Pan More Gold from the Sand: Refining Open-domain Dialogue Training with Noisy Self-Retrieval Generation
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Pan More Gold from the Sand: Refining Open-domain Dialogue Training
with Noisy Self-Retrieval Generation
Yihe Wang1 , Yitong Li2,3 , Yasheng Wang2 , Fei Mi2
Pingyi Zhou2 , Xin Wang1 , Jin Liu1∗, Qun Liu2 , Xin Jiang2
1
School of Computer Science, Wuhan University
2
Noah’s Ark Lab, Huawei
3
Huawei Technologies Ltd.
Abstract resources such as Reddit and Twitter, are hetero-
Real human conversation data are complicated,
geneous and contain utterances with many various
heterogeneous, and noisy, from whom build- topics, more freedom of topic shifting, and vague
ing open-domain dialogue systems remains responses (Kummerfeld et al., 2018). As a result,
arXiv:2201.11367v1 [cs.CL] 27 Jan 2022
a challenging task. In fact, such dialogue directly building generation models from such data
data can still contain a wealth of informa- will be inefficient and usually requires "knowledge"
tion and knowledge, however, they are not during the training.
fully explored. In this paper, we show ex-
One common solution is to introduce external
isting open-domain dialogue generation meth-
ods by memorizing context-response paired knowledge, usually, in a form of unstructured
data with causal or encode-decode language knowledge passages from Wikipedia (Dinan et al.,
models underutilize the training data. Differ- 2018) or Internet articles (Komeili et al., 2021),
ent from current approaches, using external and then, to build retrieval-augmented generation
knowledge, we explore a retrieval-generation (RAG) methods to improvement the response qual-
training framework that can increase the us- ity (Lewis et al., 2020; Izacard and Grave, 2020).
age of training data by directly considering the
However, this assumes knowledge-intensive sce-
heterogeneous and noisy training data as the
"evidence". Experiments over publicly avail-
narios, which are not suitable for general open-
able datasets demonstrate that our method can domain tasks or not robust to noise. According to
help models generate better responses, even our preliminary study, in the Reddit dataset, 43%
such training data are usually impressed as of the dialogue are merely chitchat and cannot
low-quality data. Such performance gain is match "knowledge". Moreover, building such a
comparable with those improved by enlarging knowledge-augmented dataset is very expensive
the training set, even better. We also found as it relies on large amounts of high-quality hu-
that the model performance has a positive cor-
man annotations w.r.t. knowledge grounding. And
relation with the relevance of the retrieved evi-
dence. Moreover, our method performed well thus, they are limited in size, making it hard for a
on zero-shot experiments, which indicates that knowledge-retrieval method to generalize on scale.
our method can be more robust to real-world Motivated by above, we would like to investi-
data. gate can we have better ways of utilizing open do-
1 Introduction main data without introducing external resources?
To tackle the aforementioned problem, we found
Open-domain dialogue is a long-standing problem that the context from the other relevant dialogue
in natural language processing and has aroused sessions can still be very useful for dialogue gen-
the widespread interest of researchers. Many ap- eration. To utilise such unstructured context, we
proaches have been studied, and recently, genera- take inspirations from retrieval-augmented meth-
tion models trained on large-scale data have gained ods (Lewis et al., 2020). Differently, we retrieve
more attention (Adiwardana et al., 2020; Roller useful dialogue context as evidence, build context-
et al., 2020; Xu et al., 2021; Madotto et al., 2021; evidence-response triples for each dialogue context,
Bao et al., 2019, 2020; Zhang et al., 2019; Wang and treat open-domain generation as an evidence-
et al., 2020). Open-domain dialogue systems are aware generation task. Such that our model learns
born to deal with many diverse domains, and natu- to respond with grounding on these useful evi-
rally its training data, usually crawled from online dence.
∗
Corresponding Author By this, we show that current training methodswhich learn merely using context-response pairs training dialogue model which is trained on a large-
have not fully unleashed the potential of training scale cleaned Chinese conversation dataset.
data and that our methods, only retrieving from
Retrieval Augmented Generation Retrieval is
the training data, can consistently improve the gen-
a long-considered intermediate step in dialogue
eration performance. We also perform zero-shot
system, and recently, it has been a more inten-
experiments, demonstrating that our method can be
sively studied topic for neural models. Song
robust and generalized to different domains. More-
et al. proposed an ensemble of retrieval-based
over, we found that adding extra retrieval data only
and generation-based conversation system, the re-
(without training them) can still help the model gain
trieved candidates in addition to the original query
performance, and it can even outperform traditional
are fed to a response generator, in which an ex-
methods directly trained on that part of retrieval
tra encoder was used for the retrieved response.
data. This proves our method is compatible with
Pandey et al. combined input context and retrieved
current methods with external knowledge.
responses to create exemplar embeddings which
Our contributions are summarized as follows:
were used in decoder to generate the response.
