StructFormer: Joint Unsupervised Induction of Dependency and Constituency Structure from Masked Language Modeling
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
StructFormer: Joint Unsupervised Induction of Dependency and
Constituency Structure from Masked Language Modeling
Yikang Shen∗ Yi Tay Che Zheng
Mila/Université de Montréal Google Research Google Research
Dara Bahri Donald Metzler Aaron Courville
Google Research Google Research Mila/Université de Montréal
Abstract Wang et al., 2019; Kim et al., 2019b,a). However,
most of these works focus on inducing either con-
There are two major classes of natural lan- stituency or dependency structures alone.
guage grammars — the dependency grammar
In this paper, we make two important techni-
that models one-to-one correspondences be-
tween words and the constituency grammar cal contributions. First, we introduce a new neu-
that models the assembly of one or several ral model, StructFormer, that is able to simultane-
corresponded words. While previous unsuper- ously induce both dependency structure and con-
vised parsing methods mostly focus on only in- stituency structure. Specifically, our approach aims
ducing one class of grammars, we introduce a to unify latent structure induction of different types
novel model, StructFormer, that can simulta- of grammar within the same framework. Second,
neously induce dependency and constituency StructFormer is able to induce dependency struc-
structure. To achieve this, we propose a new
tures from raw data in an end-to-end unsupervised
parsing framework that can jointly generate a
constituency tree and dependency graph. Then fashion. Most existing approaches induce depen-
we integrate the induced dependency relations dency structures from other syntactic information
into the transformer, in a differentiable man- like gold POS tags (Klein and Manning, 2004; Co-
ner, through a novel dependency-constrained hen and Smith, 2009; Jiang et al., 2016). Previous
self-attention mechanism. Experimental re- works, having trained from words alone, often re-
sults show that our model can achieve strong quires additional information, like pre-trained word
results on unsupervised constituency parsing,
clustering (Spitkovsky et al., 2011), pre-trained
unsupervised dependency parsing, and masked
language modeling at the same time. word embedding (He et al., 2018), acoustic cues
(Pate and Goldwater, 2013), or annotated data from
1 Introduction related languages (Cohen et al., 2011).
We introduce a new inductive bias that enables
Human languages have a rich latent structure. This the Transformer models to induce a directed depen-
structure is multifaceted, with the two major classes dency graph in a fully unsupervised manner. To
of grammar being dependency and constituency avoid the necessity of using grammar labels during
structures. There has been an exciting breath of training, we use a distance-based parsing mecha-
recent work targeted at learning this structure in a nism. The parsing mechanism predicts a sequence
data-driven unsupervised fashion (Klein and Man- of Syntactic Distances T (Shen et al., 2018b) and a
ning, 2002; Klein, 2005; Le and Zuidema, 2015; sequence of Syntactic Heights ∆ (Luo et al., 2019)
Shen et al., 2018c; Kim et al., 2019a). The core to represent dependency graphs and constituency
principle behind recent methods that induce struc- trees at the same time. Examples of ∆ and T are
ture from data is simple - provide an inductive illustrated in Figure 1a. Based on the syntactic
bias that is conducive for structure to emerge as distances (T) and syntactic heights (∆), we pro-
a byproduct of some self-supervised training, e.g., vide a new dependency-constrained self-attention
language modeling. To this end, a wide range of layer to replace the multi-head self-attention layer
models have been proposed that are able to success- in standard transformer model. More specifically,
fully learn grammar structures (Shen et al., 2018a,c; the new attention head can only attend its parent (to
∗
Corresponding author: yikang.shn@gmail.ca. avoid confusion with self-attention head, we use
Work done while interning at Google Reseach. “parent” to denote “head” in dependency graph) or
7196
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics
and the 11th International Joint Conference on Natural Language Processing, pages 7196–7209
August 1–6, 2021. ©2021 Association for Computational Linguistics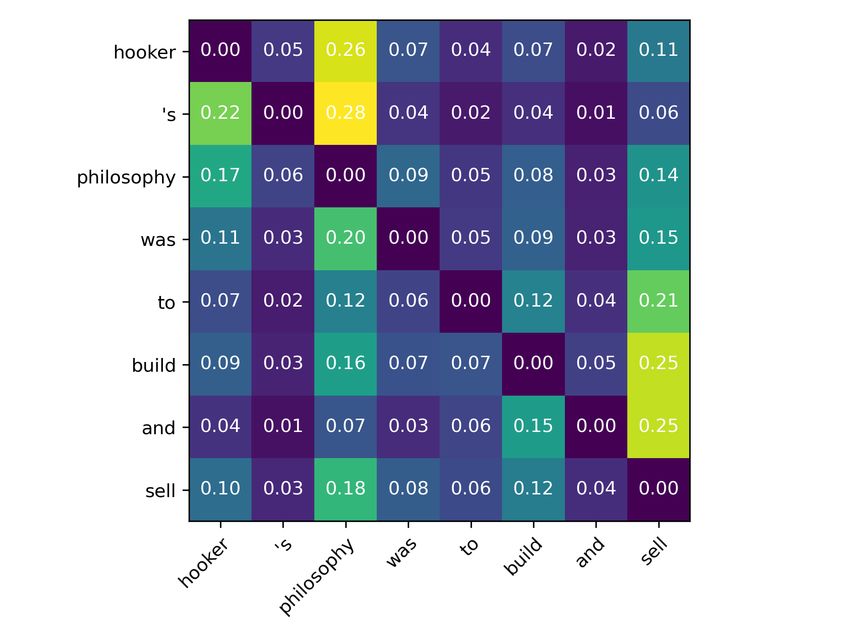
(b) Two types of dependency relations. The parent distribution
allows each token to attend on its parent. The dependent distribu-
tion allows each token to attend on its dependents. For example
(a) An example of Syntactic Distances T (grey bars) and the parent of cats is like. Cats and I are dependents of
Syntactic Heights ∆ (white bars). In this example, like like Each attention head will receive a different weighted sum
is the parent (head) of constituent (like cats) and of these relations.
(I like cats).
