SPARK USE CASE IN TELCO - Apache Spark Night 9-2-2014! Chance Coble! - Blacklight Solutions
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

SPARK USE CASE IN TELCO Apache Spark Night 9-2-2014! Chance Coble!

Use Case Profile
➾Telecommunications company
§ Shared business problems/pain
§ Scalable analytics infrastructure is a problem
§ Pushing infrastructure to its limits
§ Open to a proof-of-concept engagement with emerging technology
§ Wanted to test on historical data
➾We introduced Spark Streaming
§ Technology would scale
§ Could prove it enabled new analytic techniques (incident detection)
§ Open to Scala requirement
§ Wanted to prove it was easy to deploy – EC2 helped
2
Spark Streaming in Telco
➾Telecommunications Wholesale Business
§ Process 90 Million calls per day
§ Scale up to 1,000 calls per second
§ nearly half-a-million calls in a 5 minute window
§ Technology is loosely split into
§ Operational Support Systems (OSS)
§ Business Support Systems (BSS)
➾ Core technology is mature
§ Analytics on LAMP stack
§ Technology team is strongly skilled in that stack
3
Jargon
➾ Number
§ Comprised of Country Code (possibly), Area Code (NPA),
Exchange (NXX) and 4 other digits
§ Area codes and exchanges are often geo-coded
1 512 867 5309
4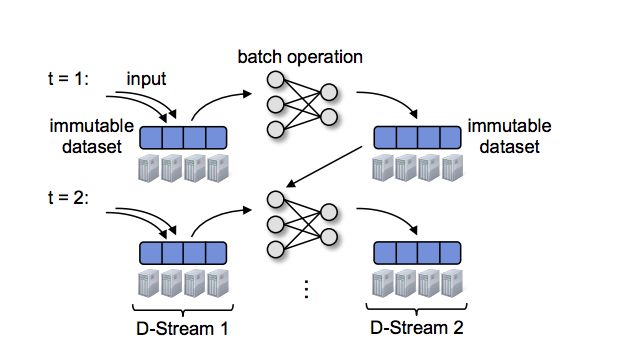
Jargon
➾Trunk Group
§ A trunk is a line connecting transmissions for two points. The group
of trunks has some common property, in this case being owned by
the same entity.
§ Transmissions from ingress trunks are routed to transmissions to
egress trunks.
➾Route – In this case, selection of a trunk group to
facilitate the termination at the calls destination
➾QoS – Quality of Service governed by metrics
§ Call Duration – Short calls are an indication of quality problems
§ ASR – Average Supervision Rate
§ This company measures this as #connected calls / #calls attempted
➾Real-time: Within 15 minutes
5The Problem
➾A switch handles most of their routing
➾Configuration table in switch governs routing
§ if-this-then-that style logic.
➾Proprietary technology handles adjustments to that table
§ Manual intervention also required
Call Logs Business Rules Database Intranet Portal
Application
6The Problem
➾Backend system receives a log of calls from the switch
§ File dumped every few minutes
§ 180 well defined fields representing features of a call event
§ Supports downstream analytics once enriched with pricing, geo-
coding and account information
Their job is to connect calls at the most efficient price
without sacrificing quality
7Why Spark?
➾Interesting technology
§ Workbench can simplify operationalizing analytics
§ They can skip a generation of clunky big data tools
§ Works with their data structures
§ Will “scale-out” rather than up
§ Can handle fault-tolerant in-memory updates
8Spark Basics - Architecture
Worker
Tasks Cache
Worker
Spark Driver
Master Tasks Cache
Spark Context
…
Worker
Tasks Cache
9Spark Basics – Call Status Count Example
val cdrLogPath = ”/cdrs/cdr20140731042210.ssv”
val conf = new SparkConf().setAppName(”CDR Count")
val sc = new SparkContext(conf)
val cdrLines = sc.textFile(cdrLogPath)
val cdrDetails = cdrLines.map(_.split(“;”))
val successful = cdrDetails.filter(x => x(6)==“S”).count()
val unsuccessful = cdrDetails.filter(x => x(6)==“U”).count()
println(”Successful: %s, Unsuccessful: %s”
.format(successful, unsuccessful))
10Spark Basics - RDD’s
➾Operations on data generate distributable tasks through a
Directed Acyclic Graph
§ Functional programming FTW!
➾Resilient
§ Data is redundantly stored, and can be recomputed through a
generated DAG
➾ Distributed
§ The DAG can process each small task, as well as a subset of the
data through optimizations in the Spark planning engine.