• we explore a retrieval-generation training frame- Weston et al. took a standard generative model
work that can increase the usage of training data which used a single encoder that takes the con-
by directly considering the heterogeneous and catenation of the original query and the retrieved
noisy training data as the "evidence". response as input. Wu et al. proposed to con-
• We show that adding extra retrieval data while struct an edit vector by explicitly encoding the lexi-
not training them can still gain performance ben- cal differences between input query and retrieved
efits, even better than traditional training with query, then the edit vector and the prototype re-
the retrieval data attached. sponse representation are fed to a decoder to gener-
ate a new response. Cai et al. extracted skeletons
• The proposed method performs well on zero- from the retrieval results, both the skeleton and
shot experiments, which indicates that our the original query were used for response genera-
method can generalize well in real-world ap- tion. Lewis et al. explored a fine-tuning recipe for
plications. retrieval-augmented generation, which combined
pre-trained parametric and non-parametric memory
2 Related Work for language generation. Izacard and Grave pro-
Open-domain Dialogue System Open-domain posed Fusion-in-Decoder method which encoded
dialogue system aims to perform chit-chat with peo- each evidence independently with the context when
ple without the task and domain restriction. It is a generative model processing the retrieved passages.
long-standing problem in natural language process- Most of these works retrieved external knowledge,
ing, recently it has aroused the widespread interest usually unstructured knowledge passages, such as
of researchers. Adiwardana et al. (2020) proposed Wizard of Wikipedia (Dinan et al., 2018), persona-
Meena, a multi-turn open-domain chatbot trained chat (Zhang et al., 2018), and Wizard of Internet
end-to-end on data mined and filtered from pub- (Komeili et al., 2021). Moreover, Li et al. (2020)
lic domain social media conversations. Blender proposed a zero-resource knowledge-grounded di-
(Roller et al., 2020; Xu et al., 2021) learn to pro- alogue model which bridged a context and a re-
vide engaging talking points and listen to their part- sponse as knowledge and expressed it as latent
ners, as well as displaying knowledge, empathy variable.
and personality appropriately, while maintaining
3 Self-retrieval Method
a consistent persona. Adapter-bot (Madotto et al.,
2021) explored prompt-based few-shot learning in We start from an open-domain dialogue dataset
dialogue tasks. Plato (Bao et al., 2019, 2020) intro- D = {(ci , ri )}N
i=1 , where ci denotes multi-turn
duced discrete latent variables to tackle the inherent dialogue context, consisting of dialogue utterances,
one-to-many mapping problem in response gener- and ri represents the response.
ation. Zhang et al. (2019) proposed DialoGPT Generally, we aim to build open-domain di-
which was trained on 147M conversation-like ex- alogue systems that retrieve useful dialogue re-
changes extracted from Reddit comment chains. sponse (as evidences) from other sessions to help
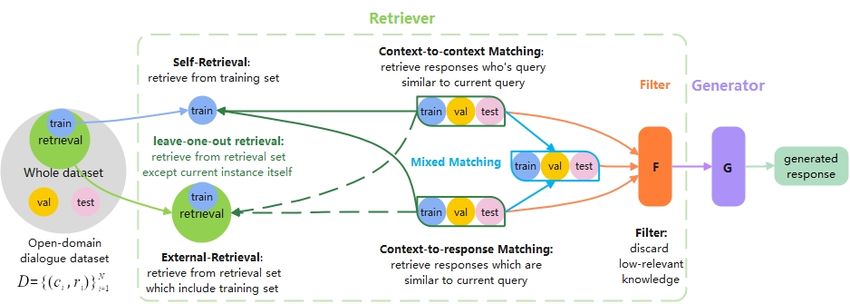
Wang et al. (2020) introduced CDial-GPT, a pre- response generation. To tackle this problem, weFigure 1: Overview of our self-retrieval approach. Our retriever first retrieves useful dialogue instances from the
training dataset, which extends current data to context-evidence-response triples. And then, we adopt evidence-
aware training models over the data with self-retrieval evidences.
proposed a two-step framework. The overview of bacher, 2018; Melucci, 2016). Therefore, we adopt
our approach is shown in Figure 1. the classic retriever BM25 (Robertson et al., 1995),
1. Firstly, we extend an open-domain dialogue which only relies on a few parameters and has been
dataset with a retriever. Given the context of cur- proven to be robust to many different scenarios.1
rent dialogue turn ci , the retriever R(e{·} |ci ) re- Generally, BM25 gives match scores based on
turns top-k relevant evidences as the evidence set bag-of-word features, and the ranking function is
Ei = {e1:k } from a retrieval set. Note that dif- based on term frequency and inverse document
ferent from existing knowledge-grounding meth- frequency. During the retrieval, for each context-
ods, we do not introduce external data for re- response pair (ci , ri ), we define the retrieval set by
triever, and we only consider retrieving evidence applying leave-one-out of the original training set
from the training data at hand. By that, we ex- S = D − {(ci , ri )}, to ensure the model cannot see
tend the dataset into context-evidence-response the true response during generation.
triples D = {(ci , Ei , ri )}N
i=1 . We explore three retrieval strategies: context-to-
2. Secondly, we adopt an evidence-aware gener- context (C 2 C) retrieval, context-to-response (C 2 R)
ation model, which is a conditional language retrieval, and a MIX retrieval.
model to generate the response y given the con- Context-to-context Matching C 2 C matches the
text and the retrieved evidence p(y|c, E). We context ci of current dialogue and the context cj
investigate two widely used architectures, an from the retrieval set S. And the evidence set of ci
auto-regressive GPT, and an encoder-decoder is defined as:
based language model T5.
