External Knowledge enabled Text Visual Question Answering
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
External Knowledge enabled Text Visual Question Answering
Arka Ujjal Deya , Ernest Valvenyb , Gaurav Harita
a IIT Jodhpur, Rajasthan, India
b Computer Vision Center, Universitat Autònoma de Barcelona, Bellaterra (Barcelona)
arXiv:2108.09717v5 [cs.CV] 20 Oct 2021
Abstract
The open-ended question answering task of Text-VQA requires reading and reasoning about local, often previously
unseen, scene-text content of an image to generate answers. In this work, we propose the generalized use of external
knowledge to augment our understanding of the said scene-text. We design a framework to extract, validate, and reason
with knowledge using a standard multimodal transformer for vision language understanding tasks. Through empirical
evidence and qualitative results, we demonstrate how external knowledge can highlight instance-only cues and thus
help deal with training data bias, improve answer entity type correctness, and detect multiword named entities. We
generate results comparable to the state-of-the-art on two publicly available datasets, under the constraints of similar
upstream OCR systems and training data.
Keywords: Scene Text, Visual Semantics, Language and Vision, External Knowledge
1. Introduction
The Visual Question Answering (VQA) problem (An-
tol et al., 2015) has seen considerable attention in the past
years. The appeal lies in the challenge itself, of trying to
answer open-ended questions about an image and the pos-
sible applications it may have in automated image under-
standing. VQA entails working with multiple data modal-
ities, viz, visual objects and question words, and model
their interaction to generate an answer.
However, despite significant progress (Goyal et al.,
2018) the generic VQA setup addressed in most of the
state-of-the-art frameworks (Kim et al., 2018; Anderson
et al., 2018) was still ignoring an important information
source: scene text. Since the advent of the printing press,
the text has made inroads in our life, and thus also in our
images (Dey et al., 2021). Scene text is ubiquitous in our
everyday images, from street or store names (Karaoglu
et al., 2017) to advertisements (Hussain et al., 2017)
or brand logos. Thus, the definition of the Text-VQA
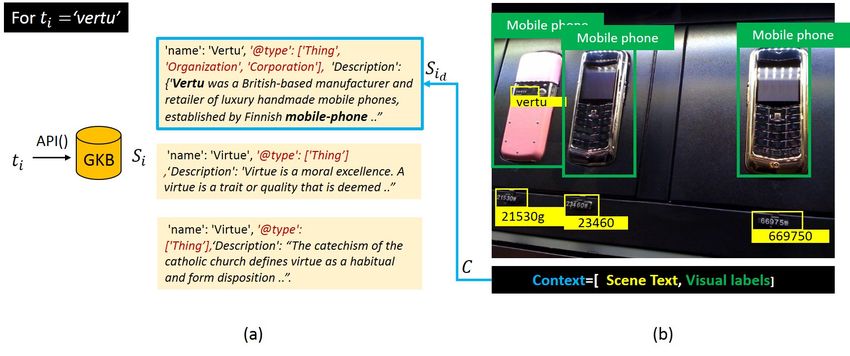
task (Singh et al., 2019a; Biten et al., 2019) generalizes Figure 1: Core Idea: Use detected visual and scene text objects, along
VQA and requires to consider not just visual objects but with external knowledge, to answer questions about an image.
also the scene text content to generate an answer.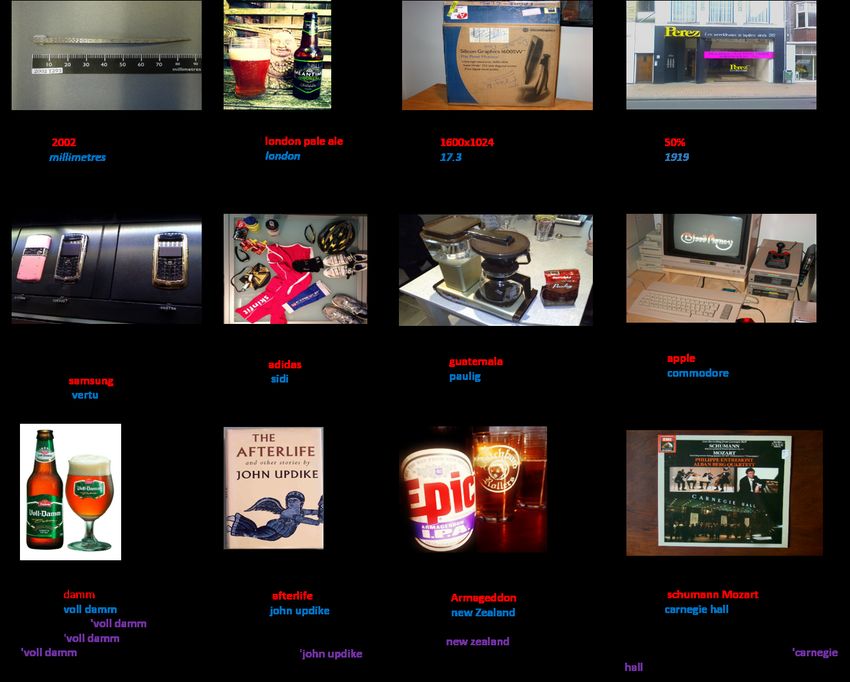
While the VQA task has its set of challenges (Kafle and swer.
Kanan, 2017b), viz. answer vocabulary, upstream detec- Thus, in this work, we propose a framework to extract,
tors, long-tailed answer distribution, language bias (Goyal validate, and reason with external knowledge in language
et al., 2018), evaluation metrics (Kafle and Kanan, 2017a), vision understanding. In summary, our primary contribu-
Text-VQA makes the VQA problem setup more generic tions are:
and introduces new challenges requiring better reading
and reasoning abilities. This was seen in (Singh et al., • We present a method to extract external knowledge
2019a; Biten et al., 2019) when the state-of-the-art fixed corresponding to scene text content in images and
vocabulary VQA models performed poorly on the inher- then validate the mined knowledge facts through im-
ently open-ended Text-VQA task. In the case of VQA, age context. This validation stage helps us deal with
fixed vocabulary-based systems (Anderson et al., 2018) the noisy nature of web scraped data.
have done reasonably well. Using answer statistics on a • We propose an end-to-end trainable architecture that
large dataset can help us find a fixed set of words cover- enables us to reason with external knowledge. Our
ing all or most of the answers. For Text-VQA, however, proposed External Knowledge enabled Text-VQA
such a fixed vocabulary of answers is not enough, as the (KTVQA) framework integrates knowledge chan-
task is set up to require reading scene text in the current nel with a standard transformer-based architecture
image. Thus a hybrid answer space, unique to each im- for the Text-VQA task. Through masked attention
age, consisting of a fixed global vocabulary of frequent maps, we control the interaction between the image
answers, together with the dynamic local set of current components and the knowledge facts. To the best of
scene text tokens, is used in practice. The open-ended na- our knowledge, we are the first to propose the gener-
ture of Text-VQA also makes it more susceptible to errors alized use of External Knowledge to the Text-VQA
due to training data bias when it fails to notice an instance task.
only cue and instead incorrectly focuses more on trained
statistics. E.g., in Figure 1, the standard Text-VQA mod- • We apply the proposed framework on standard Text-
els predict the answer to be ‘samsung’ because of the mo- VQA datasets, demonstrating the effectiveness of
bile phone-related visual content of the image. It is only external knowledge in improving results. We gen-
with external knowledge that we bring awareness about erate results that match the state-of-the-art mod-
hitherto unseen text ‘vertu’ as a mobile phone company els without using additional annotated data or pre-
which finally leads to the correct answer. We demonstrate training tasks. Our knowledge-related components
more such errors in Figure 6, row 2. While one can miti- can be readily adopted into the existing state-of-the-
gate such dataset biases by additional training on large an- art models leading to further improved results.
notated datasets, we argue for the use of External Knowl-
edge 1 . While the use of knowledge has been proposed in We describe our organization here. In Sec. 2 we present
the past, it is mostly set up as a retrieval problem (Shah the conventional approaches to Text-VQA and relate it
et al., 2019; Narasimhan and Schwing, 2018; Wang et al., to existing knowledge based systems. We follow this up
2018), where the answer is retrieved as the most relevant with our proposed method in Sec. 3 incorporating exter-
knowledge fact. We propose an end-to-end pipeline of nal knowledge into the Text-VQA task. In Sec. 4 we re-
extracting, validating, and reasoning with mined external port our experimental results and draw our insights, and
knowledge to generate answers freely from the hybrid an- finally, in Sec. 5 we present our concluding remarks.
swer space. This requires no additional training and is
thus a more resource-efficient solution. In Figure 1 we 2. Related Works
present our core idea, which is to use external knowledge
along with visual and scene text cues to generate an an- In this section, we first describe the Text-VQA prob-
lem and the conventional solutions thus far applied to it.
