A Relational Tsetlin Machine with Applications to Natural Language Understanding
←
→
Page content transcription
If your browser does not render page correctly, please read the page content below
ARXIV PREPRINT 1
A Relational Tsetlin Machine with Applications to
Natural Language Understanding
Rupsa Saha, Ole-Christoffer Granmo, Vladimir I. Zadorozhny, Morten Goodwin
Abstract—TMs are a pattern recognition approach that uses finite state machines for learning and propositional logic to represent
patterns. In addition to being natively interpretable, they have provided competitive accuracy for various tasks. In this paper, we
increase the computing power of TMs by proposing a first-order logic-based framework with Herbrand semantics. The resulting TM is
relational and can take advantage of logical structures appearing in natural language, to learn rules that represent how actions and
consequences are related in the real world. The outcome is a logic program of Horn clauses, bringing in a structured view of
unstructured data. In closed-domain question-answering, the first-order representation produces 10× more compact KBs, along with
arXiv:2102.10952v1 [cs.CL] 22 Feb 2021
an increase in answering accuracy from 94.83% to 99.48%. The approach is further robust towards erroneous, missing, and
superfluous information, distilling the aspects of a text that are important for real-world understanding.
F
1 I NTRODUCTION
U SING Artificial Intelligence (AI) to answer natural lan-
guage questions has long been an active research area,
considered as an essential aspect in machines ultimately
have successfully addressed several machine learning tasks,
including natural language understanding [5], [6], [7], [8],
[9], image analysis [10], classification [11], regression [12],
achieving human-level world understanding. Large-scale and speech understanding [13]. The propositional clauses
structured knowledge bases (KBs), such as Freebase [1], constructed by a TM have high discriminative power and
have been a driving force behind successes in this field. constitute a global description of the task learnt [8], [14].
The KBs encompass massive ever-growing amounts of in- Apart from maintaining accuracy comparable to state-of-
formation, which enable easier handling of Open-Domain the-art machine learning techniques, the method also has
Question-Answering (QA) [2] by organizing a large variety provided a smaller memory footprint and faster inference
of answers in a structured format. The difficulty arises in than more traditional neural network-based models [11],
successfully interpreting natural language by artificially in- [13], [15], [16]. Furthermore, [17] shows that TMs can be
telligent agents, both to build the KBs from natural language fault-tolerant, able to mask stuck-at faults. However, al-
text resources and to interpret the questions asked. though TMs can express any propositional formula by using
Generalization beyond the information stored in a KB disjunctive normal form, first-order logic is required to ob-
further complicates the QA problem. Human-level world tain the computing power equivalent to a universal Turing
understanding requires abstracting from specific examples machine. In this paper, we take the first steps towards
to build more general concepts and rules. When the infor- increasing the computing power of TMs by introducing a
mation stored in the KB is error-free and consistent, gener- first order TM framework with Herbrand semantics, referred
alization becomes a standard inductive reasoning problem. to as the Relational TM. Accordingly, we will in the following
However, abstracting world-knowledge entails dealing with denote the original approach as Propositional TMs.
uncertainty, vagueness, exceptions, errors, and conflicting Closed-Domain Question-Answering: As proof-of-
information. This is particularly the case when relying on concept, we apply our proposed Relational TM to so-called
AI approaches to extract and structure information, which Closed-Domain QA. Closed-Domain QA assumes a text
is notoriously error-prone. (single or multiple sentences) followed by a question which
This paper addresses the above QA challenges by refers to some aspect of the preceding text. Accordingly, the
proposing a Relational TM that builds non-recursive first- amount of information that must be navigated is less than
order Horn clauses from specific examples, distilling general for open question-answering. Yet, answering closed-domain
concepts and rules. questions poses a significant natural language understand-
Tsetlin Machines [3] are a pattern recognition approach ing challenge.
to constructing human-understandable patterns from given Consider the following example of information, taken
data, founded on propositional logic. While the idea of from [18]: “The Black Death is thought to have originated
Tsetlin automaton (TA) [4] have been around since 1960s, in the arid plains of Central Asia, where it then travelled
using them in pattern recognition is relatively new. TMs along the Silk Road, reaching Crimea by 1343. From there,
it was most likely carried by Oriental rat fleas living on
the black rats that were regular passengers on merchant
• R. Saha, O. C. Granmo and M. Goodwin are with Centre for AI Research, ships.”One can then have questions such as “Where did the
Department of IKT, University of Agder, Norway.
black death originate?” or “How did the black death make it
• V. I. Zadorozhny is with School of Computing and Information, Univer- to the Mediterranean and Europe?”. These questions can be
sity of Pittsburgh, USA, and Centre for AI Research, University of Agder, answered completely with just the information provided,
Norway.
hence it is an example of closed-domain question answer-ARXIV PREPRINT 2
ing. However, mapping the question to the answer requires real world in various domains. Automated reasoning tech-
not only natural language processing, but also a fair bit of niques use this knowledge to solve problems in domains
language understanding. that ordinarily require human logical reasoning. Therefore,
Here is a much simpler example: “Bob went to the the two key issues in knowledge engineering are how
garden. Sue went to the cafe. Bob walked to the office.” to construct and maintain knowledge bases, and how to
This information forms the basis for questions like “Where derive new knowledge from existing knowledge effectively
is Bob?” or “Where is Sue?”. Taking it a step further, given and efficiently. Automated reasoning is concerned with the
the previous information and questions, one can envision building of computing systems that automate this process.
a model that learns to answer similar questions based on Although the overall goal is to automate different forms of
similar information, even though the model has never seen reasoning, the term has largely been identified with valid
the specifics of the information before (i.e., the names and deductive reasoning as conducted in logical systems. This is
the locations). done by combining known (yet possibly incomplete) infor-
With QA being such an essential area of Natural Lan- mation with background knowledge and making inferences
guage Understanding, there has been a lot of different regarding unknown or uncertain information.
approaches proposed. Common methods to QA include the Typically, such a system consists of subsystems like
following: knowledge acquisition system, the knowledge base itself,
• Linguistic techniques, such as tokenization, POS tag- inference engine, explanation subsystem and user interface.
ging and parsing that transform questions into a precise The knowledge model has to represent the relations be-
query that merely extracts the respective response from tween multiple components in a symbolic, machine under-
a structured database; standable form, and the inference engine has to manipulate
• Statistical techniques such as Support Vector Machines, those symbols to be capable of reasoning. The “way to
Bayesian Classifiers, and maximum entropy models, reason” can range from earlier versions that were simple
trained on large amount of data, specially for open QA; rule-based systems to more complex and recent approaches
• Pattern matching using surface text patterns with tem- based on machine learning, especially on Deep Learning.
plates for response generation. Typically, rule-based systems suffered from lack of gener-
Many methods use a hybrid approach encompassing more ality, and the need for human experts to create rules in
than one of these approaches for increased accuracy. Most the first place. On the other hand most machine learning
QA systems suffer from a lack of generality, and are tuned based approaches have the disadvantage of not being able
for performance in restricted use cases. Lack of available to justify decisions taken by them in human understandable
explainabilty also hinders researchers’ quest to identify pain form [21], [22].
points and possible major improvements [19], [20]. While databases have long been a mechanism of choice
Paper Contributions: Our main contributions in this for storing information, they only had inbuilt capability
paper are as follows: to identify relations between various components, and did
• We introduce a Relational TM, as opposed to a proposi-
not have the ability to support reasoning based on such
tional one, founded on non-recursive Horn clauses and relations. Efforts to combine formal logic programming
capable of processing relations, variables and constants. with relational databases led to the advent of deductive
• We propose an accompanying relational framework
databases. In fact, the field of QA is said to have arisen from
for efficient representation and processing of the QA the initial goal of performing deductive reasoning on a set of
problem. given facts [23]. In deductive databases, the semantics of the
• We provide empirical evidence uncovering that the
information are represented in terms of mathematical logic.