Figure 1: An example of our parsing mechanism and dependency-constrained self-attention mechanism. The
parsing network first predicts the syntactic distance T and syntactic height ∆ to represent the latent structure of the
input sentence I like cats. Then the parent and dependent relations are computed in a differentiable manner
from T and ∆.
its dependents in the predicted dependency struc- based on the distributed representation of POS tags.
ture, through a weighted sum of relations shown However, most existing unsupervised dependency
in Figure 1b. In this way, we replace the complete parsing algorithms require the gold POS tags to
graph in the standard transformer model with a ge provided as inputs. These gold POS tags are la-
differentiable directed dependency graph. During beled by humans and can be potentially difficult (or
the process of training on a downstream task (e.g. prohibitively expensive) to obtain for large corpora.
masked language model), the model will gradu- Spitkovsky et al. (2011) proposed to overcome this
ally converge to a reasonable dependency graph problem with unsupervised word clustering that
via gradient descent. can dynamically assign tags to each word consid-
Incorporating the new parsing mechanism, the ering its context. He et al. (2018) overcame the
dependency-constrained self-attention, and the problem by combining DMV model with invertible
Transformer architecture, we introduce a new neural network to jointly model discrete syntactic
model named StructFormer. The proposed model structure and continuous word representations.
can perform unsupervised dependency and con- Unsupervised constituency parsing has recently
stituency parsing at the same time, and can leverage received more attention. PRPN (Shen et al., 2018a)
the parsing results to achieve strong performance and ON-LSTM (Shen et al., 2018c) induce tree
on masked language model tasks. structure by introducing an inductive bias to re-
current neural networks. PRPN proposes a pars-
2 Related Work
ing network to compute the syntactic distance of
Previous works on unsupervised dependency pars- all word pairs, while a reading network uses the
ing are primarily based on the dependency model syntactic structure to attend to relevant memories.
with valence (DMV) (Klein and Manning, 2004) ON-LSTM allows hidden neurons to learn long-
and its extension (Daumé III, 2009; Gillenwater term or short-term information by a novel gating
et al., 2010). To effectively learn the DMV model mechanism and activation function. In URNNG
for better parsing accuracy, a variety of inductive bi- (Kim et al., 2019b), amortized variational infer-
ases and handcrafted features, such as correlations ence was applied between a recurrent neural net-
between parameters of grammar rules involving work grammar (RNNG) (Dyer et al., 2016) decoder
different part-of-speech (POS) tags, have been pro- and a tree structure inference network, which en-
posed to incorporate prior information into learning. courages the decoder to generate reasonable tree
The most recent progress is the neural DMV model structures. DIORA (Drozdov et al., 2019) proposed
(Jiang et al., 2016), which uses a neural network using inside-outside dynamic programming to com-
model to predict the grammar rule probabilities pose latent representations from all possible binary
7197trees. The representations of inside and outside In other words, each syntactic distance di is as-
passes from the same sentences are optimized to sociated with a split point (i, i + 1) and specify the
be close to each other. The compound PCFG (Kim relative order in which the sentence will be split
et al., 2019a) achieves grammar induction by max- into smaller components. Thus, any sequence of
imizing the marginal likelihood of the sentences n − 1 real values can unambiguously map to an
which are generated by a probabilistic context-free unlabeled binary constituency tree with n leaves
grammar (PCFG). Tree Transformer (Wang et al., through the Algorithm 1 (Shen et al., 2018b). As
2019) adds extra locality constraints to the Trans- Shen et al. (2018c,a); Wang et al. (2019) pointed
former encoder’s self-attention to encourage the out, the syntactic distance reflects the information
attention heads to follow a tree structure such that communication between constituents. More con-
each token can only attend on nearby neighbors in cretely, a large syntactic distance τi represents that
lower layers and gradually extend the attention field short-term or local information should not be com-
to further tokens when climbing to higher layers. municated between (x≤i ) and (x>i ). While cooper-
Neural L-PCFG (Zhu et al., 2020) demonstrated ating with appropriate neural network architectures,
that PCFG can benefit from modeling lexical de- we can leverage this feature to build unsupervised
pendencies. Similar to StructFormer, the Neural dependency parsing models.
L-PCFG induces both constituents and dependen-
cies within a single model. Algorithm 1 Distance to binary constituency
Though large scale pre-trained models have tree
dominated most natural language processing tasks, 1: function C ONSTITUENT(w, d)
2: if d = [] then
some recent work indicates that neural network 3: T ⇐ Leaf(w)
models can see accuracy gains by leveraging syn- 4: else
tactic information rather than ignoring it (Marcheg- 5: i ⇐ arg maxi (d)
6: childl ⇐ Constituent(w≤i , di , d>i )
Strubell et al. (2018) introduces syntactically- 8: T ⇐ Node(childl , childr )
informed self-attention that force one attention 9: return T
head to attend on the syntactic governor of the
input token. Omote et al. (2019) and Deguchi Algorithm 2 Converting binary constituency
et al. (2019) argue that dependency-informed self- tree to dependency graph
attention can improve Transformer’s performance 1: function D EPENDENT(T, ∆)
2: if T = w then
on machine translation. Kuncoro et al. (2020) 3: D ⇐ [], parent ⇐ w
shows that syntactic biases help large scale pre- 4: else
trained models, like BERT, to achieve better lan- 5: childl , childr ⇐ T
6: Dl , parentl ⇐ Dependent(childl , ∆)
guage understanding. 7: Dr , parentr ⇐ Dependent(childr , ∆)
8: D ⇐ Union(Dl , Dr )
3 Syntactic Distance and Height 9: if ∆(parentl ) > ∆(parentr ) then
10: D.add(parentl ← parentr )
11: parent ⇐ parentl
In this section, we first reintroduce the concepts 12: else
of syntactic distance and height, then discuss their 13: D.add(parentr ← parentl )
14: parent ⇐ parentr
relations in the context of StructFormer.
