Overcoming Language Variation in Sentiment Analysis with Social Attention
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
Overcoming Language Variation in Sentiment Analysis with Social Attention
Yi Yang and Jacob Eisenstein
School of Interactive Computing
Georgia Institute of Technology
Atlanta, GA 30308
{yiyang+jacobe}@gatech.edu
Abstract terizing variation in the lexicon (Eisenstein et al.,
2010), orthography (Eisenstein, 2015), and syn-
Variation in language is ubiquitous, particu- tax (Blodgett et al., 2016). However, aside from the
larly in newer forms of writing such as social focused task of spelling normalization (Sproat et al.,
media. Fortunately, variation is not random; it
2001; Aw et al., 2006), there have been few attempts
is often linked to social properties of the au-
thor. In this paper, we show how to exploit to make NLP systems more robust to language vari-
social networks to make sentiment analysis ation across speakers or writers.
more robust to social language variation. The One exception is the work of Hovy (2015), who
key idea is linguistic homophily: the tendency shows that the accuracies of sentiment analysis and
of socially linked individuals to use language
topic classification can be improved by the inclusion
in similar ways. We formalize this idea in a
novel attention-based neural network architec-
of coarse-grained author demographics such as age
ture, in which attention is divided among sev- and gender. However, such demographic informa-
eral basis models, depending on the author’s tion is not directly available in most datasets, and
position in the social network. This has the it is not yet clear whether predicted age and gen-
effect of smoothing the classification function der offer any improvements. On the other end of
across the social network, and makes it pos- the spectrum are attempts to create personalized lan-
sible to induce personalized classifiers even guage technologies, as are often employed in infor-
for authors for whom there is no labeled data
mation retrieval (Shen et al., 2005), recommender
or demographic metadata. This model signif-
icantly improves the accuracies of sentiment systems (Basilico and Hofmann, 2004), and lan-
analysis on Twitter and on review data. guage modeling (Federico, 1996). But personal-
ization requires annotated data for each individual
user—something that may be possible in interactive
1 Introduction settings such as information retrieval, but is not typ-
Words can mean different things to different people. ically feasible in natural language processing.
Fortunately, these differences are rarely idiosyn- We propose a middle ground between group-level
cratic, but are often linked to social factors, such as demographic characteristics and personalization, by
age (Rosenthal and McKeown, 2011), gender (Eck- exploiting social network structure. The sociologi-
ert and McConnell-Ginet, 2003), race (Green, cal theory of homophily asserts that individuals are
2002), geography (Trudgill, 1974), and more inef- usually similar to their friends (McPherson et al.,
fable characteristics such as political and cultural 2001). This property has been demonstrated for lan-
attitudes (Fischer, 1958; Labov, 1963). In natural guage (Bryden et al., 2013) as well as for the demo-
language processing (NLP), social media data has graphic properties targeted by Hovy (2015), which
brought variation to the fore, spurring the develop- are more likely to be shared by friends than by ran-
ment of new computational techniques for charac- dom pairs of individuals (Thelwall, 2009). Social
295
Transactions of the Association for Computational Linguistics, vol. 5, pp. 295–307, 2017. Action Editor: Christopher Potts.
Submission batch: 10/2016; Revision batch: 12/2016; Published 8/2017.
c 2017 Association for Computational Linguistics. Distributed under a CC-BY 4.0 license.Dataset # Positive # Negative # Neutral # Tweet
Train 2013 3,230 1,265 4,109 8,604
Dev 2013 477 273 614 1,364
Test 2013 1,572 601 1,640 3,813
Test 2014 982 202 669 1,853
Test 2015 1,038 365 987 2,390
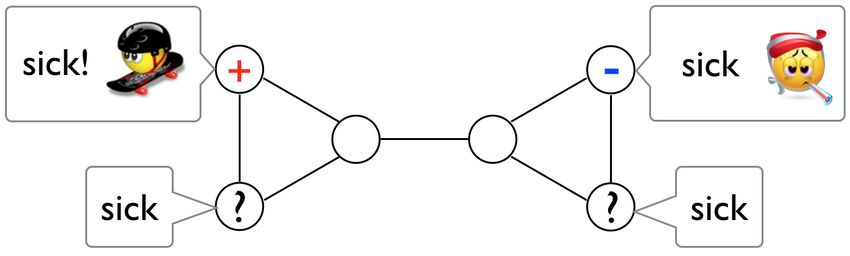
Figure 1: Words such as ‘sick’ can express opposite sen-
timent polarities depending on the author. We account for Table 1: Statistics of the SemEval Twitter sentiment
this variation by generalizing across the social network. datasets.
scale networks (Tang et al., 2015b). Applying the
network information is available in a wide range of
algorithm to Figure 1, the authors within each triad
contexts, from social media (Huberman et al., 2008)
would likely be closer to each other than to authors
to political speech (Thomas et al., 2006) to histori-
in the opposite triad. We then incorporate these
cal texts (Winterer, 2012). Thus, social network ho-
embeddings into an attention-based neural network
mophily has the potential to provide a more general
model, called S OCIAL ATTENTION, which employs
way to account for linguistic variation in NLP.
multiple basis models to focus on different regions
Figure 1 gives a schematic of the motivation for of the social network.
