The Annodata Framework: A data-centric approach to enhance metadata - Deutsche Bundesbank
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
The Annodata Framework:
A data-centric approach to enhance metadata
Technical Report 2019-14
S. Bender, J. Blaschke, H. Doll, A. Gordon, C. Hirsch, D. Hochfellner, J. Lane
Disclaimer
The views expressed in this technical report are personal views of the authors and
do not necessarily reflect the views of the Deutsche Bundesbank or the Eurosystem.
Citation
Bender, S., J. Blaschke, H. Doll, A. Gordon, C. Hirsch, D. Hochfellner, J. Lane
(2019). The Annodata Framework: A data-centric approach to enhance metadata.
Technical Report 2019-14, Deutsche Bundesbank, Research Data and Service
Centre.Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
The Annodata Framework: A data-centric approach to enhance metadata
Stefan Bender1, Jannick Blaschke1, Hendrik Doll1, Andrew Gordon2, Christian Hirsch1,
Daniela Hochfellner3, Julia Lane31
1. INTRODUCTION ........................................................................................................................ 3
2. EXISTING METADATA STANDARDS ...................................................................................... 3
3. THE ANNODATA FRAMEWORK ............................................................................................. 4
4. USE CASES: DATA PROVIDERS AND DATA USERS ......................................................... 10
5. TECHNICAL DEPLOYMENT................................................................................................... 13
6. CONCLUSION ......................................................................................................................... 13
7. REFERENCES ......................................................................................................................... 14
Abstract: The new availability of data through secure Research Data Centers (RDC)
provides a new opportunity to capture metadata based on its access and use, in addition to
that, based on its production. The new information, which we call annodata, can be used to
improve the management of and access to restricted data. We identify two types of
annodata. The first is administrative metadata, such as legal requirements and data access
workflows. The second is usage metadata, such as the number of times it is used and the
research outputs that are produced. This paper presents an integrated annodata framework
and describes how annodata can automate the management of confidential data for RDC
managers, improve dataset search and discovery for users and increase knowledge of
dataset use for data providers.
Keywords: Annodata, administrative data, usage, metadata, machine-readable, data
stewardship, confidential data, data management, data description, big data
1
Deutsche Bundesbank, email: {firstname}.{lastname}@bundesbank.de
2
Columbia University
3
New York University
The Annodata Framework: A data-centric approach to enhance metadata Page 2 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
1. Introduction
The increased availability of new types of data has transformed the practice of social
science research in many ways. One of the most important ways is that data access is
much more likely to be through a secure facility, both because the data are more granular
and because it has become much easier to re-identify individuals and businesses. This
creates challenges for both data providers and users. Data providers have to find
appropriate ways of maintaining highest privacy protection standards, but they often do not
have the tools necessary to comply with regulatory practices such as those introduced by
the GDPR, particularly to track of who has access to what data. Data users have to search
for and find the datasets most appropriate for their research from an increasing variety of
data, with little information on what data have been used for which research questions and
by which other researchers.
We propose an approach inspired by the use of paradata in survey methodology (West,
2011) which captures auxiliary information about the interview process, including
interviewer and respondent behaviors. The approach, called annodata, refers to any
additional information on a dataset that is collected during the research cycle. This can be
administrative dataset information, such as legal requirements and data access workflows.
It can also include information collected on dataset usage, such as usage quantity or
research output. Just as paradata can be used to improve survey administration, annodata
on research access can produce more efficient data administration workflows and on
dataset usage can allow efficient user-to-user knowledge transfers.
2. Existing metadata standards
To contextualize our work, we look at existing metadata approaches. It is important to note
here that the purpose of metadata overall is to serve the goals of the community that uses
it and the organizations that provide it (Willis, Greenberg & White, 2012). Different
communities and organizations have different goals that guide their collection, usage, and
sharing of data.
Many existing data repositories and archives have discussed their work in creating,
organizing, and disseminating descriptive metadata about datasets such that these
datasets might be discovered, shared, understood, and reused (Hancock, 2017; Dietrich,
2010; White, 2014; Moss et al., 2016; Rücknagel et al., 2015). That work has given rise to
generally used and flexible metadata schemas, such as schema.org, DataCite, and Dublin
The Annodata Framework: A data-centric approach to enhance metadata Page 3 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
Core, and so datasets can nowadays be described in a flexible and generally understood
way.