We then discuss Knowledge enabled systems, in particu-
1 https://developers.google.com/knowledge-graph
lar how knowledge has been applied to Vision Language
2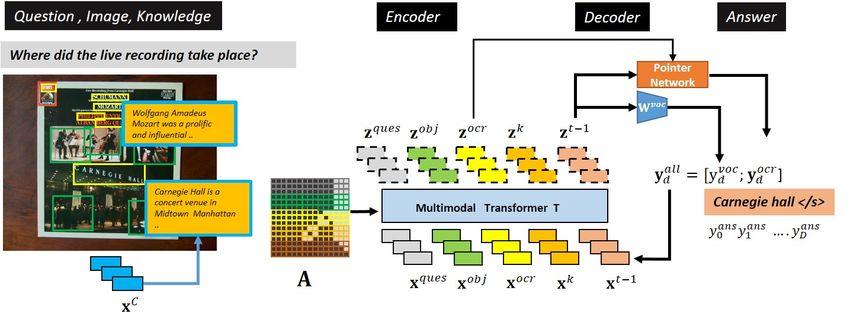
tasks, and conclude with how we relate these approaches they design a pre-training task called Relative (spatial)
to the Text-VQA problem. Position Prediction (RPP). While we note the potential
of pre-training tasks, we see it as a complementary ap-
2.1. Conventional methods on Text-VQA task proach to our work, where we propose the use of external
The Text-VQA task has received widespread attention knowledge to deal with training bias leading to better gen-
in the recent past, both in the number of datasets (Biten eralization.
et al., 2019; Singh et al., 2019a; Mishra et al., 2019) and
network architectures proposed (Hu et al., 2020; Kant 2.2. Knowledge applied to Vision Language Under-
et al., 2020; Gao et al., 2020). The initial baselines pro- standing Tasks
posed were based on augmenting existing VQA architec- Before we begin our discussion on related works in-
tures with OCR inputs (Biten et al., 2019; Singh et al., volving knowledge, we briefly define the knowledge tax-
2019a; Mishra et al., 2019). However, Text-VQA is multi- onomy we use. We differentiate between valid and rel-
modal by definition, and unlike traditional VQA with only evant knowledge facts based on the image and question
the visual stream, Text-VQA requires us to detect and en- context, respectively. We feel this distinction to be neces-
code multiple views of the image, viz. scene text and vi- sary to highlight the gap areas in the related work.
sual. Leveraging the attentional framework of the recently Valid Knowledge is the type of knowledge that is correct
introduced transformer framework and cognizant of this or true for the given image, but it need not be relevant
multimodal nature of the data, the Multimodal MultiCopy to the current task of question-answering. We propose
Mesh (M4C) (Hu et al., 2020) model was proposed. checking for knowledge validity as an important sub-task
The multimodal transformer based M4C jointly en- for any system that uses noisy web scraped data as exter-
codes the question, the image, and the scene text and nal knowledge.
employs an iterative decoding mechanism that supports Relevant Knowledge on the other hand, is not just valid
multi-step answer decoding. The performance improve- for the image but also relevant to the current task of
ments attributed to M4C led to multiple variants of this question-answering. While validity is specific to the im-
multimodal transformer-based architecture in subsequent age itself, relevance is both image and task-specific. Thus
works. While SA-M4C (Kant et al., 2020) proposes for a knowledge fact to be deemed relevant, it must also
encoding spatial relationships between detected objects be checked for validity.
through additional spatial layers atop M4C, LaAP-Net
(Han et al., 2020) proposes an evidence-based Multi- Knowledge enabled Datasets. While the use of knowl-
modal transformer model where, first, the answer bound- edge in question answering tasks has been seen in the
ing box is generated, which is subsequently embedded past, they are mostly proposed together with a Knowl-
and used as part of the final answer word decoding. While edge enabled dataset (Shah et al., 2019; Singh et al.,
M4C considers text and visual objects alike and relies 2019b; Mishra et al., 2019; Narasimhan and Schwing,
entirely on the internal transformer attentional frame- 2018; Wang et al., 2018), where the knowledge facts
work, SMA (Gao et al., 2020) has shown that more are part of the annotations provided. In these examples,
structured attention, aware of the inter-object relation- the image and the corresponding ground truth knowledge
ship, can lead to improved results. Recently in TAP facts are related by design, and thus they sidestep the
(Yang et al., 2021), the authors explore the role of Vi- issue of knowledge correctness or validity with respect
sion Language pre-training (VLP) (Devlin et al., 2019; to the image. In KVQA (Shah et al., 2019), for exam-
Lu et al., 2019; Chen et al., 2020) tasks, such as Image- ple, the dataset is built using image search against a list
Text(contrastive) Matching (ITM) and Masked Language of persons; thus, every visual cue or person in the im-
Modeling (MLM) in learning a better aligned multi- age is mapped explicitly to a knowledge cue related to
modal representation for the Text-VQA task. They also that person. Similarly, we see in (Singh et al., 2019b)
take into account the significant amount of spatial ref- a large-scale knowledge enabled dataset, comprising im-
erences in the dataset. However, instead of using it as ages of popular businesses/ brands, book covers, and film
ground truth information to reason with, like SA-M4C, posters images with the names of the brands, movies, or
3
books acting as anchor entities in the external knowledge tend to each other to generate the final image embedding.
base. Thus, for these Knowledge enabled datasets, the ac- It is important to note that none of the above two works
companying knowledge is always valid by design. Such ensure knowledge validity. This is despite the fact that
Knowledge facts provide extra supervision and forgo the DBpedia offers multiple candidate meanings for a given
need for checking for knowledge validity. Given a set of scene text query. Thus by skipping the validity checks,
valid knowledge facts, most methods (Narasimhan and both these methods allow room for spurious knowledge
Schwing, 2018; Wang et al., 2018; Narasimhan et al., facts, which can be incorrectly deemed as question rele-
2018) use contextual relevance, with the question and im- vant by virtue of semantics.
age, to select a subset of relevant knowledge facts.