Relational TM produces at least one order of magnitude Queries to deductive databases also follow the same logical
more compact KBs than the Propositional TM. At the formulation [24]. One such example is ConceptBase [25],
same time, answering accuracy increases from 94.83% which used the Prolog-inspired language O-Telos for logical
to 99.48% because of more general rules. knowledge representation and querying using deductive
• We provide a model-theoretical interpretation for the
object-oriented database framework.
proposed framework. With the rise of the internet, there came a need for
unification of information on the web. The Semantic Web
Overall, our Relational TM unifies knowledge representa-
(SW) proposed by W3C is one of the approaches that
tion, learning, and reasoning in a single framework.
bridges the gap between the Knowledge Representation and
Paper Organization: The paper is organized as follows.
the Web Technology communities. However, reasoning and
In Section 2, we present related work on Question Answer-
consistency checking is still not very well developed, despite
ing. Section 3 focuses on the background of the Proposi-
the underlying formalism that accompanies the semantic
tional TM and the details of the new Relational TM. In
web. One way of introducing reasoning is via descriptive
Sections 4 and 5, we describe how we employ Relational
logic. It involves concepts (unary predicates) and roles
TMs in QA and related experiments.
(binary predicates) and the idea is that implicitly captured
knowledge can be inferred from the given descriptions of
2 BACKGROUND AND R ELATED W ORK concepts and roles [26], [27].
The problem of QA is related to numerous aspects of Knowl- One of the major learning exercises is carried out by
edge Engineering and Data Management. the NELL mechanism proposed by [28], which aims to
Knowledge engineering deals with constructing and learn many semantic categories from primarily unlabeled
maintaining knowledge bases to store knowledge of the data. At present, NELL uses simple frame-based knowledgeARXIV PREPRINT 3
representation, augmented by the PRA reasoning system. 3.1.1 Classification
The reasoning system performs tractable, but limited types A TM takes a vector X = (x1 , . . . , xf ) of propositional
of reasoning based on restricted Horn clauses. NELL’s capa- variables as input, to be classified into one of two classes,
bilities is already limited in part by its lack of more powerful y = 0 or y = 1. Together with their negated counter-
reasoning components; for example, it currently lacks meth- parts, x̄k = ¬xk = 1 − xk , the features form a literal set
ods for representing and reasoning about time and space. L = {x1 , . . . , xf , x̄1 , . . . , x̄f }. We refer to this “regular” TM
Hence, core AI problems of representation and tractable as a Propositional TM, due to the input it works with and
reasoning are also core research problems for never-ending the output it produces.
learning agents. A TM pattern is formulated as a conjunctive clause Cj ,
While other approaches such as neural networks are formed by ANDing a subset Lj ⊆ L of the literal set:
considered to provide attribute-based learning, Inductive V Q
Logic Programming (ILP) is an attempt to overcome their Cj (X) = lk ∈Lj lk = lk ∈Lj lk . (1)
limitations by moving the learning away from the attributes E.g., the clause Cj (X) = x1 ∧ x2 = x1 x2 consists of the
themselves and more towards the level of first-order pred- literals Lj = {x1 , x2 } and outputs 1 iff x1 = x2 = 1.
icate logic. ILP builds upon the theoretical framework of The number of clauses employed is a user set parame-
logic programming and looks to construct a predicate logic ter n. Half of the n clauses are assigned positive polarity
given background knowledge, positive examples and neg- (Cj+ ). The other half is assigned negative polarity (Cj− ). The
ative examples. One of the main advantages of ILP over clause outputs, in turn, are combined into a classification
attribute-based learning is ILP’s generality of representation decision through summation:
for background knowledge. This enables the user to pro- Pn/2 Pn/2
vide, in a more natural way, domain-specific background v = j=1 Cj+ (X) − j=1 Cj− (X). (2)
knowledge to be used in learning. The use of background
In effect, the positive clauses vote for y = 1 and the negative
knowledge enables the user both to develop a suitable
for y = 0. Classification is performed based on a majority
problem representation and to introduce problem-specific
vote, using the unit step function: ŷ = u(v) = 1 if v ≥
constraints into the learning process. Over the years, ILP
has evolved from depending on hand-crafted background
0 else 0. The classifier ŷ = u (x1 x̄2 + x̄1 x2 − x1 x2 − x̄1 x̄2 ),
for instance, captures the XOR-relation.
knowledge only, to employing different technologies in
order to learn the background knowledge as part of the
3.1.2 Learning
process. In contrast to typical machine learning, which uses
feature vectors, ILP requires the knowledge to be in terms of Alg. 1 encompasses the entire learning procedure. We ob-
facts and rules governing those facts. Predicates can either serve that, learning is performed by a team of 2f TAs per
be supplied or deducted, and one of the advantages of this clause, one TA per literal lk (Alg. 1, Step 2). Each TA has
method is that newer information can be added easily, while two actions – Include or Exclude – and decides whether to
previously learnt information can be maintained as required include its designated literal lk in its clause.
[29]. Probabilistic inductive logic programming is an exten- TMs learn on-line, processing one training example
sion of ILP, where logic rules, as learnt from the data, are (X, y) at a time (Step 7). The TAs first produce a new
−
further enhanced by learning probabilities associated with configuration of clauses (Step 8), C1+ , . . . , Cn/2 , followed by
such rules [30], [31], [32]. calculating a voting sum v (Step 9).
To sum up, none of the above approaches can be ef- Feedback are then handed out stochastically to each TA
ficiently and systematically applied to the QA problem, team. The difference between the clipped voting sum
especially in uncertain and noisy environments. In this v c and a user-set voting target T decides the probability
paper we propose a novel approach to tackle this problem. of each TA team receiving feedback (Steps 12-20). Note
Our approach is based on relational representation of QA, that the voting sum is clipped to normalize the feedback
and using a novel Relational TM technique for answering probability. The voting target for y = 1 is T and for y = 0
questions. We elaborate on the proposed method in the next it is −T . Observe that for any input X , the probability of
two sections. reinforcing a clause gradually drops to zero as the voting
sum approaches the user-set target. This ensures that clauses
distribute themselves across the frequent patterns, rather
than missing some and over-concentrating on others.
