Graph Neural Netwrok with Interaction Pattern for Group Recommendation
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below

Springer Nature 2021 LATEX template
Graph Neural Netwrok with Interaction Pattern for Group
Recommendation
arXiv:2109.11345v1 [cs.IR] 21 Sep 2021
Bojie Wang1* and Yuheng Lu1
1 Schoolof Computer Science (National Pilot Software Engineering School), Beijing
University of Posts and Telecommunications, 10 Xitucheng Road, Haidian District,
Beijing, 100876, Beijing, China.
*Corresponding author(s). E-mail(s): BojieWang@bupt.edu.cn;
Contributing authors: yuheng.lu@bupt.edu.cn;
Abstract
With the development of social platforms, people are more and more inclined to combine into groups
to participate in some activities, so group recommendation has gradually become a problem worthy
of research. For group recommendation, an important issue is how to obtain the characteristic rep-
resentation of the group and the item through personal interaction history, and obtain the group’s
preference for the item. For this problem, we proposed the model GIP4GR (Graph Neural Network
with Interaction Pattern For Group Recommendation). Specifically, our model use the graph neu-
ral network framework with powerful representation capabilities to represent the interaction between
group-user-items in the topological structure of the graph, and at the same time, analyze the interac-
tion pattern of the graph to adjust the feature output of the graph neural network, the feature represen-
tations of groups, and items are obtained to calculate the group’s preference for items. We conducted
a lot of experiments on two real-world datasets to illustrate the superior performance of our model.
Keywords: Group Recommendation; Graph Neural Network; Interaction Pattern; Deep Learning
1 Introduction most recommendation systems are for individ-
ual individuals to recommend, but as people’s
As the speed of information dissemination communication on social platforms becomes more
increases, more and more information begins to convenient, people are more inclined to combine
emerge in front of people. To solve the prob- into groups to participate in activities. From this
lem of the information overload and help people perspective, some studies have investigated recom-
choose information of interest, recommendation mending items to target user groups rather than
systems have been widely deployed in online infor- individual users. This problem is called Group
mation systems, such as e-commerce platforms, Recommendation [1]. This form of users as a group
social media sites, news portals, etc. The rec- is very common in online social media, users can
ommendation system can not only increase the organize into groups to participate in some online
traffic of service providers but also help customers or offline activities.
find items of interest more easily. At present, Figure 1 is a simple example of group interac-
tion and individual interaction. In Figure 1, users
1
Springer Nature 2021 LATEX template
u1 , u2 , u3 , u4 , and u5 interacted with items t1 , individuals in group decision-making, some schol-
t2 , t3 , t6 respectively when they are individuals. ars’ research on group recommendation focuses on
When u1 , u2 , u4 form g1 , they interact with items how to automatically quantify the relative impor-
t4 . u2 , u5 form g2 interacted with item t5 . Our task tance of individuals in group decision-making,
is to predict the items to be interacted by group that is, through the interaction of each member
g3 based on the interaction history of u3 and u4 historical learning then determines the propor-
when u3 and u4 form group g3 . tion of individuals in the final group decision to
make trade-off decisions instead of using empirical
strategies. For example, the attention mechanism
is used to measure the importance of group mem-
bers [3, 4], the interaction history of each different
group member is used to obtain different weights,
and their weighted characteristics are used as the
representation of the final group, thus making up
for the traditional The shortcomings of recom-
mendation strategies highlight the role played by
individuals in group decision-making, and there-
fore exceed the performance of traditional group
recommendation methods. At the same time, some
scholars have proposed that the members of the
group may have mutual influence [5], so a model
Fig. 1 Group-User-Item interaction example
is designed for each member to learn the interac-
tion relationship between him and other members
Traditional recommendation methods are in the group, from his own and the other mem-
divided into model fusion and score fusion [2]. bers of the group. The similarity (or influence)
The score-based fusion only simulates the group’s between others is used to update the individ-
scores for items for each group member’s scores ual’s characteristic representation, and finally, the
(specific methods can be divided into average representations of the members in the group are
scores, maximum scores, and minimum scores). added to obtain the group’s representation. This
This method only considers the group score arbi- method achieves quite good results, but the prob-
trarily. The relationship between the members and lem is similar to the traditional one based on the
the final selection of items without further con- model fusion method is the same, that is, for a
sideration of the influence of the members of the group with a large number of group members, it is
group on the decision. Model-based fusion is to expensive to train the model for each group mem-
train individual and item interaction models for ber interacting with other group members. And
each member of the group recently, and aggre- these current methods are recommended based
gate their preferences, so as to obtain a model on the existing deep neural network methods.
as a group and then perform score prediction. Although deep networks have powerful data fitting
This method can only be learned the abstract capabilities, they ignore the internal topological
relationship between the group model and the structure of the data and cannot learn the deep
individual model cannot measure the participa- layers of the data more effectively. At the same
tion of different members in the final decision time, group interaction data can be better real-
based on the interaction history of different mem- ized by graph representation, so if a graph neural
bers, and the model-based method needs to train network is used, more specific features can be
the model for each group member, and compare learned.
the number of some users, for large datasets, the In reality, many structures can be represented
computational cost will be very large, so tradi- by graphs (such as social networks, protein struc-
tional recommendation methods cannot effectively tures, traffic networks, etc.), and the related tech-
perform recommendations. nologies of graph neural networks have gradually
Recently, for the problem that previous work matured [6]. Therefore, graph neural networks
cannot effectively measure the participation of have already had a wide range of applications.