Using Knowledge to Generate Answers. For knowl-
Mined External Knowledge applied to Vision Lan- edge fact-based VQA system (Narasimhan and Schwing,
guage Tasks. Closest to our work is (Wu et al., 2016), 2018; Wang et al., 2018), where the answer is from
where they propose the use of mined external knowl- a closed set of image-specific retrieved knowledge
edge to the existing VQA (Antol et al., 2015) task. They facts, answering a question translates to searching from
use text attributes predicted from an image to query the amongst a set of relevant knowledge facts. The answers in
DBpedia2 knowledge base. The questions in Text-VQA Text-VQA are, however, more generic. The answer space
are primarily focused on reading and reasoning about the extends beyond the detected OCR tokens and requires
scene text objects. Thus, instead of externally gener- generic English words, names, and numbers as shown in
ated captions or text attributes, which capture the visual (Singh et al., 2019a). This is validated by our observa-
objects’ view, we exclusively use the scene text objects tions in Table 4 where we note that only about 53.4% of
as our knowledge queries. Further, Wu et al. (2016) do the questions from the validation set could be answered
not check for explicit relevance of the individual knowl- with our Google-OCR-based OCR tokens alone. To ac-
edge facts obtained, instead aggregate them into a single count for this, (Singh et al., 2019a) proposed that the
noisy knowledge vector, encoded through Doc2vec (Le answer space be augmented with a fixed vocabulary of
and Mikolov, 2014), before feeding them to an LSTM common answers words, which, together with the OCR
pipeline for answer generation. Instead of a single aggre- tokens, can answer 84.4% of the questions. This diverse
gated knowledge representation for the entire image, we answer space of Text-VQA implies that answering should
leverage individual OCR token-specific knowledge. This not be restricted to searching amongst retrieved knowl-
enables us to discriminate amongst OCR tokens for an- edge facts alone.
swer generation based on their knowledge relevance. Thus, instead of selecting a retrieved knowledge fact
In (Ye et al., 2021) we find an example of scene text- as the answer, we propose reasoning with the retrieved
based mined external knowledge but applied to the image- knowledge facts, along with image OCR tokens, question
caption pairing task for Advertisement images (Hussain words, and image content, to guide the answer generation,
et al., 2017). The Advertisement images are rich in scene and inferring the appropriate answer comprising the OCR
text and often include brand-related keywords which con- tokens and the fixed vocabulary.
vey semantics, as observed in (Dey et al., 2021). Thus,
in (Ye et al., 2021) the authors explore this scene text
channel further and use external knowledge from DBpe- In this work, we propose the use of mined external
dia to enrich the scene text features. Similar to the contex- knowledge to the Text-VQA task, where we deal with
tual relevance schemes discussed for Knowledge enabled noisy or irrelevant knowledge and generate answers that
datasets, an image-guided attention mechanism controls extend beyond the detected knowledge facts. As such, we
the incorporation of knowledge into scene text features. solve the more general problem of what is valid, relevant
The knowledge-enriched scene text and visual objects at- knowledge, and how to reason with it during answer gen-
eration. We extend upon the basic M4C framework by
including a separate knowledge processing pipeline. Our
2 https://dbpedia.org knowledge pipeline extracts and validates web scraped
4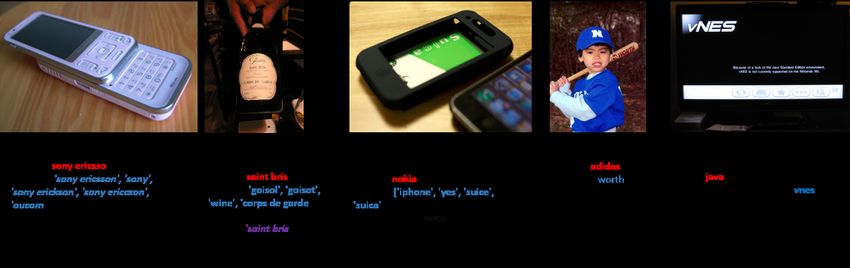
Figure 2: Extraction, Validation and Reasoning : The three stages of using external knowledge in Text-VQA.
knowledge and uses the multimodal transformer to de- corporate knowledge into the framework through the in-
fine task-specific relevance and reasoning of the vali- clusion of a separate knowledge channel and a constrained
dated knowledge. We use image context to filter out in- interaction achieved through attention masks.
valid knowledge explicitly. Similar to the multimodal We now present the details of our method by first intro-
co-attention scheme of (Ye et al., 2021), we propose a ducing the different feature formulations used, followed
knowledge-enabled multimodal transformer allowing for by our external knowledge pipeline, and finally, our an-
the visual, text, knowledge, and question nodes to attend swer generation process.
to each other through multiple layers of self-attention. We
believe that through our design choice, our knowledge- 3.1. Multi modal Features
related components can be readily incorporated into any The input to our multimodal transformer, as illustrated
of the existing multimodal transformer-based architec- in both Figure 2 and 5, consists of detected visual objects
tures discussed above, leading to further improved results. and scene text from the image, the given question, and the
mined external knowledge.
3. KTVQA: External Knowledge enabled Text-VQA Question Words. Given a sequence of L question words,
we embed them as {xques
l } (where l = 1, ..., L) using pre-
We now present our External Knowledge enabled Text- trained BERT (Devlin et al., 2019) with xques ∈ R768 .
l
VQA framework, that proposes the use of a pre-existing
External Knowledge Base to improve the Text-VQA task. Visual Objects. Following M4C, each of the M visual
KTVQA, as shown in Figure 2, entails extracting, val- object regions are encoded as xmf r , using a pre-trained
idating, and reasoning with noisy External Knowledge ResNet based Faster R-CNN (FRCNN) (Ren et al., 2015)
in a multimodal transformer framework. The inputs to model trained on Visual Genome. Additionally the
the Text-VQA task are question-answer pairs and associ- bounding box information is embedded as xbm to preserve
ated images. While VQA tasks only require exploring the spatial information. The appearance and spatial features
visual content of images, Text-VQA requires leveraging thus obtained are linearly projected and combined to gen-
scene text content too. Thus the input stream consists of erate the final set of visual object features {xob j
m } (where m
detected local visual objects and scene text. To augment = 1, ..., M) as
our understanding of scene text objects, we use an Exter- ob j
nal Knowledge Base to extract candidate meanings, which xm = LN(W1 xmf r ) + LN(W2 xbm ) (1)
we validate through context. Our proposal is based on the where W1 and W2 are learned projection matrices. LN()
multimodal transformer-based M4C architecture. We in- is layer normalization
5
Scene Text. For the N OCR tokens, both the recognized is 4 for a validation subset of 25000 words. Based on this
OCR text as well as the visual appearance is encoded. observation, we limit our maximum number of candidates
The same FRCNN based detector, used in object detec- to 4.
tion above, extracts and encodes the visual appearance
features corresponding to the bounding box regions as xnf r , Knowledge Validation through Context. The particu-
which is combined with xnf t and xnph , Fasttext (Bojanowski lar meaning a scene text word assumes depends on the
et al., 2017) and PHOC (Almazán et al., 2014) embed- context it occurs in. Thus disambiguation amongst candi-
ding respectively of the OCR token. Finally the bounding date meanings is done based on the context of the current
boxes coordinates are embedded as xbn similar to visual image. We see an example of this in Figure 3b, where the
objects, to obtain {xocr
n } (where n = 1,... , N) as
context word like ‘mobile-phone’ helps select the valid
knowledge description for ‘vertu’.
We define image context c = [t, vc], as the aggregation
ft fr ph
n = LN(W3 xn + W4 xn + W5 xn ) + LN(W6 xn ) (2)
xocr b
of the N OCR tokens t, and V class labels vc of visual
where W3 ,W4 , W5 and W6 , are learned projection matri- objects co-occurring in the current image. This context is
ces. encoded in BERT to generate {xcp } with xcp ∈ R768 (where
p = 1,..,N+V).
External Knowledge. Knowledge obtained from Given a scene text word ti and its set of candidate mean-
Google Knowledge Base (GKB) is in the form of a text ings S i = {S i j }, we use the context c of the current image
description, which is encoded using pre-trained BERT to select the valid meaning S id ∈ S i . For each candidate
sentence embedding. Corresponding to each encoded meaning S i j ∈ S i , we learn a validity score r j , given by
OCR token xocr k k
n , we have a knowledge node xn , with xn ∈
Eq. 3, which compares its BERT embeddings with those
768
R . This knowledge node is selected from among the of the context words. We deem the highest scoring can-
candidate meanings following the procedure explained in didate meaning as being the image context appropriate,
the next section. therefore valid.