our approach. The word ‘sick’ typically has a nega- We apply S OCIAL ATTENTION to Twitter senti-
tive sentiment, e.g., ‘I would like to believe he’s sick ment classification, gathering social network meta-
rather than just mean and evil.’1 However, in some data for Twitter users in the SemEval Twitter sen-
communities the word can have a positive sentiment, timent analysis tasks (Nakov et al., 2013). We fur-
e.g., the lyric ‘this sick beat’, recently trademarked ther adopt the system to Ciao product reviews (Tang
by the musician Taylor Swift.2 Given labeled ex- et al., 2012), training author embeddings using trust
amples of ‘sick’ in use by individuals in a social relationships between reviewers. S OCIAL ATTEN -
network, we assume that the word will have a simi- TION offers a 2-3% improvement over related neu-
lar sentiment meaning for their near neighbors—an ral and ensemble architectures in which the social
assumption of linguistic homophily that is the ba- information is ablated. It also outperforms all prior
sis for this research. Note that this differs from the published results on the SemEval Twitter test sets.
assumption of label homophily, which entails that
neighbors in the network will hold similar opinions, 2 Data
and will therefore produce similar document-level
labels (Tan et al., 2011; Hu et al., 2013). Linguis- In the SemEval Twitter sentiment analysis tasks, the
tic homophily is a more generalizable claim, which goal is to classify the sentiment of each message
could in principle be applied to any language pro- as positive, negative, or neutral. Following Rosen-
cessing task where author network information is thal et al. (2015), we train and tune our systems
available. on the SemEval Twitter 2013 training and devel-
opment datasets respectively, and evaluate on the
To scale this basic intuition to datasets with tens
2013–2015 SemEval Twitter test sets. Statistics of
of thousands of unique authors, we compress the
these datasets are presented in Table 1. Our train-
social network into vector representations of each
ing and development datasets lack some of the orig-
author node, using an embedding method for large
inal Twitter messages, which may have been deleted
1
Charles Rangel, describing Dick Cheney since the datasets were constructed. However, our
2
In the case of ‘sick’, speakers like Taylor Swift may em- test datasets contain all the tweets used in the Se-
ploy either the positive and negative meanings, while speak- mEval evaluations, making our results comparable
ers like Charles Rangel employ only the negative meaning. In with prior work.
other cases, communities may maintain completely distinct se-
mantics for a word, such as the term ‘pants’ in American and
We construct three author social networks based
British English. Thanks to Christopher Potts for suggesting this on the follow, mention, and retweet relations be-
distinction and this example. tween the 7,438 authors in the training dataset,
296which we refer as F OLLOWER, M ENTION and rewired.7 Each rewiring epoch involves a number of
R ETWEET.3 Specifically, we use the Twitter API to random rewiring operations equal to the total num-
crawl the friends of the SemEval users (individuals ber of edges in the network. (The edges are ran-
that they follow) and the most recent 3,200 tweets domly selected, so a given edge may not be rewired
in their timelines.4 The mention and retweet links in each epoch.) By counting the number of edges
are then extracted from the tweet text and metadata. that occur in both the original and rewired networks,
We treat all social networks as undirected graphs, we observe that this process converges to a steady
where two users are socially connected if there ex- state after three or four epochs. As shown in Fig-
ists at least one social relation between them. ure 2, the original observed network displays more
assortativity than the randomly rewired networks in
3 Linguistic Homophily nearly every case. Thus, the Twitter social networks
display more linguistic homophily than we would
The hypothesis of linguistic homophily is that so- expect due to chance alone.
cially connected individuals tend to use language
similarly, as compared to a randomly selected pair The differences in assortativity across network
of individuals who are not socially connected. We types are small, indicating that none of the networks
now describe a pilot study that provides support for are clearly best. The retweet network was the most
this hypothesis, focusing on the domain of sentiment difficult to rewire, with the greatest proportion of
analysis. The purpose of this study is to test whether shared edges between the original and rewired net-
errors in sentiment analysis are assortative on the works. This may explain why the assortativities of
social networks defined in the previous section: that the randomly rewired networks were closest to the
is, if two individuals (i, j) are connected in the net- observed network in this case.
work, then a classifier error on i suggests that errors
on j are more likely.
4 Model
We test this idea using a simple lexicon-based
classification approach, which we apply to the Se-
mEval training data, focusing only on messages that In this section, we describe a neural network method
are labeled as positive or negative (ignoring the neu- that leverages social network information to improve
tral class), and excluding authors who contributed text classification. Our approach is inspired by en-
more than one message (a tiny minority). Using the semble learning, where the system prediction is the
social media sentiment lexicons defined by Tang et weighted combination of the outputs of several ba-
al. (2014),5 we label a message as positive if it has at sis models. We encourage each basis model to focus
least as many positive words as negative words, and on a local region of the social network, so that clas-
as negative otherwise.6 The assortativity is the frac- sification on socially connected individuals employs
tion of dyads for which the classifier makes two cor- similar model combinations.
rect predictions or two incorrect predictions (New- Given a set of instances {xi } and authors {ai },
man, 2003). This measures whether classification the goal of personalized probabilistic classification
errors are clustered on the network. is to estimate a conditional label distribution p(y |
We compare the observed assortativity against the x, a). For most authors, no labeled data is avail-
able, so it is impossible to estimate this distribution
assortativity in a network that has been randomly
directly. We therefore make a smoothness assump-
3
We could not gather the authorship information of 10% of
tion over a social network G: individuals who are
the tweets in the training data, because the tweets or user ac- socially proximate in G should have similar classi-
counts had been deleted by the time we crawled the social in- fiers. This idea is put into practice by modeling the
formation. conditional label distribution as a mixture over the
4
The Twitter API returns a maximum of 3,200 tweets.
5
The lexicons include words that are assigned at least 0.99
7
confidence by the method of Tang et al. (2014): 1,474 positive Specifically, we use the double edge swap operation
and 1,956 negative words in total. of the networkx package (Hagberg et al., 2008). This opera-
6
Ties go to the positive class because it is more common. tion preserves the degree of each node in the network.