Next, we introduce how to design an effective EiC 2 C (ci , S) = argmaxK score(ci , cj ) ,
retriever in Section 3.1 and ways of implementing (cj ,rj )∈S
evidence-aware generation on the basis of state-
of-the-art pre-trained generation models in Sec- where argmaxK means selecting top k correspond-
tion 3.2. ing responses r1:k as evidences e1:k with best
matching score given by BM25.
3.1 Retrieve Dialogue Evidence
Context-to-response Matching As the retrieval
A variety of retrieval systems have been studied,
set contains the dialogue response, we also perform
including classic but effective bag-of-words system
a Context-to-response (C 2 R) Matching. It is similar
(Robertson et al., 1995) and up-to-date dense re-
to C 2 C, while C 2 R directly matches the response
triever, such as DPR (Karpukhin et al., 2020) and
in the retrieval set. In C 2 R, BM25 computes the
SparTerm (Bai et al., 2020). In this paper, we aim
matching score based on the response rj of the
with open-domain data and we would like not to
introduce more data or more parameters, which 1
We also did preliminary experiments over BM25 and
might lead to data selection bias in practice (Otter- DPR and they show no significant differences for our findings.retrieval set. input, and then it generates the response. More
precisely, for any instance (ci , Ei , ri ), all retrieved
EiC 2 R (ci , S) = argmaxK score(ci , rj ) . evidences are concatenated before the dialogue
(cj ,rj )∈S
context ci , and the model directly generates the
Mixed Matching We observed that these two response y after ci . We add special token [p]
strategies, C 2 C and C 2 R, often obtain different re- before each retrieved evidence passage, and fol-
sults. Therefore, we complement the two retrieval lowing Wang et al. (2020), we add [speaker1],
sets of C 2 C and C 2 R with each other and combine [speaker2] to each utterance to indicate differ-
them into a MIX retrieval set by re-ranking them ent speakers of muti-turn dialogue.
using BM25 score. Finally, we take their responses Fusion-in-Decoder In our setups, we have mul-
as evidences: tiple evidences for one instance, thus we adopt a
slightly different model than the standard encoder-
EiMIX (ui , S) = argmaxK {EiC 2 C , EiC 2 R } .
decoder T5 (Raffel et al., 2020). We use F I D
(Izacard and Grave, 2020), which was originally
Filter During our preliminary studies, we found
proposed for open-domain question answering. It
that some retrieved evidences are not relevant to the
considers encoding each evidence independently
current query and context. It is arguable that very
with context, so that these evidences will not af-
few relevant evidences can be retrieved for some
fect each other on the encoder side, which is a
dialogue instances, and to study this we perform
better solution to encode multiple evidences. In
analysis in Section 4.5.2 and Section 4.5.3, where
detail, F I D encodes a concatenation of the context
we study different sizes of the retrieval set to ensure
ci with each retrieved evidence ej . And then, it
more relevant evidences can be found. Undoubt-
concatenates all the encoded hidden representation,
edly, these low-relevant evidences are harmful to
and then it is passed to the decoder for generation.
response generation. Therefore, we approach a
Slightly different from the original architecture, we
simple filter to discard evidences with very low
add an additional passage that only encodes the
matching scores.
dialogue context, in case that one dialogue does
3.2 Evidence-aware Dialogue Generation not use any retrieved evidence (discussed in Sec-
tion 4.5.5). Similarly, we add special tokens as we
For generating more appropriate responses, our
did for GPT-2.
generator is a language model but also conditional
on the retrieved evidence set.2
4 Experiments
Y
p(y|ci , Ei ) = p(yt |ci , Ei , yconversation taken directly under the movie 4.3 Implementation and Setup
subreddit (Dodge et al., 2015).5 We discard For retriever, we use Elastic implementation and
instances with long turns or long sentences. In use the default parameter setups.7 As the context
total, the movie dialog dataset has 940k dialogue has a different number of turns, we use the latest
sessions after preprocessing. utterance of dialogue context as BM25 query in
For both datasets, we randomly sample a training practice, which can yield more consistent matching
set of 100k samples, a validation set of 10k sam- scores. Filter is used in all retrieval setups except
ples, and a test set of 10k samples. Data outside the baselines.