X
Previous D Steps Prediction. The answer is generated r j = Wc (Relu(Wa xS i j ) · Relu(Wa xcp )) (3)
step-wise, one word at a time either from closed global an- d = argmax r j (4)
swer vocabulary or current image OCR tokens. As seen j
in Figure 5, the current step answer word prediction re- xki = xS id (5)
quires, as part of its input, the predicted answer words
from the previous D steps {xt−1d } (where d = 1,..,D) and Where Wa , Wc , are learned projection matrix. Further,
768
xt−1
d ∈R xS i j and xc , are the BERT embeddings of jth candidate
meaning S i j and context c respectively.
3.2. External Knowledge
The Knowledge Pipeline has three stages, namely ex- Reasoning with External Knowledge. Reasoning with
traction, validation, and reasoning, as illustrated in Figure External Knowledge implies identifying relevant knowl-
2, which we elaborate upon now. edge facts and enforcing constrained interaction between
knowledge and scene text nodes. We now discuss how
Knowledge Extraction. For each detected scene text implicit relevance is achieved through transformers fol-
word, we query GKB. In case of a hit in GKB, for each lowed by our proposed constrained interaction which
query scene text word ti , we get a set of candidate mean- incorporates knowledge into scene text representation
ings S i , which we retain and later disambiguate in the while ensuring legitimacy.
knowledge validation step. In Figure 3a, we show a sam- Relevance While the validity or correctness of the ex-
ple response we get. With the default GKB API setting of ternal knowledge can be judged from its image context;
a maximum of 10 candidates per query, we observe that it says nothing about its relevance or applicability while
the median number of candidates returned per query word generating answers. The decision to include or exclude
6
Figure 3: Knowledge Extraction and Validation. Figure (a) shows knowledge extraction using Google API and Figure (b) demonstrates knowledge
validation and selection through image context. We identify knowledge validation as an important subtask for web-scraped knowledge data that is
not anchored to our Text-VQA datasets explicitly
the external knowledge fact about a scene text node is
crucial when it comes to generating answers. Instead
of an explicit task to define knowledge relevance like
Narasimhan and Schwing (2018); Wang et al. (2018), we
include the set of knowledge nodes {xkn } as part of the
transformer input and let the internal attentional frame-
work (Vaswani et al., 2017) select relevant knowledge
facts. The transformer attentional framework treats the
scene text, visual objects, question words, and knowledge
nodes alike, attending to relevant nodes based on the final
task of question answering.
Constrained Interaction The self-attention layer in the
transformer architecture allows a node to form its rep-
resentation using the other nodes in the neighborhood.
In practice, this neighborhood is typically the entire set
of co-occurring nodes, but it can also be constrained to
a smaller subset, thereby limiting which nodes interact. Figure 4: Constrained Interaction: Knowledge inclusion through Atten-
In the past, such constrained interaction through the use tion Mask matrix A. It controls the interaction between the nodes. Dark
of attention masks has found application in causal step- Cells allow interaction between corresponding nodes. AKT and AT K ,
highlighted in blue, are N × N identity matrices, binding the knowledge
wise decoding (Hu et al., 2020) and enforcing spatial rela- facts with their corresponding OCR tokens. Highlighted in pink is the
tions (Kant et al., 2020). In this work, we extend the use of D × D lower triangular sub-matrix APP enforcing causality between pre-
constrained interaction to preserve node-to-node knowl- vious decoding steps
edge legitimacy i.e., the one-to-one relationship between
scene text nodes and their corresponding validated knowl-
edge facts.
Formally, Attention Mask matrix A ∈ RE×E controls the
interaction between the L Question words, M visual ob-
7
jects, N OCR objects, N knowledge nodes and D previous The current decoding state zt−1d is linearly projected
stage predictions, with E = L + M + N + N + D. Specif- through Wvoc to generate the H dimensional vocabulary
ically, Ai j is added as a bias term to the softmax layer of scores yvoc ocr
d . While, the N dimensional OCR scores yd are
the self-attention, effectively controlling j’s role in i’s new generated through a bi-linear interaction between the cur-
representation. For intuitive understanding, the dark cells rent decoder state zt−1 ocr
d and the OCR outputs {zn } (where
in Figure 4 represent 0, and the grey/empty cells repre- n= 1,..,N). We refer to this as the Pointer network in the
sent −∞. As seen in the figure, our Attention Mask matrix Figure 5. We take the argmax on the concatenated score
d = [yd , yd ] to generate the current answer token yd .
voc ocr ans
A allows complete interaction between the visual, scene yall
text, and question words. While the scene text words We successively decode for 12 steps or till we predict the
{xocr
n } and their corresponding mined knowledge facts {xn }
k
special end marker token.
are represented as distinct nodes, their interaction is sub-
ject to certain constraints.
4. Experiments
The scene text words are symbolic representations, with
the mined knowledge facts bringing in the associated We benchmark our method on the TextVQA
semantics. This symbolic-semantic one-to-one relation dataset (Singh et al., 2019a) and the ST-VQA (Biten et al.,
needs to be preserved if we want to later discriminate 2019) dataset. Our results show that the improvements
amongst scene text words based on knowledge. The final from using knowledge are significant for both datasets.
answer generation consists of comparing the transformer We briefly discuss our implementation and dataset details,
output {zocr
n } of the scene text words with the current de- followed by a comparison of our results with the recent
coding state zt−1d . Thus, we ensure that for a given scene methods, a detailed analysis of how knowledge helps,
text word xocrn , only its own legitimate knowledge fact xkn and finally conclude with an ablation study of our model.
contributes to this final representation zocrn . This is en-
forced through the identity sub-matrices AKT , AT K , high- 4.1. Implementation and Dataset details
lighted in Figure 4, preserving node-to-node knowledge
Implementation Details. Our implementation is based
legitimacy by allowing only the related knowledge fact
on PyTorch Transformers library 3 . We adopt a multi-
and OCR token to attend to each other. Further, the lower
modal transformer architecture akin to (Hu et al., 2020).
triangular sub-matrix APP enables step-wise causal de-
Our basic transformer design is similar in spirit, with eight
coding, enforcing that the current answer generation can
attention heads and four layers, but we add masking to
only interact with previously decoded answer tokens.
constraint the external knowledge interaction. We use
Formally the outputs of our multimodal transformer T
Adam as our optimizer. We start with a learning rate of
can be defined as,
1e − 4, and step-wise reduce it further upon stagnation or
[zq , zob j , zocr , zk , zt−1 ] = T ([xq , xob j , xocr , xk ], xt−1 , A) (6) plateau.