Springer Nature 2021 LATEX template
3
This also means that the abstract data struc- problem is expressed. Section 4 presents our solu-
ture can be expressed more vividly way, and the tion to this problem. Section 5 introduces some
message passing method is adopted in the fea- details of the experiment and analyzes the results.
ture extraction, that is, a node can aggregate the Finally, Section 6 summarizes the paper and out-
information of the surrounding nodes, so it has a lines the current shortcomings and future research
good effect on information aggregation. Given the directions.
advantages of graph neural network, this article
uses the graph neural networks method to solve 2 Related Works
the problem of group recommendations. Some
works have begun to use graph neural networks to In this section we will introduce the problem
study group recommendations [7], but only use the and the related algorithms to solve the problem.
connectivity of the nodes of the graph to express Specifically, we will focus on current effort on
the order of interaction, and do not go deep into group recommendation and the development of
the graph structure of group interaction. If a graph the graph neural network.
is used to represent the interaction between group
users and items, the structure of the graph may 2.1 Group Recommendation
be different depending on the dataset. For exam-
ple, in some scenarios, when users form a group, Group recommendation requires that the per-
they will choose to revisit the previous place, that sonal preferences of all members in the group be
is, the items selected by the group will be a sub- properlyintegrated, so it requires a part of the
set of the items the user has interacted with. At process than a general personal recommendation.
the same time, it is also possible that when a user Traditional grouprecommendation methods can
forms a group, they will interact with an item that be divided into memory-based and model-based
their group members have not interacted with. methods.
Therefore, in these two cases, the use of different The first is the memory-based method.
layers of graph neural networks will lead to a large O’Connor et al. [1] have proposed some tra-
discrepancy in model performance. ditional methods to aggregate recommendation
In general, the main contributions of this results based on scores, such as maximum satisfac-
article are as follows: tion (the highest score of a member in a group is
selected as the group score for an item, in order to
• This article put forward the concept of inter- maximize group satisfaction), minimum pain (for
active repetition rate(IRR), which distinguishes an item, select the lowest score of a member in
the interactive pattern of different items (such the group as the group score, thereby pleasing all
as movies, tourist attractions, restaurants, etc.), members in the group), average (for an item, select
that is, how much users like to conduct group the average score of the members in the group as
activities when they choose the ones they have the group’s final score, thus weighing the maxi-
interacted with. mum satisfaction and minimum pain) and other
• We propose a new group recommendation methods [8], however, these strategys is too empir-
model GIP4GR based on a graph neural net- ical and too intuitive, ignoring the relationship
work and apply the proposed theory of behavior within the group (for example, different members
patterns to this model to form a universal model have different decision-making processes contribu-
of group behavior. tion). At the same time, each group within each
• We conduct comprehensive experiments on dataset may have different aggregation methods,
two real-world datasets, and demonstrated the that is, some groups tend to be the most satis-
advantages of our model compared with the fied, some tend to be the least painful, and it is
existing model, and verified some key designs of impossible to generalize to use a standard.
the model. The second is model-based methods [9, 10]
The structure of this paper is as follows: mostly using pre-processing methods. Modeling
Section 2 summarizes the research status of group the interaction between individuals and items in
recommendation related work. Section 3 intro- the group, and then fusing these user models to
duces the problem to be solved and the way the obtain a model representing the group, and then
Springer Nature 2021 LATEX template
calculating the score of the interaction between relationship between groups and users can be rep-
the group and the item, so only relatively shallow resented by graphs for more significant learning, to
features are learned. However, groups in real life the characteristics of the group. The application of
change frequently, and the members of the group graph neural network in recommendation system
may also partially overlap, which are only formed includes: Pin-Sage [16]is a kind of spread represen-
for very few activities. Moreover, it is not possible tation on the project graph through the graph con-
to refine the participation of each member in the volutional layer. NGCF [17] models the bipartite
group. graph of user items, so as to learn to aggregate the
At the same time, the probability model is also interactive information of user items. RippleNet
applied to solve the group recommendation. The [18] uses a knowledge graph to aggregate inter-
PIT model [10] proposes to represent the entire active items and richer personal information and
group as the user with the greatest influence in item information. At the same time, GLS-GRL
the group, but ignores the fact that the model will [7] also uses graph neural networks for the prob-
be effective only when the user with the great- lem of sequential group recommendation, that is,
est influence is an expert in this area, otherwise, graph neural networks are used to represent long-
the group internal attention will also shift in this term and short-term user-item interactions, so as
respect, that is, the influential ones will listen to to learn how group interests change over time.
the experienced ones. SR-GNN [6] uses a graph neural network to learn
Recently, in order to measure the percentage the sequence relationship of items interacted in a
of participation of members in the group based on session to generate embedding representation and
the interactions that the group has previously par- obtains the score of each item through attention
ticipated in, a deep representation model based on mechanism and linear transformation.