the above sets can be considered as the retrieval We performance an in-domain evaluation over
resource. Noted that in our main experiments, the the two datasets. For each dataset, we adopt the pro-
retrieval set (for train/dev/test) is exactly the train- posed three self-retrieval (SR) method, C 2 C, C 2 R,
ing set, where we only retrieve from the training set. and MIX, comparing against the GPT-2 and F I D
And experimental results using a larger retrieval baselines. We experiments with different numbers
set are investigated and reported in Section 4.5.4, of retrieval evidence passages (see Section 4.5.3).
which involves more evidence than the training set. Note that F I D degenerates to a standard T5 model
without any evidences. We retrain our model based
4.2 Metrics on the pretrained checkpoint of GPT-2,8 and T5
To compare the response quality of different mod- checkpoint for F I D.9 We do model selection based
els, we adopt both automatic metrics and human on PPL over the validation set.
evaluations. We additionally perform a zero-shot cross-
domain evaluation for both datasets using F I D.10
Automatic Metrics We deploy four commonly In this setup, we only train our best in-domain F I D
used automatic metrics for the dialogue gen- model on one dataset and then directly test on the
eration, the perplexity (PPL), unigram overlap other, while the retrieval set for inference is the
(F1), BLEU, and distinct 1,2 (Dist-1,2). F1 and training set of the target domain. All other setups
BLEU are commonly used to measure how similar follow the in-domain experiments.
the machine-generated responses is to referenced
4.4 Results
golden response (Miller et al., 2017; Papineni et al.,
2002). Dist-1,2 measure the diversity of the gener- In-domain Table 1 reports the overall in-domain
ated responses (Li et al., 2016). experimental results. Overall, our self-retrieval
methods achieve better performance consistently
Human Evaluations We also perform human across almost all automatic and human evaluation
evaluation over the generated response. Following metrics in terms of generation quality. For gener-
Song et al. (2021), we consider three conventional ation diversities (Dist-1 and Dist-2), our SR can
criteria: fluency (Flue.), informativeness (Info.), still have comparable performance with the strong
and relevance (Relv.). We recruit a team on Ama- baselines. For both GPT-2 and F I D, all three used
zon Mechanical Turk consisting of several profes- matching strategies can improve the overall per-
sional annotators, who are proficient in language formance, and MIX consistently outperforms the
tasks but know nothing about the models.6 We sam- other two. Comparing with GPT-2 and F I D, two
ple 200 instances for each model’s evaluation un- baselines achieve similar performance, while when
der every setting and each sample was evaluated by adding our retrieved evidences, we observed F I D
three people. Each criterion is rated on five scales, based methods performance better, demonstrating
where 1, 3, and 5 indicate unacceptable, moderate, the effectiveness of evidence-aware training of F I D
and perfect performance, respectively. We report in modeling multiple evidence passages. We also
the average Fleiss’s kappa score (Fleiss and Cohen, illustrate the example generated by our approach
1973) on Reddit and Movie Dialogue, 0.47 and baselines in Table 2. Above all, these results
and 0.44 respectively, indicating annotators have demonstrate that our approach could utilise more
reached moderate agreement. 7
https://www.elastic.co/
8
https://huggingface.co/gpt2/tree/main
5 9
https://research.fb.com/downloads/ https://huggingface.co/t5-small/tree/
babi/. main
6 10
https://www.mturk.com/ We ensure there is no overlap between the two datasets.Automatic Metrics Human Evaluation
Reddit PPL↓ F1↑ BLEU↑ Dist-1↑ Dist-2↑ Flue↑ Info↑ Relv↑
GPT-2 BASELINE 31.3 5.3 3.4 65.4 96.7 3.0 2.9 2.8
C2C 29.4 6.1 3.8 69.3 95.6 3.2 3.0 3.1
w. SR C2R 29.7 6.0 3.6 68.4 95.3 3.2 3.1 3.1
MIX 28.1 6.6 4.2 73.5 98.2 3.4 3.3 3.4
T5 BASELINE 25.5 5.2 3.7 95.7 96.3 3.1 3.0 3.1
C2C 25.0 8.0 5.9 91.2 93.8 3.3 3.2 3.3
F I D w. SR C2R 25.2 7.9 5.7 90.4 92.3 3.3 3.2 3.2
MIX 23.8 9.5 6.9 95.3 97.2 3.5 3.4 3.5
Movie PPL F1 BLEU Dist-1 Dist-2 Flue Info Relv
GPT-2 BASELINE 25.6 5.4 3.3 64.3 96.0 3.0 2.9 2.8
C2C 23.5 6.1 3.8 66.9 93.9 3.2 3.1 3.1
w. SR C2R 23.5 6.0 3.7 67.8 92.7 3.2 3.0 3.1
MIX 22.7 6.7 4.2 71.4 96.1 3.4 3.3 3.3
T5 BASELINE 20.5 5.2 3.7 95.2 95.8 3.1 2.9 2.9
C2C 20.1 7.7 5.5 92.3 94.1 3.3 3.2 3.2
F I D w. SR C2R 20.2 7.7 5.4 91.7 93.6 3.3 3.1 3.2
MIX 18.9 9.2 6.6 94.9 96.8 3.6 3.5 3.6
Table 1: Automatic and human evaluation of the in-domain setups over Reddit and Movie Dialog, using 8
evidences passages. GPT-2 and T5 are baselines and “w. SR” (with self-retrieval) indicates our methods. The
best results are in bold.