3 B UILDING A R ELATIONAL T SETLIN M ACHINE Clauses receive two types of feedback. Type I feedback
produces frequent patterns, while Type II feedback increases
3.1 Tsetlin Machine Foundation the discrimination power of the patterns.
A Tsetlin Automaton (TA) is a deterministic automaton that Type I feedback is given stochastically to clauses with
learns the optimal action among the set of actions offered positive polarity when y = 1 and to clauses with negative
by an environment. It performs the action associated with polarity when y = 0. Each clause, in turn, reinforces its
its current state, which triggers a reward or penalty based TAs based on: (1) its output Cj (X); (2) the action of the
on the ground truth. The state is updated accordingly, so TA – Include or Exclude; and (3) the value of the literal lk
that the TA progressively shifts focus towards the optimal assigned to the TA. Two rules govern Type I feedback:
action [4]. A TM consists of a collection of such TAs, which • Include is rewarded and Exclude is penalized with prob-
together create complex propositional formulas using con- ability s−1
s whenever Cj (X) = 1 and lk = 1. This re-
junctive clauses. inforcement is strong (triggered with high probability)ARXIV PREPRINT 4
Algorithm 1 Propositional TM advantage of logical structures appearing in natural lan-
input Tsetlin Machine TM, Example pool S , Training guage and process them in a way that leads to a compact,
rounds e, Clauses n, Features f , Voting target T , Specificity s logic-based representation, which can ultimately reduce
1: procedure T RAIN(TM, S, e, n, f, T, s) the gap between structured and unstructured data. While
2: for j ← 1, . . . , n/2 do the Propositional TM operates on propositional input vari-
3: TA+ j ← RandomlyInitializeClauseTATeam(2f ) ables X = (x1 . . . , xf ), building propositional conjunctive
4: TA− j ← RandomlyInitializeClauseTATeam(2f ) clauses, the Relational TM processes relations, variables and
5: end for
6: for i ← 1, . . . , e do constants, building Horn clauses. Based on Fig. 1 and Alg. 2,
7: (Xi , yi ) ← ObtainTrainingExample(S) we here describe how the Relational TM builds upon the
− −
8: C1+ , . . . , Cn/2 ← ComposeClauses(TA+ 1 , . . . , TAn/2 )
original TM in three steps. First, we establish an approach
9:
Pn/2 + Pn/2 −
vi ← j=1 Cj (Xi ) − j=1 Cj (Xi ) . Vote sum for dealing with relations and constants. This is done by
10: vic ← clip (vi , −T, T ) . Clipped vote sum mapping the relations to propositional inputs, allowing the
11: for j ← 1, . . . , n/2 do . Update TA teams use of a standard TM. We then introduce Horn clauses with
12: if yi = 1 then variables, showing how this representation detaches the TM
13: ← T − vic . Voting error from the constants, allowing for a more compact represen-
14: TypeIFeedback(Xi , TA+j , s) if rand() ≤ 2T
tation compared to only using propositional clauses. We
−
15: TypeIIFeedback(Xi , TAj ) if rand() ≤ 2T finally introduce a novel convolution scheme that effectively
16: else
17: ← T + vic . Voting error manages multiple possible mappings from constants to
TypeIIFeedback(Xi , TA+ variables. While the mechanism of convolution remains the
18: j ) if rand() ≤ 2T
19: −
TypeIFeedback(Xi , TAj , s) if rand() ≤ 2T same as in the original [10], what we wish to attain from
20: end if using it in a Relational TM context is completely different,
21: end for as explained in the following.
22: end for
23: end procedure
3.2.1 Model-theoretical Interpretation
The concept of Relational TM can be grounded in the
Algorithm 2 Relational TM
model-theoretical interpretation of a logic program without
input Convolutional Tsetlin Machine TM, Example pool S , functional symbols and with a finite Herbrand model [33],
Number of training rounds e
[34]. The ability to represent learning in the form of Horn
1: procedure T RAIN(TM, S, e)
2: for i ← 1, . . . , e do clauses is extremely useful due to the fact that Horn clauses
3: (X̃ , Ỹ) ← ObtainTrainingExample(S) are both simple, as well as powerful enough to describe any
4: A0 ← ObtainConstants(Ỹ) logical formula [34].
5: (X̃ 0 , Ỹ 0 ) ← VariablesReplaceConstants(X̃ , Ỹ, A0 ) Next, we define the Herbrand model of a logic program.
6: A00 ← ObtainConstants(X̃ 0 ) A Herbrand Base (HB) is the set of all possible ground atoms,
7: Q ← GenerateVariablePermutations(X̃ 0 , A00 ) i.e., atomic formulas without variables, obtained using pred-
8: UpdateConvolutionalTM(TM, Q, Ỹ 0 ) icate names and constants in a logic program P. A Herbrand
9: end for Interpretation is a subset I of the Herbrand Base (I ⊆ HB ). To
10: end procedure
introduce the Least Herbrand Model we define the immediate
consequence operator T P : P (HB) → P (HB), which for
an Herbrand Interpretation I produces the interpretation that
and makes the clause remember and refine the pattern
immediately follows from I by the rules (Horn clauses) in
it recognizes in X .1
the program P :
• Include is penalized and Exclude is rewarded with prob-
ability 1s whenever Cj (X) = 0 or lk = 0. This rein- T P (I) = {A0 ∈ HB | A0 ← A1 , ..., An
forcement is weak (triggered with low probability) and
∈ ground(P ) ∧ {A1 , ..., An } ⊆ I} ∪ I.
coarsens infrequent patterns, making them frequent.
Above, the user-configurable parameter s controls pattern The least fixed point lfp(TP) of the immediate conse-
frequency, i.e., a higher s produces less frequent patterns. quence operator with respect to subset-inclusion is the Least
Type II feedback is given stochastically to clauses with Herbrand Model (LHM) of the program P . LHM identifies the
positive polarity when y = 0 and to clauses with nega- semantics of the program P : it is the Herbrand Interpretation
tive polarity when y = 1. It penalizes Exclude whenever that contains those and only those atoms that follow from
Cj (X) = 1 and lk = 0. Thus, this feedback produces literals the program:
for discriminating between y = 0 and y = 1, by making the
clause evaluate to 0 when facing its competing class. Further ∀A ∈ HB : P |= A ⇔ A ∈ LHM.
details can be found in [3].
As an example, consider the following program P :
3.2 Relational Tsetlin Machine p(a). q(c).
In this section, we introduce the Relational TM, which a q(X) ← p(X).
major contribution of this paper. It is designed to take
Its Herbrand base is
s−1
1. Note that the probability s
is replaced by 1 when boosting true
positives. HB = {p(a), p(c), q(a), q(c)},ARXIV PREPRINT 5
Compare for reinforcement
5. Output OR of evaluations
4. Evaluate clause on i) ii)
each permutation (assume closed
world). Cf. Convolutional TM
GrandParent(Z1,Z2) ← Parent(Z1, Z3), Parent(Z3, Z2)
inference.