learning has been proposed [3, 5, 11], all of which It can be seen that the application of graph
use the attention mechanism [12], to measure the neural networks in recommendation system have
weight of different members of the group. It turns been widely used. However, for some datasets with
out that they perform better than models based different behavior patterns, the graph neural net-
on score aggregation or model aggregation. work with a fixed number of layers is easy to show
over-smoothness [19] or under-fitting phenomenon
2.2 Application of graph neural resulting in poor recommendation performance,
network in recommendation that is, GNNs that need to adjust the model
artificially for different datasets. To solve this
system
problem, we dynamically learn the group inter-
Algorithms for extracting graph information are action mode to obtain the interaction repetition
also emerging in endlessly. For example, GCN rate(IRR) of the group to give different impor-
[13] weights and aggregates the information of tance to the output of different layers as the final
surrounding nodes for each node in the graph feature representation.
according to the in-degree and out-degree of the
node; GraphSAGE [14] is to sample the surround- 3 Annoation And Problem
ing nodes of a node and then aggregate and
provide a variety of aggregation methods, such as Formulation
Max-Pooling, LSTM, Mean-Pooling; GAT [15] is
In this section we will formulate the problem
to calculate the information around each node,
we will sovle and the symbol we will use in the
get the weight of each node around, and then
following sections.
obtains the weighted central node information.
Suppose we have N users U ={u1 , u2 ,..., un },
These methods can be effectively applied to the
S groups G={g1 , g2 ,..., gs }, and M items T ={t1 ,
recommendation system. Most of the recommen-
t2 ,. .., tm }. The i-th group gi ∈ G contains
dation system models introduced before are based
members {u1 , u2 ...}. There are three interaction
on general deep neural networks, etc., and do
relationships in the dataset, namely group-user,
not take advantage of the powerful representa-
group-item, and user-item. The entire dataset can
tion capabilities of graph neural networks. The
be seen as an interact graph, where the items,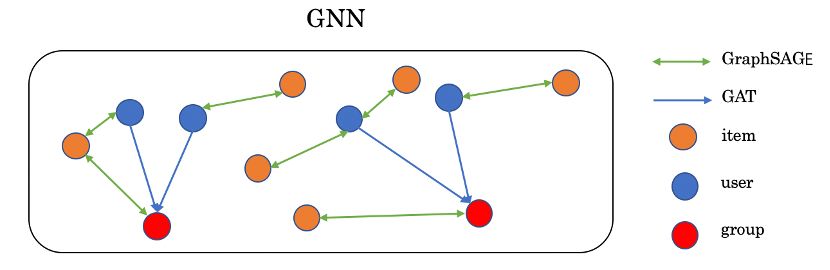
Springer Nature 2021 LATEX template
5
Table 1 Notation
indicators and applying them to subsequent cal-
Notation Description
culation tasks.
In daily life, the scenarios in which we form
G, U, T The set of group, user, item groups and then choose items to interact can be
gi , uj , tk The i-th group, j-th user, k-th item
(x) (x)
divided into the following two types:
gi , uj The x-th item of i-th group and j-th user
As shown by the red circle in Figure 3, in cer-
interacted respectatively
(n) tain scenes (such as traveling) when u1 , u2 , and u3
ez Output embedding of node z(user, group
or item) from n layer of model are organized into group g1 , they choose t4 which
G, V, E input set of graph, nodes, edges they have not experienced before. That is, when
xz Input embedding of node z(user, group people organize into groups, they may get tired of
or item)
what they have experienced before or organize into
type() Type of the entity, collection operation
groups to participate in projects suitable for group
activities. Figure 1 is also the usual situation.
users, groups, can be seen as the nodes of the The situation described by the green circle in
graph and their interaction-ship can be seen as the Figure 3 is just the opposite. When u3 , u4 , and u5
edge of the graph. are organized into a group g2 , they choose the t5
Problem: For a specific group, generate a cor- item that u5 has experienced before, and then the
responding Top@N recommended item list. item t2 that u3 has experienced before does not
Input: user set U, group set G, item set T, work. For example, in a watching movie scenario,
users, items, groups’interact graph. users like spend time and energy to form a team
Output: A list of items generated for group gi , to watch the movie they have watched. This leads
T’ ={t1 , t2 ,...}. to different interaction
patterns for different datasets so that the fixed
number of GNN layers in the model cannot reach
4 Methology a certain value. In order to measure the extent
In this part we will introduce component of the to which the used dataset belongs to which of
model and training details. The overall structure these two situations, we propose an indicator of
of the model is shown in Figure 2. In general, our Interactive Repetition Rate (IRR):
proposed model GIP4GR includes three parts. 1)
Calculating the interactive repetition rate (section S (1) (2) (n) (1) (2) (m)
4.1). The green dashed box (IRR Block) in Figure 1 X type(ti , ti ...ti ) ∩ type(tj , tj ...tj )
IRR = (1) (2) (n)
2 is mainly used to calculate the interactive repeti- S i=0 type(t , t ...t )
i i i
tion rate according to the behavior characteristics , j ∈ gi
of different datasets. 2) Learning interactive infor- (1)
mation (section 4.2) is the blue dashed box (GNN IRR is used to adjust the weight of the out-
Block) in Figure 2, which is the part of applying put of different layers of the network in the final
graph neural network to learn the in-depth infor- output, which solves the problem of the group
mation of the topological structure of the dataset. interaction type and the number of layers of the
3) Get the final representation (section 4.3) in graph neural network.