➾ Dataset
➾This construct is native to Spark computation
11Spark Basics - RDD’s
➾Lazy
➾Transformations for tasks and slices
12Streaming Applications – Why try it?
➾Streaming
Applications
§ Site Activity Statistics
§ Spam detection
§ System monitoring
§ Intrusion Detection
§ Telecommunications
Network Data
13Streaming Models
➾Record-at-a-time
§ Receive One Record and process it
§ Simple, low-latency
§ High-Throughput
➾Micro-Batch
§ Receive records and occasionally run a batch process over a
window
§ Process *must* run fast enough to handle all records collected
§ Harder to reduce latency
§ Easy Reasoning
§ Global state
§ Fault tolerance
§ Unified Code
14DStreams
➾Stands for Discretized Streams
➾A series of RDD’s
➾Spark already provided computation model on RDD’s
➾Note records are ordered as they are received
§ They are also time-stamped for global computation in that order
§ Is that always the way you want to see your data?
15Fault Tolerance – Parallel Recovery
➾ Failed Nodes
➾ Stragglers!
16Fault Tolerance - Recompute
17Throughput vs. Latency
18Anatomy of a Spark Streaming Program
val sparkConf = new SparkConf().setAppName(“QueueStream”)
val ssc = new StreamingContext(sparkConf, Seconds(1))
val rddQueue = new SynchronizedQueue[RDD[Int]]()
val inputStream = ssc.queueStream(rddQueue)
val mappedStream = inputStream.map(x => (x % 10, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
reducedStream.print()
Utilities also available for
Twitter
Kafka
ssc.start() Flume
for(i ß 1 to 30) { Filestream
rddQueue += ssc.sparkContext.makeRDD(1 to 1000, 10)
Thread.sleep(1000)
}
ssc.stop()
19Windows
Slide Window
20Streaming Call Analysis with Windows
val path = "/Users/chance/Documents/cdrdrop”
val conf = new SparkConf()
.setMaster("local[12]")
.setAppName("CDRIncidentDetection")
.set("spark.executor.memory","8g")
val ssc = new StreamingContext(conf,Seconds(iteration))
val callStream = ssc.textFileStream(path)
val cdr = callStream.window(Seconds(window),Seconds(slide)).map(_.split(";"))
val cdrArr = cdr.filter(c => c.length>136)
.map(c => extractCallDetailRecord(c))
val result = detectIncidents(cdrArr)
result.foreach(rdd => rdd.take(10)
.foreach{case(x,(d,high,low,res)) =>
println(x + "," + high + "," + d + "," + low + "," + res) })
ssc.start()
ssc.awaitTermination()
21Demonstration
22Can we enable new analytics?
➾Incident detection
§ Chose a univariate technique[1] to detect behavior out of profile
from recent events
§ Technique identifies Recent
§ out of profile events Window
§ dramatic shifts in the profile
§ Easy to understand
23Is it simple to deploy?
➾No, but EC2 helped
➾Client had no Hadoop, and little NoSQL expertise
➾Develop and Deploy
§ Built with sbt, ran on master
➾Architecture involved
§ Pushed new call detail logs to HDFS on EC2
§ Streaming picks up new data and updates RDD’s accordingly
§ Results were explored in two ways
§ Accessing results through data virtualization
§ Writing RDD results (small) to SQL database
§ Using a business intelligence tool to create report content
Call Logs Streaming DataCurrent Multiple
Analysis and Reporting
Processing Delivery
HDFS on EC2 Dashboards
Options
24Summary of Results
➾Technology would scale
§ Handled 5 minutes of data in just a few seconds
➾Proved new analytics enabled
§ Solved single-variable incident detection
§ Small, simple code
➾Made a case for Scala and Hadoop adoption
§ Team is still skeptical
➾Wanted to prove it was easy to deploy – EC2 helped
§ Burned on forward slash bug in AWS secret token
25Incident Visual
26References
➾[1] Zaharia et al : Discretized Streams
➾[2] Zaharia et al: Discretized Streams: Fault-Tolerant Streaming
➾[3] Das : Spark Streaming – Real-time Big-Data Processing
➾[4] Spark Streaming Programming Guide
➾[5] Running Spark on EC2
➾[6] Spark on EMR
➾[7] Ahelegby: Time Series Outliers
27Contact Us
CONTACT US
Email: chance at blacklightsolutions.com
Phone: 512.795.0855
Web: www.blacklightsolutions.com
Twitter: @chancecoble
28You can also read

















