3. Replace remaining constants i) Parent(Z1, Z4) Parent(Z1, Z3) Parent(Z3, Z2) Grandparent(Z1, Z2)
with variables. Generate all
replacement permutations.
ii) Parent(Z1, Z3) Parent(Z1, Z4) Parent(Z4, Z2) Grandparent(Z1, Z2)
Cf. Convolutional TM patches.
2. Replace constants in Parent(Z1, J ane) Parent(Z1, Mary) Parent(Mary, Z2) Grandparent(Z1, Z2)
consequent with variables
1. Obtain input
Parent(Bob, J ane) Parent(Bob, Mary) Parent(Mary, Peter) Grandparent(Bob, Peter)
(possibly with errors)
Subset of Interpretation (True Ground Atoms) Immediate Consequent Truth Value of
Consequent
Fig. 1. Relational TM processing steps
and its Least Herbrand Model is: map every atom in HB to a propositional input xk , obtain-
ing the propositional input vector X = (x1 , . . . , xo ) (cf. Sec-
LHM = lfp(T P ) = {p(a), q(a), q(c)}, tion 3.1). That is, consider the w-arity relation ru ∈ R, which
which is the set of atoms that follow from the program P . takes w symbols from A as input. This relation can thus
take q w unique input combinations. As an example, with
3.2.2 Learning Problem the constants A = {a1 , a2 } and the binary relations R =
{r1 , r2 }, we get 8 propositional inputs: x1,1 1 ≡ r1 (a1 , a1 );
Let A = {a1 , a2 , . . . , aq } be a finite set of constants and
x1,2
1 ≡ r (a
1 1 2 , a ); x 2,1
1 ≡ r (a
1 2 1, a ) ; x 2,2
1 ≡ r1 (a2 , a2 );
let R = {r1 , r2 , . . . , rp } be a finite set of relations of arity
x1,1 ≡ r (a
2 1 1, a ); x 1,2
≡ r (a
2 1 2, a ) ; x 2,1
≡ r2 2 , a1 ); and
(a
wu ≥ 1, u ∈ {1, 2, . . . , p}, which forms the alphabet Σ. The 2 2 2
Herbrand base
x2,2
2 ≡ r (a
2 2 2 , a ) . Correspondingly, we perform the same
mapping to get the propositional output vector Y .
HB = {r1 (a1 , a2 , . . . , aw1 ), r1 (a2 , a1 , . . . , aw1 ), Finally, obtaining an input (X̃ , Ỹ), we set the proposi-
. . . , rp (a1 , a2 , . . . , awp ), rp (a2 , a1 , . . . , awp ), . . .} (3) tional input xk to true iff its corresponding atom is in X̃ ,
otherwise it is set to false. Similarly, we set the propositional
is then also finite, consisting of all the ground atoms that output variable ym to true iff its corresponding atom is in
can be expressed using A and R. Ỹ , otherwise it is set to false.
We also have a logic program P , with program rules Clearly, after this mapping, we get a Propositional TM
expressed as Horn clauses without recursion. Each Horn pattern recognition problem that can be solved as described
clause has the form: in Section 3.1 for a single propositional output ym . This is
illustrated as Step 1 in Fig. 1.
B0 ← B1 , B2 , · · · , Bd . (4)
Here, Bl , l ∈ {0, . . . , d}, is an atom ru (Z1 , Z2 , . . . , Zwu ) 3.2.4 Detaching the Relational TM from Constants
with variables Z1 , Z2 , . . . , Zwu , or its negation The TM can potentially deal with thousands of proposi-
¬ru (Z1 , Z2 , . . . , Zwu ). The arity of ru is denoted by tional inputs. However, we now detach our Relational TM
wu . from the constants, introducing Horn clauses with variables.
Now, let X be a subset of the LHM of P , X ⊆ lfp(T P ), Our intent is to provide a more compact representation of
and let Y be the subset of the LHM that follows from X the program and to allow generalization beyond the data.
due to the Horn clauses in P . Further assume that atoms Additionally, the detachment enables faster learning even
are randomly removed and added to X and Y to produce with less data.
a possibly noisy observation (X̃ , Ỹ), i.e., X̃ and Ỹ are not Let Z = {Z1 , Z2 , . . . , Zz } be z variables representing
necessarily subsets of lfp(T P ). The learning problem is to the constants appearing in an observation (X̃ , Ỹ). Here,
predict the atoms in Y from the atoms in X̃ by learning from z is the largest number of unique constants involved in
a sequence of noisy observations (X̃ , Ỹ), thus uncovering the any particular observation (X̃ , Ỹ), each requiring its own
underlying program P . variable.
Seeking Horn clauses with variables instead of constants,
3.2.3 Relational Tsetlin Machine with Constants we now only need to consider atoms over variable configu-
We base our Relational TM on mapping the learning prob- rations (instead of over constant configurations). Again, we
lem to a Propositional TM pattern recognition problem. We map the atoms to propositional inputs to construct a propo-
consider Horn clauses without variables first. In brief, we sitional TM learning problem. That is, each propositionalARXIV PREPRINT 6
input xk represents a particular atom with a specific variable child(Z1 , Z2 ) ← parent(Z2 , Z1 ).
configuration: xk ≡ ru (Zα1 , Zα2 , . . . , Zαwu ), with wu being This is because the feature “parent(Z2 , Z1 )” predicts
the arity of ru . Accordingly, the number of constants in “child(Z1 , Z2 )” perfectly. Other candidate features like
A no longer affects the number of propositional inputs xk “parent(Z1 , Z1 )” or “parent(Z2 , Z3 )” are poor predictors of
needed to represent the problem. Instead, this is governed “child(Z1 , Z2 )” and will be excluded by the TM. Here, Z3
by the number of variables in Z (and, again, the number of is a free variable representing some other constant, different
relations in R). That is, the number of propositional inputs from Z1 and Z2 .
is bounded by O(z w ), with w being the largest arity of the Then the next training example comes along:
relations in R. Input : parent(Bob, M ary) = 1;
To detach the Relational TM from the constants, we T arget output : child(Jane, Bob) = 0.
first replace the constants in Ỹ with variables, from left to Again, we start with replacing the constants in the target
right. Accordingly, the corresponding constants in X̃ is also output with variables:
replaced with the same variables (Step 2 in Fig. 1). Finally, Input : parent(Bob, M ary) = 1;
the constants now remaining in X̃ is arbitrarily replaced T arget output : child(Z1 , Z2 ) = 0
with additional variables (Step 3 in Fig. 1). which is then completed for the input:
Input : parent(Z2 , M ary) = 1;
3.2.5 Relational Tsetlin Machine Convolution over Variable T arget output : child(Z1 , Z2 ) = 0.
Assignment Permutations The constant Mary was not in the target output, so we
Since there may be multiple ways of assigning variables introduce a free variable Z3 for representing Mary:
to constants, the above approach may produce redundant Input : parent(Z2 , Z3 ) = 1;
rules. One may end up with equivalent rules whose only T arget output : child(Z1 , Z2 ) = 0.
difference is syntactic, i.e., the same rules are expressed The currently learnt clause was:
using different variable symbols. This is illustrated in Step child(Z1 , Z2 ) ← parent(Z2 , Z1 ).