15: return D, parent
3.1 Syntactic Distance 3.2 Syntactic Height
Syntactic distance is proposed in Shen et al. Syntactic height is proposed in Luo et al. (2019),
(2018b) to quantify the process of splitting sen- where it is used to capture the distance to the root
tences into smaller constituents. node in a dependency graph. A word with high
Definition 3.1. Let T be a constituency tree for syntactic height means it is close to the root node.
sentence (w1 , ..., wn ). The height of the lowest In this paper, to match the definition of syntactic
common ancestor for consecutive words xi and distance, we redefine syntactic height as:
xi+1 is τ̃i . Syntactic distances T = (τ1 , ..., τn−1 ) Definition 3.2. Let D be a dependency graph for
are defined as a sequence of n − 1 real scalars that sentence (w1 , ..., wn ). The height of a token wi
share the same rank as (τ̃1 , ..., τ̃n−1 ). in D is δ̃i . The syntactic heights of D can be any
7198sequence of n real scalars ∆ = (δ1 , ..., δn ) that
share the same rank as (δ̃1 , ..., δ̃n ).
Although the syntactic height is defined based
on the dependency structure, we cannot rebuild the
original dependency structure by syntactic heights (a) Model Architecture (b) Parsing Network
alone, since there is no information about whether a
token should be attached to the left side or the right Figure 3: The Architecture of StructFormer. The parser
side. However, given an unlabelled constituent tree, takes shared word embeddings as input, outputs syntac-
tic distances T, syntactic heights ∆, and dependency
we can convert it into a dependency graph with
distributions between tokens. The transformer layers
the help of syntactic distance. The converting pro- take word embeddings and dependency distributions
cess is similar to the standard process of converting as input, output contextualized embeddings for input
constituency treebank to dependency treebank (Gel- words.
bukh et al., 2005). Instead of using the constituent
labels and POS tags to identify the parent of each
constituent, we simply assign the token with the xj with τj > δi can attend across the split point
largest syntactic height as the parent of each con- (i, i + 1). Thus tokens with small syntactic height
stituent. The conversion algorithm is described in are limited to attend to nearby tokens. Figure 2
Algorithm 2. In Appendix A.1, we also propose a provides an example of T, ∆ and respective depen-
joint algorithm, that takes T and ∆ as inputs and dency graph D.
jointly outputs a constituency tree and dependency However, if the left and right boundary syntac-
graph. tic distance of a constituent [l, r] are too large, all
words in [l, r] will be forced to only attend to other
words in [l, r]. Their contextual embedding will
not be able to encode the full context. To avoid this
phenomena, we propose calibrating T according to
∆ in Appendix A.2
4 StructFormer
In this section, we present the StructFormer model.
Figure 3a shows the architecture of StructFormer,
which includes a parser network and a Transformer
module. The parser network predicts T and ∆,
then passes them to a set of differentiable func-
tions to generate dependency distributions. The
Figure 2: An example of T, ∆ and respective depen- Transformer module takes these distributions and
dency graph D. Solid lines represent dependency rela-
the sentence as input to computes a contextual em-
tions between tokens. StructFormer only allow tokens
with dependency relation to attend on each other. bedding for each position. The StructFormer can
be trained in an end-to-end fashion on a Masked
Language Model task. In this setting, the gradient
3.3 The relation between Syntactic Distance back propagates through the relation distributions
and Height into the parser.
As discussed previously, the syntactic distance con- 4.1 Parsing Network
trols information communication between the two As shown in Figure 3b, the parsing network takes
sides of the split point. The syntactic height quanti- word embeddings as input and feeds them into sev-
fies the centrality of each token in the dependency eral convolution layers:
graph. A token with large syntactic height tends
to have more long-term dependency relations to sl,i = tanh (Conv (sl−1,i−W , ..., sl−1,i+W )) (1)
connect different parts of the sentence together. In
StructFormer, we quantify the syntactic distance where sl,i is the output of l-th layer at i-th position,
and height on the same scale. Given a split point s0,i is the input embedding of token wi , and 2W +1
(i, i + 1) and it’s syntactic distance δi , only tokens is the convolution kernel size.
7199Given the output of the convolution stack sN,i , term. Thus the probability that the l-th (l < i)
we parameterize the syntactic distance T as: token is inside C(xi ) is equal to the probability that
δ̃i is larger then the maximum distance τ between
τ tanh Wτ sN,i
W 1 2 s , l and i:
N,i+1
τi = (2)
1≤i≤n−1 p(l ∈ C(xi )) = p(δ̃i > max(τi−1 , ..., τl )) (7)
∞, i = 0 or i = n
= σ((δi − max(τl , ..., τi−1 ))/µ)
where τi is the contextualized distance for the i-
th split point between token wi and wi+1 . The Then we can compute the probability distribution
syntactic height ∆ is parameterized in a similar for l:
way:
p(l|i) = p(l ∈ C(xi )) − p(l − 1 ∈ C(xi ))
δi = W1δ tanh W2δ sN,i + bδ2 + bδ1 (3) = σ((δi − max(τl , ..., τi−1 ))/µ) −
σ((δi − max(τl−1 , ..., τi−1 ))/µ) (8)
4.2 Estimate the Dependency Distribution
Given T and ∆, we now explain how to estimate Similarly, we can compute the probability distribu-
the probability p(xj |xi ) such that the j-th token is tion for r:
the parent of the i-th token. The first step is iden-
p(r|i) = σ((δi − max(τi , ..., τr−1 ))/µ) −
tifying the smallest legal constituent C(xi ), that
contains xi and xi is not C(xi )’s parent. The sec- σ((δi − max(τi , ..., τr ))/µ) (9)
ond step is identifying the parent of the constituent
xj = Pr(C(xi )). Given the discussion in section The probability distribution for [l, r] = C(xi ) can
3.2, the parent of C(xi ) must be the parent of xi . be computed as:
Thus, the two-stages of identifying the parent of xi
p(l|i)p(r|i), l ≤ i ≤ r
can be formulated as: pC ([l, r]|i) = (10)
0, otherwise
D(xi ) = Pr(C(xi )) (4)
The second step is to identify the parent of [l, r].