However, the information by which data are released, protected, controlled, and its access
and usage tracked and audited is less well defined in the literature, and there is no single,
easy solution to implement metadata standard or framework. Standards like the Metadata
Encoding & Transmission Standard (METS) provide a scaffolding by which to define
administrative metadata pertaining to intellectual property and copyrights, how objects were
created and stored and original source information, but might not be granular enough to
use for designating complicated usage restrictions by file, table, column, or specific fields
in datasets. Standards such as PROV-O and PREservation Metadata: Implementation
Strategies (PREMIS)—another metadata standard stewarded by the Library of Congress—
provide guidance for defining lineage and provenance around the creation and maintenance
in preserving digital objects. Gunia and Sandusky (2010) provide a detailed description of
how PREMIS can be used to preserve Earth Science data, but are not aimed at the
complicated chain of transformations that occur over the lifetime of a datasets usage.
Chao, Cragin, and Palmer (2014), however, have proposed a standard data curation
vocabulary, which incorporates not just a description of the data but practical steps of how
the data are used by the researchers that produced and shared it. In addition, Gail and Uhlir
(2016) state the importance for research to “share, access, and reuse data”, which “requires
effective technical, syntactic, semantic and legal interoperability rules and practices”
through metadata. The International Rights Statements Working Group (2015a) introduce
a standardized vocabulary to describe usage terms and copyright status of intellectual work,
which they coin “rights statements”.
This brief review suggests that the current literature uses schema primarily based on
metadata that describes data from the production side. We tackle this challenge by
enhancing the classical metadata concept in two directions: data administration and usage.
The combination is conceptualized in the annodata framework.
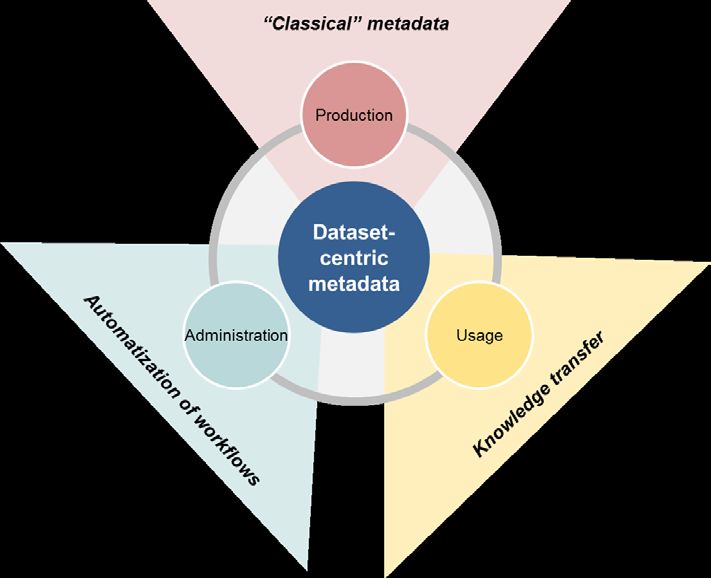
3. The annodata framework
In this section, we propose two new items to comprehensively describe datasets beyond
metadata. Such new items are precisely data on dataset administration and data on dataset
usage. The annodata framework builds on classical metadata, which are enhanced by
administrative and usage annodata with the purpose to describe datasets extensively. Each
of these three framework attributes has a specific added value (as graphically depicted in
Figure 1). “Classical” metadata is well-established as a tool to categorize data.
The Annodata Framework: A data-centric approach to enhance metadata Page 4 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
Administrative annodata brings the added benefit of allowing automated workflows towards
the dissemination of data. Usage annodata allows fast and efficient knowledge transfers by
systematically capturing what others have done with the data.