3 of Fig. 1, where variables can be assigned to constants The feature “parent(Z2 , Z1 )” is not present in the input
in two ways. To avoid redundant rules, the Relational TM in the second training example, only “parent(Z2 , Z3 ). As-
produces all possible permutations of variable assignments. suming a closed world, we thus have “parent(Z2 , Z1 )”=0.
To process the different permutations, we finally perform Accordingly, the learnt clause correctly outputs 0.
a convolution over the permutations in Step 4, employing For some inputs, there can be many different ways variables
a TM convolution operator [10]. The target value of the can be assigned to constants (for the output, variables are
convolution is the truth value of the consequent (Step 5). always assigned in a fixed order, from Z1 to Zz ). Returning
to our grandparent example in Fig. 1, if we have:
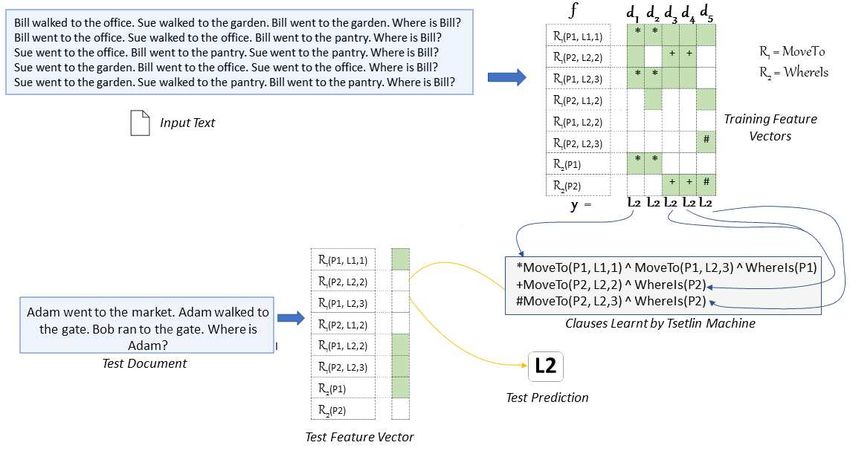
3.2.6 Walk-through of Algorithm with Example Learning Input : parent(Bob, M ary); parent(M ary, P eter);
Problem parent(Bob, Jane)
Fig. 1 contains an example of the process of detaching a Re- T arget output : grandparent(Bob, P eter).
lational TM from constants. We use the parent-grandparent replacing Bob with Z1 and Peter with Z2 , we get:
relationship as an example, employing the following Horn Input : parent(Z1 , M ary); parent(M ary, Z2 );
clause. parent(Z1 , Jane)
T arget output : grandparent(Z1 , Z2 ).
grandparent(Z1 , Z2 ) ← parent(Z1 , Z3 ), parent(Z3 , Z2 ). Above, both Mary and Jane are candidates for being Z3 .
We replace the constants in each training example with One way to handle this ambiguity is to try both, and
variables, before learning the clauses. Thus the Relational pursue those that make the clause evaluate correctly, which
TM never “sees” the constants, just the generic variables. is exactly how the TM convolution operator works [10].
Assume the first training example is Note that above, there is an implicit existential quan-
Input : parent(Bob, M ary) = 1; tifier over Z3 . That is, ∀Z1 , Z2 (∃Z3 (parent(Z1 , Z3 ) ∧
T arget output : child(M ary, Bob) = 1. parent(Z3 , Z2 ) → grandparent(Z1 , Z2 )).
Then Mary is replaced with Z1 and Bob with Z2 in the target A practical view of how the TM learns in such a scenario
output: is shown in Fig. 2. Continuing in the same vein as the
Input : parent(Bob, M ary) = 1; previous examples, the Input Text in the figure is a set of
T arget output : child(Z1 , Z2 ) = 1. statements, each followed by a question. The text is reduced
We perform the same exchange for the input, getting: to a set of relations, which act as the features for the TM to
Input : parent(Z2 , Z1 ) = 1; learn from. The figure illustrates how the TM learns relevant
T arget output : child(Z1 , Z2 ) = 1. information (while disregarding the irrelevant), in order
Here, “parent(Z2 , Z1 )” is treated as an input feature by the to successfully answer a new question (Test Document).
Relational TM. That is, “parent(Z2 , Z1 )” is seen as a single The input text is converted into a features vector which
propositional variable that is either 0 or 1, and the name indicates the presence or absence of relations (R1 , R2 ) in
of the variable is simply the string “parent(Z2 , Z1 )”. The the text, where R1 and R2 are respectively M oveT o (in the
constants may be changing from example to example, so statements) and W hereIs (in the question) relations. For
next time it may be Mary and Ann. However, they all end up further simplification and compactness of representation,
as Z1 or Z2 after being replaced by the variables. After some instead of using person and location names, those specific
time, the Relational TM would then learn the following details are replaced by (P1 , P2 ) and (L1 , L2 ), respectively. In
clause: each sample, the person name that occurs first is termed P1ARXIV PREPRINT 7
throughout, the second unique name is termed P2 , and so “MoveTo” relations. Example-Parentage has “Parent” rela-
on, and similarly for the locations. As seen in the figure, the tions as the information and “Grandparent” as the query.
TM reduces the feature-set representation of the input into
a set of logical conditions or clauses, all of which together TABLE 1
describe scenarios in which the answer is L2 (or Location 2). Relation Extraction
Remark 1. We now return to the implicit existential
Sentence Relation
and universal quantifiers of the Horn clauses, exempli- Mary went to the office. MoveTo
fied in: ∀Z1 , Z2 (∃Z3 (parent(Z1 , Z3 ) ∧ parent(Z3 , Z2 ) → John moved to the hallway MoveTo
grandparent(Z1 , Z2 )). A main goal of the procedure in Where is Mary? Location
Fig. 1 is to correctly deal with the quantifiers “for all” Example-Movement
Sentence Relation
and “exists”. “For all” maps directly to the TM architecture
Bob is a parent of Mary. Parent
because the TM is operating with conjunctive clauses and Bob is a parent of Jane. Parent
the goal is to make these evaluate to 1 (True) whenever the Mary is a parent of Peter Parent
learning target is 1. “For all” quantifiers are taken care of in Is Bob a grandparent of Peter? Grandparent
Step 3 of the relational learning procedure. Example-Parentage
Remark 2. “Exists” is more difficult because it means
that we are looking for a specific value for the variables
in the scope of the quantifier that makes the expression 4.2 Entity Extraction
evaluate to 1. This is handled in the Steps 4-6 in Fig. 1, Once the relations have been identified, the next step is to
by evaluating all alternative values (all permutations with identify the elements of the text (or the entities) that are
multiple variables involved). Some values make the expres- participating in the respective relations. Doing so allows
sion evaluate to 0 (False) and some make the expression us to further enrich the representation with the addition of
become 1. If none makes the expression 1, the output of the restrictions (often real-world ones), which allow the Rela-
clause is 0. Otherwise, the output is 1. Remarkably, this is tional TM to learn rules that best represent actions and their
exactly the behavior of the TM convolution operator defined consequences in a concise, logical form. Since the datasets
in [10], so we have an existing learning procedure in place we are using here consist only of simple sentences, each
to deal with the “Exists” quantifier. (If there exists a patch relation is limited to having a maximum of two entities (the
in the image that makes the clause evaluate to 1, the clause relations are unary or binary).