Speaker1: Why do you get to decide who has something to offer ?
Speaker2: He doesn’t , he is entitled to his opinion , this is the internet and a forum discussion thread .
People post their opinions not the truth .
Baseline Generation: Why have you already voted to make sure you for yourself to support yourself?
Key Evidence 1: I like some of them . However , we are all entitled to our own opinions .
Key Evidence 2: No you’re entitled to your opinion . I’d just prefer an opinion that didn’t contain a logical fallacy .
Our Generation: You are right. People are entitled to their opinion.
Ground Truth: I know , I was taking a round about way of trying to get him to questions his opinion .
Table 2: Examples of responses generated by baselines and our approach based on F I D.
of the dialogue data without introducing more data data compared with the vanilla training methods.
compared with the baselines.
Zero-shot Cross-domain Table 3 reports the re- 4.5 Analysis
sults of zero-shot experiments using F I D. Again,
we find that our methods with evidences achieve 4.5.1 Retrieval Strategies
better performance compared to the baselines with-
out knowledge and MIX performs the best. This Table 1 also shows the experimental results of dif-
result indicates that our approach has good gener- ferent retrieval strategies. We find that MIX perform
alisation and is robust to different datasets. better than context-to-context retrieval (C 2 C) and
Overall, both in-domain and zero-shot results context-to-response retrieval (C 2 R), and the latter
demonstrate our self-retrieval method can improve two methods show no significant difference. We
the performance of open-domain dialogue gener- thought that both C 2 C and C 2 R can retrieve useful
ation, and worth noting that our self-retrieval do evidences while from different aspects. And thus
not use any additional resource. This indicates our mixing them can yield more useful informative and
methods can unleash more potential of the dialogue relevant evidences and better performance as well.Movie Dialogue → Reddit Reddit → Movie Dialogue
PPL F1 BLEU Dist-1 Dist-2 PPL F1 BLEU Dist-1 Dist-2
T5 BASELINE 29.2 5.3 3.9 95.6 96.2 33.0 5.1 3.6 94.5 95.9
C2C 28.0 7.4 5.6 95.6 98.3 30.3 7.4 5.7 94.4 97.2
F I D w. SR C2R 28.2 7.3 5.4 94.8 98.0 30.6 7.3 5.6 93.8 96.6
MIX 26.6 9.0 6.5 96.0 98.6 27.9 8.7 6.5 94.9 97.9
Table 3: Automatic and human evaluation results of zero-shot experiments over Reddit and Movie Dialog
with 8 retrieved evidence passages. The best results are in bold.
Reddit Movie Dialog
PPL F1 BLEU Dist-1 Dist-2 PPL F1 BLEU Dist-1 Dist-2
GPT-2 baseline 31.3 5.3 3.4 65.4 96.7 25.6 5.4 3.3 64.3 96.0
p1 29.8 5.9 3.8 70.5 96.1 23.9 5.8 3.6 67.3 92.1
p2 29.3 6.1 3.9 71.2 96.6 23.6 6.0 3.8 68.6 93.2
SR p4 28.6 6.3 4.0 72.1 97.3 23.1 6.3 4.0 69.8 94.3
p8 28.1 6.6 4.2 73.5 98.2 22.7 6.7 4.2 71.4 96.1
p16 27.9 6.8 4.4 74.0 98.7 22.5 6.8 4.3 71.8 96.4
T5 baseline 25.5 5.2 3.7 95.7 96.3 20.5 5.2 3.7 95.2 95.8
p1 25.4 7.5 5.6 93.7 95.8 20.2 7.2 5.2 94.0 95.9
p2 24.9 8.1 6.0 94.1 96.3 20.0 7.8 5.6 93.8 95.4
F I D w. SR p4 24.3 8.8 6.4 94.6 97.2 19.5 8.4 6.0 94.3 96.1
p8 23.8 9.5 6.9 95.3 97.2 18.9 9.2 6.6 94.9 96.8
p16 23.6 9.7 7.0 95.6 97.8 18.7 9.4 6.8 95.2 97.0
Table 4: Experimental results of different numbers of evidences used for generation using Reddit and Movie
Dialog. p-k indicates the number of evidence passages used for generation. The best results are in bold.
