων και μέρων του λόγου, μετρούνται και ποσοστικοποιούνται και στην συνέχεια
εξάγονται από κάθε Tweet, ενώ για κάθε χρήστη, οι τελευταίες 75 αναρτήσεις του ανακτών-
ται και στη συνέχεια εξάγονται οι βαθμολογίες δημοτικότητάς του. Επιπλέον, διανύσματα
λέξεων δημιουργούνται για κάθε αναρτημένο κείμενο προκειμένου να συμπεριληφθούν τα
γλωσσικά χαρακτηριστικά στην προτεινόμενη προσέγγιση. Τα γλωσσικά χαρακτηριστικά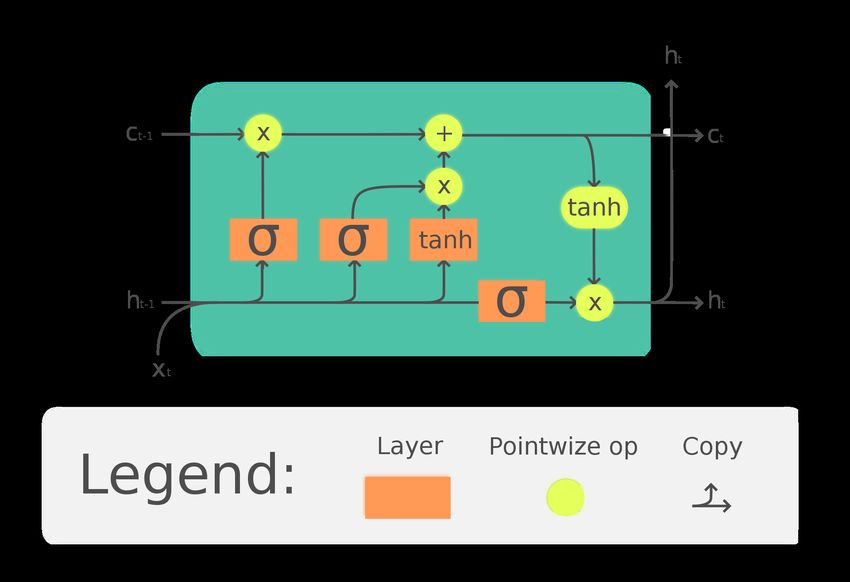
και τα μεταδεδομένα βελτιώνουν τις προβλέψεις των μοντέλων που περιλαμβάνουν μόνο εικόνα όσον αφορά την ανίχνευση μιμιδίων, επομένως τα πιο σύγχρονα ή ανταγωνιστικά μοντέλα είναι αυτά που χρησιμοποιούνται. Η συνολική προτεινόμενη αρχιτεκτονική είναι πιο κατάλληλα για εφαρμογή σε μια πλατφόρμα κοινωνικών μέσων, καθώς συνδυάζει όλα αυτά τα χαρακτηριστικά που κάνουν τα μιμίδια να χρησιμοποιούνται τόσο ευρέως στα μέσα κοινωνικής δικτίωσης. Συγκεκριμένα, το Κεφάλαιο 1 περιγράφει τη βασική ιδέα της εργασίας, αναλύοντας το κύριο θέμα πάνω στο οποίο είναι βασισμένη, να τονίσει δηλαδή τον όγκο της πληροφορίας που ενυπάρχει σε ένα μιμίδιο και τις πολλαπλές χρήσεις του στα περισσότερα σύγχρονα κοινωνικά δίκτυα. Στην εποχή μας, τα περισσότερα άτομα έχουν έναν ενεργό λογαριασμό σε τουλάχιστον μία πλατφόρμα κοινωνικών μέσων και τους χρησιμοποιούν προκειμένου να μοιραστούν τις σκέψεις και τις ανησυχίες τους, να επικοινωνήσουν με τους φίλους και τους γνωστούς τους ή ακόμη και να ενημερωθούν για τις ειδήσεις. ΄Ενας κύριος τρόπος που το κάνουν αυτό είναι μέσω της δημοσίευσης ενός μιμιδίου, εικόνων που χρησιμοποιούν χιού- μορ, σαρκασμό ή άλλα θετικά και αρνητικά συναισθήματα ως ένα δίαυλο αλληλεπίδρασης. Η ανίχνευση αυτών των εικόνων μπορεί να παρέχει συμπληρωματικές πληροφορίες και σε άλλα θέματα όπως η ανίχνευση συμβάντων και ο μετριασμός του μίσους. Συνολικά, εδώ παρουσιάζονται όλα τα χαρακτηριστικά που κάνουν τα μιμίδια να χρησιμοποιούνται τόσο συχνά στα κοινωνικά δίκτυα, τονίζουν τα ανοιχτά ζητήματα στην ανίχνευσή τους και εμ- φανίζουν τις συνεισφορές που παρέχουν στη σχετική βιβλιογραφία. Στο Κεφάλαιο 2, περιγράφονται θεμελιώδεις έννοιες που απαιτούνται αργότερα. Σε αυτές τις έννοιες περιλαμβάνονται όλοι οι διαφορετικοί ορισμοί και εξισώσεις που απαιτούν- ται για την κατανόηση των τεχνητών νευρωνικών δικτύων που είναι τα κύρια δομικά στοιχεία της αρχιτεκτονικής που προτείνει αυτή η διατριβή. Το Κεφάλαιο 3 παρουσιάζει τη σχετική εργασία, όλες δηλαδή τις έρευνες που σχετίζον- ται περισσότερο με το θέμα που αναφέρεται εδώ. Προηγούμενες εργασίες που ασχολούνται με την ανίχνευση μιμιδίων ή με την ανάλυσή τους γενικότερα παρουσιάζονται, ενώ εργασίες που αφορούν την ταξινόμηση εικόνας ή κειμένου περιλαμβάνονται επίσης καθώς αποτελούν τη βάση της προτεινόμενης αρχιτεκτονικής. Αυτά τα έργα συγκρίνονται μεταξύ τους, ενώ τα ανοιχτά ζητήματα που απαντόται στην παρούσα εργασία, αναφέρονται επίσης. Επιπλέον, στο Κεφάλαιο 4 η αρχιτεκτονική από άκρο σε άκρο που προτείνεται για την ανίχνευση μιμιδίων παρουσιάζεται και αναλύεται. Αυτή η αρχιτεκτονική μπορεί να χωρισ- τεί σε τρία μικρότερα αρθρώματα με βάση τον τύπο πληροφορίας που επεξεργάζονται. Το πρώτο παίρνει ως δεδομένο τις περιεχόμενες εικόνες των δημοσιεύσεων του Twitter και τις ταξινομεί σε μιμίδια ή όχι (΄Αρθρωμα Κατηγοριοποίησης Εικονων). Τρία προεκπαιδευμένα νευρωνικά δίκτυα κατηγοριοποίησης εικόνας που πετυχαίνουν τα βέλτιστα αποτελέσματα ή κοντά σε αυτά δοκιμάζονται εδώ. Οι άλλοι δύο τύποι χρησιμοποιούν το κείμενο και