Where xt−1 = {xt−1
d } is the set of predictions from the pre- Dataset 1: TextVQA. The TextVQA dataset consists of
vious D time steps, we initialize this with the start token. 28,408 images collected from OpenImages (Kuznetsova
et al., 2020), with 45,336 questions-answer pairs. The
3.3. Answer Generation
evaluation metric proposed is accuracy, measured via soft
Our Answer Generation consists of stepwise causal de- voting of the 10 Ground Truth answers provided.
coding of the transformer outputs, akin to the iterative de- We use Google-OCR 4 , for scene text detection and
coder introduced in (Hu et al., 2020). Briefly, we gen- recognition. Of the total 189551 detected scene text
erate the answer tokens yansd , ∀d, one token at a time or words, GKB offers an average of 2.29 different candi-
step-wise, predicting either from a fixed vocabulary of H date meanings for each of the 100972 words found in the
words or from amongst current N OCR tokens. Similar to
(Hu et al., 2020; Kant et al., 2020), the attention mask en-
forces causality by preventing current answer tokens from 3 https://pytorch.org/hub/huggingface pytorch-transformers
attending to answer tokens yet to be generated. 4 https://cloud.google.com/vision/docs/ocr
8Figure 5: KTVQA: Our proposed External Knowledge enabled Text-VQA
Knowledge Base. In Figure 3a, we see that the GKB re- ANLS refers to averaged NLS scores over all questions,
sponse includes 3 tags; name, description and attribute. while truncating scores below 0.5 to 0 before averaging
Interestingly we note that GKB exhibits tolerance towards For scene text words, we use the Rosetta-en OCR to-
spelling errors, often returning candidates with high lex- kens from Pythia (Singh et al., 2018). From the total of
ical similarity. While in some cases, this leads to correct 64830 detected scene text words, GKB offers candidate
candidate meanings even with incorrect OCR, it also leads meanings for 39053 words. The final knowledge annota-
to a significant number of false positives. Thus we re- tions mined, after the filtering described above, consist of
move entries where the queried scene text is not present in 23132 words and their candidate meanings.
the ‘name’ or ‘description’ tag of the returned candidate
meaning. For the remaining words, we merge their de- 4.2. Comparison with state-of-the-art
scription and attribute tags. This results in mined knowl-
edge facts for 57666 words, including 2917 multiword en- In Table 1 we report our Text-VQA open-ended ques-
tity names(e.g., ‘new york’, ‘burger king’) tion answering results on the datasets TextVQA and ST-
VQA. In row 7, we present our ablated instance without
knowledge, namely TVQA, and in row 8, we present our
Dataset 2: ST-VQA. The ST-VQA dataset consists of
full model KTVQA. For all models, we specify the OCR
23,038 images, from various sources (Karatzas et al.,
system used on the dataset as part of its column informa-
2013, 2015; Bigham et al., 2010; Mishra et al., 2013; Kr-
tion.
ishna et al., 2016; Veit et al., 2016), with 31791 questions-
Our primary observation is the 2.5% absolute improve-
answer pairs. To deal with OCR recognition errors that
ment of KTVQA over non-knowledge baseline TVQA
lead to answers with misplaced /missing characters, the
across datasets. For the TextVQA dataset, our model
authors (Biten et al., 2019) propose the Average Normal-
improves upon the state-of-the-art (Kant et al., 2020).
ized Levenshtein Similarity (ANLS) as an alternate eval-
For the ST-VQA dataset, our results are comparable with
uation metric. Normalized Levenshtein Similarity (NLS)
models with a similar OCR system. Table 1 also high-
is defined as,
lights the correlation between a better OCR system and
improved answer generation. We observe that, in gen-
NLS = 1 − dL (y , y )/max(y , y )
ans GT ans GT
(7)
eral, models with the Google-OCR system perform better
where yans and yGT are the predicted and ground truth compared to those with Rosetta OCR systems. To eluci-
answers respectively, with dL referring to edit distance. date this further, in Table 4, we report the Upper Bound
9Table 1: Results of Text-VQA Task on TextVQA and ST-VQA Dataset
TextVQA Dataset ST-VQA Dataset
Model OCR Val. Acc. Test Acc. OCR Val. ANLS. Test ANLS
1 LoRRA Singh et al. (2019a) Rosetta-ml 26.56 27.63 - - -
2 M4C (Hu et al., 2020) Rosetta-en 39.44 39.10 Rosetta-en 0.472 0.462
3 SMA (Gao et al., 2020) Rosetta-en 40.05 40.66 Rosetta-en - 0.466
4 CRN (Liu et al., 2020) Rosetta-en 40.39 40.96 Rosetta-en - 0.483
5 LaAP-Net (Han et al., 2020) Rosetta-en 40.68 40.54 Rosetta-en 0.497 0.485
6 SA-M4C (Kant et al., 2020) Google-OCR 43.9 - Google-OCR 0.512 0.504
7 TVQA Google-OCR 41.7 - Rosetta-en 0.468 -
8 KTVQA Google-OCR 44.26 44.2 Rosetta-en 0.499 0.48
Table 2: Results of related methods on TextVQA Dataset with additional pre-training tasks and datasets
pre-training
Model Task Dataset OCR Val. Acc. Test Acc.
1 KTVQA - - Google-OCR 44.26 44.2
2 M4C (Hu et al., 2020) - ST-VQA Rosetta-en 40.55 40.46
3 SA-M4C (Kant et al., 2020) - ST-VQA Google-OCR 45.4 44.6
4 TAP Yang et al. (2021) MLM,ITM,RPP - Rosetta-en 44.4 -
5 TAP Yang et al. (2021) MLM,ITM,RPP - Microsoft-OCR 49.91 49.71
6 TAP Yang et al. (2021) MLM,ITM,RPP ST-VQA,Textcaps,OCR-CC Microsoft-OCR 54.71 53.97
Table 3: Dataset Comparison. OCR UB: Percentage of answers com- from the TextVQA dataset, are not as good as the Google-
prising of OCR tokens alone, Vocab UB: Percentage of answers com-
prising of fixed vocabulary words only, OCR + Vocab UB: Percentage OCR tokens. Thus for the ST-VQA dataset, the erro-
of answers comprising of OCR tokens and answer vocabulary words, neous Rosetta-en tokens mean not just missing out on
i.e., the maximum achievable accuracy. answers words, leading to a lower OCR UB compared
to TextVQA, but also amount to fewer knowledge hits
Dataset TextVQA ST-VQA
compared to TextVQA, as listed in Table 3. While our
#Images 28408 23038
method generates results comparable to the state-of-the-
#Question-Answer 45,336 31791
OCR system Google-OCR Rosetta-en
art on both datasets, what is more, promising is that the
#Scene-Text 189551 64830 knowledge channel can be readily incorporated into the
#Mined Knowledge 57666 23132 existing state-of-the-art models, which could lead to fur-
OCR UB (%) 53.4 50.53 ther improvements in those models.
LA UB (%) 57.14 67.16 Across models, pre-training on additional tasks and
OCR + LA UB (%) 84.4 83.33 datasets can lead to significant improvements, as is ob-
served in Table 2. These datasets, however, comprise
accuracies on the TextVQA validation set against the dif- additional images and question/answer pairs and require
ferent OCR systems. The OCR systems can be judged resource-intensive manual annotation. Similarly, pre-
by comparing their OCR Upper Bound accuracy, which training requires additional computing resources. In con-
is the percentage of Ground truth answers that can be trast, our mined external knowledge consists of text de-
composed of OCR tokens alone. For the Validation set, scriptions for a subset of scene text words obtained in
the Rosetta-en OCR tokens have an OCR Upper Bound an unsupervised manner from web scraped data. Fur-
accuracy of 44.9% compared to 53.4% of Google-OCR, ther, our mined knowledge facts form part of our feature
as shown in Table 4. For the ST-VQA dataset, we only set for each image and do not require additional training.
have Rosetta-en OCR tokens, which, as we have seen However, despite the additional pre-training tasks for TAP
10(row 4) and additional pre-training datasets for M4C (row In row 3 of Figure 6, we see examples of correct an-
2) and SA-M4C (row 3), our Knowledge enabled model swers using Multiword entities. For Popular words like
KTVQA (row 1) still performs at par with them. Finally, ‘New York’, our trained multimodal transformer itself
we note that the improvements in TAP (row 6) can be at- should be enough to predict them in sequence, but for a
tributed to not just the additional annotated datasets but lesser-seen couplet of words such as ‘voll damm’, such
also improved OCR quality, as is evident by comparing binding is more beneficial.
rows 4 and 5.