Reddit PPL F1 BLEU ing more retrieved evidences (p16) performs better
GPT-2 BASELINE 31.3 5.3 3.4 than experiments with fewer retrieved evidences
RANDOM 31.4 5.4 3.4 (i.e. p1, p2, p4, p8). While the performance gap
SR w/o FILTER 28.8 6.2 3.9
w. FILTER 28.1 6.8 4.2
is getting smaller when increasing the evidence
numbers. Considering the trade-off between effi-
F I D (T5) BASELINE 25.5 5.2 3.7
RANDOM 25.7 5.2 3.6 ciency and performance, we report results using 8
SR w/o FILTER 24.7 8.3 6.1 evidence as our main results, which is considered
w. FILTER 23.8 9.5 6.9 to be good enough. These results indicate that we
can use more retrieved evidences, which leads to
Table 5: Effectiveness of the filters.
better experimental results and supporting more
information is significant for the generative model.
4.5.2 Effectiveness of Filter
Table 5 show the ablation study of with and without 4.5.4 Self-retrieval vs. Extra Evidences
using filter during the retrieval step on Reddit. We notice that in our experiments we make the
Here the finding is that experiment with filter (w. retrieval set exactly the same as the training set,
FILTER ), has better performance than experiments denoted as the “self-retrieval (SR)” setup. One nat-
without it (w/o FILTER), as well as a setup using ural question is can we use extra data for retrieval
random evidences (RANDOM). These show that set? To further understand this question and to val-
noisy evidences give no assistance, or even harm, idate the usefulness of our method, we carried out
to the model and that the necessity of discarding experiments with different sizes of the training set
low-relevant evidence for dialogue generation in and retrieval set. Specifically, we experiment with
our method. additional setups by enlarging the retrieval sets, i.e.
+200k, +400k, +600k, where “+” means extra data
4.5.3 Number of Retrieved Evidences
for retrieval sets, and we also adopt baselines with
We also carried out experiments with a different different training sizes of 100k, 300k, 500k, 700k
number of retrieved evidences. Table 4 reports (denoted before “+”).11
the experimental results of using k evidences (p-k)
11
for generation. We observe that experiment us- Due to data size limitation, we did not occupy all setups.(a) PPL on GPT-2 (b) F1 on GPT-2 (c) BLEU on GPT-2
(d) PPL on F I D (e) F1 on F I D (f) BLEU on F I D
Figure 2: Results of different sizes of training set and retrieval set on the Movie Dialog with 8 retrieved
evidences. “Self” indicates the training set used for self-retrieval and “+” means adding extra data for retrieval.
(a) max setup over overlaps with bins = {0, · · · , 9, ≥ 10} (b) sum setup over overlaps using bin size = 5
Figure 3: Performance by different overlaps between evidences and ground-truth responses over datasetReddit.
Figure 2 shows the experimental results.12 We sponses, and our method has good generalisation
observe that experiments with larger retrieval sets over the retrieval evidences.
achieve better results than those with small re-
trieval sets across different training sizes. We be- 4.5.5 Relevance of Evidence and
lieve larger retrieval sets can introduce more rel- Ground-truth
evant evidences, which brings performance gain
To further study how our methods make sense, we
for the model. Another interesting finding is
study how the relevance of the retrieved evidences
that adding extra data for retrieval (100+600k,
and ground-truth response can influence the gener-
300+400k, 500+200k) in our methods can outper-
ation performance. For each instance (ci , ri ) which
form the baselines (700k) with extra data added via
used n retrieval evidences EiMIX = {e1 , e2 , ..., en },
direct training. Also, under the same amount of
we compute the number of overlapped words be-
total data (700k), leveraging more data for retrieval
tween the ground-truth ri and each retrieved ev-
(100+600k, 300+400k, 500+200k) has approach-
idence. We study two setups by computing the
ing performance with the self-retrieval with full
overall overlap(E, ri ) using max and sum over
data (self, 700k). It indicates that our methods
the individual overlaps.
can increase the usage of the training data only in
a retrieval way without directly training these re- Figure 3 shows the results of these two setups.
We observed that higher overlap leads to better
12
We also report a detailed results using (100+600k) setup performance. These results indicate that high rel-
in Appendix A.1. evant retrieval evidences can help generate betterresponses and low relevant knowledge are harmful, Aditya Ramesh, Daniel M. Ziegler, Jeff Wu,
which is consistent to the findings in Section 4.5.2. Clemens Winter, Christopher Hesse, Mark Chen,
Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin
Also, there are still some low-relevant left in the
Chess, Jack Clark, Christopher Berner, Sam Mc-
retrieval step. This indicates that open-domain dia- Candlish, Alec Radford, Ilya Sutskever, and Dario
logue generation is still a difficult task, and better Amodei. 2020. Language models are few-shot learn-
retrieval methods are required to further improve ers. ArXiv, abs/2005.14165.
our generation performance. Deng Cai, Yan Wang, Wei Bi, Zhaopeng Tu, Xiaojiang
Liu, Wai Lam, and Shuming Shi. 2019. Skeleton-to-
5 Conclusion response: Dialogue generation guided by retrieval
memory. In Proceedings of the 2019 Conference of
In this paper, we propose a self-retrieval training the North American Chapter of the Association for
framework for open-domain dialogue generation. Computational Linguistics: Human Language Tech-
Different from other knowledge-intensive tasks, nologies, Volume 1 (Long and Short Papers), pages
1219–1228.
