Chinese Lip-Reading Research Based on ShuffleNet and CBAM
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
applied
sciences
Article
Chinese Lip-Reading Research Based on ShuffleNet and CBAM
Yixian Fu, Yuanyao Lu * and Ran Ni
School of Information Science and Technology, North China University of Technology, Beijing 100144, China
* Correspondence: luyy@ncut.edu.cn
Abstract: Lip reading has attracted increasing attention recently due to advances in deep learning.
However, most research targets English datasets. The study of Chinese lip-reading technology is
still in its initial stage. Firstly, in this paper, we expand the naturally distributed word-level Chinese
dataset called ‘Databox’ previously built by our laboratory. Secondly, the current state-of-the-art
model consists of a residual network and a temporal convolutional network. The residual network
leads to excessive computational cost and is not suitable for the on-device applications. In the new
model, the residual network is replaced with ShuffleNet, which is an extremely computation-efficient
Convolutional Neural Network (CNN) architecture. Thirdly, to help the network focus on the most
useful information, we insert a simple but effective attention module called Convolutional Block
Attention Module (CBAM) into the ShuffleNet. In our experiment, we compare several model
architectures and find that our model achieves a comparable accuracy to the residual network
(3.5 GFLOPs) under the computational budget of 1.01 GFLOPs.
Keywords: Chinese lip-reading; ShuffleNet; CBAM; light-weight network
1. Introduction
Lip reading is the task of recognizing contents in a video only based on visual in-
formation. It is the intersection of computer vision and natural language processing. At
the same time, it can be applied in a wide range of scenarios such as human-computer
interaction, public security, and speech recognition. Depending on the mode of recognition,
lip reading can be divided into audio-visual speech recognition (AVSR) and visual speech
Citation: Fu, Y.; Lu, Y.; Ni, R. Chinese recognition (VSR). AVSR refers to the use of image processing capabilities in lip reading to
Lip-Reading Research Based on aid speech recognition systems. In VSR, speech is transcribed using only visual information
ShuffleNet and CBAM. Appl. Sci. to interpret tongue and teeth movements. Depending on the object of recognition [1], lip
2023, 13, 1106. https://doi.org/ reading can be divided into isolated lip recognition methods and continuous lip recognition
10.3390/app13021106 methods. Isolated lip recognition method targets numbers, letters, words, or phrases,
Academic Editor: Eui-Nam Huh which can be classified into limited categories visually. The continuous lip recognition
method targets phonemes, visemes (the basic unit of visual information) [2], and visually
Received: 5 December 2022 indistinguishable characters.
Revised: 4 January 2023
In 2016, Google [3] and the University of Oxford designed and implemented the first
Accepted: 6 January 2023
sentence-level lip recognition model, named LipNet. Burton, Jake et al. [4] used the lip
Published: 13 January 2023
recognition method of CNN and LSTM to solve the complex speech recognition problem
that the HMM network could not solve. In 2019, as the attention mechanism was introduced
into the field of lip recognition, Lu et al. [5] proposed a lip-reading recognition system
Copyright: © 2023 by the authors.
using the CNN-Bi-GRU-Attention fusion neural network model, and the final recognition
Licensee MDPI, Basel, Switzerland. accuracy reached 86.8%. In 2021, Hussein D. [6] improved the above fusion lip recognition
This article is an open access article model and proposed the HLR-Net model. The model mainly was composed of the fusion
distributed under the terms and model of Inception-Bi-GRU-Attention and used the CTC loss function to match the input
conditions of the Creative Commons and output, and its recognition accuracy reached 92%.
Attribution (CC BY) license (https:// However, the research mentioned above involves English datasets, and the develop-
creativecommons.org/licenses/by/ ment of Chinese lip-reading technology is still in the initial stage. Compared with English
4.0/). which consists of only letters, Chinese is more complex. This is because Chinese Pinyin
Appl. Sci. 2023, 13, 1106. https://doi.org/10.3390/app13021106 https://www.mdpi.com/journal/applsci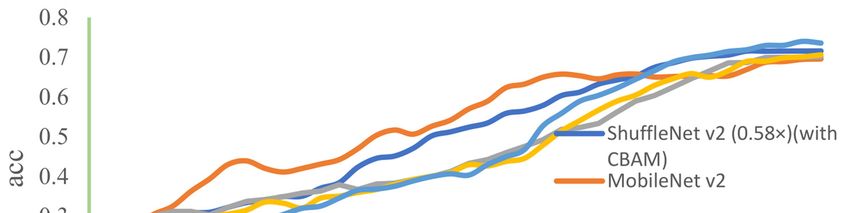
Appl. Sci. 2023, 13, x FOR PEER REVIEW 2 of 16
Appl. Sci. 2023, 13, 1106 However, the research mentioned above involves English datasets, and the develop- 2 of 15
ment of Chinese lip-reading technology is still in the initial stage. Compared with English
which consists of only letters, Chinese is more complex. This is because Chinese Pinyin
has more than 1000 pronunciation combinations and the number of Chinese characters is
has more than 1000 pronunciation combinations and the number of Chinese characters
more than 9000. Moreover, the deficiency of Chinese datasets also makes lip reading more
is more than 9000. Moreover, the deficiency of Chinese datasets also makes lip reading
challenging.
more challenging.
Additionally,
Additionally, in inrecent
recentyears,
years,building
buildingdeeper
deeperandand larger
larger neural
neural networks
networks is a is a pri-
primary
mary trend in the development of major visual tasks [7–9], which requires
trend in the development of major visual tasks [7–9], which requires computation at billions computation at
billions of FLOPs. The high cost limits the practical deployment
of FLOPs. The high cost limits the practical deployment of lip-reading models. of lip-reading models.
In
In this
this paper,
paper,we weaimaimtotopropose
propose a deep-learning
a deep-learning model
modeldesigned
designed for on-device
for on-device ap-
plication
application on our self-built dataset called ‘Databox’. Our model is improved basedthe
on our self-built dataset called ‘Databox’. Our model is improved based on on
current state-of-the-art
the current methodology
state-of-the-art methodologyconsisting of a ResNet
consisting network
of a ResNet networkand aand
Temporal Con-
a Temporal
volutional
ConvolutionalNetwork. We replace
Network. ResNet
We replace with awith
ResNet lightweight convolutional
a lightweight network
convolutional called
network
ShuffleNet with a plug-in attention module called Convolutional Block
called ShuffleNet with a plug-in attention module called Convolutional Block Attention. Attention. In Sec-
tion 2, we give
In Section 2, wea detailed description
give a detailed of all the
description of parts
all theofparts
the model.
of the In Section
model. In 3, we present
Section 3, we
and analyze
present and the results
analyze theofresults
the experiments. In SectionIn
of the experiments. 4, Section
we conclude
4, we that our model
conclude that ourar-
chitecture not only reduces computation but also maintains comparable
model architecture not only reduces computation but also maintains comparable accuracy accuracy that is
suitable for mobile platforms such as drones, robots, and phones with
that is suitable for mobile platforms such as drones, robots, and phones with limited limited computing
power.
computing power.
2. Lip-Reading
2. Lip-Reading Model
Model Architecture
Architecture
Lip reading
Lip reading is one of the most challenging problems in artificial intelligence, which
recognizes
recognizes thethe speech
speech content
content based
based onon the
the motion
motion characteristics
characteristics of of the
the speaker’s
speaker’s lips.
lips.
thedevelopment
With the developmentofofartificial
artificial intelligence
intelligence [10–12],
[10–12], traditional
traditional lip-reading
lip-reading methods
methods are
are being
being gradually
gradually substituted
substituted by deep-learning
by deep-learning methods. methods.