Figure 1: Three types of dataset related metadata
3.1. The three-fold data centric approach
The proposed concept enhances rather than replaces the existing framework and suggests
additional attributes to be considered when designing data-centric systems so that
annodata can be integrated into existing standards. Existing standards such as the Data
Documentation Initiative (DDI), PREMIS, METS, DCAT, and Schema.org have varied
approaches to designating access rights, although these have not been widely deployed in
the context of a research data facility or other similar analytical environments.
Our experience is that a three-fold (classical, administrative, usage) informational basis is
both necessary and sufficient to implement virtually all processes along the data life cycle,
notably data handling, linkage and dissemination. Automated processes along the life cycle
are made possible through such standardized data descriptions. In the following, we
present each item of the three-fold framework in detail.
The Annodata Framework: A data-centric approach to enhance metadata Page 5 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
3.2. Classical metadata
Metadata from data producers can be used to describe and document how data is being
produced. Such metadata is well-described in many high-quality available metadata
standards and schemas. A notable example for such a standard in the social sciences is
the Data Documentation Initiative (DDI). An incomplete list of attributes that we categorize
under this type of metadata includes the description of collection methodologies, how raw
data is being processed to obtain the standardized dataset, and modes of data distribution.
Table 1 provides a selected few examples of classic metadata.
Table 1: Examples for classic metadata items
Name Name of the dataset.
Creator Name(s) of the institution, and/or division, and/or department
responsible for developing, collecting and/or managing the dataset. The
first creator provides the name of the institution. The name of the creator
may or may not be identical to item "Name of Institute" (Data Owner).
The second creator gives information on the department (but not
individual persons).
Description Short description of the dataset.
Sampled The elementary units about which inferences are to be drawn and to
universe which analytic results refer.
3.3. Administrative annodata
The efficient governance of micro data requires a clear and machine-readable set of rules,
which are consistent across different datasets and potentially across different types of
facilities and repositories. This is vital for standardization of processes and wherever
possible automation of tasks and decisions within the data management process. Our
proposed approach would enhance existing processes by automatically collecting
information on how data are regulated and governed; this would significantly ease the work
of data stewards. Administrative annodata in this context thus includes to all information
that helps data resource management, such as providing information on governing data
The Annodata Framework: A data-centric approach to enhance metadata Page 6 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
dissemination, for example license restrictions, authentication, and availability (Medeiros et
al., 2011).
It is worth noting that the Dublin Core Metadata Initiative already includes the term
administrative metadata (Koch and Weibel, 2000) as “metadata-about-metadata”
necessary to manage data assets; as does the National Information Standards
Organization (Riley, 2017) as the information needed to manage a resource. Our extension
to regulatory information can substantially reduce the administrative burden for data
stewards, since administrative annodata would hold information on which datasets can be
linked, which degree of anonymization is required, which laws apply, and who can approve
data access and any other bureaucratic requirements.
Data providers can also use administrative annodata to data access by constructing fully
automated processes that use annodata to determine a user’s access to a given dataset
(Yarkoni, Tal, et al., 2019). Data Users will find out everything they need to know about
access rights and conditions and can use this information to plan their data access request.
Examples for administrative annodata items are given in Table 2.
Table 2: Examples for administrative annodata items
Data access The legal framework under which this data is collected. From this,
regime many other attributes deterministically follow.
User All potential usage restrictions that apply to the usage of a specific
restrictions dataset depending on the type of researcher or project.
Linkage All dataset-specific restrictions that apply when combing it with a
restrictions selected second dataset.
Analytical Other dataset-specific restrictions apart from user or linkage
restrictions restrictions that may apply to analysis, e.g. to datasets usage
restrictions for certain topics.
Anonymization The classification of the dataset’s degree of anonymization.
Figure 2 illustrates an example of administrate annodata designed to describe procedures
in a research data center that offer access to high quality administrative micro-level data for
research purposes. For this purpose, administrative annodata would fall into two different
The Annodata Framework: A data-centric approach to enhance metadata Page 7 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
layers. The first layer comprises access regime, database, and dataset, which describes
access to an individual dataset.