our framework only retrieves relevant dialogue in-
stances from the training data (which can be ex- Emily Dinan, Stephen Roller, Kurt Shuster, Angela
tended to a retrieval set) and without the need to Fan, Michael Auli, and Jason Weston. 2018. Wizard
train them in the generation model. It is significant of wikipedia: Knowledge-powered conversational
agents. arXiv preprint arXiv:1811.01241.
that we demonstrate that traditional training base-
lines underuitlise the training data and our method Jesse Dodge, Andreea Gane, Xiang Zhang, Antoine
can utilise more potential of data. We show that Bordes, Sumit Chopra, Alexander Miller, Arthur
Szlam, and Jason Weston. 2015. Evaluating pre-
our method improves the robustness and generality requisite qualities for learning end-to-end dialog sys-
of generative models as well as generate proper tems. arXiv preprint arXiv:1511.06931.
response for complicated human conversation. In
Joseph L Fleiss and Jacob Cohen. 1973. The equiv-
future works, we would like to study better ways
alence of weighted kappa and the intraclass corre-
of evidence retrieval and evidence-aware training lation coefficient as measures of reliability. Educa-
and we believe our approach can benefit to other tional and psychological measurement, 33(3):613–
NLP tasks, such as classification task. 619.
Gautier Izacard and Edouard Grave. 2020. Lever-
aging passage retrieval with generative models for
References open domain question answering. arXiv preprint
Daniel Adiwardana, Minh-Thang Luong, David R So, arXiv:2007.01282.
Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick
Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu, Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and
et al. 2020. Towards a human-like open-domain Wen-tau Yih. 2020. Dense passage retrieval for
chatbot. arXiv preprint arXiv:2001.09977. open-domain question answering. arXiv preprint
arXiv:2004.04906.
Yang Bai, Xiaoguang Li, Gang Wang, Chaoliang
Zhang, Lifeng Shang, Jun Xu, Zhaowei Wang, Fang- Mojtaba Komeili, Kurt Shuster, and Jason Weston.
shan Wang, and Qun Liu. 2020. Sparterm: Learn- 2021. Internet-augmented dialogue generation.
ing term-based sparse representation for fast text re- arXiv preprint arXiv:2107.07566.
trieval. arXiv preprint arXiv:2010.00768.
Jonathan K Kummerfeld, Sai R Gouravajhala, Joseph
Siqi Bao, Huang He, Fan Wang, Hua Wu, and Haifeng Peper, Vignesh Athreya, Chulaka Gunasekara, Jatin
Wang. 2019. Plato: Pre-trained dialogue generation Ganhotra, Siva Sankalp Patel, Lazaros Polymenakos,
model with discrete latent variable. arXiv preprint and Walter S Lasecki. 2018. A large-scale corpus
arXiv:1910.07931. for conversation disentanglement. arXiv preprint
arXiv:1810.11118.
Siqi Bao, Huang He, Fan Wang, Hua Wu, Haifeng
Wang, Wenquan Wu, Zhen Guo, Zhibin Liu, and Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio
Xinchao Xu. 2020. Plato-2: Towards building an Petroni, Vladimir Karpukhin, Naman Goyal, Hein-
open-domain chatbot via curriculum learning. arXiv rich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock-
preprint arXiv:2006.16779. täschel, et al. 2020. Retrieval-augmented generation
for knowledge-intensive nlp tasks. arXiv preprint
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie arXiv:2005.11401.
Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind
Neelakantan, Pranav Shyam, Girish Sastry, Amanda Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao,
Askell, Sandhini Agarwal, Ariel Herbert-Voss, and Bill Dolan. 2016. A diversity-promoting ob-
Gretchen Krueger, T. J. Henighan, Rewon Child, jective function for neural conversation models. InProceedings of the 2016 Conference of the North Haoyu Song, Yan Wang, Kaiyan Zhang, Wei-Nan
American Chapter of the Association for Computa- Zhang, and Ting Liu. 2021. Bob: Bert over
tional Linguistics: Human Language Technologies, bert for training persona-based dialogue models
pages 110–119, San Diego, California. Association from limited personalized data. arXiv preprint
for Computational Linguistics. arXiv:2106.06169.
Linxiao Li, Can Xu, Wei Wu, Yufan Zhao, Xueliang Yiping Song, Cheng-Te Li, Jian-Yun Nie, Ming Zhang,
Zhao, and Chongyang Tao. 2020. Zero-resource Dongyan Zhao, and Rui Yan. 2018. An ensem-
knowledge-grounded dialogue generation. arXiv ble of retrieval-based and generation-based human-
preprint arXiv:2008.12918. computer conversation systems.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob
Andrea Madotto, Zhaojiang Lin, Genta Indra Winata,
Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz
and Pascale Fung. 2021. Few-shot bot: Prompt-
Kaiser, and Illia Polosukhin. 2017. Attention is all
based learning for dialogue systems. arXiv preprint
you need. In Advances in neural information pro-
arXiv:2110.08118.
cessing systems, pages 5998–6008.