evaluates to 1). In this step, the more external world knowledge that
can be combined with the extracted entities, the richer the
4 QA IN A R ELATIONAL TM F RAMEWORK resultant representation. In Table 2, Example-Movement, we
could add the knowledge that “MoveTo” relation always
In this section, we describe the general pipeline to reduce involves a “Person” and a “Location”. Or in Example-
natural language text into a machine-understandable rela- Parentage, “Parent” is always between a “Person” and a
tional representation to facilitate question answering. Fig. 3 “Person”. This could, for example, prevent questions like
shows the pipeline diagrammatically, with a small example. “Jean-Joseph Pasteur was the father of Louis Pasteur. Louis
Throughout this section, we make use of two toy examples Pasteur is the father of microbiology. Who is the grandfather
in order to illustrate the steps. One of them is derived from of microbiology?”
a standard question answering dataset [35]. The other is a Note that, as per Fig. 3, it is only possible to start answering
simple handcrafted dataset, inspired by [36], that refers to the query after both Relation Extraction and Entity Extrac-
parent-child relationships among a group of people. Both tion have been performed, and not before. Knowledge of the
datasets consist of instances, where each instance is a set of Relation also allows us to narrow down possible entities for
two or more statements, followed by a query. The expected answering the query successfully.
output for each instance is the answer to the query based on
the statements. TABLE 2
Entity Extraction
4.1 Relation Extraction
Sentence Relation Entities
As a first step, we need to extract the relation(s) present Mary went to the office. MoveTo Mary, office
in the text. A relation here is a connection between two (or John moved to the hallway MoveTo John, hallway
more) elements of a text. As discussed before, relations occur Where is Mary? Location Mary, ?
in natural language, and reducing a text to its constituent Example-Movement
relations makes it more structured while ignoring superflu- Sentence Relation Entities
Bob is a parent of Mary. Parent Bob, Mary
ous linguistic elements, leading to easier understanding. We Bob is a parent of Jane. Parent Bob, Jane
assume that our text consists of simple sentences, that is, Mary is a parent of Peter Parent Mary, Peter
each sentence contains only one relation. The relation found Is Bob a grandparent of Peter? Grandparent Bob, Peter
in the query is either equal to, or linguistically related to the Example-Parentage
relations found in the statements preceding the query.
Table 1 shows examples of Relation Extraction on our
two datasets. In Example-Movement, each statement has 4.3 Entity Generalization
the relation “MoveTo”, while the query is related to “Lo- One of the drawbacks of the relational representation is
cation”. The “Location” can be thought of as a result of the that there is a huge increase in the number of possibleARXIV PREPRINT 8
Fig. 2. The Relational TM in operation
work is utilized for question answering using TM.
4.4 Computational Complexity in Relation TM
One of the primary differences between the relational frame-
work proposed in this paper versus the existing TM frame-
work lies in Relation Extraction and Entity Generalization.
The reason for these steps is that they allow us more
flexibility in terms of what the TM learns, while keeping
the general learning mechanism unchanged.
Extracting relations allows the TM to focus only on the
major operations expressed via language, without getting
Fig. 3. General Pipeline
caught up in multiple superfluous expressions of the same
thing. It also enables to bridge the gap between structured
and unstructured data. Using relations helps the resultant
clauses be closer to real-world phenomena, since they model
relations as more and more examples are processed. One
actions and consequences, rather than the interactions be-
way to reduce the spread is to reduce individual enti-
tween words.
ties from their specific identities to a more generalised
Entity Generalization allows the clauses to be succinct
identity. Let us consider two instances : “Mary went to
and precise, adding another layer of abstraction away from
the office. John moved to the hallway. Where is Mary?”
specific literals, much like Relation Extraction. It also gives
and “Sarah moved to the garage. James went to the
the added benefit of making the learning of the TM more
kitchen. Where is Sarah?”. Without generalization, we end
generalized. In fact, due to this process, the learning reflects
up with six different relations : MoveTo(Mary, Office),
‘concepts’ gleaned from the training examples, rather than
MoveTo(John, Hallway), Location(Mary), MoveTo(Sarah,
the examples themselves.
Garage), MoveTo(James, Kitchen), Location(Sarah). How-
To evaluate computational complexity, we employ the
ever, to answer either of the two queries, we only need the
three costs α, β , and γ , where in terms of computational
relations pertaining to the query itself. Taking advantage of
cost, α is cost to perform the conjunction of two bits, β is cost
that, we can generalize both instances to just 3 relations:
of computing the summation of two integers, and γ is cost
MoveTo(Person1 , Location1 ), MoveTo(Person2 , Location2 )
to update the state of a single automaton. In a Propositional
and Location(Person1 ).
TM, the worst case scenario would be the one in which all
In order to prioritise, the entities present in the query the clauses are updated. Therefore, a TM with m clauses and
relation are the first to be generalized. All occurrences of an input vector of o features, needs to perform (2o + 1) × m
those entities in the relations preceding the query are also number of TA updates for a single training sample. For a
replaced by suitable placeholders. total of d training samples, the total cost of updating is d ×
The entities present in the other relations are then re- γ × (2o + 1) × m.
placed by what can be considered as free variables (since Once weight updates have been successfully performed,
they do not play a role in answering the query). the next step is to calculate the clause outputs. Here the
In the next section we explain how this relational frame- worst case is represented by all the clauses including all theARXIV PREPRINT 9
TABLE 3
Entity Generalization : Part 1
Sentence Relation Entities Reduced Relation
Mary went to the office. MoveTo Mary, office Source MoveTo(X, office)
John moved to the hallway MoveTo John, hallway Source MoveTo(John, hallway)
Where is Mary? Location Mary, ? Target Location(X, ?)
Example-Movement
Sentence Relation Entities Reduced Relation
Bob is a parent of Mary. Parent Bob, Mary Source Parent(X, Mary)
Bob is a parent of Jane. Parent Bob, Jane Source Parent(X, Jane)
Mary is a parent of Peter Parent Mary, Peter Source Parent(Mary, Y)
Is Bob a grandparent of Peter? Grandparent Bob, Peter Target Grandparent(X, Y)
Example-Parentage
TABLE 4
Entity Generalization : Part 2
Sentence Relation Entities Reduced Relation
Mary went to the office. MoveTo Mary, office Source MoveTo(X, A)
John moved to the hallway MoveTo John, hallway Source MoveTo(Y, B)
Where is Mary? Location Mary, ? Target Location(X, ?)