297Figure 2: Assortativity of observed and randomized networks. Each rewiring epoch performs a number of rewiring
operations equal to the total number of edges in the network. The randomly rewired networks almost always display
lower assortativities than the original network, indicating that the accuracy of the lexicon-based sentiment analyzer is
more assortative on the observed social network than one would expect by chance.
predictions of K basis classifiers, any textual information. The attentional weights are
then computed from the embeddings using a soft-
K
X
p(y | x, a) = Pr(Za = k | a, G) × p(y | x, Za = k).
max layer,
k=1
(1) exp φ>
k va + bk
Pr(Za = k | a, G) = PK .
k0 exp φ>
k0 va + bk
0
The basis classifiers p(y | x, Za = k) can be arbi- (2)
trary conditional distributions; we use convolutional This embedding method uses only single-
neural networks, as described in § 4.2. The compo- relational networks; in the evaluation, we will show
nent weighting distribution Pr(Za = k | a, G) is results for Twitter networks built from networks of
conditioned on the social network G, and functions follow, mention, and retweet relations. In future
as an attentional mechanism, described in § 4.1. The work, we may consider combining all of these rela-
basic intuition is that for a pair of authors ai and tion types into a unified multi-relational network. It
aj who are nearby in the social network G, the pre- is possible that embeddings in such a network could
diction rules should behave similarly if the atten- be estimated using techniques borrowed from multi-
tional distributions are similar, p(z | ai , G) ≈ p(z | relational knowledge networks (Bordes et al., 2014;
aj , G). If we have labeled data only for ai , some Wang et al., 2014).
of the personalization from that data will be shared
by aj . The overall classification approach can be 4.2 Sentiment Classification with
viewed as a mixture of experts (Jacobs et al., 1991), Convolutional Neural Networks
leveraging the social network as side information to We next describe the basis models, p(y | x, Z = k).
choose the distribution over experts for each author. Because our target task is classification on microtext
documents, we model this distribution using convo-
4.1 Social Attention Model lutional neural networks (CNNs; Lecun et al., 1989),
The goal of the social attention model is to assign which have been proven to perform well on sentence
similar basis weights to authors who are nearby in classification tasks (Kalchbrenner et al., 2014; Kim,
the social network G. We operationalize social prox- 2014). CNNs apply layers of convolving filters to
imity by embedding each node’s social network po- n-grams, thereby generating a vector of dense lo-
sition into a vector representation. Specifically, we cal features. CNNs improve upon traditional bag-
employ the L INE method (Tang et al., 2015b), which of-words models because of their ability to capture
estimates D(v) dimensional node embeddings va as word ordering information.
parameters in a probabilistic model over edges in Let x = [h1 , h2 , · · · , hn ] be the input sentence,
the social network. These embeddings are learned where hi is the D(w) dimensional word vector cor-
solely from the social network G, without leveraging responding to the i-th word in the sentence. We use
298one convolutional layer and one max pooling layer models are inactive. This can occur because some
to generate the sentence representation of x. The basis models may be initialized with parameters that
convolutional layer involves filters that are applied are globally superior. As a result, the “dead” ba-
to bigrams to produce feature maps. Formally, given sis models will receive near-zero gradient updates,
the bigram word vectors hi , hi+1 , the features gen- and therefore can never improve. The true model
erated by m filters can be computed by capacity can thereby be substantially lower than the
K assigned experts.
ci = tanh(WL hi + WR hi+1 + b), (3) Ideally, dead basis models will be avoided be-
cause each basis model should focus on a unique
where ci is an m dimensional vector, WL and WR
region of the social network. To ensure that this
are m × D(w) projection matrices, and b is the bias
happens, we pretrain the basis models using an in-
vector. The m dimensional vector representation of
stance weighting approach from the domain adapta-
the sentence is given by the pooling operation
tion literature (Jiang and Zhai, 2007). For each basis
s= max ci . (4) model k, each author a has an instance weight αa,k .
i∈1,··· ,n−1 These instance weights are based on the author’s so-
To obtain the conditional label probability, we uti- cial network node embedding, so that socially prox-
lize a multiclass logistic regression model, imate authors will have high weights for the same
basis models. This is ensured by endowing each ba-
exp(βt> sk + βt ) sis model with a random vector γk ∼ N (0, σ 2 I),
Pr(Y = t | x, Z = k) = PT ,
> and setting the instance weights as,
t0 =1 exp(βt0 sk
+ βt0 )
(5)
where βt is an m dimensional weight vector, βt is αa,k = sigmoid(γk> va ). (7)
the corresponding bias term, and sk is the m dimen-
sional sentence representation produced by the k-th The simple design results in similar instance
weights for socially proximate authors. During pre-
basis model. training, we train the k-th basis model by optimizing
4.3 Training the following loss function for every instance:
We fix the pretrained author and word embeddings T
X
during training our social attention model. Let `k = −αa,k 1[Y ∗ = t] log Pr(Y = t | x, Za = k).
t=1
Θ denote the parameters that need to be learned, (8)
which include {WL , WR , b, {βt , βt }Tt=1 } for ev- The pretrained basis models are then assembled to-
ery basis CNN model, and the attentional weights gether and jointly trained using Equation 6.
k=1 . We minimize the following logistic
{φk , bk }K
loss objective for each training instance: 5 Experiments
T
X Our main evaluation focuses on the 2013–2015
`(Θ) = − 1[Y ∗ = t] log Pr(Y = t | x, a), (6) SemEval Twitter sentiment analysis tasks. The
t=1
datasets have been described in § 2. We train and
where Y ∗ is the ground truth class for x, and 1[·] tune our systems on the Train 2013 and Dev 2013
represents an indicator function. We train the mod- datasets respectively, and evaluate on the Test 2013–
els for between 10 and 15 epochs using the Adam 2015 sets. In addition, we evaluate on another
optimizer (Kingma and Ba, 2014), with early stop- dataset based on Ciao product reviews (Tang et al.,
ping on the development set. 2012).