Figure 2 is a yellow dashed box (Fusion Block),
according to different interaction repetition rates
and interaction information to get the final group,
4.2 Feature Representation Learning
user, and item embedding. Training details are This part corresponds to the blue dotted box
illustrated in section 4.4. block in Figure 2, which uses the current mature
GraphSAGE and GAT to aggregate and learn the
4.1 Calculate the Repetition Rate characteristics of user nodes, project nodes, and
of Group Interaction group nodes.
The partial structure of the GNN is shown
This part corresponds to the green dashed frame in Figure 4. We use the sampling and aggre-
block in Figure 2, mainly for calculating IRR gation framework GraphSAGE to aggregate theSpringer Nature 2021 LATEX template
Fig. 2 Framework of GIP4GR.
Where aggtype in this paper that is the Max-
Pooling method. σ means the sigmoid activation,
W (l) is the learning parameter matrix of the l
layer, Nu represents the one-hop adjoining node of
u, the feature of iteration is that the item t nodes
around the user node u are aggregated in the for-
mula, and the aggregation of item nodes and group
nodes is also the same.
In the group-user interaction, we use a one-
way edge (from the user to the group), and use
the GAT convolution method on this type of edge,
aiming to obtain different attention weights for
users according to different user characteristics.
The formula is as follows:
Fig. 3 As a special case of group interaction, it is
explained here that when users form a group, they can exp(actf (aT [W (l) e(l)
g W
(l) (l)
eu ]))
interact items that have been interacted before or items αgu = P (l)
that have not been interacted. For example, group g1 inter- exp(actf (aT [W (l) e(l)
k∈Ng ,Ng ∈U g W
(l) e ])))
k
acts item t4 that has not been interacted by members of (3)
the group, and group g2 interacts item t5 that has been
interacted by u5 . Among them, actf means the activation func-
tion, here we use the LeakyReLU in GAT, αgu
represents the proportion of member u in group g.
group-item and user-item (bidirectional edges)
We only aggregate the user’s characteristics into
interactions. The formula is as follows:
the group, that is, the user does not aggregate
group information. This is to allow the group to
(l) (l) use the user’s historical interaction information.
e0u = AGGREGAT Eaggtype {et , ∀t ∈ Nu , Nu ∈ T }
Learn the information related to the final deci-
(l) sion of the group. Here we use only one attention
eu (l+1) = σ(W (l+1) [eu (l) , e0u ]) (2) head in GAT (experiments have shown that oneSpringer Nature 2021 LATEX template
7
Fig. 4 IRR block structure.
head can achieve good results and also reduces it is impossible to learn from the interaction of a
computational overhead). single group member to the aggregation.
It is worth noting that these five edge con- If the number of layers selected is too large,
volution methods are all performed at the same it may cause an over-smoothing phenomenon [19],
time, and the nodes that have been repeatedly that is, the information of the group and the item
convolved are added. (For item t5 in Figure 3, the is similar, e.g.: Assuming that the item selected
information of g2 and u5 will be gathered at the by the group is previously interacted by a mem-
same time, and g2 the information of the person ber of the group, then if using two layer GNN will
is added), that is, all nodes are only equivalent to first cause the group to interact the item and the
applying a layer of GNN. group members who have interacted with the item
(as shown in g2 , u5 , and t5 in Figure 3), the group
4.3 Multilayer GNN g2 will be aggregated twice u5 ’s information, twice
t5 ’s information, u5 and t5 are also similar), the
This part corresponds to the Fusion Block in the information has been spread many times, result-
yellow dashed frame in Figure 2 and uses the inter- ing in the three expressions being very similar,
active repetition rate to obtain the weighted sum and secondly, some team members (not enough to
of the network output of different levels as the final contribute to the final decision) may have histor-
feature representation. ical interactions information is learned, resulting
As shown by the red and green circles in Figure in information redundancy, and it is difficult to
3, the datasets of different group interaction rep- assign different weights to group members.