Table 4: Upper Bounds and OCR systems: OCR UB: Percentage of an- Mitigating dataset bias. Problems due to dataset biases
swers comprising OCR tokens alone, Vocab UB: Percentage of answers are well studied (Kafle and Kanan, 2017b; Agrawal et al.,
comprising fixed vocabulary words only, OCR + Vocab UB: Percentage 2017). They can be attributed to data distribution. This re-
of answers comprising OCR tokens and answer vocabulary words, i.e.,
the maximum achievable accuracy .
sults in the network favoring answers or class types which
it has seen more examples of, often ignoring the lesser-
TextVQA Val accuracy(%) seen correct answers. Row 2 of Figure 6 shows exam-
Rosetta-ml Rosetta-en Google-OCR ples of knowledge mitigating dataset bias. Despite the
OCR UB 37.12 44.9 53.4 presence of the correct answer words in the OCR tokens
Vocab UB 48.46 59.02 57.14 detected, the baseline TVQA failed to produce the cor-
OCR + Vocab UB 67.56 79.72 84.4 rect answer words, instead predicting semantically simi-
lar words from the vocabulary. Ostensibly, the predicted
answer words are popular, with many examples in the
training data. Knowledge helps against bias by bringing
4.3. How knowledge helps in much-needed additional information about lesser-seen
Improved Answer Entity type correctness. The ques- OCR tokens.
tion asked, often, pre-determine the type of answer en-
tity. Entity type question words like ‘what time’, ‘which 4.4. Ablation Studies
place’, ‘how wide’ point towards distinct answer entity
In this section, we report results on ablated instances of
types. In row 1 of Figure 6, we see examples where exter-
our model across datasets to highlight the contribution of
nal knowledge about the OCR tokens enables us to learn
individual model components and draw insights about the
this entity type association better. As seen with the re-
transferable properties of external knowledge.
sponses from TVQA in row 1, we note that semantic word
embedding (Bojanowski et al., 2017) and character infor- Table 5: Ablation study 1: : Role of Knowledge related Components
mation (Almazán et al., 2014) about OCR token lead to
basic entity type correctness like numeric or non-numeric. TextVQA ST-VQA
Model Validation Reasoning Val. Acc. Val. ANLS.
However, the knowledge descriptions of the scene text 1 TVQA - - 41.7 0.4893
words are typically verbose and detailed, allowing us to 2 KTVQAUnc Context Unconstrained 42.73 0.4875
3 KTVQARnd Random Constrained 42.89 0.4893
better associate the scene text words with related question
4 KTVQAAll Sum of All Constrained 43.54 0.4856
words. 5 KTVQA Context Constrained 44.26 0.4991
Multiword Entity Recognition. Multiword Entities are
entities with multiple words in the name, e.g. ‘New York’,
‘Bob Dylan’ , ‘Into The Wild’, etc. We detect multiword Ablation study 1: Role of Model Components. We pro-
entities during the external knowledge extraction phase, pose validating candidate knowledge facts through im-
where we bind together OCR tokens if they are part of age context and reasoning with this validated knowledge
the same-named entity. E.g., if for OCR token ‘York’, we through constrained interaction. In this section, we inves-
find a returned named entity ‘New York’ from GKB and tigate the individual role played by these two knowledge
the OCR token ‘New’ is in the neighborhood, we bind components by comparing our full model with ablated in-
them as ‘New York’. stances. We briefly describe the ablated models below:
11Figure 6: Examples of knowledge effectiveness. TVQA is our baseline similar to M4C (Hu et al., 2020) and does not use external knowledge. The
correct answers are marked in Blue, while incorrect ones are marked with Red. Multiword Entities, row 3, are marked with Purple. In Row 1, we
see observe that with knowledge we are able to improve upon answer entity correctness. Row 2 shows the effectiveness of external knowledge in
dealing with Dataset Bias. Finally in Row 3, we showcase our Multi-word Entities.
12Figure 7: Examples of knowledge limitations. The correct answers are marked in Blue, while incorrect ones are marked with Red. Multi-word
Entities are marked with Purple
KTVQA. KTVQA is our full model, which uses con- As shown in Table 5, for both datasets, the inclusion
text to validate and thus select knowledge, and enforces of knowledge leads to improvement over the M4C based
constrained interaction during reasoning with knowledge non-knowledge baseline TVQA. We see this improve-
node. ment to be more pronounced for the TextVQA dataset,
compared to ST-VQA, by virtue of having more knowl-
TVQA. As described in Sec. 4.2 TVQA is our non- edge entries, as evident in Table 3. Further, we demon-
knowledge baseline similar to M4C. It does not use any strate the effectiveness of our constrained interaction
knowledge nodes and thus is devoid of all of our knowl- through its improvements upon the unconstrained base-
edge pipeline components. line KT V QAUnC . As discussed in Sec. 3.2, our con-
strained interaction enforces knowledge legitimacy, en-
KTVQAUnC . We propose the use of constrained inter- abling it to discriminate amongst OCR tokens based on
action, as detailed in Sec. 3.2 to preserve knowledge le- their corresponding knowledge node. Next, we high-
gitimacy. In KTVQAUnC , we allow unconstrained inter- light the improvements through context-based candidate
action between the knowledge and text nodes through the knowledge validation and selection by comparing with
use of a zero matrix as the attention Mask A. The remain- two baselines; KT V QA
Rnd which selects randomly, and
ing components are the same as the KTVQA full model, KT V QA which makes no selection and instead settles
All
including the context-based validation. for aggregation. Our results validate our hypothesis that
context can be used to select valid candidates that help
KTVQARnd . In Sec. 3.2 we argue for the use of context
downstream reasoning.
to validate and select from amongst candidate meanings.
KTVQARnd is our ablated instance, which does not use Ablation study 2: Transferable property of external
context but instead randomly selects from among the can- knowledge. We propose the use of externally mined
didate meanings. It is similar to KTVQA in every other knowledge to augment our understanding of scene text
respect, including the constrained interaction. nodes. In this section, we investigate the transferable
property of the said external knowledge by comparing our
KTVQA All . This is our ablated instance which, unlike full model with the ablated instances below:
KTVQA or KTVQARnd does not select one particular can-
didate meaning, instead aggregates all candidate mean- TVQA∗ . TVQA∗ is the TVQA model loaded with
ings. Our implementation achieves this by taking a sum KTVQA trained weights, mimicking a model that has
of the Bert embeddings of all candidates instead of select- seen external knowledge during training, but does not use
ing one. knowledge during testing.
13KTVQA∗ . KTVQA∗ is the KTVQA model loaded with predicted answer word was the incorrect OCR token ‘er-
TVQA trained weights. It mimics a model that is not icsso’.
trained with knowledge but can use knowledge during
testing. Knowledge is not Complete. Incompleteness in knowl-
In Table 6 rows 1-2, we observe that even if the use edge can manifest itself in two ways, either through a
of external knowledge is limited to the training phase, we complete miss or through false positives by incorrectly
obtain significant improvements in the test results. This referring to another entity the queried text shares name
is in line with our previous hypothesis, Sec. 4.3, about with. Thus knowledge incompleteness is a major cause of
how the verbose knowledge descriptions lead to better failure, as illustrated in Figure 7. For the fourth and fifth
generalization. Thus, while our model uses no explicit images, the correct answer forming OCR tokens ‘worth’
instance-specific knowledge during testing, the learned and ‘vnes’ were absent in the External Knowledge Base.
knowledge-enabled semantics from the training phase While for the third image, the OCR token ‘suica’ refers
leads to the improvement. Rows 3-4 suggest that knowl- to a smart card or a village in Bosnia, according to GKB,
edge can not simply be plugged in only at test time, and failing to include any reference to a cell phone case.
learning the text-knowledge association, enabled through
our knowledge components, is essential. 4.6. Results Summary
In this section we highlight the key takeaways from our
Table 6: Ablation study 2: Transferable property of external knowledge
results. Our main takeaway is that the use of external
Knowledge TextVQA ST-VQA knowledge leads to improved generalization and allows
Model Train Test Val. Acc. Val. ANLS. us to deal with dataset bias. Our primary results in Ta-
1 TVQA × × 41.7 0.4893 ble 1, shows that, given the same upstream OCR system,
2 TVQA∗ X × 43.12 0.4908 and training data, our results match the state-of-the-art on
3 KTVQA∗ × X 39.36 0.4635 two public datasets. Furthermore Table 2 suggests our
4 KTVQA X X 44.26 0.4991 model(row 1) is at par with models trained on additional
datasets(rows 2,3), and even those incorporating pretrain-
ing tasks(rows 4,5).