4.4 Initialization 5.1 Social Network Expansion
One potential problem is that after initialization, a We utilize Twitter’s follower, mention, and retweet
small number of basis models may claim most of the social networks to train user embeddings. By query-
mixture weights for all the users, while other basis ing the Twitter API in April 2015, we were able
299Network # Author # Relation ties solely depend on the input values. We adopt
the summation of the pretrained word embeddings
F OLLOWER + 18,281 1,287,260
as the sentence-level input to learn the gating func-
M ENTION + 25,007 1,403,369
tion.9 The model architecture of random attention
R ETWEET + 35,376 2,194,319
is nearly identical to S OCIAL ATTENTION: the only
Table 2: Statistics of the author social networks used for
distinction is that we replace the pretrained author
training author embeddings. embeddings with random embedding vectors, draw-
ing uniformly from the interval (−0.25, 0.25). Con-
catenation concatenates the author embedding with
to identify 15,221 authors for the tweets in the Se- the sentence representation obtained from CNN, and
mEval datasets described above. We induce so- then feeds the new representation to a softmax clas-
cial networks for these individuals by crawling their sifier. Finally, we include S OCIAL ATTENTION, the
friend links and timelines, as described in § 2. Un- attention-based neural network method described
fortunately, these networks are relatively sparse, in § 4.
with a large amount of isolated author nodes. To We also compare against the three top-performing
improve the quality of the author embeddings, we systems in the SemEval 2015 Twitter sentiment
expand the set of author nodes by adding nodes that analysis challenge (Rosenthal et al., 2015): W E -
do the most to densify the author networks: for BIS (Hagen et al., 2015), UNITN (Severyn and Mos-
the follower network, we add additional individu- chitti, 2015), and LSISLIF (Hamdan et al., 2015).
als that are followed by at least a hundred authors UNITN achieves the best average F1 score on Test
in the original set; for the mention and retweet net- 2013–2015 sets among all the submitted systems.
works, we add all users that have been mentioned Finally, we republish results of N LSE (Astudillo et
or retweeted by at least twenty authors in the origi- al., 2015), a non-linear subspace embedding model.
nal set. The statistics of the resulting networks are
presented in Table 2. Parameter tuning We tune all the hyperparam-
eters on the SemEval 2013 development set. We
5.2 Experimental Settings choose the number of bigram filters for the CNN
We employ the pretrained word embeddings used by models from {50, 100, 150}. The size of author
Astudillo et al. (2015), which are trained with a cor- embeddings is selected from {50, 100}. For mix-
pus of 52 million tweets, and have been shown to ture of experts, random attention and S OCIAL AT-
perform very well on this task. The embeddings are TENTION , we compare a range of numbers of ba-
learned using the structured skip-gram model (Ling sis models, {3, 5, 10, 15}. We found that a rela-
et al., 2015), and the embedding dimension is set tively small number of basis models are usually suf-
at 600, following Astudillo et al. (2015). We re- ficient to achieve good performance. The number of
port the same evaluation metric as the SemEval chal- pretraining epochs is selected from {1, 2, 3}. Dur-
lenge: the average F1 score of positive and negative ing joint training, we check the performance on the
classes.8 development set after each epoch to perform early
stopping.
Competitive systems We consider five competi-
tive Twitter sentiment classification methods. Con- 5.3 Results
volutional neural network (CNN) has been de- Table 3 summarizes the main empirical findings,
scribed in § 4.2, and is the basis model of S OCIAL where we report results obtained from author em-
ATTENTION. Mixture of experts employs the same beddings trained on R ETWEET + network for S O -
CNN model as an expert, but the mixture densi- CIAL ATTENTION . The results of different social
8
Regarding the neutral class: systems are penalized with networks for S OCIAL ATTENTION are shown in Ta-
false positives when neutral tweets are incorrectly classified as ble 4. The best hyperparameters are: 100 bigram
positive or negative, and with false negatives when positive or
9
negative tweets are incorrectly classified as neutral. This fol- The summation of the pretrained word embeddings works
lows the evaluation procedure of the SemEval challenge. better than the average of the word embeddings.
300System Test 2013 Test 2014 Test 2015 Average
Our implementations
CNN 69.31 72.73 63.24 68.43
Mixture of experts 68.97 72.07 64.28* 68.44
Random attention 69.48 71.56 64.37* 68.47
Concatenation 69.80 71.96 63.80 68.52
S OCIAL ATTENTION 71.91* 75.07* 66.75* 71.24
Reported results
N LSE 72.09 73.64 65.21 70.31
W EBIS 68.49 70.86 64.84 68.06
UNITN 72.79 73.60 64.59 70.33
LSISLIF 71.34 71.54 64.27 69.05
Table 3: Average F1 score on the SemEval test sets. The best results are in bold. Results are marked with * if they are
significantly better than CNN at p < 0.05.
SemEval Test tion, as it is able to model the interactions between
Network 2013 2014 2015 Average text representations and author representations. It
significantly outperforms CNN on all the SemEval
F OLLOWER + 71.49 74.17 66.00 70.55
test sets, yielding 2.8% improvement on average F1
M ENTION + 71.72 74.14 66.27 70.71
score. S OCIAL ATTENTION also performs substan-
R ETWEET + 71.91 75.07 66.75 71.24
tially better than the top-performing SemEval sys-
Table 4: Comparison of different social networks with
tems and N LSE, especially on the 2014 and 2015
S OCIAL ATTENTION. The best results are in bold. test sets.