τα μεταδεδομένα από την ίδια την ανάρτηση. Το ΄Αρθρωμα Κατηγοριοποίησης Κειμένου λαμβάνει ως δεδομένο το κείμενο που περιλαμβάνει ο χρήστης στις αναρτήσεις του. Το κείμενο προεπεξεργάζεται με την αφαίρεση περιττών λέξεων και φράσεων και στη συνέχεια δημιουργείται μια αναπαράσταση διανύσματος για αυτό. Αυτή η αναπαράσταση στη συνέχεια τροφοδοτείται σε μοντέλο που κάνει την πρόβλεψη για το αν το κείμενο πρέπει να ανήκει σε μια ανάρτηση με μιμίδια ή όχι. Το τελευταίο κομμάτι, που ονομάζεται ΄Αρθρωμα Κατη- γοριοποίησης Μεταδεδομένων, σχετίζεται με τα μεταδεδομένα που εξάγονται τόσο από τον χρήστη όσο και από την ανάρτηση. Αυτά τα χαρακτηριστικά συνδυάζονται σε ένα ενιαίο διάνυσμα και χρησιμοποιούνται για να ελεγχθούν δύο προτεινόμενα μοντέλα για αυτό το άρθρωμα. Τέλος, αυτές οι ενότητες δοκιμάζονται είτε η καθεμία από μόνη της είτε σε δι- αφορετικούς συνδυασμούς και αυτή με τα υψηλότερα αποτελέσματα είναι αυτή που τελικώς επιλέγεται. Το Κεφάλαιο 5 εξετάζει τα αποτελέσματα που ορίζονται από τις προαναφερθείσες ενότητες. Τα συγκεκριμένα αποτελέσματα επιβεβαιώνουν την πρόταση μας για μία πολυτρόπική προσέγ- γιση στον εντοπισμό μιμιδίων στα μέσα κοινωνικής δικτύωσης και συγκεκριμένα στο Twit- ter. Αρχικά, στο κάθε ένα απότα τρία προτεινόμενα αρθρώματα ελέγγχονται τα διαφορετικά υποψηφία μοντέλα που θα χρησιμοποιηθούν και αφού εντοπιστεί το καλύτερο από αυτά παίρνει τη θέση του αρθρώματος. Στη συνέχεια τα αρθρώματα ενοποιούνται σε τέσσερις δι- αφορετικούς συνδιασμούς, τρεις από τους όποιούς είναι οι διαφορετικές δυάδες αρθρωμάτων και ένας που περιέχει και τα τρία αρθρώματα μαζί. ΄Οπως δείχνουν και τα αποτελέσματα, ο συνδιασμός του αρθρώματος των εικόνων και των μεταδεδομένων είναι αυτός που βγάζει τα καλύτερα αποτελέσματα με δεύτερο αυτον που μαθαίνει από δεδομένα εικόνας και κειμέ- νου των αναρτήσεων. Το ολικό μοντέλο βγάζει επίσης καλύτερα αποτελέσματα από το μοντέλο που βασίζεται μόνο σε εικόνες, αλλά όχι εξίσου καλά με τα προηγούμενα δύο. Τέλος, στο κεφάλειο 6 ολοκληρώνεται η διπλωματική εργασία κάνοντας μια συζήτηση πάνω στα αποτελέσματα, παρουσιάζοντας τους περιορισμούς που εμφανίστηκαν στην εργασία και παραθέτοντας σκέσεις για επιπλέον έρευνες που μπορούν να γίνουν στο αντικείμενο μελ- λοντικά
Acknowledgements
The process of development of this dissertation was far from perfect with many
obstacles been presented before my path. Nevertheless, there were many people who
supported me to carry through with it.
First, I would like to thank my supervisor - Prof. Athena Vakali who believed in
me to complete this research. Her contribution with good suggestions and modifications
made the whole process possible.