Through our experiments, with empirical evidence, we
4.5. Bottleneck and Limitations also justify our model components. We identify im-
age contextual validity check as an important subtask for
Knowledge effectiveness depends on OCR quality.
noisy web data, and justify it through our results (Table
Valid knowledge extraction is dependent on correct OCR
5 rows 3,4 against row 5). Our arguments for node-to-
recognition. Incorrect OCR recognition can lead to either
node knowledge legitimacy achieved through constrained
a complete miss or false positives in the knowledge ex-
interaction are validated by our results in Table 5 (rows 2
traction phase. In the first and second images of Figure
against row 5).
7, the incorrect OCR tokens ‘goisol’ (‘goisot’) and ‘eric-
Finally our results also identify OCR quality and Knowl-
sso’ (‘ericsson’) can not be helped by external knowledge,
edge incompleteness as major bottlenecks to overcome in
which subsequently leads to incorrect answer predictions
the future.
in both cases. As discussed in Sec. 4.1, we observe that
GKB has tolerance towards incorrect spellings, wherein
it can return correct meanings even with incorrect OCR 5. Conclusion
tokens. So while in the case of ‘goisot’ we received no
hits, for ‘ericsso’, GKB tolerance allowed us to get the In this work, we look at the use of mined external
meaning corresponding to ‘ericsson’. However, this does knowledge applied to the Open-ended Text-VQA ques-
not help as the final answer words are selected from the tion answering task. Through our experiments, we ob-
OCR tokens, as discussed in Sec. 3.3. Thus despite hav- serve that this external knowledge not only provides in-
ing the correct meaning corresponding to ‘ericsson’, our valuable information about unseen scene text elements
14but also augments our understanding of the text in gen- Bigham, J., Jayant, C., Ji, H., Little, G., Miller, A., Miller, R.,
eral with detailed verbose descriptions. Our knowledge- Miller, R., Tatarowicz, A., White, B., White, S., Yeh, T.,
enabled model is robust to novel text, predicts answers 2010. Vizwiz: Nearly real-time answers to visual questions,
with improved entity type correctness, and can even pp. 333–342.
recognize multiword entities. However, the knowledge Biten, A.F., Tito, R., Mafla, A., Gomez, L., Rusinol, M., Val-
pipeline is susceptible to erroneous OCR tokens, which veny, E., Jawahar, C., Karatzas, D., 2019. Scene text visual
can lead to false positives or complete misses. This also question answering, in: Proceedings of the IEEE/CVF inter-
explains how our performance on the datasets is corre- national conference on computer vision, pp. 4291–4301.
lated with the OCR systems used.
While the use of knowledge in Vision Language un- Bojanowski, P., Grave, E., Joulin, A., Mikolov, T., 2017. Enrich-
derstanding tasks has been proposed in the past, we pro- ing word vectors with subword information. Transactions of
pose an end-to-end pipeline to extract, validate and reason the Association for Computational Linguistics 5, 135–146.
with noisy web-scraped External Knowledge. We present Chen, Y.C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z.,
this as a complementary approach to training on addi- Cheng, Y., Liu, J., 2020. Uniter: Universal image-text rep-
tional annotated data or pre-training tasks to achieve gen- resentation learning, in: European conference on computer
eralization and deal with dataset bias. Finally, we hope vision, Springer. pp. 104–120.
our results inspire the community to incorporate external
knowledge pipelines into their works, opening them up to Devlin, J., Chang, M.W., Lee, K., Toutanova, K., 2019. Bert:
knowledge and potential improvements in results. Pre-training of deep bidirectional transformers for language
understanding, in: NAACL-HLT.
6. Acknowledgement Dey, A.U., Ghosh, S.K., Valveny, E., Harit, G., 2021. Beyond
visual semantics: Exploring the role of scene text in image
This work was supported by Scheme for Promotion understanding. Pattern Recognition Letters 149, 164–171.
of Academic and Research Collaboration (SPARC), Min-
Gao, C., Zhu, Q., Wang, P., Li, H., Liu, Y., Hengel, A.V., Wu, Q.,
istry of Human Resource Development (MHRD), Gov-
2020. Structured multimodal attentions for textvqa. ArXiv
ernment of India. abs/2006.00753.
Goyal, Y., Khot, T., Agrawal, A., Summers-Stay, D., Batra, D.,
References
Parikh, D., 2018. Making the v in vqa matter: Elevating the
Agrawal, A., Kembhavi, A., Batra, D., Parikh, D., 2017. C-vqa: role of image understanding in visual question answering. In-
A compositional split of the visual question answering (vqa) ternational Journal of Computer Vision 127, 398–414.
v1.0 dataset. ArXiv abs/1704.08243.
Han, W., Huang, H., Han, T., 2020. Finding the evidence:
Almazán, J., Gordo, A., Fornés, A., Valveny, E., 2014. Word Localization-aware answer prediction for text visual question
spotting and recognition with embedded attributes. IEEE answering, in: Proceedings of the 28th International Confer-
Transactions on Pattern Analysis and Machine Intelligence ence on Computational Linguistics, COLING 2020, Interna-
36, 2552–2566. tional Committee on Computational Linguistics.
Anderson, P., He, X., Buehler, C., Teney, D., Johnson, M., Hu, R., Singh, A., Darrell, T., Rohrbach, M., 2020. Iterative
Gould, S., Zhang, L., 2018. Bottom-up and top-down atten- answer prediction with pointer-augmented multimodal trans-
tion for image captioning and visual question answering, in: formers for textvqa. 2020 IEEE/CVF Conference on Com-
Proceedings of the IEEE conference on computer vision and puter Vision and Pattern Recognition (CVPR) , 9989–9999.
pattern recognition, pp. 6077–6086.
Hussain, Z., Zhang, M., Zhang, X., Ye, K., Thomas, C., Agha,
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, Z., Ong, N., Kovashka, A., 2017. Automatic understanding
C.L., Parikh, D., 2015. Vqa: Visual question answering, in: of image and video advertisements. 2017 IEEE Conference
Proceedings of the IEEE international conference on com- on Computer Vision and Pattern Recognition (CVPR) , 1100–
puter vision, pp. 2425–2433. 1110.
15Kafle, K., Kanan, C., 2017a. An analysis of visual question an- Liu, F., Xu, G., Wu, Q., Du, Q., Jia, W., Tan, M., 2020. Cascade
swering algorithms, in: 2017 IEEE International Conference reasoning network for text-based visual question answering,
on Computer Vision (ICCV), pp. 1983–1991. in: Proceedings of the 28th ACM International Conference
on Multimedia, p. 4060–4069.
Kafle, K., Kanan, C., 2017b. Visual question answering:
Datasets, algorithms, and future challenges. Computer Vi- Lu, J., Batra, D., Parikh, D., Lee, S., 2019. Vilbert: Pretraining
sion and Image Understanding 163, 3–20. task-agnostic visiolinguistic representations for vision-and-
language tasks, in: Advances in Neural Information Process-
Kant, Y., Batra, D., Anderson, P., Schwing, A., Parikh, D., Lu, ing Systems 32: Annual Conference on Neural Information
J., Agrawal, H., 2020. Spatially aware multimodal transform- Processing Systems 2019, NeurIPS 2019, December 8-14,
ers for textvqa, in: Computer Vision–ECCV 2020: 16th Eu- 2019, Vancouver, BC, Canada, pp. 13–23.
ropean Conference, Glasgow, UK, August 23–28, 2020, Pro-
Mishra, A., Karteek, A., Jawahar, C.V., 2013. Image retrieval
ceedings, Part IX 16, Springer. pp. 715–732.
using textual cues. 2013 IEEE International Conference on
Computer Vision , 3040–3047.