In StructFormer, C(xi ) is represented as con- For any constituent [l, r], we choose the j =
stituent [l, r], where l is the starting index (l ≤ i) of argmaxk∈[l,r] (δk ) as the parent of [l, r]. In the
C(xi ) and r is the ending index (r ≥ i) of C(xi ). previous example, given constituent [4, 8], the
In a dependency graph, xi is only connected to maximum syntactic height is δ6 = 4.5, thus
its parent and dependents. This means that xi does Pr([4, 8]) = x6 . We use softmax function to pa-
not have direct connection to the outside of C(xi ). rameterize the probability pPr (j|[l, r]):
In other words, C(xi ) = [l, r] is the smallest con- (
P exp(hj /µ2 ) , l≤t≤r
stituent that satisfies: pPr (j|[l, r]) = l≤k≤r exp(hk /µ2 ) (11)
0, otherwise
δi < τl−1 , δi < τr (5)
Given probability p(j|[l, r]) and p([l, r]|i), we can
where τl−1 is the first τ δ4 and pD (j|i) =
0, i=j
τ8 = ∞ > δ4 , thus C(x4 ) = [4, 8]. To make (12)
this process differentiable, we define τk as a real
value and δi as a probability distribution p(δ̃i ). For 4.3 Dependency-Constrained Multi-head
the simplicity and efficiency of computation, we Self-Attention
directly parameterize the cumulative distribution The multi-head self-attention in the transformer
function p(δ̃i > τk ) with sigmoid function: can be seen as a information propagation mecha-
p(δ̃i > τk ) = σ((δi − τk )/µ1 ) (6) nism on the complete graph G = (X, E), where
the set of vertices X contains all n tokens in the
where σ is the sigmoid function, δi is the mean of sentence, and the set of edges E contains all possi-
distribution p(δ̃i ) and µ1 is a learnable temperature ble word pairs (xi , xj ). StructFormer replace the
7200complete graph G with a soft dependency graph 5 Experiments
D = (X, A), where A is the matrix of n × n prob-
abilities. Aij = pD (j|i) is the probability of the We evaluate the proposed model on three tasks:
j-th token depending on the i-th token. The reason Masked Language Modeling, Unsupervised Con-
that we called it a directed edge is that each specific stituency Parsing and Unsupervised Dependency
head is only allow to propagate information either Parsing.
from parent to dependent or from from dependent Our implementation of StructFormer is close to
to parent. To do so, structformer associate each the original Transformer encoder (Vaswani et al.,
attention head with a probability distribution over 2017). Except that we put the layer normalization
parent or dependent relation. in front of each layer, similar to the T5 model (Raf-
fel et al., 2019). We found that this modification
exp(wparent ) allows the model to converges faster. For all exper-
pparent = (13) iments, we set the number of layers L = 8, the em-
exp(wparent ) + exp(wdep )
bedding size and hidden size to be dmodel = 512,
exp(wdep )
pdep = (14) the number of self-attention heads h = 8, the feed-
exp(wparent ) + exp(wdep )
forward size df f = 2048, dropout rate as 0.1, and
where wparent and wdep are learnable parameters the number of convolution layers in the parsing
that associated with each attention head, pparent is network as Lp = 3.
the probability that this head will propagate infor-
5.1 Masked Language Model
mation from parent to dependent, vice versa. The
model will learn to assign this association from the Masked Language Modeling (MLM) has been
downstream task via gradient descent. Then we widely used as a pretraining object for larger-scale
can compute the probability that information can pretraining models. In BERT (Devlin et al., 2018)
be propagated from node j to node i via this head: and RoBERTa (Liu et al., 2019), authors found
that MLM perplexities on held-out evaluation set
pi,j = pparent pD (j|i) + pdep pD (i|j) (15) have a positive correlation with the end-task per-
formance. We trained and evaluated our model
However, Htut et al. (2019) pointed out that differ- on 2 different datasets: the Penn TreeBank (PTB)
ent heads tend to associate with different type of and BLLIP. In our MLM experiments, each token
universal dependency relations (including nsubj, has an independent chance to be replaced by a
obj, advmod, etc), but there is no generalist head mask token , except that we never replace
can that work with all different relations. To ac- < unk > token. The training and evaluation ob-
commodate this observation, we compute a indi- ject for Masked Language Model is to predict the
vidual probability for each head and pair of tokens replaced tokens. The performance of MLM is eval-
(xi , xj ): uated by measuring perplexity on masked words.
PTB is a standard dataset for language model-
QK T ing (Mikolov et al., 2012) and unsupervised con-
qi,j = sigmoid √ (16) stituency parsing (Shen et al., 2018c; Kim et al.,
dk
2019a). Following the setting proposed in Shen
where Q and K are query and key matrix in a et al. (2018c), we use Mikolov et al. (2012)’s
standard transformer model and dk is the dimen- prepossessing process, which removes all punc-
sion of attention head. The equation is inspired tuations, and replaces low frequency tokens with
by the scaled dot-product attention in transformer. . The preprocessing results in a vocabu-
We replace the original softmax function with a lary size of 10001 (including , and
sigmoid function, so qi,j became an independent ). For PTB, we use a 30% mask rate.
probability that indicates whether xi should attend BLLIP is a large Penn Treebank-style parsed
on xj through the current attention head. In the corpus of approximately 24 million sentences. We
end, we propose to replace transformer’s scaled dot- train and evaluate StructFormer on three splits of
product attention with our dependency-constrained BLLIP: BLLIP-XS (40k sentences, 1M tokens),
self-attention: BLLIP-SM (200K sentences, 5M tokens), and
BLLIP-MD (600K sentences, 14M tokens). They
Attention(Qi , Kj , Vj , D) = pi,j qi,j Vj (17) are obtained by randomly sampling sections from
7201BLLIP BLLIP BLLIP PRPN ON C-PCFG Tree-T Ours
Model PTB
-XS -SM -MD
SBAR 50.0% 52.5% 56.1% 36.4% 48.7%
Transformer 64.05 93.90 19.92 14.31 NP 59.2% 64.5% 74.7% 67.6% 72.1%
StructFormer 60.94 57.28 18.70 13.70 VP 46.7% 41.0% 41.7% 38.5% 43.0%
PP 57.2% 54.4% 68.8% 52.3% 74.1%
Table 1: Masked Language Model perplexities on dif- ADJP 44.3% 38.1% 40.4% 24.7% 51.9%
ADVP 32.8% 31.6% 52.5% 55.1% 69.5%
ferent datasets.