Moreover, I would like to thank Marinos Poiitis and Ilias Dimitriadis, Ph.D. can-
didates in CS department of Aristotle University of Thessaloniki who enlightened me
where my knowledge was limited and provided great ideas and writing revisions.
Last but not least, I would like to thank my family and friends who supported me
when my faith was short and understood me when my courage was shorter.
ixContents
Statement Of Authorship i
Abstract iii
Abstract (Greek) vi
Acknowledgementsς ix
List of Figures xii
List of Tables xiv
Abbreviations xv
1 Introduction 1
1.1 Exchange of Memes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Problems addressed . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3 Thesis Contribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.4 Thesis Structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 Theoretical Background - Fundamentals 10
2.1 General Neural Network Concepts . . . . . . . . . . . . . . . . . . . . . . 10
2.2 Type of Layers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3 Activation Functions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.4 Optimizers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3 Literature Review 17
3.1 Image Classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Text Classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3 Meme Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4 Meme Detection Modeling 27
4.1 Image Classification Module . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.1.1 Pre-trained Models . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.1.2 Image Text Extraction . . . . . . . . . . . . . . . . . . . . . . . . . 30
xxi
4.2 Twitter Classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2.1 Text Preprocessing and Vectoriazation . . . . . . . . . . . . . . . . 31
4.2.2 Tweet Text Classification Module . . . . . . . . . . . . . . . . . . . 33
4.2.3 Tweet’s Metadata Features . . . . . . . . . . . . . . . . . . . . . . 34
4.2.4 Tweet Metadata Classification Module . . . . . . . . . . . . . . . . 35
4.3 Modules Concatenation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5 Results and Experiments 37
5.1 Data Collection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.2 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.2.1 Experimental Environment . . . . . . . . . . . . . . . . . . . . . . 39
5.2.2 Initial Image Classification . . . . . . . . . . . . . . . . . . . . . . . 40
5.2.3 Ablation Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.2.4 Image Classification Module Results . . . . . . . . . . . . . . . . . 42
5.2.5 Metadata Classification Module Results . . . . . . . . . . . . . . . 45
5.2.6 Image Classification Module Results . . . . . . . . . . . . . . . . . 46
5.2.7 Combinations Results . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2.8 Validating the Results . . . . . . . . . . . . . . . . . . . . . . . . . 47
6 Discussion and Future Work 49
Bibliography 51List of Figures
1.1 Number of active Twitter Users from 2010 to 2019 (Source: Statista [51]) . 1