Karaoglu, S., Tao, R., Gevers, T., Smeulders, A.W., 2017. Words
matter: Scene text for image classification and retrieval. IEEE Mishra, A., Shekhar, S., Singh, A.K., Chakraborty, A., 2019.
Transactions on Multimedia 19. Ocr-vqa: Visual question answering by reading text in im-
ages, in: 2019 International Conference on Document Anal-
Karatzas, D., Gomez-Bigorda, L., Nicolaou, A., Ghosh, S., Bag- ysis and Recognition (ICDAR), IEEE. pp. 947–952.
danov, A., Iwamura, M., Matas, J., Neumann, L., Chan-
drasekhar, V.R., Lu, S., Shafait, F., Uchida, S., Valveny, E., Narasimhan, M., Lazebnik, S., Schwing, A.G., 2018. Out of the
2015. Icdar 2015 competition on robust reading, in: 2015 box: Reasoning with graph convolution nets for factual vi-
13th International Conference on Document Analysis and sual question answering, in: Advances in Neural Information
Recognition (ICDAR), pp. 1156–1160. Processing Systems 31: Annual Conference on Neural Infor-
mation Processing Systems 2018, NeurIPS 2018, December
Karatzas, D., Shafait, F., Uchida, S., Iwamura, M., i Bigorda, 3-8, 2018, Montréal, Canada, pp. 2659–2670.
L.G., Mestre, S.R., Mas, J., Mota, D.F., Almazan, J.A.,
De Las Heras, L.P., 2013. Icdar 2013 robust reading compe- Narasimhan, M., Schwing, A.G., 2018. Straight to the facts:
tition, in: 2013 12th International Conference on Document Learning knowledge base retrieval for factual visual question
Analysis and Recognition, IEEE. pp. 1484–1493. answering, in: Proceedings of the European Conference on
Computer Vision (ECCV).
Kim, J.H., Jun, J., Zhang, B.T., 2018. Bilinear attention net-
works, in: Proceedings of the 32nd International Conference Ren, S., He, K., Girshick, R., Sun, J., 2015. Faster r-cnn: To-
on Neural Information Processing Systems, p. 1571–1581. wards real-time object detection with region proposal net-
works, in: Advances in neural information processing sys-
Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, tems, pp. 91–99.
J., Chen, S., Kalantidis, Y., Li, L.J., Shamma, D., Bernstein,
Shah, S., Mishra, A., Yadati, N., Talukdar, P.P., 2019. Kvqa:
M.S., Fei-Fei, L., 2016. Visual genome: Connecting lan-
Knowledge-aware visual question answering, in: Proceed-
guage and vision using crowdsourced dense image annota-
ings of the AAAI Conference on Artificial Intelligence, pp.
tions. International Journal of Computer Vision 123, 32–73.
8876–8884.
Kuznetsova, A., Rom, H., Alldrin, N., Uijlings, J., Krasin, Singh, A., Natarajan, V., Jiang, Y., Chen, X., Shah, M.,
I., Pont-Tuset, J., Kamali, S., Popov, S., Malloci, M., Rohrbach, M., Batra, D., Parikh, D., 2018. Pythia-a plat-
Kolesnikov, A., et al., 2020. The open images dataset v4. form for vision & language research, in: SysML Workshop,
International Journal of Computer Vision 128, 1956–1981. NeurIPS.
Le, Q., Mikolov, T., 2014. Distributed representations of sen- Singh, A., Natarajan, V., Shah, M., Jiang, Y., Chen, X., Batra,
tences and documents, in: Proceedings of the 31st Interna- D., Parikh, D., Rohrbach, M., 2019a. Towards vqa models
tional Conference on International Conference on Machine that can read, in: Proceedings of the IEEE/CVF Conference
Learning - Volume 32, JMLR.org. p. II–1188–II–1196. on Computer Vision and Pattern Recognition, pp. 8317–8326.
16Singh, A.K., Mishra, A., Shekhar, S., Chakraborty, A., 2019b. Arka Ujjal Dey received his Bache-
From strings to things: Knowledge-enabled vqa model that lor’s and Master’s Degrees in Com-
can read and reason, in: Proceedings of the IEEE/CVF Inter- puter Science from Calcutta Univer-
national Conference on Computer Vision, pp. 4602–4612. sity in 2010, and 2012 respectively.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., In 2015 he obtained his Master of
Gomez, A.N., Kaiser, Ł., Polosukhin, I., 2017. Attention is Technology Degree from IIT Jodh-
all you need, in: Advances in neural information processing pur, where he is currently enrolled as
systems. a Ph.D. student in the Computer Sci-
ence and Engineering Department.
Veit, A., Matera, T., Neumann, L., Matas, J., Belongie, S.J., His research interests lie at the intersection of Computer
2016. Coco-text: Dataset and benchmark for text detection
Vision and Natural Language Processing.
and recognition in natural images. ArXiv abs/1601.07140.
Wang, P., Wu, Q., Shen, C., Dick, A., van den Hengel, A., 2018.
Fvqa: Fact-based visual question answering. IEEE Transac- Ernest Valveny received the Ph.D.
tions on Pattern Analysis and Machine Intelligence 40, 2413– degree in 1999 from the Universi-
2427. tat Autònoma de Barcelona (UAB),
where he is currently an associate
Wu, Q., Wang, P., Shen, C., Dick, A., Van Den Hengel, A., 2016.
Ask me anything: Free-form visual question answering based professor and member of the Com-
on knowledge from external sources, in: Proceedings of the puter Vision Center (CVC). His re-
IEEE conference on computer vision and pattern recognition, search work focuses mainly on doc-
pp. 4622–4630. ument analysis and pattern recogni-
tion, and more specifically in the
Yang, Z., Lu, Y., Wang, J., Yin, X., Florencio, D., Wang, L., fields of robust reading, text recognition and retrieval, and
Zhang, C., Zhang, L., Luo, J., 2021. Tap: Text-aware pre-
document understanding. He has published more than 20
training for text-vqa and text-caption, in: Proceedings of
the IEEE/CVF Conference on Computer Vision and Pattern
papers in international journals and more than 100 papers
Recognition, pp. 8751–8761. in international conferences. He is a member of IAPR
and of the editorial board of the International Journal on
Ye, K., Zhang, M., Kovashka, A., 2021. Breaking shortcuts by Document Analysis and Recognition and has served as a
masking for robust visual reasoning, in: Proceedings of the reviewer for many international journals and conferences.
IEEE/CVF Winter Conference on Applications of Computer
Vision, pp. 3520–3530.
Gaurav Harit received a Bachelor
of Engineering degree, in Electrical
Engineering, from M.B.M. Engineer-
ing College, Jai Narayan Vyas Uni-
versity Jodhpur, in 1999. He received
a Master of Technology and Ph.D.
degrees from IIT Delhi, in 2001 and
2007, respectively. He is a faculty
member in the Department of Com-
puter Science and Engineering at the Indian Institute of
Technology Jodhpur since 2010. Before joining IIT Jodh-
pur, he was a faculty member in the Department of Com-
puter Science and Engineering at IIT Kharagpur. His ar-
eas of interest are Document Image Analysis and Video
Analysis.
17You can also read

















