We now turn to a comparison of the social net-
works. As shown in Table 4, the R ETWEET + net-
filters; 100-dimensional author embeddings; K = 5 work is the most effective, although the differences
basis models; 1 pre-training epoch. To establish the are small: S OCIAL ATTENTION outperforms prior
statistical significance of the results, we obtain 100 work regardless of which network is selected. Twit-
bootstrap samples for each test set, and compute the ter’s “following” relation is a relatively low-cost
F1 score on each sample for each algorithm. A two- form of social engagement, and it is less public
tail paired t-test is then applied to determine if the F1 than retweeting or mentioning another user. Thus
scores of two algorithms are significantly different, it is unsurprising that the follower network is least
p < 0.05. useful for socially-informed personalization. The
Mixture of experts, random attention, and CNN R ETWEET + network has denser social connections
all achieve similar average F1 scores on the SemEval than M ENTION +, which could lead to better author
Twitter 2013–2015 test sets. Note that random at- embeddings.
tention can benefit from some of the personalized
information encoded in the random author embed- 5.4 Analysis
dings, as Twitter messages posted by the same au- We now investigate whether language variation in
thor share the same attentional weights. However, it sentiment meaning has been captured by different
barely improves the results, because the majority of basis models. We focus on the same sentiment
authors contribute a single message in the SemEval words (Tang et al., 2014) that we used to test lin-
datasets. With the incorporation of author social net- guistic homophily in our analysis. We are inter-
work information, concatenation slightly improves ested to discover sentiment words that are used with
the classification performance. Finally, S OCIAL AT- the opposite sentiment meanings by some authors.
TENTION gives much better results than concatena- To measure the level of model-specificity for each
301Basis model More positive More negative
1 banging loss fever broken fucking dear like god yeah wow
2 chilling cold ill sick suck satisfy trust wealth strong lmao
3 ass damn piss bitch shit talent honestly voting win clever
4 insane bawling fever weird cry lmao super lol haha hahaha
5 ruin silly bad boring dreadful lovatics wish beliebers arianators kendall
Table 5: Top 5 more positive/negative words for the basis models in the SemEval training data. Bolded entries
correspond to words that are often used ironically, by top authors related to basis model 1 and 4. Underlined entries
are swear words, which are sometimes used positively by top users corresponding to basis model 3. Italic entries refer
to celebrities and their fans, which usually appear in negative tweets by top authors for basis model 5.
Word Sentiment Example
Watch ESPN tonight to see me burning @user for a sick goal on the top ten.
sick positive
#realbackyardFIFA
@user bitch u shoulda came with me Saturday sooooo much fun. Met Romeo santos
bitch positive
lmao na i met his look a like
@user well shit! I hope your back for the morning show. I need you on my drive to
shit positive Cupertino on Monday! Have fun!
Dear Spurs, You are out of COC, not in Champions League and come May wont be
dear negative
in top 4. Why do you even exist?
Wow. Tiger fires a 63 but not good enough. Nick Watney shoots a 59 if he birdies the
wow negative
18th?!? #sick
Lol super awkward if its hella foggy at Rim tomorrow and the games suppose to be
lol negative
on tv lol Uhhhh.. Where’s the ball? Lol
Table 6: Tweet examples that contain sentiment words conveying specific sentiment meanings that differ from their
common senses in the SemEval training data. The sentiment labels are adopted from the SemEval annotations.
word w, we compute the difference between the 5.5 Sentiment Analysis of Product Reviews
model-specific probabilities p(y | X = w, Z = k) The labeled datasets for Twitter sentiment analysis
andPthe average probabilities of all basis models are relatively small; to evaluate our method on a
1 K
K k=1 p(y | X = w, Z = k) for positive and neg- larger dataset, we utilize a product review dataset
ative classes. The five words in the negative and pos- by Tang et al. (2012). The dataset consists of
itive lexicons with the highest scores for each model 257,682 reviews written by 10,569 users crawled
are presented in Table 5. from a popular product review sites, Ciao.10 The
rating information in discrete five-star range is avail-
As shown in Table 5, Twitter users correspond- able for the reviews, which is treated as the ground
ing to basis models 1 and 4 often use some words truth label information for the reviews. Moreover,
ironically in their tweets. Basis model 3 tends to the users of this site can mark explicit “trust” rela-
assign positive sentiment polarity to swear words, tionships with each other, creating a social network.
and Twitter users related to basis model 5 seem to To select examples from this dataset, we first re-
be less fond of fans of certain celebrities. Finally, moved reviews that were marked by readers as “not
basis model 2 identifies Twitter users that we have useful.” We treated reviews with more than three
described in the introduction—they often adopt gen- stars as positive, and less than three stars as nega-
eral negative words like ‘ill’, ‘sick’, and ‘suck’ posi- tive; reviews with exactly three stars were removed.
tively. Examples containing some of these words are
shown in Table 6. 10
http://www.ciao.co.uk
302Dataset # Author # Positive # Negative # Review is able to leverage the personalized information to
Train Ciao 8,545 63,047 6,953 70,000
improve sentiment analysis. Prior work has inves-
Dev Ciao 4,087 9,052 948 10,000 tigated the direction, obtaining positive results us-
Test Ciao 5,740 17,978 2,022 20,000 ing speaker adaptation techniques (Al Boni et al.,
Total 9,267 90,077 9,923 100,000 2015). Finally, by exploiting the social network of
trust relations, S OCIAL ATTENTION obtains further
Table 7: Statistics of the Ciao product review datasets. improvements, outperforming random attention by a
small but significant margin.