etition rates have different graph diameters, so it Therefore, we propose to use the previously
is very important to choose the number of layers calculated group interaction repetition rate as a
of the graph network. trade-off. We propose to use the two layer GNN
If the number of selected layers is too small, model mentioned before for feature learning (from
the embedded representation ability will be insuf- Figure 3, it can be seen that if the group needs to
ficient, that is, the group representation cannot learn the final feature, the maximum diameter is
fully obtain the necessary information of its sur- item (group selection)-group-member-item (Mem-
rounding nodes, e.g.: Assume that the items ber selection), that is, it takes two hops to get the
selected by the group are not interacted by the group member’s interest information and the item
group members before. If only one layer of the information to be aggregated into the group, so
network is used, the group can only aggregate the the maximum number of layers is set to two), and
information of its members and the information we use the interactive repetition rate to neutralize
of the items selected by the group, but cannot the first and second layers The output of is used as
learn the information of the historical interaction the final representation. That is, if the interactive
items of the group members, which means that repetition rate is relatively large, it means that the
information output by the first layer of the graphSpringer Nature 2021 LATEX template
network is more important (only the information an edge between the target group and the target
of the surrounding nodes of the first hop of the item
node is aggregated), so we use IRR to represent y̌g,v = φ(e(3) (3)
g , ev ) (5)
the interactive repetition rate, then there is: Among them,y̌g,v represents the probability(or the
size of the score) that g and v have edges,
e(3) (3)
g , ev represents the final representation of g
e(3) (1) (2)
z = IRR ∗ ez + (1 − IRR) ∗ ez , z ∈ (U, G, T ) and v respectively, φ represents the prediction
(4) function, it has many forms like dot product,
In this way, the final embedding can dynam- MLP, cosine similarity etc. In our experiment, our
ically adjust the proportion of the output of the prediction function uses the dot product method
first and second layer network in the final output (the more similar the same subspace, the larger
according to the group interaction. the score), so the predicted result is the score
This idea mainly comes from the classic com- between the items recommended for a group.
puter vision algorithm: residual connection [20],
which is used to solve the problem of gradient dis- 4.4.2 Model Optimization
appearance and gradient explosion on the back
layer network. It can also refer to JKnet [21], Regarding group recommendations, we provided
which is a method specifically used to solve the display feedback based on negative samples. Based
problem of excessive smoothing caused by too on this, the score of the observed interaction
many layers in the graph network. JKnet stitches should be higher than the corresponding score of
the output of all layers at the end, Max-Pooling the unobserved for optimization. Our loss function
and LSTM operations to obtain The final rep- is as follows:
resentation, and we are based on the way the
group interacts, and it has to be weighted for X
specific purposes.The specific process of model is arg min {1 − σ(y̌i,k − y̌i,k0 )} (6)
(i,k,k0 )∈Train
Algorithm 1:
Where Train represents the training set, that
Algorithm 1 The Method of GIP4GR is, the group item interaction graph and the (i,
Input:G(V, E), Nodes: ∀Vuser , Vitem , Vgroup ∈ V, k, k’) triplet indicates that the group i has inter-
Nodes’feature: xv , ∀v ∈ V acted with k items but has not interacted with
Initialization; k’ items (we take the items that have not inter-
Step1: Caculate the IRR acted with the group as negative samples ), where
PS type(t(1) (2) (n)
i ,ti ...ti
(1) (2) (m)
)∩type(tj ,tj ...tj ) σ represents the sigmoid function, means the
IRR= S1 i=0 (1) (2) (n) ,j ∈
type(ti ,ti ...ti ) parameters of model. The main purpose of this is
gi
to widen the gap between the scores of the pos-
Step2: Get The representation of nodes from all
itive samples and the negative samples so that
layers of the GNNs
the features between the positive samples and the
e(1)
z = GN N1 (G, xv ); negative samples are prominent.
e(2) (1)
z = GN N2 (G, ez ), (z ∈ V);
Step3: Get the final nodes representation
e(3) (1) (2)
z = IRR ∗ ez + (1 − IRR) ∗ ez , z ∈ (U, G, T )
5 Experiment
In this section, we conducted a lot of comparative
experiments with the current benchmark model on
two real-world datasets and answer the following
4.4 Model Training and research questions:
Optimization • RQ 1: Compare our proposed model with the
existing models, whether the recommendation
4.4.1 GIP4GR Prediction Method
performance is better?
We use the classic problem type in GNN link pre- • RQ 2: Can the experiment prove that includ-
diction [22], which is to judge whether there will be ing the group interaction repetition rate has anSpringer Nature 2021 LATEX template
9
impact on the performance of the model recom- DCG@N
N DCG@N = × 100% (9)
mendation, that is, can it solve the under-fitting IDCG@N
and over-smooth phenomenon when applying Where posn represents the position of the item
graph networks? in the recommended list, and IDCG is an ideal
situation for DCG.
5.1 Experiment Setting In the ”Leave One” evaluation, HR measures
whether the item used for testing is ranked in
5.1.1 Datasets the ”top@N” list (1 means yes, 0 means no), and
NDCG is given by the ranking position of the item
Due to the previously mentioned dataset [7, 8]
in the recommended list score. In order to facili-
may not meet the behavioral characteristics shown
tate comparison with existing work, we uniformly
in Section 3.2, we reused the two real-world
set the the experiment in HR@10, NDCG@10 and
datasets used in [3, 23] datasets CAMRa2011 and
HR@5, NDCG@5.
MaFengWo. The details of the datasets can be
seen in Table 2. It can be seen that the interactive
repetition rate of CAMRa2011 and MaFengWo is 5.1.3 Baselines
exactly at the opposite extremes. In order to show that our model is superior to the
existing models(RQ 1), we compared the current
Table 2 Illustration of Datasets superior models as follow:
Data CAMRa2011 MaFengWo • NCF+AVG [8, 24]: This is a model that
Number of Users 602 5275 aggregates scores. It uses the NCF framework
Number of Groups 290 995
Number of Items 7710 1513
for each group member to learn and predict the
Average Size of Group 2.08 7.19 score of the item and regards the average score
Number of User-Item 116344 3976 of the group member for the item as the group’s
interactions score for the item. At the same time, there are
Number of Group-Item 145068 3595
interactions
also the maximum and minimum scores of group
Interactive Repetition Rate 0.825 0.09 members as the group scores, but the effect is
not as good as the average strategy, so only this
method of aggregation is shown.