Depending Depending on the char-
on the functional func-
tional characteristics,
acteristics, the lip-reading
the lip-reading method mainlymethod mainly
consists of aconsists
frontendof anetwork
frontend network
and and
a backend
a backend network. The frontend networks include Xception [13],
network. The frontend networks include Xception [13], MobileNet [14,15], ShuffleNet MobileNet [14,15],
ShuffleNet
[16,17], [16,17],GoogLeNet,
VGGNet, VGGNet, GoogLeNet,
ResNet, andResNet, and DenseNet
DenseNet[18], while the [18], whilenetworks
backend the backend
in-
clude Temporal Convolutional Network [19,20], the Long Short-Term Memory Memory
networks include Temporal Convolutional Network [19,20], the Long Short-Term (LSTM)
(LSTM)
[21], and[21], and the
the Gate Gate Unit
Control Control
(GRU)Unit[22].
(GRU)
The [22]. The attention
attention mechanism, mechanism, aimedal-
aimed at better at
better allocation
location of resources,
of resources, processes
processes more important
more important information
information in a feature
in a feature map. map. Our
Our net-
work is composed of ShuffleNet, CBAM and TCN, with the structure shown in Figure 1.1.
network is composed of ShuffleNet, CBAM and TCN, with the structure shown in Figure
Temporal Convolution Network
ShuffleNet Predict Results
+
Softmax
Channel Attention Spatial Attention
…
Module Module
C3D Refine feature
Input feature
CBAM
Figure 1. The architecture of the lip-reading model. Given a video sequence, we extract 29 consecu-
Figure 1. The architecture of the lip-reading model. Given a video sequence, we extract 29 consecutive
tive frames that have a single channel indicating a gray level. The frames firstly go through a 3D
frames that with
convolution have kernel
a single5 ×channel indicating
7 × 7 called C3D. aAgray level. network
ShuffleNet The frames firstlywith
inserted go through a 3D
the attention
convolution
module with
called kernel
CBAM 5 × 7for
is used ×spatial
7 called C3D. A ShuffleNet
downsampling. network
Finally, insertedofwith
the sequence thevectors
feature attention
is
module
fed called
into the CBAM Convolutional
Temporal is used for spatial downsampling.
for temporal Finally, the
downsampling sequence
followed by aofSoftMax
feature layer.
vectors is
fed into the Temporal Convolutional for temporal downsampling followed by a SoftMax layer.
The model consists of five parts:
Input: using the Dlib library for detecting 68 landmarks of the face, we can crop the
lip area and extract 29 consecutive frames from the video sequence. The frames go through
a simple C3D network for generic feature extraction.
CNN: ShuffleNet performs spatial downsampling of a single image.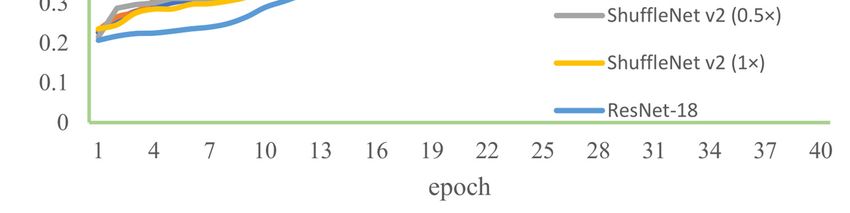
Appl. Sci. 2023, 13, 1106 3 of 15
CBAM: Convolutional Block Attention Mechanism includes two independent modules
that focus on important information of the channel dimension and the spatial dimension.
TCN: models the output of the frontend network and learns the long-term dependen-
cies from several consequent images.
Output: lastly, we pass the result of the backend to SoftMax for classifying the
final word.
2.1. ShuffleNet
With the development of deep-learning technology, the concept of the convolutional
neural network (CNN) has developed rapidly in recent years. Considered as a fully
connected network with multiple layers that can simulate the structure of the human brain,
a convolutional neural network can perform supervised learning and recognition directly
from images. Convolutional neural networks are mainly composed of the following types
of layers: input layer, convolutional layer, ReLU layer, Pooling layer, and fully connected
layer. By stacking these layers together, a complete convolutional neural network can be
constructed. CNN is great at processing video, which is a superposition of images. It is
typically deployed in autonomous driving, security, medicine and so on.
However, with neural networks becoming deeper and deeper, computation complexity
increases significantly as well, which motivated the appearance of the lightweight model
architecture design, including MobileNet V2, ShuffleNet V1, ShuffleNet V2, and Xception.
Under the same FLOPs, the accuracy and speed of these models are shown in Table 1.
Table 1. Measurement of accuracy and GPU speed of four different lightweight models with the
same level of FLOPs on COCO object detection. (FLOPs: float-point operations).
GPU Speed
Model mmAP (%)
(Images/s)
FLOPs 40M 140M 300M 500M 40M 140M 300M 500M
Xception 21.9 29.0 31.3 32.9 178 131 101 83
ShuffleNet v1 20.9 27.0 29.9 32.9 152 85 76 60
MobileNet v2 20.7 24.4 30.0 30.6 146 111 94 72
ShuffleNet v2 23.7 29.6 32.2 34.2 183 138 105 83
We can see from Table 1 that ShuffleNet V2 has the highest accuracy and the fastest
speed among the four different architectures. Therefore, we utilize ShuffleNet V2 as the
frontend of our model. It mainly uses two new operations, namely, pointwise group
convolution and channel shuffle, which greatly reduce the computational cost without
affecting recognition accuracy.
2.1.1. Group Convolution
Group convolution was firstly used in AlexNet for distributing the network over two
GPUs, which proved its effectiveness in ResNeXt [23]. Conventional convolution adopts
channel-dense connection, which performs a convolution operation on each channel of
input features.
For conventional convolution, the width and height of the kernel are K and the C
represents the number of input channels; if the number of the kernel is N, the number of
the output channel is also N. The number of parameters is calculated as follows:
P(CC) = K × K × C × N (parameters)
(CC: Conventional Convolution)Appl. Sci. 2023, 13, x FOR PEER REVIEW 4 of 15
Appl. Sci. 2023, 13, x FOR PEER REVIEW 4 of 15
Appl. Sci. 2023, 13, 1106 4 of 15
P(CC) = K × K × C × N (parameters)
(CC: Conventional Convolution)
P(CC) = K × K × C × N (parameters)
For groupconvolution,
For group convolution, thethe channels
channels of input
of the the input features
features are divided
are divided into G into G groups,
groups,
such(CC:
such thatConventional
that thenumber
the Convolution)
numberofof
thethe kernel
kernel is C/G;
is C/G; thethe results
results fromfrom G groups
G groups are concatenated
are concatenated into into
For
larger
larger groupoutputs
feature
feature convolution,
outputsofof theN
thethe
N channels
channel.
channel. ofThe
The the number
inputoffeatures
number are divided
parameters is into
is calculated
of parameters G
asgroups,
follows:
calculated as follows:
such that the number of the kernel is C/G; the results from G groups are concatenated into
NP(GC)
P(GC)
larger feature outputs of the = K ×=KK
channel. ××C/G
The K × C/
×N
number Gof(parameters)
×parameters
N (parameters)
is calculated as follows:
(GC: GroupConvolution)
(GC: Group Convolution)
P(GC) = K × K × C/ G × N (parameters)
From the
FromGroup above
the above formulas, we we
formulas, can can tell the
tell that thatnumber
the number of parameters
of parameters in groupin group convo-
convolu-
(GC: Convolution)
lution is much
tion is much
From smaller
smaller
the above
thanthan
that that
formulas, of tell
of conventional
we can conventional convolution.
convolution.
that the number of parameters in group convo-
The conventional
The conventional convolution
convolutionandand
group convolution
group are illustrated
convolution in Figure
are illustrated in 2.Figure 2.
lution is much smaller than that of conventional convolution.