System Test Ciao
CNN 78.43 6 Related Work
Mixture of experts 78.37
Random attention 79.43* Domain adaptation and personalization Do-
Concatenation 77.99 main adaptation is a classic approach to handling
S OCIAL ATTENTION 80.19** the variation inherent in social media data (Eisen-
stein, 2013). Early approaches to supervised do-
Table 8: Average F1 score on the Ciao test set. The best
main adaptation focused on adapting the classifier
results are in bold. Results are marked with * and ** if
they are significantly better than CNN and random atten-
weights across domains, using enhanced feature
tion respectively, at p < 0.05. spaces (Daumé III, 2007) or Bayesian priors (Chelba
and Acero, 2006; Finkel and Manning, 2009). Re-
cent work focuses on unsupervised domain adap-
We then sampled 100,000 reviews from this set, and tation, which typically works by transforming the
split them randomly into training (70%), develop- input feature space so as to overcome domain dif-
ment (10%) and test sets (20%). The statistics of ferences (Blitzer et al., 2006). However, in many
the resulting datasets are presented in Table 7. We cases, the data has no natural partitioning into do-
utilize 145,828 trust relations between 18,999 Ciao mains. In preliminary work, we constructed social
users to train the author embeddings. We consider network domains by running community detection
the 10,000 most frequent words in the datasets, and algorithms on the author social network (Fortunato,
assign them pretrained word2vec embeddings.11 As 2010). However, these algorithms proved to be un-
shown in Table 7, the datasets have highly skewed stable on the sparse networks obtained from social
class distributions. Thus, we use the average F1 media datasets, and offered minimal performance
score of positive and negative classes as the evalu- improvements. In this paper, we convert social net-
ation metic. work positions into node embeddings, and use an
The evaluation results are presented in Table 8. attentional component to smooth the classification
The best hyperparameters are generally the same as rule across the embedding space.
those for Twitter sentiment analysis, except that the
Personalization has been an active research topic
optimal number of basis models is 10, and the op-
in areas such as speech recognition and information
timal number of pretraining epochs is 2. Mixture
retrieval. Standard techniques for these tasks include
of experts and concatenation obtain slightly worse
linear transformation of model parameters (Legget-
F1 scores than the baseline CNN system, but ran-
ter and Woodland, 1995) and collaborative filter-
dom attention performs significantly better. In con-
ing (Breese et al., 1998). These methods have re-
trast to the SemEval datasets, individual users of-
cently been adapted to personalized sentiment anal-
ten contribute multiple reviews in the Ciao datasets
ysis (Tang et al., 2015a; Al Boni et al., 2015). Su-
(the average number of reviews from an author is
pervised personalization typically requires labeled
10.8; Table 7). As an author tends to express similar
training examples for every individual user. In con-
opinions toward related products, random attention
trast, by leveraging the social network structure, we
11
https://code.google.com/archive/p/ can obtain personalization even when labeled data is
word2vec unavailable for many authors.
303Sentiment analysis with social relations Previ- plex, and in many cases emoticons do not refer to
ous work on incorporating social relations into sen- sentiment (Walther and D’Addario, 2001). Our ap-
timent classification has relied on the label consis- proach does not rely on distant supervision, and as-
tency assumption, where the existence of social con- sumes only that the classification decision function
nections between users is taken as a clue that the should be smooth across the social network.
sentiment polarities of the users’ messages should
be similar. Speriosu et al. (2011) construct a hetero- 7 Conclusion
geneous network with tweets, users, and n-grams as
This paper presents a new method for learning to
nodes. Each node is then associated with a senti-
overcome language variation, leveraging the ten-
ment label distribution, and these label distributions
dency of socially proximate individuals to use lan-
are smoothed by label propagation over the graph.
guage similarly—the phenomenon of linguistic ho-
Similar approaches are explored by Hu et al. (2013),
mophily. By learning basis models that focus on
who employ the graph Laplacian as a source of reg-
different local regions of the social network, our
ularization, and by Tan et al. (2011) who take a fac-
method is able to capture subtle shifts in meaning
tor graph approach. A related idea is to label the
across the network. Inspired by ensemble learn-
sentiment of individuals in a social network towards
ing, we have formulated this model by employing
each other: West et al. (2014) exploit the sociolog-
a social attention mechanism: the final prediction is
ical theory of structural balance to improve the ac-
the weighted combination of the outputs of the ba-
curacy of dyadic sentiment labels in this setting. All
sis models, and each author has a unique weight-
of these efforts are based on the intuition that indi-
ing, depending on their position in the social net-
vidual predictions p(y) should be smooth across the
work. Our model achieves significant improvements
network. In contrast, our work is based on the in-
over standard convolutional networks, and ablation
tuition that social neighbors use language similarly,
analyses show that social network information is the
so they should have a similar conditional distribu-
critical ingredient. In other work, language varia-
tion p(y | x). These intuitions are complementary:
tion has been shown to pose problems for the entire
if both hold for a specific setting, then label consis-
NLP stack, from part-of-speech tagging to informa-
tency and linguistic consistency could in principle
tion extraction. A key question for future research
be combined to improve performance.
is whether we can learn a socially-infused ensemble
Social relations can also be applied to improve
that is useful across multiple tasks.
personalized sentiment analysis (Song et al., 2015;
Wu and Huang, 2015). Song et al. (2015) present 8 Acknowledgments
a latent factor model that alleviates the data sparsity
problem by decomposing the messages into words We thank Duen Horng “Polo” Chau for discus-
that are represented by the weighted sentiment and sions about community detection and Ramon As-
topic units. Social relations are further incorporated tudillo for sharing data and helping us to reproduce
into the model based on the intuition that linked in- the NLSE results. This research was supported by
dividuals share similar interests with respect to the the National Science Foundation under award RI-
latent topics. Wu and Huang (2015) build a person- 1452443, by the National Institutes of Health un-
alized sentiment classifier for each author; socially der award number R01GM112697-01, and by the
connected users are encouraged to have similar user- Air Force Office of Scientific Research. The content
specific classifier components. As discussed above, is solely the responsibility of the authors and does
the main challenge in personalized sentiment analy- not necessarily represent the official views of these
sis is to obtain labeled data for each individual au- sponsors.
thor. Both papers employ distant supervision, using
emoticons to label additional instances. However,
emoticons may be unavailable for some authors or References
even for entire genres, such as reviews. Further- Mohammad Al Boni, Keira Qi Zhou, Hongning Wang,
more, the pragmatic function of emoticons is com- and Matthew S Gerber. 2015. Model adaptation for
304personalized opinion analysis. In Proceedings of the Jacob Eisenstein. 2015. Systematic patterning
Association for Computational Linguistics (ACL). in phonologically-motivated orthographic variation.