• AGREE [3]: The model uses the attention
5.1.2 Evaluation Metrics mechanism, which determines the weight of
each group member’s decision on the item
We adopted the ”leave one” evaluation method,
according to the degree of interaction of each
which has been widely used to evaluate the perfor-
member in the group with the target item.
mance of Top@N recommendations. Specifically,
• GREE:This method is a variant of AGREE. It
for each group, we randomly delete several items
removes the attention mechanism of AGREE.
in the interaction for testing, thereby dividing the
It is assumed that each member has the same
training set and the test set, and the ratio of the
contribution to the group’s decision-making. It
training set to the test set is 10:1.
is different from NCF+AVG in that it calculates
For each group, we randomly select 100 items
the group feature in advance and then calculates
that have not been interacted with before as the
the score of the item for the group feature.
negative sample. In order to evaluate the per-
formance of Top@N recommendations, we have In order to illustrate the effect of group inter-
adopted widely used indicators Hit Rate (HR@N) action repetition rate on recommendation perfor-
and Normalized Discounted Cumulative Gain mance(RQ 2), we set up the following experiment
(NDCG@N). to verify our hypothesis in section 4.3:
Hited • One Layer GNN: Use only One Layer of
HR@N = × 100% (7) the GNN mentioned in section 4.3 to observe
N
N the performance difference between the two
X posn
DCG@N = (8) datasets.
n=1
log2 (n + 1)Springer Nature 2021 LATEX template
• Two Layers GNN: Use a two layesr GNN to
compare the effect of using One Layer on two
datasets.
• Two Layers GNN with Residual Connec-
tion: Compared with the ordinary Two Layers
GNN, this residual layer is to directly add
the output results of the two layers to verify
whether the weighted two-layer network output
will be better after the effect of the interactive
repetition rate.
Fig. 5 Performance of HitRate@10 in the two datasets
5.1.4 Implementation and under different negative sampling ratios.
Hyperparameter Settings
We implement our method on the Pytorch plat-
form and use the DGL library to implement our
GNN model. We use the Adam [25] optimizer to
perform all gradient-based calculations. Based on
experiments, we found that adjusting the learning
rate to 0.05 can achieve the best results. Regard-
ing the size of the data, we found that setting the
Embedding size too large will increase the diffi-
culty of training, that is, it is difficult to achieve
convergence. If it is too small, it will lead to
Fig. 6 Performance of NDCG@10 in the two datasets
insufficient encoding of the necessary information. under different negative sampling ratios.
Therefore, we set the Embedding size to 32, and
in two layers, the ReLU [26] activation function is
the two indicators of the MaFengWo dataset have
used between the GNN. In AGREE, GREE and
started to level off from 10. This is due to the
NCF+AVG, the experimental settings we adopted
problem of data scale. When the amount of data
refer to the best settings in [3]. The hyperparam-
is relatively large and dense, a relatively low
eters in One/Two Layer GNN and Two Layers
negative sampling rate will be required to make
GNN with Residual Connection are consistent
the model tend to fit. In summary, we set the
with our model parameters. We chose the xavier
positive-negative sample ratio to 1:10.
method for the initialization of the network, and
the Embedding of each node uses the initializa-
tion based on the normal distribution. To prevent 5.2 Performance Comparison
errors, we repeat each experiment 5 times, and 5.2.1 Model Performance
the average value of the maximum value of each Comparison(RQ 1)
experiment plus the standard deviation is used as
the final result of the model. Table 3 and Table 4 represent the performance on
Since the dataset does not have explicit nega- the datasets CAMRa2011 and MaFengWo, respec-
tive feedback, 100 items that are not selected in tively. It can be seen that our proposed model
each group are taken as negative samples. Dur- performs much better on HitRate and NDCG than
ing training, we conducted a lot of experiments on the existing models. Among them, NCF+AVG has
these two datasets and found that the positive and the worst effect. (NCF+AVG, AGREE, GREE
negative sample ratio is adjusted between 1:10 and three models based on ordinary neural networks
1:12. The model works best. The specific adjust- have not very different results in these indicators).