Table 3: Fraction of ground truth constituents that were
BLLIP 1987-89 Corpus Release 1. All models are predicted as a constituent by the models broken down
tested on a shared held-out test set (20k sentences, by label (i.e. label recall)
500k tokens). Following the settings provided in
(Hu et al., 2020), we use subword-level vocabulary
extracted from the GPT-2 pre-trained model rather the C-PCFG (Kim et al., 2019a) achieve a stronger
than the BLLIP training corpora. For BLLIP, we parsing performance with its strong linguistic con-
use a 15% mask rate. straints (e.g. a finite set of production rules), Struct-
The masked language model results are shown in Former may have a border domain of application.
Table 1. StructFormer consistently outperforms our For example, it can replace the standard trans-
Transformer baseline. This result aligns with previ- former encoder in most of the popular large-scale
ous observations that linguistically informed self- pre-trained language models (e.g. BERT and Re-
attention can help Transformers achieve stronger BERTa) and transformer based machine translation
performance. We also observe that StructFormer models. Different from the transformer-based Tree-
converges much faster than the standard Trans- T (Wang et al., 2019), we did not directly use con-
former model. stituents to restrict the self-attention receptive field.
But StructFormer achieves a stronger constituency
5.2 Unsupervised Constituency Parsing parsing performance. This result may suggest that
The unsupervised constituency parsing task com- dependency relations are more suitable for gram-
pares the latent tree structure induced by the model mar induction in transformer-based models. Table
with those annotated by human experts. We use 3 shows that our model achieves strong accuracy
the Algorithm 1 to predict the constituency trees while predicting Noun Phrase (NP), Preposition
from T predicted by StructFormer. Following the Phrase (PP), Adjective Phrase (ADJP), and Adverb
experiment settings proposed in Shen et al. (2018c), Phrase (ADVP).
we take the model trained on PTB dataset and eval- 5.3 Unsupervised Dependency Parsing
uate it on WSJ test set. The WSJ test set is section
23 of WSJ corpus, it contains 2416 human expert The unsupervised dependency parsing evaluation
labeled sentences. Punctuation is ignored during compares the induced dependency relations with
the evaluation. those in the reference dependency graph. The most
common metric is the Unlabeled Attachment Score
Methods UF1 (UAS), which measures the percentage that a token
RANDOM 21.6 is correctly attached to its parent in the reference
LBRANCH 9.0 tree. Another widely used metric for unsupervised
RBRANCH 39.8 dependency parsing is Undirected Unlabeled At-
PRPN (Shen et al., 2018a) 37.4 (0.3) tachment Score (UUAS) measures the percentage
ON-LSTM (Shen et al., 2018c) 47.7 (1.5)
Tree-T (Wang et al., 2019) 49.5
that the reference undirected and unlabeled connec-
URNNG (Kim et al., 2019b) 52.4 tions are recovered by the induced tree. Similar
C-PCFG (Kim et al., 2019a) 55.2 to the unsupervised constituency parsing, we take
Neural L-PCFGs (Zhu et al., 2020) 55.31
StructFormer 54.0 (0.3) the model trained on PTB dataset and evaluate it
on WSJ test set (section 23). For the WSJ test set,
Table 2: Unsupervised constituency parsing tesults. * reference dependency graphs are converted from
results are from Kim et al. (2020). UF1 stands for Un- its human-annotated constituency trees. However,
labeled F1. there are two different sets of rules for the conver-
sion: the Stanford dependencies and the CoNLL de-
Table 2 shows that our model achieves strong re- pendencies. While Stanford dependencies are used
sults on unsupervised constituency parsing. While as reference dependencies in previous unsupervised
7202Relations MLM Constituency Stanford Conll
PPL UF1 UAS UUAS UAS UUAS
parent+dep 60.9 (1.0) 54.0 (0.3) 46.2 (0.4) 61.6 (0.4) 36.2 (0.1) 56.3 (0.2)
parent 63.0 (1.2) 40.2 (3.5) 32.4 (5.6) 49.1 (5.7) 30.0 (3.7) 50.0 (5.3)
dep 63.2 (0.6) 51.8 (2.4) 15.2 (18.2) 41.6 (16.8) 20.2 (12.2) 44.7 (13.9)
Table 4: The performance of StructFormer with different combinations of attention masks. UAS stands for Unla-
beled Attachment Score. UUAS stands for Undirected Unlabeled Attachment Score.
Methods UAS the strong performances on both dependency pars-
w/o gold POS tags ing and masked language modeling, we believe
DMV (Klein and Manning, 2004) 35.8 that the dependency graph schema could be a vi-
E-DMV (Headden III et al., 2009) 38.2
UR-A E-DMV (Tu and Honavar, 2012) 46.1
able substitute for the complete graph schema used
CS* (Spitkovsky et al., 2013) 64.4* in the standard transformer. Appendix A.4 provides
Neural E-DMV (Jiang et al., 2016) 42.7 examples of parent distribution.