Figure 2: Six types of annodata for the example of a research data center
The rationale behind this is as follows. Typically, a number of different modes are available
to access individual datasets. An access mode is a mode via which access to the data can
be granted. Examples include download of data or secure on-site access at the premises
of the data providing institution. Each access mode in turn may have a number of different
access protocols attached to it. Access protocols describe the criteria that have to be fulfilled
to be granted access under a specific access mode. The protocol-criteria often times are
imposed by a combination of the legal basis, the affiliation of the researcher (e.g. internal
vs. external) and the degree of anonymization (non-anonymized vs. fully anonymized) of
the requested data.
Note that this example distinguishes between a dataset and a database. For example, the
national credit register is a database whereas the national credit register for the period 1992
to 2017 constitutes a dataset. It follows from this definition that an important distinction
between databases and datasets is the frequency with which both are updated. While the
former is updated frequently because of new information the latter, once fixed, is never
updated making datasets better suited to ensure reproducibility of research results. To
reduce the burden to implement administrative annodata for each datasets separately,
datasets should inherit as much attributes as possible from databases.
The Annodata Framework: A data-centric approach to enhance metadata Page 8 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
To be able to fully construct automated processes, the dataset must be unambiguously tied
to an access regime. This requires, first, that database has to be partitioned into datasets
based on the degree of anonymization of the requested data. Second, each dataset needs
to be unambiguous identifiable for example by assigning persistent identifiers such as e.g.
Digital Object identifiers (DOI). One may also tie access regimes to databases. However,
two things are to be considered. First, different parts of a database may be governed by
different access regimes. Second, assigning persistent identifiers to databases may prove
conceptually hard as they may be in constant updating cycles.
The second layer of the administrative annodata describes the access to multiple linked
datasets that may be requested by researchers when conducting research. To be able to
handle these cases, this layer comprises of information on record linkage, restrictions
incurred when combining datasets, and decision rules that describe which data access
protocol must be applied in cases of multiple datasets.
Besides information on the technical feasibility, the record linkage element also includes
information on the methods applied and the underlying assumptions used when creating
this link. The latter is especially important to put researchers into the position to gauge the
quality of the link and take a decision whether they want to use this link in own research.
Information on any restrictions applying to specific datasets are collected in the combining
restriction element. Finally, to allow the possibility of linking datasets from different access
regimes administrative annodata also needs to define unambiguous decision rules, which
access protocol, applies in these cases. For example, different access regimes may call for
different contracts that the researcher has to sign before being granted data access. For
these cases, the decision rule’s element may specify a dedicated protocol that contain a
rule to which contract applies under the given circumstances.
3.4. Data usage annodata
Annodata on data usage can track the activity of current and prior researchers and projects
and use that information to better understand potential use cases, identify dataset-specific
characteristics and provide guidance to new researchers. Usage annodata can be
converted into user recommendation systems, which suggest specific studies or datasets
other researchers have used working in the same field, similar to what is being done in
private industry (Hu et al., 2006). A new effort has recently been launched to automate the
collection of context specific annodata in social science research (Lane, Mulvany, Nathan
2019): these data can be used to report usage statistics and improve the quality of data.
The Annodata Framework: A data-centric approach to enhance metadata Page 9 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
Annodata on data usage includes items such as publications that use a particular dataset,
defining data experts, as well as code snippets and user comments about the quality of a
given dataset. The combination of this information identifies datasets that are often used
together and provide additional information on possible data linkages. Such data
enrichment strategies can then be used to recommend data to new users allowing a more
efficient micro data usage and knowledge exchange with peers.
Annodata on data usage can be obtained by text mining techniques from research
publications, by obtaining user feedback in the form of comments and by analyzing
researcher code for empirical analyses. To analyze and learn from researchers’s comments
an integrated system allowing researchers to comment and share information is currently
being implemented at NYU, in collaboration with the Bundesbank and others.
Table 3: Examples for usage annodata items
Publications Publications for which the dataset was used.
Code Code specifically written to process or analyse the dataset.
User feedback Dataset-specific feedback and comments from data users.
Table 3 presents examples for what we consider usage annodata. We continue by
outlining two use-cases that benefit or are made possible from our introduced three-fold
produce-administrate-use framework.