Massimo Melucci. 2016. Impact of query sample se- Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong
lection bias on information retrieval system ranking. Jiang, Xiaoyan Zhu, and Minlie Huang. 2020. A
2016 IEEE International Conference on Data Sci- large-scale chinese short-text conversation dataset.
ence and Advanced Analytics (DSAA), pages 341– In NLPCC.
350.
Jason Weston, Emily Dinan, and Alexander Miller.
Alexander H. Miller, Will Feng, Dhruv Batra, Antoine 2018. Retrieve and refine: Improved sequence gen-
Bordes, Adam Fisch, Jiasen Lu, Devi Parikh, and eration models for dialogue. In Proceedings of the
Jason Weston. 2017. Parlai: A dialog research soft- 2018 EMNLP Workshop SCAI: The 2nd Interna-
ware platform. In EMNLP. tional Workshop on Search-Oriented Conversational
AI, pages 87–92.
Jahna Otterbacher. 2018. Addressing social bias in in-
formation retrieval. In CLEF. Yu Wu, Furu Wei, Shaohan Huang, Yunli Wang, Zhou-
jun Li, and Ming Zhou. 2019. Response generation
Gaurav Pandey, Danish Contractor, Vineet Kumar, and by context-aware prototype editing. In Proceedings
Sachindra Joshi. 2018. Exemplar encoder-decoder of the AAAI Conference on Artificial Intelligence,
for neural conversation generation. In Proceedings volume 33, pages 7281–7288.
of the 56th Annual Meeting of the Association for Jing Xu, Arthur Szlam, and Jason Weston. 2021. Be-
Computational Linguistics (Volume 1: Long Papers), yond goldfish memory: Long-term open-domain
pages 1329–1338. conversation. arXiv preprint arXiv:2107.07567.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur
Jing Zhu. 2002. Bleu: a method for automatic eval- Szlam, Douwe Kiela, and Jason Weston. 2018. Per-
uation of machine translation. In ACL. sonalizing dialogue agents: I have a dog, do you
have pets too? arXiv preprint arXiv:1801.07243.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan,
Dario Amodei, Ilya Sutskever, et al. 2019. Lan- Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen,
guage models are unsupervised multitask learners. Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing
OpenAI blog, 1(8):9. Liu, and Bill Dolan. 2019. Dialogpt: Large-scale
generative pre-training for conversational response
Colin Raffel, Noam Shazeer, Adam Roberts, Kather- generation. arXiv preprint arXiv:1911.00536.
ine Lee, Sharan Narang, Michael Matena, Yanqi
Zhou, Wei Li, and Peter J. Liu. 2020. Exploring
the limits of transfer learning with a unified text-to-
text transformer. Journal of Machine Learning Re-
search, 21(140):1–67.
Stephen E Robertson, Steve Walker, Susan Jones,
Micheline M Hancock-Beaulieu, Mike Gatford, et al.
1995. Okapi at trec-3. Nist Special Publication Sp,
109:109.
Stephen Roller, Emily Dinan, Naman Goyal, Da Ju,
Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott,
Kurt Shuster, Eric M Smith, et al. 2020. Recipes
for building an open-domain chatbot. arXiv preprint
arXiv:2004.13637.A Appendix
A.1 Full results of Retrieving Extra data
We present a full results of enlarging the retrieval
set to (100+600k) for both Reddit and Movie
Dialogue, shown in Table 6. The training set is
100k as the same as the self-retrieval setup in main
results.
Reddit PPL↓ F1↑ BLEU↑
GPT-2 BASELINE 31.3 5.3 3.4
C2C 28.0 6.2 3.8
GPT-2 w. DR C2R 28.2 6.0 3.7
MIX 26.9 6.8 4.3
T5 BASELINE 25.5 5.2 3.7
C2C 23.6 9.6 7.2
F I D w. DR C2R 23.8 9.4 7.1
MIX 21.9 12.0 9.0
Movie PPL↓ F1↑ BLEU↑
GPT2 BASELINE 25.6 5.4 3.3
C2C 22.5 6.0 3.7
GPT-2 w. DR C2R 22.6 5.9 3.5
MIX 21.7 7.3 4.7
T5 BASELINE 20.5 5.2 3.7
C2C 19.2 9.1 6.9
F I D w. DR C2R 19.4 9.0 6.7
MIX 17.7 11.5 8.5
Table 6: Automatic evaluations of the in-domain setups
on the Reddit and Movie Dialog datasets with 8
evidences for retrieval. The best results are in bold.You can also read

















