Gaussian DMV (He et al., 2018) 43.1 (1.2)
INP (He et al., 2018) 47.9 (1.2) Since our model uses a mixture of the relation
Neural L-PCFGs (Zhu et al., 2020) 40.5 (2.9)
StructFormer 46.2 (0.4) probability distribution for each self-attention head,
we also studied how different combinations of re-
w/ gold POS tags (for reference only)
DMV (Klein and Manning, 2004) 39.7 lations affect the performance of our model. Table
UR-A E-DMV (Tu and Honavar, 2012) 57.0 6 shows that the model can achieve the best per-
MaxEnc (Le and Zuidema, 2015) 65.8
Neural E-DMV (Jiang et al., 2016) 57.6
formance while using both parent and dependent
CRFAE (Cai et al., 2017) 55.7 relations. The model suffers more on dependency
L-NDMV† (Han et al., 2017) 63.2 parsing if the parent relation is removed. And if the
dependent relationship is removed, the model will
Table 5: Dependency Parsing Results on WSJ testset. suffer more on the constituency parsing. Appendix
Starred entries (*) benefit from additional punctuation-
A.3 shows the weight for parent and dependent
based constraints. Daggered entries († ) benefit from
larger additional training data. Baseline results are relations learnt from MLM tasks. It’s interesting
from He et al. (2018). to observe that Structformer tends to focus on the
parent relations in the first layer, and start to use
both relations from the second layer.
parsing papers, we noticed that our model some-
times output dependency structures that are closer
to the CoNLL dependencies. Therefore, we report 6 Conclusion
UAS and UUAS for both Stanford and CoNLL
dependencies. Following the setting of previous
papers (Jiang et al., 2016), we ignored the punctua- In this paper, we introduce a novel dependency and
tion during evaluation. To obtain the dependency constituency joint parsing framework. Based on
relation from our model, we compute the argmax the framework, we propose StructFormer, a new
for dependency distribution: unsupervised parsing algorithm that does unsuper-
vised dependency and constituency parsing at the
k = argmaxj6=i pD (j|i) (18) same time. We also introduced a novel dependency-
constrained self-attention mechanism that allows
and assign the k-th token as the parent of i-th token. each attention head to focus on a specific mixture
Table 5 shows that our model achieves competi- of dependency relations. This brings Transformers
tive dependency parsing performance while com- closer to modeling a directed dependency graph.
paring to other models that do not require gold The experiments show promising results that Struct-
POS tags. While most of the baseline models still Former can induce meaningful dependency and
rely on some kind of latent POS tags or pre-trained constituency structures and achieve better perfor-
word embeddings, StructFormer can be seen as an mance on masked language model tasks. This re-
easy-to-use alternative that works in an end-to-end search provides a new path to build more linguistic
fashion. Table 6 shows that our model recovers bias into a pre-trained language model.
61.6% of undirected dependency relations. Given
7203References Junxian He, Graham Neubig, and Taylor Berg-
Kirkpatrick. 2018. Unsupervised learning of syntac-
Jiong Cai, Yong Jiang, and Kewei Tu. 2017. Crf tic structure with invertible neural projections. In
autoencoder for unsupervised dependency parsing. Proceedings of the 2018 Conference on Empirical
arXiv preprint arXiv:1708.01018. Methods in Natural Language Processing, pages
1292–1302.
Shay B Cohen, Dipanjan Das, and Noah A Smith. 2011.
Unsupervised structure prediction with non-parallel
William P Headden III, Mark Johnson, and David Mc-
multilingual guidance. In Proceedings of the 2011
Closky. 2009. Improving unsupervised dependency
Conference on Empirical Methods in Natural Lan-
parsing with richer contexts and smoothing. In Pro-
guage Processing, pages 50–61.
ceedings of human language technologies: the 2009
Shay B Cohen and Noah A Smith. 2009. Shared logis- annual conference of the North American chapter of
tic normal distributions for soft parameter tying in the association for computational linguistics, pages
unsupervised grammar induction. In Proceedings of 101–109.
Human Language Technologies: The 2009 Annual
Conference of the North American Chapter of the As- Phu Mon Htut, Jason Phang, Shikha Bordia, and
sociation for Computational Linguistics, pages 74– Samuel R Bowman. 2019. Do attention heads in
82. bert track syntactic dependencies? arXiv preprint
arXiv:1911.12246.
Hal Daumé III. 2009. Unsupervised search-based
structured prediction. In Proceedings of the 26th Jennifer Hu, Jon Gauthier, Peng Qian, Ethan Wilcox,
Annual International Conference on Machine Learn- and Roger P Levy. 2020. A systematic assessment
ing, pages 209–216. of syntactic generalization in neural language mod-
els. arXiv preprint arXiv:2005.03692.
Hiroyuki Deguchi, Akihiro Tamura, and Takashi Ni-
nomiya. 2019. Dependency-based self-attention for Yong Jiang, Wenjuan Han, Kewei Tu, et al. 2016. Un-
transformer nmt. In Proceedings of the Interna- supervised neural dependency parsing. Association
tional Conference on Recent Advances in Natural for Computational Linguistics (ACL).
Language Processing (RANLP 2019), pages 239–
246. Taeuk Kim, Jihun Choi, Daniel Edmiston, and Sang-
goo Lee. 2020. Are pre-trained language mod-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and els aware of phrases? simple but strong base-
Kristina Toutanova. 2018. Bert: Pre-training of deep lines for grammar induction. arXiv preprint
bidirectional transformers for language understand- arXiv:2002.00737.
ing. arXiv preprint arXiv:1810.04805.
Yoon Kim, Chris Dyer, and Alexander M Rush. 2019a.
Andrew Drozdov, Patrick Verga, Mohit Yadav, Mohit Compound probabilistic context-free grammars for
Iyyer, and Andrew McCallum. 2019. Unsupervised grammar induction. In Proceedings of the 57th An-
latent tree induction with deep inside-outside recur- nual Meeting of the Association for Computational
sive auto-encoders. In Proceedings of the 2019 Con- Linguistics, pages 2369–2385.
ference of the North American Chapter of the Asso-
ciation for Computational Linguistics: Human Lan- Yoon Kim, Alexander M Rush, Lei Yu, Adhiguna Kun-
guage Technologies, Volume 1 (Long and Short Pa- coro, Chris Dyer, and Gábor Melis. 2019b. Unsuper-
pers), pages 1129–1141. vised recurrent neural network grammars. In Pro-
ceedings of the 2019 Conference of the North Amer-
Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros,
ican Chapter of the Association for Computational
and Noah A Smith. 2016. Recurrent neural network
Linguistics: Human Language Technologies, Vol-
grammars. In Proceedings of NAACL-HLT, pages
ume 1 (Long and Short Papers), pages 1105–1117.