1.2 BarkBox company utilizes memes to advertise their brand. . . . . . . . . . 2
1.3 Meme image macro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Sketch image macro (Source: Akron Beacon Journal 1 ) . . . . . . . . . . . 3
1.5 Quote image macro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.6 Meme sample of type-1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
4figure.caption.21
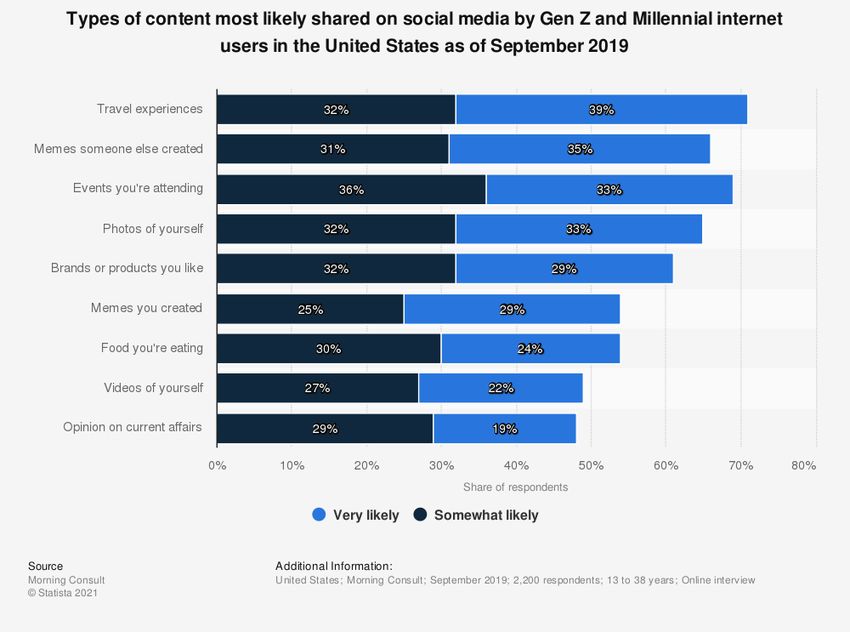
1.8 Meme is the third most likely content to be posted by USA-based social
media members born after 1980 (Source: Statista [52]) . . . . . . . . . . . 5
1.9 End-to-end process used in current dissertation. . . . . . . . . . . . . . . . 8
2.1 A basic neural network with one input, one output and one neuron layers. 11
12figure.caption.40
14figure.caption.44
2.4 The resulting optimization of the SGD relies to the random starting point
(Source: Deep AI 2 ). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.5 An example of backprogation process in a simple network (Source: Deep
AI 333 ). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4.1 Meme detection architecture . . . . . . . . . . . . . . . . . . . . . . . . . . 27
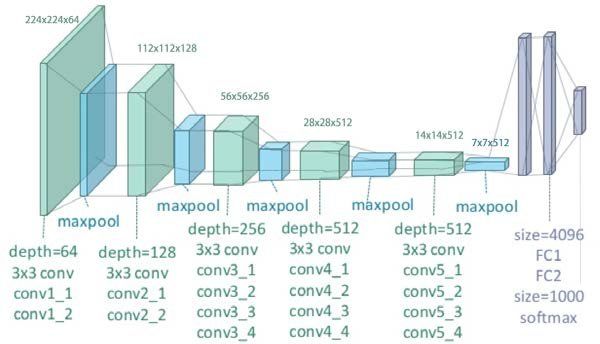
4.2 The architecture of original VGG-19 model (source: [63]) . . . . . . . . . . 28
xiixiii
4.3 The resulting images after using the Image Text Extraction module. . . . 31
4.4 Proposed RCNN model for the TCM . . . . . . . . . . . . . . . . . . . . . 33
4.5 The second model for MCM based on MENET architecture (green nodes
are user input vectors and blue node is Tweet input vector). . . . . . . . . 35
5.1 Data collection process . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.2 Initial ICM results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.3 Vgg-19 results per epoch. . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.4 ResNet-50 results per epoch. . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.5 Inception-V3 results per epoch. . . . . . . . . . . . . . . . . . . . . . . . . 44List of Tables
3.1 Meme analysis methods and usages (MG: Meme Generation, HD: Hate
Detection, TC: Template Classification, GD: Genre Detection, MD: Meme
Detection) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.1 Original Inception-V3 architecture (source: [54]) . . . . . . . . . . . . . . . 30
4.2 Data fields of Tweet JSON file . . . . . . . . . . . . . . . . . . . . . . . . . 32
5.1 Final image dataset used for training ICM that is used for Tweets’ collection 38
5.2 Number of Tweets per Class and per Hashtag . . . . . . . . . . . . . . . . 39
5.3 Number of experiments conducted per module and combination . . . . . . 42
5.4 Experiments conducted for MCM modules with different class weights
(class 0: non memes, class 1: memes) . . . . . . . . . . . . . . . . . . . . . 45
5.5 Experiments conducted for combinations of the three proposed modules. . 47
xivAbbreviations
ADAM Adaptive Moment Estimation
AWD-LSTM ASGD Weight-Dropped LSTM
BOW Bag Of Words
CapsNets Capsule Networks
CNN Convolutional Neural Network