4. Use cases: Data providers and data users
4.1. Data providers
A recent trend in empirical research is the proliferation of research data centers (RDCs),
which offer access to high quality administrative micro-level data for research purposes.
RDCs, as opposed to Research Data Repositories, are defined here as institutions
responsible for making their data available to researchers and their own staff in a manner
often governed by specific privacy of confidentiality regimes. Examples include the United
States Federal Reserve System or National Central Banks in the Eurosystem such as the
Deutsche Bundesbank.
RDCs provide researchers and analysts with access to selected micro data in the context
of independent scientific research projects. They have twin imperatives. The first of these
The Annodata Framework: A data-centric approach to enhance metadata Page 10 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
is administrative in nature: to maintain highest privacy protection standards, since access
to micro data is subject to legal and data protection requirements. The second is to provide
the highest quality access to researchers, so that the best possible use is made of the data.
We believe that high quality annodata will enable RDCs to respond to each of these
imperatives.
The Federal Reserve Board has provided a useful overview of the administrative challenges
as a result of their attempts to set up a data service following the 2008 economic crisis
(Cannon, 2014). They quickly found that one-size-fit-all standards and technology for
automation of data management and data governance are lacking or non-existent. Indeed,
data management and data governance practices are not traditionally conceived as
technology, infrastructure and metadata challenges, but challenges of business process
and operation (Datoo, 2019). In particular, RDCs must keep track of administrative dataset
attributes; such as who has access to data in which degree of granularity and
anonymization, and which data can be linked to which.
Administrative annodata on the dataset-specific legal, organizational or technical rules and
requirements that are needed for the performance of data stewardship related tasks will
support the data steward in RDC administration and help improve data access. For
example, the privacy principles and regulations that have been imposed by lawmakers can
be attached to a given dataset and the resulting annodata can be used by the RDC to
automate privacy protection mechanisms at all times during a research lifecycle. Thus,
administrative annodata that contain machine-readable and detailed information on
dataset-related access rules and restrictions can be used to design workflows providing
access to confidential micro data and support data governance in general.
Some work has already been done in this area. For example, the National Information
Exchange Model (NIEM) has proposed automating reasoning around access to datasets
pertaining to privacy policy (Yuan, 2016). In addition, established system architectures such
as Amazon Web Services Identity and Access Management (IAM), while not exactly a
metadata standard, provide a framework or model whereby granular user access and
permissions is established and employed as a set of roles that can be applied to users at
multiple levels of granularity (i.e., at resource level or even at levels such as columns in
databases).
Usage annodata can help support RDCs who are also tasked with providing information
and consulting researchers on data selection, data content and analytical approaches. For
this task, usage annodata (from publications, researcher code, and researcher comments)
may be used to enhance existing applications in a user-centric way, which leads to obtaining
The Annodata Framework: A data-centric approach to enhance metadata Page 11 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
refined services. Better services in turn allow better research, because the available micro
data is better described and can be used for effectively.
4.2. Harmonizing data access across institutions
One example of harmonized producer metadata from producers is the INEXDA 2 Metadata
Schema, which is mainly based on the da|ra metadata schema (Helbig et al 2014, in turn
in line with the DataCite Metadata Schema). Adapting an existing metadata schema to fit
the purpose of INEXDA provides a level of standardization for micro data coming from
different countries, institutions, and collection purposes. The schema facilitates a
comprehensive inventory of existing granular datasets conducted in the member
institutions.
The INEXDA metadata schema was designed specifically for micro data datasets where a
dataset is defined as a snapshot of a database at a certain point in time (INEXDA, 2019).
For example, information in the national credit register for the period 1992 to 2017 would
constitute a dataset. The national credit register without any restrictions on time would be
the database. Databases may also be described by the INEXDA metadata schema.
However, this may involve establishing conventions for some metadata items (e.g.
“Publication date”). This structure with smaller “datasets” inheriting attributes from larger
“databases” makes sense for our proposed annodata schema, too.