The conventional convolution and group convolution are illustrated in Figure 2.
Input Features Output Features Input Features Output Features
Input
C=12Features N=6 Output O=6
Features Input Features
C=12 G=3
Output Features
O=6
C=12 N=6 O=6 C=12 G=3 N=6 O=6
N=6
(a)
(a) (b) (b)
Figure
Figure 2.
Figure 2.(a)
2. (a)Conventional
(a) Conventional
Conventional Convolution
Convolution
Convolution (b)
(b)Group
(b) Convolution.
Group
Group C,
C,N,
Convolution.
Convolution. N,G,
G,and
C, O
O correspond
N, G,
and and to
tothe
O correspond
correspond the to the
numbers
numbers
numbers ofof the
ofthe channel,
thechannel,
channel,kernel, group,
kernel,
kernel, and
group,
group, output,
andand respectively.
output,
output, respectively.
respectively.
2.1.2. Channel
2.1.2. ChannelShuffle
Shuffle
2.1.2. Channel Shuffle
However, group
However, group convolution
convolution also
also leads
leadsto to the
the problem
problem that
that different
different groups
groups can
can no
no
longer
longer
However,
share
group convolution
share information.
information. Therefore,
also leadsperforms
Therefore,ShuffleNet
ShuffleNet to the problem
performs aachannel
channel that different
shuffle
shuffle
groups
operation
operation on can no
on
longer
the share
the output information.
output features
features so
so that Therefore,
that information ShuffleNet
information cancan circulate performs
circulate through a channel
through different shuffle
different groups operation
groups without
without on
the outputcomputing
increasing
increasing features costs.
computing so that
costs. The
Theinformation
process of
process can
of the
the circulate
channel
channel through
shuffle
shuffle is shown different
in Figuregroups
3. without
increasing computing costs. The process of the channel shuffle is shown in Figure 3.
Channels
Channels Input
Input
GConv1
GConv1
Feature
Feature
Channel Shuffle
Channel Shuffle
GConv2
GConv2
Output
Figure
Figure 3.
3. The
The process
process of
of the
the Channel
Channel Shuffle.
Shuffle. The
TheGConv2
GConv2layer
layerisis allowed
allowed to
to obtain
obtain features
features of
of
different from the GConv1 layer due to the Output
different groups from the GConv1 layer due to the Channel Shuffle layer. That means theinput
groups Channel Shuffle layer. That means the inputand
and
output channels will be fully related. (GConv: Group Convolution).
output channels will be fully related. (GConv: Group Convolution).
Figure 3. The process of the Channel Shuffle. The GConv2 layer is allowed to obtain features of
different groups from the GConv1 layer due to the Channel Shuffle layer. That means the input and
output channels will be fully related. (GConv: Group Convolution).Appl. Sci. 2023, 13, x FOR PEER REVIEW 5 of 15
2.1.3. ShuffleNet V2 Unit
Appl. Sci. 2023, 13, 1106 As shown in Figure 4a, in ShuffleNet V2 unit 1, a channel split is firstly performed 5 of 15
on the input feature map, which is divided equally into two branches. The left branch
remains unchanged, whereas the right branch undergoes three convolution operations.
When the convolution is completed, the two branches will be concatenated to fuse the
2.1.3. ShuffleNet V2 Unit
features. Finally, Channel Shuffle is used to communicate information between different
As shown in Figure 4a, in ShuffleNet V2 unit 1, a channel split is firstly performed on
groups.
the input featurein
As shown map, which
Figure 4b,isindivided equally
ShuffleNet V2into
unittwo branches.
2, the The
channel is left
notbranch
divided remains
at the
unchanged, whereas the right branch undergoes three convolution operations.
beginning, and the feature map is directly inputted to the two branches. Both branches When
the
useconvolution is completed,
3 × 3 deep convolution the twothe
to reduce branches will of
dimension bethe
concatenated to Then,
feature map. fuse the
thefeatures.
concat-
Finally, Channel Shuffle is used to communicate information
enation operation is performed on the output of the two branches. between different groups.
Channel Split
1×1 Conv
1×1 Conv 3×3 DWConv
(stride=2)
3×3 DWConv
(stride=2)
3×3 DWConv
1×1 Conv
1×1 Conv
1×1 Conv
Concat
Concat
Channel Shuffle Channel Shuffle
(a) (b)
Figure 4.
Figure 4. (a)
(a) ShuffleNet
ShuffleNet V2
V2 Unit1
Unit1 (b)
(b) ShuffleNet
ShuffleNet V2
V2 Unit2.
Unit2. ShuffleNet-V2
ShuffleNet-V2 is is an
an effective
effective lightweight
lightweight
deep-learningnetwork
deep-learning networkwith
with only
only 2M2M parameters.
parameters. It the
It uses usesidea
theofidea of convolution
group group convolution from
from AlexNet
AlexNet and channel shuffle, which not only greatly reduce the number of model parameters, but
and channel shuffle, which not only greatly reduce the number of model parameters, but also improve
also improve the robustness of the model. (DWConv [20]: Depth Wise Convolution).
the robustness of the model. (DWConv [24]: Depth Wise Convolution).
2.2. Convolutional
As shown in Block Figure Attention Module
4b, in ShuffleNet V2 unit 2, the channel is not divided at the
beginning, and the feature map is directly inputtedmap
In the field of image processing, the feature contains
to the a variety
two branches. of important
Both in-
branches use
× 3 deep convolution
3formation. The traditional convolutional
to reduce the dimensionneural network
of the feature performs
map. Then, convolution in the
the concatenation
same wayisonperformed
operation all channels, but output
on the the importance
of the twoofbranches.
information varies greatly depending on
different channels, hence, treating each channel equally can decrease the precision of the
2.2. Convolutional Block Attention Module
network.
In
Tothe field of
improve theimage processing,
performance the feature neural
of convolutional map contains
networks a for
variety of important
feature extraction,
information. The traditional convolutional neural network performs
Woo et al. [Error! Reference source not found.] put forward a convolutional attention convolution in the
same way onnamed
mechanism all channels, but the importance
Convolutional of information
Block Attention varies greatly
Module (CBAM) in 2018,depending
which is a
on different
simple channels,
and effective hence, treating
attention module each channel equally
for feedforward can decrease
convolutional thenetworks
neural precisionand
of
the network.
contains two independent sub-modules, namely, Channel Attention Module (CAM) and
To improve
Spatial Attentionthe performance
Module (SAM),of convolutional
which neural networks
perform Channel for feature
and Spatial extraction,
Attention, respec-
Woo et al. [25] put forward a convolutional attention mechanism named
tively. They added a module that can be seamlessly integrated into any Convolutional Convolutional
Block
Neural Attention
NetworkModule
(CNN)(CBAM)
architecturein 2018,
and which
trainedisend-to-end
a simple and effective
with attention
the base CNN to module
classi-
for feedforward convolutional neural networks and contains two independent
cal networks such as ResNet and MobileNet. The analysis showed that the attention mech- sub-modules,
namely,
anism inChannel
the spatialAttention Module
and channel (CAM) and
dimensions Spatialthe
improved Attention Module
performance (SAM),
of the which
network to
perform
a certainChannel
extent. and Spatial Attention, respectively. They added a module that can be
seamlessly integrated into any Convolutional Neural Network (CNN) architecture and
trained end-to-end with the base CNN to classical networks such as ResNet and MobileNet.