ment process is shown in Figure 5 and Figure Our model uses GNN, each embedding of a node
6. It can be seen that the changes in HR@10 gathers more information from surrounding nodes
and NDCG@10 in the CAMRa2011 dataset have and can learn more effectively than ordinary neu-
not changed much since the beginning of 6, while ral networks. Therefore, the results of training theSpringer Nature 2021 LATEX template
11
Table 3 The performance of the deep neural network based model and our model on the CAMRa2011
dataset
CAMRa2011
HR@10 NDCG@10 HR@5 NCDCG@5
NCF+AVG 0.753± 0.072 0.443± 0.052 0.554± 0.032 0.376± 0.044
AGREE 0.787± 0.035 0.456± 0.042 0.572± 0.028 0.384± 0.038
GREE 0.767± 0.030 0.447± 0.038 0.568± 0.029 0.356± 0.032
GIP4GR 0.925± 0.003 0.873± 0.008 0.894± 0.008 0.861± 0.020
Table 4 The performance of the deep neural network based model and our model on the MaFengWo
dataset
MaFengWo
HR@10 NDCG@10 HR@5 NCDCG@5
NCF+AVG 0.614± 0.023 0.398± 0.036 0.484± 0.039 0.323± 0.055
AGREE 0.637± 0.034 0.435± 0.025 0.473± 0.028 0.369± 0.037
GREE 0.615± 0.031 0.414± 0.024 0.442± 0.032 0.348± 0.031
GIP4GR 0.848± 0.010 0.662± 0.004 0.750± 0.013 0.609± 0.023
model also show a lower variance, indicating that of two layers. The price of its universality is its
the performance of the model is also relatively performance. This approach is similar to JKnet,
stable. At the same time, the method based on that is, let the model learn the weights of differ-
the characteristics of group members (AGREE, ent layers of each node. Due to the sparseness of
GREE) is better than relying solely on scores the data, the performance of the model cannot
(NCF+AVG). This shows that the degree of pref- be optimal and the performance is unstable (that
erence for an item of each group member cannot is, the standard deviation is relatively large.) so
reflect the preferences of items when gathered in it is difficult to converge during training, and our
a group. Finally, the model with the Attention proposed model has achieved the best results by
mechanism (AGREE) is better than the average fusing the features between layers according to the
of group member characteristics (GREE), which structure of the dataset.
shows that different group members have differ- It is worth noting that comparing Table 3 and
ent contributions to group decision-making, so it Table 5, Table 4 and Table 6 respectively, it can be
also explains to us the graph’s attention network found that the model performance of GNN based
(GAT) is used when fusing individuals into group on single layer or double layer is better than the
features. model based on deep neural network, which also
shows in the group-user-item interaction graph,
5.2.2 The Effect of IRR on Model there is more structural information that can be
Performance(RQ 2) obtained through GNN, so the use of GNN in
group recommendation is the correct choice.
It can be seen from Table 5 and Table 6 that due Finally, the representation of the trained nodes
to the relatively large IRR on the CAMRa2011 embedding is reduced by T-SNE, and conclusions
dataset, the One Layer GNN has better per- similar to the above results can be obtained intu-
formance than the Two Layers GNN; and the itively. In Figure 7, the blue dots represent items,
MaFengWo dataset is due to the comparison of the the red dots represent users, and the pink dots
IRR is small, so using a Two Layers GNN is bet- represent groups. It can be seen from Figure 7
ter than using a One Layer GNN. But we pursue that due to the impact of the IRR of the dataset,
a more universal model structure, it is impossible the effect of One Layer of GNN and our model
to use different models for different datasets. Sec- GIP4GR are relatively close, and the Two Layers
ondly, the effect of Two Layers+Res is more like a GNN with Residual Connection model is infe-
compromise between the simple use of One Layer rior to them, but the three points are separate,
and Two Layers GNN. It simply adds the outputSpringer Nature 2021 LATEX template
Table 5 Comparison of the performance of the general GNN model and our model on the CAMRa2011
dataset
CAMRa2011
HR@10 NDCG@10 HR@5 NCDCG@5
One Layer GNN 0.920± 0.004 0.860± 0.012 0.892± 0.010 0.837± 0.001
Two Layers GNN 0.867± 0.017 0.612± 0.055 0.739± 0.033 0.582± 0.050
One Layer GNN+Res 0.875± 0.016 0.613± 0.042 0.756± 0.033 0.582± 0.050
GIP4GR 0.925± 0.003 0.873± 0.008 0.894± 0.008 0.861± 0.020
Table 6 Comparison of the performance of the general GNN model and our model on the MafengWo
dataset
MaFengWo
HR@10 NDCG@10 HR@5 NCDCG@5
One Layer GNN 0.741± 0.012 0.543± 0.011 0.631± 0.018 0.508± 0.018
Two Layers GNN 0.836± 0.018 0.638± 0.032 0.732± 0.027 0.594± 0.037
One Layer GNN+Res 0.838± 0.011 0.643± 0.017 0.735± 0.018 0.581± 0.019
GIP4GR 0.848± 0.011 0.662± 0.004 0.750± 0.013 0.609± 0.023
Fig. 7 CAMRa2011 dataset’s dimensionality reduction Fig. 8 MaFengWo dataset’s dimensionality reduction
visualization. visualization.
you can’t make the difference significant. The
Meanwhile, in the MaFengWo dataset, it can
Two Layers GNN have the worst effect, which is
be seen intuitively from Figure 8 that due to the
reflected in the fact that the embedding of the
relatively small IRR, the effect of using a One
group and the embedding of the item are dif-
Layer GNN is the worst. Secondly, the effects of
ficult to separate, which is consistent with our
the Two layers GNN and our model GIP4GR are
experimental data.
relatively close, and the effect of the Two Layers
GNN with Residual Connection is inferior to the
two, which is consistent with our hypothesis.