199–209.
Alexander Gelbukh, Sulema Torres, and Hiram Calvo. Dan Klein. 2005. The unsupervised learning of natural
2005. Transforming a constituency treebank into a language structure. Stanford University Stanford.
dependency treebank. Procesamiento del lenguaje
natural, (35):145–152. Dan Klein and Christopher D Manning. 2002. A gener-
ative constituent-context model for improved gram-
Jennifer Gillenwater, Kuzman Ganchev, João Graça, mar induction. In Proceedings of the 40th Annual
Fernando Pereira, and Ben Taskar. 2010. Sparsity Meeting of the Association for Computational Lin-
in dependency grammar induction. ACL 2010, page guistics, pages 128–135.
194.
Dan Klein and Christopher D Manning. 2004. Corpus-
Wenjuan Han, Yong Jiang, and Kewei Tu. 2017. based induction of syntactic structure: Models of de-
Dependency grammar induction with neural lexi- pendency and constituency. In Proceedings of the
calization and big training data. arXiv preprint 42nd annual meeting of the association for computa-
arXiv:1708.00801. tional linguistics (ACL-04), pages 478–485.
7204Adhiguna Kuncoro, Lingpeng Kong, Daniel Fried, International Conference on Learning Representa-
Dani Yogatama, Laura Rimell, Chris Dyer, and Phil tions.
Blunsom. 2020. Syntactic structure distillation pre-
training for bidirectional encoders. arXiv preprint Valentin I Spitkovsky, Hiyan Alshawi, Angel Chang,
arXiv:2005.13482. and Dan Jurafsky. 2011. Unsupervised dependency
parsing without gold part-of-speech tags. In Pro-
Phong Le and Willem Zuidema. 2015. Unsupervised ceedings of the 2011 Conference on Empirical Meth-
dependency parsing: Let’s use supervised parsers. ods in Natural Language Processing, pages 1281–
arXiv preprint arXiv:1504.04666. 1290.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man- Valentin I Spitkovsky, Daniel Jurafsky, and Hiyan Al-
dar Joshi, Danqi Chen, Omer Levy, Mike Lewis, shawi. 2013. Breaking out of local optima with
Luke Zettlemoyer, and Veselin Stoyanov. 2019. count transforms and model recombination: A study
Roberta: A robustly optimized bert pretraining ap- in grammar induction.
proach. arXiv preprint arXiv:1907.11692.
Emma Strubell, Patrick Verga, Daniel Andor,
Hongyin Luo, Lan Jiang, Yonatan Belinkov, and James David Weiss, and Andrew McCallum. 2018.
Glass. 2019. Improving neural language models by Linguistically-informed self-attention for semantic
segmenting, attending, and predicting the future. In role labeling. arXiv preprint arXiv:1804.08199.
Proceedings of the 57th Annual Meeting of the Asso-
ciation for Computational Linguistics, pages 1483– Kewei Tu and Vasant Honavar. 2012. Unambiguity reg-
1493. ularization for unsupervised learning of probabilis-
tic grammars. In Proceedings of the 2012 Joint
Diego Marcheggiani and Ivan Titov. 2017. En- Conference on Empirical Methods in Natural Lan-
coding sentences with graph convolutional net- guage Processing and Computational Natural Lan-
works for semantic role labeling. arXiv preprint guage Learning, pages 1324–1334.
arXiv:1703.04826.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob
Tomáš Mikolov et al. 2012. Statistical language mod- Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz
els based on neural networks. Presentation at Kaiser, and Illia Polosukhin. 2017. Attention is all
Google, Mountain View, 2nd April, 80:26. you need. In Advances in neural information pro-
cessing systems, pages 5998–6008.
Yutaro Omote, Akihiro Tamura, and Takashi Ninomiya.
2019. Dependency-based relative positional encod- Yaushian Wang, Hung-Yi Lee, and Yun-Nung Chen.
ing for transformer nmt. In Proceedings of the In- 2019. Tree transformer: Integrating tree structures
ternational Conference on Recent Advances in Natu- into self-attention. In Proceedings of the 2019 Con-
ral Language Processing (RANLP 2019), pages 854– ference on Empirical Methods in Natural Language
861. Processing and the 9th International Joint Confer-
ence on Natural Language Processing (EMNLP-
John K Pate and Sharon Goldwater. 2013. Unsuper- IJCNLP), pages 1060–1070.
vised dependency parsing with acoustic cues. Trans-
actions of the Association for Computational Lin- Hao Zhu, Yonatan Bisk, and Graham Neubig. 2020.
guistics, 1:63–74. The return of lexical dependencies: Neural lexical-
ized pcfgs. Transactions of the Association for Com-
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine putational Linguistics, 8:647–661.
Lee, Sharan Narang, Michael Matena, Yanqi Zhou,
Wei Li, and Peter J Liu. 2019. Exploring the limits
of transfer learning with a unified text-to-text trans-
former. arXiv preprint arXiv:1910.10683.
Yikang Shen, Zhouhan Lin, Chin-wei Huang, and
Aaron Courville. 2018a. Neural language modeling
by jointly learning syntax and lexicon. In Interna-
tional Conference on Learning Representations.
Yikang Shen, Zhouhan Lin, Athul Paul Jacob, Alessan-
dro Sordoni, Aaron Courville, and Yoshua Bengio.
2018b. Straight to the tree: Constituency parsing
with neural syntactic distance. In Proceedings of the
56th Annual Meeting of the Association for Compu-
tational Linguistics (Volume 1: Long Papers), pages
1171–1180.
Yikang Shen, Shawn Tan, Alessandro Sordoni, and
Aaron Courville. 2018c. Ordered neurons: Integrat-
ing tree structures into recurrent neural networks. In
7205A Appendix height, we use a ReLU activation function to keep
only the positive values:
A.1 Joint Dependency and Constituency
Parsing [l,r] = ReLU min τl−1 − δ[l,r] , τr − δ[l,r]
(20)
Algorithm 3 The joint dependency and con- To make sure all constituent are not isolated and
stituency parsing algorithm. Inputs are a sequence maintain the rank of T, we subtract all T by the
of words w, syntactic distances d, syntactic heights maximum of :
h. Outputs are a binary constituency tree T, a de-
δˆi = δi − max
pendency graph D that is represented as a set of [l,r] (21)
{[l,r]}/[1,n]
dependency relations, the parent of dependency
graph D, and the syntactic height of parent.