The analysis showed that the attention mechanism in the spatial and channel dimensions
improved the performance of the network to a certain extent.Given an intermediate feature map, the CBAM module will sequentially comput
attention maps along two independent dimensions (channel and space), and
Appl. Sci. 2023, 13, x FOR PEER REVIEW 6 ofthen
15 multi
Appl. Sci. 2023, 13, 1106 ply the attention map with the input feature map for adaptive feature optimization. 6 of 15
It determines the attention region by evaluating the importance of both the channe
and Given
spatialanorientation of feature
intermediate the image
map,tothe
suppress irrelevant
CBAM module willbackground
sequentially information
compute and
Given an
strongly maps
attention intermediate
emphasize feature map,
the information
along two the CBAM
of the target
independent dimensions module will sequentially
to be detected.
(channel compute
and space), and then multi-
attention maps along
ply the attention maptwowithindependent dimensions
the input feature (channel
map for andfeature
adaptive space),optimization.
and then multiply
the attention map with the input feature map for adaptive feature optimization.
2.2.1.It Channel
determines the attention
Attention region by evaluating the importance of both the channel
Module
and It determines
spatial the attention
orientation region
of the image toby evaluating
suppress the importance
irrelevant of both
background the channel
information and
In theorientation
and spatial channel attention module,
of the image the input
to suppress feature
irrelevant map (H ×information
background W × C) is and
respectively
strongly emphasize the information of the target to be detected.
processed
strongly by global
emphasize the maximum
information pooling andtoglobal
of the target average pooling based on its length
be detected.
and width
2.2.1. Channel to Attention
extract information
Module and compress spatial information; two different featur
2.2.1. Channel Attention Module
maps of
In the
size
the channel
1 × 1 ×
channelattention
C are generated,
attentionmodule,
module,the
respectively.
theinput
inputfeature
Then
featuremap map(H
they
(H××W
are
W×× C)
each
C) is
inputted
is respectively
respectively
into a two
In
layer neural network with one hidden layer foraverage
calculation, where the
processed
processed by global
by global maximum
maximum pooling
pooling and
and global
global pooling
average pooling based
based onparameters
on length in thi
its length
its
network
and width
width to are shared.
to extract The
extract information first
information and layer has
and compress C/r (channel
compress spatial reduction
spatial information;
information; two rate, set
two different to r
different feature= 16) neurons
feature
and
and the
maps
maps of
second
of size
size 11 ××1layer
1× × C arehas
C are
C neuralrespectively.
generated,
generated,
units, following
respectively. Then thethey
they
Then
activation
are each function
inputted
are each inputted intoReLU.
ainto
two-a
Then th
output
layer neural
two-layer feature network
neural map
network elements
with with are
one hidden added and
layer layer
one hidden merged,
for calculation, and the
wherewhere
for calculation, Hard–Sigmoid
the parameters
the parameters activation
in this
network
function are
is shared.
used to The first
generate layer
the has C/r
feature (channel
map (1 reduction
in this network are shared. The first layer has C/r (channel reduction rate, set to rthe
× 1 × C) rate,
that set
is to r
inputted= 16) neurons,
to = 16)spatial at
and the
neurons, second
tention module. layer
and the second has
In terms C neural
layerof has units,
a single following
image,
C neural the
channel
units, activation
following attention function ReLU.
focusesfunction
the activation on what Then the
in the imag
ReLU.
output
Then thefeature
is important. map
outputAverage featureelements
map
poolingare added
elements
givesare and merged,
added
feedback to and
and thepixel
merged,
every Hard–Sigmoid
andon thethe activation
Hard–Sigmoid
feature map, whil
function
activation is used to generate the feature map (1 × 1
maximum pooling gives feedback only where the response is the strongest inthe
function is used to generate the feature map× C)(1that
× 1 is
× inputted
C) that isto the
inputted spatialto at- featur
the
tentionattention
spatial module. In terms ofIna terms
module. single of
image,
a singlechannel
image, attention
channel focuses on what
attention focuses in theon image
whatattention
map when performing the gradient backpropagation calculation. The channel
is the
in important.
image isAverage important. pooling
Averagegivespooling
feedback givesto feedback
every pixel to on thepixel
every feature on map, while
the feature
module ispooling
maximum
shown gives in Figure
feedback
5. only where the response is the strongest in the feature
map, while maximum pooling gives feedback only where the response is the strongest in
the feature map when performing thebackpropagation
map when performing the gradient gradient backpropagation calculation. The channel
calculation. Theattention
channel
Max
module Pooling
is shown in Figure
attention module is shown in Figure 5. 5.
Max Pooling
Avg Pooling
Channel
Avg Pooling
Attention Weight
Channel
Shared MLP
Attention Weight
Figure 5. The channel Shared MLP
attention module. The module uses both Max Pooling outputs and Avg Pool
ing outputs with a shared network.
Figure 5. The channel attention module. The module uses both Max Pooling outputs and Avg Pooling
Figure 5. The channel attention module. The module uses both Max Pooling outputs and Avg Pool-
ing outputs
outputs withwith a shared
a shared network.
network.
2.2.2. Spatial Attention Module
2.2.2.
2.2.2. Spatial
Spatial Attention
Attention Module
Module module, the feature maps outputted from the CAM modul
In the spatial attention
In the spatial
In the spatialandattention
attention module,
module, the
the feature
feature maps
maps outputted
outputted from the
fromandthe CAM
CAM module
module
are compressed merged by channel-wise maximum pooling average pooling sep
are
are compressed
compressed and
and merged
merged by
by channel-wise
channel-wise maximum
maximum pooling
pooling and and average
average pooling
pooling sep-
arately, and
separately, and
two
two
featuremaps
mapsof of
featuremaps
size
sizeH
HW××W1 are
H ××W
× 1obtained.
are obtained.
Then the
Then the concatenation
concatenation
arately, and two
operation isperformed,feature
performed, and of size
the dimension × 1 are obtained.
is reducedaafter Then the concatenation
a 7 × 7 convolution kerne
operation
operation is is performed, andand the
the dimension
dimension isis reduced after a77×× 77 convolution
reduced after convolution kernel
kernel
operationtoto
operation obtain
obtain thethe spatial
spatial attention
attention featurefeature
map (H map
×W (H× ×1).WThe
× 1). The attention
spatial spatial attention
operation to obtain the spatial attention feature map (H × W × 1). The spatial attention
moduleisisshown
module shown in in Figure
Figure 6. 6.
module is shown in Figure 6.
SpatialSpatial
Attention
Attention Weight Weight
Output
Output
Convolution
Convolution Layer
Layer
[Max Pooling, Avg Pooling]
[Max Pooling, Avg Pooling]
Figure 6. The spatial attention module. The module uses two outputs from Max Pooling and Avg
Figure6.6.