Ramon F Astudillo, Silvio Amir, Wang Ling, Mário Journal of Sociolinguistics, 19.
Silva, and Isabel Trancoso. 2015. Learning word rep- Marcello Federico. 1996. Bayesian estimation methods
resentations from scarce and noisy data with embed- for n-gram language model adaptation. In Proceed-
ding sub-spaces. In Proceedings of the Association for ings of International Conference on Spoken Language
Computational Linguistics (ACL). (ICSLP).
AiTi Aw, Min Zhang, Juan Xiao, and Jian Su. 2006. A Jenny R. Finkel and Christopher Manning. 2009. Hier-
phrase-based statistical model for SMS text normaliza- archical bayesian domain adaptation. In Proceedings
tion. In Proceedings of the Association for Computa- of the North American Chapter of the Association for
tional Linguistics (ACL). Computational Linguistics (NAACL).
Justin Basilico and Thomas Hofmann. 2004. Unify- John L Fischer. 1958. Social influences on the choice of
ing collaborative and content-based filtering. In Pro- a linguistic variant. Word, 14.
ceedings of the International Conference on Machine Santo Fortunato. 2010. Community detection in graphs.
Learning (ICML). Physics Reports, 486(3).
John Blitzer, Ryan McDonald, and Fernando Pereira. Lisa J. Green. 2002. African American English: A Lin-
2006. Domain adaptation with structural correspon- guistic Introduction. Cambridge University Press.
dence learning. In Proceedings of Empirical Methods Aric A. Hagberg, Daniel A Schult, and P Swart. 2008.
for Natural Language Processing (EMNLP). Exploring network structure, dynamics, and function
Su Lin Blodgett, Lisa Green, and Brendan O’Connor. using networkx. In Proceedings of the 7th Python in
2016. Demographic dialectal variation in social me- Science Conferences (SciPy).
dia: A case study of african-american english. In Pro- Matthias Hagen, Martin Potthast, Michael Büchner, and
ceedings of Empirical Methods for Natural Language Benno Stein. 2015. Webis: An ensemble for twitter
Processing (EMNLP). sentiment detection. In Proceedings of the 9th Inter-
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, national Workshop on Semantic Evaluation.
Jason Weston, and Oksana Yakhnenko. 2014. Trans- Hussam Hamdan, Patrice Bellot, and Frederic Bechet.
lating embeddings for modeling multi-relational data. 2015. lsislif: Feature extraction and label weighting
In Neural Information Processing Systems (NIPS). for sentiment analysis in twitter. In Proceedings of the
John S Breese, David Heckerman, and Carl Kadie. 1998. 9th International Workshop on Semantic Evaluation.
Empirical analysis of predictive algorithms for collab- Dirk Hovy. 2015. Demographic factors improve classifi-
orative filtering. In Proceedings of Uncertainty in Ar- cation performance. In Proceedings of the Association
tificial Intelligence (UAI). for Computational Linguistics (ACL).
John Bryden, Sebastian Funk, and Vincent Jansen. 2013. Xia Hu, Lei Tang, Jiliang Tang, and Huan Liu. 2013. Ex-
Word usage mirrors community structure in the online ploiting social relations for sentiment analysis in mi-
social network twitter. EPJ Data Science, 2(1). croblogging. In Proceedings of Web Search and Data
Ciprian Chelba and Alex Acero. 2006. Adaptation of Mining (WSDM).
maximum entropy capitalizer: Little data can help a Bernardo Huberman, Daniel M. Romero, and Fang Wu.
lot. Computer Speech & Language, 20(4). 2008. Social networks that matter: Twitter under the
Hal Daumé III. 2007. Frustratingly easy domain adapta- microscope. First Monday, 14(1).
tion. In Proceedings of the Association for Computa- Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and
tional Linguistics (ACL). Geoffrey E Hinton. 1991. Adaptive mixtures of local
Penelope Eckert and Sally McConnell-Ginet. 2003. Lan- experts. Neural computation, 3(1).
guage and Gender. Cambridge University Press. Jing Jiang and ChengXiang Zhai. 2007. Instance weight-
Jacob Eisenstein, Brendan O’Connor, Noah A. Smith, ing for domain adaptation in NLP. In Proceedings of
and Eric P. Xing. 2010. A latent variable model the Association for Computational Linguistics (ACL).
for geographic lexical variation. In Proceedings of Nal Kalchbrenner, Edward Grefenstette, and Phil Blun-
Empirical Methods for Natural Language Processing som. 2014. A convolutional neural network for mod-
(EMNLP). elling sentences. In Proceedings of the Association for
Jacob Eisenstein. 2013. What to do about bad language Computational Linguistics (ACL).
on the internet. In Proceedings of the North American Yoon Kim. 2014. Convolutional neural networks for
Chapter of the Association for Computational Linguis- sentence classification. In Proceedings of Empirical
tics (NAACL). Methods for Natural Language Processing (EMNLP).