1: function B UILD T REE(w, d, h)
2: if d = [] and w = [w] and h = [h] then
3: T ⇐ Leaf(w), D ⇐ [], parent ⇐ w, height
⇐h
4: else
5: i ⇐ arg max(d)
6: Tl , Dl , parentl , heightl ⇐
BuildTree(di , w>i , h>i )
8: T ⇐ Node(childl ⇐ Tl , childr ⇐ Tr )
9: D ⇐ Union(Dl , Dr )
10: if heightl > heightr then
11: D.add(parentl ← parentr )
12: parent ⇐ parentl , height ⇐ heightl
13: else
14: D.add(parentr ← parentl )
15: parent ⇐ parentr , height ⇐ heightr
16: return T, D, parent, height
A.2 Calibrating the Syntactic Distance and
Height
In Section 3.3, we explained the relation between
∆ and T, that if δi < τj , the i-th word won’t be
able to attend beyond the j-th split point. How-
ever, in a specific case, the constraint will isolate
a constituent [l, r] from the rest of the sentence.
If τl−1 and τr are larger then all height δl,...,r in
the constituent, then all words in [l, r] won’t be
able to attend on the outside of the constituent.
This phenomenon will prevent their output contex-
tual embedding from encoding the full context. To
avoid this phenomenon, we propose to calibrate
the syntactic distance T according to the syntactic
height ∆. First, we compute the maximum syntac-
tic height for each constituent:
δ[l,r] = max (δl , ..., δr ) , lA.3 Dependency Relation Weights for Self-attention Heads
(a) Dependency relation weights learnt on PTB
(b) Dependency relation weights learnt on BLLIP-SM
Figure 4: Dependency relation weights learnt on different datasets. Row i constains relation weights for all at-
tention heads in the i-th transformer layer. p represents the parent relation. d represents the dependent relation.
We observe a clearer preference for each attention head in the model trained on BLLIP-SM. This probably due to
BLLIP-SM has signficantly more training data. It’s also interesting to notice that the first layer tend to focus on
parent relations.
7207A.4 Dependency Distribution Examples
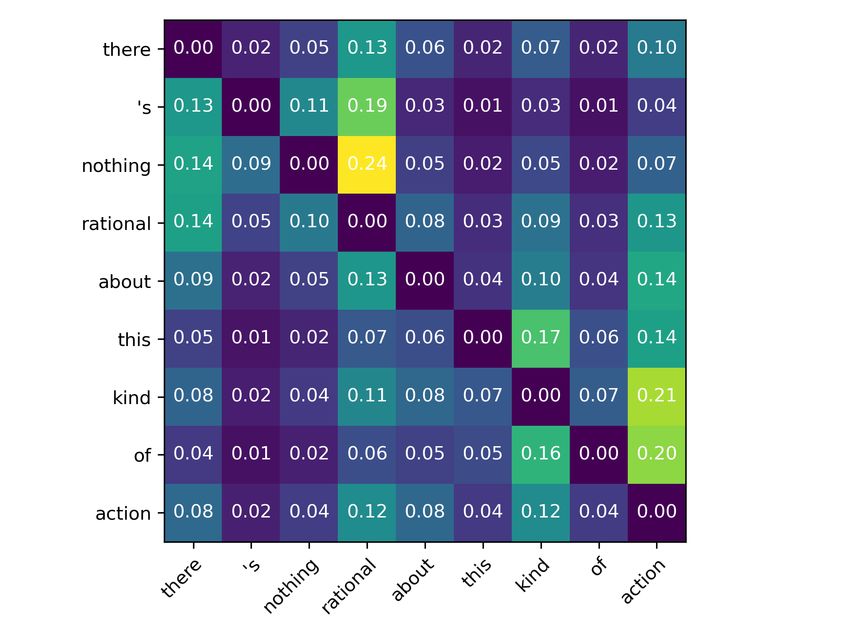
(a)
(b)
Figure 5: Dependency distribution examples from WSJ test set. Each row is the parent distribution for the respec-
tive word. The sum of each distribution may not equal to 1. Against our intuition, the distribution is not very
sharp. This is partially due to the ambiguous nature of the dependency graph. As we previously discussed, at least
two styles of dependency rules (Conll and Stanford) exist. And without extra constraint or supervision, the model
seems trying to model both of them at the same time. One interesting future work will be finding an inductive bias
that can encourage the model to converge to a specific style of dependency graph.
7208A.5 The Performance of StructFormer with different mask rates
Mask rate MLM Constituency Stanford Conll
PPL UF1 UAS UUAS UAS UUAS
0.1 45.3 (1.2) 51.45 (2.7) 31.4 (11.9) 51.2 (8.1) 32.3 (5.2) 52.4 (4.5)
0.2 50.4 (1.3) 54.0 (0.6) 37.4 (12.6) 55.6 (8.8) 33.0 (5.7) 53.5 (4.7)
0.3 60.9 (1.0) 54.0 (0.3) 46.2 (0.4) 61.6 (0.4) 36.2 (0.1) 56.3 (0.2)
0.4 76.9 (1.2) 53.5 (1.5) 34.0 (10.3) 52.0 (7.4) 29.5 (5.4) 50.6 (4.1)
0.5 100.3 (1.4) 53.2 (0.9) 36.3 (9.8) 53.6 (6.8) 30.6 (4.2) 51.3 (3.2)
Table 6: The performance of StructFormer on PTB dataset with different mask rates. Dependency parsing is
especially affected by the masks. Mask rate 0.3 provides the best and the most stable performance.
7209You can also read

















