Figure
Pooling The
The
which spatial
spatial
are attention
attention
pooled along module.
module.
the The module
The module
channel axis anduses uses
two
passes two
to aoutputs
outputs
them from Max from
convolution Max and
Pooling
layer. Pooling
Avg and Av
Pooling which are pooled along the channel axis and passes them to a convolution
Pooling which are pooled along the channel axis and passes them to a convolution layer. layer.Appl. Sci.
Appl. Sci. 2023,
2023, 13,
13, 1106
x FOR PEER REVIEW 77 of 16
of 15
2.3. Temporal
2.3. Temporal Convolutional
ConvolutionalNetwork
Network
The topic
The topic of
of sequence
sequence modeling
modeling hashas been
been commonly
commonly associated
associated with
with the
the Recurrent
Recurrent
Neural Network
Neural Network (RNN),
(RNN), suchsuch as
as LSTM
LSTM and GRU. However, However, there
there are
are bottlenecks
bottlenecks inin these
these
models. Up
models. Upuntil
untilrecently,
recently, researchers
researchers began
began to consider
to consider CNNCNN and found
and found that certain
that certain CNN
architectures can achieve
CNN architectures betterbetter
can achieve performance
performance in many taskstasks
in many thatthat
are are
underestimated.
underestimated. In
2018, Shaojie
In 2018, BaiBai
Shaojie et al. [8][8]
et al. proposed
proposedthethe
Temporal
Temporal Convolutional
Convolutional Network
Network (TCN),
(TCN),which
which is
an improvement
is an improvement of the CNN
of the CNNnetwork.
network .
Compared
Compared with
with conventional
conventional one-dimensional convolution, TCN employs two dif-
ferent
ferent operations7:
operations7: casual convolution and dilated dilated convolution.
convolution. It is more adaptive
adaptive forfor
dealing
dealing with
with sequential
sequential datadata due
due to
to its temporality and large receptive fields. In addition,
the
the residual
residual connection
connection is is used,
used, which
which is is aa simple
simple yet
yet very
very effective
effective technique
technique toto make
make
training deep neural networks easier. The structure of the TCN is shown
training deep neural networks easier. The structure of the TCN is shown in Figure 7. in Figure 7.
Input
+
Dropout
ReLU
BN
Dilated Conv &
Causal Conv
1*1 Conv
Dropout
ReLU
Dilated Conv &
Causal Conv
BN
Output
Figure 7. The
Figure Thestructure of the
structure Temporal
of the Convolutional
Temporal Network.
Convolutional Dilated
Network. casual casual
Dilated convolution, weight
convolution,
normalization, dropout, and the optional 1 × 1 Convolution are needed to complete the residual
weight normalization, dropout, and the optional 1 × 1 Convolution are needed to complete the
block. block.
residual
2.3.1.
2.3.1. Casual
Casual Convolution
Convolution
Causal
Causalconvolution
convolutiontargets
targetsthe thetemporal
temporal data, which
data, ensures
which thethe
ensures model cannot
model cannotdisrupt
dis-
the
ruptorder in which
the order we model
in which the data.
we model the The
data.distribution predicted
The distribution for a certain
predicted component
for a certain com-
of the signal
ponent only
of the depends
signal on the component
only depends predicted predicted
on the component before. That means
before. only
That the “past”
means only
can
the influence
“past” can theinfluence
“future”.the
It is“future”.
differentItfrom the conventional
is different from the filter which looks
conventional filterinto the
which
future as well
looks into the as the past
future while
as well sliding
as the pastover
whilethesliding
data. over the data.
It
It can
can be
be used
used for
for synthesis
synthesis withwith
←←
x1 x1 sample
sample (f1(f1
(0,(0,
. . .…, 0))
, 0))
x2 ← sample (f2 (x1, 0, …, 0))
x2 ← sample (f2 (x1, 0, . . . , 0))
←←
x3 x3 sample
sample (f3(f3 (x1,
(x1, x2,x2,
0, .0,. .…, 0))
, 0))
←←
xT xT sample
sample (fT(fT
(x1,(x1,
x2,x2,
. . . …,
, xTxT−1, 0))
−1, 0))
where 00 ssrepresent
where representunknown
unknownvalues.
values.
Theprocess
The processofofthe
thestandard
standard convolution
convolution andand casual
casual convolution
convolution is shown
is shown in Figure
in Figure 8a,b.
8 a,b.Appl.Appl. Sci. 2023,
Sci. 2023, 13, x13,
FOR1106PEER REVIEW 8 of 15 8 of 16
Appl. Sci. 2023, 13, x FOR PEER REVIEW 8 of 16
(a)(a) (b) (b)
Figure
Figure8.8.
Figure (a)Standard
8.(a) Standard
Standard Convolution
Convolution and
Convolution and
and(b)
(b) Casual
Casual
(b) Convolution.
Convolution.
Casual Standard
Standard
Convolution. convolution
convolution
Standard does
doesnot
convolution not take
takenot take
does
the
the direction
direction of
of convolution
convolution into
into account.
account. Casual
Casual Convolution
Convolution moves
moves the
the kernel
kernel in
in one
one direction.
direction.
the direction of convolution into account. Casual Convolution moves the kernel in one direction.
2.3.2.
2.3.2. Dilated
Dilated Convolution
Convolution
2.3.2. Dilated Convolution
Dilated
Dilated convolution, is
convolution, is also
also known
known as as Atrous
AtrousConvolution.
Convolution. The The idea
idea behind
behind dilated
dilated
Dilated is
convolution convolution, is also known as Atrous Convolution. The idea behind dilated
convolution is to “inflate” the kernel, which in turn skips some of the points. In
to “inflate” the kernel, which in turn skips some of the points. In aa network
network
convolution
made
made up up of is to “inflate”
of multiple
multiple layers the
layers of kernel,
of dilated
dilated which in turn
convolutions,
convolutions, theskips
the some
dilation
dilation rateof
rate the points.
is increased
is increased In a network
exponen-
exponen-
tially
tially at each layer. While the number of parameters grows only linearly with the layers,
made at
up each
of layer.
multiple While
layers theofnumber
dilated of parameters
convolutions, grows
the only
dilation linearly
rate with
is the
increased exponen-
layers,
the
tially effective receptive
at each layer. field
While grows exponentially with the layers. As a result, the dilated
the effective receptive fieldthe number
grows of parameters
exponentially with the grows
layers.onlyAs alinearly with
result, the the layers,
dilated
convolution provides a way that not only increases the receptive field but also contributes
the effective receptive
convolution provides a field grows
way that exponentially
not only with
increases the the layers.
receptive field butAsalso
a result, the dilated
contributes
to the reduction of the computing cost. The process of dilated convolution is illustrated
to the reduction
convolution of theacomputing
provides way that not cost.only
The process
increasesof dilated convolution
the receptive field is illustrated
but in
also contributes
in Figure 9.
toFigure 9.
the reduction of the computing cost. The process of dilated convolution is illustrated in
Figure 9.
Output
Dilation=4
Output
Dilation=4
Hidden Layer
Dilation=2
Hidden Layer
HiddenDilation=2
Layer
Dilation=1
Hidden Layer
Input
Dilation=1
Figure 9.9. The
The process
process of
of dilated
dilated convolution.
convolution. Dilated
Dilated convolution
convolution applies
applies the
the filter
filter over aa region
region
Figure
Input toover
larger than itself by skipping a certain number of inputs, which allows the network have a large
larger than itself by skipping a certain number of inputs, which allows the network to have a large
receptive field.
receptive
Figure field.process of dilated convolution. Dilated convolution applies the filter over a region
9. The
larger
2.3.3.than
2.3.3. itself Connection
Residual
Residual by skipping a certain number of inputs, which allows the network to have a large
Connection
receptive field.