4.3. Data users
Implementing the proposed annodata framework allows establishing machine-readable
rules to automate processes. For the data users these automated process are a valuable
asset as well. Having a built out module that displays transparent access requirements and
offers a way to easily request data and manage research projects will help navigate the
research project at any given point in time.
Furthermore, recommendation systems built upon data usage annodata can automatically
give advice to new users which datasets to use and who dataset experts are. Like online
retailers, users see, “based on your preferences, you might also like”.
Collecting comments of users to specific datasets and providing code to harmonize data
and clean data fosters knowledge exchange within the research community.
2
The International Network for Exchanging Experience on Statistical Handling of Granular Da-ta (INEXDA) provides a
platform for exchanging experiences on statistical handling of granu-lar data for central banks, national statistical institutes
and international organisations. As such, it supports the G20 process, notably the Data Gaps Initiative 2 recommendation
aiming to promote the exchange of (granular) data as well as metadata. The network was founded in January 2017. More
information on INEXDA can be found at https://www.bis.org/ifc/publ/ifcwork18.htm
The Annodata Framework: A data-centric approach to enhance metadata Page 12 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
5. Technical Deployment
The challenge is to build and deploy a system to administer the annodata framework. Our
approach has been to develop a “Data Stewardship” web application that can be used by
various data providers (Henke and Hochfellner, 2019). The goal of the application is to
provide an automated and structured workflow that can be used by Research Data Centers,
as well as other stewards of confidential data, to manage approvals, track data access and
manage use by analysts and researchers. It is also designed to automate the onboarding
of researchers in terms of dataset search and discovery and approval. It facilitates the data
access and approval process, reduces administrative time, and improves resource
utilization. It provides data stewards with reports on data access and usage metrics.
The main features of the module for data owners are (i) management of dataset policies
and data stewards, (ii) management of data access requests and approval workflows, (iii)
management of the legal paperwork, and (iv) reporting on dataset usage, listing projects,
and user-generated metadata. The main features of the module for researchers are (i)
automated data search and discovery, (ii) automated application process, (iii) transparent
approval process and (iv) automated export process.
This is a first step towards integrating the annodata framework into a research facility that
governs legally protected administrative data.
6. Conclusion
In the current paper, we map out a three-fold approach for thinking about dataset attributes.
Besides classical metadata, we propose administrative- and usage annodata as further
dataset characteristics. In existing metadata schemas, some items of these novel aspects
show up incidentally, however, we offer a structured way of thinking on the categorization
of these elements, and also which further items to include. It is absolutely fundamental that
these new elements are combinable with existing metadata schema.
Our proposed “Produce, Administer, Use” three-fold schema maps well to the model of the
empirical knowledge generating process (Bender et al, forthcoming). The cycle describes
information flow in empirical research using confidential micro data. Information flows from
data services to researchers to publications and – if properly structured –back to data
services. Such information feedback from usage allows data services to improve. From
there on, the empirical knowledge generating process starts over, but on a higher level, with
improved data services allowing better research in turn.
The Annodata Framework: A data-centric approach to enhance metadata Page 13 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
The information flows generated from the knowledge generating process are encapsulated
in metadata and annodata. Data services to research include metadata from the producer
side, allowing the researcher to make an informed decision on whether to apply for the
confidential data. Administrative annodata both informs data services (informing
researchers), as well as governs research (degree of access restrictions). In turn,
researchers generate publications as well as implicit knowledge. If publications and implicit
knowledge are properly extracted and structured, we obtain usage annodata, allowing the
empirical knowledge generating process to be complete.
We argue that the three metadata and annodata items Produce – Administer– Use are both
necessary and sufficient conditions to inform the design of workflows governing automated
and user-centric data usage applications in fields such as research data centers, data
archives and institutional repositories, online retailers, and institutional data exchange.
Having the annodata framework allows easy and automated integration of information into
for the management and use of new data.
7. References
Bender, Stefan, and Hausstein, Brigitte and Hirsch, Christian: An Introduction to INEXDA’s
Metadata Schema. IFC Bulletin No 29, 2019b.
Bender, Stefan; Doll, Hendrik Christian and Hirsch, Christian. Who’s Waldo: Conceptual
issues when characterizing data in empirical research. In: Where’s Waldo. Sage. 2019a.