GMMs Gaussian Mixture Model
GloVe Global Vectors
ICM Image Classification Module
KNN K-Nearest Neighbor
LSTM Long Short-Term Memory
MCM Metadata Classification Module
NLP) Natural Language Processing
OCR Optical Character Recognition
ReLU Rectifier Linear Unit
RNN Recurrent Neural Network
RMSProp Root Mean Square propagation
SGD Stochastic Gradient Descent
TF-IDF Term Frequency-Inverse Document Frequency
TCM Text Classification Module
xvChapter 1
Introduction
In modern times, social network services are an integral part of most people’s everyday
occupation. Platforms like Facebook, Instagram and Youtube have created big depart-
ments that are associated with the development of technologies or effects that had lead
to a total of at least 1 billion users each one [43], like recommendation systems which lead
to echo groups [18]. On the other hand, new and trending social media platforms like
TikTok (2017) and IGTV (2018, powered by Instagram) “want in on the party“ acquiring
hundreds of active users with each passing day, while competing with the “giants“ for
some usage time. Although that competition has affected Twitter as it is depicted in
figure 1.1, it still assembles at least 320 million active users each month.
Figure 1.1: Number of active Twitter Users from 2010 to 2019 (Source: Statista
[51])
12
All these rising numbers, accompanied with the increasing number of social networks,
as more of them are exhibited each day, indicate one thing: social networks directly affect
user behavior as well as the environment in which they operate and intercommunicate.
Each one of us uses social media platforms daily to learn the news, exchange thoughts
and ideas with our friends and colleagues, or even for plain entertainment. In fact,
sometimes we even use our social media accounts while we are occupied in other activities
like watching television or spending time with our friends. A lot of users post a status
on their accounts about something important happening in their life while their closest
people have yet to hear about it. Moreover, companies utilize the promptness with which
a social network transfers messages or ideas by advertising either their or third party’s
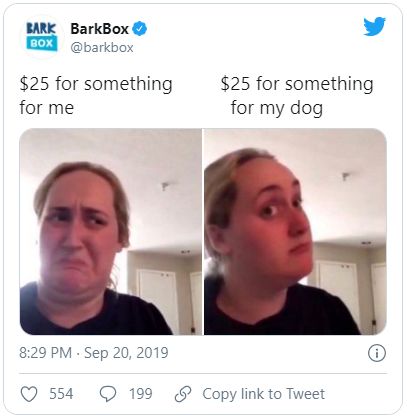
products and services, turning down the traditional marketing ways. In figure 1.2, a dog
products service increases its popularity using a meme while keeping its marketing costs
low.
Figure 1.2: BarkBox company utilizes memes to advertise their brand.
Additionally, the accumulation of so many users with different beliefs, political and
economical statuses or languages can lead to one major point: exchange of ideas!
This aspect of social networks is crucial for the complex structure that constitutes the
modern world community. Social media users share their concerns about major events,
their thoughts for a probable solution on a crisis or post an idea to entertain and provoke
laughter. Such a manifestation of an idea is called Meme.You can also read

















