Dataflows
Data flowsthrough
througheacheach layer
layer sequentially
sequentially in traditional
in traditional feedforward
feedforward neuralneural
networks.net-
works. They tend to come across problems such as exploding gradients
They tend to come across problems such as exploding gradients and vanishing gradients, and vanishing
2.3.3.
with
Residual
gradients, withConnection
the network the network deeper
becoming becominganddeeper
deeperandfordeeper for betterand
better accuracy accuracy and perfor-
performance. To
make Data
mance. theToflows
make through
training the
converge each
training layer in
converge
more easily, sequentially
more inthetraditional
easily, innetwork,
the residual residual feedforward
network,
another added neural
path isanother path net-
from
is added
works.
the fromtend
firstThey
layer the first layer
to to
directly the directly
come to
across layer
output thebypassing
problemsoutput layer
such asbypassing
the exploding
intermediate thegradients
intermediate
layers. Theand layers.
vanishing
residual
The residual
network has network
been has
widely been widely
adopted by adopted
many by
models many
such models
as ResNetsuch
gradients, with the network becoming deeper and deeper for better accuracy and perfor-foras ResNet
image for image
processing,
processing,
Transformer
mance. Transformer
To makefor natural for natural
language
the training language
processing,
converge more processing,
AlphaFold
easily, infor AlphaFold
theprotein fornetwork,
protein
structure
residual structure
predictions,
another path
etc. The process of traditional feedforward with and without residual connection
predictions, etc. The process of traditional feedforward with and without residual connec- is shown
is added from the first layer directly to the output layer bypassing the intermediate layers.
in Figure
tion 10a,b.in Figure 10 a,b.
is shown
The residual network has been widely adopted by many models such as ResNet for image
processing, Transformer for natural language processing, AlphaFold for protein structure
predictions, etc. The process of traditional feedforward with and without residual connec-
tion is shown in Figure 10 a,b.Appl. Sci.Sci.
Appl. 2023, 13, x
2023, 13,FOR
1106PEER REVIEW 9 of 915
of 15
x
x
Layer i
Layer i
F F
Layer i +n
Layer i +n
F(x)
+ x
F(x)
F(x)+x
(a) (b)
Figure 10. 10.
Figure (a) Feedforward without
(a) Feedforward the residual
without connection.
the residual (b) Feedforward
connection. with thewith
(b) Feedforward residual con-
the residual
nection. Residual Connection is a kind of skip-connection that learns residual functions with respect
connection. Residual Connection is a kind of skip-connection that learns residual functions with
to the layer inputs rather than learn unreferenced functions.
respect to the layer inputs rather than learn unreferenced functions.
3. Experiment
3. Experiment
3.1.3.1. Dataset
Dataset
Because
Because Chinese
Chinese lip recognition
lip recognition technology
technology is initial
is in its in its stage,
initialthe
stage, the and
quality quality
num-and
bernumber of lip-reading
of lip-reading datasetsdatasets available
available still havestill have way
a long a longto way to go.ofMost
go. Most of the current
the current lip-
lip-reading
reading datasetsdatasets
are in are in English.
English. There There are influential
are a few a few influential onesas:
ones such such as:
(1).(1).
TheThe AVLetters
AVLetters dataset
dataset is theis first
the first audio-visual
audio-visual speechspeech dataset
dataset whichwhich contains
contains 10
10 speakers, each of whom makes three independent statements
speakers, each of whom makes three independent statements of 26 English letters. There of 26 English letters. There
areare
780780 utterances
utterances in total.
in total.
(2). The XM2VTS
(2). The XM2VTS dataset dataset includes
includes 295 volunteers,
295 volunteers, each
each of of whom
whom reads reads two-digit
two-digit se-
sequences
quences and phonetically
and phonetically balanced
balanced sentences
sentences (10 numbers,
(10 numbers, 7 words)
7 words) at normal
at normal speaking
speaking
speed.
speed. There
There areare 7080
7080 utterance
utterance instances
instances in total.
in total.
(3). The BANCA dataset is recorded
(3). The BANCA dataset is recorded in four indifferent
four different languages
languages (English,
(English, French, French,
Ital-
Italian, Spanish) and filmed under three different conditions
ian, Spanish) and filmed under three different conditions (controlled, degraded (controlled, degraded
and ad-and
adverse)
verse) with awith
totala of
total
208ofparticipants
208 participants and nearly
and nearly 30,000 30,000 utterances.
utterances.
(4). The OuluVS dataset aims to provide a unified
(4). The OuluVS dataset aims to provide a unified standard for standard for performance
performance evaluation
evalua-
of audio-visual speech recognition systems. It contains 20 participants, each of whom states
tion of audio-visual speech recognition systems. It contains 20 participants, each of whom
10 daily greeting phrases 5 times for a total of 1000 utterance instances.
states 10 daily greeting phrases 5 times for a total of 1000 utterance instances.
(5). The LRW dataset is derived from BBC radio and television programs instead of
(5). The LRW dataset is derived from BBC radio and television programs instead of
being recorded by volunteers. It selects the 500 most frequent words and captures short
being recorded by volunteers. It selects the 500 most frequent words and captures short
video of the speakers saying these words, thus there are more than 1000 speakers and more
video of the speakers saying these words, thus there are more than 1000 speakers and
than 550 million utterances. To some extent, the LRW dataset meets the requirements of
more than 550 million utterances. To some extent, the LRW dataset meets the require-
deep learning in terms of data volume. Existing advanced methods trained on the LRW
ments of deep learning in terms of data volume. Existing advanced methods trained on
dataset are shown in Table 2.
the LRW dataset are shown in Table 2.
Table 2. Existing methods with different architectures trained on the LRW dataset. (LRW: Lip Reading
Table 2. Existing
in the Wild). methods with different architectures trained on the LRW dataset. (LRW: Lip Read-
ing in the Wild).
Year Method Frontend Backend Input Size LRW
Year Method Frontend Backend Input Size LRW
2016 Chung et al. [26] VGGM - 112 × 112 61.1%
20162017 Chung et al.
Stafylakis et al. [27] VGGM ResNet-34 - BiLSTM 112×112
112 × 112 61.1%
83.5%
20172019Stafylakis
Wangetetal.
al. [28] ResNet-34
Multi-Grained ResNet-18 BiLSTM 88 × 88 83.5%
Conv BiLSTM 112x112 83.3%
2019 Weng et al. [29] Two-Stream ResNet-18 BiLSTM 112 × 112 84.1%
20192020 WangLuo et al.
et al. [30]Multi-GrainedResNet-18
ResNet-18 Conv BiLSTM BiGRU 88×88
88 × 88 83.3%83.5%
20192020 Weng et al. et al. [31]
Martinez Two-Stream ResNet-18
ResNet-18 BiLSTM TCN 112x112
88 × 88 84.1%85.3%
2020 Luo et al. ResNet-18 BiGRU 88×88 83.5%Appl. Sci. 2023, 13, x FOR PEER REVIEW 10 of 15
Appl. Sci. 2023, 13, 1106
2020 Martinez et al. ResNet-18 TCN 88×88 85.3%
10 of 15
However, the datasets above are all targeted at English lip-reading, and we still need
ChineseHowever,
datasets.theTherefore,
datasets we
abovedecided
are allto use a self-made
targeted at Englishdataset to perform
lip-reading, and weourstillexper-
iment.
need Chinese datasets. Therefore, we decided to use a self-made dataset to perform
ourPinyin, often shortened to just pinyin, is the official romanization system for Stand-
experiment.
ard Mandarin Chinese,
Pinyin, often consisting
shortened of basic
to just pinyin, phonemes
is the (56), consonants
official romanization (23),
system for and simple
Standard
Mandarin Chinese, consisting of basic phonemes (56), consonants (23), and simple
vowels (36). This results in 413 potential combinations plus special cases. Given the four vowels
(36).ofThis
tones results inthere
Mandarin, 413 potential combinations
are around plus syllables.