305Diederik Kingma and Jimmy Ba. 2014. Adam: A Michael Speriosu, Nikita Sudan, Sid Upadhyay, and Ja-
method for stochastic optimization. arXiv preprint son Baldridge. 2011. Twitter polarity classification
arXiv:1412.6980. with label propagation over lexical links and the fol-
William Labov. 1963. The social motivation of a sound lower graph. In Proceedings of Empirical Methods for
change. Word, 19(3). Natural Language Processing (EMNLP).
Yann LeCun, Bernhard Boser, John S Denker, Donnie R. Sproat, A.W. Black, S. Chen, S. Kumar, M. Osten-
Henderson, Richard E Howard, Wayne Hubbard, and dorf, and C. Richards. 2001. Normalization of non-
Lawrence D Jackel. 1989. Backpropagation applied standard words. Computer Speech & Language, 15(3).
to handwritten zip code recognition. Neural computa- Chenhao Tan, Lillian Lee, Jie Tang, Long Jiang, Ming
tion, 1(4). Zhou, and Ping Li. 2011. User-level sentiment anal-
Christopher J Leggetter and Philip C Woodland. 1995. ysis incorporating social networks. In Proceedings of
Maximum likelihood linear regression for speaker Knowledge Discovery and Data Mining (KDD).
adaptation of continuous density hidden markov mod- Jiliang Tang, Huiji Gao, and Huan Liu. 2012. mtrust:
els. Computer Speech & Language, 9(2). discerning multi-faceted trust in a connected world. In
Wang Ling, Chris Dyer, Alan Black, and Isabel Trancoso. Proceedings of Web Search and Data Mining (WSDM).
2015. Two/too simple adaptations of word2vec for Duyu Tang, Furu Wei, Bing Qin, Ming Zhou, and Ting
syntax problems. In Proceedings of the North Ameri- Liu. 2014. Building large-scale twitter-specific senti-
can Chapter of the Association for Computational Lin- ment lexicon: A representation learning approach. In
guistics (NAACL). Proceedings of the International Conference on Com-
Miller McPherson, Lynn Smith-Lovin, and James M putational Linguistics (COLING).
Cook. 2001. Birds of a feather: Homophily in social Duyu Tang, Bing Qin, and Ting Liu. 2015a. Learning se-
networks. Annual review of sociology. mantic representations of users and products for docu-
Preslav Nakov, Zornitsa Kozareva, Alan Ritter, Sara ment level sentiment classification. In Proceedings of
Rosenthal, Veselin Stoyanov, and Theresa Wilson. the Association for Computational Linguistics (ACL).
2013. Semeval-2013 task 2: Sentiment analysis in Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun
twitter. In Proceedings of the 7th International Work- Yan, and Qiaozhu Mei. 2015b. Line: Large-scale in-
shop on Semantic Evaluation. formation network embedding. In Proceedings of the
Mark EJ Newman. 2003. The structure and function of Conference on World-Wide Web (WWW).
complex networks. SIAM review, 45(2). Mike Thelwall. 2009. Homophily in MySpace. Journal
Sara Rosenthal and Kathleen McKeown. 2011. Age pre- of the American Society for Information Science and
diction in blogs: A study of style, content, and online Technology, 60(2).
behavior in pre- and Post-Social media generations. In Matt Thomas, Bo Pang, and Lillian Lee. 2006. Get
Proceedings of the Association for Computational Lin- out the vote: Determining support or opposition from
guistics (ACL). Congressional floor-debate transcripts. In Proceed-
Sara Rosenthal, Preslav Nakov, Svetlana Kiritchenko, ings of Empirical Methods for Natural Language Pro-
Saif M Mohammad, Alan Ritter, and Veselin Stoy- cessing (EMNLP).
anov. 2015. Semeval-2015 task 10: Sentiment analy- Peter Trudgill. 1974. Linguistic change and diffusion:
sis in twitter. In Proceedings of the 9th International Description and explanation in sociolinguistic dialect
Workshop on Semantic Evaluation. geography. Language in Society, 3(2).
Aliaksei Severyn and Alessandro Moschitti. 2015. Joseph B. Walther and Kyle P. D’Addario. 2001. The
Unitn: Training deep convolutional neural network for impacts of emoticons on message interpretation in
twitter sentiment classification. In Proceedings of the computer-mediated communication. Social Science
9th International Workshop on Semantic Evaluation. Computer Review, 19(3).
Xuehua Shen, Bin Tan, and ChengXiang Zhai. 2005. Im- Zhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng
plicit user modeling for personalized search. In Pro- Chen. 2014. Knowledge graph embedding by trans-
ceedings of the International Conference on Informa- lating on hyperplanes. In Proceedings of the National
tion and Knowledge Management (CIKM). Conference on Artificial Intelligence (AAAI).
Kaisong Song, Shi Feng, Wei Gao, Daling Wang, Ge Yu, Robert West, Hristo Paskov, Jure Leskovec, and Christo-
and Kam-Fai Wong. 2015. Personalized senti- pher Potts. 2014. Exploiting social network structure
ment classification based on latent individuality of mi- for person-to-person sentiment analysis. Transactions
croblog users. In Proceedings of the 24th Interna- of the Association for Computational Linguistics, 2.
tional Joint Conference on Artificial Intelligence (IJ- Caroline Winterer. 2012. Where is America in the Re-
CAI). public of Letters? Modern Intellectual History, 9(03).
306Fangzhao Wu and Yongfeng Huang. 2015. Personal-
ized microblog sentiment classification via multi-task
learning. In Proceedings of the National Conference
on Artificial Intelligence (AAAI).
307308
You can also read

















