Example-Movement
Sentence Relation Entities Reduced Relation
Bob is a parent of Mary. Parent Bob, Mary Source Parent(X, Z)
Bob is a parent of Jane. Parent Bob, Jane Source Parent(X, W)
Mary is a parent of Peter Parent Mary, Peter Source Parent(Z, Y)
Is Bob a grandparent of Peter? Grandparent Bob, Peter Target Grandparent(X, Y)
Example-Parentage
corresponding literals, giving us a cost of α × 2o × m (for a context of the single sample. Thus, if each sample contains
single sample). r Relations, and a Relation R involves e different entities
The last step involves calculating the difference in votes (E1 , E2 , ..., Ee ), and maximum possible cardinality of sets
from the clause outputs, thus incurring a per-sample cost of E1 , E2 , ..., Ee are |E1 | = |E2 | = ... = |En | = r, the number
β × (m − 1). of features become
o = { |r| |r| |r|
(e+1)
1 × 1 × ... 1 } × r = r
Taken together, the total cost function for a Propositional .
TM can be expressed as: In most scenarios, this number is much lower than the
f (d) = d×[(γ×(2o+1)×m)+(α×2o×m)+(β×(m−1))] one obtained without the use of Entity Generalization.
Expanding this calculation to the Relation TM scenario, A little further modification is required when using the
we need to account for the extra operations being per- convolutional approach. In calculating f (d), the measure
formed, as detailed earlier: Relation Extraction and Entity of o remains the same as we just showed with/without
Generalization. The number of features per sample is re- Entity Generalization. However the second term in the
stricted by the number of possible relations, both in the equation, which refers to the calculation of clause outputs
entirety of the training data, as well as only in the context of (d × α × 2o × m), changes due to the difference in mech-
a single sample. For example, in the experiments involving anism of calculating outputs for convolutional and non-
“MoveTo” relations, we have restricted our data to have 3 convolutional approaches. In the convolutional approach,
statements, followed by a question (elaborated further in the with Entity Generalization, we need to consider free and
next section). Each statement gives rise to a single “MoveTo” bound variables in the feature representation. Bound vari-
relation, which has 2 entities (a location and a person). ables are the ones which are linked by appearance in the
When using the textual constants (i.e., without Entity source and target relations, while the other variables, which
Generalization), the maximum number of possible features are independent of that restriction, can be referred to as
thus becomes equal to the number of possible combination the free variables. Each possible permutation of the free
between the unique entities in the relations. Thus if each variables in different positions are used by the convolutional
sample contains r Relations, and a Relation R involves approach to determine the best generic rule that describes
e different entities (E1 , E2 , ..., Ee ), and cardinality of sets the scenario. In certain scenarios, it may be possible to have
E1 , E2 , ..., Ee be represented as |E1 |, |E2 |, ..., |Ee |, the num- certain permutations among the bound variables as well,
ber of features in the above equation can be re-written as without violating the restrictions added by the relations.
o = { |E11 | × |E12 | × ... |E1e | } × r.
One such scenario is detailed with an example in Section
As discussed earlier in Section 4.3 as well as shown in the 5.2, where a bound “Person” entity can be permuted to
previous paragraph, this results in a large o, since it depends allow any other “Person” entity, as long as the order of
on the number of unique textual elements in each of the en- “MoveTo” relations are not violated. However, it is difficult
tity sets. Using Entity Generalization, the number of features to get a generic measure for the same, which would work ir-
no longer depends on the cardinality of set En,1≤n≤e in the respective of the nature of the relation (or their restrictions).
context of the whole dataset. Instead, it only depends on the Therefore, for the purpose of this calculation, we only takeARXIV PREPRINT 10
into account the permutations afforded to us by the free Possible Answers : [Office, Pantry, Garden, Foyer,
variable. Using the same notation as before, if each sample Kitchen]
contains r Relations, and a Relation R involves e different Once training is complete, we can use the inherent inter-
entities, the total number of variables is R × e. Of these, if pretability of the TM to get an idea about how the model
v is the number of free variables, then they can be arranged learns to discriminate the information given to it. The set
in v! different ways. Assuming v is constant for all samples, of all clauses arrived at by the TM at the end of training
the worst case f (d) can thus be rewritten as represents a global view of the learning, i.e. what the model
f (d) = d × [(γ × (2o + 1) × m) + (v! × α × 2o × m) + has learnt in general. The global view can also be thought
(β × (m − 1))] . of as a description of the task itself, as understood by the
machine. We also have access to a local snapshot, which
is particular to each input instance. The local snapshot
5 E XPERIMENTAL STUDY involves only those clauses that help in arriving at the
To further illustrate how the TM based logic modelling answer for that particular instance.
works practically, we employ examples from a standard Table 5 shows the local snapshot obtained for the above
question answering dataset [35]. For the scope of this work, example. As mentioned earlier, the TM model depends on
we limit ourselves to the first subtask as defined in the two sets of clauses for each class, a positive set and a
dataset, viz. a question that can be answered by the pre- negative set. The positive set represents information favour
ceding context, and the context contains a single supporting of the class, while the negative set represents the opposite.
fact. The sum of the votes given by these two sets thus represent
To start with, there is a set of statements, followed the final class the model decides on. As seen in the example,
by a question, as discussed previously. For this particular all the classes other than “Pantry” receive more negative
subtask, the answer to the question is obtained by a single votes than positive, making it the winning class. The clauses
statement out of the set of statements provided (hence the themselves allow us to peek into the learning mechanism.
term, single supporting fact). For the class “Office”, a clause captures the information that
Input:William moved to the office. Susan went to the garden. (a) the question contains “William”, and (b) the relationship
William walked to the pantry. Where is William? MoveTo(William, Office) is available. This clause votes in
Output: pantry support of the class, i.e. this is an evidence that the answer
We assume the following knowledge to help us construct to the question “Where is William?” may be “Office”. How-
the task: ever, another clause encapsulates the previous two pieces of
1) All statements only contain information pertaining to information, as well as something more : (c) the relationship
relation MoveTo MoveTo(William, Pantry) is available. Not only does this
2) All questions only relate to information pertaining to clause vote against the class “Office”, it also ends up with a
relation CurrentlyAt larger share of votes than the clause voting positively.
3) Relation MoveTo involves 2 entities, such that The accuracy obtained over 100 epochs for this experi-
M oveT o(a, b) : a ∈ {P ersons}, b ∈ {Locations} ment was 94.83%, with a F-score of 94.80.