1600 unique special cases. Given the four tones of
Mandarin, there are around 1600 unique syllables.
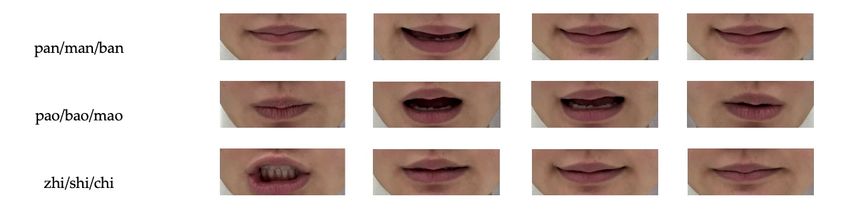
Moreover, in Mandarin, if the phonemes such as ‘b’/ ‘p’/ ‘m’, ‘d’/ ’t’/ ’n’, ‘g’/ ’k’/ ’h’,
Moreover, in Mandarin, if the phonemes such as ‘b’/‘p’/‘m’, ‘d’/‘t’/‘n’, ‘g’/‘k’/‘h’,
‘zh’/ ’ch’/ ’sh’ are followed by the same final, they show no obvious difference visually in
‘zh’/‘ch’/‘sh’ are followed by the same final, they show no obvious difference visually in
liplip
movement.
movement.They Theyare
are shown
shown in inFigure
Figure11.11.
(a) (b)
Figure
Figure (a)(a)Pinyin
11.11. Pinyinwith
withsimilar
similar lip
lipmovement
movement(b)(b)
corresponding lip movement.
corresponding lip movement.
To make the experiment less challenging, we avoid choosing Mandarin characters
To make the experiment less challenging, we avoid choosing Mandarin characters
with the same Pinyin or similar Pinyin and collect more common and simple two-word
with the same Pinyin or similar Pinyin and collect more common and simple two-word
characters in daily life for the time being. As soon as we make progress on the current
characters in daily
dataset, further life for
research forthe time
more being.Mandarin
complex As soonwill
as we make progress on the current
be studied.
dataset,We further
make research for more
a dataset called complex
‘Databox’ Mandarin
consisting of 80will be studied.
volunteers, each of whom says
We make
twenty specifica words
datasettencalled
times,‘Databox’
including: consisting of 80‘Gong
‘Tai Yang (sun)’, volunteers, each ‘Shui
Zuo (work)’, of whomJiao says
(sleep)’,
twenty ‘Chi Fan
specific (eat)’,ten
words ‘Bai Yun (cloud)’,
times, ‘Shun
including: Li Yang
‘Tai (well)’,(sun)’,
‘Zhong’Gong
Guo (China)’, ‘Dui Bu
Zuo (work)’, Qi Jiao
’Shui
(sorry)’, ‘Xie Xie (thanks)’, ‘Zai Jian (goodbye)’, ‘Xue Xiao (school)’, ‘Wan Shua
(sleep)’, ’Chi Fan (eat)’, ’Bai Yun (cloud)’, ’Shun Li (well)’, ’Zhong Guo (China)’, ’Dui Bu (play)’, and
Qi so on. In the
(sorry)’, ’Xieend,
Xiewe have a total
(thanks)’, ’ZaiofJian
16,000 lip-reading‘Xue
(goodbye)’, videos.Xiao (school)’, ‘Wan Shua (play)’,
and soExperiment
3.2. on. In theSettings
end, we have a total of 16,000 lip-reading videos.
(1) Data Preprocessing:
3.2. Experiment
Firstly, weSettings
collect all the videos and put them in different folders according to the class
(1) We
label. Data Preprocessing:
use python libraries os and glob to list and fetch all files respectively and return
videos andwe
Firstly, labels as NumPy
collect all thearrays.
videosThen andwe putuse the OpenCV
them library
in different to read
folders 29 framesto the
according
from each video and crop the lip area by detecting 68 landmarks of the
class label. We use python libraries os and glob to list and fetch all files respectivelyface with the dlib and
library. Afterward, all the frames are resized to 112 × 112, normalized,
return videos and labels as NumPy arrays. Then we use the OpenCV library to read and converted to 29
grayscale. Video data augmentation also proves necessary to overcome the problem of
frames from each video and crop the lip area by detecting 68 landmarks of the face with
limited diversity of data, including Random Crop, Random Rotate, Horizontal Flip, Vertical
theFlip,
dliband
library. Afterward,
Gaussian Blur. all the frames are resized to 112 × 112, normalized, and con-
verted to(2)grayscale.
ParametersVideo data augmentation also proves necessary to overcome the prob-
Settings:
lem of limited
We utilize the open-sourcedincluding
diversity of data, Random Crop,
libraries Tensorflow Random
and Keras, whichRotate,
provideHorizontal
high-level Flip,
Vertical
APIs forFlip, andbuilding
easily Gaussian andBlur.
training models. The model is trained on servers with four
NVIDIA Titan X GPUs.
(2) Parameters Settings: We split the dataset into the training dataset and the test dataset
using a ratio of 8:2 and set the epoch
We utilize the open-sourced libraries and batch size to 6032
Tensorflow andusing
Keras,the which
Adam optimizer
provide high-
with an initial learning rate of 3 × 10 −4 . The frontend and backend of the network are
level APIs for easily building and training models. The model is trained on servers with
pretrained on LRW. Dropout is applied with a probability of 0.5 during the training and
four NVIDIA Titan X GPUs. We split the dataset into the training dataset and the test
finally the standard Cross Entropy loss is used to measure how well our model performs.
dataset using a ratio of 8:2 and set the epoch and batch size to 6032 using the Adam opti-
mizer with an initial learning rate of 3e-4. The frontend and backend of the network are
pretrained on LRW. Dropout is applied with a probability of 0.5 during the training and
finally the standard Cross Entropy loss is used to measure how well our model performs.Appl. Sci. 2023, 13, 1106 11 of 15
3.3. Recognition Results
(1) Comparison with the current State-of-the-Art:
In this section, we compare against two frontend types: ResNet-18 and MobileNet v2
on our dataset. ResNet is an extremely deep network using a residual learning framework
that obtains a 28% relative improvement over the COCO dataset. MobileNet is a small, low-
latency, low-power model designed to maximize accuracy and meet resource constraints
for on-device applications. For a fair evaluation, all the models are combined with the
same backend: Temporal Convolutional Network. The performances of different models
are shown in Table 3.
Table 3. Performance of different models. The number of channels is scaled for different capacities,
marked as 0.5×, 1×, and 2×. Channel widths are the standard ones for ShuffleNet V2, while the base
channel width for TCN is 256 channels.