Block, William C.; Bilde Andersen, Christian; Bontempo, Daniel E;Gregory, Arofan;
Howald, Arofan; Kieweg, Douglas;Radler, Barry T. Documenting a wider variety of data
using the data documentation initiative 3.1. DDI Working Paper Series – Longitudinal best
practice, no.1. 2011.
Borgman, C. L. (2012). The conundrum of sharing research data. Journal of the American
Society for Information Science & Technology, 63(6), 1059-1078.
http://dx.doi.org/10.1002/asi.22634
Cannon, San and Degn Pan. 2016. First Forays into Research Data Dissemination: A
Tale from the Kansas City Fed, IASSIST Quarterly. pp. 35-39
Clement, Gail and Uhlir, Paul. Legal Interoperability of Research Data: Principles and
Implementation Guidelines. RDA-CODATA Legal Interoperability Interest Group, 2016.
DOI: 10.5281/zenodo.162241
The Annodata Framework: A data-centric approach to enhance metadata Page 14 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
Chao, T. C., Cragin, M. H. and Palmer, C. L. (2015), Data Practices and Curation
Vocabulary (DPCVocab). J Assn Inf Sci Tec, 66: 616-633. doi:10.1002/asi.23184
“Controlling Data Usage Using Structured Data Governance Metadata.” 2017.
http://search.ebscohost.com/login.aspx?direct=true&db=edspap&AN=edspap.201703087
15&site=eds-live.
“Data Management for Combined Data Using Structured Data Governance Metadata.”
2018.
http://search.ebscohost.com/login.aspx?direct=true&db=edspap&AN=edspap.201803417
80&site=eds-live.
Datoo, A. (2019). Data, Data Modelling and Governance. In Legal Data for Banking, A.
Datoo (Ed.). doi:10.1002/9781119357216.ch4
Dietrich, Dianne. 2010. Metadata Management in the Data Staging Repository, Journal of
Library Metadata, Vol. 10 Issue 2, pp.79-98 DOI: 10.1080/19386389.2010.506376
Henke, Graham & Daniela Hochfellner, The NYU Data Stewardship Module (2019),
(available at https://coleridgeinitiative.org/assets/docs/ADRF White Paper_ Data
Stewardship).
Gunia, Betsy and Sandusky, Robert J. (2010), Designing metadata for long‐term data
preservation: DataONE case study. Proc. Am. Soc. Info. Sci. Tech., 47: 1-2.
doi:10.1002/meet.14504701435
Hancock, Andrew. 2017. The Modernisation of Statistical Classifications to Knowledge
and Information Management Systems, The Electronic Journal of Knowledge
Management Vol. 15, Issue 2. pp. 126-144
Helbig, Kerstin, Hausstein, Brigitte, Koch, Ute, Meichsner, Jana, Kempf, Andreas Oskar.
da|ra Metadata Schema, gesis technical report 2014|17, 2014
Hu, Xiao; Downie, J. Stephen; Ehmann, Andreas F. Exploiting Recommended Usage
Metadata: Exploratory Analyses. In: ISMIR. 2006. S. 19-22.
INEXDA. INEXDA–The granular data network. IFC Bulletin No 29, 2019.
International Rights Statements Working Group. Recommendations for Standardized
International Rights Statements, 2015a.
International Rights Statements Working Group. Requirements for the Technical
Infrastructure for Standardized International Rights Statements, 2015b.
The Annodata Framework: A data-centric approach to enhance metadata Page 15 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
Japec, L., Kreuter, F., Berg, M., Biemer, P., Decker, P., Lampe, C., ... & Usher, A. (2015).
Big data in survey research: AAPOR task force report. Public Opinion Quarterly, 79(4),
839-880.
Korhonen, Janne & Melleri, Ilkka & Hiekkanen, Kari & Helenius, Mika. (2012). Designing
Data Governance: An Organizational Perspective. The GSTF Journal of Computing. 2.
10.5176/2251-3043_2.4.203.