4) Relation CurrentlyAt involves 2 entities, such that
CurrentlyAt(a, b) : a ∈ {P ersons}, b ∈ {Locations} 5.1.1 Allowing Negative Literals in Clauses
5) MoveTo is a time-bound relation, it’s effect is super-
seded by a similar action performed at a later time. Above results were obtained by only allowing positive liter-
als in the clauses. The descriptive power of the TM goes up
if negative literals are also added. However, the drawback
5.1 Without Entity Generalization to that is, while the TM is empowered to make more precise
The size of the set of statements from which the model has to rules (and by extension, decisions), the overall complexity
identify the correct answer influences the complexity of the of the clauses increase, making them less readable. Also,
task. For the purpose of this experiment, the data is capped previously, the order of the MoveTo action could be implied
to have a maximum of three statements per input, and over by the order in which they appear in the clauses, since only
all has five possible locations. This means that the task for one positive literal can be present per sentence, but in case
the TM model is reduced to classifying the input into one of of negative literals, we need to include information about
five possible classes. the sentence order. Using the above example again, if we do
To prepare the data for the TM, the first step involves re- allow negative literals the positive evidence for Class Office
ducing the input to relation-entity bindings. These bindings looks like:
form the basis of our feature set, which is used to train the Q(W illiam) AND N ot(Q(Susan)) AND
TM. Consider the following input example: M oveT o(S1, W illiam, Off ice) AND
Input => MoveTo(William, Office), MoveTo(Susan, Gar- N OT (M oveT o(S3, W illiam, Garden)) AND
den), MoveTo(William, Pantry), Q(William). N OT (M oveT o(S3, W illiam, F oyer)) AND
Since the TM requires binary features, each input is N OT (M oveT o(S3, W illiam, Kitchen)) AND
converted to a vector, where each element represents the N OT (M oveT o(S3, Susan, Garden)) AND
presence (or absence) of the relationship instances. N OT (M oveT o(S3, Susan, Off ice)) AND
Secondly, the list of possible answers is obtained from N OT (M oveT o(S3, Susan, P antry)) AND
the data, which is the list of class labels. Continuing our N OT (M oveT o(S3, Susan, F oyer)) AND
example, possible answers to the question could be: N OT (M oveT o(S3, Susan, Kitchen)).ARXIV PREPRINT 11
TABLE 5
Local Snapshot of Clauses for example “William moved to the office. Susan went to the garden. William walked to the pantry. Where is William?”
Total Votes
Class Clause +/- Votes
for Class
Q(William) AND MoveTo(William, Office) + 12
Office -35
Q(William) AND MoveTo(William, Office)˜ AND MoveTo(William, Pantry) - 47
Q(William) AND MoveTo(William, Office)˜ AND MoveTo(William, Pantry) + 64
Pantry +49
Q(William) AND MoveTo(William, Office) - 15
MoveTo(Susan, Garden) + 12
Garden -36
Q(William) AND MoveTo(William, Office) AND MoveTo(William, Pantry) - 48
- + 0
Foyer -106
Q(William) AND MoveTo(William, Office) AND MoveTo(William, Pantry)
- 106
AND MoveTo(Susan, Garden)
- + 0
Kitchen -113
Q(William) AND MoveTo(William, Office) AND MoveTo(William, Pantry)
- 113
AND MoveTo(Susan, Garden)
At this point, we can see that the use of constants lead → M oveT o(W illiam, off ice) + M oveT o(Susan, garden) +
to a large number of repetitive information in terms of the M oveT o(W illiam, pantry)
rules learnt by the TM. Generalizing the constants as per → M oveT o(P1 , off ice) + M oveT o(P2 , garden) +
M oveT o(P1 , pantry)
their entity type can prevent this.
→ M oveT o(P1 , L1 ) + M oveT o(P2 , L2 ) + M oveT o(P1 , L3 )
→ M oveT o(P1 , L1 ) + ∗ + M oveT o(P1 , Ln )
5.2 Entity Generalization =⇒ Location(P1 , Ln ).
Given a set of sentences and a following question, the first From the above two subsections, we can see that with
step remains the same as in the previous subsection, i.e. more and more generalization, the learning encapsulated
reducing the input to relation-entity bindings. In the second in the TM model can approach what could possibly be a
step, we carry out a grouping by entity type, in order to human-level understanding of the world.
generalize the information. Once the constants have been
replaced by general placeholders, we continue as previously, 5.3 Variable Permutation and Convolution
collecting a list of possible outputs (to be used as class As described in Section 3.2.5, we can produce all possible
labels), and further, training a TM based model with binary permutations of the available variables in each sample (after
feature vectors. Entity Generalization) as long as the relation constraints
As before, the data is capped to have a maximum of three are not violated. Doing this gives us more information per
statements per input. Continuing with the same example as sample:
above, Input:William moved to the office. Susan went to the garden.
Input:William moved to the office. Susan went to the garden. William walked to the pantry. Where is William?
William walked to the pantry. Where is William? Output: pantry
Output: pantry 1. Reducing to relation-entity bindings: Input
1. Reducing to relation-entity bindings: Input => MoveTo(William, Office), MoveTo(Susan, Garden),
=> MoveTo(William, Office), MoveTo(Susan, Garden), MoveTo(William, Pantry), Q(William)
MoveTo(William, Pantry), Q(William) 2. Generalizing bindings: => MoveTo(Per1, Loc1),
2. Generalizing bindings: => MoveTo(Per1, Loc1), MoveTo(Per2, Loc2), MoveTo(Per1, Loc3), Q(Per1)
MoveTo(Per2, Loc2), MoveTo(Per1, Loc3), Q(Per1) 3. Permuted Variables: => MoveTo(Per2, Loc1),
3. Possible Answers : [Loc1, Loc2, Loc3] MoveTo(Per1, Loc2), MoveTo(Per2, Loc3), Q(Per2)
The simplifying effect of generalization is seen right away: 4. Possible Answers : [Loc1, Loc2, Loc3]
even though there are 5 possible location in the whole This has two primary benefits. Firstly, in a scenario where
dataset, for any particular instance there are always max- the given data does not encompass all possible structural
imum of three possibilities, since there are maximum three differences in which a particular information maybe rep-
statements per instance. resented, using the permutations allows the TM to view a
As seen from the local snapshot (Table 6), the clauses closer-to-complete representation from which to build it’s
formed are much more compact and easily understandable. learning (and hence, explanations). Moreover, since the TM
The generalization also releases the TM model from the can learn different structural permutations from a single
restriction of having had to seen definite constants before sample, it ultimately requires fewer clauses to learn effec-
in order to make a decision. The model can process “Rory tively. In our experiments, permutations using Relational
moved to the conservatory. Rory went to the cinema. Cecil TM Convolution allowed for up to 1.5 times less clauses
walked to the school. Where is Rory?”, without needing than using a non-convolutional approach.
to have encountered constants “Rory”, “Cecil”, “school”, As detailed in Section 4.4, convolutional and non-
“cinema” and “conservatory”. convolutional approaches have different computational
Accuracy for this experiment over 100 epochs was complexity. Hence, the convolutional approach makes sense
99.48% , with a F-score of 92.53. only when the reduction in complexity from fewer clauses
A logic based understanding of the relation “Move” balance the increase due to processing the convolutional
could typically be expressed as : window itself.You can also read

















