Method Top-1 Acc. (%) FLOPs × 109 Params × 106
ResNet-18 74.4 3.46 12.55
MobileNet v2 69.5 1.48 3.5
ShuffleNet v2 (1×) 71.3 1.73 3.9
ShuffleNet v2 (0.5×) 68.4 0.89 3.0
ShuffleNet v2 (0.5×) (CBAM) 71.2 1.01 3.1
We can see that ResNet-18 has the best accuracy but consumes the most comput-
ing power. The accuracy and computational complexity of ShuffleNet v2 (1×) [19] and
MobileNet v2 are similar using our dataset. When the channel width of Shufflenet v2 is
reduced, there is a decrease in accuracy. But after the attention module CBAM is inserted,
the performance of ShuffleNet v2 (0.5×) is almost the same as ShuffleNet v2 (1×) with the
decrease of FLOPs. In summary, ShuffleNet v2 (0.5×) (CBAM; the one we propose) sur-
passes MobileNet v2 by 0.7% in recognition accuracy and reduces computation resources
by almost 60% compared with ResNet-18, which has the highest accuracy.
As is shown in Figure 12, the x-axis represents how many epochs the model has been
trained for and the y-axis represents the accuracy of the model. The accuracy of the ResNet-
18 network rises the most slowly in the beginning, because it has the most parameters
and the best accuracy. The model ShuffleNet v2 (0.5×) (CBAM) converges well when the
Appl. Sci. 2023, 13, x FOR PEER REVIEW 12 of 16
number of epochs reaches 30 and achieves the second-highest accuracy compared with
other models.
Figure 12. Comparison
Figure 12. Comparison of
of the
the accuracy
accuracy on
on different
different models.
models.
As is shown in Figure 13, the x-axis represents how many epochs the model has been
As is shown in Figure 13, the x-axis represents how many epochs the model has been
trained for and the y-axis represents loss values, which indicates the difference from the
trained for and the y-axis represents loss values, which indicates the difference from the
desired targets. The loss function of the ResNet-18 network decreases the fastest among
desired targets. The loss function of the ResNet-18 network decreases the fastest among
the four architectures because it has the largest number of parameters. When the number
of iterations reaches 30, the loss value of the ShuffleNet (0.5×) (CBAM) network starts to
change more slowly and becomes stable. It implies that the model fits the data well and
at this point the parameters are optimal. Compared with ShuffleNet v2 (0.5×), the Shuf-Appl. Sci. 2023, 13, 1106 12 of 15
3, x FOR PEER REVIEW the four architectures because it has the largest number of parameters.12When
of 15the number
of iterations reaches 30, the loss value of the ShuffleNet (0.5×) (CBAM) network starts to
change more slowly and becomes stable. It implies that the model fits the data well and at
this point the parameters are optimal. Compared with ShuffleNet v2 (0.5×), the ShuffleNet
number of epochs (0.5
reaches 30 and achieves the second-highest accuracy compared with
×) (CBAM) has a lower lost value. The ShuffleNet (0.5×) (CBAM) shares a similar loss
other models. with MobileNet but has a faster GPU speed which is already discussed in Table 2.
0.65
0.6 MobileNet v2
0.55 ShuffleNet v2 (0.5×) (CBAM)
0.5 ShuffleNet v2 (0.5×)
ResNet-18
0.45
loss
0.4
0.35
0.3
0.25
0.2
1 4 7 10 13 16 19 22 25 28 31 34 37 40
epoch
Figure 13. Comparison of loss on different models.
A part of the results of different models on some words are shown in Table 4.
Table 4. Partition of the results of different models on some words.
Figure 13. Comparison of loss on different models.
Model/ ResNet-18 MobileNet v2 ShuffleNet v2 (1×) ShuffleNetv2 (0.5×) ShuffleNet v2 (0.5×)
CharacterAs is shown in(%)Figure 13, the x-axis
(%) represents how(%) many epochs the(%) model has been
(CBAM) (%)
trained for and the
Tai-Yang y-axis represents
78.00% loss values, which
73.00% 74.00%indicates the65.00%
difference from the76.00%
(sun)
desired
Gong-Zuo (work) targets. The loss
73.00% function of the
72.00% ResNet-18 network
72.00% decreases the
69.00% fastest among76.00%
the(sorry)
Dui-Bu-Qi four architectures
79.00%because it has the largest number
71.00% 69.00%of parameters. When the number
69.00% 79.00%
Shui-Jiao (sleep) 79.00% 71.00% 68.00% 69.00% 76.00%
of iterations reaches 30, the loss value of the ShuffleNet(0.5×) (CBAM) network starts to
Chi-Fan
70.00% 68.00% 62.00% 60.00% 73.00%
change more slowly and becomes stable. It implies that the model fits the data well and
(eat)
Bai-Yun (cloud) 79.00% 79.00% 68.00% 66.00% 76.00%
Shun-Liat (well)
this point the parameters
79.00% are optimal.
72.00% Compared69.00%
with ShuffleNet67.00%
v2 (0.5×), the Shuf-
79.00%
Zhong-GuofleNet (0.5×) (CBAM)
(China) 75.00%has a lower lost value. The ShuffleNet
70.00% 65.00% (0.5×) (CBAM)
63.00% shares a simi-
73.00%
Jian-Pan
lar loss with MobileNet
(sorry)
78.00% but has a faster
70.00% GPU speed which
68.00% is already discussed
63.00% in Table 78.00%
2.
A part of the results of different models on some words are shown in Table 4.
Xie-Xie (thanks) 73.00% 74.00% 66.00% 65.00% 70.00%
Zai-Jian (goodbye) 77.00% 70.00% 60.00% 66.00% 77.00%
Xue-Xiao (school) 75.00% 70.00% 69.00% 66.00% 73.00%
Table 4. Partition of the results of different models on some words.
Bai-Zhi
79.00% 71.00% 69.00% 69.00% 78.00%
(paper)
ResNet-18 MobileNet v2 79.00%
Shu-Ben ShuffleNet v272.00%(1×) ShuffleNetv2
69.00% (0.5×) ShuffleNet
63.00% v2 (0.5×) 72.00%
(book)
(%) Gang-Bi (%) (%) (%) (CBAM)(%)
79.00% 70.00% 73.00% 56.00% 71.00%
(pen)
78.00% Shou-Ji 73.00% 79.00% 74.00% 69.00% 65.00%
69.00% 76.00%
65.00% 79.00%
(phone)
Dian-Nao
79.00% 69.00% 67.00% 60.00% 73.00%
73.00%(computer) 72.00% 72.00% 69.00% 76.00%
Ping-Guo
75.00% 63.00% 62.00% 60.00% 69.00%
(apple)
79.00% Xiang-Jiao
(banana)
71.00% 79.00% 69.00% 69.00% 69.00%
69.00% 79.00%
64.00% 78.00%
Pu-Tao
ep) 79.00% (grape) 71.00% 73.00% 68.00% 69.00% 68.00%
69.00% 67.00%
76.00% 77.00%
70.00% 68.00% 62.00% 60.00% 73.00%
ud) 79.00% 79.00% 68.00% 66.00% 76.00%
ll) 79.00% 72.00% 69.00% 67.00% 79.00%You can also read

















