6 Conclusion
In this work, we proposed a GNN method to solve
the problem of group recommendation and pro-
posed a new model GIP4GR. First, we put forwardSpringer Nature 2021 LATEX template
13
the concept of group interaction repetition rate for [5] Vinh Tran, L. et al. Interact and decide:
the problem of group recommendation. Secondly, Medley of sub-attention networks for effective
we proposed the use of GNN to learn on the group group recommendation, 255–264 (2019).
recommendation dataset, that is, on each layer of
the network, GAT is used to learn the contribu- [6] Xu, C. et al. Graph contextualized self-
tion of each member in the group decision-making, attention network for session-based recom-
and GraphSAGE is used to aggregate the group mendation., Vol. 19, 3940–3946 (2019).
and the item, the user’s representation. Finally,
the group IRR is applied to a GNN-based frame- [7] Wang, W. et al. Group-aware long-and
work, and the characteristics of the dataset itself short-term graph representation learning for
are used to weighting the first layer and second sequential group recommendation, 1449–1458
layer GNN for better performance. And a large (2020).
number of experiments have been conducted on
[8] Baltrunas, L., Makcinskas, T. & Ricci, F.
two real-world datasets and compared with the
Group recommendations with rank aggre-
best existing methods, our model has achieved
gation and collaborative filtering, 119–126
the best results. The current shortcoming of this
(2010).
work is that it does not consider the interaction
between members of the group, that is, the mem- [9] Agarwal, D. & Chen, B.-C. flda: matrix fac-
bers are only regarded as the attribute nodes of torization through latent dirichlet allocation,
the group, and the interactive connections of the 91–100 (2010).
group members are not counted as part of the
graph. Subsequent work may consider connecting [10] Chin, J. Y., Zhao, K., Joty, S. & Cong, G.
the member nodes in the group, separately consid- Anr: Aspect-based neural recommender, 147–
ering the message passing between users when the 156 (2018).
entire interaction graph is used for message pass-
ing, and reflecting this influence on the weight of [11] Wu, S. et al. Session-based recommendation
the group are two important issues. with graph neural networks, Vol. 33, 346–353
(2019).
7 Declarations [12] Bahdanau, D., Cho, K. & Bengio, Y. Neu-
Conflict of interest The authors declare that ral machine translation by jointly learn-
they have no conflict of interest. ing to align and translate. arXiv preprint
arXiv:1409.0473 (2014) .
References [13] Kipf, T. N. & Welling, M. Semi-supervised
classification with graph convolutional net-
[1] O’connor, M., Cosley, D., Konstan, J. A. &
works. arXiv preprint arXiv:1609.02907
Riedl, J. Polylens: A recommender system for
(2016) .
groups of users, 199–218 (Springer, 2001).
[14] Hamilton, W. L., Ying, R. & Leskovec, J.
[2] Berkovsky, S. & Freyne, J. Group-based recipe
Inductive representation learning on large
recommendations: analysis of data aggrega-
graphs, 1025–1035 (2017).
tion strategies, 111–118 (2010).
[15] Veličković, P. et al. Graph attention net-
[3] Cao, D. et al. Attentive group recommenda-
works. arXiv preprint arXiv:1710.10903
tion, 645–654 (2018).
(2017) .
[4] Wang, P., Li, L., Wang, R., Xu, G. & Zhang,
[16] Ying, R. et al. Graph convolutional neural
J. Socially-driven multi-interaction attentive
networks for web-scale recommender systems,
group representation learning for group rec-
974–983 (2018).
ommendation. Pattern Recognition Letters
145, 74–80 (2021) .Springer Nature 2021 LATEX template
[17] Wang, X., He, X., Wang, M., Feng, F. &
Chua, T.-S. Neural graph collaborative filter-
ing, 165–174 (2019).
[18] Wang, H. et al. Ripplenet: Propagating user
preferences on the knowledge graph for rec-
ommender systems, 417–426 (2018).
[19] Li, Q., Han, Z. & Wu, X.-M. Deeper insights
into graph convolutional networks for semi-
supervised learning (2018).
[20] He, K., Zhang, X., Ren, S. & Sun, J. Deep
residual learning for image recognition, 770–
778 (2016).
[21] Xu, K. et al. Representation learning on
graphs with jumping knowledge networks,
5453–5462 (PMLR, 2018).
[22] Zhang, M. & Chen, Y. Weisfeiler-lehman
neural machine for link prediction, 575–583
(2017).
[23] Cao, D. et al. Social-enhanced attentive
group recommendation. IEEE Transactions
on Knowledge and Data Engineering (2019) .
[24] He, X. et al. Neural collaborative filtering,
173–182 (2017).
[25] Kingma, D. P. & Ba, J. Adam: A method
for stochastic optimization. arXiv preprint
arXiv:1412.6980 (2014) .
[26] Glorot, X., Bordes, A. & Bengio, Y. Deep
sparse rectifier neural networks, 315–323
(JMLR Workshop and Conference Proceed-
ings, 2011).You can also read

















