Lane, Julia & Mulvany, Ian & Nathan, Paco (2019) Rich Search and Discovery for
Research Datasets: Building the next generation of scholarly infrastructure, SAGE
publications.
Smith, Ken & Seligman, Len & Rosenthal, Arnon & Kurcz, Chris & Greer, Mary & Macheret,
Catherine & Sexton, Michael & Eckstein, Adric. (2014). "Big Metadata": The Need for
Principled Metadata Management in Big Data Ecosystems. 10.1145/2627770.2627776.
Staunton, C., Slokenberga, S., & Mascalzoni, D. (2019). The GDPR and the research
exemption: considerations on the necessary safeguards for research biobanks. European
Journal of Human Genetics, 1.
Koch, Traugott and Weibel, Stuart L. The Dublin Core Metadata Initiative. D-Lib Magazine,
Volume 6, Number 12. 2000.
Koch, Ute and Akdeniz, Esra and Meichsner, Jana and Hausstein, Brigitte and Harzenetter,
Karoline: da|ra Metadata Schema: Documentation for the Publication and Citation of Social
and Economic Data. Version 4.0. GESIS Papers 2017/25.)
Medeiros, N., Bills, L., Blatchley, J., Pascale, C., & Weir, B. Managing administrative
metadata. Library Resources & Technical Services, 47(1), 28-35. 2011.
Moss, Elizabeth, Christin Cave, and Jared Lyle. 2015. "Sharing and citing research data: A
repository's perspective." West Academic Publishing.
Riley, Jenn. 2017 "Understanding metadata." Washington DC, United States: National
Information Standards Organization
(http://www.niso.org/publications/press/UnderstandingMetadata.pdf): 23.
Rücknagel, J., Vierkant, P., Ulrich, R., Kloska, G., Schnepf, E., Fichtmüller, D., Reuter, E.,
Semrau, A., Kindling, M., Pampel, H., Witt, M., Fritze, F., van de Sandt, S., Klump, J.,
Goebelbecker, H.-J., Skarupianski, M., Bertelmann, R., Schirmbacher, P., Scholze, F.,
Kramer, C., Fuchs, C., Spier, S., Kirchhoff, A. (2015): Metadata Schema for the Description
of Research Data Repositories: version 3.0, 29 p. DOI: http://doi.org/10.2312/re3.008
The Annodata Framework: A data-centric approach to enhance metadata Page 16 of 17Deutsche Bundesbank, Research Data and Service Centre
14 October 2019
Schönberg, Tobias. Data Access to Micro Data of the Deutsche Bundesbank. Technical
Report 2018-01, Deutsche Bundesbank, Research Data and Service Centre, 2018.
Singson, Jaime (Cambridge, MA), and Xiaohua (Palo Alto, CA) Chen. 2005. “Method and
Apparatus for Facilitating Data Stewardship for Metadata in an ETL and Data Warehouse
System.”
http://search.ebscohost.com/login.aspx?direct=true&db=edspap&AN=edspap.200500440
97&site=eds-live.
Taylor, Sean J. 2013. “Real Scientists Make Their Own Data.” Sean J. Taylor Blog,
January 25. Available at http://bit.ly/15XAq5X
West, Brady, Paradata in survey research. Surv. Pract. 4, 1–8 (2011)
White, Hollie C. 2014. Descriptive Metadata for Scientific Data Repositories: A
Comparison of Information Scientist and Scientist Organizing Behaviors, Journal of
Library Metadata, Vol. 14, Issue 1, pp. 24-51, DOI: 10.1080/19386389.2014.891896
Willis, Craig, Greenberg, Jane and White, Hollie. (2012), Analysis and synthesis of
metadata goals for scientific data. J Am Soc Inf Sci Tec, 63: 1505-1520.
doi:10.1002/asi.22683
Yuan, Ben Z. 2016. Adapting NIEM input for automated privacy policy reasoning. pp. 1-5.
DOI:10.1109/THS.2016.7568953
The Annodata Framework: A data-centric approach to enhance metadata Page 17 of 17You can also read

















































